Алексей Барабанов, IT-директор «Хлебница» и спикер курса «RabbitMQ для админов и разработчиков», подготовил конспект о типовых архитектурных паттернах RabbitMQ. Из него вы узнаете, как настроить пайплайны обработки и реализовать очереди повторных попыток (в том числе, через механизм dead letter exchange).

Другие конспекты:
Пайплайн
Пайплайн — базовый элемент архитектуры, когда нужна последовательная обработка различными сервисами. Например, сначала требуется проверить авторизацию, затем выполнить дедупликацию и только после произвести запись данных сообщения в базу данных.
За счёт использования очередей в пайплайне хорошо видны bottleneck’и — узкие места, перед которыми скапливаются сообщения на обработку. Также есть понятный механизм расшивания посредством увеличения количества консьюмеров (конечно, это не серебряная пуля, так как проблемы могут быть у другого сервиса типа БД).
Плюс такого подхода — возможность удобного траблшутинга. На любом этапе вы можете добавить дублирующую очередь и получать копии сообщений как для разбора, так и для отправки на непродовые окружения.

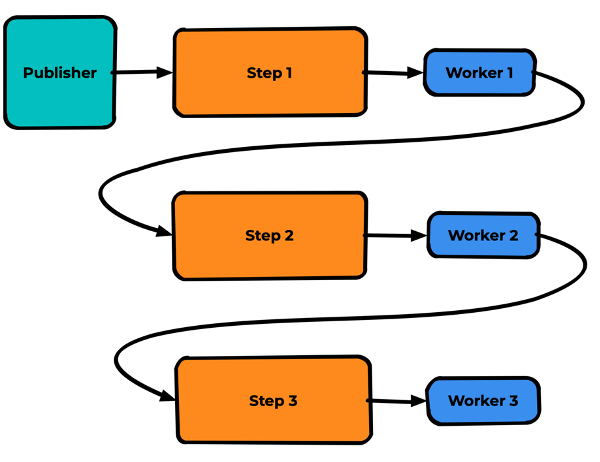
Типовой пример пайплайна обработки: Publisher отправляет сообщение, и затем оно передаётся от worker к worker по мере обработки. Worker 1 проверяет авторизацию, 2 — дедупликатор, 3 — пишет в БД.
Картинка с очередями выглядит немного сложнее, но суть та же:
Здесь и далее я не рисую exchanges перед очередями, но надо понимать, что они везде есть. Опускаю их только для упрощения схемы.
Важно: worker 1 и worker 2 на данной схеме являются одновременно и consumer, и publisher. А что произойдёт, если worker 2 перестанет справляться с дедупликацией сообщений?
Представим, что код проверки написан не оптимально, и скорость проверки ниже, чем частота прихода новых сообщений.
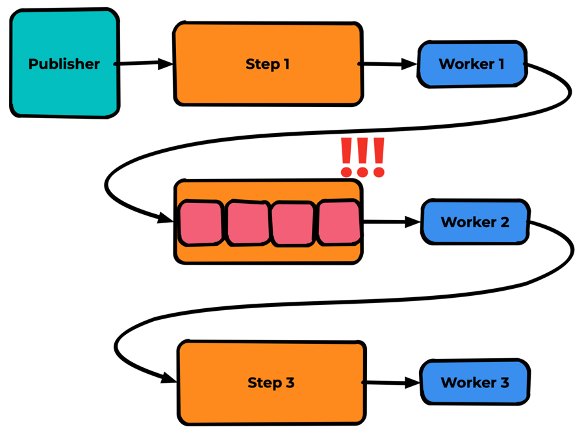
В этом случае очередь сообщений перед worker 2 начнёт расти, о чём нам тут же сообщит система мониторинга.
