 |
 |
«100500-ый текст про Midjourney», — подумал сейчас кто-то. Справедливости ради, шумиха вокруг нейросети немного поутихла, а работа над Midjourney — нет. Сейчас доступна четвертая версия генератора картинок, и если вы еще его не тестировали — самое время.
В этом тексте я не только покажу, как прогрессирует Midjourney, но и подробно опишу, как параметры влияют на конечный результат генерации. Это позволит вам выжать максимум из нейронной сети и эффективно использовать ограниченное количество бесплатных генераций.
Если и это вам бесполезно, то под катом много красивых и смешных картинок — котов и «горячих собак».
Дисклеймер
Обновления. Midjourney — это активно развивающийся проект. Это значит, что какие-то функции могут быть отключены, а какие-то добавлены. Даже официальное руководство пользователя не успевает за развитием проекта.

Цензура. Все материалы, сгенерированные в Midjourney, должны подходить под рейтинг PG-13. Если случайно получилось что-то неприличное, то это можно отметить для удаления. Строка запроса фильтруется на предмет «неправильных» слов, а попытки намеренно обойти фильтр могут привести к бану. Входные изображения, кстати, тоже фильтруются.
Публичность. Все запросы на генерацию и их результат доступны публично в галерее на сайте midjourney.com. Существует два способа избежать публичности: опция Stealth Generation за дополнительные $20 или тариф Pro Plan. Но даже в этом случае команды модерации и разработки Midjourney могут смотреть что вы делаете. Все описанные в статье команды и параметры доступны на бесплатном тарифном плане.
Приступим к генерациям!
С чего все началось
Моя первая генерация в Midjourney состоялась 27 июня 2022 года. Вернулся я 27 декабря.
Я особо ничего не ожидал, но сразу видно, как за полгода изменилось качество детализации и общий взгляд нейросети.
Запрос: valhalla


Я берег бесплатные генерации как зеницу ока. Но, увидев разницу, решился на месяц стандартного плана (Standard Plan) по цене $30. Мне казалось, что лимит самого дешевого тарифа в 200 генераций я очень быстро исчерпаю. Спойлер: за неделю я сделал более 500 генераций.
Отличия платной версии от бесплатной
Безлимитные генерации. Это основная причина, по которой я решился на подписку. Standard Plan предлагает 15 часов быстрой (fast) генерации и безлимит медленной генерации (relaxed). Бесплатный тарифный план предлагает 25 минут генерации, что примерно равно 25 изображениям. Способ генерации fast и relaxed влияет только на приоритет в очереди. Вечерами время relaxed-генерации может доходить до 10 минут между отправкой запроса и получением результата. Параллельно могут выполняться две генерации, остальные будут стоять в очереди.
Личные сообщения. На бесплатном тарифном плане бот генерирует изображения только в каналах сервера. Те, кто заглядывал в каналы сервера Midjourney, знают, что там нескончаемый поток генераций. С недавних пор бота можно пригласить на свой сервер, где «все свои». На платном тарифном плане бот позволяет генерировать изображения в том числе в личных сообщениях с ботом. Мелочь, а приятно (и удобно).
Лицензия. На бесплатном тарифном плане на все сгенерированные изображения действует лицензия Creative Commons Noncommercial 4.0 Attribution International License, разрешающая все, кроме коммерческого использования. Для платных тарифных планов разрешается такое использование сгенерированных изображений с условием, что у Midjourney будут неисключительные права на сгенерированные изображения и текстовые запросы. Юридический текст доступен в условиях использования.
Расширенные возможности. Остальное я считаю скорее приятным бонусом, чем полноценной особенностью платной версии. В Discord открывается дополнительный канал с технической поддержкой, куда имеют доступ только подписчики. На сайте появляется возможность смотреть генерации конкретного пользователя и оценивать свои и чужие изображения. Оценки изображений могут привести к получению «призовых» часов генерации.
Опции, которые можно передавать для генерации, не зависят от тарифного плана. Однако некоторые опции значительно повышают расход доступных минут генерации и могут быть расточительными для бесплатного тарифного плана.

Параметры генерации
Базовые параметры
В конце строки запроса можно указать параметры генерации. Сперва пройдемся по базовым параметрам:
- --ar 16:9 — соотношение сторон сгенерированной картинки,
- --seed <число> — целочисленное неотрицательное «зерно» для случайной генерации,
- --w <число> и --h <число> — явное указание ширины и высоты изображения в пикселях.
Если вам нравится какая-то комбинация параметров, то для них можно создать псевдоним командой /prefer option set <имя> <значение>. Но это уже для продвинутых пользователей.
Версии алгоритмов Midjourney
Когда мои коллеги сравнивали Midjourney со Stable Diffusion и DALL-E, у нее был алгоритм третьей версии. С декабря актуальная версия — 4. Помимо этого, есть доступ к NIJI-модификации и тестовым версиям алгоритмов. Разные версии алгоритмов имеют разное видение запросов. На данный момент доступно 7 версий:
- v1 — оригинальный алгоритм MJ. Очень абстрактный.
- v2 — оригинальный алгоритм, применяемый до 25 июля 2022 года.
- v3 — алгоритм, актуальный до декабря 2022 года.
- v4 — текущий актуальный алгоритм.
- niji — аниме-модификация.
- MJ Test — тестовый алгоритм.
- MJ Photo Test — еще один тестовый алгоритм.
Номерные версии выбираются параметром --v, а остальные — ключами: --miji, --test и --testp соответственно.
Котики — это в некотором смысле «фундамент» интернета. Так и начнем с генерации кота без дополнительных параметров и уточняющих слов.
 |
v1. Фулсайз |
 |
v2. Фулсайз |
 |
v3. Фулсайз |
 |
v4. Фулсайз |
 |
MJ Test. Фулсайз |
 |
MJ Photo Test. Фулсайз |
 |
NIJI. Фулсайз |
Оставим в покое экспериментальные версии — сгенерируем пейзаж и что-нибудь абстрактное.
| beautiful landscape | Khokhloma |
 |
 |
| v1. Фулсайз | v1. Фулсайз |
 |
 |
| v2. Фулсайз | v2. Фулсайз |
 |
 |
| v3. Фулсайз | v3. Фулсайз |
 |
 |
| v4. Фулсайз | v4. Фулсайз |
 |
 |
| NIJI. Фулсайз | NIJI. Фулсайз |
Прогресс заметен невооруженным взглядом. Четвертая версия Midjourney превосходит своих предшественников не только по качеству, но и по скорости генерации. Но за качество и скорость надо чем-то расплачиваться. Алгоритм v4 и более новые поддерживают только два соотношения сторон: 1:1 и 3:2 (2:3).
nature landscape --v 3 --ar 21:9

