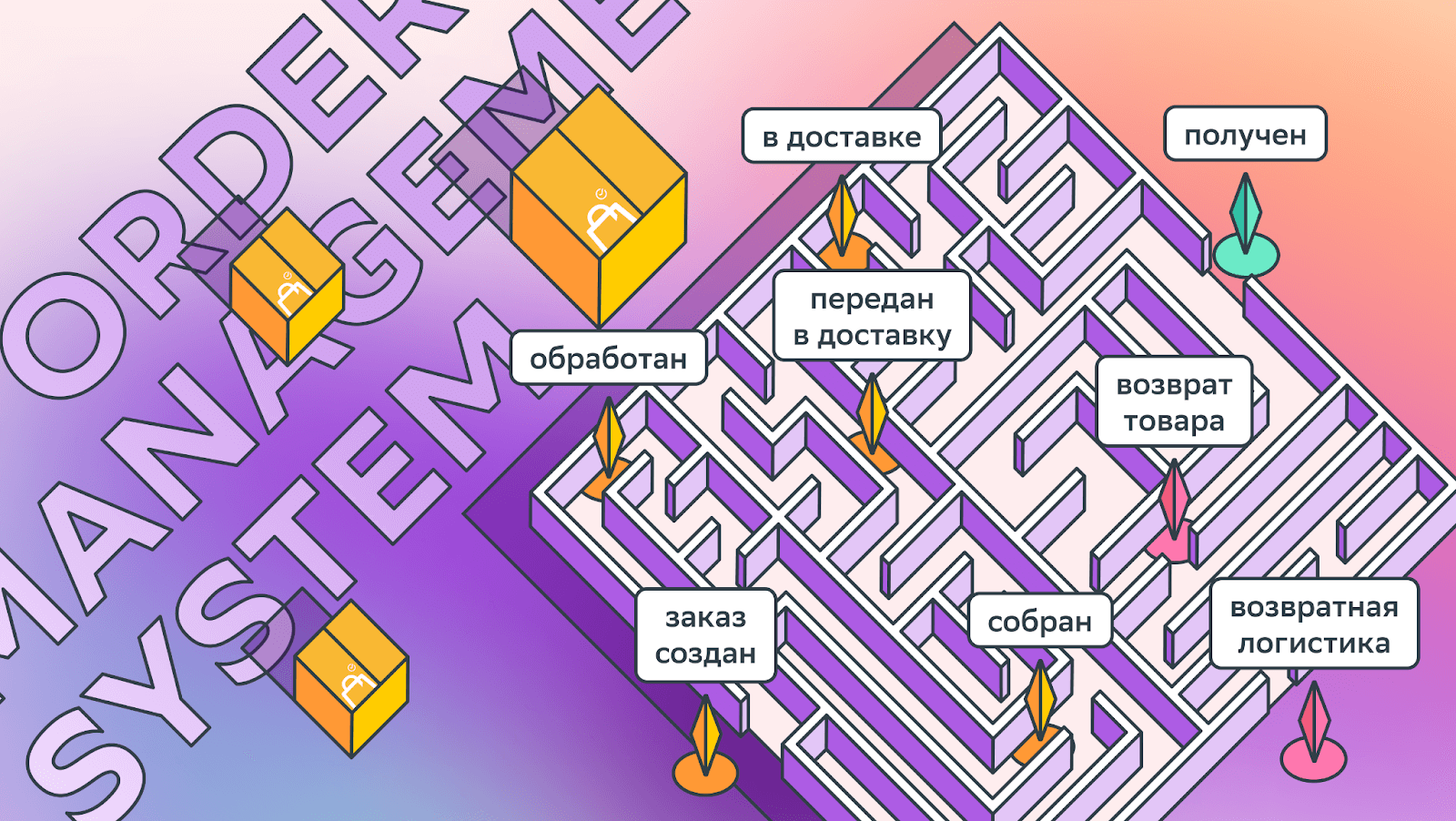
СберМегаМаркет — мультикатегорийный маркетплейс, объединяющий продавцов и покупателей. Для первых это канал продаж с широкой аудиторией, а для вторых — возможность покупать различные товары в одном месте, с программой лояльности и доставкой.
Получается, у маркетплейса сразу две группы клиентов, и нужно реализовать функциональность ИТ-платформы так, чтобы было удобно и продавцам, и покупателям, с чем мы успешно справляемся.
Привет, Хабр! Меня зовут Лосников Сергей, я старший архитектор в СберМегаМаркете. Основное направление моей деятельности - это осуществление архитектурного надзора над бизнес-процессами в направлении операций, а так же над сервисами и системами, поддерживающими их работу. В этой статье я расскажу, как устроена наша система управления заказами и в чем ее особенность. Осторожно, впереди лонгрид.

ИТ-ландшафт СберМегаМаркета изначально затачивался под микросервисную архитектуру — стильно, модно, молодежно. Вопреки или благодаря различным обстоятельствам эту идеологию удается сохранять и преумножать. Но мало просто иметь набор микросервисов, необходимо обеспечивать их слаженную работу.
