Если что-то не сжимается — возможно, что-то тут не так

Выпадающие значения, также называемые «выбросами», — привычная всем преграда, о которую спотыкаются наука о данных и машинное обучение. Концепция выпадения значений интуитивно понятна, но математическому определению поддаётся с трудом. Думаю, дело в том, что придумать такое определение довольно сложно, ведь выброс может по-разному восприниматься разными людьми. Подробности — к старту нашего флагманского курса по Data Science.

Чтобы посмотреть все востребованные профессии, кликните по баннеру.
Возьмём такой набор данных:

Уверен, что большинство людей — как и я — сочтут точку вверху справа выбросом. Точка в середине уже интереснее: с одной стороны, она не относится к окружности, построенной вами в своей голове, поэтому должна быть выбросом. С другой стороны, её координаты x и y не выглядят безумно в сравнении с другими точками — точка в середине действительно является настолько средним значением, насколько это возможно.
Тем не менее я счёл бы эту точку выбросом: мне ощущаю правильным, что точки фактических данных образуют окружность. Но построить на этом работающий алгоритм поиска выбросов не получится.
Если этот маленький двухмерный пример уже может вызвать дискуссию, представьте, что будет, если взять многомерные данные, которые уже не получится оценить визуально. Давайте создадим детектор выбросов при помощи автоэнкодеров, в Tensorflow. Для этого нам потребуется всего несколько строк кода.
Почему нас волнуют выбросы?
Выбросы по определению отличаются от других значений в наборе данных. Выбросами могут стать, в том числе:
- опечатки и ошибки измерений: кто-то внёс в базу вес тела человека 777 кг вместо 77 кг;
- фиктивные значения: что-то не удалось измерить, и в конвейере данных появилось фиксированное значение 999;
- точки редких данных / естественные выбросы: в наборе данных по подержанным автомобилям появился Ferrari, который сильно отличается от остальных.
Выбросы волнуют нас потому, что они могут сильно исказить результаты анализа и процесс машинного обучения при помощи модели.
Если вы подаёте на вход модели ошибки, опечатки и фиктивные значения, то скармливаете ей мусор, а значит, итогом работы модели также окажется мусор.
Загрузка в модель естественных выбросов может привести к переобучению по этим редким точкам данных, о чём важно помнить.
Есть много методов борьбы с выбросами, я не буду подробно на них останавливаться. Наиболее распространённый способ — отсев выбросов. Так мы теряем часть данных, но общее качество вашего анализа или модели может стать выше.
Поиск выбросов
Искать выбросы можно по-разному. На классном сайте scikit-learn приводят сравнение:
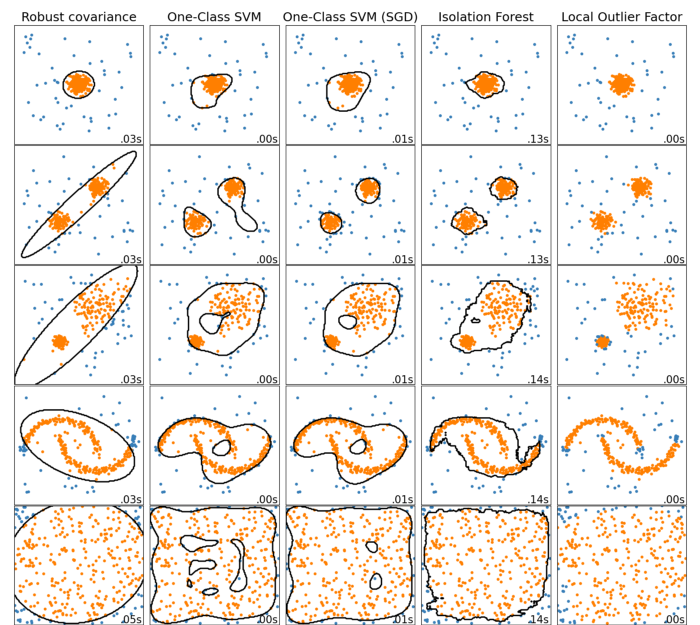
https://scikit-learn.org/stable/auto_examples/miscellaneous/plot_anomaly_comparison.html
Однако мы уделим внимание другому методу, которого на сайте scikit-learn вы (пока) не найдёте:
Автоэнкодеры
Метод основан на автоэнкодерах, вводную статью по которым я опубликовал здесь.
Напомню: хороший автоэнкодер должен уметь сжимать (кодировать) данные с уменьшением размерности, а затем безошибочно распаковывать (декодировать) их.
Можно оттолкнуться от этой идеи и придумать такую логику поиска выбросов с автоэнкодера:
Точку можно считать выбросом, если для неё автоэнкодер вносит большую ошибку.
Для ясности уточню: кодер пытается научиться лучшему кодированию на заданном наборе данных. Поскольку большая часть набора не является выбросами, на автоэнкодер больше всего будут влиять обычные данные, и обрабатывать их он будет лучше.
Выброс — это то, чего кодер не видел при обучении. А значит, кодеру трудно будет найти для него хорошее кодированное значение. Простая идея, правда? Попробуем воплотить её в жизнь!
Простой пример с кодером Tensorflow
Понять и применить этот подход на практике поможет простой пример.
Кодирование окружности
Напишем код для нашего вводного примера с окружностью. Сначала сгенерируем набор данных:
import tensorflow as tf
tf.random.set_seed(1234)
t = tf.expand_dims(tf.linspace(0., 2*3.14, 1000), -1)
noise = tf.random.normal((1000, 2), stddev=0.05)
points = tf.concat([tf.cos(t), tf.sin(t)], axis=1) + noiseГрафик выглядит так:

