 ]
]
Одна из самых приятных вещей в жизни разработчика архитектуры ПО и технологического эксперта Intel — возможность наблюдать за фантастическими достижениями Центров передового опыта (CoE) OneAPI по всему миру. Недавно лаборатория UC Davis Visualization & Interface Design Innovation (VIDI) Lab поделилась опытом применения глубокого обучения в создании интерактивной визуализации для науки. Подробности — к старту флагмансокго курса по Data Science.
Роль глубокого обучения в крупномасштабной визуализации научных данных
Образцы работ группы UC Davis VIDI
Введение
Почему это важно?
В последние годы детализация научных моделей растёт экспоненциально. При моделировании могут легко генерироваться сотни терабайтов данных. Для имитационных моделей, которые создают трёхмерное представление данных, результат моделирования становится понятнее после просмотра и анализа с помощью модуля рендеринга в реальном времени.
Нетрудно догадаться, что визуализация терабайтов данных с помощью столь реалистичных методов, как трассировка лучей (представьте себе более совершенный вариант реализации этого метода) и трассировка пути, с использованием даже самых мощных графических процессоров представляет собой сложную задачу. Прямое применение единственного алгоритма визуализации и стандартные алгоритмы сжатия не дают достаточной производительности и скорости сжатия для поддержки взаимодействия в реальном времени и в таком масштабе. Хотя просмотр результатов моделирования чрезвычайно полезен даже при скорости 1 кадр в секунду, предоставление реалистичной интерактивной визуализации, допустим, при скорости 30 кадров в секунду, уже гораздо интереснее с точки зрения исследования.
Именно над этим работают профессор Кван-Лю Ма и его сотрудники, Дэвид Бауэр и Ци У. Они объединили результаты последних исследований глубокого обучения и рендеринга, чтобы создать нечто особенное.
Немедленное визуальное представление нейросетью для сжатия
Одна из основных трудностей состоит в необходимости сжимать и распаковывать большие наборы быстро — настолько быстро, чтобы сделать возможным интерактивный рендеринг в реальном времени. Если скорость рендеринга — 30 кадров в секунду, то время декомпрессии не должно превышать 33,3 миллисекунды.
Типы и скорости сжатия
Ещё одна часть головоломки — степень сжатия. Алгоритмы сжатия без потерь восстанавливают оригинал полностью. Алгоритмы сжатия с потерями этого не делают. Нетрудно догадаться, что алгоритмы сжатия без потерь, как правило, дают сжатие меньше.
В повседневной жизни люди обычно пользуются zip, mp3 и JPEG. Первый сжимает данные без потерь со степенью сжатия около 3:1. Два других сжимают с потерями и позволяют достичь степеней сжатия 20:1 и 10:1. Таким образом, наибольшая степень сжатия привычных нам алгоритмов даёт размер данных в 1/20 от исходного.
Для рендеринга в реальном времени прежде всего важны быстрая декомпрессия и как можно меньшие потери при сжатии. Во многих случаях степени сжатия 20:1 для этих целей недостаточно.
На помощь приходит немедленное нейронное представление
Как показали последние 10 лет, современные нейросети отлично справляются с кодированием и быстрым декодированием. Эти свойства делают их подходящими для сжатия крупномасштабных данных.
Ещё одна полезная особенность нейросетей как метода сжатия — это то, что, в отличие от большинства алгоритмов, представление не увеличивается по мере роста размера набора данных. Можно было бы ожидать, что с ростом сложности данных статическое представление имеет всё большие потери.
Однако у достаточно большой сети рост потерь нелинеен. При огромных размерах имитационных моделей можно использовать большую нейронную сеть, что приводит к высокой степени сжатия и минимальным потерям информации при увеличении объёма данных. Команда VIDI сообщает о результатах, которые «в 10–1000 раз меньше необработанных данных и обучаются почти немедленно с использованием MLP и hash-grid-кодирования»¹.