cyberpunk city --v 3 --ar 21:9

nature landscape --v 3 --ar 32:9

Таким образом, если вы уверенный пользователь монитора с соотношением сторон 21:9 или 32:9, то можете отложить идею сгенерировать детализированные обои для рабочего стола.
На момент написания статьи разработчики планируют добавить генерацию изображений с соотношением сторон 16:9 и 9:16.
Этапы генерации в формате видео
Бот в Discord показывает прогресс создания изображения. Что делать, чтобы получить видео этого процесса?
Видео в разных версиях: v1, v2, v3.
Произвольные соотношения сторон картинки — не единственное, что потерялось в v4. Параметр --video, который отправляет видео генерации изображения, также не попал в четвертую версию нейросети. Более того, я уточнял у поддержки — мне ответили, что этой функциональности не будет для v4.
«Костыли», конечно, никто не отменял. Существует параметр --stop <число>, который прерывает генерацию на указанном проценте готовности. Если явно указать seed и перебирать значение параметра stop, то можно получить все итерации и самостоятельно собрать из них анимацию.

К счастью или сожалению, на v4 можно получить около 16 кадров, что делает итоговую анимацию немного дерганной. Но, как говорится, на безрыбье и рак рыба.
Закончим с грустным и перейдем к детальной настройке запросов.
Акцент на словах
При генерации на изображении может возникнуть непрошенные элементы, имеющие стойкую ассоциацию с запросом. Рассмотрим запрос hot dog. Его можно трактовать как горячую (по каким-то причинам) собаку, так и как уличную еду.

Красиво, сочно и грустно, если вы хотели увидеть собаку. Дополним запрос и укажем, что хотим животное.

Теперь мы видим животное, которое является частью еды. Ай-яй-яй! Явно зададим в запросе, что не хотим видеть никакой еды при генерации. Для этого после набора слова необходимо поставить два двоеточия и задать «вес» этой последовательности. Отрицательный вес означает ваше нежелание видеть это на генерации. Например:
hot dog::1 food::-1 animal
Горячей собаке даем вес 1, а у еды, наоборот, отнимаем. Главное требование такого подхода: сумма всех указанных весов не может быть отрицательной.

Вуаля, никакой еды. К сожалению, это работает не всегда, но об этом мы поговорим далее.
Изображение в качестве запроса
В качестве запроса можно указать прямую ссылку на изображение и указать запрос, как изменить картинку. Текстовый запрос обязателен, так как Midjourney использует картинку в качестве образца, из которого подбираются основные детали и композиция. При этом на выходе получается полностью новое изображение.
На момент написания статьи можно указывать более одной картинки, но картинкам нельзя задавать веса.
Запрос: (ссылка) man notebook cyberpunk --ar 3:2
 |
 |
Как вам Гарольд, который скрывает боль в 2077? Согласен, возможно, это не самый удачный пример. Тем не менее, можно генерировать картинки и объединять их. Например, сгенерируем неонового котика и абстрактный рисунок.


Итоговый результат:
Запрос: (ссылка 1) (ссылка 2) neon cat

Этот красавец — третья итерация совмещения неонового котика с абстрактным рисунком.
Запрос: (ссылка) anime style --niji
 |
 |
Обратите внимание, что Midjourney «разбирает» и использует объекты, которые встречаются на изображениях или в текстовом виде. Однако чем более насыщенная на детали оригинальная картинка, тем больше вероятность, что что-то пойдет не так, как вам хочется.

В чатах сервера Midjourney я увидел это и сделал скриншот, чтобы показать коллеге пример того, как люди просят совместить несовместимое. По каким-то причинам поиск на сервере Midjourney не работает, поэтому этот пример остался только в качестве скриншота.
Соответствует ли результат запрошенному? Сложный вопрос. Но в запросе используется интересный параметр для стиля.
Детализация и стилизация
Midjourney позволяет задавать качество детализации генерации с помощью аргумента --q. По умолчанию этот аргумент имеет значение 1, но может изменяться в диапазоне от 0.25 до 5. Этот аргумент является модификатором затрачиваемого времени. Так, --q 2 займет в два раза больше времени на генерацию, а --q 0.25 — в четыре раза меньше.
Запрос: future city --seed 123456
| --q 0.25 | --q 1 (по умолчанию) | --q 5 |
 |
|
|
| --v 3 --q 0.25 | --v 3 --q 1 | --v 3 --q 5 |
 |
 |
 |
Для v4 значения q > 1 никак не влияют на генерацию, а значения меньше изменяют детали. Однако для v3 это буквально множитель времени и детализации: q=5 генерируется около пяти минут.
На видео заметно, как дополнительные итерации проявляют новые детали, а длительность видео возросла с 7 до 36 секунд.
Запрос: future city --seed 123456