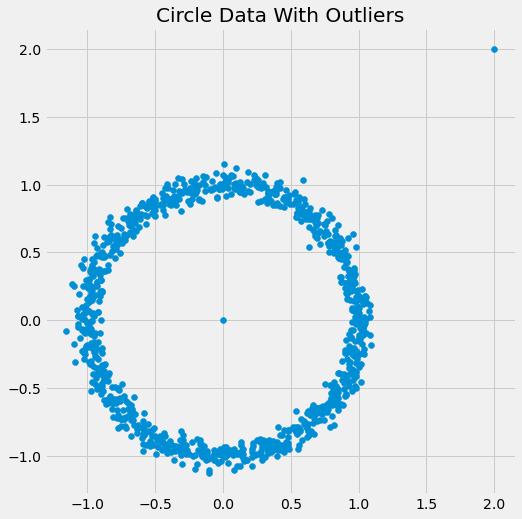
Добавим точки выбросов:
points_with_outliers = tf.concat(
[
points,
tf.constant([[0., 0.], [2., 2.]]) # the outliers
],
axis=0)Результат:
Теперь напишем и обучим автоэнкодер, который сожмёт двухмерные данные в одномерные:
shuffled_points = tf.random.shuffle(points)
encoder = tf.keras.Sequential([
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1) # one-dimensional output
])
decoder = tf.keras.Sequential([
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(2) # decode to two dimensions again
])
autoencoder = tf.keras.Sequential([
encoder,
decoder
])
autoencoder.compile(loss="mse")
autoencoder.fit(
x=shuffled_points, # goal is that output is
y=shuffled_points, # close to the same input
validation_split=0.2, # to check if the model is generalizing
epochs=500
)
# Output:
[...]
# Epoch 500/500
# 25/25 [==============================] - 0s 2ms/step - loss: # 0.0037 - val_loss: 0.0096Отправим точки данных в автоэнкодер:
reconstructed_points = autoencoder(points_with_outliers)Посмотрим на реконструированные данные:

Автоэнкодер хорошо распознал базовый паттерн. Это не идеальная окружность, конечно, но я бы сказал, что получилось довольно неплохо.
Видно, что автоэнкодер научился разворачивать окружность в одномерную линию и сворачивать её обратно в окружность:

Кроме того, по цветам видно, что восстановленные точки очень близки к оригиналу.
Обнаружение выбросов
Куда же пропали выбросы? Переведём все наши точки в модель и выделим в ней обе точки выбросов:

Автоэнкодер поместил оба выброса на изученную аппроксимированную окружность. Иными словами, обе точки сместились на большое расстояние, поскольку были очень далеко от окружности. Выведем некоторые значения:
import pandas as pd
reconstruction_errors = tf.reduce_sum(
(model(points_with_outliers) - points_with_outliers)**2,
axis=1
) # MSE
pd.DataFrame({
"x": points_with_outliers[:, 0],
"y": points_with_outliers[:, 1],
"reconstruction_error": reconstruction_errors
})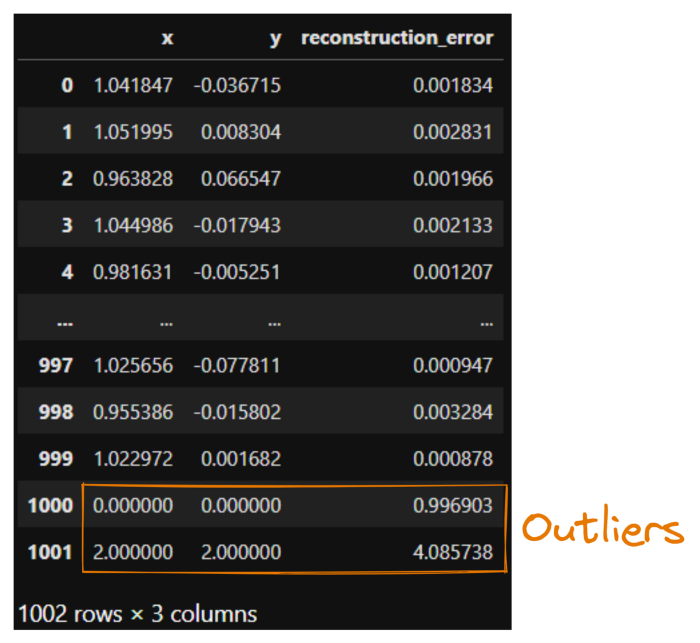
Даже без особого анализа сразу видно, что обычные точки данных имеют ничтожную ошибку реконструкции — около 0,002, а у наших искусственно добавленных выбросов ошибка составляет около 1 и 4. Прекрасно!
Момент, сейчас мы опять заглядывали в таблицу, чтобы найти выбросы. Нельзя ли это как-то автоматизировать?
Логичный вопрос! Да, можно. Для этого есть несколько способов. Например, можно сказать, что все точки с ошибкой реконструкции >µ+3σ являются выбросами. В этой формуле µ — среднее всех ошибок реконструкции, а σ — стандартное отклонение.
Ещё можно сказать, что точки данных с наибольшим x% ошибок реконструкции являются выбросами. В этом случае мы будем считать, что x% набора данных состоит из выбросов, что также известно как фактор загрязнения (contamination factor), который можно найти в некоторых других алгоритмах обнаружения выбросов, таких как изолированный лес (isolation forest).
Сравнение с методами определения выбросов с сайта Scikit-Learn
Я написал детектор для быстрого и грубого обнаружения выбросов, поддающийся сравнению с решениями scikit-learn.
from sklearn.base import BaseEstimator, OutlierMixin
import numpy as np
class AutoencoderOutlierDetector(BaseEstimator, OutlierMixin):
def __init__(self, keras_autoencoder, contamination):
self.keras_autoencoder = keras_autoencoder
self.contamination = contamination
def fit(self, X, y=None):
self.cloned_model_ = tf.keras.models.clone_model(self.keras_autoencoder)
self.cloned_model_.compile(loss="mse")
self.cloned_model_.fit(
x=X,
y=X,
epochs=1000,
verbose=0,
validation_split=0.2,
callbacks=[
tf.keras.callbacks.EarlyStopping(patience=10)
]
)
reconstruction_errors = tf.reduce_sum(
(self.cloned_model_(X) - X) ** 2,
axis=1
).numpy()
self.threshold_ = np.quantile(reconstruction_errors, 1 - self.contamination)
return self
def predict(self, X):
reconstruction_errors = tf.reduce_sum(
(self.cloned_model_(X) - X) ** 2,
axis=1
).numpy()
return 2 * (reconstruction_errors < self.threshold_) - 1Если использовать ту же архитектуру автоэнкодера, что и для окружности, получится:

Здесь виден один недостаток: использование нейросети неподходящей архитектуры может привести к странным контурам. При использовании более простого автоэнкодера с 2 нейронами на скрытый слой вместо 16, как в прошлом примере, получим:

Я бы сказал, это уже чуть лучше, но хорошим такой результат всё ещё не назовёшь.
Домашнее задание для вас: найдите архитектуру, которая выдаст приемлемые результаты при работе с этими небольшими, игрушечными наборами данных!
Заключение
Выбросы могут нарушить анализ и модели. Поэтому нужно уметь выявлять и обрабатывать их. Один из способов сделать это — автоэнкодеры: модель машинного обучения (зачастую это нейросеть) кодирует и снова декодирует данные. Если на стадиях кодирования/декодирования с одной из точек данных что-то идёт не так, эта точка может оказаться выбросом.
Основная идея выглядит стройной, но вам всё равно придётся хорошенько подумать о том, как сконструировать автоэнкодер. Хотя это может быть крайне сложно, такой автоэнкодер сделает то, чего не могут сделать другие модели для обнаружения выбросов. Изолированный лес и прочие модели имеют фиксированную архитектуру, которая позволяет лишь подстраивать некоторые гиперпараметры. Автоэнкодеры дают полную свободу действий — со всеми её плюсами и минусами.
Надеюсь, вы вынесли для себя что-то новое, интересное и полезное. Спасибо, что читали!
Научим вас аккуратно работать с данными, чтобы вы прокачали карьеру и стали востребованным IT-специалистом. Если вы не найдёте работу, мы просто вернём деньги (возврат — акция в рамках «Чёрной пятницы»).
Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
А также
Комментарии (2)

antiquar
09.11.2022 11:28По видимости это тематика робастных статистических процедур.
Было бы неплохо, если бы Вы указали место предложенного метода среди существующих подходов к проблеме.
VPryadchenko
Ну так это ключевой вопрос, однозначного ответа на который - нет. Легко рассуждать об удачности выбора архитектуры, когда можно просто посмотреть на точки на плоскости. А если у вас миллионы многомерных данных, да ещё из какого-нибудь не просто интерпретируемого домена?