В активностях продавцов и покупателей на маркетплейсе задействованы различные сервисы, параллельно обрабатываются несколько контекстов каждого конкретного заказа: обслуживание покупателя, контакты с продавцом, логистическое исполнение, управление платежами и т.д. Разные контексты могут обрабатывать отдельные сервисы, и чтобы синхронизировать их работу, нужен оркестратор. Мы таким оркестратором назначили OMS.
Order Management System (OMS) — система, которая автоматизирует весь цикл бизнес-процессов, связанных с созданием, обработкой и выполнением заказов. |
Что представляет собой наша OMS и причем здесь 1С
Как только на витрине создается клиентский заказ, он попадает в OMS, где контролируется оплата и сроки исполнения, координируется работа с поставщиками и службами логистики, предоставляются данные и запускаются процессы подкапотных сервисов.
Наша OMS — это система отслеживания жизненного цикла заказа. Управления заказами там в действительности не так много, ведь, обеспечивая координацию работы нескольких участников и процессов, влиять на физический мир из виртуального невозможно.
Архитектурно OMS — ORM-система, разработанная на платформе 1С:Предприятие и позволяющая дизайнить сам процесс жизненного цикла заказа, причем в первую очередь с помощью визуальных инструментов, а не кода. Такая разработка процессов сама себя документирует, никакие типовые решения при разработке системы не задействованы. Даже БСП, если вы понимаете, о чем я.
Библиотека стандартных подсистем (БСП) — конфигурация от компании 1С с обширным набором уже готовой функциональности, на базе которой можно разрабатывать новые программные решения. |
И сразу о том, почему 1С
Здесь будет уместна шутка, мол, мы пошли в импортозамещение задолго до того, как это стало мейнстримом. Но дело не только в этом.
В далеком 2017 году уже были аналоги, которые можно было рассматривать, но по различным причинам от них отказались: сложность поддержки, недостаток функциональности, экономия финансов, в конце концов. Были даже попытки разработать подобный движок на java + SQL (здесь и далее имеется в виду вендор, ушедший из РФ), однако в этом варианте процессы описывались исключительно кодом, что делало управление ими слишком сложным. Плюс длительность разработки именно визуальных средств управления «с нуля» исключила и этот вариант.
В то же время платформа 1С:Предприятие из коробки предоставляет все необходимое: функциональность быстрой разработки визуальных форм и интерактивной работы с данными, распараллеливание обработки, масштабирование системы, а также возможности интеграции через REST API.
Отдельно отмечу качество КОРП-поддержки от вендора. Наши запросы, от консультаций и помощи в поиске проблем до регистрации и устранения ошибок платформы, обрабатываются быстро и в полном объеме. А для бизнеса такая качественная поддержка поставщика — существенный фактор в пользу использования программного решения.
Если платформу 1С ассоциировать только с бухгалтерией и финансами, есть вероятность упустить весьма удобный и полезный инструмент быстрого прототипирования и разработки программных решений. На платформе можно быстро реализовывать новые фичи, проверять гипотезы, внедрять запросы бизнеса в различных областях — мы подтвердили это на собственном опыте. А когда видим, что фича взлетела, но с нагрузкой платформа 1С уже не справляется, — переводим функциональность на более подходящий стек, имея на руках работающий прототип, понимание процессов и план дальнейшего развития.
Как на JVM можно запускать различные java-приложения, так и на 1С:Предприятие можно внедрять различные программные решения, написанные на внутреннем языке платформы. Но не будем идеализировать платформу.
О некоторых особенностях системы и способах их обхода
OMS — это событийно ориентированная процессинговая система. Единица процессинга — лот, неделимая торговая единица. Каждая штука товара, которую покупатель добавляет в заказ, в системе обработки заказов выделяется в самостоятельный с точки зрения процессинга лот, связанный с заказом, в рамках которого этот самый лот существует.
Жизненный путь каждого лота описывается картой процессов (далее КП). КП отражает всё многообразие бизнес-процессов, их ветвление, зависимости и реакции на события, то есть на факты, произошедшие в физическом или виртуальном мире, например, доставку покупателю, отмену заказа и др.