Значительные отличия можно получить с помощью аргумента --s. Для Midjourney v3 этот аргумент принимает значения от 625 до 65000, а для v4 — от 0 до 1000. Чем больше этот параметр для v3, тем больше алгоритм позволит себе отклонений от оригинальной идеи. Для v4 описания нет, но значение изменяет взгляд нейросети при неизменном зерне.
Запрос: future city --seed 123456


Запрос: neon cat --seed 2325760227


Хотя я быстро абстрагировался от каналов с людьми и перешел в уютную переписку с ботом, я нередко заходил в каналы технической поддержки. Однажды я заметил там пользователя из категории «раньше было лучше!», который жаловался на изменение визуального стиля в Midjourney. Тогда ему посоветовали запустить генерацию с недокументированным параметром --style. На текущий момент для v4 доступны два стиля: 4a и 4b.
Кажется, мы обговорили основные опции, которые позволяют варьировать изображения. Перейдем к некоторым хорошим и плохим практикам работы с нейросетями.
Мифы и легенды
Нейросети не умеют рисовать конечности
К счастью или сожалению, это не миф, а неотвратимая реальность.


Даже если сконцентрировать внимание нейросети на необходимости нарисовать руку или лапу, все равно что-то пойдет не так. Неправильное количество пальцев? Легко. Пальцы как будто без костей? Без проблем. Ногти посреди фаланг? Заверните парочку.
Если вы не собираетесь обрабатывать изображение, то по возможности избегайте генерации конечностей живых существ крупным планом. Даже слово beautiful не помогает. А должно ли?
Метки «качества» и количества
Через несколько минут пребывания в любом чате для генераций изображений обязательно встретится человек, запрос которого на 70-80% состоит из слов, призывающих нейросеть к максимальной детализации. И сразу начинаешь верить, что это поможет. Количество бесплатных генераций ограничено, и нет времени на эксперименты!
Основной запрос: woman portrait --seed 2131932819
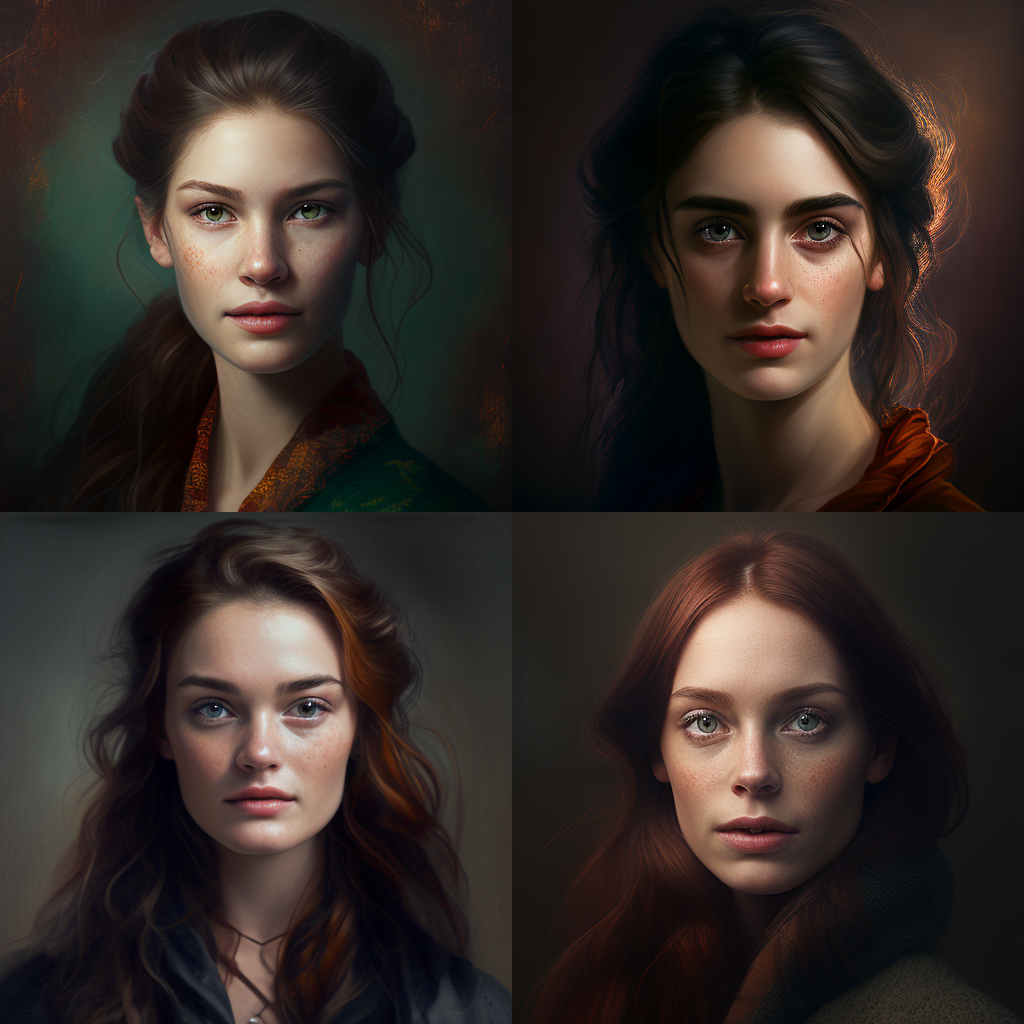