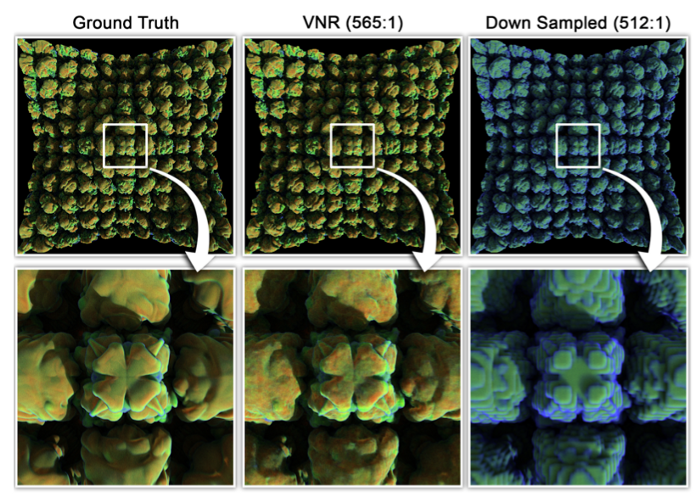
Рисунок 1 — Качество немедленного нейронного представления (VNR, Instant Neural Representation) в сравнении с наивным методом при одинаковой степени сжатия. Image courtesy of UC Davis VIDI group
На рисунке 1 хорошо видна ценность этого алгоритма сжатия по сравнению с традиционными алгоритмами.
Создание представлений
Для обучения модели сжатия группе VIDI потребовалось получить данные 3D-модели и привести их к виду, который лучше подходит для стандартного машинного обучения. С логической точки зрения, процесс обучения был довольно стандартным:
- Взять случайные выборки данных в трёхмерном пространстве.
- Кодировать каждую выборку при помощи hash-grid-кодирования для создания тензора передачи модели глубокого обучения.
- Обучить модель по реальным точкам выборки, получаемой на выходе.
Чтобы сделать этот процесс предельно производительным, группа VIDI создавала базовые обучающие выборки с помощью библиотеки Intel® Open Volume Kernel, реализацией спецификации oneAPI OpenVKL, который оказался действенным методом для внушительных объёмов данных.
При правильной конфигурации обучение модели примерно в 20 000 операций занимает менее минуты. Это позволяет получить приемлемое пиковое отношение сигнала к шуму — около 30 дБ в большинстве случаев и до 49 дБ в отдельных наборах данных. Для тех, кто не знаком с пиковым отношением сигнала к шуму, это соотношение измеряется в децибелах (дБ). Чем оно выше, тем ближе изображение к оригиналу.
Компенсация недостатков
Возможности немедленного нейронного представления впечатляют. Тем не менее само по себе оно может оказаться недостаточным для эффективной интерактивной визуализации в реальном времени. Чтобы компенсировать недостатки метода, UC Davis VIDI разработала несколько алгоритмов выборки и визуализации данных немедленного нейронного представления.
К сожалению, описание этих методов выходит за рамки тематики этой статьи. Вы можете ознакомиться с их подробностями в статье Instant Neural Representation and the associated rendering optimizations.
Конечно же, интереснее всего посмотреть, как эти методы работают вместе. Как быстро можно обучить немедленное нейронное представление и насколько интересных результатов достигла группа UC Davis VIDI, вы можете увидеть в этом видео:
Заключение
Я всегда считал цифровое обучение технологией для решения особо сложных задач с огромным пространством возможных решений. При этом я не задумывался о его возможностях в решении задач с «хорошо известным» решением. немедленное нейронное представление — отличный пример применения моделей цифрового обучения для эвристической оптимизации данных, которые могут преобразовываться с некоторыми потерями.
немедленное нейронное представление и подобные методы позволяют использовать в реальном времени всё более сложные данные моделирования. Чтобы почувствовать разницу между скоростью 1 кадр в секунду и 60 кадров в секунду, посмотрите это забавляющее видео:
Я с восторгом и оптимизмом смотрю на подобные новаторские решения, которые будут и дальше двигать науку к новым открытиям. Возможность взаимодействия с данными имитационной модели со скоростью 30 и более кадров в секунду может стать переломным моментом для учёных, которым больше не придётся работать со своими данными в режиме слайд-шоу.
[1] Qi Wu, David Bauer, Michael J. Doyle, Kwan-Liu Ma, Instant Neural Representation for Interactive Volume Rendering, 2022, https://arxiv.org/abs/2207.11620v2
Научим вас аккуратно работать с данными, чтобы вы прокачали карьеру и стали востребованным IT-специалистом.

Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
А также
Zara6502
Я ничуть не приуменьшаю заслуги ZIP, но сам лично еще с 1992 года пользуюсь ARJ, LHA, HA, RAR, 7Z - zip-ом пакую только для людей которые совсем не понимают о чем идет речь и которые железно смогут распаковать zip средствами ОС.
И если раньше использование других архиваторов было определено уменьшением размера архива для дискет, например RAR с опциями -s -m5, то сегодня я чаще пользуюсь сжатием NTFS для своих разделов, а там где это неприменимо (например NAS), то архивирую 7Z. Можно конечно делать ZIP Deflate64, но уже исторически не вижу смысла ради этого переключаться в настройках. Для некоторых задач пользуюсь консольным zpaq64.