Процессы в системе могут быть последовательными, параллельными, зависимыми, независимыми, цикличными и т.д. Для визуального представления того, что происходит внутри нашей OMS, идеально подходит этот шедевр (жаль, не знаю, кто его автор):
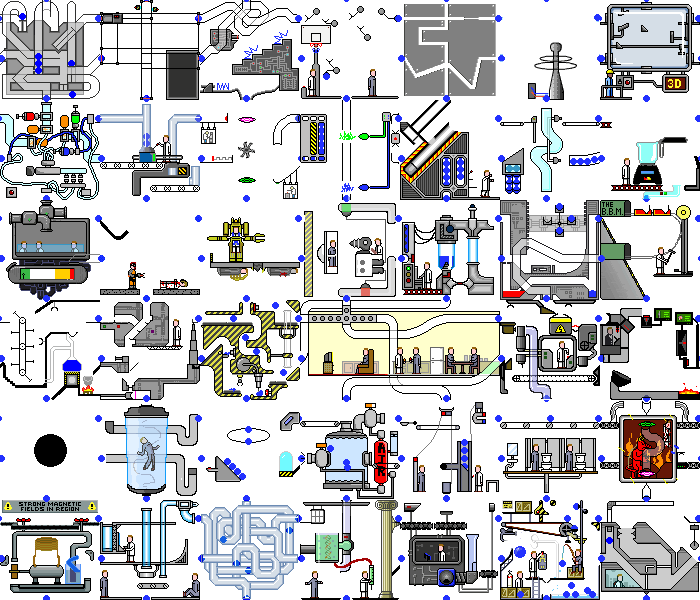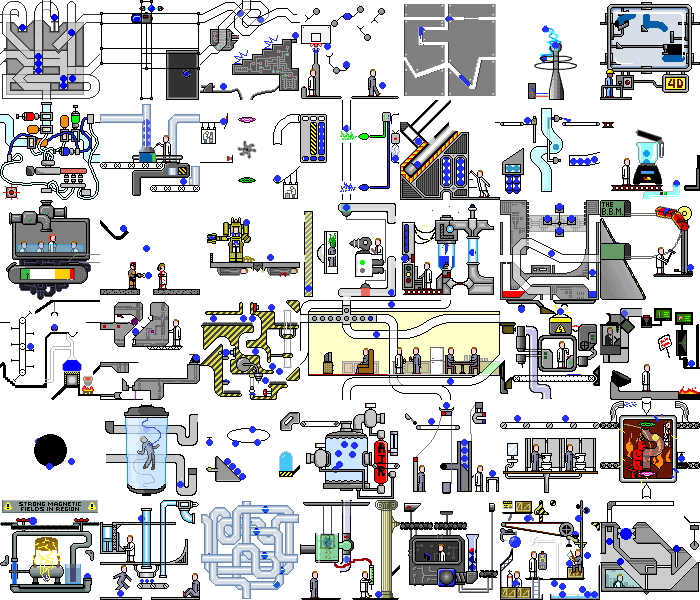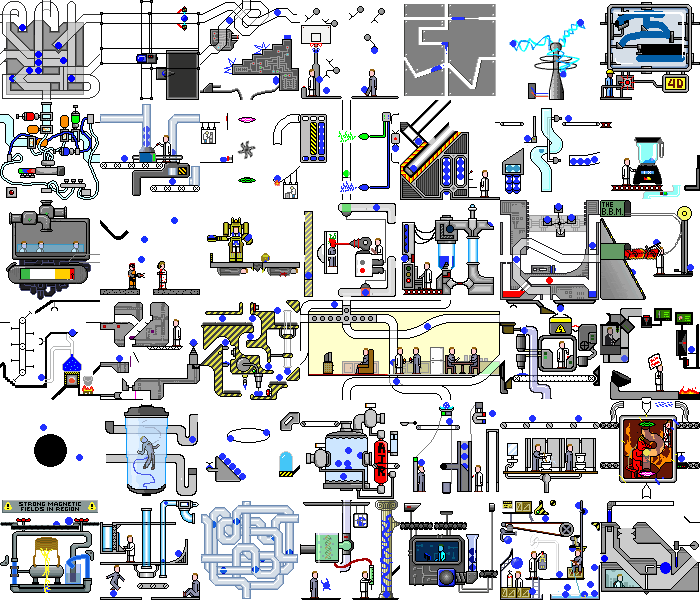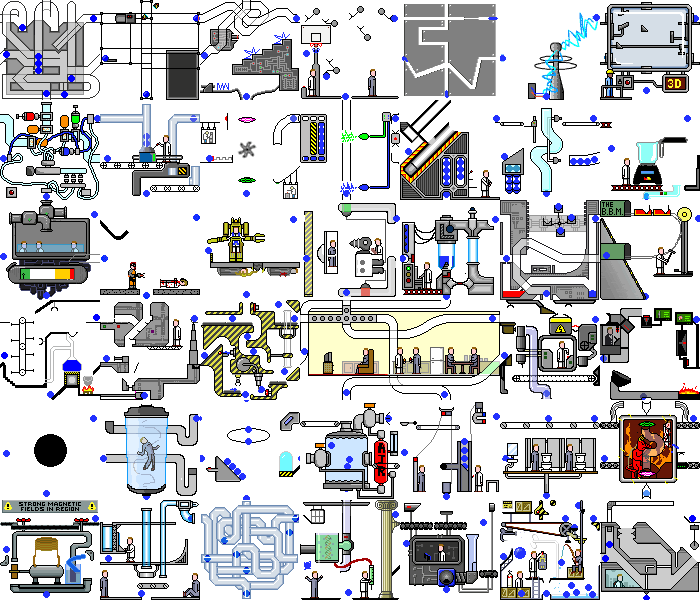
Карта процессов: из чего состоит и почему напоминает пошаговую стратегию
Каждый процесс содержит заранее определенный набор возможных шагов — узлов КП, которые лот может пройти. Для описания процесса используется наша собственная внутренняя нотация. Узлы бывают нескольких видов:
Действие — узел выполнения конкретных, заранее определенных действий: интеграционный вызов, запись или обращение к СУБД и т.д.;
Терминальный — узел завершения процесса;
Ожидание — узел, реализующий приостановку процессинга лота до достижения определенной абсолютной или относительной временной точки;
Триггер — узел без функционального действия, описывающий начало участка карты процесса, ответственного за обработку некоторого возникшего события;
Группа — узел без функционального действия, обеспечивающий иерархическую группировку других узлов.
