В этой статье мы разберём несколько аномальных случаев высокой нагрузки в СУБД PostgreSQL. Что это такое? Обычно PostgreSQL хорошо показывает себя под нагрузкой и оправдывает ожидания в отношении производительности — она остаётся высокой. Но при определённых профилях нагрузки СУБД может вести себя не так, как мы ожидаем. Это и есть аномалии, на которых мы сосредоточимся в данной статье (для тех, кто предпочитает видео, эта информация доступна в виде записи доклада на HighLoad++).
Наша компания помогает обслуживать мультитерабайтные базы данных в крупных проектах, поэтому мой рассказ об аномалиях основан на реальном опыте промышленной эксплуатации СУБД в Postgres Professional — порой мы сталкиваемся с тем, что СУБД ведёт себя не так, как мы ожидали.
Также в рамках статьи мы рассмотрим следующее:
какие инструменты и каким образом мы использовали для диагностики аномалий,
какие изменения вносили,
чего смогли добиться в результате,
какие рекомендации можем дать на основе полученного опыта.
Инструментарий профилирования
Что мы используем для определения профиля нагрузки? Как правило, это стандартные инструменты для профилирования:
Perf
FlameGraph

База данных потребляет два ключевых ресурса оборудования, это процессор и диски. Если нагружены процессоры, то инструменты профилирования помогают понять, что же происходит внутри этого «чёрного ящика». Самым популярным инструментом является Perf, хотя, конечно, существует eBPF и другие. Perf даёт огромное количество информации в виде текста — речь может идти о десятках мегабайт, а то и гигабайт текста. Столько текста вручную быстро проанализировать затруднительно. Для облегчения этой задачи существует инструмент FlameGraph, созданный Бренданом Греггом (Brendan Gregg). FlameGraph умеет преобразовывать исходный текст в картинки, и такая визуализация облегчает анализ.
О профилировании нагрузки в PostgreSQL подробно рассказал Дмитрий Долгов на PGConfEU ’22.
Шпаргалка по Perf
Чтобы быстро запустить профилирование системы, можно использовать команду perf top. Команда определяет, на какие функции процессор тратит больше всего времени. Иногда этого уже достаточно, чтобы понять, в чём проблема.
Зачастую проблема кроется не в функциях, которые показывает perf top, а в том, что их вызывает, но эту информацию perf top уже не покажет. В этом случае необходимо профилировать систему «вширокую», делая периодические снимки стеков. Это можно сделать с помощью следующих команд:
perf record -F 99 -a -g --call-graph=dwarf sleep 2
perf script --header --fields comm,pid,tid,time,event,ip,sym,dso На выходе вы получите большой текстовый файл, который можно визуализировать с помощью FlameGraph.
У взаимодействия Perf с PostgreSQL есть две особенности. Во-первых, он требует debuginfo, которая не устанавливается с пакетом PostgreSQL по умолчанию — придётся доустанавливать. Во-вторых, Perf должен быть собран с поддержкой библиотеки libunwind — это библиотека, которая позволяет качественно построить стеки вызовов. Построенные без использования данной библиотеки стеки будут либо урезанными, либо не содержать названия функций, и вы по ним ничего не поймёте.
Давайте посмотрим на пример взаимодействия с Perf. Мы выполнили профилирование, построили вот такой FlameGraph:

Видно, что наибольшее количество времени процессор проводит внутри функции GetSnapshotData. Она вызывается из GetTransactionSnapshot, а эта, в свою очередь, из exec_eval_simple_expr. Этой функции нет в ядре PostgreSQL, поскольку она из модуля plpgsql, то есть у нас вызывается PL-код. А что в нём называется простым выражением? Нечто вроде i = i+1. В версиях PostgreSQL до Postgres 12 включительно каждое такое выражение требовало создания снимка данных, в 13-й версии это поправили.
Снимки в PostgreSQL
Снимки в MVCC-системе PostgreSQL используются для обеспечения изоляции транзакций, чтобы пользователь мог модифицировать данные в базе так, будто он работает с ней один, несмотря на десятки тысяч других подключений.
Определить текущий снимок для данной транзакции можно с помощью функции pg_current_snapshot(). Она возвращает нам следующие данные: xip_list - список активных транзакций , xmin - минимальную транзакцию в этом списке и xmax - следующую доступную транзакцию в системе. Если активных транзакций много, то снимок тоже может быть большим.
