Два года назад я выполнял задачу по сортировке строк в алфавитном порядке , учитывая каждый символ этой строки. В принципе это была задача скорее сортировки слов, чем строк в виде предложений, но большого отличия в этом нет. Конечно, в Java существуют встроенные инструменты для этих действий, но здесь надо было проверить мои способности в решении обычных логических задач (умения на основе своих решений составить определенный алгоритм).
Решать эту задачу обычным способом желания не было. Поэтому решил пойти привычным путём , когда делаешь так, как , возможно, делать не стоит, и никто так не делает, но сделать очень хочется. Так как в процессе изобретения велосипеда я не одинок, то решил лишний раз подтвердить свою принадлежность к данному комьюнити. Я решил попробовать реализовать внезапно возникшую идею представления строки в виде числа, то бишь сигнатуры. Причем надо было реализовать эту идею таким образом, чтобы число зависело от символов и их порядка, находящихся в строке. Т.е. сделать так, чтобы сортировка этих чисел была эквивалентна сортировке строк в алфавитном порядке по всем символам этих строк.
Решение
Что такое строка? В принципе это последовательность символов (обычно из таблицы ASCII кодов), - массив типа char[], где каждому элементу массива соответствует определенная буква самой строки.
Что такое тип char ? В Java это тип данных, занимающий 2 байта, где старший байт является просто кодировкой страницы UTF-8 (алфавита страны), а младший байт — кодировкой самого символа (буквы) из таблицы ASCII-кодов.
Что из этого возможно получить в виде выгоды? Ну, конечно же возможно! Вообще, старший байт , если мы сортируем список строк (слов) , описываемых одной страницей UTF-8 ASCII кодов, можно отбросить. Он является лишь маркером для выяснения страны происхождения данных строк. Значит одно из условий, для решения задачи данным способом — это необходимость того, что все строки происходят из одной страницы ASCII кодов.
Теперь осталось определить правилo для вычисления сигнатуры строки , чтобы ее значение зависело от последовательности символов в алфавитном порядке.
- Правило. Пусть мы имеем строку STR1, где каждый символ имеет определенный вес WEIGHT, что минимально возможное значение веса символа в любом месте строки , всегда больше значения суммы всех максимальных возможных последующих весов символов в этой строке.
Length — длина строки.
weight[i] — вес символа в строке, где i = 1 and i <= length (i — это номер символа в строке.)
Определяем такое правило :
weight [i] > sum (weight[i+1] … weight[length])
сигнатура строки STR1:
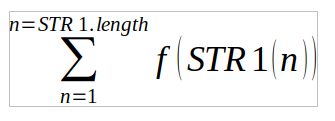
, где n — натуральное число, функция f(x) — вычисляет вес символа в строке являя собой вес weight(n), а результат sign<?> является суммой значений f(x).
Не уверен, что мои объяснения прояснили алгоритм решения этой задачи, но я хотя бы попробовал сделать это.
Я реализовал это решение на Java, создав довольно примитивное приложение. Код класса реализации представлен ниже. И этого, как ни странно, вполне достаточно для вычисления данной сигнатуры.
Код реализации данного функционала на Java представлен ниже.

Здесь метод getHashString вычисляет данную сигнатуру. В принципе ничего из ряда вон выходящего здесь нет. Но результат все-таки есть, и положительный.
Ниже представлен тестовый экран с результатом создания сигнатур очень неудобных строк для сравнения их по этим самым сигнатурам.

Строки в таблице представлены уже отсортированными по значениям сигнатур , видимых в столбце hash.
Попробуем добавить еще одну неудобную строку.
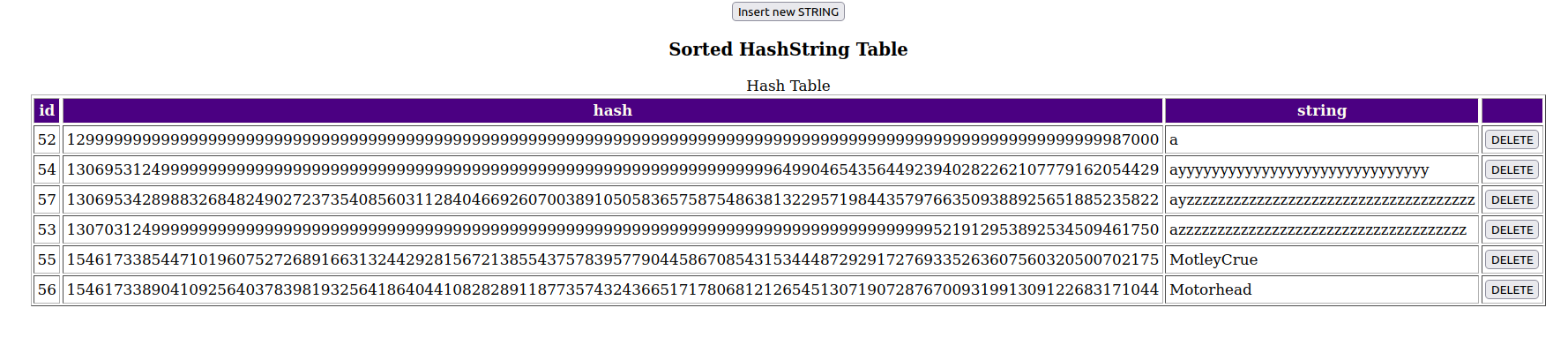
Как мы можем увидеть, добавилась строка с id = 57. Вообще она очень похожа со строкой с id=53. Ее длина больше, чем у 53-й строки, символы, находящиеся в ней категорически не отличаются от 53-й, кроме второго , который минимально меньше второго символа 53-й строки. y<z минимально. Но все равно сигнатура этой строки меньше, чем 53-й и сортировка, используя сигнатуры строк в алфавитном порядке, прошла успешно.
Вообще говоря, значение сигнатуры не является единственным и неповторимым. Оно зависит от основы, на которой вычисляется его значение. Меняя основу, можно получать ряды сигнатур, которые между собой соотносятся одинаково, и количество этих рядов в принципе может быть бесконечным.
Возникает вопрос : «А зачем все это нужно?» Дать на него категорический положительный ответ не могу. Возможны некоторые ситуации, при которых это целесообразно применять. К примеру, хранение в памяти словарей в виде бинарных деревьев, значительно убыстряющих поиск и добавление искомых слов и возможность отправки, вместо к примеру секретных слов, сигнатур, которые легко можно достать из хорошо защищенных структур данных…. Но это не точно.
Во всяком случае, задача была решена как мне хотелось : так , как не делают обычно, и как делать не стоит. Но оно же работает!
Комментарии (17)