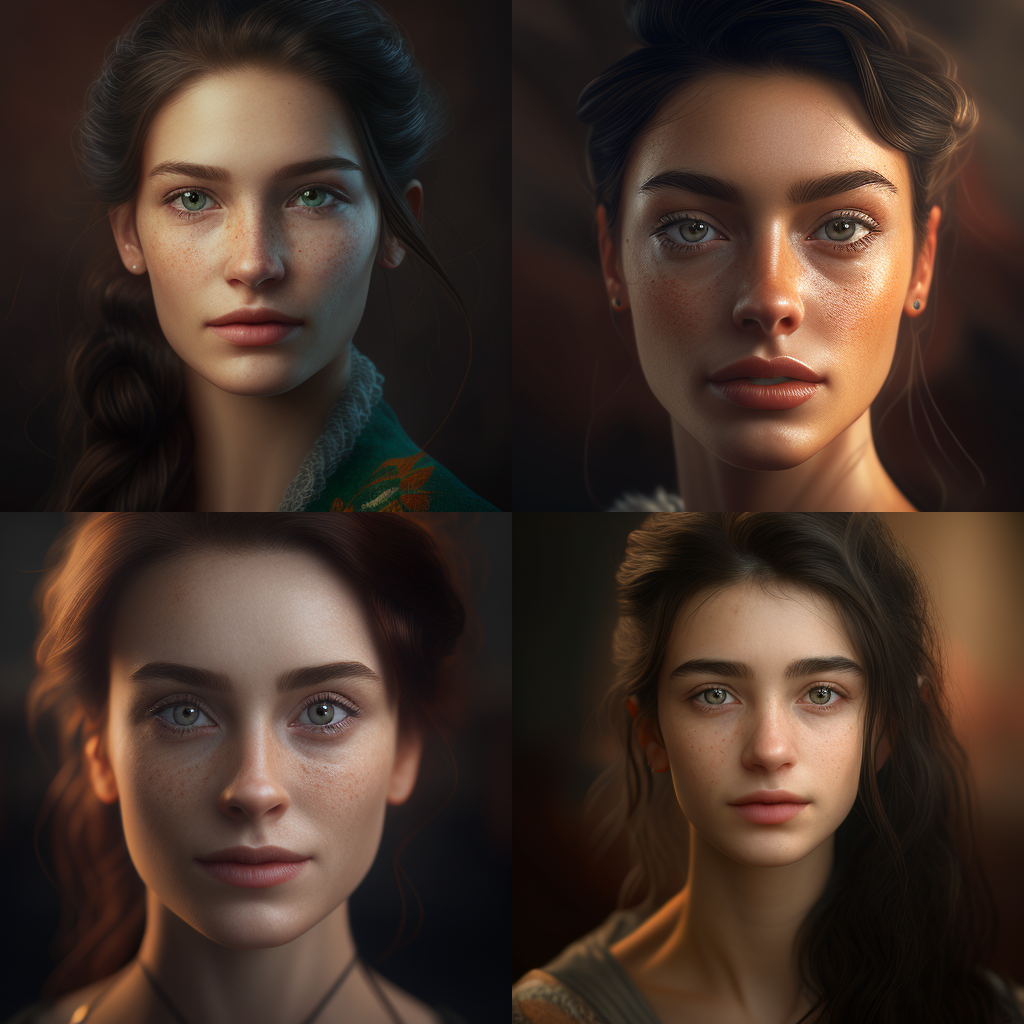
Слова Octane (Renderer), unreal (engine), realistic и 8k отсылают к желанию сделать изображение более реалистичным, более детализированным и более прекрасным. Несомненно, Midjourney видит эти слова, и они влияют на генерацию. Но каких-то существенных изменений это не вносит. Да и чувство прекрасного у всех разное.
Основной запрос: woman portrait --seed 2131932819



Нейросеть не умеет читать ваши мысли и с трудом понимает, что такое beautiful. Зато она понимает уточняющие слова, которые позволяют задать стиль и цветовую гамму.


Однако с уточняющими словами нужно быть аккуратными. Во-первых, запрос с точным числом объектов на изображении может провалиться, если объектов больше трех.
Несовместимые стили
Например: мне нравится неоновый стиль и котики. А котики — это то, что отлично получается у Midjourney.

Я сгенерировал пару десятков таких прекрасных котиков, прежде чем задумался о цвете фона. Я захотел белый фон. Ну или хотя бы белого кота.




Становится очевидно, что если на светлых неоновых котов Midjourney еще как-то согласна, то вот на светлый фон для неоновых котов — нет. И с этим остается только смириться. Я попробовал разные цвета, разное построение предложений, синонимы к слову «background» — все бестолку.
Иногда на изображении появляется текст, а письменную речь, как и руки, Midjourney генерирует плохо. В некоторых случаях даже text::-1 не помогает избавиться от назойливого текста. Особенно актуально, если в запросе есть слово logo.
Когда не можешь справиться с прямым смыслом слов, начинаешь думать про скрытый смысл предложений. А зря.
Фразеологизмы, устойчивые выражения и языки
Как-то в интернете я нашел пост. Мол, вот как нейросети видят русские устойчивые выражения.
 |
 |
 |
| жадина-говядина | деловая колбаса | ядрена вошь |
Источник: Telegram-канал «Нейросеть for Fun»
Конечно, такой заголовок привлекает читателя и побуждает поделиться с друзьями. Но на поверку это всего лишь отличный маркетинговый ход.


Какая-никакая говядина появляется только на дословном переводе жадины-говядины — «greedy beef», а в оригинальном написании появится портрет девушки. И то корова с оригинального изображения, скорее всего, появилась не с первого раза и была дополнена различными словами.
Кстати, портрет девушки — это защитная реакция Midjourney, когда она не в силах понять, что от нее хотят. В любой непонятной для нейронной сети ситуации будет нарисован портрет девушки. Даже запрос на английском «nine dots» покажет портрет девушки! Хотя бывают и исключения.