Снимок с помощью функции GetSnapshotData генерируется не каждый раз. Частота создания снимка зависит от выбранного режима работы с базой данных. При выборе ReadCommitted он будет генерироваться для каждого запроса (в plpgsql даже для каждого выражения). Если вы выберете RepeatableRead, снимок будет создан только один раз для транзакции. Данный режим выгоден для приложений с долгими транзакциями, он может сократить время их выполнения.
Насколько сложно серверу PostgreSQL сгенерировать такой снимок? Во-первых, он содержит список активных транзакций — следовательно, нам нужно как-то определить, какие транзакции выполняются в системе. До выхода PostgreSQL 14 снимок формировался обходом всех подключений, которых могут быть тысячи или десятки тысяч. Обычно активных транзакций бывает значительно меньше, чем подключений. В таком случае полный обход получается малоэффективным. Начиная с 14-й версии, Postgres не обходит подключения, поскольку хранит список активных транзакций.
Чтобы сгенерировать снимок, нужно получить «читающую» блокировку на список подключений или транзакций. Транзакции в ходе создания снимка могут создаваться, удаляться, заканчиваться — они постоянно меняются. Таким образом, мы получаем ещё и проблему масштабирования за счёт RW-блокировок.
Как экономить на снимках в PostgreSQL?
В случае проблем с функцией GetSnapshotData, потребляющей чересчур много ресурсов процессора, прежде всего, стоит использовать как можно более свежую версию PostgreSQL. (Причины мы объяснили чуть выше: в 14-й версии изменился способ подсчёта активных транзакций, а до этого приходилось обходить idle-подключения; после выхода 13-й каждое выражение перестало требовать создания снимка).
Если обновление уже выполнено, и у вас последняя версия Postgres, можно уменьшить количество генераций снимков. Для этого можно, например, перейти от ReadCommitted к Repeatable Read.
Подтранзакции в PostgreSQL
Зачастую мы даже не подозреваем о существовании такого функционала, как подтранзакция, пока в одно прекрасное утро не обнаруживаем, что на любимом продуктивном сервере транзакции начали выполняться в разы медленнее.
В случае возникновения подобных проблем с производительностью стоит первым делом посмотреть представление pg_stat_activity, чтобы понять, чем занимаются процессы. В нём можно увидеть состояние каждого запроса, узнать время начала транзакции и её статус, а также получить некоторые другие сведения.
Если вы видите там что-то вроде SubtransControlLock+subtrans или SubtransSLRULock, то причиной «проседания» производительности является механизм подтранзакций. Генерируются они в нескольких случаях:
С помощью явно вызванной команды savepoint, которая сохраняет состояние транзакции, чтобы в ней можно было что-то поменять или «откатить» её к предыдущему состоянию.
При использовании конструкции try-catch в PL-языках, когда мы хотим поймать exception и «откатить» состояние базы данных на момент перед try (а некоторые PL-языки до сих пор создают подтранзакции на каждую команду)
Подтранзакция практически ничем не отличается от обычной транзакции в СУБД. Это классическая транзакция с небольшой особенностью — ссылкой на родительскую (под)транзакцию (parent XID). Чтобы определить, выполнилась ли данная подтранзакция или нет, приходится вычислять не один, а два статуса — дополнительно нужно найти топовую транзакцию и проверить ещё и её статус.
Где Postgres хранит информацию о подтранзакциях? СУБД PostgreSQL спроектирована так, что для каждого подключения предусмотрено хранение до 64 подтранзакций в специальном массиве ProcArray. Массив находится в разделяемой памяти сервера PostgreSQL, и это даёт быстрый доступ из любого клиентского подключения. Но в случае, когда какое-нибудь подключение создаёт больше 64 подтранзакций, этот способ хранения перестаёт работать...
На диске в папке pg_subtrans хранится parent XID для каждой подтранзакции (с момента последней контрольной точки, checkpoint). Чтобы обращаться к диску пореже, предусмотрен SLRU-кэш подтранзакций, состоящий из 32 буферов по 8 Кб. Всего туда помещается 65536 подтранзакций. Часто этого достаточно, но в высоконагруженных системах мы легко можем генерировать и больше 65 тысяч (под)транзакций в секунду! (Кстати, очень советуем проверить, а сколько файлов у вас в pg_subtrans прямо сейчас?)
