
В этом посте мы расскажем про метрику Churn Rate, нам предстоит разобраться с такими вопросами, как:
Что такое Churn Rate?
Зачем нужна эта метрика?
Как ее считать, используя SQL?
Как ее считать, используя Python?
Наша задача – максимально быстро и понятно дать ответы на вопросы, зачем нужна метрика и как ее правильно рассчитывать с помощью различных технических инструментов. В статье представлен код для генерации данных, чтобы каждый мог попробовать рассчитать метрику самостоятельно.
Что такое Churn Rate
Метрика Churn Rate позволяет дать ответ на вопрос, какая доля пользователей перестала пользоваться сервисом, иначе говоря, – отвалилась. Отвалившимся пользователем считается тот, который со дня своей предыдущей активности не заходил в сервис в течение некоторого фиксированного периода времени (10 дней, 2 недели, 1 месяц и т.п.). Почему используется временное окно? Ответ прост – мы не можем ждать всю жизнь, чтобы точно сказать, вернется тот или иной пользователь или нет. По этой причине мы используем метрику отсутствия в рамках какого-то периода, причем:
Чем больше временное окно – тем метрика точнее.
Чем меньше временное окно – тем раньше мы будем знать результат.
Пример: 1 декабря в наше приложение зашло 100 пользователей, нам интересно, какая доля из них не зайдет в сервис повторно в течение 28 дней. Допустим, таких пользователей было 17 человек → Churn Rate = 17%. (метрику мы сможем посчитать спустя 28 дней с интересующей нас даты).
Формула расчета
Churn Rate = [кол-во отвалившихся пользователей] / [ кол-во пользователей, которые были активны в выбранный день]

Возвращаясь к предыдущему примеру, у нас есть:
День Х: 1 декабря
Временное окно: 28 дней
Дата X + временное окно: текущая дата + 28 дней (до 29 декабря)
Пользователи, которые были активны в выбранный день: 100 человек, зашедшие в приложение 1 декабря
Отвалившиеся пользователи: 17 человек, которые зашли в приложение 1 декабря, но не заходили снова в течение 28 дней, т.е. до 29 декабря
Важно понимать, что Churn Rate в большинстве случаев не будет равен 1 - Retention Rate (доля пользователей, которая была активна в дату X и вернулась в сервис спустя какой-то промежуток времени).
Почему Churn Rate ≠ 1 - Retention Rate ? Потому что в рамках периода пользователи отваливаются не одним махом. Вот график Retention Rate для разных периодов на дату X:
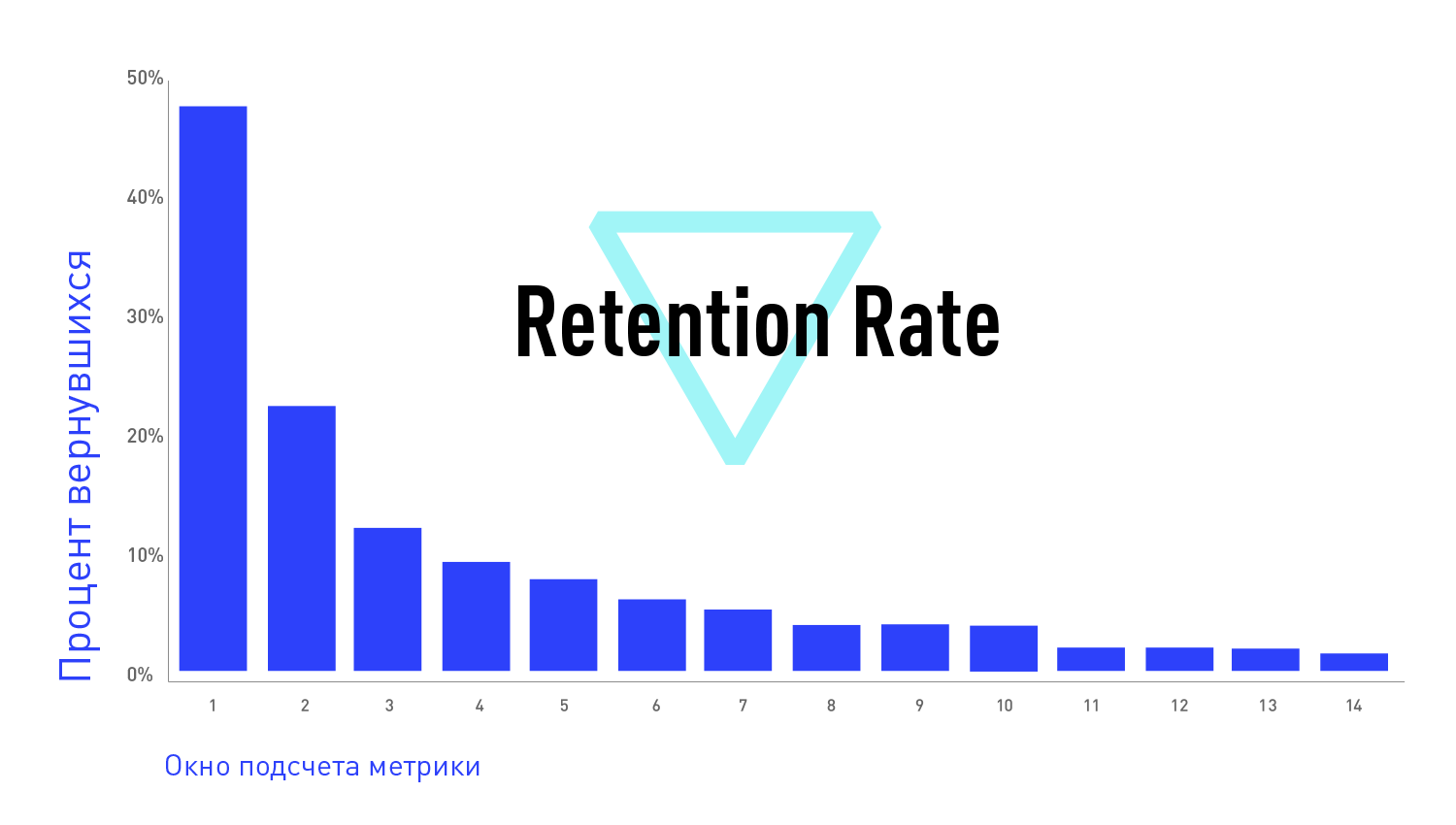
Мы видим, что часть пользователей была активна в период временного окна Churn’а → если пользователь был неактивен на 28 день, это не значит, что на протяжении всего предыдущего периода он также отсутствовал, поэтому Churn Rate ≠ 1 - Retention Rate (но если бы Retention Rate был бы кумулятивный, то равенство выполнялось).