Результат запроса «суп с котом» продемонстрировал наличие кота, хоть и без супа. Но я связываю это с популярностью котов.
Русские крылатые выражения переводятся на английский, и в процессе теряется сакральный смысл. Но это не самая большая проблема, ведь в английском языке тоже есть фразеологизмы — идиомы.
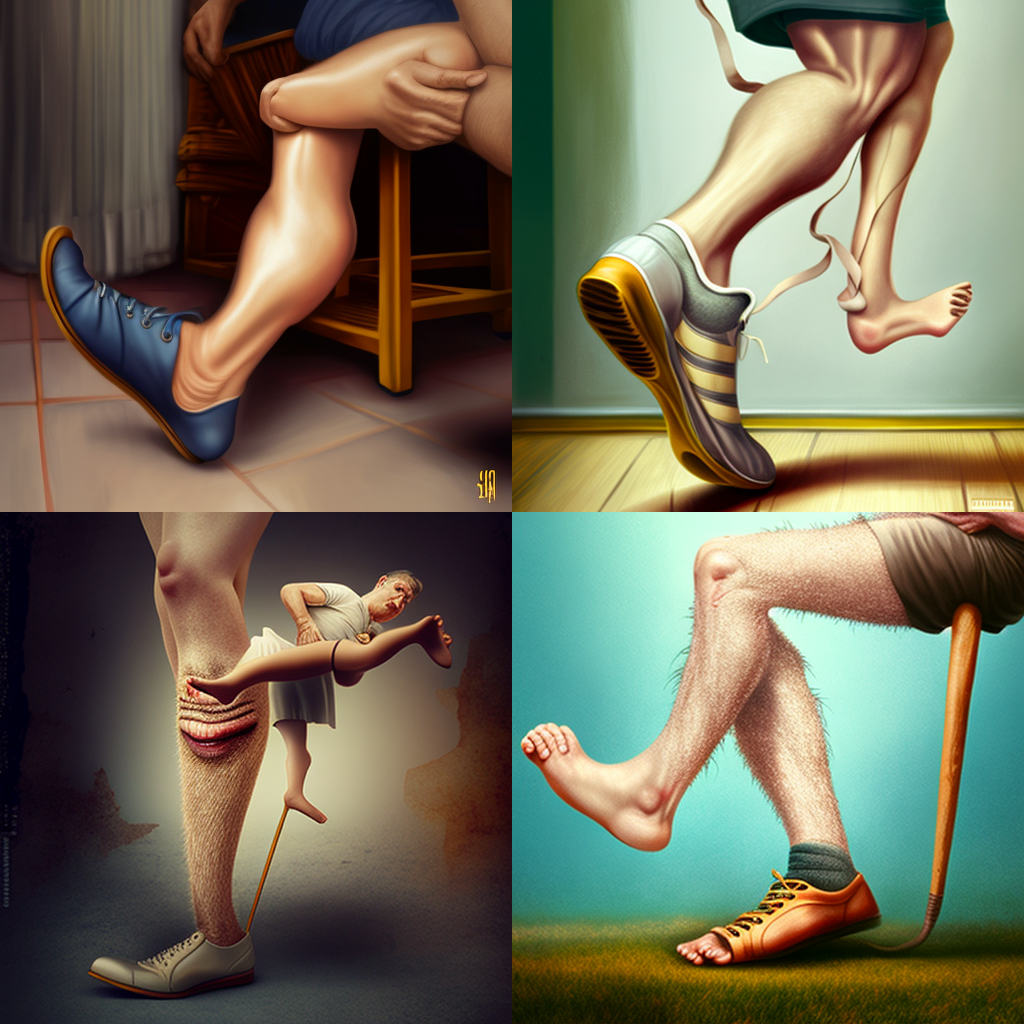


И… Midjourney дословно продемонстрировала значение каждой из этих идиом:
- are you pulling my leg — вы меня разыгрываете,
- get your ducks in a row — держать [что-то] в порядке,
- face the music — принять наказание за совершенный проступок.
Я не рассчитывал на понимание идиом, но проверить очень хотелось.
Как лучше использовать Midjourney?
После генерации почти половины тысячи картинок и безуспешных попыток добиться рисунка из своих фантазий я вынес следующие утверждения, которые помогут насладиться взаимодействием с нейросетями.
- Не стоит ставить сложное и детальное ТЗ. С четкими проработанными требованиями нужно обращаться к дизайнеру или художнику.
- Midjourney может творить потрясающие картинки: выберите ключевые слова вашей идеи и комбинируйте их для достижения великолепного результата.
- Если картинка не впечатляет, то есть кнопка повторения с новым зерном, а если не нравится лишь маленькая деталь, то есть кнопка вариаций.
- Midjourney идеально подходит для генерации портретов и крупных планов: можно сделать себе аватарку.

Мой ник странный, но в интернете я видел только одну визуализацию: красную луну. И вот Midjourney по моему нику сгенерировал нечто потрясающее. К сожалению, так работает не со всеми никами — иногда будет портрет девушки. Но добавьте слово logo и все изменится.
Заключение
Midjourney сильно прокачалась, но все еще не может конкурировать с художниками и дизайнерам. Нейронные сети могут сделать эпичную и сочную картинку, но с трудом вплетают сюжет и отсылки к своим кумирам. Когда фотография становилась популярна, художники всерьез забеспокоились, что это конец живописи. Но этого не случилось.
Я никогда не умел рисовать, да и срисовывал плохо. Я умею только писать: код и тексты. И для меня нейросеть Midjourney — это уникальная возможность превратить свой текст в визуальный контент, который радует глаз. Пара ключевых слов превращаются в пейзаж, который может стать источником вдохновения. Плохо ли? Хорошо!
Ссылка на альбом с котиками от MJ →
Если вам нравится читать про нейронки, изучите эти тексты:
→ Сможет ли Midjourney заменить дизайнеров? Тестируем нейронную сеть
→ Баттл «художников»: сравниваем Midjourney, DALL-E 2 и Stable Diffusion
→ Копирайтеры больше не нужны? Просим новую нейросеть Notion AI написать про Python
Комментарии (64)

ramzes2
11.01.2023 18:55+10А семь красных линий может?
Alexrook
11.01.2023 19:28+3Это такая вещь, где чем проще желаемый результат, тем тяжелее его добиться, иногда невозможно вообще. Все равно будет выдавать не то и додумывать лишнее. Особенно тяжело добиться правильных форм - прямых линий, окружностей, плавных кривых линий и так далее. Поэтому генерация какой-то техники - это не для нейросетей. На превьюшке может быть красиво, если мельком взглянуть, а откроешь, присмотришься… и прослезишься.