Проблемы с подтранзакциями и их решение
Первая из них очевидна — SLRU-кэш для подтранзакций не такой уж большой. Вторая заключается в том, что поиск 8-килобайтного буфера в SLRU выполняется линейно, простым перебором. Чем больше размер кэша, тем больше потребуется ресурсов процессора для поиска нужного буфера. Стоит отметить, что у SLRU-кэша мультитранзакций и у прочих есть аналогичные проблемы.
Какой эффект оказывает на производительность чрезмерная генерации подтранзакций? Возможно замедление на несколько процентов, но может случиться и «проседание» в 10 раз. При этом увеличение SLRU-кэша, если даже вам доступны терабайты памяти, не поможет ускорить работу системы — поиск по кэшу останется линейным.
Лучший вариант решения — не генерировать больше 64-х подтранзакций. Но в следующих версиях, SLRU-кэши, как мы надеемся, будут работать иначе. В мае 2020 года Андрей Бородин предложил для включения в ядро PostgreSQL патч, позже доработанный Иваном Лазаревым и Юрием Соколовым из Postgres Professional. Он позволит администратору СУБД использовать настройку slru_buffers_size_scale, чтобы увеличить размер SLRU-кэша в несколько раз, т.е. появится новый параметр, с помощью которого можно будет масштабировать этот кэш под нужды вашего приложения. Также патч заменяет простой линейный поиск на бинарный, сортируя буферы в памяти. Подробнее об этой разработке можно почитать вот здесь. Кстати, эта доработка уже попала в Postgres Pro Enterprise.
Кэш системного каталога
SLRU-кэши не единственные «поставщики» аномалий в PostgreSQL — иногда они возникают из-за кэша системного каталога. Чтобы отдать результат по запросу, нужно сначала построить план выполнения запроса. Как происходит планирование? Приходит запрос, и СУБД проверяет, какие таблицы есть в базе данных, какие есть колонки, какого они размера, какая собрана статистика. Только после перебора различных вариантов определяется лучший план, который уходит на выполнение.
Информация о колонках, статистика, и так далее, лежит на диске в виде системных таблиц. Чтобы запросы выполнялись быстро, в Postgres эти данные подгружаются с диска, причём даже не в shared memory, а напрямую в локальные кэши конкретного подключения. Это позволяет максимально быстро осуществить планирование запроса.
Как пополняется данный кэш? Если мы один раз ничего не нашли в кэше и прочитали из базы данных, затем эти данные переиспользуется для всех будущих запросов. Eсли в базе данных структура поменялась — добавилась колонка или удалили целиком таблицу, то надо выполнить инвалидацию информации о таблице в кэшах других подключений, чтобы вытеснить устаревшую информацию из кэша. Инвалидация может быть глобальной, когда сбрасывается весь кэш полностью, либо потабличной. Потабличная инвалидация позволяет не перезагружать кэш постоянно.
Все изменения в базе данных осуществляются с помощью DDL и utility-команд. А DDL в Postgres транзакционный, то есть при выполнении команды ALTER TABLE сообщение о сбросе кэша рассылается не сразу. Транзакция должна успешно завершиться, и только тогда, когда происходит commit, отправляется сообщение об изменении. Оно широковещательное (broadcast), и нет смысла рассылать его каждому процессу в отдельности. Напротив проще сохранить такие сообщения в общем циклическом буфере. Его размер - 4096 элементов.
Именно в этот буфер постепенно добавляются новые сообщения и циклически перезаписываются сообщения из прошлого. Другие соединения в различные моменты времени времени проверяют этот буфер, считывают обновления, и корректируют свои кэши. Это может происходить в начале или в процессе выполнения запроса.
Некоторые соединения не успевают прочитать эти 4000+ сообщений в буфере. Что с ними происходит? Для таких соединений выставляется определённый флаг (reset), информирующий о том, что они должны сбросить кэш и перечитать его снова. Чем больше не успевающих прочитать данный буфер вовремя, тем больше обращений к системным таблицам. В этом случае планирование запросов будет заметно замедляться.
