
В статье будет рассмотрен один из методов поиска изменений в памяти процесса, на основе построения полной карты уязвимых к перехвату адресов. Рассмотрена работа со списками загрузчика, ручным разбором таблиц импорта/отложенного импорта/экспорта/TLS загруженных файлов, c обработкой форварда функций и ApiSet редиректов.
Будет показана методика доступа в 64 битное адресное пространство чужого процесса из 32 битного кода через статически сформированный ассемблерный шлюз, так и подход с применением автоматически генерируемого гейта.
Будет дано много комментариев «почему» применяется тот или иной подход, а также описание различных проблемных ситуаций, основанных в том числе как на собственном опыте, так и на разборе кода системного загрузчика, поэтому будет интересна и подготовленным специалистам.
0. В качестве вступления
Думаю, практически у ста процентов читающих данную статью в компании есть служба технической поддержки, и я думаю что не ошибусь если как минимум половина из вас писала для своей службы техподдержки вспомогательные утилиты, наподобие сборщиков системной информации, которые помогают делать общие выводы о состоянии компьютера пользователя и окружении вашего софта, запущенного на этом компьютере.
У наших технарей тоже есть такой инструмент и мне приходится периодически его расширять под новые изменяющиеся требования, добавляя те или иные ситуации, которые необходимо прогнать на машине пользователя чтобы выяснить, корректно ли работает та или иная часть софта на данной конкретной машине.
Где-то полгода назад у нас появилась очередная идея, есть очень много разноплановых ошибок которые достаточно проблематично покрыть тестами, но по результатам накопленного методом проб и ошибок опыта было выяснено что большая часть из них происходит по причине вмешательства стороннего софта в тело нашего процесса. Это могут быть как антивирусы, так и всякие DLP, а то и вовсе зловреды, которые лезут к нам в процесс, перехватывают некоторые критичные для выполнения API на себя и в обработчиках перехваченных функций ломают полностью логику исполнения кода.
Поэтому было принято решение контролировать такое вмешательство через одну из утилит, которой пользуется наша служба техподдержки, и на основе её работы быстро выяснять — кто именно, куда конкретно влез и главное, что именно он там поломал.
Собственно идея достаточно простая и она будет развитием моей предыдущей статьи "Карта памяти процесса". Суть её заключается в следующем: чтобы провернуть такой трюк, нужно уметь самостоятельно рассчитывать все критические адреса в теле удаленного процесса, знать, что должно находится по этим адресам и в автоматическом режиме просто пробежаться по ним и проверить, есть ли изменения или нет.
Правда при общей простоте идеи реализация получилось достаточно трудоемкая.
Самая большая проблема при этом была в том что утилита 32 битная, а софт, работающий у пользователя может быть как 32 бита, так и 64 (второе более вероятно), поэтому для работы с 64 битным процессом пришлось писать соответствующую обвязку.
И то я бы не сказал, что это решение в финале получилось полным, т.к. мне стало в какой-то момент времени лень обрабатывать одну из ситуаций, к решению которой я хотел подключить таблицы контекста активации процесса, (правда в них, как оказалось, нет нужной мне информации) поэтому там я выкрутился простым трюком, о котором расскажу чуть позже.
Короче в итоге получилось такое, как бы это назвать… антивирусный сканер на минималках :)
В этой статье я пройдусь по всем этапам построения такого сканера с нуля, постаравшись подробно описать каждый шаг чтобы было не только понимание что именно тут происходит, а чтобы вы (при желании, конечно) могли бы реализовать свой вариант такого сканера, даже не пользуясь моими наработками.
Для каждого из этапов будет свой код, который будет расширятся от главы к главе, обрастая функционалом, а в самом конце я дам ссылку на финальную реализацию данного фреймворка, который использую сам у себя в инструментарии (если вдруг кто захочет просто воспользоваться готовым решением подключив его к себе в проект).
1. Таблица экспорта
Для начала разберем принцип получения экспортируемых исполняемым файлом (или библиотекой) адресов функций, читая эту информацию напрямую из образа на жестком диске. Вся эта информация хранится в таблице экспорта, поэтому с неё и начнем.
Данная таблица применяется в случае динамической линовки функций посредством LoadLibrary + GetProcAddress, а также для заполнения таблиц импорта и отложенного импорта загружаемых библиотек в случае статической компоновки (на этом пока не акцентируйте внимание).
Я не буду сильно углубляться по формату РЕ файла, благо на эту тему есть огромное количество статей (ссылки будут в конце статьи), поэтому описывать буду только интересующие для текущей задачи моменты. А текущей задачей будет получить от таблицы экспорта два адреса по каждой экспортируемой функции.
- Первый это RAW и VA адрес, по которому размещен код тела функции.
- А второй — RAW и VA адрес, в котором лежит RVA указатель на первый адрес.
Да, сразу же оговорюсь, в данной статье будут применяться три термина относительно адресации:
- RAW адрес — смещение от начала файла на диске (всегда 4 байта).
- RVA адрес (relative virtual address), это относительный адрес в том виде, в котором он записан в исполняемом файле (всегда 4 байта). Как правило он указывается относительно ImageBase записанном в РЕ заголовке файла, либо относительно hInstance файла в памяти приложения, но бывают и другие варианты, я буду их указывать, когда потребуется.
- VA адрес — реальный адрес в адресном пространстве процесса. Т.к. нам нужно работать и с 32 битами и с 64, то он хранится в виде 8-байтного ULONG_PTR64 (UInt64), но содержит в зависимости от битности процесса либо 32 битный указатель, либо 64 битный. VA адрес (как правило) рассчитывается исходя из базы загрузки файла IMAGE_OPTIONAL_HEADERхх.ImageBase и прибавления к ней RVA адреса, но могут быть и исключения (например структуры ApiSet таблиц, которые рассмотрим немного позже, содержат RVA адреса относительно своего заголовка, а не ImageBase.
- Чтением структуры IMAGE_DOS_HEADER, с которой начинается исполняемый файл
- Переходом на смещение IMAGE_DOS_HEADER._lfanew, указывающий на начало PE заголовка
- Проверкой наличия четырехбайтной сигнатуры IMAGE_NT_SIGNATURE и чтением идущей за ней структуры IMAGE_FILE_HEADER.
- Из этой структуры будут интересны два поля. NumberOfSections и Machine. В зависимости от значения второго нужно прочитать идущую следом:
- либо структуру IMAGE_OPTIONAL_HEADER32 в случае если IMAGE_FILE_HEADER.Machine = IMAGE_FILE_MACHINE_I386
- либо структуру IMAGE_OPTIONAL_HEADER64 в случае если IMAGE_FILE_HEADER.Machine = IMAGE_FILE_MACHINE_AMD64
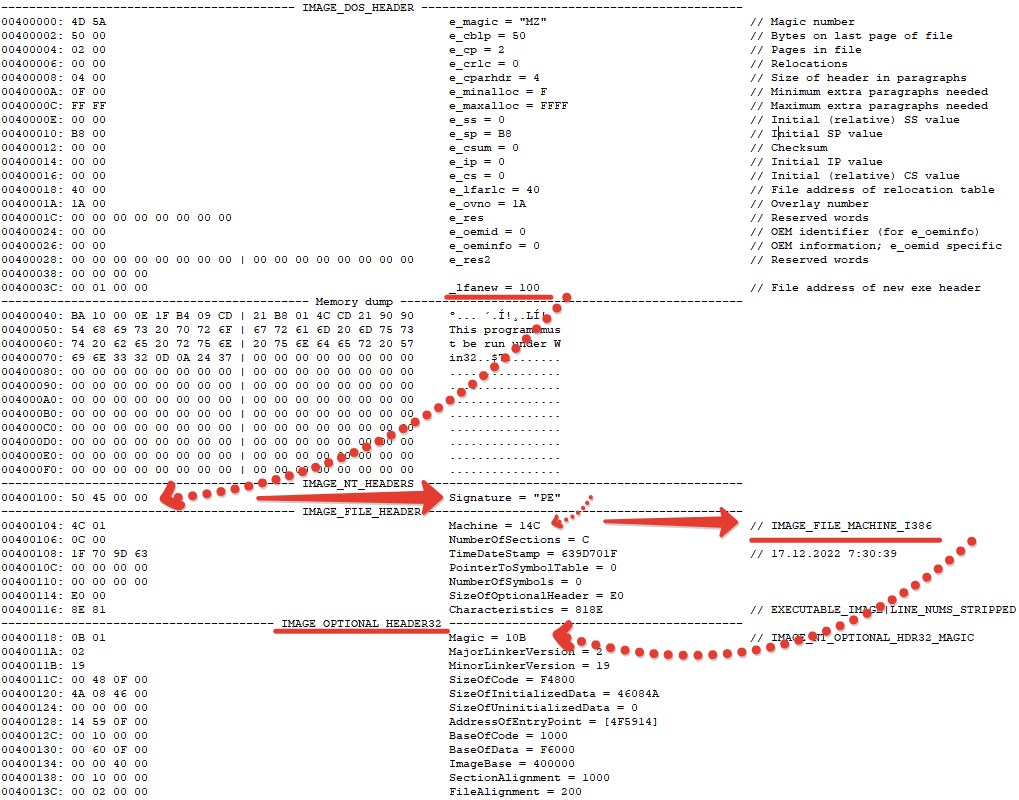
Различия структур IMAGE_OPTIONAL_HEADER друг от друга заключается в размере полей.
32 битная содержит 4 байтные DWORD, а 64 битная восьмибайтные ULONGLONG.
Последним полем IMAGE_OPTIONAL_HEADERхх содержит массив IMAGE_DATA_DIRECTORY (всего 16 элементов). Вот именно он и будет интересен, а если конкретнее, то самый первый его элемент, обозначающийся индексом IMAGE_DIRECTORY_ENTRY_EXPORT.
Но, прежде чем начать работу с этим массивом, необходимо прочитать и запомнить данные о секциях исполняемого файла. Их количество записано в поле IMAGE_FILE_HEADER.NumberOfSections, и представляют они из себя массив структур IMAGE_SECTION_HEADER которые идут сразу после IMAGE_OPTIONAL_HEADERхх.
Структура IMAGE_DATA_DIRECTORY[IMAGE_DIRECTORY_ENTRY_EXPORT], это всего два поля:
- VirtualAddress (DWORD) — RVA адрес директории
- Size (DWORD) — её размер
- VirtualAddress (DWORD) — RVA адрес секции
- VirtualSize (DWORD) — её размер в адресном пространстве процесса
- PointerToRawData (DWORD) — RAW адрес секции
- SizeOfRawData (DWORD) — размер RAW данных в файле
Так вот, если создать пустое консольное приложение и выполнить над ним описанные выше шаги, то на руках будет структура с (примерно) такими параметрами:
IMAGE_DATA_DIRECTORY[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress = 0x103000В данном случае я говорю про Delphi 10.4, которая создает исполняемые файлы с тремя экспортируемыми функциями:
IMAGE_DATA_DIRECTORY[IMAGE_DIRECTORY_ENTRY_EXPORT].Size = 0x96
dbkFCallWrapperAddr, _dbk_fcall_wrapper и TMethodImplementationIntercept
Чтобы прочитать содержимое таблицы экспорта из файла на диске, полученный RVA адрес 0x103000 не подходит и нужно его пересчитать в RAW и вот именно тут пригодится информация из массива IMAGE_SECTION_HEADER, который содержит данные для преобразования из одного типа указателя в другой.
Для этого потребуется новый класс TRawPEImage. Этапы чтения структур заголовка (LoadFromImage + LoadNtHeader) и секций (LoadSections) я пропущу, отмечу только один нюанс.
Так как подразумевается работа с 64 битным кодом из 32 битного приложения, то поле FNtHeader в данном классе имеет тип TImageNtHeaders64 и при чтении 32 битного заголовка происходит этап конвертации 32 битного опционального заголовка в 64. Это сделано только для удобства работы.
Начну сразу с реализации утилитарных функций. Первые две функции выглядит так:
function TRawPEImage.RvaToVa(RvaAddr: DWORD): ULONG_PTR64;
begin
Result := FImageBase + RvaAddr;
end;
function TRawPEImage.VaToRva(VaAddr: ULONG_PTR64): DWORD;
begin
Result := VaAddr - FImageBase;
end;Собственно это и есть все преобразование из RVA адресации в VA и наоборот.
Для преобразования из RVA адреса в RAW потребуется три вспомогательных функции:
function TRawPEImage.AlignDown(Value, Align: DWORD): DWORD;
begin
Result := Value and not DWORD(Align - 1);
end;
function TRawPEImage.AlignUp(Value, Align: DWORD): DWORD;
begin
if Value = 0 then Exit(0);
Result := AlignDown(Value - 1, Align) + Align;
end;Эти две функции отвечают за выравнивание, а третья отвечает за поиск секции, к которой принадлежит RVA адрес:
function TRawPEImage.GetSectionData(RvaAddr: DWORD;
var Data: TSectionData): Boolean;
var
I, NumberOfSections: Integer;
SizeOfRawData, VirtualSize: DWORD;
begin
Result := False;
NumberOfSections := Length(FSections);
for I := 0 to NumberOfSections - 1 do
begin
if FSections[I].SizeOfRawData = 0 then
Continue;
if FSections[I].PointerToRawData = 0 then
Continue;
Data.StartRVA := FSections[I].VirtualAddress;
if FNtHeader.OptionalHeader.SectionAlignment >= DEFAULT_SECTION_ALIGNMENT then
Data.StartRVA := AlignDown(Data.StartRVA, FNtHeader.OptionalHeader.SectionAlignment);
SizeOfRawData := FSections[I].SizeOfRawData;
VirtualSize := FSections[I].Misc.VirtualSize;
// если виртуальный размер секции не указан, то берем его из размера данных
// (см. LdrpSnapIAT или RelocateLoaderSections)
// к которому уже применяется SectionAlignment
if VirtualSize = 0 then
VirtualSize := SizeOfRawData;
if FNtHeader.OptionalHeader.SectionAlignment >= DEFAULT_SECTION_ALIGNMENT then
begin
SizeOfRawData := AlignUp(SizeOfRawData, FNtHeader.OptionalHeader.FileAlignment);
VirtualSize := AlignUp(VirtualSize, FNtHeader.OptionalHeader.SectionAlignment);
end;
Data.Size := Min(SizeOfRawData, VirtualSize);
if (RvaAddr >= Data.StartRVA) and (RvaAddr < Data.StartRVA + Data.Size) then
begin
Data.Index := I;
Result := True;
Break;
end;
end;
end;В ней происходит перебор секций, и первым этапом идет пропуск секций с нулевым размером или отсутствующими данными.
Вторым этапом вычисляется нижняя граница секции (её начало) на основе VirtualAddress с округлением вниз на значение SectionAlignment.
Третьим — верхняя граница (её конец) на основе сначала Misc.VirtualSize с округлением вверх на значение SectionAlignment, а потом SizeOfRawData с округлением вверх на значение FileAlignment.
Важный нюанс, Misc.VirtualSize может быть равен нулю и это штатное значение, в таком случае в качестве конечного адреса секции берется значение из SizeOfRawData к которому также применяется округление вверх, но уже на значение SectionAlignment.
Реальный размер секции в адресном пространстве равен меньшему из двух рассчитанных значений.
Последний этап, это проверка — попадает ли переданный RVA адрес в диапазон адресов секций.
После того как номер секции, к которой принадлежит RVA адрес определен, необходимо произвести его конвертацию посредством следующей функции:
function TRawPEImage.RvaToRaw(RvaAddr: DWORD): DWORD;
var
NumberOfSections: Integer;
SectionData: TSectionData;
SizeOfImage: DWORD;
PointerToRawData: DWORD;
begin
Result := 0;
// ... граничные проверки вырезаны
if GetSectionData(RvaAddr, SectionData) then
begin
PointerToRawData := FSections[SectionData.Index].PointerToRawData;
if FNtHeader.OptionalHeader.SectionAlignment >= DEFAULT_SECTION_ALIGNMENT then
PointerToRawData := AlignDown(PointerToRawData, DEFAULT_FILE_ALIGNMENT);
Inc(PointerToRawData, RvaAddr - SectionData.StartRVA);
if PointerToRawData < FSizeOfFileImage then
Result := PointerToRawData;
end;
end;В ней сначала происходит проверка редких ситуаций, когда RVA адрес принадлежит заголовкам файла и второй случай, когда в файле вообще нет секций (случаи граничные, поэтому рассматривать не буду).
После чего происходит сама конвертация, из конвертируемого RVA адреса вычитается RVA адрес начала секции и к результату прибавляется PointerToRawData, указывающий на смещение секции относительно начала файла. Результатом будет RAW адрес, опираясь на который можно прочитать данные из образа файла на диске.
Осталось написать еще одну утилитарную функцию, она пригодится для работы с адресами директорий, которые TRawPEImage хранит уже преобразованными в VA.
function TRawPEImage.VaToRaw(VaAddr: ULONG_PTR64): DWORD;
begin
Result := RvaToRaw(VaToRva(VaAddr));
end;Если проверить этот код на 'ntdll.dll' то в случае Win11 из 32 битного процесса (при этом будет подгружена библиотека из SysWOW64) данные будут такие:
- RVA адрес директории экспорта = 0х110360 (VA при этом равен 0x77A60360)
- Принадлежит директории '.text', которая начинается с RVA 0x1000, размером 0х122800 байт, PointerToRawData = 0х400.
- Значит в реальном файле RAW адрес директории экспорта должен быть равен: 0х110360 — 0x1000 + 0х400 = 0х10F760
Можно для самопроверки открыть эту библиотеку в HEX редакторе и сравнить с тем, что находится по VA адресу таблицы экспорта в процессе.

Скриншот показал, что данные совпали, значит RAW адрес получен правильно и пришло время читать саму таблицу экспорта напрямую из файла.
В качестве реципиента я взял маленькую библиотеку для работы с ACE архивами, так как в ней более наглядно можно увидеть для чего предназначен каждый список таблицы экспорта. Итак, таблица экспорта функций начинается со структуры IMAGE_EXPORT_DIRECTORY, которую нужно прочитать самым первым шагом.
function TRawPEImage.LoadExport(Raw: TStream): Boolean;
var
I, Index: Integer;
LastOffset: Int64;
ImageExportDirectory: TImageExportDirectory;
FunctionsAddr, NamesAddr: array of DWORD;
Ordinals: array of Word;
ExportChunk: TExportChunk;
begin
Result := False;
LastOffset := VaToRaw(ExportDirectory.VirtualAddress);
if LastOffset = 0 then Exit;
Raw.Position := LastOffset;
Raw.ReadBuffer(ImageExportDirectory, SizeOf(TImageExportDirectory));
if ImageExportDirectory.NumberOfFunctions = 0 then Exit;
// читаем префикс для перенаправления через ApiSet,
// он не обязательно будет равен имени библиотеки
// например:
// kernel.appcore.dll -> appcore.dll
// gds32.dll -> fbclient.dll
Raw.Position := RvaToRaw(ImageExportDirectory.Name);
if Raw.Position = 0 then
Exit;
FOriginalName := ReadString(Raw);
// читаем масив Rva адресов функций
SetLength(FunctionsAddr, ImageExportDirectory.NumberOfFunctions);
Raw.Position := RvaToRaw(ImageExportDirectory.AddressOfFunctions);
if Raw.Position = 0 then
Exit;
Raw.ReadBuffer(FunctionsAddr[0], ImageExportDirectory.NumberOfFunctions shl 2);Вначале идет проверка, получилось ли преобразовать VA адрес директории в RAW (т.е. результат работы VaToRaw). Таких проверок будет по коду много, и чуть позже я покажу в каком случае эти проверки могут сработать.
Особо отмечу — все адреса из структуры IMAGE_EXPORT_DIRECTORY представлены в виде RVA, т.е. для работы с ними всегда требуется преобразование, либо в RAW если читаем из файла, либо в VA если читаем из памяти!
Следующим шагом идет проверка количества экспортируемых функций, так как наличие директории экспорта еще не означает что в ней есть данные.
Далее читается имя библиотеки. Сейчас оно не интересно, но будет использоваться в следующих главах.
Ну и последним подготовительным шагом читается массив адресов экспортируемых функций. Это список DWORD, содержащий RVA адреса экспортируемых функций.
Вот так выглядит таблица экспорта для библиотеки UNACEV2.DLL
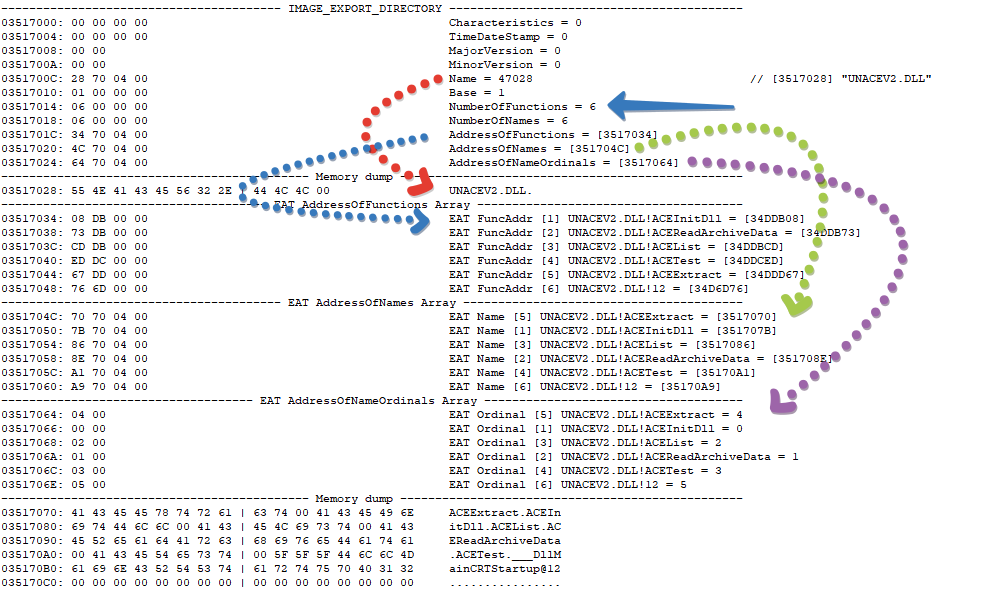
Вначале идет структура IMAGE_EXPORT_DIRECTORY и стрелками я показал на какие данные ссылаются её поля. Самое важное поля в ней это NumberOfFunctions + AddressOfFunctions.
Остальные поля со стрелками NumberOfNames + AddressOfNames + AddressOfNameOrdinals могут быть равны нулю, но NumberOfFunctions + AddressOfFunctions обязательно должны присутствовать, т.к. именно они дают возможность получить доступ к экспортируемым функциям хотя бы по их ORDINAL значению (т.е. по индексу экспортируемой функции, а не по имени).
Итак, синяя стрелка показывает на список экспортируемых функций. Первая запись:
03517034: 08 DB 00 00 EAT FuncAddr [1] UNACEV2.DLL!ACEInitDll = [34DDB08]- 03517034- это адрес в котором хранится RVA значение экспортируемой функции ACEInitDll
- 08 DB 00 00- это 4 байта которые и являются RVA адресом функции. Если преобразовать их в DWORD это будет означать 0x0000DB08 (числа хранятся в памяти в little-endian формате, т.е. обратно их привычному представлению).
