Только ленивый (включая и сценаристов нашего сериала) уже не высказался со своим мнением по поводу «Who is Big Data?» Сегодня давайте порассуждаем не про объемы, а про скорострельность потоков данных. Англоязычное слово Bolt имеет так много смыслов, что легко можно подобрать другой смысл для двухбуквия BD вместо Big Data — Bolt Data, в том числе: удар молнии, вылетать, выболтать, говорить быстро и невнятно.
Модное поветрие обращать внимание только на объемы (Big) уже привело к массовому разочарованию обычного населения. Вот выступает на очередной конференции очередной представитель очередного портала, скажем, с базой данных резюме: «У нас настоящая огромная Биг Дата! 20 миллионов резюме! В прошлом месяце мы переехали на новый 8-64-192-ядерный сервер с 4-8-32 ТБ памяти!»
Дышим ровно и представляем картинку Древнего Египта: 20 000 рабов перетаскивают огромные каменные блоки и возводят очередную, 105-ую, Пирамиду Хеопса. Поскольку ЗАДАЧА определяет решение, а не РЕШЕНИЕ придумывает себе задачу, то для местного Тутанхамона и «древне-египетского портала резюме» такой объем данных (20 миллионов карточек) — плюнуть и растереть.
Представим картинку: почесывая толстое брюшко выходит утром на балкон МантесумХеопс-XXI и повелевает: «Найти мне к вечеру 5 новых омывательниц ног, вчерашних пришлось скормить львам». Поворачивается и уходит, и работа закипает: каждый из 20 000 рабов бросают каменные блоки, хватают по 1 000 резюме, быстренько просматривают каждое за 20 секунд, и к обеду у Главного Евнуха уже 20-30 резюме для собеседования. МантесумХеопс-XXI и его голодные львы — довольны, сыты и счастливы. И рабы тоже передохнули от таскания террабайт камней («ядер»).
Как видим, результат достигнут ВОВРЕМЯ и без лишних умных слов. А назовет ли кто-то сей процесс Big Data или нет — древним египтянам по папирусу. Так что когда вы видите очередное клише, то расслабьтесь, и подумайте о Древнем Египте :-)
Сегодня (материал был размещен на Мегамозге 16-го апреля) прошла очередная Прямая линия с В.В. Путиным. Задачка с технологической точки зрения куда более интересная (мы уже обсуждали в прошлой серии про «Кнопку Обамы»), чем пирамида резюме, в том ключе, что для подрастающего научно-технического поколения и для интересующихся ново-египтян позволяет на реальном примере обсудить Bolt Data и поговорить о лингвистике.
Вот график реакции (см. выше один из переводов слова Bolt — говорить быстро и невнятно) сотен тысяч русскоязычных пользователей соцмедиа: журналистов, политических деятелей, экономистов, мам, пап, бабушек и внуков:
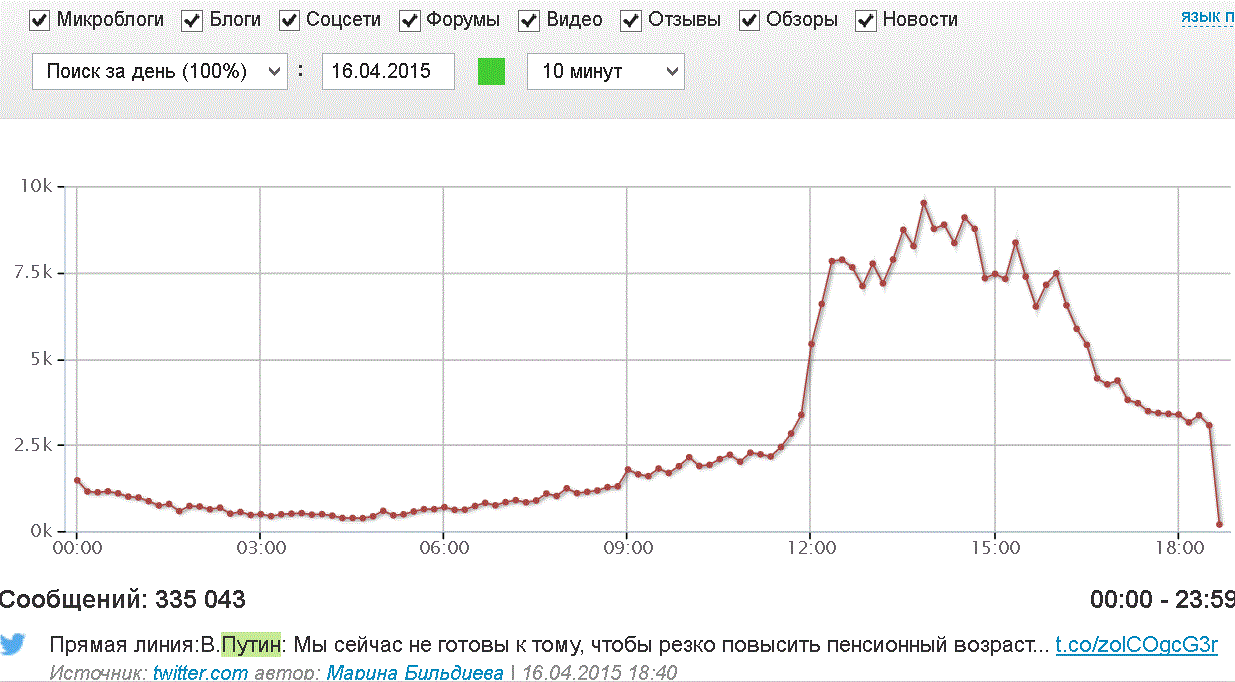
Возможно ли обработать подобный «поток сознания» с помощью 20 000 древне-египетских рабов? Не получается. Ведь только 2-3% обсуждений/комментариев происходит в широко-публичных местах (крупные группы в ВК или ФБ, текстовых трансляцих федеральных агентств и СМИ), остальные «народные выкрики» происходят в рупоры личных аккаунтов для друзей, подруг. Смотреть за каждым из миллиарда аккаунтов Твиттера, Фейсбука или ВКонтакте — на Земле народа не хватит.
