Привет! Меня зовут Андрей Захаров, я Senior Data Scientist в СберМаркете. Когда вы заказываете продукты к пятничному ужину, мы должны быть уверены, что для доставки хватит сборщиков и курьеров. Поэтому мы прогнозируем число заказов в каждом магазине с точностью до часа. В статье — как мы это сделали на данных, которые устаревают уже за 3 месяца.
Проблема: данные спроса устаревают за 3 месяца
Люди заказывают еду всё чаще: доставка быстрее, планировать легче, приложения удобнее и понятнее. Со своей стороны мы подключаем новые магазины и расширяем области доставки. В 2021 году мы доставили в 4 раза больше заказов, чем в 2020.
Из-за такого различия в спросе «тогда» и «сейчас» старые данные о заказах плохо подходят для прогноза объёмов продаж. Иначе говоря, исторический тренд спроса создаёт неоднородность данных в обучающем датасете, и она снижает точность модели после обучения.
Но мы хотим использовать максимальное количество исторических данных, включая спрос и год, и два назад. Ведь люди покупают по тем же причинам, просто меняется общий объём потребления.
Чтобы решить эту проблему, мы заменили прогноз конкретного количества заказов на прогноз скорости их роста, т. е. производную. Так мы используем историю спроса за весь период наблюдений.
Мы прогнозируем число заказов на 14 дней вперед на основе данных за предыдущий 21 день.
Какие данные мы используем, чтобы спрогнозировать заказы
По истории всех магазинов, с которыми мы работаем, мы собрали около миллиона обучающих пар для модели. На вход подаём объём спроса в каждом магазине, его часы работы, размер, число уникальных товарных позиций, географическое положение, маркетинговые акции СберМаркета, планы по открытиям новых магазинов и погоду. На выходе — спрос за последующие 14 дней.

Пример обучающей пары для конкретного магазина на 1 июня 2022 года
Прогнозируем скорость изменения, а не количество заказов
Количество заказов не только меняется в рамках одного магазина, но и различается между магазинами разного размера. В гипермаркетах сотни заказов в сутки, а в мелких магазинах десятки, если не единицы. Если использовать все данные для обучения — точность снижается.
Обе эти проблемы мы решаем за счёт нормировки данных — переходу от абсолютного спроса к скорости его изменения. Нормировка происходит внутри каждой обучающей пары датасета. Выполняется она следующим образом:
- Вычисляется медиана спроса me(7) за последние семь дней.
- На эту медиану делятся 21 значение спроса «на входе» и 14 значений спроса «на выходе».

Нормировка спроса для конкретного магазина на 1 июня 2022
Поясню, почему мы выбираем нормировку на медиану, а не на среднее значение (математическое ожидание). Иногда число заказов нетипично растет в несколько раз на пару дней. Это может быть как результат активной рекламной компании СберМаркета, так и стечение внешних обстоятельств.
Среднее значение чувствительно к таким выбросам. Для ряда значений {10; 10; 10; 1000; 10; 10; 10}, среднее равно 151, а медиана 10. Поэтому, чтобы добиться однородности датасета, мы нормируем данные с помощью медианы.
Отдельная модель на каждый из 14 дней прогноза
На каждый день прогноза мы строим отдельную модель, которая предсказывает спрос по отношению к медиане прошлой недели. Мы тестировали создание одной общей модели вместо 14 отдельных. В её параметры входил «лаг» прогноза в днях (i от 1 до 14, «на какой день делается прогноз»). Но этот вариант показал результаты хуже.
Мы используем LGBMRegressor, который задействует градиентный бустинг. В гиперпараметрах бустинга можно задать init_score — значение, вокруг которого начинается поиск решения. Так как мы перешли к относительным значениям, которые ото дня к дню колеблются вокруг единицы, мы задаём init_score = 1.
Прогнозируем спрос на каждый день
Когда модель обучена на исторических данных, мы подставляем реальные значения спроса за последний 21 день и умножаем их на медиану за прошедшую неделю. Модель возвращает прогноз числа заказов на 14 дней.