EvilFox
11.01.2023 20:12+1Поэтому генерация какой-то техники - это не для нейросетей
Stable diffusion справляется лучше.
https://civitai.com/models/1798/carhelper-for-sd-2x
Но конечно зависит от нужной вам технике.
Alexrook
13.01.2023 03:33Спасибо, поковыряюсь, если будет время.
Я не имел в виду, что не справляется вообще. Нет, превьюшки могут быть сногсшибательные. Но вот пока. ни одна нейросеть не умеет рисовать даже простейшие автомобильные диски ) Ни и по другим мелочам беда. Иногда некоторые линии уходят не туда, куда должны, иногда получается просто каша в каких-то местах. С теми же портретами - это уже продакшн рэди решение - генерируй и используй, просто иногда идеальные изображения, пока не доходит дело до рук и особенно пальцев, ну а про пальцы ног я вообще молчу. Но портреты уже вполне доведены до совершенства. Природа получается достаточно хорошо. А вот, например, городские пейзажи, как и машины, не очень. Тоже те линии, которые должны идти прямо, уходят куда-то не туда, пересекаются, искривляются. В общем, что-то точное рисовать нейросетями невозможно. И не знаю, даст ли эта технология такую возможность вообще. Я не специалист, но мне кажется, что сама идея постепенного убирания шума не может обеспечить идеальное воспроизведение сложных техногенных объектов. Для органики подходит куда лучше.

Firemoon Автор
11.01.2023 23:44+8
Ну, эти семь красных линий, возможно, похожи на то, что хотел заказчик. А может и нет ¯\_(ツ)_/¯

amarkevich
12.01.2023 02:41+3оригинальная задача несколько сложнее:
Нам нужно нарисовать семь прямых красных линий. Все они должны быть строго перпендикулярны, и, кроме того, некоторые нужно нарисовать зеленым цветом, а некоторые – прозрачным. Как вы считаете, это реально?

un7ikc
12.01.2023 15:40+1вот что получилось:
Hidden text
7 red perpendicular lines, 2 of which are green and 2 are transparent













mrise
11.01.2023 21:19+10Не смотря на безумную красивость, Midjourney, имхо, уже начал уступать Stable Diffusion в плане точности и возможностей для генерации.
Потому что пока MJ рос "вглубь", SD вырос "вширь".
Десятки моделей (сотни - если считать миксы), возможность добавлять собственные объекты, использовать эстетические градиенты, делать свои миксы или тонкую настройку под целевые изображения...
И это не говоря о гораздо более удобном туллинге (маски, в том числе 3д, для img2img); возможности генерировать сотни изображений в поиске того самого, правильного ракурса; возможности манипулировать запросом (включи вот этот термин с такого по такой шаг, с такой силой).
(Правда, стоит заметить слона в комнате, и признать, что значительное число моделей натренировано рисовать исключительно полуодетых анимешных девушек.)Firemoon Автор
11.01.2023 21:59+2Возможность дообучения и переобучения — это неоспоримый плюс SD. Правда, этот самый слон посреди комнаты...
Я слышал про SD в ключе именно отсутствия цензуры, но после вашего замечания (а так же замечаний комментаторов выше в этой статье и пара дискуссий в комментариях к статьям моих коллег) кажется, что разобрать SD повнимательнее — это хорошая идея.
mrise
12.01.2023 00:33+4Разобрать SD - это хорошая идея, если вам нужно сгенерировать что-то конкретное и сложное, с несколькими субъектами.
В таких случаях txt2img это только начало процесса. Потому что нейросеть не различает право/лево, не умеет считать (пальцы!), и не обладает пространственным мышлением.
Поэтому, если запросить рыжего кота в лягушачьей шапке на плече у пришельца в элипсойдном футуристическом кресле, ничего не получится. Кот будет, стул будет, возможно, если повезёт, где-то рядом будет пришелец.
Поэтому вместо того, чтобы делать картинку целиком, нужно разбить её на части, и добавлять элементы в формате коллажа.
Сделать кота в лягушачьей шапке. Кота на плече. Пришельца в футуристическом кресле. Затем применить навыки гимпа/фотошопа/пейнта, чтобы совместить это всё в одну картинку, и готовить на небольшом уровне шума до душевного спокойствия.
Нейросеть можно представить себе как очень пьяного художника. Рука помнит, как писать, но нужен постоянный контроль со стороны, чтобы получить то, что нужно. И возможности контроля в SD гораздо выше и гранулярнее.