Подсчет метрики на практике
Технические инструменты:
SQL – Google BigQuery
Python – Jupyter Notebook
BI – Data Studio
Для расчета метрик будем использовать синтетические данные. Генерируем их следующим образом:
1. Импортируем библиотеки
import names
import random
import datetime as dt
import pandas as pd2. Генерируем массив значений для будущего датафрейма (может занимать несколько минут)
# здесь будут храниться все имена пользователей, которые мы будем использовать
# таких имен у нас будет не больше 10000 (они не обязательно окажутся уникальными)
names_list = []
for i in range(10000):
names_list.append(names.get_full_name())
# значения, которые будут подставляться случайным образом
platforms = ['ios', 'android']
columns = ['event_date', 'platform', 'name', 'event_type']
events = ['purchase', 'productPreview', 'addToCart', 'productClick', 'search', 'feedbackSent']
# формируем соотвествие имени и платформы пользователя
# (для простоты предполагаем,
# что каждый пользователь использует только одну из двух возможных платформ)
names_platform_dict = {}
for name in names_list:
names_platform_dict[name] = random.choice(platforms)
# формируем массивы юзеров по степени уникальности
regular_users = names_list[:2000]
not_regular_users = names_list[2000:]
# здесь будут храниться строки для будущего датафрейма
df_values = []
# основной цикл
# проходимся по всем датам с 1 декабря 2021 по 29 мая 2023
for date_index in range(180):
date = dt.date(2022, 12, 1) + dt.timedelta(days=date_index)
# сколько строк будут соответствовать одному дню
rows_number = random.randrange(2000, 3000)
for name_index in range(rows_number):
# здесь мы задаем недельную сезонность
# в будни доля регулярных юзеров будет выше
if (date_index + 2) % 7 == 0 or (date_index + 3) % 7 == 0:
list_of_names = random.choices([regular_users, not_regular_users], weights = [4, 1])[0]
else:
list_of_names = random.choices([regular_users, not_regular_users], weights = [7, 1])[0]
name = random.choice(list_of_names)
event_type = random.choice(events)
platform = names_platform_dict[name]
# добавляем строку в массив всех строк для будущего датафрейма
df_values.append([date, platform, name, event_type])3. Полученный датафрейм
# создаем датафрейм
events = pd.DataFrame(data=df_values, columns=columns)
events.event_date = pd.to_datetime(events.event_date)
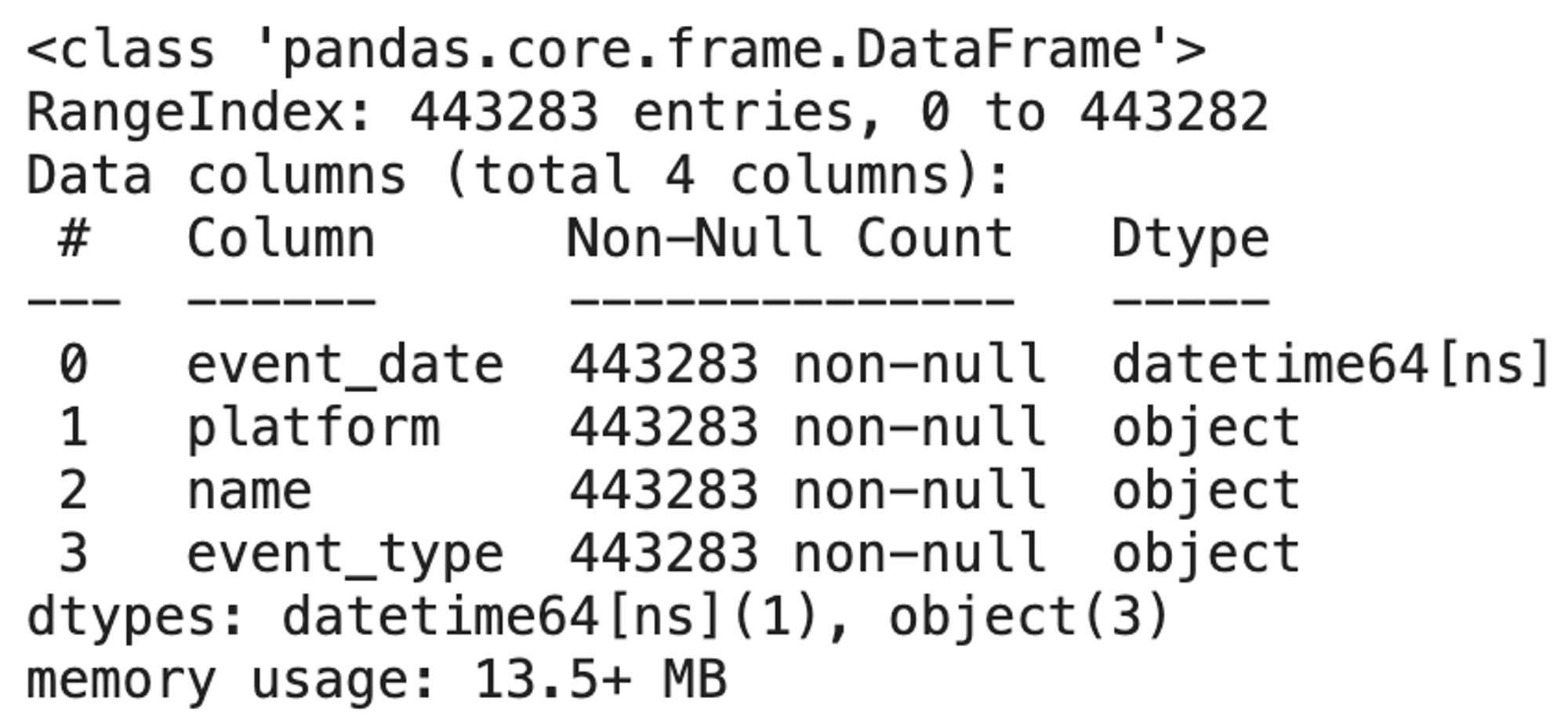
eventsВ нашем случае исходный датафрейм выглядит следующим образом:

Также можно ознакомиться с основной информацией
4. Выгрузка данных
# В исходной директории, где лежит файл с кодом, можно будет найти csv-файл
events.to_csv('./example_events.csv')Контекст
Мы работаем в компании, которая занимается продажей товаров через приложение на смартфоне. Приложение существует на двух платформах: Android и iOS. В компании принято считать метрику оттока с окном в 28 дней.
Как считать Churn Rate с помощью SQL
Мы загрузили данные в Google BigQuery (среда может быть любой).