tzlom
08.01.2023 16:09Я хз как там в джаве строки хранятся ( UTF-16?), но ASCII и UTF-8 тут явно не к месту

koresh_builder
08.01.2023 18:04А если "сигнатуры" считать на ГПУ, это не позволит ускорить сортировку относительно классических способов?

AlehSukhadolski Автор
08.01.2023 21:38Классический способ естественно лучше... Но здесь возможна передача данных сигнатур через сеть, нечто вроде криптографии... Плюс у каждой строки может быть бесконечное количество сигнатур. Т.е. хранимые словари можно менять динамически.... В общем, задача скорее для упражнения ума, чем для практики. Но...... могут быть варианты

oldnomad
08.01.2023 19:26Как насчёт сортировки трёх строк: "абв", "а0в", и "а5в" (именно в нижнем регистре)?
Ситуаций когда все строки гарантированно из одного блока Unicode на практике почти не бывает. Разве что если ваша строка из чистого ASCII (0x00020-0x0007E). Даже без цифр в русском тексте неизбежно будут пробелы, точки, запятые, и прочие символы из других блоков, так что отбрасывание старшего байта char приведёт к неверной сортировке. И это ещё без учёта суррогатных пар, нормализации, и прочих прелестей.
AlehSukhadolski Автор
08.01.2023 19:30Здесь Вы правы. Символы должны быть из одной таблицы. Если символы из одной таблицы, то ничего не мешает отсортировать их.... Класс был сделан для всех символов таблицы.... от 0 до 255 ... Пробелы я конечно не учитывал. Но в принципе ничто не мешает их учесть, так же как их профильтровать знаки препинания и прочее... Да и решал я ее в принципе для слов , а не текста.... Чисто умозрительная задача, которая практического применения вряд ли будет иметь.... ))))

LaRN
09.01.2023 10:03А насколько объем памяти необходимый для хранения сигнатур меньше чем объем памяти необходимый для хранения строк? Есть ли выйгрыш? Если сигнатуры длиннее исходных строк, то в общем случае при сортировке сравнить две сигнатуры будет не дешевле чем две строки.

wataru
09.01.2023 13:21+2Мда… А откуда у вас там взялось число 257? Не смущает, что оно очень близко к 256?
Почитайте, что ли про системы счисления. Все вам сразу станет понятно.Эта ваша сигнатура — это просто интерпретация строки, как числа, записанного в 256-ричной системе счисления. 256, потому что значений у символа может быть столько.
Вот только это все вообще не несет в себе никакого смысла. Потому что biginteger под капотом все-равно будет хранить эти данные в виде строки байт. И мне вообще кажется, что там тоже будет использоватся 256-ричная система счисления, а значит там в памяти будет лежать вот эта же самая строка. И все сравнения будут выполнятся точно также как и со строками. Спрашивается, зачем все это?
AlehSukhadolski Автор
09.01.2023 16:30256 - размер таблицы ASCII Алгоритм требует этого. Если делать только по буквам и цифрам, то его можно существенно уменьшить. Насчет Бигинтежер Вы правы.... Но здесь возможно кодирование словарей динамически.... А вот насчет зачем все это, то склонен с Вами согласиться..
AlehSukhadolski Автор
09.01.2023 18:35Вы правы про системы счисления. Про biginteger тоже. От себя могу сказать только то, что для любой строки может быть бесконечное количество отображений в виде числа В зависимости от основы. Я ничего не хотел доказать, просто попробовал. А число 257 меня совершенно не смущает, потому что оно находится рядом с 256. Именно поэтому я его применял. Простите, если был не корректен....

AlehSukhadolski Автор
09.01.2023 16:32Нет, не придумал. И , думаю, этого не стоило делать.... Хотя, это позволяет динамически кодировать словари слов в рантайме...... Думаю, что такое никому не надо
wataru
09.01.2023 18:17Смотрите внимательно, в какую из кнопок "ответить" вы нажимаете. Вы отвечаете на свою статью, а не на чей-то комментарий.

gybson_63
09.01.2023 16:32Вы это чего, придумали N-значную систему счисления? =) Ну так и берите вес как n^i.
AlehSukhadolski Автор
09.01.2023 16:34Там есть правило. Вес символа любого должен быть больше сумм всех весов , следующих за ним..... Тогда это работает....
Hrodvitnir
Вставьте это как дисклеймер к статье:)
AlehSukhadolski Автор
Благодарю Вас... Стоит последовать Вашему совету. :))