Вот такие задачки мы и именуем rtBD&A — real-time Big Data & Analytics (по-русски, типа: аналитика неструктурированных данных больших объемов в реальном времени). С "rt" — понятно, с BD (Big/Bolt Data) — тоже понятно, всего-то введен фактор ограничения по времени (в радиотехники есть соответствующий термин «скважность»), давайте чуть раскроем A — Analytics. Оставим в стороне проблематику «слУшать» миллионы и миллиарды публичных сообщений (про эти системы мы говорили в предыдущей серии), поговорим о проблеме «слЫшать», а также о необходимости «понимать» язык птиц, зверей и людей.
Вот здесь нам и пригодится крутая система модулей E-ngine (название у системы конечно другое, но до публичного объявления пока остановимся на таком, для нашего сериала это не принципиально): по «живому потоку» данных, генерируеммому миллионами людей, нужно:
— Определить язык сообщения;
— Провести лингвистическую обработку текста;
— Определить, что текст о «Путине», а не о «путИне» (если кто не в курсе — это время промыслового лова рыбы);
— Классифицировать сообщение (определить существующую тематику или предложить новую);
— Выявить объекты NER (именованные сущности — фамилии, населенные пункты, названия заводов и пр.), причем не-словарными методами (ну не было в словарях и Википедии объекта «Челябинский метеорит» до катастрофы);
— Определить тональность высказывания (позитив-нейтральность-негатив), причем важная объектная тональность, а не просто «как обычно делается»;
— и еще всякое по мелочи…
— На сладкое: грамотность и пунктуация наших текстов в соцмедиа — ну вы сами знаете :-)
Чтобы усилить представление, давайте прикинем на пальцах: за 4 часа (время Прямой линии) в публичных популярных соцмедиа (микроблоги, соцсети, новости и комментарии, форумы, блоги, видео, обзоры, отзывы) пользователями генерится порядка 8-10 млн русскоязычных (кириллических) сообщений (наша публичная реал-тайм статистика по соцмедиа). Т.е. для обработки «на лету» нужно успевать обрабатывать до 1.000 неструктурированных сообщений В СЕКУНДУ и «молотить» такой поток модулями E-ngine.
Средняя «по больнице» длина сообщений в русскоязычном интернете ~1 Кб. Оценить скорости работы E-ngine вы можете самостоятельно. Для оценки можно использовать презентационные данные системы Compreno (разработка наших друзей и замечательной команды Abbyy) — очень сильный и прекрасный инструмент, на разработку которого потрачено тысячи человеко-лет: для обработки 1 Кб текста понадобится 5-10 секунд, но и качество обработки «книжного языка» — очень высокое.
Итак, краткое содержание серии:
1. Не ловимся на уже избитый и местами даже «убитый» термин Big Data — термин явно ждет судьба гордого термина 90-х «Портал», которое можно встретить в названии везде и всюду, типа «Портал вечернего клуба танцев в селе Подосиновики».
2. Сквозь прищур оцениваем великолепную длину ног новой PR-щицы, щебещущей про «наши петабайты» никому не нужных данных. Данные нужны нужные.
3. И вОвремя.