- EAT FuncAddr [1] — это комментарий к экспортируемой функции поясняющий тип адреса и в скобках содержащий ORDINAL экспортируемой функции. Замечу – Ordinal это не порядковый номер, это именно индекс функции, который получается сложением IMAGE_EXPORT_DIRECTORY.Base и порядкового номера функции в таблице адресов. При загрузке функции по ординалу применяется вызов GetProcAddress(dll, MAKEINTRESOURCE(ordinal)). В текущей библиотеке он равен единице, а вот в ntdll например он равен восьми.
- UNACEV2.DLL!ACEInitDll = [34DDB08] — сама экспортируемая функция, а в скобках содержится её VA адрес, который вернет GetProcAddress (VA = RVA + ImageBase)
Из четвертого пункта можно понять, что так как RVA равен 0xDB08, а VA адрес равен 0х34DDB08 то Instance библиотеки (адрес, по которому она загружена) равен 0х034D0000
Если посмотреть на первый список, то можно заметить, что все ординалы функций (в первых квадратных скобках) идут по порядку от единицы до шести. Это условие всегда будет соблюдаться, дело в том, что это (как правило) тот порядок, в котором они объявлены в коде библиотеки. Вот как они идут в коде, так обычно и прописываются в списке экспорта (это можно наглядно увидеть по их RVA или VA значениям, которые идут на увеличение, правда это не всегда так).
Более интересны два другие списка, в частности список, на который указывает параметр AddressOfNames. Это список имен функций в количестве IMAGE_EXPORT_DIRECTORY.NumberOfNames объявленных строго в отсортированном порядке (обязательное условие), именно по этим именам идет поиск функции в случае вызова GetProcAddress, а сортировка нужна для ускорения поиска. При этом — имя функции это такой-же RVA указатель на буфер с именем (строго на Ansi буфер).
Строго говоря отсортированный список имен функций практически всегда не будет соответствовать их декларации из первого (AddressOfFunctions) списка, поэтому для соответствия какое имя какому адресу соответствует, существует третий список — AddressOfNameOrdinals. Это список двухбайтовых WORD, в количестве IMAGE_EXPORT_DIRECTORY.NumberOfNames каждый из которых соответствует (по индексу) такому же имени функции и содержащий индекс от нуля в самом первом списке AddressOfFunctions.
Можно проверить это утверждение опираясь на картинку выше:
1. имя самой первой функции из списка AddressOfNames:
0351704C: 70 70 04 00 EAT Name [5] UNACEV2.DLL!ACEExtract = [3517070]
2. соответствующий ей ординал индекс из списка AddressOfNameOrdinals
03517064: 04 00 EAT Ordinal [5] UNACEV2.DLL!ACEExtract = 4
3. индекс равен четырем. Это реальный индекс от нуля в самом первом списке RVA адресов функций. Четвертая запись из списка AddressOfFunctions:
03517044: 67 DD 00 00 FuncAddr [5] UNACEV2.DLL!ACEExtract = [34DDD67]
4. Ну а ORDINAL индекс этой функции равен индексу в списке + база, т.е. пяти.
Хитрый момент — индекс всего два байта!
Именно из-за этого ограничения ни у кого не получится сделать библиотеку, экспортирующую больше 65535 функций (я знаю людей, которые пробовали).
Вот примерно такой-же алгоритм и необходимо написать:
// Важный момент!
// Библиотека может вообще не иметь функций экспортируемых по имени,
// только по ординалам. Пример такой библиотеки: mfperfhelper.dll
// Поэтому нужно делать проверку на их наличие
if ImageExportDirectory.NumberOfNames > 0 then
begin
// читаем массив Rva адресов имен функций
SetLength(NamesAddr, ImageExportDirectory.NumberOfNames);
Raw.Position := RvaToRaw(ImageExportDirectory.AddressOfNames);
if Raw.Position = 0 then
Exit;
Raw.ReadBuffer(NamesAddr[0], ImageExportDirectory.NumberOfNames shl 2);
// читаем массив ординалов - индексов через которые имена функций
// связываются с массивом адресов
SetLength(Ordinals, ImageExportDirectory.NumberOfNames);
Raw.Position := RvaToRaw(ImageExportDirectory.AddressOfNameOrdinals);
if Raw.Position = 0 then
Exit;
Raw.ReadBuffer(Ordinals[0], ImageExportDirectory.NumberOfNames shl 1);
// сначала обрабатываем функции экспортируемые по имени
for I := 0 to ImageExportDirectory.NumberOfNames - 1 do
begin
Raw.Position := RvaToRaw(NamesAddr[I]);
if Raw.Position = 0 then Continue;
// два параметра по которым будем искать фактические данные функции
ExportChunk.FuncName := ReadString(Raw);
ExportChunk.Ordinal := Ordinals[I];
// VA адрес в котором должен лежать Rva линк на адрес функции
// именно его изменяют при перехвате функции методом патча
// таблицы экспорта.
ExportChunk.ExportTableVA := RvaToVa(
ImageExportDirectory.AddressOfFunctions + ExportChunk.Ordinal shl 2);
// Смещение в RAW файле по которому лежит Rva линк
ExportChunk.ExportTableRaw := VaToRaw(ExportChunk.ExportTableVA);
// Само RVA значение которое будут подменять
ExportChunk.FuncAddrRVA := FunctionsAddr[ExportChunk.Ordinal];
// VA адрес функции, именно по этому адресу (как правило) устанавливают
// перехватчик методом сплайсинга или хотпатча через трамплин
ExportChunk.FuncAddrVA := RvaToVa(ExportChunk.FuncAddrRVA);
// Raw адрес функции в образе бинарника с которым будет идти проверка
// на измененные инструкции
ExportChunk.FuncAddrRaw := RvaToRaw(ExportChunk.FuncAddrRVA);
// вставляем признак что функция обработана
FunctionsAddr[ExportChunk.Ordinal] := 0;
// переводим в NameOrdinal который прописан в таблице импорта
Inc(ExportChunk.Ordinal, ImageExportDirectory.Base);
// добавляем в общий список для анализа снаружи
Index := FExport.Add(ExportChunk);
// vcl270.bpl спокойно декларирует 4 одинаковых функции
// вот эти '@$xp$39System@%TArray__1$p17System@TMetaClass%'
// с ординалами 7341, 7384, 7411, 7222
// поэтому придется в массиве имен запоминать только самую первую
// ибо линковаться они могут только через ординалы
// upd: а они даже не линкуются, а являются дженериками с линком на класс
// а в таблице экспорта полученном через Symbols присутствует только одна
// с ординалом 7384
FExportIndex.TryAdd(ExportChunk.FuncName, Index);
// индекс для поиска по ординалу
// (если тут упадет с дубликатом, значит что-то не верно зачитано)
FExportOrdinalIndex.Add(ExportChunk.Ordinal, Index);
end;
end;Что здесь происходит:
Самым первым шагом идет проверка, а есть ли вообще список имен? Если есть, то происходят все те же самые действия, про которые я рассказал выше и заполняется структура, в которой будет хранится информация по каждой экспортируемой функции. Её пока не рассматриваю, она пригодится гораздо позже, для кода анализатора.
Единственно что упомяну, это то, что именно на этом этапе рассчитывается реальный VA адрес каждой функции на основе Instance библиотеки переданного в конструкторе класса, и хранится он в ExportChunk.FuncAddrVA, а также адрес поля в таблице экспорта, в котором этот адрес записан в памяти процесса, это ExportChunk.ExportTableVA.
Оба этих адреса будет контролировать анализатор на следующих этапах, т.к. изменением значения, на которое указывает ExportTableVA осуществляется установка перехватчика через правку таблицы экспорта, а правкой данных, которые указывает FuncAddrVA осуществляется установка перехватчика прямой правкой кода функции (не важно каким именно способом, через HotPatch или трамплин или вообще модификация поведения функции посредством изменения её кода целиком).
Для ускорения работы с классом помимо списка экспорта FExport используются два словаря.
- Словарь имен функций FExportIndex
- Словарь ординалов функций FExportOrdinalIndex
Дело в том, что по правилам дубликатов в списке имен экспорта быть не должно, но как видно по комментарию к коду, Delphi вполне допускает такие дубликаты, правда момент заключается в том, что эти имена не принадлежат функциям как таковым, а указывают на некие публичные структуры. Такое встречается и в штатных библиотеках, например экспортируемая из ntdll RtlNtdllName фактически функцией не является, т.к. является просто указателем на строку.
Впрочем, такие ситуации будут рассмотрены немного позже, когда буду расширять код класса, а сейчас остался последний шаг.
Данные по функциям экспортирующихся по имени загружены, но есть очень много библиотек экспортирующих часть функций только по ординалам (без имени), поэтому третьим шагом нужно обработать оставшиеся функции, опираясь на значение FunctionsAddr[Index], которое обнуляется для обработанных ранее функций (или изначально было равно нулю из-за пропуска в списке ординалов).
Кстати, по поводу списка адресов. Данный список может идти с разрывами, т.е. если простым языком, некоторые функции экспортируемые по ординалу могут отсутствовать. Тогда вместо RVA такой функции будет записан ноль, вот как в случае экспорта библиотеки cabinet.dll

Именно на такие пропуски и идет закладка, когда я упомянул что нужно проверять значение FunctionsAddr[Index]. Итак — последний шаг:
// обработка функций экспортирующихся по индексу
for I := 0 to ImageExportDirectory.NumberOfFunctions - 1 do
if FunctionsAddr[I] <> 0 then
begin
// здесь все тоже самое за исключение что у функции нет имени
// и её подгрузка осуществляется по её ординалу, который рассчитывается
// от базы директории экспорта
ExportChunk.FuncAddrRVA := FunctionsAddr[I];
ExportChunk.Ordinal := ImageExportDirectory.Base + DWORD(I);
ExportChunk.FuncName := EmptyStr;
// сами значения рассчитываются как есть, без пересчета в ординал
ExportChunk.ExportTableVA := RvaToVa(
ImageExportDirectory.AddressOfFunctions + DWORD(I shl 2));
ExportChunk.FuncAddrVA := RvaToVa(ExportChunk.FuncAddrRVA);
ExportChunk.FuncAddrRaw := RvaToRaw(ExportChunk.FuncAddrRVA);
// добавляем в общий список для анализа снаружи
Index := FExport.Add(ExportChunk);
// имени нет, поэтому добавляем только в индекс ординалов
FExportOrdinalIndex.Add(ExportChunk.Ordinal, Index);
end;По чтению таблицы экспорта всё, точнее это конечно же только первый этап, но для демонстрации корректности работы класса будет рассмотрен небольшой тестовый пример.
var
Raw: TRawPEImage;
hLib: THandle;
ExportFunc: TExportChunk;
begin
hLib := GetModuleHandle('ntdll.dll');
Raw := TRawPEImage.Create('c:\windows\system32\ntdll.dll', ULONG64(hLib));
try
for ExportFunc in Raw.ExportList do
if ExportFunc.FuncAddrVA <> ULONG64(GetProcAddress(hLib, PChar(ExportFunc.FuncName))) then
Writeln(ExportFunc.FuncName, ' wrong addr: ', ExportFunc.FuncAddrVA);
finally
Raw.Free;
end;
end.В данном примере загружается ntdll.dll и идет проверка рассчитанного адреса каждой экспортируемой функции с его реальным значением, полученным через вызов GetProcAddress.
Если все сделано правильно, то результатом выполнения будет только одна строчка
Export count: 2469Полученный в результате код достаточен, чтобы перейти к следующему этапу, его можно забрать для самостоятельного изучения по этой ссылке.
Правда если меня сейчас читают люди, полностью понимающие то, что происходит в этой главе, пока не начинайте возмущаться что выполнены не все необходимые шаги по полноценной загрузке таблицы экспорта. Я про это в курсе, но на данном этапе они пока что не нужны — все будет, но чуть позже.
2. Работа со списками загрузчика
Встает вопрос — как получить список загруженных файлов(библиотек) в удаленное адресное пространство процесса.
Вообще, конечно, технически есть вполне себе штатный способ, через вызов EnumProcessModulesEx, но с ним есть нюанс — он не покажет данные по 64 битным модулям, будучи вызван из 32 битного процесса.
В этом можно убедиться вот таким кодом:
function EnumProcessModulesEx(hProcess: THandle; lphModule: PHandle;
cb: DWORD; var lpcbNeeded: DWORD; dwFilterFlag: DWORD): BOOL; stdcall;
external 'psapi.dll';
procedure TestEnumSelfModules;
const
LIST_MODULES_ALL = 3;
var
Buff: array of THandle;
Needed: DWORD;
I: Integer;
FileName: array[0..MAX_PATH] of Char;
begin
EnumProcessModulesEx(GetCurrentProcess, nil, 0, Needed, LIST_MODULES_ALL);
SetLength(Buff, Needed shr 2);
if EnumProcessModulesEx(GetCurrentProcess, @Buff[0], Needed, Needed, LIST_MODULES_ALL) then
begin
for I := 0 to Integer(Needed) - 1 do
if Buff[I] <> 0 then
begin
FillChar(FileName, MAX_PATH, 0);
GetModuleFileNameEx(GetCurrentProcess, Buff[I], @FileName[1], MAX_PATH);
Writeln(I, ': ', IntToHex(Buff[I], 1), ' ', string(PChar(@FileName[1])));
end;
end;
end;
Слева то что он выведет, а справа реальная ситуация. Отображены только 32 битные модули, загруженные из папки C:\Windows\SysWOW64\ причем из-за работающего редиректа, этот факт прячется и пути к библиотекам показываются как C:\Windows\System32\ хотя это на самом деле не так.
Такое ограничение вполне себе понятно, дело в том, что он возвращает список инстансов, а инстанс это адрес загрузки библиотеки, т.е. указатель по сути, который для 32 бит может держать только 4 байта и не сможет вместить в себя полный 64 битный адрес.
Давайте сразу же уточню один момент.
В 64 битной ОС НЕ СУШЕСТВУЕТ 32 битных процессов! Все процессы, без исключения, являются 64 битными, и когда стартует 32 битное приложение, сначала инициализируется 64 битный процесс, в который загружаются библиотеки WOW64 подсистемы и только потом в него загружаются 32 битные образы, которые работают с ОС не напрямую, а через WOW64 подсистему, конвертирующую все 32 битные вызовы API в их 64 битные аналоги.
Именно поэтому:
- В 32 битном процессе постоянно присутствуют загруженные 64 битные библиотеки
- Флаг IMAGE_FILE_LARGE_ADDRESS_AWARE выставленный в РЕ заголовке предоставляет доступ ко всем 4 гигабайтам памяти, а не к трем, как это будет на 32 битной OS при включенном PAE (Physical Address Extension) и флаге /3GB в boot.ini
Для это нужно произвести небольшую подготовку.
В модуле RawScanner.Types я декларирую три новых структуры TModuleData, UNICODE_STRING32 и UNICODE_STRING64, и создаю новый модуль RawScanner.Wow64. Он будет содержать все необходимое для работы с 64 битными процессами, а именно обертки над следующими функциями:
- IsWow64Process — для детекта работы WOW64 подсистемы
- Wow64DisableWow64FsRedirection + Wow64RevertWow64FsRedirection — для отключения и включения редиректа библиотек из System32 в SysWOW64
- NtWow64QueryInformationProcess64 — аналог функции NtQueryInformationProcess для работы с 64 битными процессами.
- NtWow64ReadVirtualMemory64 — для чтения памяти удаленного процесса по 64 битным указателям, недоступным при вызове ReadProcessMemory
Структура TModuleData и список TModuleList будут хранить информацию по загруженным модулям и использоваться на следующих этапах.
Итак, где хранятся все данные о загруженных библиотеках? Их формирует загрузчик для каждого процесса (причем в двух экземплярах если процесс 32 битный). Представляет из себя двунаправленный список, доступ к которому нужно получить из блока окружения процесса, который сам по себе также представляет структуру, одним из полей которой является поле PPEB_LDR_DATA->Ldr.
Чтобы получить данные из списков загрузчика, нужно сначала научится правильно прочесть адрес начала этих списков.
Может быть четыре разных ситуации:
- Мы 32 битное приложение, которое будет читать данные из 64 битного
- Мы 64 битное приложение, которое будет читать данные из 32 битного
- Мы приложение, которое будет читать данные из процесса такой-же битности (т.е. два разных случая под разную битность).
Шаг первый, открываем процесс и проверяем его битность:
var
hProcess: THandle;
IsWow64Mode: LongBool;
begin
hProcess := OpenProcess(
PROCESS_QUERY_INFORMATION or PROCESS_VM_READ,
False, GetCurrentProcessId);
Wow64Support.IsWow64Process(hProcess, IsWow64Mode);Флаг IsWow64Mode будет сигнализировать о том, что удаленный процесс работает под WOW64 подсистемой.
Следующим шагом потребуется декларация структуры блока окружения процесса (полная структура не нужна, достаточно будет только до поля загрузчика):
TPEB = record
InheritedAddressSpace: BOOLEAN;
ReadImageFileExecOptions: BOOLEAN;
BeingDebugged: BOOLEAN;
BitField: BOOLEAN;
Mutant: THandle;
ImageBaseAddress: PVOID;
LoaderData: PVOID; // именно это поле нас и интересует
end;После чего потребуются еще две декларации её-же только строго соответствующие битности списка загрузчика, из которого будет производится чтение.
Еще раз заострю внимание, у 32 битного процесса на 64 битной ОС таких списков будет два, соответственно блоков окружения процесса, через которые происходит выход на список также будет два, для 64 бит и 32-битный для WOW64!
TPEB32 = record
InheritedAddressSpace: BOOLEAN;
ReadImageFileExecOptions: BOOLEAN;
BeingDebugged: BOOLEAN;
BitField: BOOLEAN;
Mutant: ULONG;
ImageBaseAddress: ULONG;
LoaderData: ULONG;
end;
TPEB64 = record
InheritedAddressSpace: BOOLEAN;
ReadImageFileExecOptions: BOOLEAN;
BeingDebugged: BOOLEAN;
BitField: BOOLEAN;
Mutant: ULONG_PTR64;
ImageBaseAddress: ULONG_PTR64;
LoaderData: ULONG_PTR64;
end; Загрузка данных будет достаточно тривиальная, посредством вызова NtQueryInformationProcess с флагом ProcessBasicInformation получаем информацию о процессе, в которой, помимо прочего будет поле PROCESS_BASIC_INFORMATION.PebBaseAddress, содержащее адрес блока окружения процесса.
Вот из него и будут читаться нужные данные.
function ReadNativePeb(hProcess: THandle; out APeb: TPEB64): Boolean;
const
ProcessBasicInformation = 0;
var
PBI: PROCESS_BASIC_INFORMATION;
dwReturnLength: Cardinal;
NativePeb: TPEB;
begin
Result := NtQueryInformationProcess(hProcess,
ProcessBasicInformation, @PBI, SizeOf(PBI), @dwReturnLength) = 0;
if not Result then
Exit;
Result := ReadRemoteMemory(hProcess, ULONG_PTR64(PBI.PebBaseAddress),
@NativePeb, SizeOf(TPEB));
if Result then
{$IFDEF WIN32}
APeb := Convert32PebTo64(TPEB32(NativePeb));
{$ELSE}
APeb := TPEB64(NativePeb);
{$ENDIF}
end;Данная функция всегда возвращает 64 битный PEB, это сделано только для удобства работы с этой структурой. Если читается 32 битный PEB, то результат преобразуется в 64 битный аналог вызовом Convert32PebTo64.
Но она покрывает только два случая из четырех вышеперечисленных.
Показываю остальные варианты:
- При чтении 32 битного PEB из 32 битного процесса (при этом мы сами находимся в 32 битной сборке)
- При чтении 64 битного PEB из 64 битного процесса (при этом мы сами находимся в 64 битной сборке)
function Read64PebFrom32Bit(hProcess: THandle; out APeb: TPEB64): Boolean;
const
ProcessBasicInformation = 0;
var
PBI64: PROCESS_BASIC_INFORMATION64;
dwReturnLength: Cardinal;
begin
Result := Wow64Support.QueryInformationProcess(hProcess,
ProcessBasicInformation, @PBI64, SizeOf(PBI64), dwReturnLength);
if not Result then
Exit;
Result := ReadRemoteMemory(hProcess, PBI64.PebBaseAddress,
@APeb, SizeOf(TPEB64));
end;Код практически идентичен предыдущему за одним исключением, здесь так-же читается информация по процессу с флагом ProcessBasicInformation, но вызывается уже 64 битный вариант функции через WOW64 хэлпер, который возвращает информацию именно по 64 битному PEB, поэтому этап конвертации тут пропущен, ибо этот вызов всегда читает именно 64 битную структуру.
Данный вызов применяется только в том случае, когда он вызван из 32 битной сборки и запущен на 64 битной ОС, причем применяется для чтения 64 битного PEB в процессах любой битности.
И последний вариант:
function Read32PebFrom64Bit(hProcess: THandle; out APeb: TPEB64): Boolean;
const
ProcessWow64Information = 26;
var
PebWow64BaseAddress: ULONG_PTR;
dwReturnLength: Cardinal;
Peb32: TPEB32;
begin
Result := NtQueryInformationProcess(hProcess,
ProcessWow64Information, @PebWow64BaseAddress, SizeOf(ULONG_PTR),
@dwReturnLength) = 0;
if not Result then
Exit;
Result := ReadRemoteMemory(hProcess, PebWow64BaseAddress,
@Peb32, SizeOf(TPEB32));
if Result then
APeb := Convert32PebTo64(Peb32);
end;Этот вызов применяется строго из 64 битной сборки для чтения 32 битного PEB в 32 битном процессе (в 64 битном он отсутствует).
Из изменений, опять используется вызов NtQueryInformationProcess но уже с флагом ProcessWow64Information возвращающим информацию только по 32 битному PEB, поэтому в конце, при успешном чтении данных, идет этап конвертации в 64 битный аналог.