Поэтому первое правило — как можно реже вызывать DDL на нагруженных системах. При необходимости лучше создать временную таблицу в начале сессии и переиспользовать её. Постоянно создавать и удалять таблицы для того или иного действия не рекомендуется. Postgres оптимально работает с транзакционной нагрузкой (вставка, удаление, и так далее), но при высокой частоте создания, удаления или изменения структуры таблиц СУБД становится плохо.
Второй совет — надо мониторить инвалидации кэша системных каталогов. К сожалению, «ванильная» версия СУБД Postgres предоставляет не очень много информации о том, как они себя ведут. Мы разработали специальное расширение pgpro_stats. В нем уже есть информация о том, что происходит в системе с инвалидациями. Об этом расширении вы можете почитать в документации.
Антитюнинг Postgres: что не стоит включать никогда
Если вы не знаете, для чего нужен тот или иной параметр, существует опасность антитюнинга — неверного выставления настроек. Например, в PostgreSQL есть параметр force_parallel_mode. Звучит очень заманчиво: все запросы будут выполняться параллельно. Но стоит обратить внимание на одну важную вещь: этот параметр создан не для того, чтобы ускорить систему. Его сделали для своих целей разработчики СУБД. Он служит для того чтобы разработчики PostgreSQL могли проверить тот или иной сценарий. То есть force_parralel_mode не надо ни в коем случае выставлять в промышленной системе!
Чем грозит включение этой опции? Запросы, которые в обычном режиме быстро выполнялись одним ядром процессора, потребуют создания новых дополнительных параллельных обработчиков (workers). Обработчики для своей работы подгружают информацию о системных каталогах в свои кэши, инициализируют структуры памяти, что в итоге занимает значительное количество времени. Пример результатов профилирования в данном случае можно увидеть на данной картинке:

Второй пример антитюнинга — включение параметра debug_discard_caches. Кэш системного каталога при этом отключится, и для всех запросов мы будем обращаться только к диску. Стоит быть внимательным, чтобы такие параметры по ошибке не были выставлены в активное состояние. Если вдруг заметите, что они включены, то поскорее выключите, ведь вышеперечисленные проблемы были выявлены с помощью профилирования реальных систем заказчиков!
Потребление ресурсов процессора в пространстве ядра (kernel space)
Бывает, что клиенты приходят к нам с жалобами на «греющийся» процессор, когда значение load_average превышает разумные значения. При этом Postgres — это единственная система, которая работает на данном сервере и в основном в пространстве ядра (Kernel Space).

Как на иллюстрации выше, процессорное время распределено так, что режим system занимает 87% времени — гораздо больше, чем user, на который приходится около 10% времени. Чтобы понять, в чём дело, стоит начать с запуска команды perf top, и буквально через пару секунд получим результат:

На скриншоте видно, что в пространстве ядра выполняется множество функций, названия которых начинаются с audit_. Они относятся к функционалу аудита в ядре Linux, позволяющий следить за всеми системными вызовами и по определенным правилам выполнять запись в log-файлы системы. Попробовали отключить систему аудита вызовом команды auditctl -e 0:
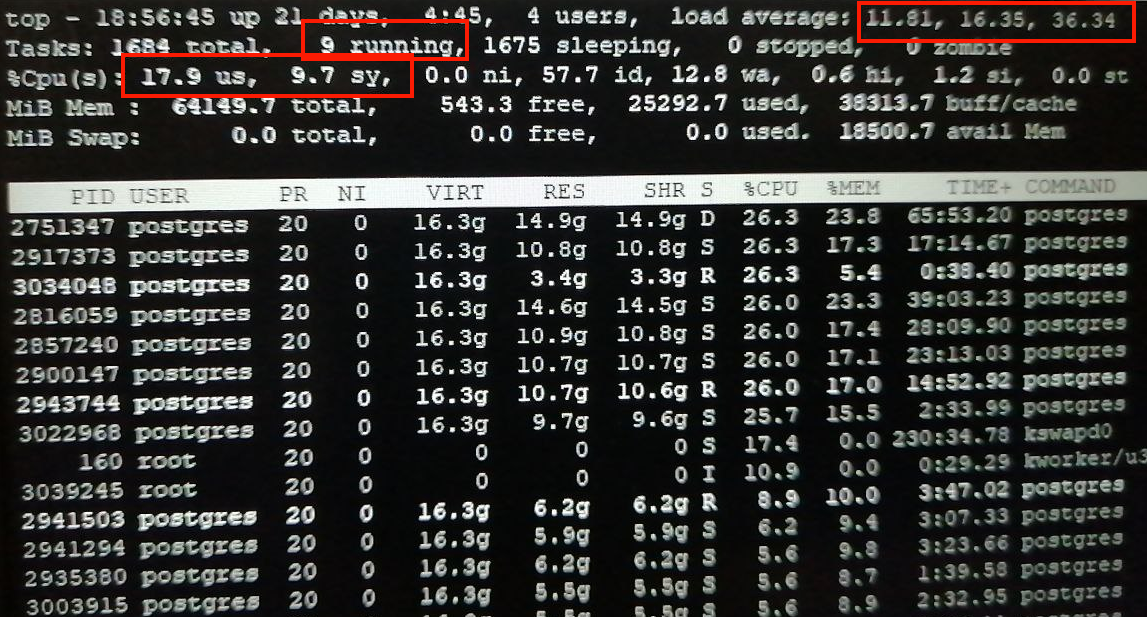