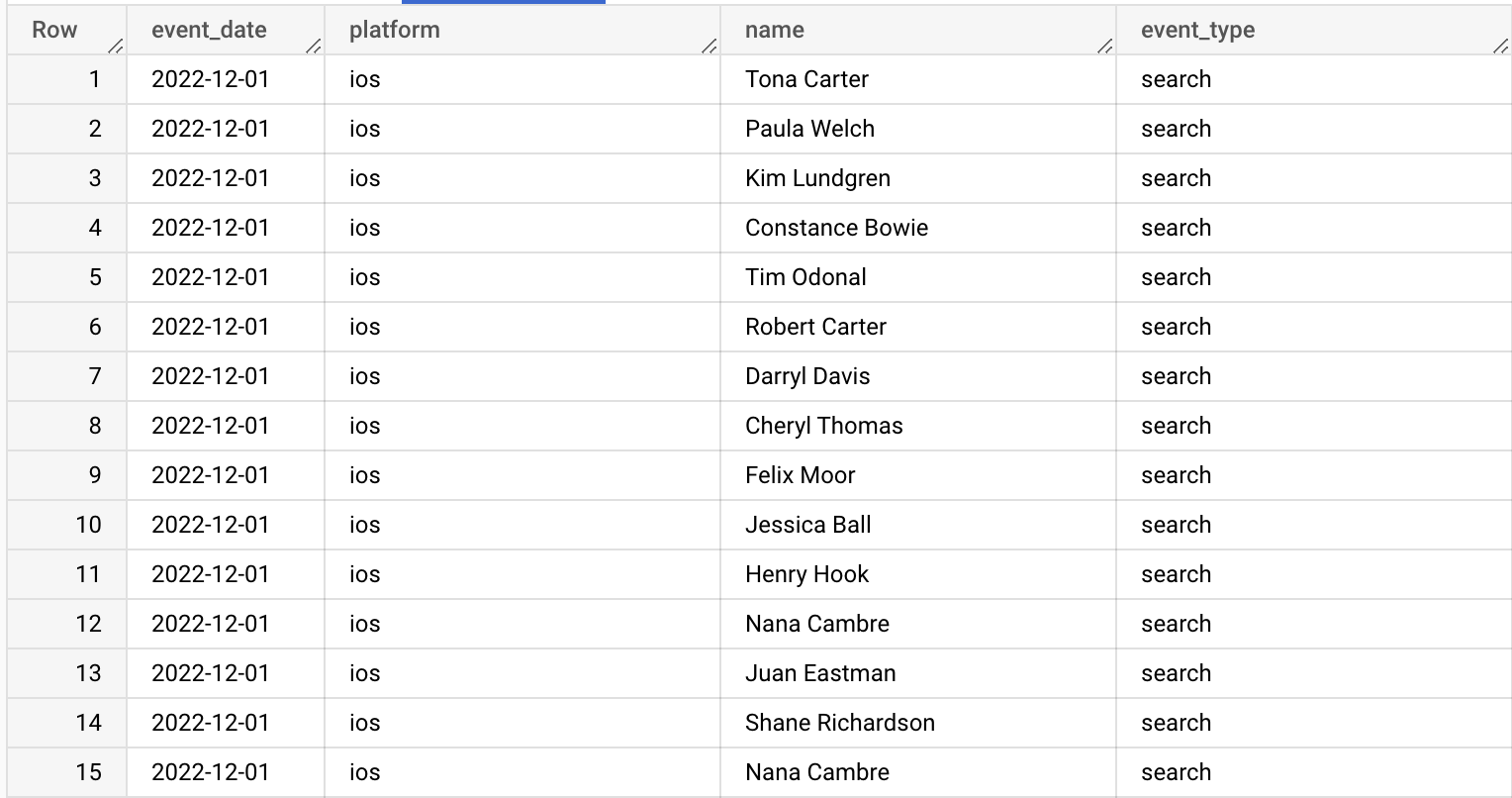
Перейдем к расчету метрики.
Так как метрику принято подсчитывать с окном в 28 дней (в описанном кейсе), то неправильно считать метрику для тех дат, с момента наступления которых не наступил 28-й день. По этой причине эти строки мы срежем на последнем этапе запроса.
Так как у пользователя может быть в один и тот же день несколько событий, стоит предварительно оставить только уникальные соответствия платформы, пользователя и даты.
Для каждого пользователя в рассматриваемую дату найдем дату его следующего события, потом посчитаем количество дней до этой даты. Полученное кол-во дней будем сравнивать с временным окном метрики. Если пользователь отсутствовал ≥ 28 дней с рассматриваемой даты, он попадает в отток.
Получился следующий код:
-- находим уникальные соответствия имени, платформы и даты активности
-- нас волнует, был ли пользователь активен в тот или иной день
-- нет разницы, что именно он делал
WITH names_days AS (
SELECT DISTINCT
platform,
event_date,
name,
-- оконной функцией находим дату следующей активности пользователя
LEAD(
event_date
) OVER(PARTITION BY name ORDER BY event_date) AS next_event_date
FROM example_events
),
main AS (
SELECT
*,
-- находим, через сколько дней случилось следующее событие пользователя
DATE_DIFF(next_event_date, event_date, DAY) AS days_till_next_event
FROM names_days
)
SELECT
event_date,
-- находим долю пользователей:
-- которые отсутствовали не меньше 28 дней с этого дня от числа всех пользователей
-- и которые были активны в этот день
-- также сюда можно добавить срез по платформе