Для удобства реализуется вот такой шлюз, который сам будет вызывать нужный вариант кода в зависимости от текущей сборки приложения.
function ReadPeb(hProcess: THandle; Read32Peb: Boolean; out APeb: TPEB64): Boolean;
begin
ZeroMemory(@APeb, SizeOf(TPEB64));
if Read32Peb then
{$IFDEF WIN32}
Result := ReadNativePeb(hProcess, APeb)
else
Result := Read64PebFrom32Bit(hProcess, APeb);
{$ELSE}
Result := Read32PebFrom64Bit(hProcess, APeb)
else
Result := ReadNativePeb(hProcess, APeb);
{$ENDIF}
end;Тест шлюза может выглядеть вот так:
var
PEB32, PEB64: TPEB64;
// загружаем блоки окружения процесса (если есть)
ReadPeb(hProcess, True, PEB32);
ReadPeb(hProcess, False, PEB64);И вот только теперь, когда код чтения адреса загрузчика готов, можно приступать к работе с ним, для этого смотрим на картинку:
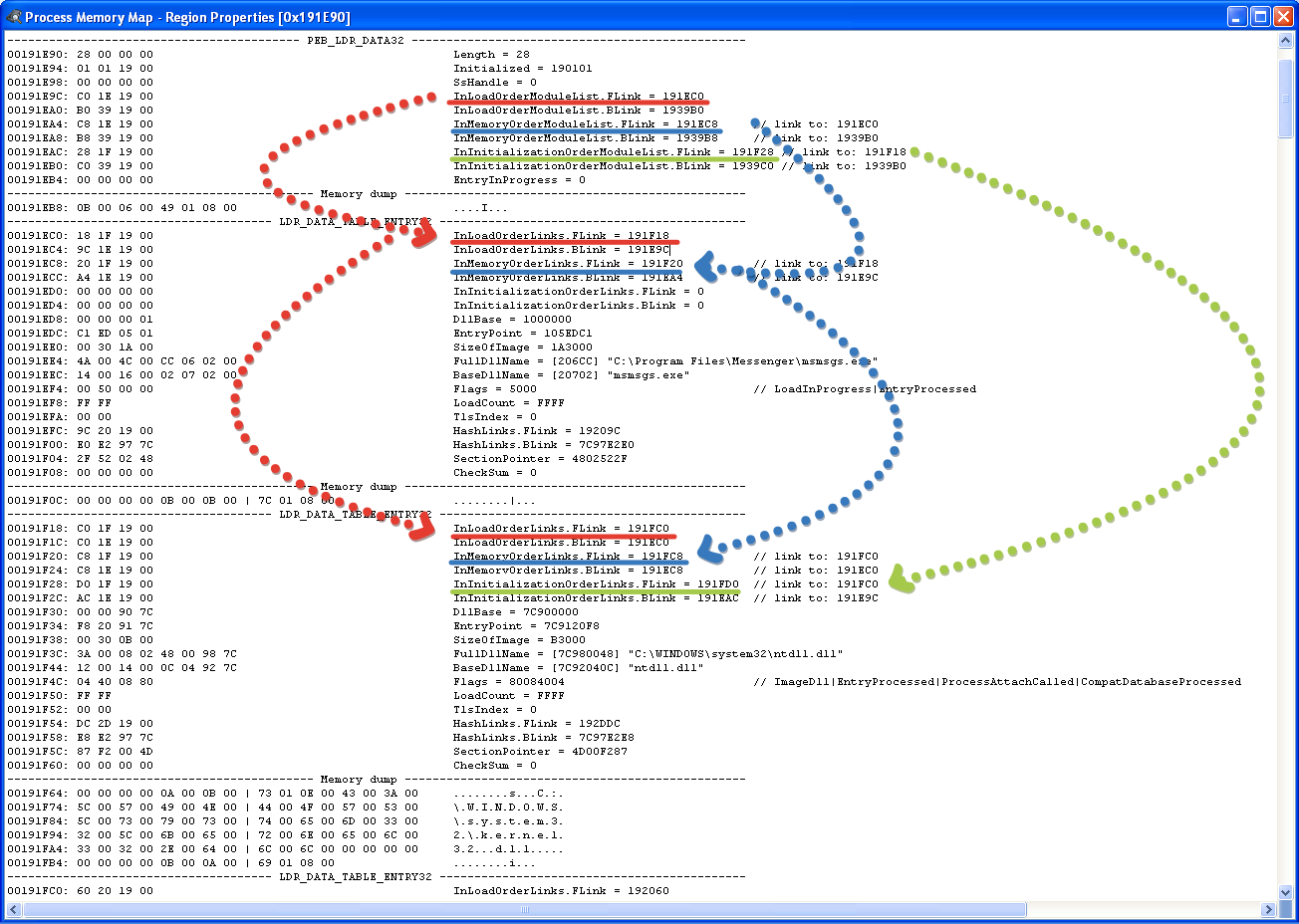
Здесь я взял изображение из WinXP только по той причине, что в ней списки загрузчика расположены в памяти более компактно, чем в остальных версиях Windows, в которых они разбросаны по страницам сильно далеко друг от друга.
Прочитанная ранее структура PEB содержит указатель на структуру PEB_LDR_DATA, которая содержит ссылки на три публичных двунаправленных списка, состоящих из элементов LDR_DATA_TABLE_ENTRY.
Если посмотрим на декларацию в MSDN, то в ней практически все поля спрятаны, кроме одного списка, содержащий список загруженных модулей, отсортированный в порядке их размещения в памяти
PEB_LDR_DATA structure
Пропущен список InLoadOrderModuleList (сортировка в порядке загрузки) и InInitializationOrderModuleList (сортировка в порядке инициализации).
Вообще чисто технически, помимо этих трех списков, операционная система держит еще 32 таких-же, использующихся для ускорения работы того-же GetModuleHandle (поэтому, когда пишут код, скрывающий себя из этих трех списков, типа руткит на минималках — всегда забывают еще и про дополнительные, скрытые).
Впрочем, это лирика, сейчас хочу показать нюанс, на котором многие спотыкаются. А спотыкаются, потому что в MSDN не правильное описание полей структуры (в смысле комментарий к ним).
Посмотрите на декларацию структур:
LIST_ENTRY32 = record
FLink, BLink: ULONG;
end;
PEB_LDR_DATA32 = record
Length: ULONG;
Initialized: BOOL;
SsHandle: ULONG;
InLoadOrderModuleList: LIST_ENTRY32;
InMemoryOrderModuleList: LIST_ENTRY32;
InInitializationOrderModuleList: LIST_ENTRY32;
// etc...
end;
LDR_DATA_TABLE_ENTRY32 = record
InLoadOrderLinks: LIST_ENTRY32;
InMemoryOrderLinks: LIST_ENTRY32;
InInitializationOrderLinks: LIST_ENTRY32;
DllBase: ULONG;
EntryPoint: ULONG;
SizeOfImage: ULONG;
FullDllName: UNICODE_STRING32;
BaseDllName: UNICODE_STRING32;
Flags: ULONG;
// etc...
end;Смотрите, вот два поля, первое указывает на начало двусвязного списка, отсортированного в порядке загрузки PEB_LDR_DATA.InLoadOrderModuleList.FLink, точнее содержит VA адрес первой структуры LDR_DATA_TABLE_ENTRY из этого списка.
По логике и PEB_LDR_DATA.InMemoryOrderModuleList.FLink должен указывать на LDR_DATA_TABLE_ENTRY другого списка, отсортированного в порядке размещения в памяти, ибо об этом написано в MSDN.
Собственно пруф:

Однако это не соответствует действительности!
На самом деле каждый LIST_ENTRY указывает на самого себя в следующей структуре, а не на её начало, таким образом:
- PEB_LDR_DATA.InLoadOrderModuleList.FLink указывает на LDR_DATA_TABLE_ENTRY.InLoadOrderLinks (+0 от начала LDR_DATA_TABLE_ENTRY)
- PEB_LDR_DATA.InMemoryOrderModuleList.FLink указывает на LDR_DATA_TABLE_ENTRY.InMemoryOrderLinks (+ sizeof(LIST_ENTRY) от начала LDR_DATA_TABLE_ENTRY)
- PEB_LDR_DATA.InInitializationOrderModuleList.FLink указывает на LDR_DATA_TABLE_ENTRY.InInitializationOrderLinks (+ sizeof(LIST_ENTRY) * 2 от начала LDR_DATA_TABLE_ENTRY)
Для чтения данных загрузчика наиболее удобным будет InLoadOrderModuleList.
function TLoaderData.Scan64LdrData(LdrAddr: ULONG_PTR64): Integer;
var
Ldr: PEB_LDR_DATA64;
Entry: LDR_DATA_TABLE_ENTRY64;
Module: TModuleData;
begin
Result := 0;
// читаем первичную структуру для определения начала списка
if not ReadRemoteMemory(FProcess, LdrAddr,
@Ldr, SizeOf(PEB_LDR_DATA64)) then
Exit;
LdrAddr := Ldr.InLoadOrderModuleList.FLink;
// крутим цикл, пока не встретим завершающую структуру
while (ReadRemoteMemory(FProcess, LdrAddr,
@Entry, SizeOf(LDR_DATA_TABLE_ENTRY64))) and (Entry.DllBase <> 0) do
begin
Module.ImageBase := Entry.DllBase;
Module.Is64Image := True;
SetLength(Module.ImagePath, Entry.FullDllName.Length shr 1);
if not ReadRemoteMemory(FProcess, Entry.FullDllName.Buffer,
@Module.ImagePath[1], Entry.FullDllName.Length) then
begin
LdrAddr := Entry.InLoadOrderLinks.FLink;
Continue;
end;
// ...
FModuleList.Add(Module);
LdrAddr := Entry.InLoadOrderLinks.FLink;
Inc(Result);
end;
end;Так выглядит цикл чтения данных из списка 64 битного PEB->Ldr. Очень просто и компактно, условие выхода состоит из проверки завершающей структуры в списке, у которой все поля равны нулю (в данном случае проверка идет только по полю Entry.DllBase).
Но это для 64 бит, с которым никаких проблем не будет, а вот с 32 битами все намного хитрее. Дело в том, что прямо сейчас нельзя нормально подгрузить список библиотек. Посмотрите самую первую картинку в начале главы, как вы думаете, откуда EnumProcessModulesEx брал информацию о модулях? Все верно, оттуда же откуда и мы сейчас, из списков загрузчика в удаленном процессе, и там, в этих списках для 32 битного PEB->Ldr все пути ведут к c:\windows\system32\ хотя по факту библиотеки грузятся совершенно по другому пути.
Как выкрутится из такой ситуации, будет показано в следующей главе, а сейчас, чтобы не мешать все в одну кучу, я покажу как можно решить эту проблему через применение небольшого костыля. Он нужен чтобы показать финальную работу класса, который был написан в этой главе и далее использоваться не будет.
Итак, код чтения списка 32 битного загрузчика (вместе с костылем) будет выглядеть вот так (целиком код приводить не буду, он похож на чтение 64 бит).
Потребуется вот такой вспомогательный костыль, проверяющий — является ли файл на диске 32 битным:
function IsFile32(const FilePath: string): Boolean;
var
DosHeader: TImageDosHeader;
NtHeader: TImageNtHeaders32;
Raw: TBufferedFileStream;
begin
Raw := TBufferedFileStream.Create(FilePath, fmShareDenyWrite);
try
Raw.ReadBuffer(DosHeader, SizeOf(TImageDosHeader));
Raw.Position := DosHeader._lfanew;
Raw.ReadBuffer(NtHeader, SizeOf(TImageNtHeaders32));
Result := NtHeader.FileHeader.Machine = IMAGE_FILE_MACHINE_I386;
finally
Raw.Free;
end;
end;а на место троеточия в коде выше встанет вот такой костыль:
// нюанс, 32 битные библиотеки в списке LDR будут прописаны с путем из
// дефолтной системной директории, хотя на самом деле они грузятся
// из SysWow64 папки. Поэтому проверяем, если SysWow64 присутствует
// то все 32 битные пути библиотек меняем на правильный посредством
// вызова GetMappedFileName + нормализация.
// Для 64 битных это делать не имеет смысла, т.к. они грузятся по старшим
// адресам куда не может быть загружена 32 битная библиотека, а по младшим
// мы и сами сможет прочитать данные из 32 битной сборки
if FUse64Addr then
begin
// GetMappedFileName работает с адресами меньше MM_HIGHEST_USER_ADDRESS
// если адрес будет больше - вернется ноль с ошибкой ERROR_INVALID_PARAMETER
if Module.ImageBase < MM_HIGHEST_USER_ADDRESS then
begin
MapedFilePathLen := GetMappedFileName(FProcess, Pointer(Module.ImageBase),
@MapedFilePath[1], MAX_PATH * SizeOf(Char));
if MapedFilePathLen > 0 then
Module.ImagePath := NormalizePath(Copy(MapedFilePath, 1, MapedFilePathLen));
end
else
begin
// а если адрес библиотеки выше допустимого, то будем делать костыль
// проверка, находится ли файл в системной директории?
if Module.ImagePath.StartsWith(Wow64Support.SystemDirectory, True) then
begin
// проверка, есть ли файл на диске и является ли он 32 битным?
if not (FileExists(Module.ImagePath) and IsFile32(Module.ImagePath)) then
begin
// нет, файл отсутствует либо не является 32 битным
// меняем путь на SysWow64 директорию
Module.ImagePath := StringReplace(
Module.ImagePath,
Wow64Support.SystemDirectory,
Wow64Support.SysWow64Directory, [rfIgnoreCase]);
// повторная проверка
if not (FileExists(Module.ImagePath) and IsFile32(Module.ImagePath)) then
// если в SysWow64 нет подходящего файла, чтож - тогда пропускаем его
// потому что мы его всеравно не сможем правильно подгрузить и обработать
Module.ImagePath := EmptyStr;
end;
end;
end;
end;Логика кода банальна, все что можно прочитать через штатный вызов GetMappedFileName, читаем через него (получая таким образом правильный путь к загруженной библиотеке).
Правда GetMappedFileName требует нормализации пути, т.к. возвращаемая им строка выглядит как "\Device\HarddiskVolume1\Windows\SysWOW64\ntdll.dll" и её надо привести в соответствие букве диска (но это мелочи).
А вот для всего что прочитать не получится, будет работать костыль, в котором будет проверка — действительно ли библиотека лежащая в c:\windows\system32\ является 32 битной, и если нет — то будет вторая проверка, а есть ли такая же, но уже в syswow64, и если есть — то путь меняется на «правильный».
Ну и теперь тестовый код:
var
Loader: TLoaderData;
// полученые адреса загрузчика передаем лоадеру списков
Loader := TLoaderData.Create(hProcess, IsWow64Mode);
try
Loader.Load32LoaderData(PEB32.LoaderData);
Loader.Load64LoaderData(PEB64.LoaderData);
Writeln(0, ': ', IntToHex(Loader.RootModule.ImageBase, 1), ' ', Loader.RootModule.ImagePath);
for var I := 0 to Loader.Modules.Count - 1 do
Writeln(I + 1, ': ', IntToHex(Loader.Modules[I].ImageBase, 1), ' ', Loader.Modules[I].ImagePath);
finally
Loader.Free;
end; 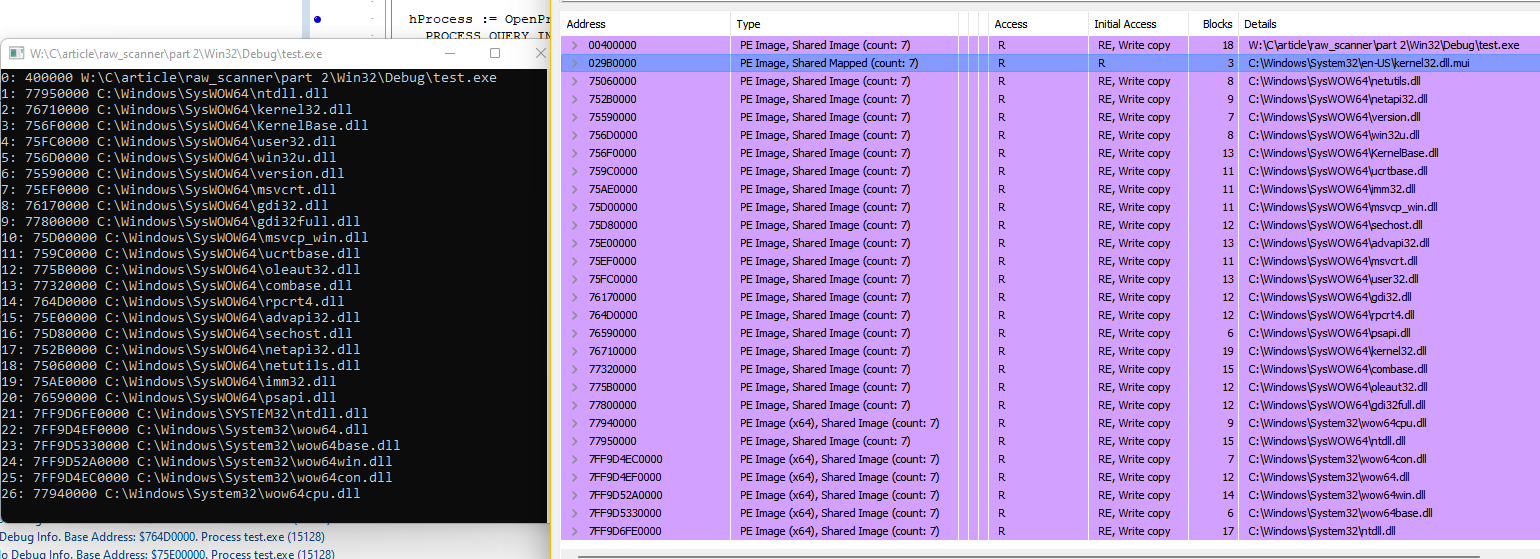
Результат совпал, код вывел все 27 модулей из списков загрузчика, пропустив только один загруженный C:\Windows\System32\en-US\kernel32.dll.mui
Но с ним как раз все нормально, т.к. данная библиотека не является исполняемой и отсутствует в списках загрузчика т.к. загружена с флагом LOAD_LIBRARY_AS_DATAFILE.
Код ко второй главе для самостоятельного изучения доступен по этой ссылке.
А теперь пришло время разбираться с костылем при чтении данных из 32 битного загрузчика
3. Вызов 64 битного кода из 32 битного контекста
Итак, еще раз напомню основной тезис второй главы: в 64 битной OS нет 32 битных процессов. Есть только строго 64 битные, а вся 32 битность эмулируется посредством WOW64 подсистемы.
Когда вы вызываете какую-либо API из своего 32 битного кода, управление ей передается не напрямую — происходит этап конвертации параметров в формат, который требует 64 битный аналог этой API и её прямой вызов.
Что за конвертация: тут все заключается в соглашении о вызовах. Как правило это STDCALL который в 32 битах требует передачи всех параметров через стэк, а вот в 64 битах STDCALL работает немного по-другому, а именно он похож на вызов с соглашением FASTCALL, где первые четыре параметра идут через регистры (RCX/RDX/R8/R9) а остальные через стек.
Microsoft x64 calling convention
Но есть нюанс, напрямую вызвать 64-битный аналог нельзя. Дело в том, что любой 32 битный код и 64 битный исполняются в разных контекстах!
Если вы откроете свой отладчик и перейдете в режим ассемблера, то увидите, что селектор сегмента кода CS будет равен 0х23 (для 32 битного приложения), а если мы будем отлаживать 64 битное приложение, то контекст станет равен 0x33.
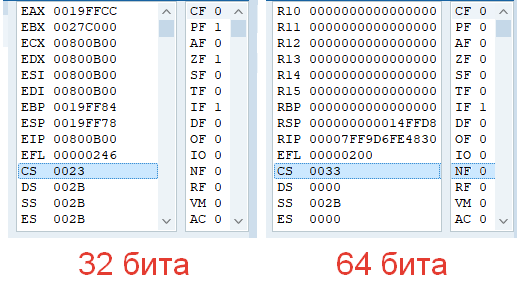
В зависимости от операционной системы такое переключение контекста делается разными способами, но все в итоге приходит к одному — вызову одной из этих инструкций
- JMP FAR 0x33:addr
- CALL FAR 0x33:addr
- PUSH 0x33 + PUSH addr + RETF
Давайте посмотрим все это на примере вызова функции NtQueryVirtualMemory() вызываемой в Windows 8.1 (на Windows 10 и выше картинка будет немного другая, но суть в итоге не изменится).
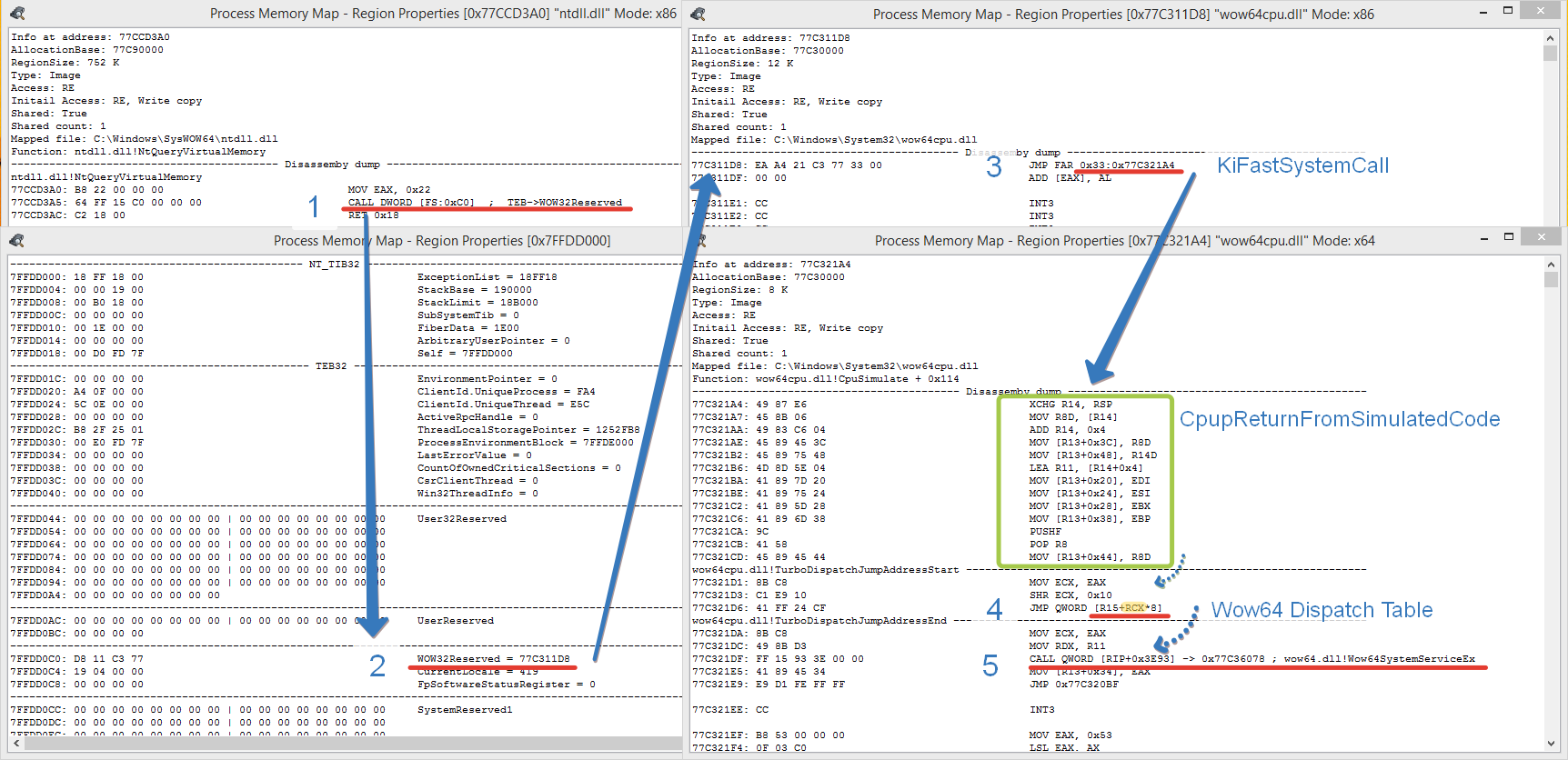
По шагам:
Функция начинается с инициализации регистра EAX некоей константой 0х22. Это так называемый SDT индекс (порядковый номер в таблице системных вызовов, или в оригинале — System Service Dispatch Table).
Ну точнее как, на самом деле SDT индекс занимает только младшее слово (16 бит), а вот старшее уже является вторым индексом для WDT (специальная таблица диспетчеризации Wow64 вызовов, о ней чуть позже).
Следующим шагом происходит вызов через сегмент FS с адресом 0xC0.
Cегмент FS в случае 32 битного кода всегда указывает на структуру Thread Environment Block (TEB), т.н. блок окружения потока (в 64 битах за это отвечает GS), а адрес 0xC0 указывает на смещение в этой структуре от её начала.
В MSDN полноценной документации по этой структуре вы не найдете, но (внезапно) она достаточно хорошо документирована в википедии:
Win32 Thread Information Block
Эта структура создается для каждого потока вашего приложения, причем в случае 32 битного приложения на 64 битной Windows, создается в двух экземплярах (32 и 64 бита соответственно).