Для наглядности рассмотрим пример простенького процесса — бармен обслуживает нового покупателя — если бы он был реализован в OMS:

Естественное движение по КП — сверху вниз. Возможны и эдакие GoTo-переходы между участками процессов, реализованные либо через узлы действий соответствующей функциональности, либо через позиционирование на триггер, которое движок процессинга выполняет автоматически при появлении в системе определенного События. Так на картинке выше стрелками показаны возможные переходы лотов по процессу обслуживания покупателя.
Для справки: GoTo-переход возможен не только вниз, но и вверх, например, для реализации циклического процесса. |
Карта процессов из примера выше содержит 13 узлов. Для сравнения, в КП OMS маркетплейса более 4500 узлов, а разработка процесса напоминает пошаговую стратегию.
Представляете, какая у нас работа? Разрабатываем движок пошаговой стратегии, сами в него играем, и нам за это еще и платят. Не работа, а мечта. Мега-мечта. Желающим почувствовать себя частью команды разработки OMS могу предложить обратиться к известному дудлу — процесс дизайна карты будет очень схожий.
Изначально предполагалось, что визуальные средства позволят вывести функцию дизайна бизнесовых процессов из команды разработки и передать ее неким аналитикам или продуктовым менеджерам, но на деле все оказалось сложнее. Необходимость некоторого понимания внутреннего устройства и исторически накопившаяся сложность, а также то, что процесс дизайна здесь схож с разработкой кода, пока не позволили это сделать.
Нагрузка: примерные расчеты и немного про обеспечение обработки
Представьте, что в день регистрируется 1 млн заказов с двумя товарами в каждом. Как мы уже знаем, единица процессинга — лот, а значит, в наших заказах будет 2 млн лотов. Допустим, каждый из них пройдет треть имеющихся узлов карты, то есть 1500 узлов из 4500. Таким образом количество выполненных на узлах действий в сутки будет равно 3 млрд.
Если предположить, что каждое действие представляет собой только одну некую простую операцию интеграции или обращения к СУБД, а распределение нагрузки строго равномерное в течение суток, то получим 34 722 операции в секунду. И это без учета API трафика, который предоставляет OMS. Обеспечивать обработку такой нагрузки нам позволяют приемы из очень широкого спектра областей.
Код: оценка качества и наши системы контроля версий
Под каждым узлом карты процессов скрывается вариант действия, описанный программным кодом.
Для справки: на момент написания статьи количество строк кода в OMS перевалило за 160 000. Размер проекта определяется в первую очередь величиной задачи, которую он решает, поэтому статистические данные приводятся с целью общего ознакомления. |
Качество программного кода — одна из тех важных областей, которые могут существенно повлиять на производительность системы. Оценка качества программного кода выполняется как по текущим задачам силами команды разработки, так и непрерывно с помощью SonarQube. Кроме естественных для языков программирования подходов по чистоте, простоте кода и корректности алгоритмизации, в нашем случае было не обойтись без глубокого понимания работы самой платформы.
В качестве систем контроля версий мы используем штатное хранилище платформы 1С:Предприятие и Git. Пока не используем EDT, если это кого-то интересует.
СУБД: одновременная работа с несколькими системами и другие особенности подхода
На платформе 1С:Предприятие кроме исполнения кода приложения важно взаимодействие с СУБД, потому что без базы данных приложение 1С в принципе не может быть развернуто. Стройность структур данных, оптимальность запросов, наличие покрывающих индексов, качество обслуживания СУБД — это всё критически важно. И нагрузка порядка 40 тыс. запросов в секунду и 50 тыс. транзакций в секунду к этому очень располагает. Наши DBA мега-гуру в этих вопросах — Саше Плясунову персональный привет.
При реализации задач, связанных с обращениями к СУБД, разработчики скрупулезно изучают планы запросов, чтобы добиться максимальной производительности. Если нужно, привлекают DBA, которые собирают статистику по нагрузке, дают ценные рекомендации, совместно трудятся над изменением структуры базы данных для повышения эффективности работы.
Лицензионное соглашение 1С запрещает использовать кастомные индексы, хинты, нештатные реструктуризации и прочие рискованные с точки зрения платформы, но жизненно важные для крупных решений, приемы. Такая «борьба» с платформой ведется не с целью сломать, а чтобы дополнить и улучшить.