Если есть возможность горизонтального масштабирования — запускаем ещё один инстанс worker 2:
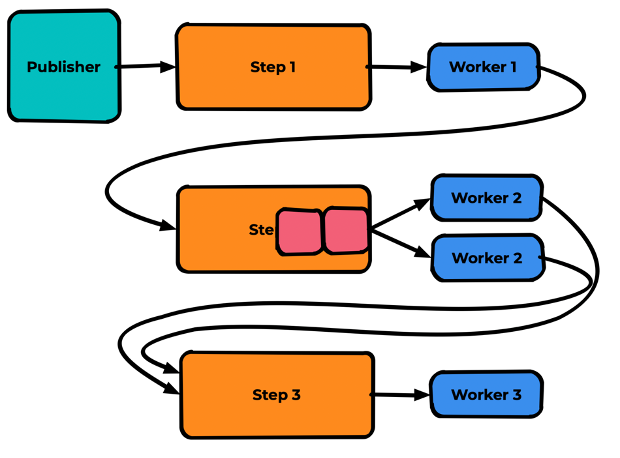
И они вдвоём ускоряют обработку сообщений. Разумеется, ускорить обработку таким способом получится не всегда. Если worker’ы упираются в скорость используемой БД, надо расшивать её или оптимизировать их код. Однако узкое горлышко обработки вы будете видеть сразу.
Очередь повторных попыток
Очередь повторных попыток — один из базовых элементов архитектуры приложения. Используется, когда есть вероятность неуспешной обработки сообщения (как «временные трудности» в целом, так и проблемы с обработкой конкретного сообщения). Работает, если нет необходимости в строгой последовательности обработки, так как подразумевает возможность временного пропуска сообщения.
Существуют два основных алгоритма реализации:
ack+publish — когда consumer сам подтверждает сообщение из основной очереди и паблишит в очередь повторных попыток;
reject+dlx — через механизм dead letter exchange.
Dead Letter eXchange
Dead Letter eXchange (DLX) — это явное или назначенное через Policy свойство очереди. Указывает RabbitMQ, куда необходимо отправлять сообщение при наступлении одного из событий:
x-mesage-ttl — превышение времени жизни;
x-max-length — превышение длины очереди;
reject — явный реджект сообщений со стороны консьюмера.
Для одной очереди можно указать только один DLX, что несколько снижает гибкость. Также вы можете указать dead-letter-routing-key, а можете не указывать — тогда сохраняется текущий для каждого сообщения.
Пример ack+publish
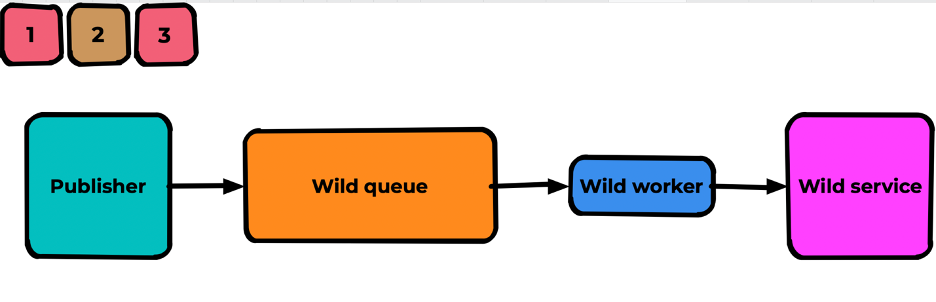
Предположим, у нас есть обработка сообщений, использующая некий внешний сервис, находящийся вне нашей зоны ответственности. Пускай сообщение «2» в данный момент не может быть им успешно обработано.