Содержит кучу полезных для работы полей, допустим самое первое поле 32 битного TEB это указатель на верхушку SEH фреймов (текущей цепочки обработчиков исключений), через TEB реализованы все threadvar (точнее через поле TLS слотов) и прочее-прочее… Сейчас нас интересует поле Wow32Reserved, на которое указывает оффсет 0хС0, которое содержит в себе адрес функции KiFastSystemCall, состоящей из одной единственной инструкции JMP FAR
Инструкция KiFastSystemCall, выглядящая как JMP FAR 0x33:0x77C331A4 производит переключение селектора сегмента кода CS в 64 битный режим с выставлением значения 0х33 и передает управление на 64 битный код, в функцию CpupReturnFromSimulatedCode.
Не удивляйтесь такому странному названию функции, как я и говорил — в 64 битной Windows нет 32 битных процессов и эта функция означает что мы вернулись в родную среду из эмуляции 32 бит.
CpupReturnFromSimulatedCode, производит переключение на 64 битный стек и сохраняет состояние части регистров в CPUCONTEXT, после чего происходит передача управления функции TurboDispatchJumpAddressStart().
Именно в этой функции и происходит работа с старшей частью регистра EAX, которая была установлена еще на самом первом этапе.
Если вкратце — эта константа (старшая часть — на картинке выделена оранжевым) является индексом в т.н. Wow64 Dispatch Table (WDT) на которую указывает регистр R15. Комбинацией этих двух регистров (R15 + старшая часть EAX, перемещенная в ECX) из данной таблицы выбирается адрес обработчика, которому и передается управление (конвертация 32 битных параметров для вызова 64 битного аналога функции).
Точнее как, сама функция TurboDispatchJumpAddressEnd это такая большая вершимель кода обрабатывающая параметры вызываемой функции тем или иным способом, а вот WDT это в общем приближении аналог некоей таблицы switch-case которая располагается (как правило) чуть выше директории экспорта.
Если подгрузить отладочные символы, то можно увидеть имена обработчиков, вот я тут выписал несколько из них, чтобы было общее представление что каждый из них делает:
ServiceNoTurbo — расположен в самом начале TurboDispatchJumpAddressEnd (хэндлер по умолчанию для большинства вызовов)
Thunk0Arg
Thunk0ArgReloadState
Thunk1ArgSp
Thunk1ArgNSp
Thunk2ArgNSpNSp
…
Thunk4ArgSpNSpNSpNSpReloadState
Thunk4ArgNSpSpNSpNSp
Thunk4ArgSpSpSpNSp
ThunkNone — конец таблицы диспатча, прямой переход на INT3
Сам же SDT индекс NtQueryVirtualMemory содержится в младшей части этой некоей константы и равен он 0х22 — именно с этими параметрами и будет произведет вызов в ядро, что будет соответствовать своему 64 битному аналогу.
Конкретно для текущего вызова NtQueryVirtualMemory WDT индекс равен нулю, поэтому посредством таблицы диспетчеризации произойдет передача управления на хэндлер ServiceNoTurbo в результате чего будет произведен вызов Wow64SystemServiceEx.
Для справки: В Windows 10 и выше часть этих шагов изменена, в частности вызов через TEB заменен на аналогичную ему цепочку вызовов Wow64SystemServiceCall -> KiFastSystemCall, причем KiFastSystemCall теперь передает управление не напрямую в CpupReturnFromSimulatedCode, а определяет её адрес через WDT (такая вот оптимизация, видимо в будущем будут еще расширять).
И вот примерно такая же обвязка сделана для каждой 32-битной API функции, в том числе и для GetMappedFileName (а если точнее для NtQueryVirtualMemory которую она использует для своей работы).
Но минус в том, что все эти обработчики из WDT знают, что их вызвали из 32 битного кода, а стало быть, они точно знают, что 64 битные указатели к ним прийти не могут.
А задача стоит, напомню (для решения проблемы, описанной во второй главе) вызвать полноценный 64 битный аналог функции (именно NtQueryVirtualMemory), передав в неё полноценный 64 битный указатель.
Вообще NtQueryVirtualMemory будет в этой статье эдаким краеугольным камнем, вокруг которого все вертится. Она будет применяться для реализации следующих альтернатив (имеется ввиду функции, чьи 64 битные аналоги будут вызываться из 32 бит напрямую):
- VirtualQueryEx — реализуется через вызов NtQueryVirtualMemory с флагом MemoryBasicInformation (равным нулю)
- QueryWorkingSet — то же, только флаг MemoryWorkingSetList (равный единице)
- GetMappedFileName — то же, только флаг MemoryMappedFilenameInformation (равный двойке)
А сейчас надо разобраться с нюансами вызова 64 битных функций и по сути написать аналог Wow64SystemServiceEx (не полноценный, конечно, но аналог).
Итак, так как нельзя использовать вызов через TEB посредством сегмента FS (по причине что там ждут 32 битный указатель), нужно как-то определить адрес 64 битной функции в адресном пространстве нашего процесса.
Это уже можно сделать, так как:
- известен способ, как получить адрес 64 битной NTDLL (код из второй главы)
- известен способ, как получить адрес экспортируемой библиотекой функции (код из первой главы)
1. Нужно контролировать стек. В 32 битах стек выравнивается по границе 4 байт, а вот в 64 битах он выровнен по границе 8 байт, поэтому перед передачей управления 64 битной функции нужно удостоверится в том что регистр ESP содержит правильное значение (грубо ESP mod 8 = 0).
Строго говоря, нужно контролировать значения двух регистров ESP + EBP, но из-за особенностей формирования 64 битного стекового фрейма, достаточно будет проконтролировать только ESP, т.к. его значение будет передано в конечном итоге в RBP и оба регистра будут содержать уже выровненные значения.
2. Контролировать размеры теневого пространства (ShadowSpace), используемого для сброса регистров RCX/RDX/R8/R9. Данная область должна быть всегда выделена на стеке перед вызовом любой 64 битной stdcall функции, даже в случае, когда она принимает меньшее количество параметров. В случае если количество параметров больше четырех, размер ShadowSpace расширяется на их размер.
3. Перевести 32 битные параметры, лежащие на стеке (из-за соглашения STDCALL) в требуемый формат 64 битного вызова.
NtQueryVirtualMemory имеет шесть параметров: NtQueryVirtualMemory function
Первые 4 параметра должны будут идти в регистрах RCX/RDX/R8/R9, остальные будут размещены на стеке, причем изначально все шесть параметров будут лежать на 32 битном стеке с оффсетом в 4 байта, а вот при переносе последних двух на 64 битный стек, нужно учитывать что они должны располагаться уже с учетом 8 байтного выравнивания.
4. Если нам нужно передать значения через регистры, можно воспользоваться стандартными EAX/EBX/ECX/EDX/ESI/EDI которые после переключения в 64 битный код преобразуются к RAX/RBX/RCX/RDX/RSI/RDI. Тоже будет работать и при обратном переключении, за исключением что старшие 32 бита каждого регистра будут отрезаны, т.е. мы сможем вытащить только младшую часть значения 64 битных регистров (а больше нам и не надо).
5. 8 байтовый 64 битный результат вполне укладывается в размер регистра RAX, но для передачи его в 32 бита нужно использовать пару EAX+EDX где EDX должен содержать старшие 32 бита RAX.
На этом список требований закончился, можно начинать писать код. Заголовок функции будет выглядеть так:
function NtQueryVirtualMemory64(FuncRVA: ULONG_PTR64; hProcess: THandle;
BaseAddress: ULONG_PTR64; MemoryInformationClass: DWORD;
MemoryInformation: Pointer; MemoryInformationLength: DWORD;
ReturnLength: PULONG64): NTSTATUS; assembler; stdcall;
asm
end;К списку параметров добавился адрес функции (первый параметр), остальные без изменения и соответствуют параметрам оригинальной функции.
Думаю, с первым параметром все понятно — это адрес на который мы должны передать управление в 64 битном коде, и он равен реальному адресу NtQueryVirtualMemory в 64 битной NTDLL.
Обратите внимание что первый и третий параметр объявлены как ULONG_PTR64. Это восьмибайтный тип, именно он будет заменять 64 битные указатели в 32 битном коде.
Декларация соглашения stdcall (и наличие хотя бы одного параметра) заставит Delphi сгенерировать пролог и эпилог функции, используя который будет удобно обработать пункт первый из необходимых действий, а именно коррекцию стека по восьмибайтной границе. Если прямо сейчас вызвать эту заглушку функции, то пролог и эпилог (в CPU) будут выглядеть следующим образом:
asm
// этот код будет сгенерирован Delphi автоматически
// ... пролог ...
push ebp // сохраняется база предыдущего стекового кадра
mov ebp, esp // инициализация базы новой верхушкой стека начинает таким образом новый стековый кадр
// ... и эпилог ...
pop ebp // восстановление базы предыдущего стекового кадра
ret $24 // возврат с коррекцией верхушки стека (ESP) 0х24 = пять параметров по 4 байта + 2 параметра по 8 байт
end;Следующий шаг — добавляем контроль выравнивания 32 битного стека по границе 8 байт:
mov eax, esp // берем текущее значение Stack Pointer
and eax, 7 // нас интересует значение младших трех бит, отсекаем все лишнее
cmp eax, 0 // проверяем - равно ли получившееся число нулю?
je @stack_aligned
// если не равно, тогда стек не выровнен, в EAX будет оффсет от ESP на сколько
// сдвинулись данные в 32-битном стеке после правки значения ESP
sub esp, eax
@stack_aligned:
// отсюда работаем с выровненным по границе 8 байт стекомВажный нюанс, т.к. декларация stdcall, все параметры функции в текущий момент расположены на 32 битном стеке. Но т.к. мы выполняем коррекцию верхушки стека, необходимо знать на какое значение была произведена эта коррекция, чтобы потом из ESP/RSP получить правильные параметры. Именно за это и отвечает регистр EAX, который будет содержать в себе либо ноль (означающий что коррекция не производилась) либо другое число (должна быть четверка, но это не всегда обязательно). Конечно, можно было бы использовать регистр EBP как фиксированную точку, но нам предстоит переход в 64 битный режим, где также потребуется сформировать стековый фрейм, а он будет расположен относительно актуального значения ESP/RSP, так что EBP не подойдет.
Чтобы было более понятно, то после контроля выравнивания стека будет одно из двух состояний:

Т.е. либо стек УЖЕ был выровнен и тогда коррекция значения ESP не требуется, и оно будет равно значению EBP. Либо второй вариант — была произведена коррекция и значение ESP стало меньше EBP на какое-то значение (обычно на 4).
Главное тут понимать — 64 битный стек начнется ПОСЛЕ ESP, не важно, была подвижка его значения или нет.
Теперь следующий шаг — переключение в 64 битный режим:
push $33 // пишем новый сегмент кода
db $E8, 0, 0, 0, 0 // call +5
add [esp], 5 // правим адрес возврата на идущий за retf
retf // дальний возврат со сменой сегмента кода на CS:0х33 + адрес
// начиная отсюда мы в 64 битном режиме!!!Данный код рассмотрим более подробно. Ключевой функцией здесь является RETF, именно она переключает сегментный селектор CS и передает управление на указанный адрес, причем оба этих значения должны быть расположены на стеке. И очень важный момент — она всегда работает с блоком строго 8 байт (сегмент+адрес), не важно из какого режима происходит вызов, из 32 бит или из 64.
Выглядит это следующим образом, допустим ESP у нас изначально равнялся 0x100 (для простоты)
- push $33 — этим мы разместили 4 байта на стеке с новым значением селектора сегмента, при этом верхушка стека уменьшилась на эти 4 байта (ESP = 0xFC)
- call +5 — (вызов реализован в виде опкодов, т.к. дельфи не позволяет написать такую инструкцию прямо в коде), данная инструкция размещает на стеке 4 байта в качестве адреса возврата, т.е. куда должно вернуться управление после завершения вызова, и переходит непосредственно на этот адрес (т.е. сдвигает регистр EIP ровно на указанные 5 байт, которые равны длине этой инструкции). Таким образом у нас на стеке лежат уже два числа, первое с контекстом, второе содержит адрес инструкции add (стек теперь равен ESP = 0xF8)
- add [esp], 5 — увеличивает значение адреса возврата на стеке, размещенное предыдущим вызовом на пять байт. Пять байт — это общая длина инструкций add[] (4 байта) и retf (1 байт), таким образом адрес размещенный на стеке изменился на адрес следующей инструкции после RETF (регистр ESP не изменился и остался равен ESP = 0xF8)
- retf — переключает селектор сегмента кода на значение расположенное по адресу [ESP + 4] и передает управление на адрес на который указывает [ESP], при этом увеличивает значение регистра ESP на использованные в качестве параметров 8 байт (в итоге вершина стека стала равной изначальному значению, ESP/RSP = 0x100)
Впрочем (для отладки) можно взять 64 битный WinDbg — он умеет работать с кодом, который прыгает из 32 бит в 64 и обратно.
Теперь приступаем ко второму этапу, переводу параметров, расположенных на 32 битном стеке в их 64 битный аналог и пишем уже 64 битный код.
Для начала сформируем 64 битный стековый кадр:
push ebp // push rbp
db $48 sub esp, $30 // sub rsp, $30
db $48 mov ebp, esp // mov rbp, rspВот тут такой… тонкий момент. Обратите внимание что я пишу вроде бы 32 битные инструкции, однако, так как в текущий момент этот код будет исполнятся в 64 битном режиме, то и интерпретироваться эти инструкции будут именно как 64 битные, в комментарии справа указано что именно будет выполнять процессор в этот момент. Единственный момент, это наличие префикса перед второй и третьей инструкцией ввиде db $48.
Это так называемый REX префикс. Грубо говоря, каждая инструкция — это набор опкодов выглядящих как префикс + опкод + ModRM + SIB ну и далее…
Вот поле ModRM у каждой инструкции (где оно присутствует) используется для 32 битной адресации, а REX префикс позволяет эту адресацию расширить. Если убрать REX префикс то в 64 битном коде эти инструкции будут трактоваться абсолютно так-же как и в 32 битном, т.е. работа будет с регистрами ESP + EBP, а не RSP + RBP. И хотя сейчас эти регистры содержат реально 32 битные значения, лучше писать все-же правильно (во избежание).
Можно конечно было их написать прямо через опкоды (DB/DW/DD) но такой вариант реализации мне показался более удобным.
Ну и если вернуться к стековому кадру — его наличие обязательно, т.к. согласно спецификации, не смотря на то что часть из шести параметров у вызываемой 64 битной NtQueryVirtualMemory пойдет через регистры, мы обязаны выделить под них место на стеке (т.н. ShadowSpace), этим и обусловлено наличие инструкции sub rsp, $30 (0х30 = 6 параметров * 8 байт).
Следующим шагом получим адрес последнего параметра, расположенного на 32 битном стеке, а именно ReturnLength и тут нам потребуется немного математики.
Смотрите на картинку выше, ReturnLength изначально располагался по адресу EBP + 0x28.
Сам EBP равен значению ESP + коррекция в регистре EAX, т.е. ReturnLength = ESP + EAX + 0x28;
Дальше, мы поместили на стек значение RBP изменив регистр RSP (в который он преобразовался из ESP после переключения контекста) ровно на 8 байт, после чего зарезервировали место на 64 битном стеке еще под шесть восьмибайтных параметров. Добавляем эти 8 байт + 6 * 8 (всего 0x38) к константе, получается вот такой адрес — RSP + RAX + 0x60:
db $48 lea eax, [esp + eax + $60] // lea rax, [rsp + rax + $60]Получив правильный адрес параметров на 32 битном стеке, переносим последние два (ReturnLength + MemoryInformationLength) на 64 битный:
// 1. ReturnLength
mov ecx, [eax] // mov ecx, dword ptr [rax]
db $48 mov [esp + $28], ecx // mov [rsp + $28], rcx
// 2. и размер данных "MemoryInformationLength"
mov ecx, [eax - 4] // mov ecx, dword ptr [rax - 4]
db $48 mov [esp + $20], ecx // mov [rsp + $20], rcxСмотрите, под 64 битные параметры зарезервировано 0х30 байт, ReturnLength самый последний, значит он должен быть расположен в последних восьми байтах, т.е. диапазон от 0x28 до 0x30.
Предпоследним на стек пойдет MemoryInformationLength со смещением 0x20 от начала зарезервированного стека.
И на этом со стеком все — осталось перенести оставшиеся 4 параметра в соответствующие регистры:
// регистр R9 содержит указатель на память (MemoryInformation),
// куда будет помещаться результат
db $44 mov ecx, [eax - 8] // mov r9d, dword ptr [rax - 8]
// регистр R8 содержит идентификатор MemoryInformationClass
db $44 mov eax, [eax - $C] // mov r8d, dword ptr [rax - $С]
// регистр RDX содержит BaseAddress
db $48 mov edx, [eax - $14] // mov rdx, [rax - $14]
// RCX должен содержать hProcess
mov ecx, [eax - $18] // mov ecx, dword ptr [rax - $18]Обратите внимание что все параметры за исключением BaseAddress имеют размер 32 бита поэтому читаются именно как dword ptr[], при этом когда идет запись в регистр ECX (являющийся младшей частью RCX) старшая часть регистра RCX очищается. В этом большое отличие от работы с младшими частями регистра ECX, где при изменении CX/CL/CH старшая часть остается на месте.
На текущий момент можно сказать, что выполнены все те-же самые подготовительные действия, которые выполняется в функции Wow64SystemServiceEx, поэтому раз все готово, настал момент вызова 64 битной NtQueryVirtualMemory:
call [eax - $20] // call [rax - $20]Всё! Функция выполнилась, результат выполнения будет размещен в регистре RAX, который после переключения в 32 битный режим преобразуется в EAX, таким образом будет содержать в себе результат выполнения 64 битной функции и нам не нужно делать лишних телодвижений.
Для возврата результата функции здесь в принципе будет достаточно того, что вернется в регистре RAX, но чтоб быть последовательным все же желательно выполнить правильное преобразование в регистровую пару, которую будет требовать 32 битный код в случае, если будет возвращаться восьмибайтное значение:
db $48 mov edx, eax // mov rdx, rax
db $48, $C1, $EA, $20 // shr rdx, $20Младшая часть регистра RAX при переходе в 32 битный режим преобразуется в значение регистра EAX, а старшая часть, после этих двух строк будет перемещена в регистр EDX откуда его заберет вызываемый код (если это потребуется). Правда Delphi не позволяет записать инструкцию SHR в нормальном виде, поэтому она объявлена как набор опкодов.
Осталось только подчистить за собой:
db $48 lea esp, [ebp + $30] // lea rsp, [rbp + $30]
pop ebp Этими двумя строчками схлопывается 64 битный стековый кадр, он больше не нужен и можно переключаться обратно в 32 бита:
db $E8, 0, 0, 0, 0 // call +5
mov [esp + 4], $23 // mov dword ptr [rsp + 4], $23
add [esp], $0D // add dword ptr [rsp], $0D
retf // дальний возврат со сменой сегмента кода на CS:0х23 + адрес
// начиная отсюда мы опять в 32 битном режимеВыход выглядит практически идентично коду входа, за исключением одного момента. Т.к. вызов CALL происходит в 64 битном режиме, на стек сразу помещаются 8 байт и дополнительного PUSH уже не требуется, достаточно будет поправить только текущие значение, а именно [ESP + 4] теперь должен быть равен 0x23 а адрес возврата [ESP] нужно увеличить на 13 байт (длинна трех инструкций mov + add + retf)
Не стоит боятся того, что после вызова CALL на стек изначально был размещен 8 битный указатель, т.к. он расположен в 32 битном участке кода старшие 32 бита (в которых расположен селектор) будут гарантировано равны нулю и их можно смело использовать.
Теперь надо убрать возможные последствия коррекции верхушки стека, выставив регистру ESP значение равное EBP:
mov esp, ebpЭто всё — дальше отработает эпилог функции, который подчистит все что осталось и вернет управление вызывающему коду.
Теперь можно увидеть, как выглядит функция целиком. Я специально её оставил в таком виде чтобы можно было её наглядно «пощупать» в отладчике.
В следующих главах вместо данной функции будет использоваться уже функция для автогенерации гейта, которая будет формировать динамически примерно такой-же код, как описано выше, только немного оптимизированный (с использованием JMP FAR и прямого CALL) и автоматически производить конвертацию 32 битных параметров в зависимости от их количества (т.е. её можно применять для генерации переходного гейта при вызове любой 64 битной функции с соглашением STDCALL, главное правильно указать количество и размеры её параметров и адрес).
Все что было описано выше имеет даже название (не я придумал) — Heavens Gate :)
Почему именно так, кто придумал и главное зачем — вопрос не ко мне.
Впрочем, это был только первый шаг, теперь настало время применить эту функцию к коду из предыдущей главы чтобы убрать «костыль» и реализовать правильное определение пути загруженной библиотеки по её инстансу.
Один из нюансов работы с таким прямым вызовом 64 битной функции — это то, что адрес буфера, в который функция пишет MemoryInformation, всегда должен быть выровнен по границе 8 байт, поэтому чтобы не забывать о таком нюансе проще сразу написать универсальную обертку. Выглядеть она будет вот так:
function GetMappedFileName64(hProcess: THandle; lpv: ULONG_PTR64;
lpFilename: LPCWSTR; nSize: DWORD): DWORD;
...
begin
{$IFDEF WIN32}
Result := 0;
if NtQueryVirtualMemoryAddr <> 0 then
begin
// структура TMappedFileName должна быть выровнена по 8-байтной границе
// поэтому стек не используем, а выделяем принудительно
MappedFileName := VirtualAlloc(nil,
SizeOf(TMappedFileName), MEM_COMMIT, PAGE_READWRITE);
try
Status := NtQueryVirtualMemory64(NtQueryVirtualMemoryAddr, hProcess, lpv,
MemoryMappedFilenameInformation, MappedFileName,
SizeOf(TMappedFileName), @ReturnLength);
if not NT_SUCCESS(Status) then
begin
BaseSetLastNTError(Status);
Exit(0);
end;
nSize := nSize shl 1;
cb := MappedFileName^.ObjectNameInfo.MaximumLength;
if nSize < cb then
cb := nSize;
Move(MappedFileName^.FileName[0], lpFilename^, cb);
if cb = MappedFileName^.ObjectNameInfo.MaximumLength then
Dec(cb, SizeOf(WChar));
Result := cb shr 1;
finally
VirtualFree(MappedFileName, SizeOf(TMappedFileName), MEM_RELEASE);
end;
end
else
{$ENDIF}
Result := GetMappedFileName(hProcess, Pointer(lpv), lpFilename, nSize);
end;Этот код практически один в один повторяет реализацию GetMappedFileName, только использует вызов NtQueryVirtualMemory64 для 32 бит, в случае если снаружи был назначен её адрес.