С точки зрения платформы 1С:Предприятие никто не должен влиять на структуру базы данных, кроме нее самой. Что вполне понятно, ведь она монопольно перестраивает базу данных в соответствии с заложенной в приложении структурой. Разработчику нет необходимости вручную менять структуру таблиц, он влияет в первую очередь на бизнес-логику приложения. Тем не менее, предоставляя удобство разработчику, платформа отнимает возможность низкоуровневого влияния на базу данных, что критично для высоконагруженных проектов.
Исторически для нас основная СУБД — SQL. При этом мы успешно тестируем работу и на PostgreSQL, правда пока только в dev и test окружениях. Здесь скрывается еще одна особенность, подробнее о которой расскажу ниже, — наша OMS может одновременно работать на нескольких СУБД.
Чтобы распределять нагрузки, используем механизм копий баз данных платформы 1С:Предприятие. Копии реализуем сами средствами СУБД, по сути это ReadOnly-ноды в AlwaysOn-кластере. На копию направляем запросы на чтение в тех случаях, когда не критична актуальность данных — так снимается нагрузка с горячей ноды, уменьшается риск и количество блокировок.
Инфраструктура: как получить лучшую производительность и всё, что нужно для счастья
Для развертывания сервисов мы используем как физические хосты, так и виртуализацию. При высокой нагрузке, которую генерирует OMS, развертывать, например, SQL на виртуальных хостах — не лучший вариант. Технически это, конечно, возможно, но оказаться на одном хосте с каким-нибудь движком полнотекстового поиска типа ElasticSearch чревато нереальными тормозами. Те же аргументы относятся и к развертыванию сервера платформы 1С:Предприятие. Лучшая производительность у нас именно на тех кластерах, которые развернуты на физике: Intel Xeon Gold, SSD, сотня DDR5. Что еще нужно для счастья?
Как говорил выше, виртуализацию тоже используем. Среди бизнес-моделей работы маркетплейса есть модели с операционным и с безоперационным исполнением:
Операционные модели — когда площадка берет на себя организацию логистики. Соответственно, требуется много ресурсов на обработку и взаимодействие со службами доставки.
Безоперационные модели — когда маркетплейсу не нужно организовывать логистику. Например, формат «Закажи и забери»: покупатель резервирует товар через площадку в удобном для себя магазине, затем забирает оттуда самостоятельно.
Так вот безоперационные модели — первые кандидаты на размещение в виртуализации, потому что требуют меньше ресурсов на обработку исполнения заказов.
Быстрые и стабильные каналы связи — само собой разумеющиеся вещи, которые важны не только в пределах конкретного ЦОДа, но и между разными ЦОДами. С резервированием и блэкджеком. Объемы данных, которые прокачиваются через OMS на вход и на выход, довольно большие. Одних логов накапливается порядка 1 ТБ в день. Прописью: один терабайт, Карл!
DevOps: что используем, или особенность деплоя OMS в четырех частях
Качество разработки и высокий TTM достигаются, в том числе, с использованием методологий автоматизации технологических процессов тестирования, настройки и развертывания. Используем конвейеры на Jenkins, и собственные разработки на той же платформе 1С:Предприятие.
Здесь надо отметить особенность деплоя OMS, который состоит из четырех частей:
1. Деплой изменения структуры базы данных. Говорил выше, что платформа сама обеспечивает реструктуризацию таблиц, однако, иногда может быть целесообразно и ручное вмешательство. Например, это актуально для изменения больших таблиц базы данных. Не частый, но вполне реальный кейс.
Штатный механизм реструктуризации платформы на больших таблицах исторически медленный, а так как операция выполняется в монопольном режиме доступа к БД, это чревато длительным простоем и недоступностью системы. Чтобы ускорить процесс, использовали приемы с подменой исходной большой таблицы на идентичную по структуре, но пустую.
Так технологический процесс реструктуризации со стороны платформы выполнялся практически мгновенно, а саму большую таблицу с данными меняли уже ручными скриптами, зачастую более оптимальными и быстрыми, да еще и без остановки сервиса.
2. Деплой кода. Здесь отмечу возможность деплоя на горячую систему без ее остановки — так называемое «динамическое обновление». Большинство разработчиков и администраторов платформы рассматривают это как вредную процедуру, но бывает, что без нее не обойтись.
Также одним из удачных решений по устранению багов на работающем сервисе оказался механизм расширений платформы: чтобы оперативно убрать проблему, устанавливается расширение с багфиксом. А после переноса изменений и деплоя основной конфигурации расширение удаляется.
3. Деплой карты процессов. Речь о нашей карте процессов, пример которой мы рассматривали выше. Именно в соответствии с реализованными процессами исполняются лоты и Заказы. КП очень живой элемент системы и довольно критичный. Будучи данными по сути, КП такая же важная часть системы, как и код. Любые нелогичности и нестыковки могут привести к некорректной обработки и, как следствие, потере заказов.
Деплой КП должен учитывать не только корректную обработку будущих Заказов и лотов, но и тех, что уже существуют в системе и двигаются по процессам.