Прогноз и факт для мая в одном из магазинов
Прогноз спроса на каждый час
Общее количество заказов на день — это хорошо. Но в течение дня спрос тоже меняется. В середине дня заказов меньше, а утром и вечером — намного больше. У нас есть возможность подстраивать смены сотрудников под часовые нагрузки, если мы сумеем их спрогнозировать. Так что мы прорабатываем прогноз до каждого часа рабочего времени.
Для этого мы используем распределение количества заказов по часам за три последние недели. Мы вычисляем усреднённый профиль для каждого дня, с учётом того, какой это день недели, является ли он выходным, праздничным или рабочим.

Почасовое распределение заказов. В будни больше всего заказов до и после работы. В выходные спрос более равномерный
Имея дневные профили, распределяем спрогнозированное для каждого дня число заказов по часам. Получаем искомые почасовые прогнозы.
Как мы оцениваем качество прогнозов
Подход с нормировкой значений внедрялся постепенно. В роли метрики качества мы используем среднее абсолютное процентное отклонение MAPE. На графике видно, как мы постепенно внедряли улучшения в алгоритм, в том числе и подход с нормировкой.

Улучшение со временем прогноза для одного из магазинов. Чем ниже значение MAPE, тем прогноз точнее
Другие задачи прогнозирования
Прогноз спроса в каждом городе
- Планируем найм сборщиков и курьеров на месяц в каждом городе, с учетом ожидаемой загрузки доставки.
- Период прогноза: на каждый день в течение месяца.
- На вход модели дополнительно подаем планы открытия новых точек в городе.
Для решения этой задачи датасет формируется из суммарных значений спроса по городам. Обращу внимание, есть соблазн просто взять прогнозы по каждому магазину в городе и просуммировать их.