Спустя буквально несколько минут системе «полегчало», причём значительно: sys cнизился в 8 раз, а user слегка подрос. Правила аудита перепроверили — оказалось, что безопасники на сервере выставили избыточные правила auditd, что и привело к вышеупомянутым проблемам Postgres. (Извините за качество скриншотов, это не демо-стенд, а реальные системы.)
Баг наблюдаемости под нагрузкой (HighLoad Observability Bug)
Система с большим числом max_connections (>= 1000) выполняет простые запросы (SELECT, UPDATE), никаких жалоб от клиентов нет. Но если проактивно заглянуть в pg_stat_activity, то видно, что активно выполняющиеся запросы ждут чтения от клиента (ClientRead):
select wait_event, state, count(1)
from pg_stat_activity
where backend_type = 'client backend'
and state = 'active'
group by wait_event, state;
wait_event | state | count
------------+--------+-------
ClientRead | active | 5
<null> | active | 1Неужели надвигается проблема с производительностью? Сейчас придут клиенты с жалобами, что система «подвисает»?
Попробуем разобраться. В представлении pg_stat_activity видны активные транзакции и их ожидание. Согласно выводу pg_stat_activity, большинство сессий ждет ClientRead.

Смотрим в исходный код. Выясняем, что данное ожидание выставляется только внутри библиотеки libpq, когда мы заходим внутрь функции secure_read(). В комментариях к этой функции написано, что это ожидание, пока Unix socket не будет доступен на чтение (“wait until the socket is ready”). То есть никаких действий система не выполняет: она не читает данные с диска, не планирует и не выполняет какой-нибудь запрос, не коммитит транзакции и т.п. Она просто ждет от клиента, когда пришлют новый запрос.
Но секундочку, мы видели, что сессии были активны, то есть что-то выполняли. Получаем противоречие. Может, их статус был неверным? Перепроверим: статус «активно» в pg_stat_activity выставляется в начале выполнения запроса, а как только действие заканчивается, статус переходит в idle, и уже потом вызывается в функции secure read(). Вывод: активных соединений с ожиданием СlientRead не может быть согласно коду. Это ошибка pg_stat_activity!
Это представление берёт информацию из двух мест. Первое место в памяти называется BackendStatusArray. Этот массив хранит информацию о состоянии подключения — активно или неактивно, какой запрос выполняется, когда была начата транзакция, какой IP-адрес задействован, и т.п.
Вторая область памяти, откуда берётся информация об ожидании — ProcArray. Представление pg_stat_activity, судя по коду, получает эту информацию не совсем одномоментно — сначала идёт обращение к первому массиву, а потом ко второму. В результате может получиться, что соединение уже не активно, но отображается как активное.
Этот баг pg_stat_activity мы попытались поправить — уже отправили патч в сообщество, получили первую обратную связь и планируем продолжать улучшать и исправлять наше решение.
Index-Only Scan
Практически во всех СУБД есть способ выбора данных, известный как Index-Only Scan. Чем он отличается от обычного доступа к данным через индекс? При использовании индекса для выборки строк из таблицы мы сначала идём по дереву индекса, находим указатель на положение строк в таблице и потом из таблицы выбираем нужные данные.
Отличие в том, что Index-Only Scan позволяет нам выбирать данные для запроса из индекса, не заглядывая в таблицу. Все нужные для запроса колонки уже находятся в самом индексе, нам незачем лишний раз обращаться к таблице.