Теперь можно подправить код в функции TLoaderData.Scan32LdrData удалив оттуда код «костыля» и заменив его на вот такой вызов:
if FUse64Addr then
begin
MapedFilePathLen := GetMappedFileName64(FProcess, Module.ImageBase,
@MapedFilePath[1], MAX_PATH * SizeOf(Char));
if MapedFilePathLen > 0 then
Module.ImagePath := NormalizePath(Copy(MapedFilePath, 1, MapedFilePathLen));
end;Последним шагом осталось инициализировать переменную, содержащую адрес 64 битной NtQueryVirtualMemory, это делается вот таким кодом, который должен быть вызван перед работой со списками загрузчика из второй главы:
if IsWow64Mode then
begin
LocalLoader := TLoaderData.Create(hProcess, True);
try
if LocalLoader.Load64LoaderData(PEB64.LoaderData) > 0 then
for var Module in LocalLoader.Modules do
begin
if ExtractFileName(Module.ImagePath).ToLower = 'ntdll.dll' then
begin
Wow64Support.DisableRedirection;
try
NtDll := TRawPEImage.Create(Module.ImagePath, Module.ImageBase);
try
Index := NtDll.ExportIndex('NtQueryVirtualMemory');
if Index >= 0 then
SetNtQueryVirtualMemoryAddr(NtDll.ExportList.List[Index].FuncAddrVA);
finally
NtDll.Free;
end;
finally
Wow64Support.EnableRedirection;
end;
Break;
end;
end;
finally
LocalLoader.Free;
end;
end;Задача данного кода:
- через 64 битный список загрузчика определить инстанс NTDLL
- загрузить её и получить адрес NtQueryVirtualMemory
- назначить этот адрес служебной переменной
Код к третьей главе для самостоятельного изучения доступен по этой ссылке.
4. Обработка Forward деклараций и анализ таблиц экспорта
Перед тем как приступить к следующему шагу нужно выполнить некоторые подготовительные действия, чтобы потом на них не отвлекаться.
Первым делом, весь код из test.dpr предыдущей главы, уходит в новый класс TRawScanner, задача которого выполнить подготовительные действия (создать нужные классы и выполнить инициализацию адреса 64 битной NtQueryVirtualMemory). Этот класс будет входной точкой, через которую будет вестись вся остальная работа с кодом (для удобства).
А также нужно сделать класс контейнер TRawModules, который будет хранить в себе список TRawPEImage и предоставлять методы для работы с ними.
Шлюз для вызова 64 битной NtQueryVirtualMemory заменен на универсальный гейт, его код я рассматривать не буду, он просто более оптимизирован по сравнению с кодом шлюза из предыдущей главы и выполняет всю рутинную работу по подготовке среды окружения и конвертации параметров автоматически.
У центрального TRawScanner будет, помимо конструктора и деструктора, всего один основной метод InitFromProcess(PID), а также несколько свойств.
- свойство Modules — которое будет представлять из себя класс TRawModules
- свойство Analizer — новый класс анализатора, который будет реализован в этой главе.
TRawModules = class
private
FItems: TObjectList;
FIndex: TDictionary;
FImageBaseIndex: TDictionary;
...
public
function AddImage(const AModule: TModuleData): Integer;
procedure Clear;
function GetModule(AddrVa: ULONG_PTR64): Integer;
function GetProcData(const LibraryName, FuncName: string; Is64: Boolean;
var ProcData: TExportChunk; CheckAddrVA: ULONG_PTR64): Boolean; overload;
function GetProcData(const LibraryName: string; Ordinal: Word;
Is64: Boolean; var ProcData: TExportChunk; CheckAddrVA: ULONG_PTR64): Boolean; overload;
function GetProcData(const ForvardedFuncName: string; Is64: Boolean;
var ProcData: TExportChunk; CheckAddrVA: ULONG_PTR64): Boolean; overload;
property Items: TObjectList read FItems;
end;Для реализации быстрой работы функций GetModule и GetProcData используется два словаря:
- FIndex — словарь с ключом по имени библиотеки
- FImageBaseIndex — словарь с ключом по hInstance библиотеки
Делается это при помощи API QueryWorkingSet. Суть метода заключается в следующем, когда выделяется память, каждая страница памяти подгружается в общий пул, так называемый WorkingSet представляющий из себя список виртуальных страниц которые отображены на адресное пространство процесса (утрированно, находящихся в физической памяти, и хотя это не совсем так, но близко), где помимо адреса каждой страницы этот пул содержит информацию о текущих атрибутах защиты страницы (Protection), флаг — является ли страница доступной для совместного использования (Shared), а также количество процессов, совместно использующих данную страницу в текущий момент времени (SharedCount).
Когда процесс загружает библиотеку, для большинства из них (т.н. knowndlls) этап чтения образа библиотеки с диска пропускается и библиотека мапится в адресное пространство процесса как сегмент, ну это что-то типа кэширования для ускорения работы. И все страницы памяти, выделенные под библиотеку, помечаются как общедоступные, т.е. одну и туже страницу (но только в режиме чтения) может использовать несколько процессов одновременно.
В случае если грузится обычная библиотека (ну, например, разработанная вами самостоятельно) в этом случае уже идет её реальное чтение с диска, НО даже после этого, все её страницы помечаются как общедоступные.
Так вот, как только будет произведена попытка записи в любую из общедоступных страниц, будет создана копия этой страницы и все изменения будут отображены только в данной копии, а сама страница конечно будет отсоединена от механизма совместного использования, со сбросом флагов Shared и SharedCount. Вот именно это и будет определяться в качестве подстраховки.
Вообще (в качестве справочной информации) QueryWorkingSet достаточно часто используется в антиотладке, позволяя помимо определения изменений страниц памяти детектировать работу сканеров памяти, которые не производят изменений, а просто ищут что-то в нашем процессе.
Делается такой детектор в два этапа:
- Выделяется контрольная страница через VirtualAlloc и её адрес где-либо сохраняется.
- Далее производится сброс ворксета вызовом SetProcessWorkingSetSize с указанием вторым и третьим параметров значения «SIZE_T(-1)»
Теперь к реализации — эта функция работает через представленную в предыдущей главе NtQueryVirtualMemory64 передавая ей в качестве флага MemoryWorkingSetList равный единице. Если вызовать QueryWorkingSet из 32 битного кода, то результатом будет информация только по страницам памяти доступным из 32 бит (до лимита в MM_HIGHEST_USER_ADDRESS), а так как анализатор интересует полный диапазон страниц, то вызывать нужно именно её 64 битный аналог (точнее 64 битную NtQueryVirtualMemory).
Нюанс с вызовом NtQueryVirtualMemory64 в том что т.к. это 64 битная функция, то и все адреса, которые она принимает на вход, должны соответствовать значениям, которые может принять 64 битный указатель, т.е. все эти адреса должны быть выравнены по границе 8 байт, в противном случае NtQueryVirtualMemory64 вернет STATUS_DATATYPE_MISALIGNMENT. Чтобы не забыть про этот нюанс и не контролировать каждый вызов используется промежуточная обертка:
{$IFDEF WIN32}
function InternalNtQueryVirtualMemory64(FuncRVA: ULONG_PTR64; hProcess: THandle;
BaseAddress: ULONG_PTR64; MemoryInformationClass: DWORD;
MemoryInformation: Pointer; MemoryInformationLength: DWORD;
ReturnLength: PULONG64): NTSTATUS;
var
AlignedBuff: Pointer;
begin
AlignedBuff := VirtualAlloc(nil,
MemoryInformationLength, MEM_COMMIT, PAGE_READWRITE);
try
Result := NtQueryVirtualMemory64(FuncRVA, hProcess, BaseAddress,
MemoryInformationClass, AlignedBuff, MemoryInformationLength,
ReturnLength);
Move(AlignedBuff^, MemoryInformation^, MemoryInformationLength);
finally
VirtualFree(AlignedBuff, MemoryInformationLength, MEM_RELEASE);
end;
end;
{$ENDIF}Внутри данной обертки нет проверки результата и AlignedBuff всегда копируется в результирующий буфер MemoryInformation.
Дело в том, что штатными кодами ошибок для этой функции, помимо STATUS_SUCCESS является допустим и STATUS_INFO_LENGTH_MISMATCH, который означает что не хватает размера выделенного буфера, при этом требуемый размер будет размещен в AlignedBuff и его нужно вернуть вызывающему коду.
Сама же реализация функции выглядит вот так:
function QueryWorkingSet64(hProcess: THandle; pv: Pointer; cb: DWORD): Boolean;
{$IFDEF WIN32}
const
MemoryWorkingSetList = 1;
var
Status: NTSTATUS;
{$ENDIF}
begin
{$IFDEF WIN32}
// если мы в чистой 32 битной ОС то просто производим 32 битный вызов
// с перекидыванием результата в массив с 64 битными адресами
if not Wow64Support.Use64AddrMode then
begin
Result := QueryWorkingSet32(hProcess, pv, cb);
Exit;
end;
// в противном случае нам нужен полный WorkSet с 64 битными страницами
if Assigned(NtQueryVirtualMemory64) then
begin
Status := InternalNtQueryVirtualMemory64(
hProcess, 0, MemoryWorkingSetList, pv, cb, nil);
if NT_SUCCESS(Status) then
Exit(True);
end;
Result := False;
{$ELSE}
Result := QueryWorkingSet(hProcess, pv, cb);
{$ENDIF}
end;В ней вначале идет проверка, если мы находимся под чистой 32 битной ОС, то происходит вызов функции QueryWorkingSet32, которая делает вызов нативной QueryWorkingSet с преобразованием результата вызова в массив 64 битных указателей.
В противном случае вызываем NtQueryVirtualMemory64 с флагом MemoryWorkingSetList.
С подготовительными действиями закончили, пришло время писать код анализатора. В новом модуле RawScanner.Analyzer пишем класс:
TPatchAnalyzer = class
private
...
function CheckPageSharing(AddrVa: ULONG_PTR64;
out SharedCount: Byte): Boolean;
protected
procedure DoModifyed(HookData: THookData);
procedure InitWorkingSet;
procedure ScanExport(Index: Integer; Module: TRawPEImage);
procedure ScanModule(Index: Integer);
public
constructor Create(AProcessHandle: THandle; ARawModules: TRawModules);
destructor Destroy; override;
function Analyze(
AProcessTableHook: TProcessTableHookCallBack;
AProcessCodeHook: TProcessCodeHookCallBack): TAnalizeResult;
end;Полностью его рассматривать я не буду, опишу только общий принцип и узкие моменты.
В конструктор класса приходит хэндл открытого процесса и список модулей для анализа (подготовленный классом TRawScanner). Хэндл потребуется для работы QueryWorkingSet64, ну а список — именно по нему и будет идти анализ.
Единственным методом доступным снаружи является функция Analyze, которая параметрами принимает два калбэка реализованных во внешне коде, и именно они будут вызываться в том случае, если анализатор обнаружил какие-то нарушения в памяти удаленного процесса. Задача данного метода инициализировать WorkingSet процесса вызовом процедуры InitWorkingSet после чего в цикле вызвать для каждого модуля из списка TRawModules процедуру ScanModule.
ScanModule в свою очередь загружает в память образ сканируемого модуля (в TMemoryStream) и вызывает ScanExport.
И вот ScanExport нужно рассмотреть более подробно. Задача данной процедуры состоит в контроле целостности таблицы экспорта в удаленном адресном пространстве, сравнением значений, записанных в ней с заранее рассчитанными.
Если немножко подсократить код функции, то основная её часть выглядит вот так:
procedure TPatchAnalyzer.ScanExport(Index: Integer; Module: TRawPEImage);
begin
ExportDirectory := TRemoteStream.Create(FProcessHandle,
Module.ExportDirectory.VirtualAddress, Module.ExportDirectory.Size);
try
ZeroMemory(@HookData, SizeOf(THookData));
... инициализация структуры
for Exp in Module.ExportList do
begin
...
HookData.RawVA := Exp.FuncAddrVA;
...
if not ExportDirectory.ReadMemory(Exp.ExportTableVA, 4,
@HookData.ExportAdv.ExpRemoteRva) then
Continue;
HookData.RemoteVA :=
HookData.ExportAdv.ExpRemoteRva + Module.ImageBase;
if HookData.RemoteVA <> HookData.RawVA then
begin
if Exp.ForvardedTo <> EmptyStr then
if not FRawModules.GetProcData(Exp.ForvardedTo,
Module.Image64, ForvardedExp, HookData.RemoteVA) then
begin
HookData.Calculated := False;
DoModifyed(HookData);
Continue;
end
else
HookData.RawVA := ForvardedExp.FuncAddrVA;
if HookData.RemoteVA <> HookData.RawVA then
begin
DoModifyed(HookData);
Continue;
end;
end;
end;
finally
ExportDirectory.Free;
end;
end;Первым идет вызов TRemoteStream.Create — это простенький класс представляющий из себя обертку над TMemoryStream и выступающий в качестве кэша, т.к. в процессе анализа будет много чтений памяти удаленного процесса, чтобы не вызывать на каждый чих ReadRemoteMemory вся память, из которой теоретически будет происходить чтение, сразу копируется в этот кэш за один присест.
Следующим шагом идет основной цикл, в котором последовательно выбирается каждая запись из таблицы экспорта переданного на вход модуля Module.ExportList, при этом для каждой записи заполняется структура, которая в случае обнаружения несовпадений будет отдаваться наружу в калбэк, для последующей обработки внешним кодом.
Для каждой записи читается RVA адрес экспортируемой функции через (рассчитанный еще в TRawPEImage адрес в таблице экспорта) Exp.ExportTableVA, после чего прочитанный RVA адрес переводится в VA сложением с базой текущего модуля ImageBase (ну т.е. с его hInstance).
И делается проверка — если полученное значение не равно тому, которое рассчитал наш код еще в классе TRawPEImage (вторая глава) то это может означать три варианта:
- код расчета «правильного» значения ошибочен
- код в таблице экспорта действительно пропатчен и ведет на установленный извне перехватчик.
- экспортируемая функция перенаправлена, и её реализация находится в другом модуле
Второй вариант вполне допустим, но как правило первое сравнение не успешно по причине форварда, т.е. перенаправления адреса функции на совершенно другой модуль. Поэтому следующим шагом происходит поиск адреса перенаправленной функции и, если получилось его найти — повторное сравнение.
Ну а если и в этом случае адреса не совпали, тогда уже вызывается внешний обработчик через DoModifyed, в которой происходит проверка шаринга страницы через вызов функции CheckPageSharing и заполнение результата в структуре, отдаваемой в калбэк. В ней есть нюанс, поэтому рассмотрим её код поподробней:
function TPatchAnalyzer.CheckPageSharing(AddrVa: ULONG_PTR64;
out SharedCount: Byte): Boolean;
begin
Result := FWorkingSet.TryGetValue(AddrVA and PageMask, SharedCount);
if not Result then
if ReadRemoteMemory(FProcessHandle, AddrVa, @Tmp, 1) then
begin
InitWorkingSet;
Result := FWorkingSet.TryGetValue(AddrVA and PageMask, SharedCount);
end;
end;Здесь происходит следующее, сначала происходит попытка найти информацию о странице, к которой принадлежит адрес, в текущем пуле страниц ворксета, при этом (т.к. грануляция страниц 4096 байта), применяется маска, отсекающая младшую часть адреса.
А вот если страница не нашлась, то происходит попытка её подгрузки в ворксет чтением одного байта по указанному адресу (чуть выше я рассказывал про детект сканера памяти, вот тут тоже самое) в результате чего (если получилось прочитать) повторно перестраиваем ворксет и еще раз пытаемся получить информацию по странице.
Так вот, как только нашлось не совпадение, вызывается калбэк, назначенный во внешнем коде, в который передается информация в виде структуры с параметрами, описывающими — что именно наш анализатор нашел и что ему не нравится. Реализацию калбэка я рассматривать не буду, он достаточно тривиальный и основная его задача — это вывод результата в форматированном виде. Код колбэка и вспомогательных функций находится в модуле "display_utils.pas".
Давайте посмотрим, как это все будет работать. В коде демопримера я специально ввел дефайн, чтобы вы смогли посмотреть, как будет работать код на текущий момент времени, при еще не реализованной обработке форвард деклараций функций.
Для этого раскоментируйте директиву DISABLE_FORWARD_PROCESSING в инклуде «defines.inc».
Вот они все, четыре функции из user32.dll (скриншот снят на Windows 11, на других ОС список функций может быть другим).
Анализатор показал, что адреса всех четырех функций ведут вместо библиотеки user32 (которая их экспортирует) куда-то внутрь ntdll.dll
Чтобы было понятней что именно выводит анализатор, то разъясню:
- сначала пишется тип перехвата (Export/Import/Delay Import), далее имя библиотеки и функции
- далее идет контрольный статус, получаемый через контроль шаринга страницы. Status: PATCHED означает что страница была модифицирована.
- Expected: HEX_VALUE — ожидаемый адрес экспортируемой функции
- present: HEX_VALUE — текущий адрес экспортируемой функции (если получилось определить — пишется имя модуля, которому принадлежит этот адрес)
- в заголовке таблицы поле Raw (0xHEX_VALUE) — смещение от начала файла, где содержится RVA адрес экспортируемой функции
- в последней строке VA адрес в таблице экспорта с записью об функции, её значение в оригинальном файле и значение в удаленном адресном пространстве
Можно посмотреть как выглядит таблица экспорта user32.dll через сторонний инструмент и там увидеть вот такую картинку:
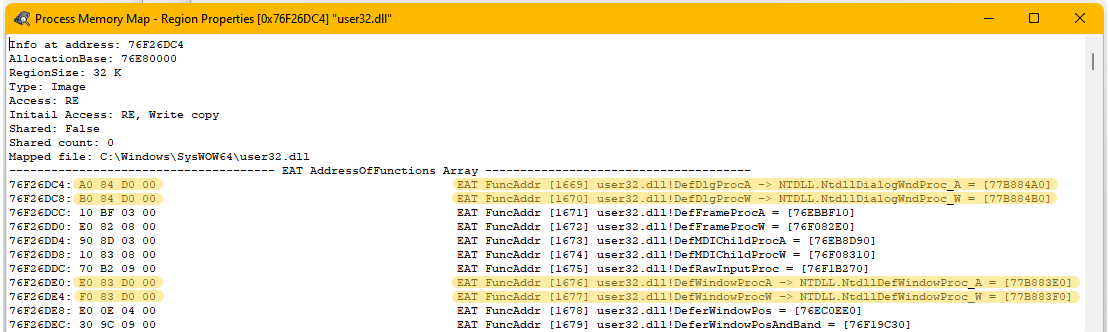
Да, каждая из показанных четырех функций действительно перенаправлена, рассмотрим вот эту строчку вывода анализатора поподробней:
Export modified user32.dll -> DefDlgProcA. Status: PATCHED!
Expected: 0000000076F2A133, present: 0000000077B884A0 --> ntdll.dll
Addr: |Raw (0xA61C4): |Remote:
----------------------------------------------------------------------------------------------------------------------------
0000000076F26DC4|33 A1 0A 00 |A0 84 D0 00и будем сверять её с текущей записью в таблице экспорта:
76F26DC4: A0 84 D0 00 EAT FuncAddr [1669] user32.dll!DefDlgProcA -> NTDLL.NtdllDialogWndProc_A = [77B884A0]
- адрес 76F26DC4 — анализатор правильно определил адрес записи в таблице экспорта и показал, что текущее значение «A0 84 D0 00» не соответствует рассчитанному.
- «present: 0000000077B884A0 --> ntdll.dll» анализатор правильно определил текущий адрес функции, и он соответствует «NTDLL.NtdllDialogWndProc_A = [77B884A0]» на которую произошло перенаправление.
- «Expected: 0000000076F2A133» а давайте посмотрим, что хранится по адресу, который ожидал анализатор.

А там строка «NTDLL.NtdllDialogWndProc_A»!!! Причем адрес этой строки находится в директории экспорта.
Собственно — это все что нужно знать про перенаправление, серьезно :)
Ну а если без шуток, то действительно у большинства функций RVA адрес в таблице экспорта ведет куда-то внутрь секции кода этого же модуля, и только у перенаправленных функций он ведет на строку в директории экспорта, т.е. по факту такую проверку форварда можно сделать прямо в TRawPEImage:
function TRawPEImage.IsExportForvarded(RvaAddr: DWORD): Boolean;
begin
Result := DirectoryIndexFromRva(RvaAddr) = IMAGE_DIRECTORY_ENTRY_EXPORT;
end;И этого будет вполне достаточно.
Вообще, конечно, с форвардом это они удачно придумали, можно спокойно переносить ранее реализованные куски код тасуя их между модулями причем без потери совместимости, только нужно учитывать, что функция, на которую произошло перенаправление, сама может быть перенаправлена!
Пример такой функции (нашлось в Win11): USP10.ScriptGetLogicalWidths -> GDI32.ScriptGetLogicalWidths -> gdi32full.ScriptGetLogicalWidths
И при расчете адреса экспортируемой функции (точнее значения, которое должно быть записано в таблице экспорта) форвард нужно учитывать обязательно.
Осталось только реализовать обработку, это делается буквально добавлением нескольких строк кода в класс TRawPEImage (ориентируйтесь на директиву DISABLE_FORWARD_PROCESSING).
Выглядят они вот так:
{$IFNDEF DISABLE_FORWARD_PROCESSING}
if IsExportForvarded(FunctionsAddr[ExportChunk.Ordinal]) then
begin
Raw.Position := ExportChunk.FuncAddrRaw;
if Raw.Position = 0 then Continue;
ExportChunk.OriginalForvardedTo := ReadString(Raw);
ProcessApiSetRedirect(FOriginalName, ExportChunk);
end
else
begin
ExportChunk.OriginalForvardedTo := EmptyStr;
ExportChunk.ForvardedTo := EmptyStr;
end;
{$ENDIF}Т.е. проверяем через показанную выше IsExportForvarded, является ли запись об экспорте перенаправленной, и если да — читаем строку форварда.
Этот же код нужно продублировать чуть ниже, где обрабатываются функции, экспортирующиеся по ординару.
Код к четвертой главе для самостоятельного изучения доступен по этой ссылке.
Пора переходить к таблице импорта, где помимо форварда деклараций функций появляются редиректы…
5. Таблица импорта
Импорт в РЕ файлах, в отличие от таблицы экспорта, устроен немного по-другому. Во-первых, как правило он расположен не в одной, а сразу в двух директориях. Это директория с дескрипторами импорта IMAGE_DIRECTORY_ENTRY_IMPORT и директория с адресами импорта IMAGE_DIRECTORY_ENTRY_IAT.
Бывают, конечно, исключения, когда он умещается только в первой директории, но это редкость. В импорте отсутствует какая-то единая таблица, дело в том что обычно импортируются функции из разных библиотек и для каждой из этих библиотек в директории импорта создается свой дескриптор.
Каждый дескриптор — это структура IMAGE_IMPORT_DESCRIPTOR, чем больше библиотек используются в импорте РЕ файла, тем больше этих структур будет объявлено, причем допускается повторное объявление дескриптора на одну и ту же библиотеку, в котором будет описан другой набор импортируемых функций.
Дескрипторы пишутся последовательно один за одним, от начала директории IMAGE_DIRECTORY_ENTRY_IMPORT, при этом самый последний дескриптор должен содержать в поле Characteristics значение ноль, что означает конец списка дескрипторов.
В дескрипторе интересны три поля.
1. Name — содержит RVA адрес с Ansi строкой хранящей имя библиотеки. Т.е. грубо переведя его в VA/Raw можно прочитать например «kernel32.dll»
2. FirstThunk — содержит RVA адрес на первый элемент списка структур IMAGE_THUNK_DATA, каждая из которых в действительности (и по сути) структурой не является, а представляет из себя либо DWORD, либо ULONGLONG который хранит некое число, которое трактуется четырьмя разными способами:
А: в случае если в числе взведен старший бит, т.е. выполняется условие Value and IMAGE_ORDINAL_FLAGXX <> 0, данное число трактуется как Ordinal, что означает о необходимости загрузки библиотеки по имени Name и поиска функции через GetProcAddress по её порядковому номеру в списке экспорта.