Это распространенная ошибка новичка. Нужно создать отдельный датасет и обучить модель для прогноза спроса на уровне города. Благодаря закону больших чисел данные по целому городу испытывают гораздо меньше статистических колебаний, чем данные по отдельным магазинам. Тут правило простое: что ты прогнозируешь, на том и должно происходить обучение.
Прогноз спроса и оборота во всей стране
- Планируем бюджет СберМаркета и контролируем выполнение плана по всей стране.
- Период прогноза: на каждый день в течение месяца.
- На вход модели дополнительно подаем средний чек, поскольку в плане отражаем оборот.
Обучающий датасет формируется из значений спроса по России. Аналогично ситуации с городами, для прогноза по всей стране создаётся отдельная модель.
Прогноз спроса в новом магазине
- Планируем число курьеров и сборщиков в новом магазине.
- Период прогноза: на каждый день в течении месяца.
- У нового магазина нет истории заказов, поэтому мы строим прогноз на данных ближайших похожих магазинов. Для нового Магнита, который открывается в городе, мы делаем прогноз на основе других Магнитов в этом же городе. Подход для решения этой задачи — предмет отдельной статьи.
Посмотрите аналогичную модель для нефтехимии
Наш подход с нормировкой исторических данных универсален. Осенью 2021 года я опробовал его на соревновании по прогнозу спроса на нефтехимическую продукцию. Моя модель заняла 1 место. Если хотите разобраться, как она работает — вот данные и решение на гитхабе.
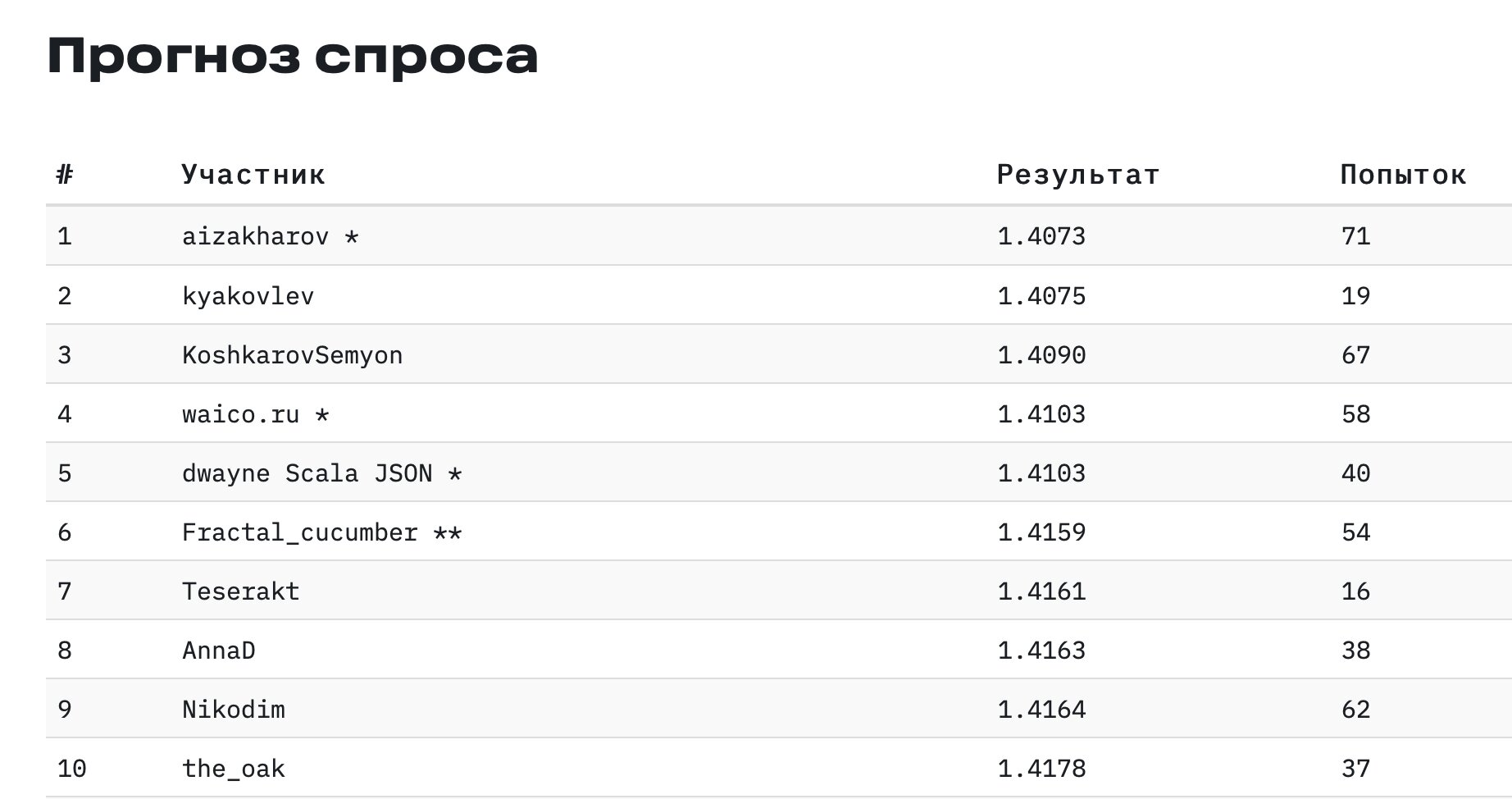
Моя модель в первой строке. Чем меньше число в столбце “Результат”, тем результат лучше (это статистика отклонения от истинных значений)
Мы завели соцсети с новостями и анонсами Tech-команды. Если хотите узнать, что под капотом высоконагруженного e-commerce, следите за нами там, где вам удобнее всего: Telegram, VK.
Asimandia
Смотрю в итоговую графу "результат" и вижу, что у тебя еще и наибольшее количество самбитов. Расскажи какие методы пробинга лидерборда стоит использовать?
aizakharov94 Автор
Не использовал) В основном тестировал различные признаки.