К сожалению, в PostgreSQL индексы не хранят информацию об xmin и xmax, которые позволяют сказать, видна ли строка для данной транзакции. Эти сведения хранятся в таблице, их придётся читать оттуда. Но в чём тогда смысл Index-Only Scan, если нам снова надо читать таблицу?
Чтобы избежать обращения к таблице, была сделана оптимизация в виде маленькой компактной карты видимости (visibility map). Она хранит дополнительный бит, подтверждающий, что все строчки в данном блоке таблицы видны для всех транзакций. То есть делать проверку xmin и xmax не нужно.
В карте видимости выделено по 2 бита на один блок таблицы. Или в пересчёте, один блок visibility map соответсвует 256 МБ таблицы. К сожалению, Index-Only Scan работает одномоментно только с одним её блоком. Если в очень большой таблице нам надо пройти по индексу и выбрать сотню строк, то, скорее всего, мы будем затрагивать разные области таблицы по 256 МБ. И, скорее всего, на каждую строчку нам нужно будет обращаться к разным блокам visibility map. Переключение между блоками снизит производительность сканирования Index-only scan.
Решение очевидно — стоит научить карту видимости работать с большим количеством блоков. Уже есть патч, и он хорошо себя показал. Стоит показать его работу на примере:
before=# explain analyse select * from test order by id;
QUERY PLAN
-----------------------------------------------------
Index Only Scan using test_idx on test (cost=0.56..1533125.37 rows=59013120 width=8) (actual time=0.080..16211.427 rows=59013120 loops=1)
Heap Fetches: 0
Planning Time: 0.115 ms
Execution Time: 18294.049 ms
(4 rows)Таблица в примере выше содержит 60 миллионов строк. В ней хранятся только ID, и мы хотим выбрать их упорядоченно. Есть индекс по этой таблице, в котором все ID хранятся упорядоченно. PostgreSQL выполняет Index-Only Scan, и прочитывает 59 миллионов строк менее чем за 19 секунд. Хороший результат, но давайте применим патч:
after=# explain analyse select * from test order by id;
QUERY PLAN
--------------------------------------------------------
Index Only Scan using test_idx on test (cost=0.56..1533125.37 rows=59013120 width=8) (actual time=0.056..7522.781 rows=59013120 loops=1)
Heap Fetches: 0
Planning Time: 0.076 ms
Execution Time: 9501.317 ms
(4 rows)Время чтения сократилось вдвое, теперь мы читаем те же самые 59 миллионов строк уже за 9,5 секунд!
Проблема Index Scan во вложенном цикле Nested Loop
Последнюю проблему, о которой хочется рассказать в данной статье, мы обнаружили совсем недавно, и для неё пока нет патча. Пусть Index Scan вызывается во внешней части вложенного цикла (Nested Loop). Чтобы сэмулировать проблему, создадим небольшую таблицу с индексом по ключевой колонке ID:
drop table if exists t_small;
create table t_small as
select i as id, md5(i*i || 'HASH') as value
from generate_series(1,20) i;
create index t_small_pk on t_small (id);
analyze t_small;...и попробуем зайти в этот индекс внешне 5 миллионов раз:
set enable_hashjoin = off;
set enable_mergejoin = off;
set work_mem = 100000000;
select t_small.value
from t_small, generate_series(1,5000000) i
where t_small.id = i + 1000
limit 10;...и проверяем план:
...
-> Nested Loop (cost=0.14..887512.00 rows=500000 width=33) (actual time=2256.209..2256.210 rows=0 loops=1)
...
-> Index Scan using t_small_pk on t_small (cost=0.14..0.16 rows=1 width=37) (actual time=0.000..0.000 rows=0 loops=5000000)
Index Cond: (id = (i.i + 1000))
Buffers: shared hit=5000000
Planning Time: 0.197 ms
Execution Time: 2288.133 msСогласно плану действительно есть некоторый вложенный цикл, который во внешней части идёт в Index Scan и делает 5 миллионов заходов. Всё прекрасно выполняется за 2 секунды.