Если реализовать другую карту — получится уже не система обработки заказов СберМегаМаркета, а система управления работой барменов, как в другом нашем примере.
4. Деплой дополнительных настроек. Здесь есть аналогия с картой процессов. Некоторые дополнительные настройки системы, влияющие на логику ее работы, хранятся в БД. Эти настройки — неотъемлемая часть деплоя, и могут зависеть от окружения dev/test/prod или, например, от целевой модели работы кластера. Например, если речь идет об операционных и безоперационных моделях работы маркетплейса.
Интеграции: про асинхронное интеграционное взаимодействие и сервис логистической интеграции
Общение OMS с окружающими его сервисами происходит через REST API. Для процессинга любое интеграционное взаимодействие — боль, ведь обработка вызова на стороне сервиса-адресата может занимать время, а если не повезет, то можно поймать и таймаут.
Ожидание синхронного ответа при реализации действия на каком-то узле карты процессов — потеря времени и простой процессинга, когда он ничего не делает, а просто ждет. Если бы ожидание ответа на каждом интеграционном вызове было по 10 мс, то из нашего теоретического примера нагрузки можно было бы получить: 34 722 операций * 100 мс = ~58 минут совокупного простоя. Далеко бы мы на этом не уехали.
Для устранения такого негативного эффекта в OMS используем асинхронное интеграционное взаимодействие. Нативной поддержки асинхронных вызовов на момент написания статьи в платформе 1С:Предприятие не появилось. Есть способы использования технологии COM или .NET в приложениях 1С, но у нас же микросервисы!
Разработали сервис асинхронизации. Можно сказать, что это некий зачаток шины данных, но кроме OMS он никем больше не был востребован, поэтому дальнейшего развития не получил. Однако, это не умаляет его важности и функциональных возможностей.
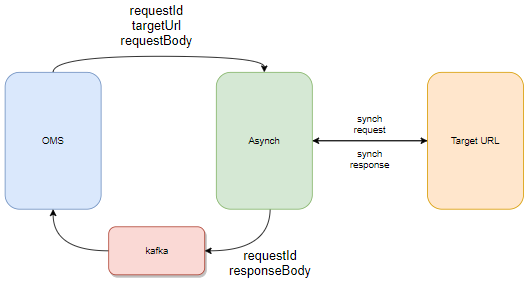
Когда OMS хочет реализовать интеграционное взаимодействие с внутренним или внешним сервисом, она дает поручение на это сервису асинхронизации. Передача поручения сервису асинхронизации с высокой степенью гарантии стабильная и быстрая.
Поручение содержит идентификатор самого поручения, целевой URL и тело запроса. После передачи поручения процессинг OMS продолжает работу и переходит к следующей операции. В то же время сервис асинхронизации реализует очередь отправки синхронных вызовов в целевые сервисы согласно полученным поручениям.
По готовности ответы сервиса асинхоронизации передаются в OMS либо на callbackURL, либо через брокер сообщений, например, Kafka. Чаще всего для передачи ответов используется брокер, что позволяет OMS начитывать ответы согласно скорости своего внутреннего пищеварения, а не давиться от влетающих callback-сообщений.
Отдельная история — взаимодействие OMS с сервисами логистики. Маркетплейс исторически сотрудничает сразу с несколькими логистическими партнерами. Для работы с ними нужно реализовать комплекс интеграций, а так как у каждого партнера своя спецификация, то и разнообразие таких интеграций достаточно большое.
На заре создания OMS все интеграции реализовывались непосредственно в ней. Эти задачи требовали больших ресурсов команды разработки и блокировали параллельные активности. Для решения проблемы создали специальный сервис интеграции, который поддерживает отдельная команда разработки.

Сервис логистической интеграции (LIS) работает по принципам, похожим на работу асинхронизатора. Почему же тогда мы его не использовали? Мы решили избавить OMS от понимания специфики интеграции с каждым конкретным логистическим партнером, а сосредоточили знания и усилия системы на общей бизнес-логике.
Для этого разработали унифицированный интеграционный протокол между OMS и LIS, который обладал некоторой избыточностью, но покрывал все возможные запросы дальнейшей специфической интеграции LIS с конкретным логистическим партнером.
Так OMS просто просит LIS, например, зарегистрировать поручение исполнения доставки: для этого использует унифицированный протокол, предполагающий передачу конкретного исполнителя, которому предназначено поручение.
А сервис логистической интеграции знает спецификации этого исполнителя и реализует интеграционное взаимодействие, результаты которого передает обратно асинхронно через Kafka, как в кейсе с асинхронизатором.
Процессинг: как организована многопоточность OMS на платформе 1С
Обработать большое количество заказов невозможно без использования многопоточности, и наша OMS не исключение.
На платформе 1С:Предприятие многопоточность приложения осуществляется через механизм фоновых заданий. Эти потоки и есть основные генераторы нагрузки в системе. В идеале, интерактивных пользовательских сеансов в системе быть не должно, но в небольшом количестве они все же есть для работы с инцидентами по исполнению заказов. Так как карта процессов «живет» в данных системы, то и работа с ней, анализ и изучение требуют интерактивного пользовательского взаимодействия.