4. Интеллектуальные решения, методы и алгоритмы имеют тем бОльшую ценность, чем выше скорость решений, методов и алгоритмов. Не все задачи можно растащить на 20 000 древне-египетских рабов.
А между сериями можно порассуждать на досуге про новый путь «Голубого гиганта»: IBM продал Lenovo подразделение ПК, задружился с Twitter, направил 10 000 сотрудников на переобучение в Data Scientist, и на днях купил AlchemyAPI (замечательный движок типа E-ngine для нескольких западных языков).
На фоне долгожителя и «вечно молодого» IBM (выбрасывает старое, быстроменяется на новое) совсем не удивляет скоротечная жизнь великого когда-то и амбициозного Sun Microsystems (замечательные серверы были, кстати, и Java живее всех живых), а теперь и новая новость, что когда-то мировой финский лидер мобильного мира Nokia (приобретенный недавно Microsoft'ом) решил прикарманить «непотопляемых и вечных» Lucent/Alcatel, которые даже в паре не смогли противостоять китайцам.
Не останавливайтесь надолго под красивыми знаками, как бы Big Data их не звали — это всего лишь красивые раскрученные названия. Двигайтесь — решайте задачи, а не заучивайте решения. Желаем постоянно меняться и открывать новые дороги — это так интересно давать новым решениям новые имена.
P.S. У вашей компании есть понимание как решать задачи типа приведенных выше «не-египетским путем»? Вы чувствуете в себе задатки Data Scientist и примерно понимаете, как «опознать» ситуацию с «Челябинским метеоритом» за 3 минуты, а не 3 часа (как среагировала пресса)? Вы способны алгоритмизировать выявление новых методик спам-ботов Твиттера? Тогда вы находитесь на одном из многих, но точно верном пути — у вас прекрасное будущее.
В следующих сериях: NoSQL или колоночные СУБД, откуда растут ноги у слуха, что «данные кончаются», человечество — как всемирный мусорщик.
1-я серия. Big Data — как мечта
2-я серия: Big Data негатива или позитива?
3-я серия: «Кнопка Обамы»
4-я серия. Революция мозгов
5-я серия: Большая игра. Частное мнение
Комментарии (9)

OzzyTech Автор
17.04.2015 14:38Интересный аспект, спасибо за точный комментарий ))
Кстати, в этом аспекте переориентация 10 000 сотрудников IBM смотрится очень даже по Тутанхамонски ))
RPG18
17.04.2015 15:08Под рабами подразумевал ядра/сервера. Если правильно подсчитал, то в вашей задаче имели порядка 3.6Gb данных каждый час, последовательная обработка 1k сообщений на одном ядре занимает порядка 2-ух часов.
Решение IBM вполне себе оправдано, где найдешь на рынке труда 10 000 готовых сотрудников?OzzyTech Автор
17.04.2015 16:18Ага, спасибо за уточнение, теперь более понятно о чем речь. Данных на самом деле в несколько раз (3-5) больше, в том числе и «на входе». Поскольку, с одной стороны, в виду определенной специфики, распределенная система должна быть сильно децентрализована, во-вторых, символы =/= байты, и, главное, есть много сопутствующей информации (начиная от адреса ресурса и заканчивая гео-метками и списками друзей, читателей и пр.).
Кроме того, есть дополнительные расходы для оптимизации скорости Монго и Эластика, авторской базы и пр. и пр. Поэтому в нашей сфере мы обычно «не мыслим» Гбайтами трафика, а используем сущности «сообщение», «текст», «список», «автор» и пр. И лишь когда нужна грубая оценка ширины канала или дисковых массивов-кластеров, тогда «снижаемся» на уровень байт и бит.

meta4
17.04.2015 17:37«Быстрые Big Data данные» — это прямо бинго. Мало того что тавтология, так и еще бессмыслица — данные быстрыми быть не могут.
OzzyTech Автор
17.04.2015 18:21Уважаемый meta4, сложно ответить на комментарий в подобном духе (тональности). Тратить время на проблему различия-восприятия «цвета платья» или неколичественного уровня быстроты обработки лингвомодулей — бессмысленно.

achekalin
17.04.2015 18:50Но по сути мы приходим к тому, о чем начали: если у нас есть данные, к ним нужна обработка. Если данных много — мы бьем их на кусочки, и обрабатываем каждый отдельно. Если может сделать это параллельно — прекрасно, просто добавляем серверы (тысячи их) и время у нас уменьшается (только главное правильно нарезать каждому работу).