Попробуем теперь параллельно выполнять тот же запрос ещё в нескольких подключениях одновременно. И тут неожиданный факт — чем больше подключений, тем больше времени требуется для выполнения данного запроса:

Такие запросы под нагрузкой создают большие проблемы, производительность базы данных ощутимо «проседает». Следующий график общей производительности показывает, сколько раз в секунду можно заходить в индекс:

Не более чем 2000 раз в 1 миллисекунду (то есть 2 миллиона раз в 1 секунду) на все сессии. Проблему выявили с помощью профилирования, но решения пока не нашли.
Послесловие
Именно так, в ходе повседневной работы инженеров по производительности, появляются идеи для наших разработок, которые впоследствии становятся частью PostgreSQL и СУБД Postgres Pro. За последние годы функциональные возможности PostgreSQL сильно улучшились — достаточно вспомнить появление в ядре MERGE; продолжается работа над SQL/JSON, предлагаются всё новые оптимизации для повышения производительности. В использовании свежих версий есть реальный практический смысл — надеюсь, мне удалось наглядно это продемонстрировать.
Комментарии (14)

CrushBy
00.00.0000 00:00Поэтому первое правило — как можно реже вызывать DDL на нагруженных системах. При необходимости лучше создать временную таблицу в начале сессии и переиспользовать её. Постоянно создавать и удалять таблицы для того или иного действия не рекомендуется.
Вот тут не очень понял. Часто создавать и удалять обычную (не временную) таблицу не имеет никакого смысла. Но все вещи, описанные до этого, для временных таблиц также выглядят странно. Зачем уведомлять другие подключения об изменениях временных таблиц, которые нужны фактически только текущему соединению ? То есть не очень понятно, частый DDL для временных таблиц - зло или нет ?

mizhka Автор
00.00.0000 00:00Частый DDL для временных таблиц в любом случаи зло. Это и посылка сообщений об инвалидациях (даже fast_truncate посылает инвалидацию) и замусоривание таблиц системного каталога (от этого увы никуда не деться). Стоит отметить что внутри ядра PostgreSQL инвалидации нужны не только для того, чтобы информировать другие подключения, но ещё к примеру откатить изменения системного каталога в текущем процессе при ROLLBACK-е.
CrushBy
00.00.0000 00:00замусоривание таблиц системного каталога (от этого увы никуда не деться)
Да, есть такая проблема. У нас стабильно pg_class, pg_statistic и pg_attribute разрастаются до 2ГБ. И проблема еще в том, что на сильной загрузке сделать их VACUUM FULL почти нереально из-за блокировок. В итоге приходится с этим просто жить. Непонятно правда насколько такой разросшийся pg_class и pg_statistic влияют на производительность.
Причем мы то DDL как раз особо часто не делаем. А делаем только TRUNCATE (да, не fast_trunc, так как по ряду причин нужны именно транзакционные временные таблицы) и ANALYZE. Причем первый мало того, что меняет pg_class за счет relfilenode, так он еще же и создает новые файлы, что при определенных проблемах может приводить к проблемам на уровне файловой системы. У нас была такая проблема с CentOS 8, когда количество файлов временных таблиц в каталоге начинало превышать 500.000 то местами начинались чудеса (куча процессов висела в TRUNCATE и ANALYZE временных таблиц). К сожалению, не было времени разбираться пришлось откатиться на CentOS 7, и проблема ушла.
Однако, к сожалению, отказаться от временных таблиц тяжело. И именно из-за проблем с планированием. Известно, что PostgreSQL всегда строго придерживается плана, даже если все пошло не так. И легко получить nested loop со сложностью много миллионов. И пока единственный способ с этим бороться - это INSERT фактически подплана в промежуточную таблицу (причем приходится делать TRUNCATE, чтобы не делать DDL по созданию новой), ее ANALYZE, и далее запрос с этой временной таблицей. Тогда PostgreSQL будет уже знать точное количество записей и планировать исходя из нее.
Более того, сейчас практически невозможно автоматически определить, где именно ошибся PostgreSQL. В итоге мы просто ставим таймаут запросу, и если запрос отменяется по нему, то мы считаем, что наверное PostgreSQL ошибся, и сами выбираем как ему разбить запрос на несколько с временными таблицами.
Это я все к чему. К сожалению, как обходится без TRUNCATE и ANALYZE не очень понятно. И в PostgreSQL с этим есть проблемы. В частности то, что инфраструктура со временными таблицами не вынесена как-то отдельно от постоянных таблиц. Но я понимаю, что так было сделать гораздо проще и надежнее.