-- `distinct` ниже в данном случае не необходим,
-- но при ином формате исходных данных он может понадобиться
COUNT(DISTINCT
IF(
days_till_next_event < 28,
NULL,
name
)
) / COUNT(DISTINCT name) AS churn_rate
FROM main
WHERE 1 = 1
-- срезаем строки, где не прошло 28 дней с текущей даты
AND event_date <= (SELECT DATE_SUB(MAX(event_date), INTERVAL 28 DAY) FROM example_events)
GROUP BY 1
ORDER BY 1Если оконных функций в используемой версии SQL нет, то можно:
Обратиться к отсортированной по
name,event_dateисходной таблице через подзапрос и применить функциюLEAD/LAGбез окна (предусмотрев вSELECTусловие на соответствие имени. EX:IF(LAG(name) = name, LAG(event_date), NULL)
Пронумеровать строки в отсортированной по
name,event_dateисходной таблице и поджойнить ее саму не себя черезtable.index = table.index + 1 AND table.name = table.name
На выходе получаем таблицу, в которой на каждую дату подсчитан показатель Churn Rate с окном в 28 дней:
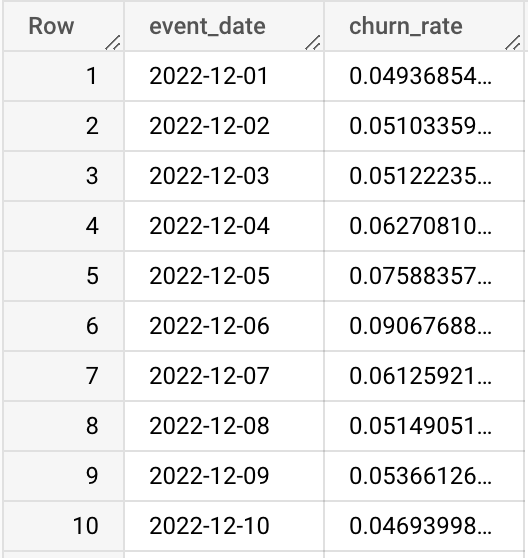
Результат полученного запроса не очень удобно анализировать, смотря на результат SQL-запроса. Поэтому визуализируем итог с помощью BI-инструмента:
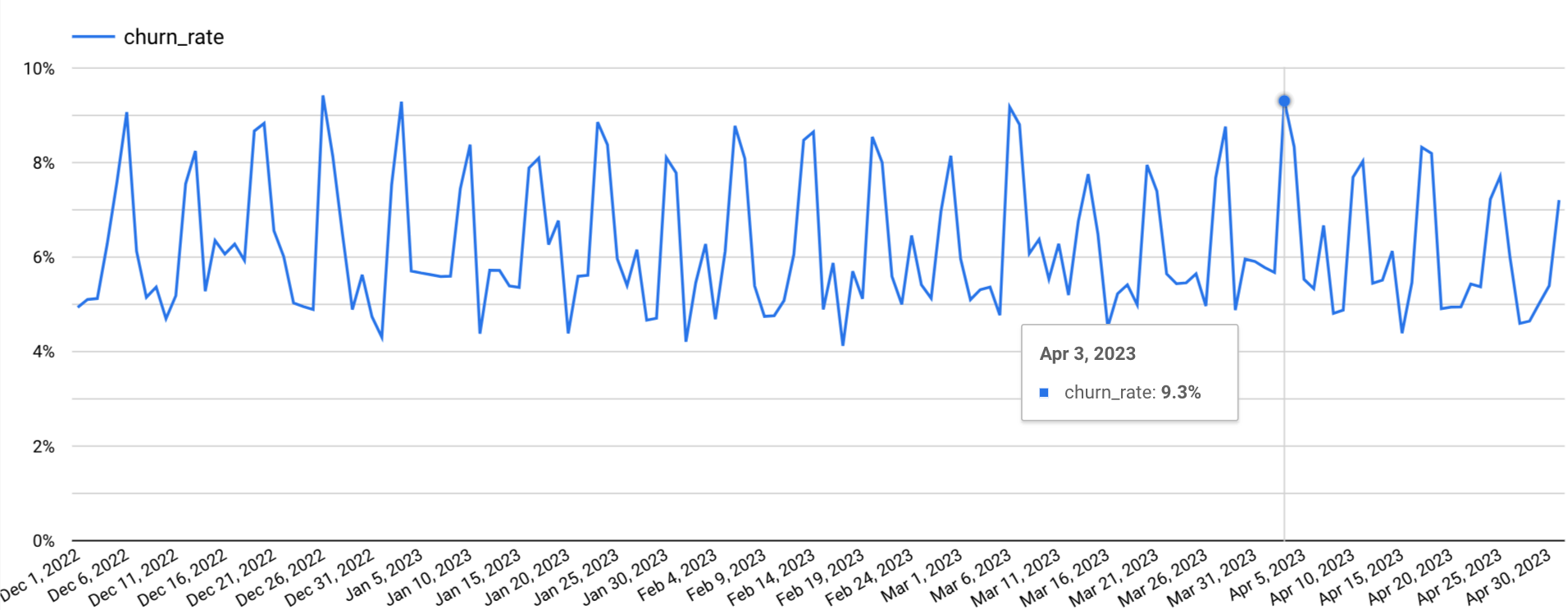
Нам также может быть интересно, как ведет себя метрика в зависимости от выбранной платформы. Для того, чтобы вывести такой график, в исходный SQL-запрос нужно добавить дополнительное поле группировки platform (также не забыть указать его в SELECT)
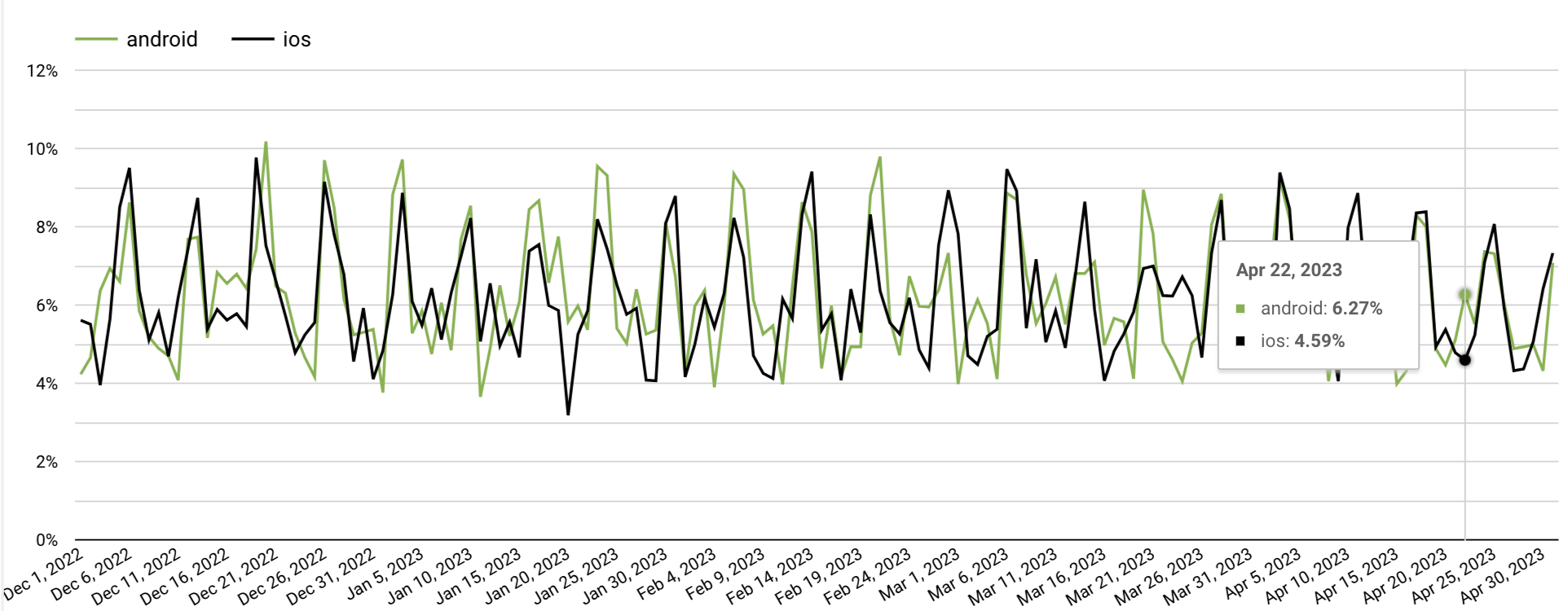
В обоих случаях наблюдается сезонность: в выходные дни отток пользователей выше.