Сообщения помещаются в очередь:

Worker берёт сообщение 1 в обработку:

После успешной обработки первого сообщения доходит дело до второго — проблемного. Происходит ошибка его обработки:
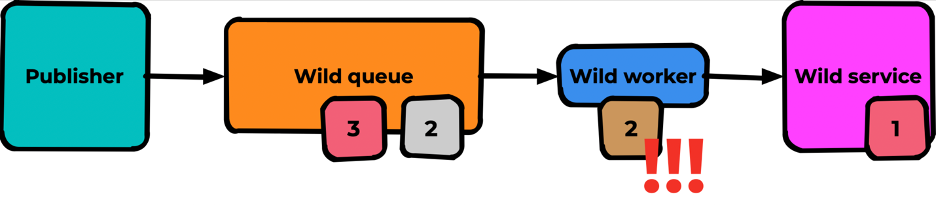
Если мы сделаем nack этому сообщению, оно вернётся в очередь на тоже самое место:
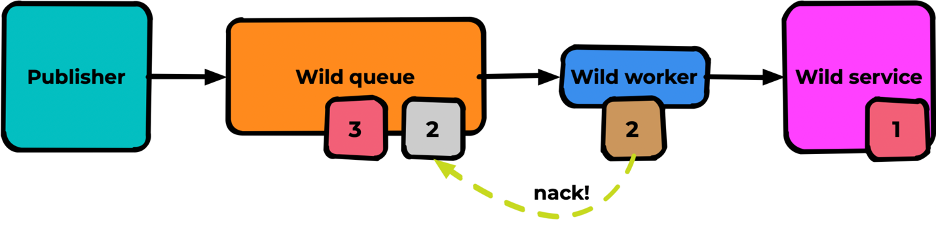
И незамедлительно будет закинуто в worker:
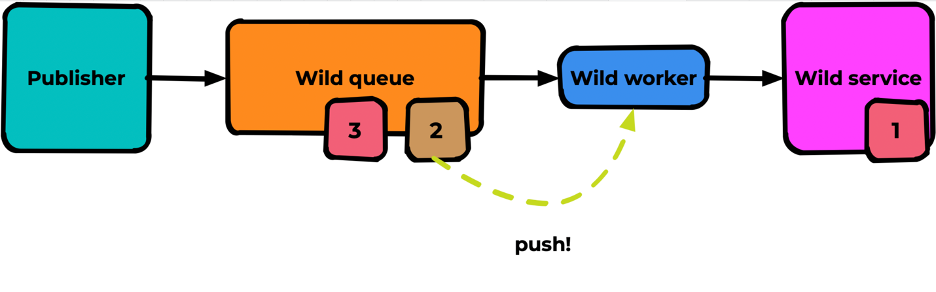
Но здесь его снова ждёт неуспешная обработка. И пока одно сообщение будет бегать туда-сюда, оно, как тромб, забьёт голову очереди. В результате все сообщения, которые могли бы быть обработаны, будут висеть в очереди и ждать своего часа:
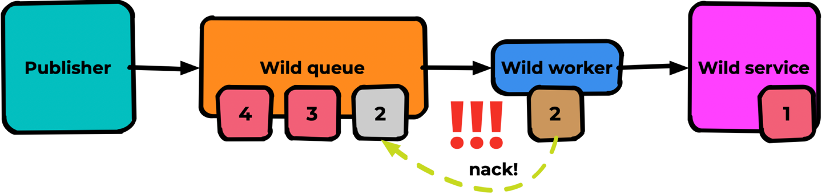
Как раз для таких случаев нужен паттерн очереди повторных попыток. Суть в том что мы создаем дополнительную очередь «retry queue», куда складируем неуспешно обработанные сообщения:
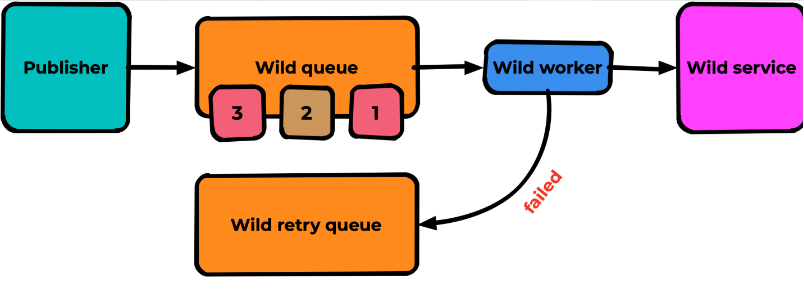
В случае ошибки обработки worker должен сделать ACK из основной очереди и publish в новую очередь:
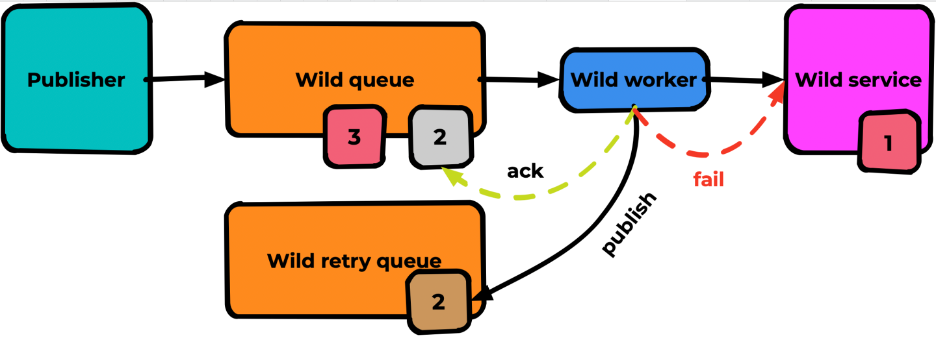
В результате для нашего примера 1 и 3 сообщения будут успешно обработаны, а 2 останется в выделенной очереди ожидать своего часа:
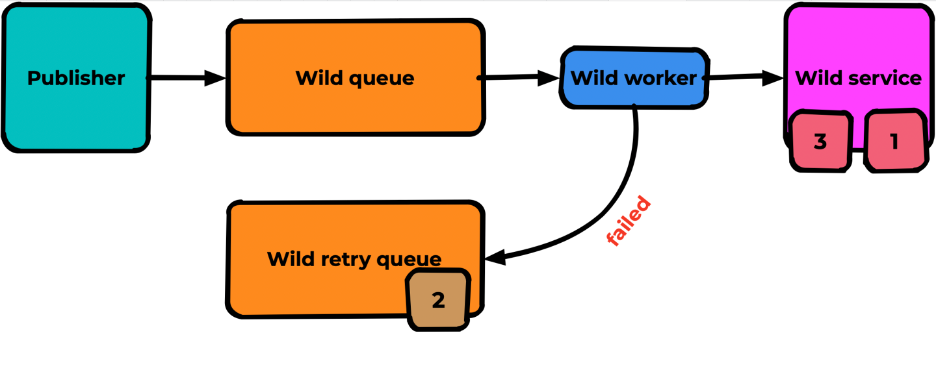
Это как раз подход ack+publish. Он наиболее часто используется в IT-системах, потому что разработчики не знают о некоторых возможностях RabitMQ. Я же рекомендую использовать другой метод — reject+DLX.
Пример reject+dlx
Всё аналогично, но для очереди мы декларируем DLX = Fail, который ведёт в ту самую очередь повторных попыток:

При неуспешной обработке мы делаем reject(false) вместо ack и publish:
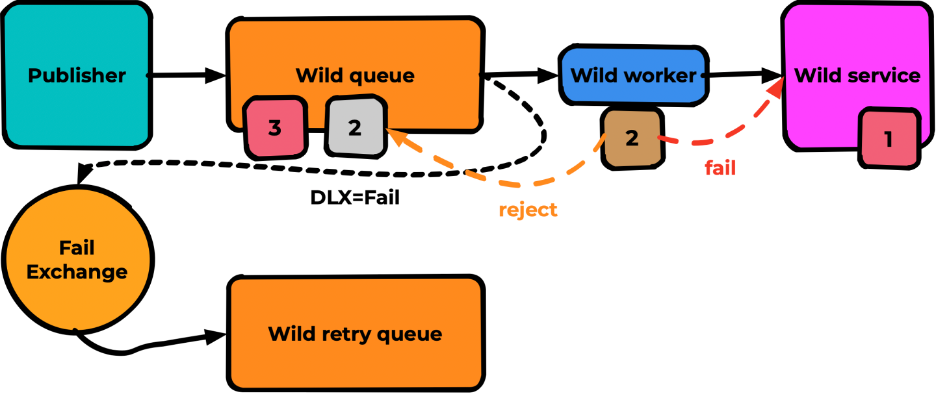
Принцип тот же, но работает проще: меньше кода — меньше возможных проблем. Результат ожидаемо аналогичный:
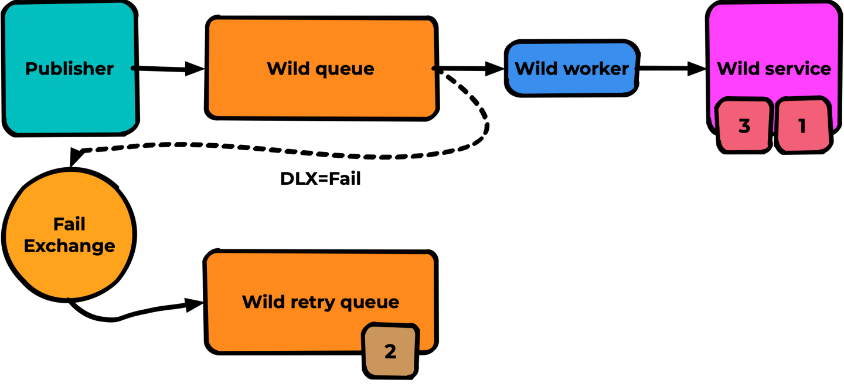
Но ведь нам нужно совершать повторные попытки обработки, а не просто складывать сообщения в отстойник. Для этого мы используем тот же самый механизм DLX + механизм TTL:
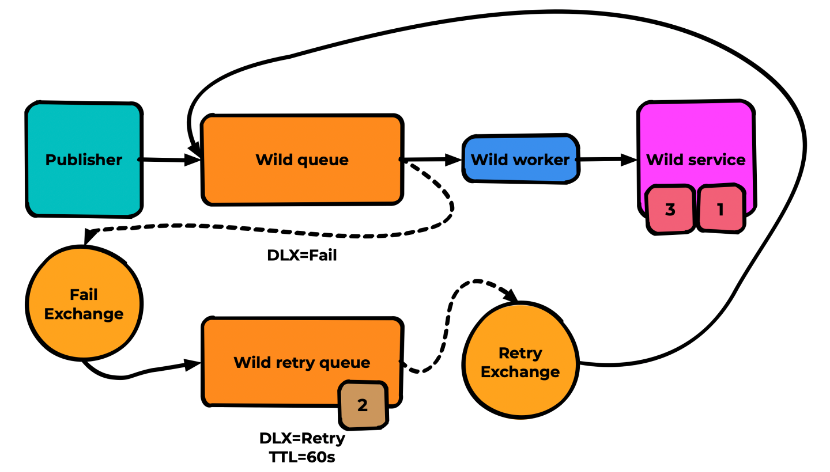
В результате сообщение 2 будет каждую минуту возвращаться в основную очередь. Будет происходить попытка его обработки и так до тех пор, пока сообщение не будет успешно обработано. Просто и без лишнего кода.
Для очередей без consumer, где возможно хранение сообщений, рекомендую также добавлять признак lazy-queue, чтобы RabbitMQ старался не держать эти сообщения в оперативке.
Про нейминг очередей: важно сразу договориться, чтобы не разводить бардака на проекте. Названия очередей должны быть поняты всем, а специализированные очереди (типа очередей с ттл и dlx или очередей-отстойников для сбойных сообщений/дублей) лучше дополнять суффиксами, например .dlx или .fail. Желательно, чтобы начало названия очереди совпадало с названием workload’а/контейнера. Это позволит легко и просто находить worker, отвечающий за обработку очереди.

Biga
Отличная статья, спасибо!
Сколько раньше ни читал про сервисы очередей, никогда не было понятно, как их толком применять.