wadeg
00.00.0000 00:00Все эти проблемы с планированием/оптимизацией легко решались бы, если бы идеологи pg до сих пор не отказывались бы упорото от хинтов. Но они придумали себе, будто бы сервер всегда лучше знает, как оптимизировать запрос, и всех этих проблем старательно не видят (не их же проблема, да?)
К счастью, есть расширения, позволяющие отчасти решить проблему. pg_hint_plan, например, вполне живой пример того. Попробуйте, в вашем случае хотя бы кошмар с кучей промежуточных времянок сократится, а если повезет, то и городить его не придется.
billexp
00.00.0000 00:00Использование хинтов может решить некоторые проблемы, но это сложная задачка, требующая от разработчика знаний о внутренних механиках СУБД и специфике работы приложения, и оно имеет и обратную сторону - сервер, действительно, может построить более оптимальный план, при ошибке хинт просто не сработает и сервер, опять же, будет использовать свои планы, а при изменении, к примеру, индексов придется переписывать хинты. Учитывая что хинт обычно пишется в каких-то очень неочевидных случаях - разбираться тому кто придет поддерживать код с хинтами часто бывает очень непросто.
Я не против хинтов - я много работал с ними, и хорошо знаю что это совсем не панацея.
wadeg
00.00.0000 00:00Учитывая, что хинты обычно пишутся именно тогда, когда ясно, что сервер косячит с планами, все перечисленное становится малосущественным — за исключением, конечно, меняющихся индексов и прочей физической структуры. Когда это не учитывается (или когда хинтов просто не завезли, как в тот же pg), начинается дурной вариант заката солнца вручную — попытки переписать запрос так, чтобы сервер все-таки построил план, близкий к тому, который у хорошего разработчика всегда в голове уже при написании запроса, и надеяться, что при любом изменении, например, статистики, все не сломается заново.
И да, сервер практически никогда не нарисует план лучше того, который в голове у хорошего разработчика, а вот сделать из плана даже среднего запроса полную и удивительную чертовщину — запросто. "Практически" — потому что помню случай, где сервер применил логически неочевидную оптимизацию, и выдал суперэффективный, но удивительный на первый (и по десятый включительно) взгляд план.
И, разумеется, этим действительно должны заниматься люди со знаниями и опытом явно выше среднего.
CrushBy
00.00.0000 00:00после выхода 13-й каждое выражение перестало требовать создания снимка
Кстати, зато в 13й поломали работу plpgsql. Если послать pg_cancel_backend в тот момент, когда запрос выполняется в определенном месте на определенном этапе внутри plpgsql функции, то валится вообще весь сервер. Причем это тяжело воспроизвести (так как отменяется часто, а валится раз в 2-3 месяца). Выглядит это вот так :

И это бывает совершенно на разных plpgsql функциях. В итоге приходится все переписывать на чистый SQL.
mizhka Автор
00.00.0000 00:00+1Два события похоже что связаны, но стоит разобраться что это. Обычно в dmesg сваливается информация о краше, одна строчка. На неё бы взглянуть. Наверно лучше в личку :)


pluzanov
00.00.0000 00:00+5Кстати по описанным в статье причинам, параметр force_parralel_mode в 16-й версии переименовали в debug_parallel_query.

Vitaly2606
00.00.0000 00:00Отличная статья, спасибо!
Чуть более года назад тоже разбирались с проблемой связанной с подтранзакциями в нагруженной системе. Я тестировал патч v17 - https://gitlab.com/postgres-ai/postgresql-consulting/tests-and-benchmarks/-/issues/22
В результате была написана статья, рекомендую почитать https://postgres.ai/blog/20210831-postgresql-subtransactions-considered-harmful
Смотрю уже доступен патч v24, надо будет выделить время и проверить что изменилось. А пока, пришли к выводу что надо выпиливать использование подтранзакций в нагруженных системах.
smagen
Ну всё же наоборот. exec_eval_simple_expr вызывает GetTransactionSnapshot, а GetTransactionSnapshot вызывает GetSnapshotData. На картинке обратный стек вызовов, а не прямой.
mizhka Автор
Конечно же. Спасибо большое! Текст поправил.
mark_ablov
Меня как и автора тоже смутил обратный flamegraph :)