Процессинг OMS поднимает пул горячих потоков, и циклами начинает распределять между ними заказы. В каждом цикле участвуют только те потоки, которые обработали ранее переданные порции и освободились. Потоки не ждут друг друга, таким образом минимизируется время простоя потоков.
Заказы могут как попадать в процессинг, так и исключаться из него. Попадают в процессинг новые заказы или запущенные новые процессы по уже существующим. Исключаются из процессинга заказы, завершившие свой жизненный цикл, а также лоты которых находятся на узлах «Ожидание».
Лоты одного заказа всегда передаются на обработку в один поток — так нет нужды в синхронизации обработки одного заказа несколькими потоками, а также устраняются потенциальные блокировки как со стороны платформы, так и со стороны СУБД. Внутри потока лоты одного заказы всегда обрабатываются последовательно.
Обработка лотов заказа со стороны процессинга заключается в перемещении их по карте процессов, выполнении логики соответствующих узлов, реакции на возникающие события через позиционирование лотов на узлы-триггеры.
Масштабирование: возможности и ограничения, которые мы преодолели
Обслуживать возрастающую нагрузку невозможно без определения подходов к масштабированию. У платформы 1С:Предприятие в этом плане есть неплохие возможности, но есть и ограничения, которые нам пришлось преодолеть.

В целом, приложения на платформе 1С:Предприятие обслуживают такие узлы: веб-кластер, кластер сервера 1С и кластер СУБД. Решение задачи масштабирования должно учитывать возможность увеличения мощностей каждого из них.
Вертикальное масштабирование возможно на всех этих узлах:
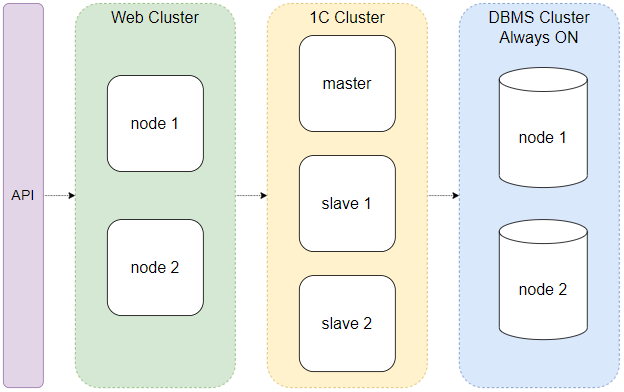
С горизонтальным масштабированием на первый взгляд все тоже неплохо. Каждый из узлов может быть представлен в виде набора нод, между которыми распределяется нагрузка. Имея лицензию КОРП, аналога мелкомягкой неограниченной по процессорам и возможностям лицензии, мы добавили рабочие slave-серверы в кластер 1С, на которые распределяется нагрузка по исполнению потоков процессинга. Одна из схем распределения — четные потоки на один slave-сервер, нечетные на другой.
Однако здесь нужно обратить внимание на одну из особенностей приложений 1С, о которой говорилось ранее, — экземпляр приложения работает со своей базой данных, и пара эта неделима. Невозможно к одной базе данных подключить более одного работающего экземпляра приложения. Технически это сделать получится, только в итоге они начнут «толкаться локтями», что приведет к краху данных и неработоспособности обоих приложений.
Казалось бы, вроде ж можно нарастить количество серверов в кластере 1С, чего еще нужно? Оно-то можно, только не получится «растянуть» это приложение на два ЦОДа. В кластере 1С есть понятие «центральный сервер» — это master, точка входа для сеансов, без чего кластер не работает.
Можно сделать более одного центрального сервера и так повысить отказоустойчивость. Как показала наша практика, падение даже одного центрального сервера из нескольких может привести к неработоспособности приложения. Дело, конечно, в нас — просто мы не умеем их готовить. Но это понимание никак не способствовало успешному масштабированию системы.
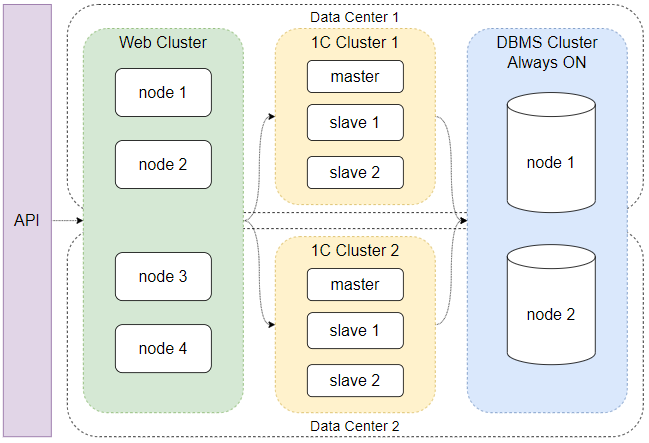
При том, что к одной базе нельзя подключить более одного работающего экземпляра приложения, есть вариант в дополнение к одному работающему экземпляру приложения подключить standby-кластер 1С. Это может помочь повысить отказоустойчивость системы.