Б: в случае если старший бит не взведен, это означает что число содержит RVA адрес на структуру IMAGE_IMPORT_BY_NAME
В: если применяется связанный импорт (в статье рассмотрен не будет) данное число трактуется как VA адрес импортируемой функции. Это условие достаточно редко встречается и применимо только для значений списка, на который указывает FirstThunk, в списке OriginalFirstThunk не используется.
Г: теоретически, в зависимости от значения ForwarderChain дескриптора, может содержать RVA адрес строки перенаправления, но на практике я такого никогда не встречал, не видел упоминания ни в одной статье по РЕ формату и этот вариант рассматривать не буду.
Все четыре варианта актуальны только тогда, когда список читается напрямую из файла. Когда он читается из памяти запущенного приложения, в нем всегда будут размещены VA адреса импортируемых функций, модификацией данного списка занимается загрузчик при старте приложения.
Конец списка означает элемент со значением ноль.
Кстати, именно этот список, на который указывает FirstThunk хранится отдельно от директории импорта в специальной директории IMAGE_DIRECTORY_ENTRY_IAT, так называемой Import Address Table. Подозреваю что сделано это для того, чтобы не происходило отсоединения таблицы экспорта от механизма шаринга страниц памяти, вынеся все изменяемые загрузчиком поля в отдельный блок памяти, в который и происходит запись актуальных данных. И именно его будет контролировать код анализатора.
3. OriginalFirstThunk — все тоже самое что и FirstThunk, только для списков, на которые указывает это поле каждого дескриптора актуальны только первые два пункта, т.е. в этих списках никогда не будет VA адресов функций, ни при чтении из файла на диске, ни при чтении из памяти запущенного приложения. Только RVA адрес структуры IMAGE_THUNK_DATA или Ordinal.
А вот IMAGE_THUNK_DATA это простая структура, которая состоит из двух полей.
Hint — порядковый номер импортируемой функции в списке экспорта библиотеки, по которому её предпочтительней искать. Используется загрузчиком для ускорения поиска импортируемой функции при инициализации таблицы импорта.
Name — Ansi строка, завершающаяся нулем, содержащая имя функции.
Вот картинка чтобы было более наглядно:
Синим цветом показаны данные списка OriginalFirstThunk и сам список, обведенный синим квадратом (обращайте внимание на адреса)
Зеленым показаны данные списка FirstThunk с реальными VA адресами импортируемых функций (ну, точнее всего одной функции).
Оба списка заканчивается нулем.
Фиолетовым показан как осуществляется переход на реальный адрес с именем библиотеки, а красный квадрат показывает начало единственной структуры IMAGE_THUNK_DATA, конкретно его поля Hint, которое содержит число 137 (отображенное в подсказке справа).
Из всех этих данных контролировать потребуется только значения, которые содержат списки FirstThunk, т.к. именно правкой этих значений и осуществляется установка перехватчика правкой таблицы импорта.
Итак, задача — пробежаться по всем дескрипторам директории импорта и загрузить данные из списков каждого дескриптора.
Сразу перейду к коду:
function TRawPEImage.LoadImport(Raw: TStream): Boolean;
...
Result := False;
Raw.Position := VaToRaw(FImportDir.VirtualAddress);
if Raw.Position = 0 then Exit;
ZeroMemory(@ImportChunk, SizeOf(TImportChunk));
while (Raw.Read(ImageImportDescriptor, SizeOf(TImageImportDescriptor)) =
SizeOf(TImageImportDescriptor)) and (ImageImportDescriptor.OriginalFirstThunk <> 0) do
begin
// запоминаем адрес следующего дексриптора
NextDescriptorRawAddr := Raw.Position;
// вычитываем имя библиотеки импорт из которой описывает дескриптор
Raw.Position := RvaToRaw(ImageImportDescriptor.Name);
if Raw.Position = 0 then
Exit;
// инициализируем размер записей и флаги
IatDataSize := IfThen(Image64, 8, 4);
OrdinalFlag := IfThen(Image64, IMAGE_ORDINAL_FLAG64, IMAGE_ORDINAL_FLAG32);
// вычитываем все записи описываемые дескриптором, пока не кончатся
IatData := 0;
ImportChunk.ImportTableVA := RvaToVa(ImageImportDescriptor.FirstThunk);
OriginalFirstThunk := RvaToVa(ImageImportDescriptor.OriginalFirstThunk);
if OriginalFirstThunk = 0 then
OriginalFirstThunk := ImportChunk.ImportTableVA;
repeat
LastOffset := VaToRaw(OriginalFirstThunk);
if LastOffset = 0 then
Exit;
Raw.Position := LastOffset;
Raw.ReadBuffer(IatData, IatDataSize);
if IatData <> 0 then
begin
// проверка - идет импорт только по ORDINAL или есть имя функции?
if IatData and OrdinalFlag = 0 then
begin
// имя есть - нужно его вытащить
Raw.Position := RvaToRaw(IatData);
if Raw.Position = 0 then
Exit;
Raw.ReadBuffer(ImportChunk.Ordinal, SizeOf(Word));
ImportChunk.FuncName := ReadString(Raw);
end
else
begin
// имени нет - запоминаем только ordinal функции
ImportChunk.FuncName := EmptyStr;
ImportChunk.Ordinal := IatData and not OrdinalFlag;
end;
FImport.Add(ImportChunk);
Inc(ImportChunk.ImportTableVA, IatDataSize);
Inc(OriginalFirstThunk, IatDataSize);
end;
until IatData = 0;
// переходим к следующему дескриптору
Raw.Position := NextDescriptorRawAddr;
end;
Result := ImageImportDescriptor.OriginalFirstThunk = 0;
end;Код начинает выполняться с определения Raw адреса директории импорта в физическом файле.
Скажем так это лишняя перестраховка, т.к. директория импорта как правило всегда в наличии, отсутствует она только у библиотек которые содержат исключительно ресурсы и не имеют исполняемого кода, либо у специально подготовленных исполняемых файлов, в основном написанных на ассемблере, т.к. штатный компилятор врятли вам позволит сотворить такой трюк.
Следующим идет цикл — последовательно считываются все дескрипторы импорта у каждого из которых читается имя описываемой библиотеки, выставляются флаги для детектирования Ordinal значений в списках и размер элементов списка. После чего идет хитрый момент.
В структуре ImportChunk (которая будет содержать данные по каждому элементу из всех таблиц импорта) в поле ImportTableVA запоминается адрес элемента списка из IAT на который указывает FirstThunk (именно его будет контролировать анализатор), но адрес, по которому будет производится реальное чтение из списка забирается из списка OriginalFirstThunk, элементы которого никогда не меняются загрузчиком.
Это сделано по причине, описанной в пункте «В» чуть выше, а именно потому, что список FirstThunk иногда может содержать VA значения функций, т.е. заранее подготовленные реальные адреса (так называемая привязка).
Если база загрузки библиотеки равна значению прописанному в IMAGE_OPTIONAL_HEADER, (плюс выполнятся контрольные проверки из BOUND_IMPORT) загрузчик в этом случае пропускает всю настройку таблицы импорта, в противном случае используется список OriginalFirstThunk, на основании данных которого происходит инициализация списка FirstThunk.
Достаточно редко, но встречается такое, что список OriginalFirstThunk отсутствует. В этом случае его заменяет список FirstThunk и именно это условие учитывается при начале чтения вот в этом коде:
if OriginalFirstThunk = 0 then
OriginalFirstThunk := ImportChunk.ImportTableVA;Если этот список отсутствует, FirstThunk гарантированно будет содержать только те данные, которые должен был содержать OriginalFirstThunk, в противном случае, если бы библиотека загрузилась не по своей базе (или не отработали условия в директории связанного импорта) было бы невозможно инициализировать IAT, на которую указывает FirstThunk, т.к. в этом списке отсутствовали бы RVA адреса на IMAGE_THUNK_DATA.
Ну и в самом конце проверяется условие окончания списка (проверкой на ноль) и, если список еще не закончился, читается каждый его элемент либо как Ordinal (c проверкой через наличие флага OrdinalFlag), либо как структура IMAGE_THUNK_DATA, после чего все заносится в результирующий список доступный извне.
Выглядит все гораздо проще чем само объяснение.
Прежде чем приступить к коду анализатора полученного импорта, нужно учесть следующие два момента.
1. Нельзя анализировать таблицы импорта библиотек/исполняемых файлов, которые должны работать в нулевом кольце. У таких модулей в РЕ заголовке будет присутствовать флаг IMAGE_SUBSYSTEM_NATIVE. Если вы возразите что такие модули не могут быть загружены в третьем кольце (в котором работает весь прикладной код) я отвечу, что это не так. Допустим на Win11 есть такой системный процесс SearchHost и он использует для своей работы библиотеку C:\Windows\System32\LegacySystemSettings.dll у которой (внезапно) в импорте объявлена ntoskrnl.exe экспортирующая функцию wcschr().
Естественно, из-за этой записи ntoskrnl будет подгружен в процесс целиком, но её импорт загрузчик обрабатывать не будет, в противном случае ему пришлось бы подгрузить всё ядро в третье кольцо, а там много чего есть, включая статический импорт из драйверов.
Поэтому анализатор должен проверять — если на вход пришел модуль с флагом IMAGE_SUBSYSTEM_NATIVE, обработку его импорта производить не нужно.
2. В процесс могут быть загружены так называемые СОМ+ модули, это библиотеки, содержащие только IL код не выполняемый нативно.
У таких библиотек в COR20 заголовке выставлен флаг COMIMAGE_FLAGS_ILONLY, а так-же у файла в таблице импорта есть единственная заглушка ведущая на mscoree.dll -> _CorDllMain().
Загрузчик, при наличии данного флага, не обрабатывает таблицу импорта, что можно наглядно увидеть в "...base\ntdll\ldrapi.c" в функции LdrpLoadDll()
{
// if the image is COR-ILONLY, then don't walk the import descriptor
// as it is assumed that it only imports %windir%\system32\mscoree.dll, otherwise
// walk the import descriptor table of the dll.
}При наличии данного флага также не обрабатывается секция релокации. Однако если библиотека должна загружаться в 32 битное приложение ILAsm может исключить этот флаг, заменив его на COMIMAGE_FLAGS_32BITREQUIRED.
Определить такие библиотеки можно не только читая COM заголовок. Признак не исполняемого IL образа содержится так-же и в флагах таблицы загрузчика LDR_DATA_TABLE_ENTRYxx.Flags and LDRP_COR_IMAGE <> 0, который выставляет при инициализации процесса функция LdrpInitializeProcess().
Помимо этого, у всех этих модулей страница, которой принадлежит адрес точки входа, помечена как не исполняемая.
Так как импорт не инициализирован, то такие модули так же необходимо пропускать при анализе таблиц импорта.
Вот теперь можно писать код для анализатора. В немного сокращенном виде он выглядит так:
procedure TPatchAnalyzer.ScanImport(Index: Integer; Module: TRawPEImage);
function CheckRemoteVA: Boolean;
begin
Result := HookData.Calculated and
(HookData.RemoteVA = HookData.RawVA);
end;
//...
begin
if Module.ImportList.Count = 0 then Exit;
if Module.NtHeader.OptionalHeader.Subsystem = IMAGE_SUBSYSTEM_NATIVE then
begin
Inc(FAnalizeResult.Import.Skipped, Module.ImportList.Count);
Exit;
end;
if Module.ComPlusILOnly then
begin
if Module.EntryPoint <> 0 then
if VirtualQueryEx64(FProcessHandle,
Module.EntryPoint, MBI,
SizeOf(TMemoryBasicInformation64)) = SizeOf(TMemoryBasicInformation64) then
if MBI.Protect and (
PAGE_EXECUTE or
PAGE_EXECUTE_READ or
PAGE_EXECUTE_WRITECOPY or
PAGE_EXECUTE_READWRITE) = 0 then
begin
Inc(FAnalizeResult.Import.Skipped, Module.ImportList.Count);
Exit;
end;
end;
// подгружаем кэш таблицы импорта, обычно она сидит в секции IAT
// но в редких случаях эта секция отсутствует и таблица размещается прямо в секции импорта
CacheVA := IfThen(Module.ImportAddressTable.Size = 0,
Module.ImportDirectory.VirtualAddress, Module.ImportAddressTable.VirtualAddress);
CacheSize := IfThen(Module.ImportAddressTable.Size = 0,
Module.ImportDirectory.Size, Module.ImportAddressTable.Size);
if CacheSize > 0 then
AIat := TRemoteStream.Create(FProcessHandle, CacheVA, CacheSize)
else
Exit;
try
AddrSize := IfThen(Module.Image64, 8, 4);
ZeroMemory(@HookData, SizeOf(THookData));
// ...
for Import in Module.ImportList do
begin
HookData.FuncName := Import.ToString;
HookData.RawVA := 0;
// зачитываем текущий адрес из таблицы импорта
if not AIat.ReadMemory(Import.ImportTableVA, AddrSize, @HookData.RemoteVA) then
Continue;
if Import.FuncName = EmptyStr then
HookData.Calculated := FRawModules.GetProcData(Import.LibraryName,
Import.Ordinal, Module.Image64, Exp, HookData.RemoteVA)
else
HookData.Calculated := FRawModules.GetProcData(Import.LibraryName,
Import.FuncName, Module.Image64, Exp, HookData.RemoteVA);
if HookData.Calculated then
HookData.RawVA := Exp.FuncAddrVA
else
if not CheckRemoteVA then
begin
DoModifyed(HookData);
Continue;
end;
if not CheckRemoteVA then
begin
// если функция перенаправлена, пытаемся её подгрузить
if Exp.ForvardedTo <> EmptyStr then
if not FRawModules.GetProcData(Exp.ForvardedTo,
Module.Image64, Exp, HookData.RemoteVA) then
begin
HookData.Calculated := False;
HookData.ImportAdv.OriginalForvardedTo := Exp.OriginalForvardedTo;
HookData.ImportAdv.ForvardedTo := Exp.ForvardedTo;
DoModifyed(HookData);
Continue;
end
else
begin
HookData.RawVA := Exp.FuncAddrVA;
HookData.ImportAdv.OriginalForvardedTo := EmptyStr;
HookData.ImportAdv.ForvardedTo := EmptyStr;
end;
if not CheckRemoteVA then
DoModifyed(HookData);
end;
end;
finally
AIat.Free;
end;
end;В самом начале идут три проверки:
- на наличие импорта
- проверка модулей с флагом IMAGE_SUBSYSTEM_NATIVE
- проверка COM+ модулей
После чего идет цикл по всем записям, полученным от всех дескрипторов импорта текущего модуля.
Сначала читается текущее значение в удаленном адресном пространстве процесса из ранее рассчитанного адреса в списке FirstThunk (этот адрес хранится в ImportTableVA), а потом производится попытка самостоятельного поиска записи об экспортируемой функции в загруженных ранее таблицах экспорта (по Ordinal или по имени).
Если запись нашлась — происходит сравнение результатов, рассчитанного и актуального значений, а если не нашлась, то вызывается внешний калбек.
Причем если запись нашлась, но адреса не совпали, идет проверка перенаправления через содержимое поля ForvardedTo и, если оно заполнено, сравнивается перенаправленная запись.
И вот если сейчас запустить код демонстрационного примера на Windows XP или Vista то все отработает штатно. Он не выведет никаких ошибок, просто покажет список загруженных библиотек и остановится, но… ситуация кардинально поменяется, как только он будет запущен на Windows 7 и выше.
Множеству записей в импорте анализатор не смог подобрать соответствующую запись в экспорте, о чем говорит текст «Export record missing».
Причем практически все эти записи ведут на отсутствующие на жестком диске библиотеки «api-ms-win-xxx.dll» или «ext-ms-win-xxx.dll»
И такое происходит как у записей в таблицах импорта, так и в таблицах экспорта, обратите внимание на самую последнюю строчку:
Import modified imm32.dll -> kernel32.GetProcessMitigationPolicy, at address: 7641D0D4
Export record missing, present: 0000000075DECF40, forvarded to "api-ms-win-core-processthreads-l1-1-1.GetProcessMitigationPolicy" --> KernelBase.dllСам импорт обработан правильно и запись ведет на kernel32.GetProcessMitigationPolicy, но сама эта функция перенаправлена и ведет на отсутствующую в текущем списке экспорта библиотеку «api-ms-win-core-processthreads-l1-1-1.dll», причем по факту текущий адрес в таблице импорта ведет внутрь «KernelBase.dll».
Сейчас будем с этим разбираться, ну а сам код к пятой главе доступен по этой ссылке.
6. ApiSet редиректы
Начиная с Windows 7 совершилась небольшая революция, в Windows было внедрено ядро MinWin. Скажем так это минимальная сборка Windows с самым необходимым набором функционала, что позволило в дальнейшем легко разрабатывать такие специализированные OS как Windows IoT, взамен Embedded.
Часть функционала из kernel32/user32/gdi32/etc… переехала в другие библиотеки, причем в зависимости от типа операционной системы, набор библиотек с конечным функционалом может меняться. А чтобы прикладной код был универсален, Microsoft придумала концепцию виртуальных библиотек.
Брались группы функций, например для работы с файлами (CreateFile/FindFirstFile/etc...), и переносились в библиотеку, допустим «api-ms-win-core-file-l1-1-0.dll». И в самом начале, в Windows 7, эти библиотеки даже присутствовали в «c:\windows\system32\» и их можно было посмотреть. Сами они вообще не содержали никакого кода, и их задача была в предоставлении внешнему коду своей таблицы экспорта, в которой были объявлены записи о всех функциях с их редиректами к библиотеке, содержащей реальный код функций. Впрочем, их наличие никаких плюсов не давало, т.к. загрузка таких библиотек через LoadLibrary возвращала ошибку ERROR_DLL_INIT_FAILED, а сейчас, в Windows 11 этих библиотек вообще нет, да они в принципе и не нужны.
Как это работает: все функции, реализация которых перенесена в ядро MinWin (их достаточно большой список), указываются в таблицах импорта/экспорта не с указанием имени библиотеки, которая их реализует, а с указанием именно таких промежуточных виртуальных библиотек, именно они были показаны на последнем скриншоте. Загрузчик при инициализации таблиц импорта/экспорта производит подмену виртуальных библиотек на реальные, реализующие финальный код функции после чего процесс может нормально запустится, т.к. все адреса у него актуализированы.
А делает он такой редирект на основе специальной служебной таблицы, называемой ApiSet Map, расположенной в библиотеке apisetschema.dll в виде отдельной секции ".apiset" причем эта библиотека не подгружается в процесс, отмапливается только сама секция. И вот формат этой секции представляет наибольший интерес.
Во-первых, он абсолютно не документирован, во-вторых, на текущий момент существует три версии данного формата.
- версия два, используется в Windows 7 и Windows 8
- версия четыре используется в Windows 8.1
- версия шесть используется в Windows 10 и Windows 11
Ну а в-третьих, данная таблица присутствует в каждом процессе и нет необходимости её чтения из чужого адресного пространства, достаточно её прочитать у самого себя.
Ссылка на адрес памяти, содержащий отмапленный ApiSet расположена в блоке окружения процесса (PEB), это именно та структура, посредством которой происходило чтение данных из таблиц загрузчика. Так как чтение таблицы может (и будет) происходить из текущего процесса, то получение необходимого адреса упрощается и сводится всего лишь к паре ассемблерных строк:
function TApiSetRedirector.GetPEBApiSet: Pointer;
asm
{$IFDEF WIN32}
mov eax, fs:[30h]
mov eax, [eax + 38h]
{$ELSE}
mov rax, gs:[60h]
mov rax, [rax + 68h]
{$ENDIF}
end;Здесь, посредством регистра FS (или GS для 64 бит), который указывает на блок окружения потока (TEB), читается адрес структуры PEB (смещение поля TEB->ProcessEnvironmentBlock равно 0х30 и 0х60 для 32 и 64 бит соответственно), после чего читается значение поля PEB->ApiSetMap (смещение 0х38 и 0х68 для 32 и 64 бит соответственно).
Сразу же упомяну о двух моментах, чтобы не останавливаться на них позже.
1. Все структуры, описанные ниже, содержат адреса в RVA формате, но базой, от которой идет отсчет RVA адреса, является адрес самой таблицы, который был получен кодом выше. Т.е. если в какой-то структуре содержится число 0х123, а таблица размещается в памяти по адресу 0х30000, то это означает что VA адрес будет равен 0х30123!
2. Во всех форматах ApiSet таблицы строки хранятся в виде вот такой структуры:
TApiSetString = record
Offset: ULONG;
Length: USHORT;
end;Где Offset — это RVA адрес UNICODE строки (не Ansi), а Length — её длина в байтах (не в символах).
После получения адреса ApiSet таблицы нужно определится в каком формате она представлены, за это отвечает самое первое поле заголовка таблицы, представляющее из себя LONG, в котором будет записана версия 2, 4 или 6:
procedure TApiSetRedirector.Init;
begin
FApiSetVer := PLONG(FApiSet)^;
case FApiSetVer of
2: Init2;
4: Init4;
6: Init6;
end;
end;Начну с самого простого формата за номером два.
Он представляет из себя четыре структуры.
1. Заголовок таблицы:
TApiSetNameSpace2 = record
Version,
Count: ULONG;
end;С него начинается ApiSet таблица второй версии и задача этой структуры, сообщить, помимо версии, о количестве содержащихся в ней записей о редиректе.
2. Сразу за ней идет массив структур TApiSetNameSpaceEntry2, в количестве, указанном в заголовке таблицы.
TApiSetNameSpaceEntry2 = record
Name: TApiSetString;
DataOffset: ULONG;
end;Поле Name, это и есть искомая строка редиректа, выглядит обычно вот в таком виде с учетом регистра (если прочитать через TApiSetString): «MS-Win-Core-ErrorHandling-L1-1-0». Этой строке будет соответствовать запись в таблицах импорта/экспорта примерно такого вида:
- или «api-ms-win-core-errorhandling-l1-1-0.dll»
- или «ext-ms-win-core-errorhandling-l1-1-0.dll»
Поле DataOffset — RVA адрес следующей структуры:
TApiSetValueEntry2 = record
NumberOfRedirections: ULONG;
end; Она представляет из себя всего одно поле, обозначающее количество возможных вариантов редиректа, сразу за которой идет массив структур, описывающих куда именно нужно произвести редирект в количестве NumberOfRedirections:
TApiSetValueEntryRedirection2 = record
Name: TApiSetString;
Value: TApiSetString;
end;И вот тут достаточно интересный момент. Самое первое поле Name представляет из себя, по сути, фильтр, уточняющий в каких случаях данный редирект должен применяться и содержит в себе либо имя библиотеки, либо остается пустым.
А вот второе поле указывает на какую конкретно библиотеку произойдет редирект.
Давайте посмотрим на картинку:
ApiSetValueEntry2 содержит в себе число два, и сразу за ней идут две записи, причем первая перенаправляет в kernel32.dll (поле Value), а вторая в kernelbase.dll, причем у второй указано что Name равен kernel32.dll.
Как это работает: например, nsi.dll имеет в импорте запись об GetLastError которую экспортирует API-MS-Win-Core-ErrorHandling-L1-1-0.dll
По умолчанию для всех библиотек включается редирект на kernel32.dll, но и сам kernel32.dll в таблице импорта имеет запись об GetLastError (на которую еще и форвард идет из таблицы экспорта), причем из той-же библиотеки API-MS-Win-Core-ErrorHandling-L1-1-0.dll.