Как считать метрику с помощью Python
Импортируем библиотеки.
import numpy as np
import datetime as dt
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.ticker as mtickЗагрузим данные из csv-файла.
events = pd.read_csv('./example_events.csv', parse_dates = ['event_date'])Выполним аналогичные преобразования средствами Python. Для начала оставим только уникальные сочетания name, platform, event_date:
events_grouped = events.groupby(['event_date', 'platform', 'name'])\
.agg({'event_type' : 'count'})\
.reset_index()
events_grouped.columns = ['event_date', 'platform', 'name', 'events_number']Теперь для каждого пользователя найдем дату его следующего события. Также найдем, через сколько дней состоялось его следующее событие:
events_grouped['next_event_date'] = events_grouped.groupby(['name', 'platform'])['event_date'].shift(-1)
events_grouped['days_till_next_event'] = (events_grouped['next_event_date'] - events_grouped['event_date']) / np.timedelta64(1, 'D')Для простоты добавим маркер, считаем ли мы пользователя «отчернившимся» в рассматриваемую дату
events_grouped['is_churned_int'] = events_grouped.days_till_next_event.apply(lambda x: 0 if x < 28 else 1)После всех преобразований данные имеют следующий вид:
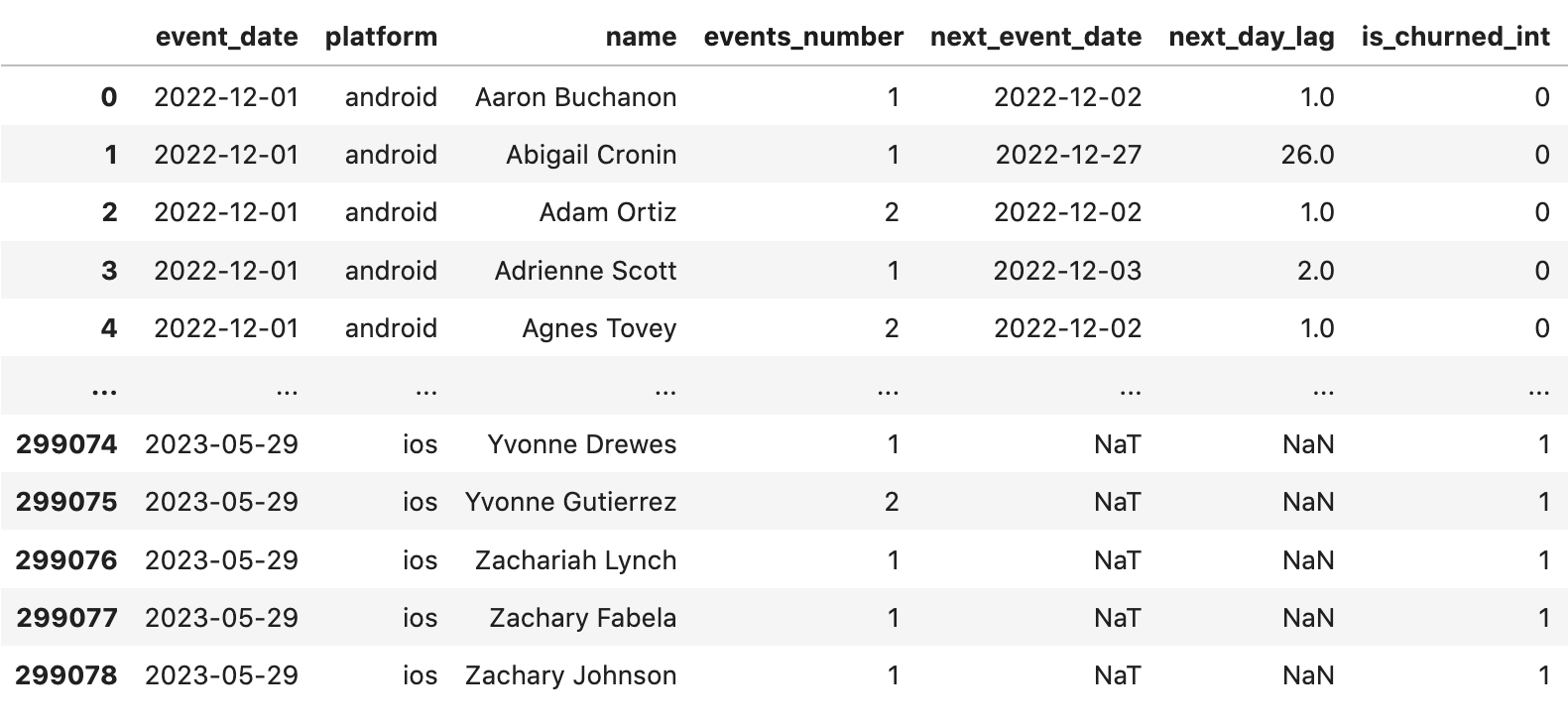
У нас есть все для того, чтобы посчитать метрику Churn Rate. Найдем максимальную дату, с момента которой прошел 28 дней , срежем ненужные строки. После посчитаем для каждой даты кол-во уникальных пользователей (DAU) и число тех, кто попал в отток. Затем рассчитаем долю тех, кто попал в отток, от общего числа.