При недоступности горячего кластера 1С или даже всего ЦОДа, можно переключиться на standby-кластер в другом ЦОДе. При этом БД будет использоваться та же самая, которую средствами, например, SQL можно растянуть между ЦОДами. Однако, это не решит вопрос масштабирования системы. Кроме того, узким местом может стать СУБД из-за особенностей сетей. В конце концов, как говорится, рискованно «хранить все яйца в одной корзине».

Как можно масштабировать приложение, например, на Go? Воспользоваться возможностями контейнеризации и развернуть необходимое количество экземпляров приложения. А как сделать подобное для приложения на платформе 1С:Предприятие?
Мы решили, что для нас не проблема развернуть несколько экземпляров OMS, каждый из которых обладает свойствами отказоустойчивости, между которыми распределяется входящая нагрузка по заказам, и каждый работает с собственным кластером 1С и базой данных. База данных при этом собственная во всех смыслах — они могут различаться даже по используемой СУБД: один экземпляр OMS на SQL, другой на PostgreSQL. Могут не значит работают, мы не самоубийцы.
Для реализации этого проекта мы создали дополнительный сервис шардирования, который распределяет входящий трафик заказов между экземплярами OMS. Разработали Service Discovery, чтобы с минимальными затратами подключить новое приложение OMS в уже существующее окружение. В дополнение к очевидному способу распределения round-robbin можно настроить распределение заказов с учетом их бизнесовых параметров, например, по тем самым моделям операционного исполнения. Кроме распределения между экземплярами OMS входящего трафика по заказам, сервис шардирования умеет в умное распределение по API: запрос по конкретному заказу будет направлен именно в тот экземпляр OMS, где этот заказ «живет» и обрабатывается.
В такой схеме можно добавлять новые экземпляры OMS, распределять их между несколькими ЦОДами. Пока мы не используем контейнеризацию через Docker или Kubernetes для развертывания OMS. Чтобы управлять группой развернутых экземпляров, мы разработали собственный «Центр управления» и через него делаем, например, раскатку деплоя, настроек и т.д.
Логирование: собственный подход к реализации вместо штатного механизма
При разработке системы мы старались руководствоваться методологией «Приложения двенадцати факторов», в которой регламентируется, что приложение генерирует логи, но не должно заниматься вопросами их маршрутизации и хранения. В целом, платформа 1С:Предприятие поддерживает этот пункт наличием на сервере 1С специального сервиса логирования. Он собирает логи, которые генерируют приложения, и складывает их в специальное хранилище.
Сразу скажу, что мы практически отказались от использования этого штатного механизма. Он конечно работает, ведь совсем выключить его значит потерять часть информации, поэтому эти логи мы тоже собираем. Но пользуемся лишь для регистрации ошибок самой платформы — той категории ошибок, которые разработчик никак не может обработать на уровне своего кода.
Как же тогда OMS реализует логирование? Мы используем собственную механику. Каждый экземпляр приложения генерирует логи в виде JSON-сообщения определенной структуры. Сообщение содержит исчерпывающее описание, начиная от временной отметки, уровня лога и экземпляра OMS, заканчивая более широкой детализацией, например, для логирования интеграционного взаимодействия. Каждое сообщение сохраняется во временный файл на дисковую систему хоста, на котором развернут кластер и исполняется текущий рабочий процесс.

Сохраняем файлы с логами на выделенные быстрые диски, после они экспортируются агентом в EFK, где уже консолидируются, хранятся, ротируются и используются для анализа.
Выше я говорил, что за день генерируется объем логов порядка 1 ТБ — этот объем логов генерирует один экземпляр OMS. При этом у нас есть максимально детализированная картина работы как каждого конкретного экземпляра, так и сервиса в целом. Кстати, подробнее прочитать про опыт построения высоконагруженной системы логирования можно в этой статье нашего блога.
Мониторинг: как отслеживать корректность работы OMS
Отслеживать корректность работы нашей OMS помогают широко известные инструменты Prometeus, Grafana, Zabbix, ЦКК из пакета КИП от 1С.
Кроме технологического мониторинга работы различных параметров серверов, также отслеживаем бизнесовые метрики. Приложение реализует специальное API для сервиса мониторинга, куда отдает описание параметров своего внутреннего исполнения. Системы мониторинга собирают метрики для целей визуализации и оповещения об инцидентах.
В качестве заключения
Наша система OMS — мощный и гибкий инструмент поддержки бизнеса. Это уникальный продукт как с бизнесовой, так и с технологической точки зрения. Синергетическое сочетание иногда совсем не очевидных стеков, технологий, подходов создают простор для творчества, побуждают к непрерывному поиску и росту.
В одну статью сложно вложить все детали и тонкости работы, но возможно даже такое несколько общее описание кому-то принесет пользу.
Будем рады видеть Вас на маркетплейсе СберМегаМаркет, а наша OMS легко и радостно обработает все ваши заказы.