
Привет! На связи Николай Шикунов и Леонид Сидоров из ML-команды СберМаркета. Модель, над которой мы работаем, прогнозирует наличие товаров на полках во всех точках, представленных в приложении, и называется out-of-stock model. В этой статье хотим рассказать, какую проблему бизнеса мы решаем, как эволюционировал наш подход к управлению остатками с 2019 года и к чему мы пришли сейчас.
Что такое SKU и зачем управлять ассортиментом?
Начнём с небольшой вводной в бизнес-логику. СберМаркет – это сервис доставки продуктов и товаров первой необходимости. В приложении клиент добавляет в корзину товары из каталога выбранного магазина (например, Ашана или Метро), а после оформления заказа сборщики собирают эти продукты в торговом зале и передают заказ курьеру, который отправляется по адресу клиента.
Сейчас к СберМаркету подключено более 25 тысяч магазинов, а общее число товаров (они же SKU или stock-keeping units, дословно «наименования, хранящееся на складе») достигло 200 миллионов. Нюанс в том, что у СберМаркета нет своих дарксторов и наши сборщики пользуются теми же полками в магазине, что и обычные покупатели. Когда сборщик не находит выбранный клиентом продукт, в зависимости от настроек клиента товар либо заменяют на другой, либо исключает из сборки. Это мы называем отменой и заменой.
Почему отмены и замены это плохо?
Отмены и замены тянут за собой целый айсберг причин. Если мы не собрали молоко, которое заказал клиент, падает удовлетворенность, оценка заказа и retention. Как следствие, начинает страдать и экономика: от отсутствия товара в корзине падает средний чек и GMV, страдает скорость сборки и в итоге снижается прибыльность на заказ.

Чтобы контролировать отмены и замены мы ввели следующие метрики:
Доля отменённых и заменённых позиций в заказе. Другое название этой метрики — not-found rate.
Обратная ей метрика — целостность заказов. Это доля корзины, которую мы собрали без отмен и замены.

Как вы уже могли догадаться, наша ключевая задача снижать долю отмен и замен, а значит показывать клиенту в каталоге только те товары, которые мы сможем ему привезти.
Почему на данные от ритейлеров нельзя полагаться?
Здесь у вас может возникнуть вопрос: «Разве ритейлеры не предоставляют нам актуальную информацию об остатках?» Это справедливое замечание , но, к сожалению, сток товаров у ритейлера не всегда точный. Этому есть много причин:
товар быстро закончился и это не успели отразить в данных;
товар «затерялся» в магазине или его не успели принести со склада;
товар ещё не приехал в магазин;
поставку зарезервировали под оптовый заказ и товары не доступны розничным покупателям;
и самое неочевидное: количество товара не отражает его качества. Напрмер, на полке может стоять 25 бутылок молока, но у всех у них срок годности заканчивается через 1-2 дня. Такие продукты мы не можем собрать для клиента по нашим внутренним регламентам качества.

Мы поняли, что нужно взять этот процесс в свои руки: не надеяться на ритейлеров, а прогонять перечень товаров через алгоритм, который будет говорить, что на самом деле есть, а чего нет. И именно эту информацию транслируем в приложении и на сайте.

Баланс между целостностью и доступностью
В погоне за сокращением отмен и замен нельзя забывать о сохранении объёма товарного ассортимента. Введём ещё две метрики:
Доля заблокированных алгоритмом SKU (по-другому block-rate) среди всего ассортимента.
Обратная ей метрика — доступность ассортимента — показывает какая доля всех SKU доступна для заказа в приложении.

Есть две крайности, причем в обоих случаях страдает прибыльность на заказ:
Мы можем заблокировать почти весь ассортимент СберМаркета. Целостность будет 100%. Но маленький ассортимент грозит низкой конверсией и падением выручки.
Мы ничего не блокируем и ассортимент максимальный. Но возникает много отмен/замен, падает retention и клиентский опыт также становится негативным.
Наша задача состоит как раз в том, чтобы найти золотую середину между целостностью и доступностью, при которой:
не страдает конверсия;
клиенты не испытывают избыточный негатив от отмен и замен;
вместе это положительно работает на экономику компании.
Подходы к управлению остатками
Итак, мы пришли к тому, что нам нужен алгоритм, с помощью которого мы принимаем решение, показывать товар в каталоге или нет. Рассмотрим краткую историю развития этого алгоритма в СберМаркете.
1. Минимальный порог
Первый способ — ограничение с помощью минимального порога. Мы взяли за правило: если сток больше 3, то товар виден в каталоге, если меньше — не виден.
Результат. Отмены и замены сократились на 5 процентных пунктов.
Недостатки. Block-rate составил 18,5%. При такой логике страдает сегмент нон-фуд. Например, 3 дорогие сковородки в супермаркете — это вполне нормальный остаток, на который можно рассчитывать.
2. Минимальный порог для каждого SKU
Далее мы начали подбирать минимальный порог для каждого SKU. Рассчитывали его как 20-й перцентиль стока за месяц. Если сток меньше минимального, то товар автоматически блокируется в каталоге.
Результат. Отмены и замены сократились ещё на 5 процентных пунктов.
Недостатки. Block-rate составил 20%. С таким подходом у нас появились ошибки в нашем главном сегменте — food.
Почему стали возникать ошибки в сегменте food?
До этого момента мы считали, что чем больше сток у товара, тем больше вероятность, что товар есть на полке. И, соответственно, чем товара меньше, тем больше вероятность, что на полке его нет.
Оказалось, это не всегда так. Ниже представлен график стока картофеля, красным отмечены точки, в которых возникли отмены и замены. Мы видим, что они происходили как при максимальном стоке, так и при минимальном. Строгой зависимости нет, отмены и замены возникают хаотически. Кажется, данным от ритейлеров стоило доверять ещё меньше, чем мы делали это в первых двух подходах.