Но вопрос никуда не делся: что сделать с _кусочком_ данных? Раб, таскающий камни, вовсе не факт что хорошо определит качество человека по его резюме, не говоря уже про навыки анализа сообщений в сторону Президента. А даже если каждый раб и примет какое-то решение (что при громадном числе рабов займет не годы, а часы), на втором шаге нужно сравнить и принять решения по результатам работы каждого раба.
В общем, как ни крути, и как ни называй — все уходит в алгоритмы.OzzyTech Автор
17.04.2015 22:02На мой взгляд, в первом абзаце у Вас получилась очень хорошее описание идеологии Hadoop ))
Подобный подход идеально описывает, например, задачу по генетике с разбором цепочек ДНК, состоящих всего из нескольких кирпичиков, или потоковых несвязанных (или малосвязанных) данных — чеков в магазине, новых резюме в рекрутинг и т.д. Все то, что характерихуется у математиков цепочками Маркова с нулевой длиной.
Выскажу личную трактовку с «неприличной» аналогией (физики и химики гордо закидают яблоками) — ситуация аналогично неопределенности Гейзенберга и переход от атомов к молекулам: для «правильных» объемов Big Data нужно и достаточно столько, чтобы _совокупность данных_ производила НОВУЮ сущность-данные, которые будут вести себя совершенно _иначе_ (электрон превращается из частицы волной).
Если мы как о примере говорим про &A (data scientist), то до недавнего времени был только мозг человека, который на интуиции находил решение (Шеркол Холмс). Сейчас, с развитием инструментария, который хоть немного, но уже подвинул (расширил) «компьютерные мозги» от просто «молотилки чисел» в сторону лингвистики-семантики-взаимосвязей-анализа, появляется более широкое поле выявление НОВЫХ сущностей-связей-агрегаций.
Грубо говоря, как автомобиль позволил ЛЮБОМУ человеку убыстриться в 20 раз, как вертолет позволил прыгнуть в высоту в 1000 раз, так и Big Data должны позволить любому человеку, а не только Шерлоку Холмсу, в 100 раз повысить наблюдательность.
BlessMaster
07.05.2015 16:32Кстати, не обязательно Hadoop и иже с ним. Вполне актуально не только направление «вширь», но и направление «вглубь» — SIMD, GPGPU, ASIC — очень интересно посмотреть на историю развития майнинга и самих криптовалют, где принцип «время — деньги» — основа бытия.
По поводу того, что инструмент улучшает пользователя — это, имхо, заблуждение. Транспорт ускорил перемещение человека и грузов, расширил сами диапазоны: расстояние, габариты, масса, скорость, но человека не изменил. Бутылочное горлышко неэффективности человека из транспортировки, перешло в другой класс задач. И с каждым витком прогресса это бутылочное горлышко всё уверенней и уверенней подбирается к самому человеку, как самому слабому и мало меняющемуся/развивающемуся звену.
Но что объединяет в этом примере человечество и криптовалюты? Не каждый человек может себе позволить передвижение с помощью автомобиля, а тем более вертолёта. Космический транспорт — вообще до сих пор удел редких избранных, которых всё ещё можно перечислять по именам. Не каждая задача оправдывает подобные затраты.
Более скоростные перемещения требуют и более дорогой инфраструктуры, которые уже не могут себе позволить не только отдельные люди, но и целые страны — автобаны, высокоскоростные железные дороги, космопорты; сам скоростной транспорт и целая промышленность, которая требуется для строительства, производства, обслуживания. Экспансия упирается в эффективность каналов связи, стоимость энергии, ограниченность ресурсов получения энергии и лимиты «экологического долга». «Рост» вглубь — в затраты на производство более совершенной и миниатюрной модели.
В результате мы и ходим по сужающейся спирали, повышая КПД и открывая новые источники (средства доставки) энергии, создавая всё более тонкие и мощные инструменты манипулированя окружающим миром. То же относится и к BD: развиваем алгоритмы, собираем побольше данных, совершенствуем числодробилки и средства коммуникации.
Имхо, суть «новой сущности» — это всегда более короткий, более быстрый, более дешёвый, более энергоэкономный «путь из точки А в точку Б». При том, что все эти «более» — не взаимозаменяемы. Более короткий не значит более быстрый, более дешёвый и более энергоэкономный, если срезать придётся пешком и по болотам, вместо автомобиля по трассе в объезд. Так же и с данными: Hadoop — это не обязательно худшее решение, если данные таки не вмещаются в оперативную память или память при векторном процессоре. Само сравнение без подобных уточнений оказывается некорректным.
Такое вот вышло отрицание отрицания в отдельно взятом комментарии, которое на самом деле ничего не отрицает, а лишь подтверждает тезисы сериала )
RPG18
Как понимаю рабы никуда не делись, мы просто задали им другой алгоритм работы?