# ищем максимальную дату, для которой подсчет метрики можно считать корректным
max_relevant_date = events_grouped.event_date.max() - dt.timedelta(days=28)
churn_rate = events_grouped.query('event_date <= @max_relevant_date')\
.groupby(['event_date'])\
.agg({'is_churned_int' : 'sum', 'name' : 'nunique'})
churn_rate.columns = ['churned', 'dau']
# расчитываем метрику
churn_rate['churn_rate'] = churn_rate['churned'] / churn_rate['dau']
# переводим ее в проценты
churn_rate['churn_rate_perc'] = churn_rate['churn_rate'] * 100Получаем следующую таблицу с метрикой Churn Rate:
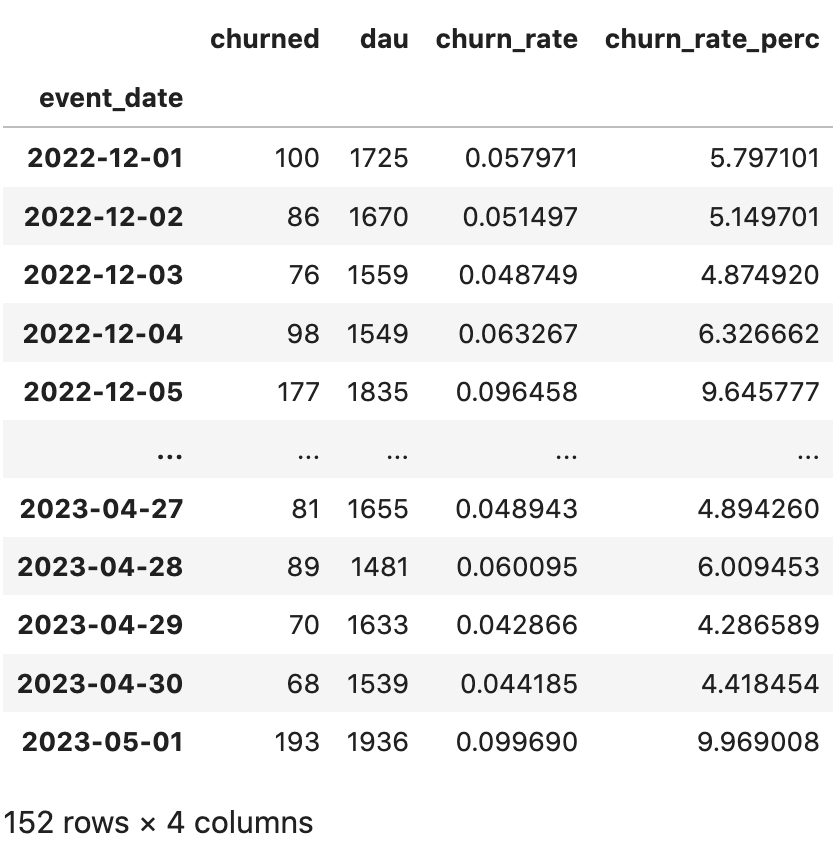
Визуализируем полученные результаты средствами Python:
palette = sns.color_palette(['#ff6063', '#32b6aa', '#ffcc53'])
sns.set_palette(palette)
plt.figure(figsize=(20,10))
plt.grid()
ax = sns.lineplot(data=churn_rate, y='churn_rate_perc', x='event_date')
ax.set_title ('Churn Rate', fontsize=15)
ax.set_xlabel('Дата', fontsize=15)
ax.set_ylabel('Процент оттока', fontsize=15)
ax.set(ylim=(0, 50))
ax.yaxis.set_major_formatter(mtick.PercentFormatter())
plt.show()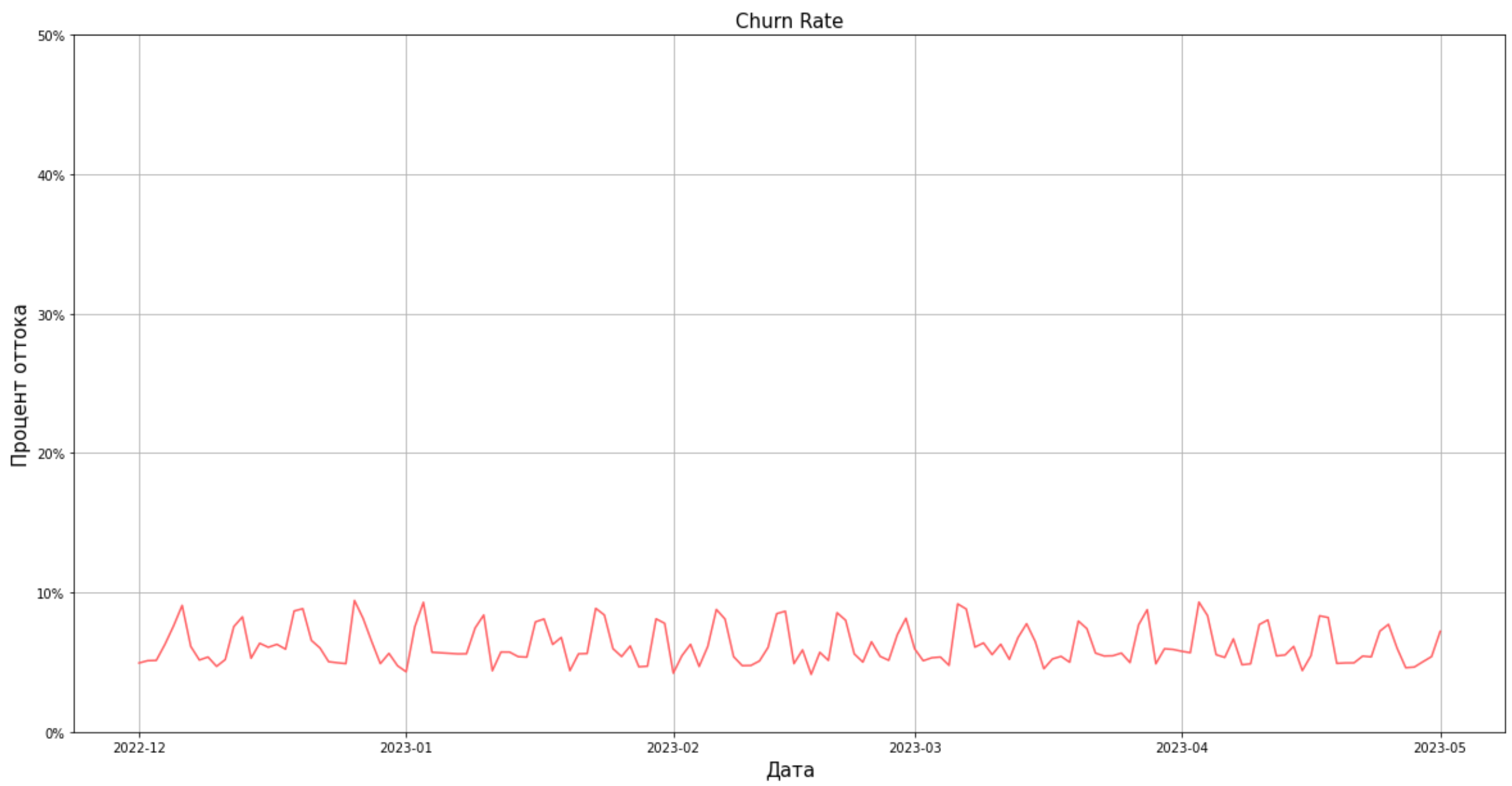