В поисках альтернативного сигнала
Мы решили, что нужно больше внимания уделить другим сигналам — от сборщиков. Сборщики находятся в магазине в реальном времени и лучше понимают, что действительно есть на полках, а чего нет. Сигнал от сборщика очень сильный. Если в магазине не удалось что-то не собрать, значит с этим товаром действительно есть проблема.

3. Алгоритм автоматической блокировки
На основе этого открытия мы придумали следующую логику. Если возникает отмена или замена по товару, то мы его блокируем на несколько часов. Про эту логику мы написали отдельную статью на Хабре.
Мы решили совместить два подхода: сначала весь ассортимент проходит через алгоритм минимального стока, и дальше в случае отмен и замен включается алгоритм автоблокировки.
Результат. Алгоритм позволил улучшить not-found-rate ещё на 2 процентных пункта.
Недостатки. Вместе эти подходы дают 30% заблокированного ассортимента. Стало трудно контролировать работу этих двух алгоритмов и захотелось избавиться от двух принципов и заменить их на один новый.
4. ML-модель out-of-stock
Так мы приступили к разработки ML-модели. Она должна была подсчитывать вероятность того, что товар не получится собрать в ближайшее время, и если эта вероятность достаточно высокая, то мы не отображаем этот товар в каталоге. Для модели мы объединили информацию от ритейлеров и от сборщиков.
Результат. Мы отключили все предыдущие алгоритмы и оставили только ML-модель. Она помогла нам ещё на 3 процентных пункта снизить процент отмен и замен.

Но самое главное — block-rate впервые снизился и достиг 18%. В сравнении со всеми предыдущими, этот алгоритм блокирует меньше товаров, чем самый первый подход с константой 3, но при этом он даёт гигантский прирост по целостности.
Вызовы при решении ML-задачи
ML-модель стала лучшим решением по предсказанию остатков, но добиться такого результата мы смогли не сразу. Хотим поделиться сложностями, с которыми мы столкнулись по ходу работы.
Мы описали задачу как бинарную классификацию: сможет ли сборщик собрать товар, если его закажут в ближайший час. Обучающей выборкой (train) стали данные о заказанных корзинах. На них модель училась предсказывать, смог ли сборщик собрать позицию. В качестве inference выборки выступили все SKU СберМаркета. Мы использовали модель градиентного бустинга.
Вызов #1 Неравномерное обучение для разных категорий товаров
Train и inference выборки сильно отличаются по своей природе: первая содержит в себе информацию только по тем товарам, которые заказывали, а вторая — все SKU. Неоднородность выборок хорошо видно на графике ниже. На нём изображены распределения прогнозов модели на train и inference. Видим, что распределение на inference смещено вправо, то есть в проде модель ведёт себя агрессивнее.

Почему это произошло? Модель не очень точно ведёт себя на тех товарах, по которым у неё мало данных для обучения:
Non-food товары. Обычно в корзинах покупателей большинство товаров — это продукты питания (food). При этом на витрине СберМаркета ассортимент в сегментах food и non-food примерно равен. Это одно из ключевых различий между выборками train и inference. Для non-food небольшие стоки являются более нормальным значением, чем для food, но ML-модель начала блокировать non-food товары по тем же критериям, что и food.
Редко покупаемые товары. Модель привыкла получать сильный сигнал от сборщиков, и когда его нет (из-за того, что товар покупают не так часто), она начинает блокировать доступные, но редкие товары.
Поэтому мы поделили все SKU СберМаркет на 4 категории: food или non-food и часто или редко покупаемые. Мы разделили модель на 4 непересекающихся сегмента, каждый со своими уникальными фичами.