Вот для такой ситуации в ApiSet включена запись что kernel32.dll должна быть перенаправлена не в саму себя, а в kernelbase.dll
Схематично вторая версия ApiSet таблицы выглядит в виде вот такого дерева:
TApiSetNameSpace2 // количество виртуальных библиотек
TApiSetNameSpaceEntry2 // вирт библиотека "API-MS-Win-Core-Console-L1-1-0.dll"
TApiSetNameSpaceEntry2 // вирт библиотека "API-MS-Win-Core-DateTime-L1-1-0.dll"
TApiSetNameSpaceEntry2 // вирт библиотека "API-MS-Win-Core-Debug-L1-1-0.dll"
TApiSetNameSpaceEntry2 // вирт библиотека "API-MS-Win-Core-DelayLoad-L1-1-0.dll"
TApiSetNameSpaceEntry2 // вирт библиотека "API-MS-Win-Core-ErrorHandling-L1-1-0.dll"
TApiSetValueEntry2 // количество вариантов редиректов
TApiSetValueEntryRedirection2 // описание редиректа по умолчанию
TApiSetValueEntryRedirection2 // описание дополнительного условия редиректа
...И код её чтения:
procedure TApiSetRedirector.Init2;
...
begin
NameSpaceEntry := PApiSetNameSpaceEntry2(PByte(FApiSet) + SizeOf(TApiSetNameSpace2));
for I := 0 to PApiSetNameSpace2(FApiSet)^.Count - 1 do
begin
LibFrom := GetString(NameSpaceEntry.Name).ToLower;
ValueEntry := Pointer(PByte(FApiSet) + NameSpaceEntry.DataOffset);
EntryRedirection := Pointer(PByte(ValueEntry) + SizeOf(TApiSetValueEntry2));
for A := 0 to ValueEntry.NumberOfRedirections - 1 do
begin
Redirection := GetString(EntryRedirection.Value);
Key := LibFrom + GetString(EntryRedirection.Name);
AddRedirection(Key, Redirection);
Inc(EntryRedirection);
end;
Inc(NameSpaceEntry);
end;
end;В этом коде всего два нюанса:
- все RVA адреса пересчитываются в VA сложением с адресом самой таблицы (эту адресацию я уже упомянул в самом начале, но на всякий случай).
- формирование ключа для поиска редиректа. Для всех случаев он хранится как имя виртуальной библиотеки, т.е. «api-ms-win-core-errorhandling-l1-1-0», а частные случаи для конкретных библиотек, хранятся с указанием имени этой библиотеки: «api-ms-win-core-errorhandling-l1-1-0kernel32.dll»
Теперь формат таблицы за номером четыре, который применяется в Windows 8.1
Заголовок выглядит в виде такой структуры:
TApiSetNameSpace4 = record
Version,
Size,
Flags,
Count: ULONG;
end;По сравнению со второй версией добавились поля Size, содержащий полный размер ApiSet таблицы в байтах, и поле Flags — которое (по идее) должно содержать какие-то флаги, значения и назначение которых мне не известны. На моих тестовых стендах это поле всегда было равно нулю.
Далее все также идет массив структур TApiSetNameSpaceEntry4, в количестве, указанном в заголовке таблицы.
TApiSetNameSpaceEntry4 = record
Flags: ULONG;
Name: TApiSetString;
Alias: TApiSetString;
DataOffset: ULONG;
end;Здесь появилось два новых поля, назначение которых мне также не известно, это Flags (содержит либо единицу, либо тройку), и поле Alias — содержащее сокращенное имя виртуальной библиотеки (применение не известно). Остальные поля остались старыми и работают также, т.е. DataOffset — это RVA адрес на структуру:
TApiSetValueEntry4 = record
Flags,
NumberOfRedirections: ULONG;
end;Опять, появилось поле с каким-то флагом, что делает — не понятно (на тесте всегда равен нулю).
Ну и сразу за ним, также как и во второй версии ApiSet, идет массив реальных редиректов:
TApiSetValueEntryRedirection4 = record
Flags: ULONG;
Name: TApiSetString;
Value: TApiSetString;
end;Кроме дополнительного поля флага (который всегда равен нулю), ничего не поменялось. Таким образом, структура и код чтения четвертой версии ApiSet таблицы, ничем не отличается, за исключением что используются новые версии структур с дополнительным и не влияющими ни на что, полями.
А вот ApiSet версии шесть, который пошел начиная с Windows 10 и продолжает используется в Windows 11, устроен немножко хитрее.
Заголовок выглядит следующим образом:
TApiSetNameSpace6 = record
Version,
Size,
Flags,
Count,
EntryOffset,
HashOffset,
HashFactor: ULONG;
end;По сравнению с заголовком четвертой версии добавились три поля:
- Поле EntryOffset, который является RVA адресом начала массива редиректов. Раньше они шли сразу за заголовком (впрочем, в шестой версии тоже идут сразу за ним), но наличие этого поля подразумевает что ситуация в какой-то момент времени может изменится, и они могут быть перемещены по любом другому произвольному адресу.
- Поле HashOffset, новое понятие для ApiSet таблиц, майкрософт решило ускорить работу с таблицей и добавило в неё хэши имен виртуальных библиотек. Это поле хранит RVA указатель на начало массива структур описывающих хэш к каждой записи. Если честно мне этот механизм показался не удобным поэтому в коде я использую обычный словарь, который справляется с хранением имен библиотек намного удобнее и применим к любой версии ApiSet, поэтому это поле в коде будет игнорироваться.
- HashFactor — это поле содержит число от которого начинает считаться хэш, тоже не интересно.
TApiSetNameSpaceEntry6 = record
Flags: ULONG;
Name: TApiSetString;
HashedLength: ULONG;
ValueOffset,
ValueCount: ULONG;
end;- Поле Flags — некоторые источники утверждают, что это поле хранит флаг Sealed равный единице, за что он отвечает, не известно, но он выставлен у всех записей.
- Поле Name — это искомое имя виртуальной библиотеки. Причем в отличии от младших версий, оно представлено целиком со всеми необходимыми префиксами, например вот так: «api-ms-win-core-errorhandling-l1-1-3»
- Поле HashedLength — а вот это размер имени библиотеки в байтах, с которой должен сниматься хэш. Очень важное поле, т.к. имя виртуальной библиотеки, имеет свою версионность, например errorhandling в Windows 7 заканчивался цифрой ноль, на Windows 8.1 вообще присутствует две записи, с версией ноль и с версией один, в Windows 10 она шла с цифрой два (в самых первых сборках), а сейчас идет за версией три, как и в Windows 11. Старые же версии программ содержат привязку к актуальным на момент их сборки наименованиям виртуальных библиотек, и параметр HashedLength указывает размер наименования, который будет одинаков для всех без учета версионности, таким образом давая возможность запуска старым сборкам программ.
- Поле ValueOffset — аналог старого поля DataOffset, содержит RVA адрес на массив структур редиректа
- Поле ValueCount — новое поле, которое заменяет собой старую структуру TApiSetValueEntryХ и содержит размер массива редиректов для виртуальной библиотеки.
Это применимо для модулей ядра, например ntoskrnl.exe который имеет редирект на виртуальную библиотеку «ext-ms-win-ntos-ksecurity-l1-1» ну и несколько других сугубо специфичных для ядра. Такой исполняемый файл может быть подгружен в адресное пространство процесса (я упоминал про это в пятой главе) но его таблица импорта будет свернута в самого себя на заглушки, поэтому такие модули с IMAGE_SUBSYSTEM_NATIVE не обрабатываются и редиректы для таких виртуальных библиотек пустые.
Раз структура, по сути, не поменялась, то показывать её декларацию я не буду, а вместо неё покажу структуру описывающую хэш имени.
Она использоваться не будет, поэтому просто для справки.
TApiSetHashEntry6 = record
Hash,
Index: ULONG;
end;Код чтения шестой версии таблицы такой:
procedure TApiSetRedirector.Init6;
...
begin
NameSpaceEntry := PApiSetNameSpaceEntry6(PByte(FApiSet) +
PApiSetNameSpace6(FApiSet)^.EntryOffset);
for I := 0 to PApiSetNameSpace6(FApiSet)^.Count - 1 do
begin
LibFrom := GetString(NameSpaceEntry.Name);
SetLength(LibFrom, NameSpaceEntry.HashedLength div SizeOf(Char));
ValueEntry := Pointer(PByte(FApiSet) + NameSpaceEntry.ValueOffset);
for A := 0 to NameSpaceEntry.ValueCount - 1 do
begin
Redirection := GetString(ValueEntry.Value);
Key := LibFrom + GetString(ValueEntry.Name);
if not Redirection.IsEmpty then
begin
Inc(FUniqueCount);
FData.AddOrSetValue(Key, Redirection);
end;
Inc(ValueEntry);
end;
Inc(NameSpaceEntry);
end;
end;Это, собственно, все по поводу чтения, теперь нужно подключить ApiSet к загрузчику модулей TRawPEImage.
Для этого необходимы два метода доступных снаружи для обработки редиректа:
function TApiSetRedirector.RemoveSuffix(const Value: string): string;
var
LastSuffixIndex: Integer;
begin
if FApiSetVer = 6 then
begin
LastSuffixIndex := Value.LastDelimiter('-');
if LastSuffixIndex > 0 then
Exit(Copy(Value, 1, LastSuffixIndex));
end;
Result := Value;
end;
function TApiSetRedirector.SchemaPresent(const LibName: string;
var RedirectTo: string): Boolean;
var
Tmp: string;
begin
if FData.Count = 0 then Exit(False);
Tmp := RemoveSuffix(RedirectTo.ToLower);
// сначала получаем с привязкой к текущей библиотеке
Result := FData.TryGetValue(Tmp + LibName.ToLower, RedirectTo);
// а если нет записи, то получаем перенаправление по умолчанию
if not Result then
Result := FData.TryGetValue(Tmp, RedirectTo);
end;Функция RemoveSuffix отвечает за изъятие версионной метки из имени виртуальной библиотеки, в случае если используется ApiSet версии шесть, а SchemaPresent производит поиск редиректа, соответствующий имени виртуальной библиотеки в комбинации с именем библиотеки, из которой идет вызов (для обработки специальных ситуаций, когда должен быть применен отдельный редирект, а не общий).
Кстати при обработке таблиц экспорта должно использоваться именно то имя библиотеки которое записано в поле ImageExportDirectory.Name, именно по ней производится редирект, а не по текущему имени библиотеки (которая может быть банально переименована — о таком случае).
Инициализацию ApiSet нужно произвести при открытии процесса, для этого в процедуре TRawScanner.InitFromProcess в самом начале объявляется вызов ApiSetRedirector.LoadApiSet;
В загрузчике модулей необходимо добавить метод работы с редиректором:
procedure TRawPEImage.InternalProcessApiSetRedirect(const LibName: string;
var RedirectTo: string);
var
ForvardLibraryName, FuncName: string;
begin
if not ParceForvardedLink(RedirectTo, ForvardLibraryName, FuncName) then
Exit;
ForvardLibraryName := ChangeFileExt(ForvardLibraryName, '');
if ApiSetRedirector.SchemaPresent(LibName, ForvardLibraryName) then
RedirectTo := ChangeFileExt(ForvardLibraryName, '.') + FuncName;
end;Его задачей будет преобразовывать вызовы ведущие в виртуальные библиотеки, на вызовы, идущие к конечным, в которых реализован реальный код функций.
Например, при входных данных:
LibName = 'KERNEL32.dll'RedirectTo преобразуется в 'kernelbase.AddDllDirectory'
RedirectTo = 'api-ms-win-core-libraryloader-l1-1-0.AddDllDirectory'
Ну а вызов этого метода будет размещен в двух заглушках ProcessApiSetRedirect обрабатывающих импорт и экспорт.
Теперь, если запустить код демопримера, можно увидеть, что он отработал без ошибок и вывел в консоль только список загруженных библиотек без ошибок, которые присутствовали в коде предыдущей главы.
Но это еще не все — есть еще таблица отложенного импорта, и её тоже нужно контролировать.
Код к шестой главе для самостоятельного изучения доступен по этой ссылке.
7. Отложенный импорт
Как мне кажется, с отложенным импортом разработчики PE формата перемудрили, он избыточен, ведь есть обычная динамическая загрузка библиотек, в которой можно удобно принять решение что нужно делать, в случае если требуемая функция (или вообще библиотека целиком) отсутствует. Этот гибкий механизм зачем-то преобразовали в гораздо менее удобный механизм отложенного импорта. Его суть заключается в следующем — в PE файле в отдельной директории строится список дескрипторов отложенного импорта, в которые помещаются данные об импортируемых функциях «предположительно отсутствующих» на операционной системе пользователя и эта таблица не обрабатывается загрузчиком, что позволяет программе запуститься без выдачи сообщения «The procedure entry point {%FuncName%} could not be located in the dynamic link library {%LibName%}».
Изначальные адреса таких функций указывают на код их инициализации, который должен выполнится при первом вызове такой функции.
Причем в Microsoft Visual Studio это все документировано и код такого обработчика доступен как для изучения, так и для модификации под свои требования, подробнее можно узнать в MSDN.
А вот в Delphi с этим все сложнее, заменить его на свой и вообще посмотреть, как он работает увы не удастся (разве что только в асм коде), т.к. он реализован в отсутствующем delayhlp.cpp (название модуля подозрительно похоже на такой-же аналог у MSVC). Причем это может приводить к весьма печальным ошибкам, например в ранних версиях Delphi в коде _delayLoadHelper была допущена критическая ошибка, которую никак нельзя было исправить на тот момент для 64 битных сборок. Дело в том что код данного стаба при инициализации адреса функции не сохранял на стеке регистры XMM0..XMM3, использующиеся для передачи аргументов с плавающей запятой. Это приводило к невозможности импорта функций с такими параметрами через таблицу отложенного импорта из-за их порчи, так как GetProcAddress в процессе работы сама меняет значения этих регистров.
Разработчики Wine, зная об этой особенности даже сделали специальный патч в обвязке kernel:
https://gitlab.winehq.org/wine/wine/-/blob/master/dlls/kernel32/module.c
Впрочем, это лирика, если огрубить, то задача обработчика инициализации отложенного импорта заключается в вызове GetModuleHandle/LoadLibrary + GetProcAddress после чего полученный адрес функции размещается в нужном поле таблицы отложенного экспорта, заменяя текущий, указывающий на код инициализации.
Соответственно если первый раз вызов произошел успешно и адрес функции определился правильно, то повторный вызов функции, импортирующейся через отложенную таблицу импорта, будет идти уже напрямую, минуя код инициализации.
В контексте статьи именно это поле в таблице и будет интересно, причем надо сразу закладываться что «правильных» значений в этом поле может быть два: адрес кода инициализации и адрес реальной функции.
Расположена отложенная таблица импорта в директории IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT и представляет из себя массив дескрипторов:
TImgDelayDescr = record
grAttrs, // attributes
rvaDLLName, // RVA to dll name
rvaHmod, // RVA of module handle
rvaIAT, // RVA of the IAT
rvaINT, // RVA of the INT
rvaBoundIAT, // RVA of the optional bound IAT
rvaUnloadIAT, // RVA of optional copy of original IAT
dwTimeStamp: DWORD; // 0 if not bound,
// O.W. date/time stamp of DLL bound to (Old BIND)
end;— Поле grAttrs, содержит флаг типа адресации полей дескриптора.
- Адреса, содержащиеся в этой структуре, могут быть представлены в двух видах:
- В виде RVA, при этом поле grAttrs будет равно dlattrRva (равное единице).
- В виде VA указателя (поле grAttrs будет равно нулю), причем эта привязка будет идти относительно ImageBase указанного в PE заголовке и, если загрузка произошла по другому адресу, данное значение нужно будет пересчитать относительно текущей базы.
Т.е. потребуется вот такая утилитарная функция:
function GetRva(Value: ULONG_PTR64): ULONG_PTR64;
const
dlattrRva = 1;
begin
if DelayDescr.grAttrs = dlattrRva then
Result := Value
else
Result := Value - NtHeader.OptionalHeader.ImageBase;
end;Судя по комментариям в MSDN, RVA адресация началась с VC 7.0, раньше писали как есть в виде прямых VA указателей. Ну а в Delphi сразу формируют в RVA адресации сразу, как только она появилась.
- Поле rvaDLLName, отвечает за имя библиотеки, из которой будет производится импорт.
- Поле rvaHmod — содержит указатель на поле содержащее hInstance этой библиотеки и используется в коде инициализации при проверке, загружена ли уже такая библиотека или нет. Если библиотека была загружена и позже выгружена, поле обнуляется. Можно было бы использовать в коде анализатора для проверки инициализации дескриптора, но есть нюанс, а именно — если код инициализации получил инстанс библиотеки через GetModuleHandle и не производил реальную загрузку библиотеки, это поле останется равным нулю.
- Поле rvaIAT, указатель на начало массива адресов импортируемых функций. Именно этот массив будет контролироваться анализатором. Размер массива и порядок элементов полностью соответствует аналогичному массиву из поля rvaINT.
- Поле rvaINT, указатель на начало массива имен импортируемых функций. Именно по этому массиву определяется количество импортируемых функций, т.к. он, в отличие от rvaIAT всегда заканчивается пустым элементом равным нулю. Так-же как и в обычном импорте вместо имени функции в этом массиве может лежать Ordinal функции вместо имени, для определения которого используются те-же маски IMAGE_ORDINAL_FLAG64 и IMAGE_ORDINAL_FLAG32.
- Поле rvaBoundIAT, теоретически должно использоваться для настройки массива rvaIAT через связанный импорт, но на практике мне такое не встречалось и буфер, на который указывает данное поле всегда был пуст.
- rvaUnloadIAT, содержит указатель на динамически формируемый массив, отвечающий за восстановление полей массива rvaINT при выгрузке библиотеки, из которой происходил импорт функций. Т.е. если из этой библиотеки были проинициализированы только две функции из десяти импортируемых, будет содержать ровно два элемента указывающих на код, отвечающий за сброс полей rvaINT каждой из функций обратно на код их инициализации.
- dwTimeStamp, поле относится к связанному импорту (rvaBoundIAT) и не интересно.
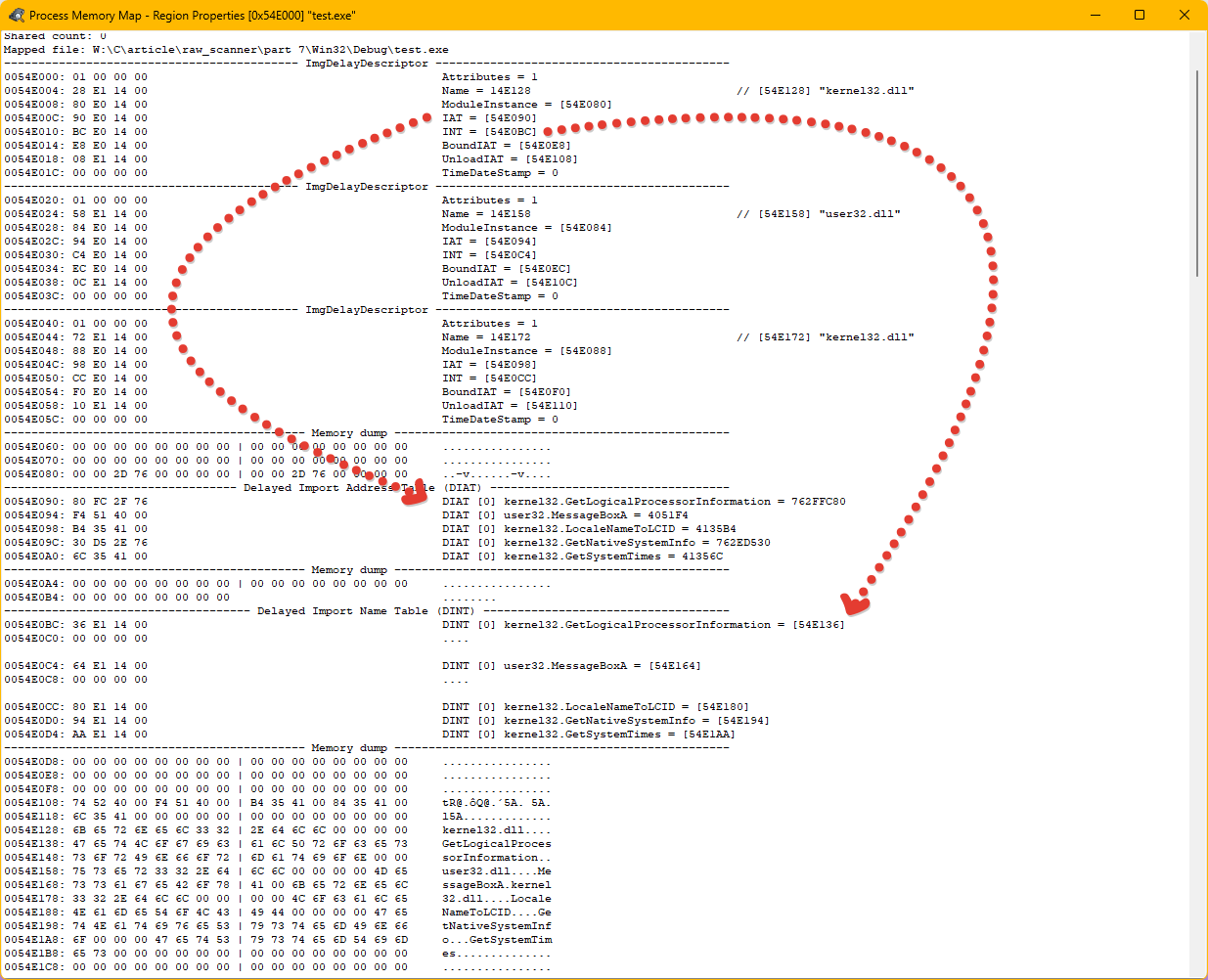
Наглядно видно, что массивы rvaIAT от всех трех дескрипторов объединены в один сплошной (левая стрелка DIAT), поэтому размерность каждого из массивов устанавливается по rvaINT (правая стрелка DINT). Ну а то, что на kernel32.dll ссылаются два дескриптора, это уже особенности как обычного импорта, так и отложенного импорта, такой вот нюанс.