Hu3yP7
12.01.2023 10:53+4Правда, стоит заметить слона в комнате, и признать, что значительное число моделей натренировано рисовать исключительно полуодетых анимешных девушек.
Спрос рождает предложение

inkelyad
12.01.2023 16:09+1Правда, стоит заметить слона в комнате, и признать, что значительное число моделей натренировано рисовать исключительно полуодетых анимешных девушек.
(разглядывая most downloaded на сайте, где модели публикуют)
Ну про анимешных - это не совсем верно. Хотя результат ожидаем, да.
FreeNickname
12.01.2023 16:17+2А что за сайт?
inkelyad
12.01.2023 16:19+4civitai.com
Весьма NSFW по очевидным причинам.EDIT: прочитал всю ветку и понял, как это выглядит :-) поэтому уточню - там чуть меньше приблизительно половины - про героические портреты разных персонажей в разных стилях. Вполне SFW - как раз на обложку книги. Но так получается, что если модель в принципе хорошо людей рисует, то персонажей различной степени (не) одетости оно тоже хорошо рисует.
mrise
12.01.2023 16:41Надо заметить, что civitai появился после того, как много моделей подобной направленности турнули с huggingface. Так что выборка не полностью репрезентативная.
С другой стороны, на том же Реддите половина постов - это либо девушки, либо "я научил нейросеть рисовать себя, смотрите!", так что.... да.

morijndael
12.01.2023 23:06Вот она, сила открытого кода. Пока над MJ работает одна команда (пусть и за деньги), над SD колдуют сотни энтузиастов с горящими глазами, сочетая и складывая наработки друг друга
Из особенно впечатлившего меня — запуск на видеокарточках с 2ГБ VRAM (рекомендуется 8)
Ну и UI от Automatic1111 это прям офигенная штука. Настоящий швейцарский нож. Там, где не может SD, в UI интегрированы другие модели. Апскейл (до 2.0 был особенно полезен), исправление лиц, и ещё много-много опциональных плагинов.

anzay911
11.01.2023 23:26+3Мне кажется, идеальное применение - обложки к альбомам и саундтрекам для музыкантов.

Lizdroz
12.01.2023 18:04Лица художников, рисовавших обложки к альбомам для музыкантов, представили?
mrise
12.01.2023 18:47Тут и представлять не нужно. Тема является постоянным источником драмы и токсичности для сообществ художников и "ИИ-художников".
На артстейшн, например, уже был протест по поводу использования ИИ.Скриншот Artstation от 14 декабря,
Доходит до смешного. Художника забанили на r/Art, потому что модератор посчитал, что она слишком похожа на генерацию ИИ. В ответ на предложение показать PSD-файл в качестве доказательства, модератор посоветовал художнику научиться рисовать в своём, "не похожем на ИИ" стиле. (история, eng)





Philistine1917
12.01.2023 07:28+1Напомнило
И видимо, такая нейронная сеть не умеет считать. У неё есть понятия "один", "похожи" и "много". Как и у человека которого не учили считать.

XanderBass
12.01.2023 07:31+13Так, ну с горячими собаками мы разобрались. А как быть с горячими кисками? :D

Antikiller
12.01.2023 09:02+2Я попробовал разные цвета, разное построение предложений, синонимы к слову «background» — все бестолку.
Сначала удивился — вроде бы недавно генерировал себе именно что котов (правда, не неоновых, а психоделических) с разными фонами, и всё работало. Попробовал воспроизвести, и...
Посмотреть генерации

реально в 50% случаев запрос на белый фон игнорируется, а в остальных - смешивается с чёрным тем или иным образом. Но даже на генерации с абсолютно белым фоном само котообразное чёрное.
Я предположил, что это особенность акцента «neon», тянущего за собой по умолчанию «чёрный фон». Поигрался:
Найти белую кошку в светлой комнате
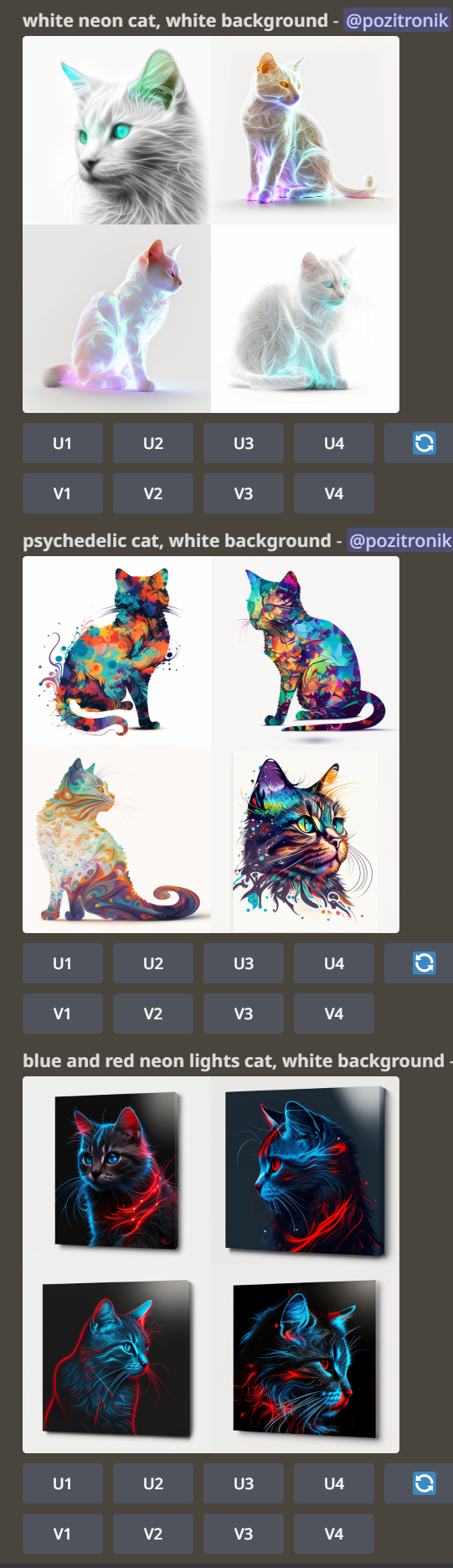
Определённо, есть завязка на «neon», не находите?
Antikiller
12.01.2023 09:07Но можно и белый фон, в итоге:
rainbow neon cat, white background

Firemoon Автор
12.01.2023 11:42Мои поздравления!
Хотя все же стоило прислушаться к упрямству MJ: на черном фоне мне субъективно нравится больше.