Результат: Мы снизили процент блокировки на 8 процентных пунктов. До этого модель пыталась подобрать стратегию под большинство товаров, то есть под самую популярную категорию — food. А теперь мы запустили 4 разных модели и блокировка стала более точной.
Вызов #2 Feedback loop
Ещё одна особенность в том, что модель влияет на свою обучающую выборку. Если мы выключим какой-то товар на витрине, то пользователь не сможет его заказать и мы не узнаем, был ли он на полке в магазине. То есть в выборку train попадают данные на основе работы самой модели. Таким образом, мы решаем не исходную задачу, а задачу, которая постоянно меняется и на которую влияем мы сами. Это ухудшает качество модели и мы не можем корректно подсчитать ML-метрики.
Чтобы нивелировать этот эффект, мы начали проводить регулярный аудит out-of-stock модели. Мы не можем узнать реальное состояние на полке всех товаров на витрине СберМаркета (SKU слишком много), но можем сгенерировать подвыборку, которая будет обладать основными свойствами витрины.
В рамках аудита сборщики специально проверяют статус попавших в неё товаров, и мы можем сверить факт с предсказаниями алгоритма. Так мы считаем ML-метрики и контролируем, верно ли развивается модель.
Вызов #3 Как варьировать порог
Порог — это та вероятность отсутствия товара, по достижению которой мы исключаем его из каталога. Варьируя порог, мы можем влиять на бизнес метрики.
Немного поигравшись с показанными ранее метрикам, получим следующие формулы, справедливые для inference-выборки:
Если мы будем увеличивать recall, то уменьшим процент отмен/замен. То есть наша модель не будет включать товары, которые нужно было бы заблокировать.
Если будем увеличивать precision, то уменьшим процент ошибочно заблокированных товаров. То есть модель будет менее агрессивной и не будет блокировать доступные товары.
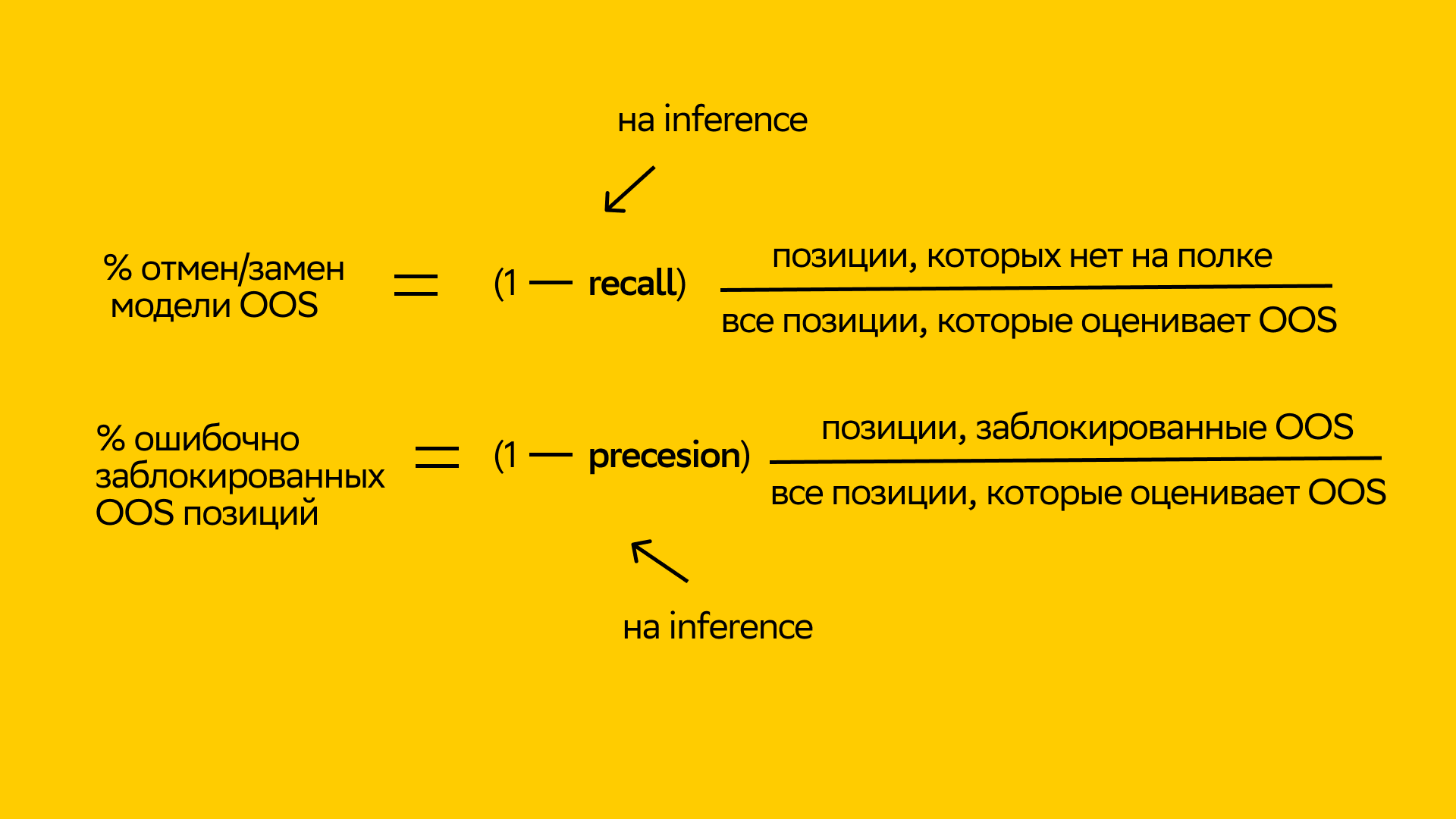
Получив такие формулы, мы смогли перейти от кривой precision-recall к кривой целостности-доступности, которая более понятная для бизнеса и стороннего наблюдателя. По ней удобно ориентироваться, где мы сейчас находимся и что мы получим, изменив тот или иной порог.