Если мы хотим посчитать метрику отдельно по платформе, то поле platform необходимо добавить к полям группировки, а также вынести в легенду при построении графиков
churn_rate_platform = events_grouped.query('event_date <= @max_relevant_date')\
.groupby(['event_date', 'platform'])\
.agg({'is_churned_int' : 'sum', 'name' : 'nunique'})
churn_rate_platform.columns = ['churned_names', 'dau']
churn_rate_platform['churn_rate'] = churn_rate_platform['churned_names'] / churn_rate_platform['dau']
churn_rate_platform['churn_rate_perc'] = churn_rate_platform['churn_rate'] * 100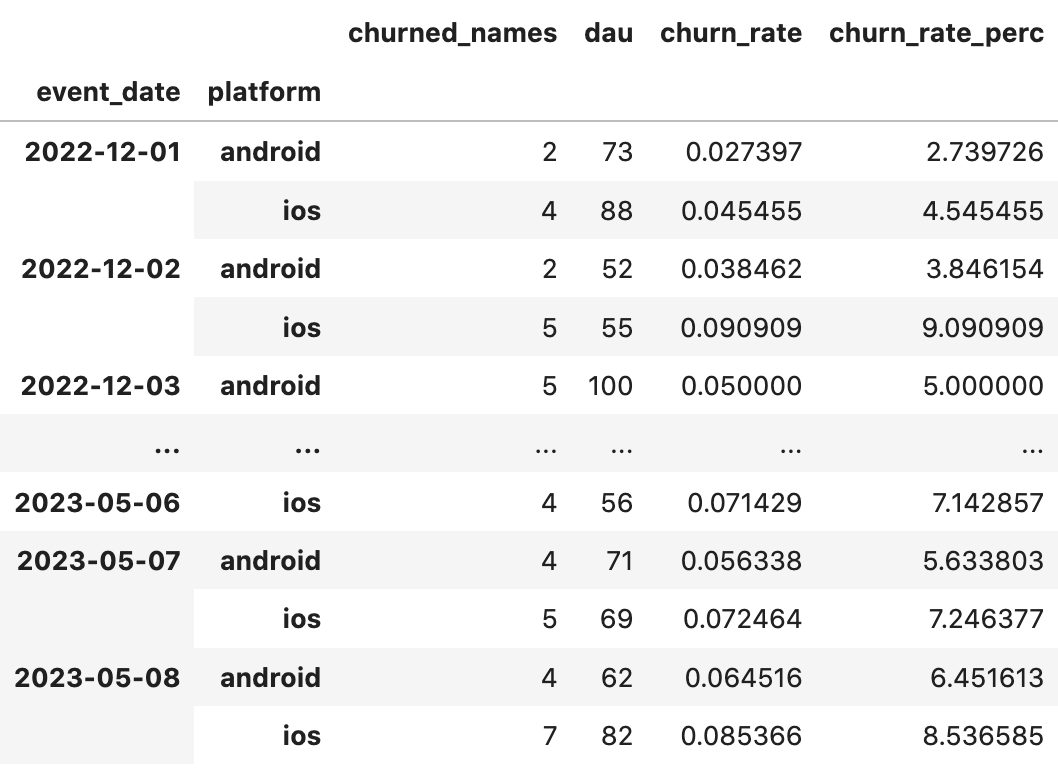
plt.figure(figsize=(20,10))
plt.grid()
ax = sns.lineplot(data=churn_rate_platform, y='churn_rate_perc', x='event_date', hue='platform')
ax.set(ylim=(0, 50))
ax.yaxis.set_major_formatter(mtick.PercentFormatter())
ax.set_title ('Churn Rate', fontsize=15)
ax.set_xlabel('Дата', fontsize=15)
ax.set_ylabel('Процент оттока', fontsize=15)
plt.show()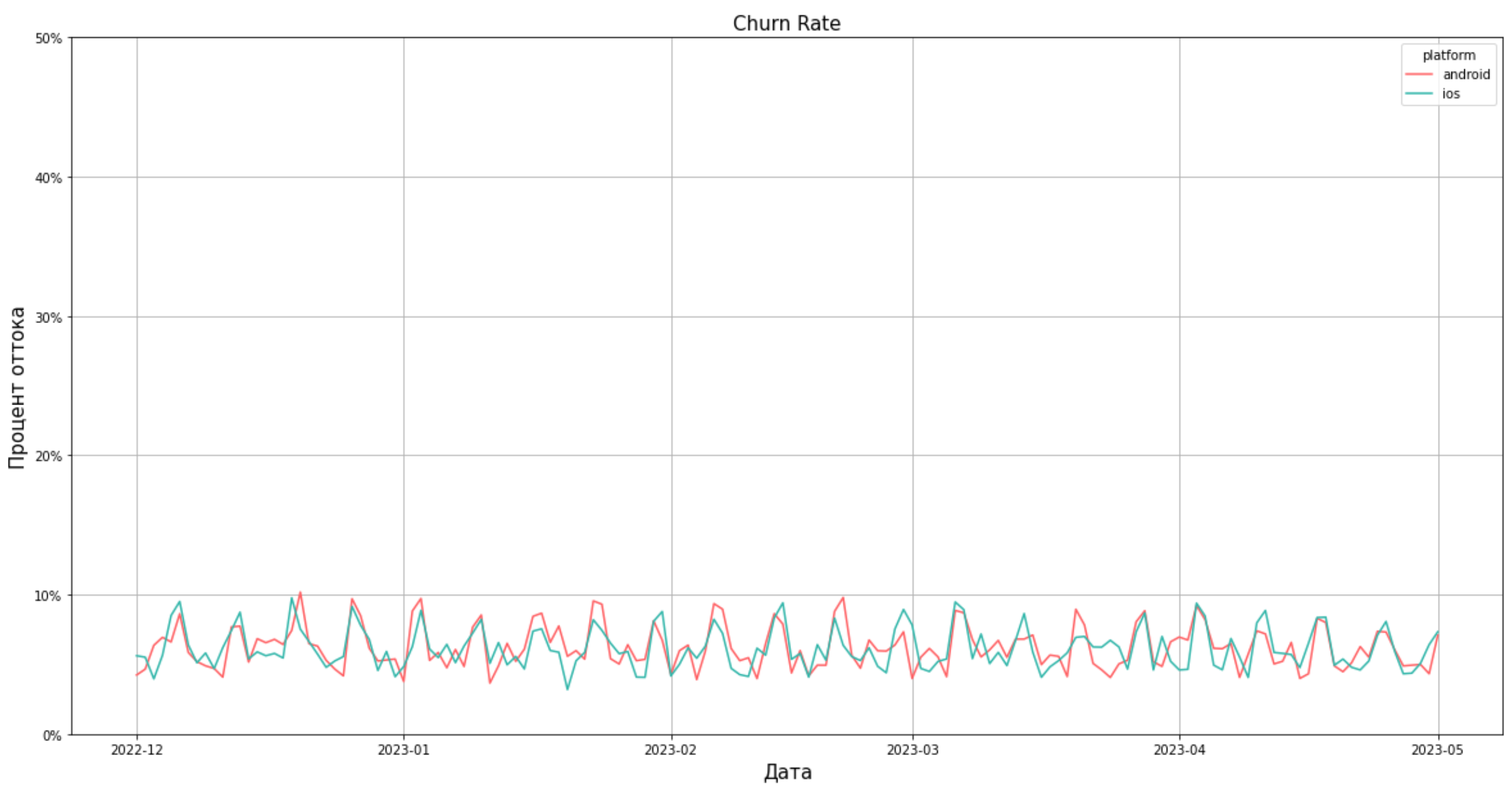
Post Scriptum
Разобранный метод подсчета – классический. В ряде случаев целесообразнее рассчитывать метрику иным способом, всё зависит от бизнес-контекста и решаемой задачи.