KirillBelovTest
12.01.2023 09:49+2На счет того, как генерируются руки и конечности. Меня тут заставили нарисовать сначала кошечку - я нарисовал только голову и получилось ровно и узнаваемо. Потом нужно было нарисовать собачку. Я решил ее сделать в профиль в полный рост и голова получилось нормально, а вот ноги очень криво. Очень естественно, что для человека конечности рисовать сложнее. Для нейросети видимо так же
mrise
12.01.2023 10:29+6Одна из шуток в сообществе Stable Diffusion зкалючается в том, что у нейросети так плохо получаются руки потому, что они получаются плохо и у человеческих художников.
Поэтому хитрые художники стараются их прятать, в результате чего у нейросети гораздо меньше референсов, и они более плохого качества.

Arxitektor
12.01.2023 09:55+1Жаль запуск такой штуки не возможен на домашних мощностях. Нужно что-то на порядки мощнее чем 4090. Жаль не сделать децентрализованное решение на подобие майнинга для генерации картинок. Подключаешься к пулу и получаешь генерации согласно твоему вкладу в мощности.

FirExpl
12.01.2023 10:41+2Stable Diffusion спокойно работает на видеокартах от 8ГБ, для макбуков есть ещё и оптимизированные под CoreML версии. Так что если не нужен именно MidJourney, то генерация картинок сейчас очень доступная

gatoazul
12.01.2023 11:10+1Отлично работает даже без видеокарты. 5 минут на картинку.
FirExpl
12.01.2023 12:49+1MBP M1 Pro. SD сконевертирована в CoreML + Swift фреймворк для SD от Apple. Где-то 30 секунд на картинку 512х512 в 30 шагов.
P.S. если кто-то хочет попробовать SD на маках без лишних заморочек то искать DiffusionBee (больше функционала, SD v1.5) или Mochi Diffusion (UI для оптимизированной под Apple SD)

positron48
12.01.2023 11:19Генерация - да, но чтобы дообучить модель своим объектом - будь добр иметь хотя бы 16 Гб видеопамяти, а лучше все 24

mousesanya
12.01.2023 13:16+2Не обязательно дообучать, можно подключить Hypernetwork. 8ГБ видеопамяти достаточно будет и результат неплохой.
mousesanya
12.01.2023 11:43У меня SD на моей GTX1070 работает нормально. Хотелось бы побыстрее конечно, но терпимо, результаты можно получить неплохие и быстро. К примеру гриды 4*4 генерятся в среднем 20-30мин (90 сэмплов, 512*512). Даже Hypernetwork обучается. С Dreambooth, да, не хватает VRAM. Но вроде можно задействовать CPU
mrise
12.01.2023 14:46Прошу прощения за любопытство, но зачем вам 90 сэмплов? Вроде бы на большинстве не-ansestrial сэмплеров разница почти исчезает на 30 шагах, на некоторых моделях - на 15-20.
По поводу Dreembooth - есть (непроверенная, с геморроем) инструкция для 8gb.
mousesanya
12.01.2023 18:03+1Ну с моими любимыми сэмплерами разница есть между 30/60/90 (SD 2.1). 30 Мне вообще не нравится, может для каких-то определенных целей и подойдет :)
mrise
12.01.2023 14:32+1Над децентрализованным решением для нейросеток уже работают.
Не так давно вышел проект большой текстовой модели https://petals.ml/, который заявляет о скорости генерации в 1 токен/секунду при размере модели 100B.
Можно ли так делать с Midjourney - мы не знаем, его архитектура вроде закрыта. Со Stable diffusion так тоже не получится, по крайней мере по мнению диванных экспертов.
Однако, уже существуют проекты вроде https://stablehorde.net/, которые используют гораздо более незамысловатый подход из краудсорсинга и пула воркеров.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
asdcxfrt
13.01.2023 09:45Попросите ChatGPT написать запросы.
У них же под капотом вроде одинаковый движок? Читал что ИИ отлично понимают друг друга.
zartdinov
Не знаю насчет Midjourney, но есть обратные генераторы, когда по картинке получаешь запрос для таких моделей. Если есть примеры (неон с белым фоном и тд.), то можно глянуть какой текст нужно ему отправлять. Мне кажется, что так нужно работать с этими моделями чтобы не гадать и не перебирать.
Sabin
Вы имеете ввиду interrogator, вроде встроенного clip или, например, wd14tagger или что-то принципиально другое?
zartdinov
Да, скорей всего я видел clip-interrogator на huggingface, про который написали ниже, вряд ли что-то другое.
cyber_roach
Можете скинуть пример такого генератора?
Чтобы именно картинку текстом описывал.
Просто у меня чувство, что вы путаете с чтением exif, практически все сети записывают туда запрос, для дальнейшей работы, и да, если картинка была сгенерирована нейросетью, то считав ее метаданные, можно получить начальный текстовый запрос, который был использован для ее генерации
mrise
Нет, не путает. Такая штука встроена в некоторые SD-дистрибутивы, например, automatic1111, или доступна онлайн.
Пример CLIP:
https://huggingface.co/spaces/fffiloni/CLIP-Interrogator-2
Пример Deep Danbooru (если я правильно понимаю, аналог wd14tagger):
http://dev.kanotype.net:8003/deepdanbooru/
perfect_genius
Что-то нереальное. deepdanbooru распознало практически всё на картинке, даже сложные элементы О_о
AlexG37G
Такое?
https://huggingface.co/spaces/pharma/CLIP-Interrogator