Однако, по этим графикам всё ещё трудно судить, какой порог самый лучший. Здесь нам на помощь приходит коэффициент бэта в f-мере. Он отвечает за то, в сколько раз recall для нас важнее, чем precision. Значит, мы можем оптимизировать f-меру, заранее передав в неё пропорцию между этими метриками. Исходя из бизнес соображений, мы можем выбрать целевое соотношение целостности и доступности и после этого подобрать оптимальный порог, чтобы получить лучшее соотношение из доступных.
Например, мы можем решить, что целостность для нас в два раза важнее, чем доступность, и оптимизировать f-меру при beta=2. Тогда наша precision-recall кривая превратится в красивый график с ярко выраженным максимумом

Google wide and deep своими руками
Всегда хочется улучшать качество модели и недавно мы наткнулись на нейронную сеть Wide&Deep от Google. Она состоит из глубокой и широкой части:
глубокая часть отвечает за генерализацию и ищет абстрактные закономерности в данных,
широкая нужна для запоминания фактов в обучающей выборке.
Нам очень понравилась идея, но чтобы перейти на нейронную сеть, нам пришлось бы отказаться от большинства имеющихся наработок. К тому же нам бы пришлось использовать такой драгоценный ресурс как GPU.
Поэтому мы решили взять модель от Google в качестве вдохновения и сделать собственную вариацию на тему. Существующую модель на градиентном бустинге мы решили использовать в качестве глубокой модели и дополнить её «широкой» моделью линейной регрессии из библиотеки vowpal wabbit.
Результат. Увидели прирост в качестве, но будем дорабатывать модель перед релизом.
Итоги
Хочется подчеркнуть главные идеи, которые мы извлекли по ходу развития нашей модели.
Хоть машинное обучение является лучшим решением, но с ним можно и подождать, начав с более простых в реализации подходов. Они тоже могут давать результат, достаточный для решения бизнес задачи.
Во многих бизнес-метриках присутствует trade-off и важно найти правильный баланс между ними, чтобы улучшать имеющиеся системы и строить новые.
Разделение моделей по сегментам SKU очень сильно улучшает доступность ассортимента. Это казалось не самым очевидным решением, которое дало значительный прирост эффективности.
И на последок, не забывайте, что модель может влиять сама на себя и если не решать этот вопрос, то модель станет неконтролируемой и принесёт вам много боли.
Надеюсь, вы нашли эту статью интересной и смогли извлечь полезные для себя идеи из нашего опыта. Если возникнут вопросы, стучитесь к нам в личку.

Tech-команда СберМаркета завела соцсети с новостями и анонсами. Если хочешь узнать, что под капотом высоконагруженного e-commerce, следи за нами в Telegram и YouTube.
materiatura
Любопытная практика. В старорежимные времена, основным параметром бизнеса была прибыль. Если вводились новые параметры, то первое, что делалось, - оценивалось их влияние на прибыльность. Новый дивный мир с легкостью придумывает параметры, объявляет их важными, называет метриками и строит графики.
Еще мило, что к ошибкам ретейлеров по наличию товара, прибавляется ошибка доставщика по оценке этой ошибки. Правда в обмен, на мою удовлетворенность нарисованным миром, мне же не показали травмирующую меня пустоту полок.
Интересное направление развития прогнозирования "вверх". В смысле, что считалось, что конечной точкой генерации прибыли была полка магазина. Магазин прогнозировал для производителя ожидаемые продажи, производитель транслировал "вниз" ожидаемые закупки сырья и комплектующих, производители сырья транслировали "вниз" ожидаемые закупки оборудования и так далее... Каков следующий шаг "вверх"? Прогнозирование качества доставки разными доставщиками?
Лично мне, это все нравиться. ))