Например, часто нам не интересно смотреть на показатель, построенный по всем событиям. Если мы говорим о поисковиках, которые часто установлены в браузере «страницей по умолчанию», то учитывать при расчете Churn’а нечто из разряда «Пользователь открыл страницу», кажется, не очень полезно, ведь это вряд ли можно считать за активность пользователя.
Если мы говорим о web-платформе, известный факт, что среди новых пользователей, зашедших на ресурс, внушительная доля покидает его практически мгновенно. За долей таких пользователей лучше следить отдельно (Bounce Rate), а метрику оттока также строить без них.
Возможные вопросы
1. Есть даты, для которых мы еще не знаем, заходил ли пользователь в последующий период или нет (речь про окно подсчета метрики). Что будет, если не срезать такие строки?
В таком случае после первой даты, для которой в аналитике не найдется даты, превышающей ее на временное окно подсчета метрики, метрика поплывет вверх. Такой результат мы получим потому, что не будем знать о последующих активностях пользователя → при расчете будет считаться, что он попал в отток. График в таком случае будет выглядеть примерно так:
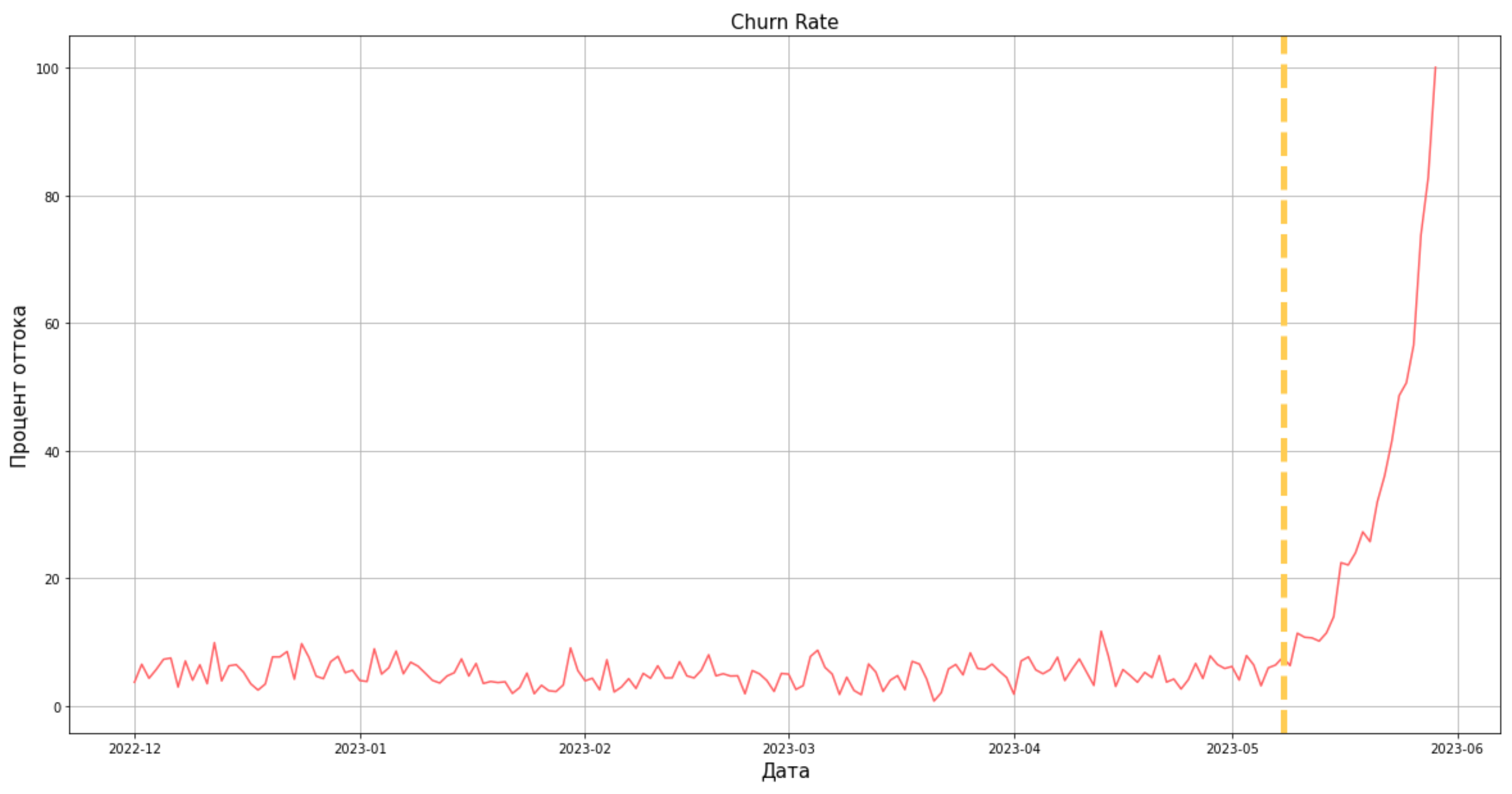
2. Но метрика не говорит нам о том, кого сервис потерял насовсем!
Да, так и есть, но что такое вообще «фактический отток»? Мы никогда не можем знать наверняка, зайдет ли пользователь. в наш сервис повторно (даже если он отсутствовал в нем несколько лет). Метрика нужна для того, чтобы отслеживать тенденцию в динамике, она не скажет нам о том, сколько пользователей мы потеряли навсегда.
3. Наблюдается аномальное изменение метрики, в чем искать причины?
Причин изменений метрик Churn Rate может быть бесконечно много, причем для каждой сферы они будут свои. Постараемся охватить основные:
Реклама
перераспределены бюджеты;
изменены рекламные кампании;
подключены новые каналы.
Изменения в продукте
изменены цены;
изменен вида продукта (приложения, сайта, виджета и тд);
изменены функций (в приложении появилась возможность осуществлять звонки или теперь нельзя оплачивать товары какими-то электронными кошельками).
Прочее
Конкуренты;
Субституты;
Новостной фон.
Важнее уметь отвечать на вопросы:
Какая аудитория учитывается в показателе?
Что могло послужить причиной негативного опыта?
Что может сейчас беспокоить аудиторию?
4. Как подобрать окно для подсчета метрики?
Размер используемого окна зависит от сферы бизнеса и наших ожиданий. Нужно понимать, что, используя большее окно для подсчета, мы будем дольше ждать, но получим более точные результаты.
Спасибо за внимание!
Спасибо, что дочитали до конца! Надеемся, материал окажется полезным.
Если у вас остались вопросы, будем рады ответить на них в комментариях. Также, если вы считаете, что было бы круто рассмотреть подобным образом другие темы, пишите о них. Постараемся затронуть их в одном из последующих постов.