Для чтения директории отложенного импорта первоначально необходимо получить её адрес:
with FNtHeader.OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT] do
begin
FDelayDir.VirtualAddress := RvaToVa(VirtualAddress);
FDelayDir.Size := Size;
end;После чего можно писать код чтения:
function TRawPEImage.LoadDelayImport(Raw: TStream): Boolean;
...
begin
Result := False;
Raw.Position := VaToRaw(DelayImportDirectory.VirtualAddress);
if Raw.Position = 0 then Exit;
IntData := 0;
DataSize := IfThen(Image64, 8, 4);
ZeroMemory(@ImportChunk, SizeOf(TImportChunk));
ImportChunk.Delayed := True;
OrdinalFlag := IfThen(Image64, IMAGE_ORDINAL_FLAG64, IMAGE_ORDINAL_FLAG32);
Raw.ReadBuffer(DelayDescr, SizeOf(TImgDelayDescr));
while DelayDescr.rvaIAT <> 0 do
begin
NextDescriptorRawAddr := Raw.Position;
Raw.Position := RvaToRaw(GetRva(DelayDescr.rvaDLLName));
if Raw.Position = 0 then Exit;
ImportChunk.OrigLibraryName := ReadString(Raw);
ProcessApiSetRedirect(ImageName, ImportChunk);
IAT := GetRva(DelayDescr.rvaIAT);
INT := GetRva(DelayDescr.rvaINT);
repeat
Raw.Position := RvaToRaw(INT);;
if Raw.Position = 0 then Exit;
Raw.ReadBuffer(IntData, DataSize);
if IntData <> 0 then
begin
if IntData and OrdinalFlag = 0 then
begin
Raw.Position := RvaToRaw(GetRva(IntData));
if Raw.Position = 0 then Exit;
Raw.ReadBuffer(ImportChunk.Ordinal, SizeOf(Word));
ImportChunk.FuncName := ReadString(Raw);
end
else
begin
ImportChunk.FuncName := EmptyStr;
ImportChunk.Ordinal := IntData and not OrdinalFlag;
end;
ImportChunk.ImportTableVA := RvaToVa(IAT);
Raw.Position := VaToRaw(ImportChunk.ImportTableVA);
if Raw.Position = 0 then Exit;
Raw.ReadBuffer(ImportChunk.DelayedIATData, DataSize);
FImport.Add(ImportChunk);
Inc(IAT, DataSize);
Inc(INT, DataSize);
end;
until IntData = 0;
Raw.Position := NextDescriptorRawAddr;
Raw.ReadBuffer(DelayDescr, SizeOf(TImgDelayDescr));
end;
end;Так-же как и в обычном импорте происходит первичная настройка размеров адресов и флагов для детектирования Ordinal значений функций, после чего идет последовательное чтение дескрипторов и обязательный контроль редиректа на виртуальные библиотеки, посредством вызова ProcessApiSetRedirect. У каждого дескриптора зачитывается массив rvaINT по которому контролируется размер массива rvaIAT (напоминаю — они синхронизированы).
Теперь нужно подключить вызов этой функции в TRawPEImage.LoadFromImage и внести изменения в код анализатора.
function CheckRemoteVA: Boolean;
begin
if Import.Delayed then
begin
if HookData.Calculated then
Result :=
(HookData.RemoteVA = Import.DelayedIATData) or
(HookData.RemoteVA = HookData.RawVA)
else
Result := HookData.RemoteVA = Import.DelayedIATData;
end
else
Result := HookData.Calculated and
(HookData.RemoteVA = HookData.RawVA);
end;
...
HookData.RemoteVA := 0;
if Import.Delayed then
HookData.RawVA := Import.DelayedIATData
else
HookData.RawVA := 0;Основные изменения произошли в CheckRemoteVA в которой обрабатывается ситуация что каждое поле в таблице может содержать одно из двух значений, либо указатель на код инициализации (в таком случае это значение будет равно Import.DelayedIATData) либо указатель на реальную функцию (HookData.RawVA если таковая будет найдена среди загруженных библиотек).
Если прямо сейчас запустить демо-пример, то результат слегка удивит:
На экране будут записи о том, что практически каждая импортированная через отложенный импорт функция перехвачена.
Можете сами попробовать раскоментировав директиву IGNORE_RELOCATIONS в начале модуля RawScanner.ModulesData.
Если проверить содержимое таких полей в памяти процесса на соответствие тем числам который записаны в теле библиотек, то действительно будут расхождения:

А расхождения будут по причине того, что изначальные адреса в массиве rvaIAT которые указывают на код инициализации каждой импортируемой функции записаны в VA адресации, т.е. с учетом базы модуля. На скриншоте это наглядно видно, в памяти библиотека расположена по адресу 0х762D0000, но в PE заголовке её база указана как 0х6B800000 отсюда и разница в значениях, на которой у анализатора идет промах.
Выйти из этой ситуации можно двумя способами, не правильным, пересчитав адреса руками из старой ImageBase в новую, и правильным — подключив обработку таблицы релокаций, расположенной в отдельной директории IMAGE_DIRECTORY_ENTRY_BASERELOC.
Как она работает: в коде приложения есть предостаточно мест, где встречается прямая VA адресация, причем встречается прямо в коде тела приложения, где налету уже не пересчитать разность баз загрузки, вот тут и выручает таблица релокаций, которую загрузчик обрабатывает при старте.
Грубо все адресное пространство процесса разделено на страницы размером в 4096 байт (диапазон адресов в рамках страницы 0..0xFFF), а таблица релокаций содержит в себе информацию о всех таких страницам и смещениям в них (в этом-же диапазоне) по которым будут расположены базозависимые адреса.
Выглядит это следующим образом, в директории IMAGE_DIRECTORY_ENTRY_BASERELOC идет массив структур:
TImageBaseRelocation = record
VirtualAddress: DWORD;
SizeOfBlock: DWORD;
end;Поле VirtualAddress, содержит RVA адрес, который указывает на конкретную страницу, содержащую адреса требующие коррекции базы.
Поле SizeOfBlock содержит общий размер (в байтах) всех смещений в рамках страницы плюс размер самого заголовка. Т.е. грубо если на странице встречаются шесть адресов которым требуется пересчет, SizeOfBlock = Count * SizeOf(Word) + SizeOf(TImageBaseRelocation) = 20 байт.
Сами блоки представляют из себя двухбайтовое значение в котором старшие 4 бита являются флагом определяющим тип блока, а оставшиеся 12 бит непосредственно офсетом в диапазоне 0..0хFFF.
Типов блоков много, но реально в РЕ файле будет всего три:
const
IMAGE_REL_BASED_ABSOLUTE = 0;
IMAGE_REL_BASED_HIGHLOW = 3;
IMAGE_REL_BASED_DIR64 = 10;Первый используется для выравнивания и не содержит никакой полезной информации, а остальные два применяются в 32 битных и 64 битных образах, указывая на то, что в младших 12 битах содержится офсет.
Код, читающий таблицу релокаций достаточно тривиален:
function TRawPEImage.LoadRelocations(Raw: TStream): Boolean;
...
begin
FRelocationDelta := ImageBase - FNtHeader.OptionalHeader.ImageBase;
if not Image64 then
FRelocationDelta := DWORD(FRelocationDelta);
Result := FRelocationDelta = 0;
if Result then Exit;
Reloc := FNtHeader.OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_BASERELOC];
if (Reloc.VirtualAddress = 0) or (Reloc.Size = 0) then Exit;
Raw.Position := RvaToRaw(Reloc.VirtualAddress);
if Raw.Position = 0 then Exit;
MaxPos := Raw.Position + Reloc.Size;
while Raw.Position < MaxPos do
begin
Raw.ReadBuffer(ImageBaseRelocation, SizeOf(TImageBaseRelocation));
Dec(ImageBaseRelocation.SizeOfBlock, SizeOf(TImageBaseRelocation));
for I := 0 to Integer(ImageBaseRelocation.SizeOfBlock shr 1) - 1 do
begin
Raw.ReadBuffer(RelocationBlock, SizeOf(Word));
case RelocationBlock shr 12 of
IMAGE_REL_BASED_HIGHLOW,
IMAGE_REL_BASED_DIR64:
FRelocations.Add(Pointer(RvaToRaw(ImageBaseRelocation.VirtualAddress + RelocationBlock and $FFF)));
end;
end;
end;
Result := True;
end;Самой первой строкой рассчитывается дельта, означающая разницу между текущей базой загрузки и изначально указанной в РЕ заголовке.
Если разница отсутствует (равна нулю), т.е образ был загружен по тому адресу, какой указал разработчик при компиляции, то смысла грузить таблицу релокаций нет, т.к. все базозависимые адреса содержат актуальные значения.
Ну а дальше последовательно читаются все записи по каждой странице, на основе размера, указанного в заголовке каждой TImageBaseRelocation.
Реальный адрес, который требует перерасчета, равен RVA адресу страницы + офсету, указанному в блоке.
Информация по каждой отдельной странице идет сразу же за окончанием данных по предыдущей, для выравнивания используются блоки IMAGE_REL_BASED_ABSOLUTE.
После того как таблица релокаций прочитана, её необходимо применить к текущему образу файла, считанного с диска:
procedure TRawPEImage.ProcessRelocations(AStream: TStream);
...
begin
if FRelocationDelta = 0 then Exit;
Reloc := 0;
AddrSize := IfThen(Image64, 8, 4);
for var RawReloc in FRelocations do
begin
AStream.Position := Int64(RawReloc);
AStream.ReadBuffer(Reloc, AddrSize);
Inc(Reloc, FRelocationDelta);
AStream.Position := Int64(RawReloc);
AStream.WriteBuffer(Reloc, AddrSize);
end;
end;Код вообще тривиальный, просто бежим по рассчитанным при чтении таблицы релокаций адресам и прибавляем к каждому дельту.
И теперь, если добавить перед загрузкой таблицы отложенного импорта следующий код, то демо-пример заработает так как нужно:
procedure TRawPEImage.LoadFromImage;
...
begin
if LoadRelocations(Raw) then
ProcessRelocations(Raw);
LoadDelayImport(Raw);
...
end;Код к седьмой главе для самостоятельного изучения доступен по этой ссылке.
8. TLS калбэки и детектирование модификации кода.
На текущем этапе анализатору доступна практически вся необходимая информация об удаленном процессе, за исключением адресов TLS калбэков, которые выполняются ДО точки входа каждого модуля. Про них я уже писал ранее поэтому останавливаться на разъяснениях не буду, сразу покажу код для получения их адресов.
Адреса калбэков расположены в виде массива, на начало которого указывает структура _IMAGE_TLS_DIRECTORY32/64, а если точнее её поле AddressOfCallBacks. Данная структура расположена в директории IMAGE_DIRECTORY_ENTRY_TLS, поэтому первым шагом надо получить её адрес:
with FNtHeader.OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_TLS] do
begin
FTlsDir.VirtualAddress := RvaToVa(VirtualAddress);
FTlsDir.Size := Size;
end;Сама структура выглядит следующим образом (на примере 64 битной её версии):
_IMAGE_TLS_DIRECTORY64 = record
StartAddressOfRawData: ULONGLONG;
EndAddressOfRawData: ULONGLONG;
AddressOfIndex: ULONGLONG; // PDWORD
AddressOfCallBacks: ULONGLONG; // PIMAGE_TLS_CALLBACK *;
SizeOfZeroFill: DWORD;
Characteristics: DWORD;
end;Первые четыре поля в действительности являются указателями, поэтому размер в зависимости от битности образа исполняемого файла меняется (4 и 8 байт).
Адреса, содержащиеся в данных полях, идут в VA адресации и загрузчик при старте приложения (точнее при загрузке модуля) производит их актуализацию посредством секции релоков.
Поля StartAddressOfRawData, EndAddressOfRawData и SizeOfZeroFill отвечают за размеры шаблона TLS, это грубо говоря блок данных, который копируется в TLS секцию каждого потока структуры TEB (Thread Environment Block) при старте потока.
Чтобы было понятней — при помощи этого механизма работают такие вещи как threadvar, т.е. переменные, которые содержат данные, принадлежащие только текущему потоку.
AddressOfIndex и Characteristics — тоже относятся к этому механизму и не интересны, все что нужно получить из этой структуры, это значение поля AddressOfCallBacks. Он указываем на массив VA адресов заканчивающийся нулем.
В памяти процесса это выглядит вот таким образом:

Сам код загрузки TLS калбэков:
function TRawPEImage.LoadTLS(Raw: TStream): Boolean;
function TlsVaToRva(Value: ULONG_PTR64): DWORD;
begin
Result := Value - NtHeader.OptionalHeader.ImageBase
end;
begin
Result := False;
Raw.Position := VaToRaw(TlsDirectory.VirtualAddress);
if Raw.Position = 0 then Exit;
AddrSize := IfThen(Image64, 8, 4);
// пропускаем 3 поля IMAGE_TLS_DIRECTORYхх:
// StartAddressOfRawData + EndAddressOfRawData + AddressOfIndex
// становясь, таким образом, сразу на позиции AddressOfCallBacks
Raw.Position := Raw.Position + AddrSize * 3;
Counter := 0;
TlsCallbackRva := 0;
// зачитываем значение AddressOfCallBacks
Raw.ReadBuffer(TlsCallbackRva, AddrSize);
// если цепочка колбэков не назначена - выходим
if TlsCallbackRva = 0 then Exit;
// позиционируемся на начало цепочки калбэков
Raw.Position := RvaToRaw(TlsVaToRva(TlsCallbackRva));
if Raw.Position = 0 then Exit;
repeat
Raw.ReadBuffer(TlsCallbackRva, AddrSize);
if TlsCallbackRva <> 0 then
begin
Chunk.EntryPointName := 'Tls Callback ' + IntToStr(Counter);
Chunk.AddrVA := RvaToVa(TlsVaToRva(TlsCallbackRva));
Chunk.AddrRaw := VaToRaw(Chunk.AddrVA);
FEntryPoints.Add(Chunk);
Inc(Counter);
end;
until TlsCallbackRva = 0;
end;Он очень простой, читается поле IMAGE_TLS_DIRECTORYхх.AddressOfCallBacks и если оно не равно нулю, то вычитываются все адреса, пока не дойдем до нулевого.
Теперь несмотря на то, что все необходимые анализатору адреса получены, нужно выполнить некоторые подготовительные действия.
Во первых — часть известных анализатору функций не являются исполняемыми, например экспортируемые NTDLL.DLL функции NlsMbCodePageTag и NlsMbOemCodePageTag в действительности являются указателями на таблицы кодовых страниц, которые сформирует загрузчик и в образе данной библиотеки вообще указывают в пустоту между секциями .data и .pdata, а это приводит к тому что невозможно узнать их RAW адрес, т.к. он по факту отсутствует, ибо RVA не принадлежит ни одной из секций.
Ну или функция RtlNtdllName, которая является указателем на строку «ntdll.dll».
Такие функции нужно отметить, как «не исполняемые», чтобы анализатор пропускал их при проверке, иначе будет FalsePositive реакция.
function TRawPEImage.IsExecutable(RvaAddr: DWORD): Boolean;
const
ExecutableCode = IMAGE_SCN_CNT_CODE or IMAGE_SCN_MEM_EXECUTE;
...
begin
Result := GetSectionData(RvaAddr, SectionData);
if Result then
begin
PointerToRawData := FSections[SectionData.Index].PointerToRawData;
if FNtHeader.OptionalHeader.SectionAlignment >= DEFAULT_SECTION_ALIGNMENT then
PointerToRawData := AlignDown(PointerToRawData, DEFAULT_FILE_ALIGNMENT);
Inc(PointerToRawData, RvaAddr - SectionData.StartRVA);
Result :=
(PointerToRawData < FSizeOfFileImage) and
(FSections[SectionData.Index].Characteristics and ExecutableCode = ExecutableCode);
end;
end;Задача этой функции проверить, принадлежит ли переданный адрес какой-либо секции, и если принадлежит, то уточнить — выставлены ли у секции флаги наличия кода и разрешения на исполнение. Каждая функция, полученная через таблицу экспорта, должна быть проверена этим кодом.
Во-вторых, есть один очень сложный момент, который не получилось у меня «нормально» решить, дело в том, что в памяти процесса может быть загружено несколько одинаковых библиотек, но из разных директорий. Особенно это актуально для comctl32.dll.
К примеру приложение без манифеста загрузит comctl32.dll пятой версии, работает и вдруг в какой-то момент времени загружает еще одну библиотеку, у которой в таблице импорта указана HIMAGELIST_QueryInterface, которая отсутствует в пятой comctl32, но вполне себе присутствует в шестой, и именно шестая версия comctl32.dll и будет загружена в адресное пространство процесса, а весь остальной импорт у этой новой библиотеки будет перенаправлен либо на comctl32.dll от шестой версии, либо пятой, либо вообще в разнобой (и такая ситуация встретилась). Все зависит от конкретной реализации загрузчика в текущей операционной системе.
Другая ситуация: например я делаю библиотеку A.DLL которая статически слинкована на библиотеку B.DLL через таблицу импорта, после чего, делаю две копии библиотеки B.DLL в разных папках и загружаю их обе через LoadLibrary(), после чего гружу уже A.DLL и тут опять не понятно, в зависимости от ОС адреса импорта в A.DLL будут направлены либо на первую загруженную B.DLL, либо на вторую, причем еще есть нюанс — если одна из B.DLL будет расположена в папке с A.DLL то загрузчик будет линковать импорт уже на неё, причем если она не загружена — то с одновременной загрузкой.
А еще же есть Hard-import link, когда у импортируемой функции указывается либо относительный, либо полный путь к библиотеке, такие ситуации загрузчик обрабатывает особым способом.
В итоге я решил не переусложнять код и поступил следующим образом. У класса TRawPEImage ввел поле RelocatedImages: TList а в методе TRawModules.AddImage добавил проверку, если образ с таким именем уже присутствует в списке загруженных, то он добавляется не в общий список, а в список RelocatedImages уже присутствующего модуля. После чего реализовал следующие две функции:
function CheckImageAtAddr(Image: TRawPEImage; CheckAddrVA: ULONG_PTR64): Boolean;
begin
Result := (Image.ImageBase < CheckAddrVA) and
(Image.ImageBase + UInt64(Image.VirtualSizeOfImage) > CheckAddrVA);
end;
function TRawPEImage.GetImageAtAddr(AddrVA: ULONG_PTR64): TRawPEImage;
begin
Result := Self;
if (RelocatedImages.Count > 0) and not CheckImageAtAddr(Self, AddrVA) then
begin
for var Index := 0 to RelocatedImages.Count - 1 do
if CheckImageAtAddr(RelocatedImages[Index], AddrVA) then
begin
Result := RelocatedImages[Index];
Break;
end;
end;
end;Первая проверяет, принадлежит ли переданный VA адрес области памяти, в которой располагается идущий первым параметром образ РЕ файла.
Вторая же просто идет по списку альтернативных образов и ищет тот, которому принадлежит адрес, возвращая результатом либо себя, либо перенаправленный РЕ файл.
Дешево и сердито :)
Третий момент, код проверяемой функции может быть очень маленький, причем сама функция может быть расположена в самом конце секции. Если проверять модификацию тела функций сверкой первых 64 байт, то может произойти ситуация что эти 64 байта захватят данные, которые в физическом образе файла уже принадлежат совершенно другой секции, т.е. когда файл будет загружен, эти данные будут расположены по совершенно другому адресу, не так как в бинарном файле.
dclIndyProtocols270.bpl export: Finalize
Expected: B8 1C 4B 42 23 E8 F2 BB FF FF C3 90 ! FF 25 04 A1 42 23 8B C0...
Present: B8 1C 4B 42 23 E8 F2 BB FF FF C3 90 ! 00 00 00 00 00 00 00 00...Например, вот так выглядит код функции Finalize, строчка Expected указывает на данные, которые были прочитаны из образа файла на диске, а строчка Present на прочитанные из памяти. Восклицательным знаком я отделил данные, которые относятся к следующей секции. Если вы разбираетесь в машинных кодах то сразу можете заметить что последние два байта перед восклицательным знаком соответствуют опкодам инструкций RET И NOP, и можно на их основе узнать об окончании тела функции, но дело в том что вместо них там может быть и JMP, а так-же другие варианты передачи управления ранее по коду, да и подключение в код фреймворка собственного дизассемблера я решил избыточным чтобы разбираться с такими ситуациями, поэтому поступил проще, а именно добавил следующую функцию:
function TRawPEImage.FixAddrSize(AddrVA: ULONG_PTR64;
var ASize: DWORD): Boolean;
...
begin
AddrRva := VaToRva(AddrVA);
Result := GetSectionData(AddrRva, Data);
if Result then
begin
if Data.StartRVA + Data.Size < AddrRva + ASize then
ASize := Data.StartRVA + Data.Size - AddrRva;
end;
end;Её задача проверять выход VA адреса за диапазон секции, и корректировать переданный размер.
И вот только теперь можно расширить анализатор, добавив в него проверку тела функций на их модификацию:
procedure TPatchAnalyzer.CompareBinary(AddrVa: ULONG_PTR64; AddrRaw: DWORD;
const FuncName: string; Module: TRawPEImage);
const
DefaultBuffSize = 64;
...
begin
Inc(FAnalizeResult.Code.Scanned);
SetLength(RawBuff, DefaultBuffSize);
SetLength(RemoteBuff, DefaultBuffSize);
BuffSize := DefaultBuffSize;
Module.FixAddrSize(AddrVA, BuffSize);
// зачитываем блок из файла
FRaw.Position := AddrRaw;
FRaw.ReadBuffer(RawBuff[0], BuffSize);
// и из памяти
if not ReadRemoteMemory(FProcessHandle, AddrVA,
@RemoteBuff[0], BuffSize) then
Exit;
if not CompareMem(@RawBuff[0], @RemoteBuff[0], BuffSize) then
begin
Data.Patched :=
CheckPageSharing(AddrVA, SharedCount) and
(SharedCount = 0);
// блоки не совпали
// отдаем на анализ внешнему обработчику, если таковой назначен
if Assigned(FProcessCodeHook) then
begin
Data.ProcessHandle := FProcessHandle;
Data.Image64 := Module.Image64;
Data.ImageBase := Module.ImageBase;
Data.ExportFunc := ChangeFileExt(Module.ImageName, '.' + FuncName);
Data.AddrVA := AddrVA;
Data.RawOffset := AddrRaw;
Data.Raw := @RawBuff[0];
Data.Remote := @RemoteBuff[0];
Data.BufSize := BuffSize;
FProcessCodeHook(Data);
end;
end;
end;Функция очень простая по своей сути, на вход приходит два адреса, AddrVa — адрес функции в адресном пространстве процесса, AddrRaw — офсет в образе файла на диске. По этим адресам читается 64 байта (или меньше — коррекция размера идет через FixAddrSize) после чего оба блока сравниваются. При расхождении вызывается внешний обработчик, который будет разбираться, что именно с этими буферами не так.
Подключить вызов этой процедуры нужно в двух местах, в сканировании экспорта, добавив в конец следующий кусок кода:
// 1. Если функция перенаправлена в другой модуль - пропускаем проверку
if Exp.OriginalForvardedTo <> EmptyStr then
begin
Inc(FAnalizeResult.Code.Skipped);
Continue;
end;
// 2. Если функция не содержит кода - пропускаем проверку
if not Exp.Executable then
begin
Inc(FAnalizeResult.Code.Skipped);
Continue;
end;
// после того как удостоверились что запись в таблице экспорта валидная
// и не перенаправлена в другой модуль, то тогда
// проверяем бинарный код функции
CompareBinary(Exp.FuncAddrVA, Exp.FuncAddrRaw, Exp.ToString, Module);Этим будет проверятся тело каждой экспортируемой функции каждого известного анализатору модуля.
А также сделать новый метод, в котором будет производиться сканирование всех EntryPoint и TLS калбэков загруженных модулей:
procedure TPatchAnalyzer.ScanEntryPoints(Index: Integer; Module: TRawPEImage);
begin
for var I := 0 to Module.EntryPointList.Count - 1 do
with Module.EntryPointList.List[I] do
CompareBinary(AddrVA, AddrRaw, EntryPointName, Module);
end;Причем вызываться она будет для всех модулей, которые не являются COM+ (содержащими только IL код)
if not Module.ComPlusILOnly then
ScanEntryPoints(Index, Module);И в заключение, пожалуй, стоит рассмотреть код самого калбэка, в котором принимается решение — была ли модификация тела функции или нет.
Для его работы по-хорошему нужен полноценный дизассемблер, но в рамках статьи я посчитал это избыточным (она и так вышла достаточно объемная) поэтому заменил его на простенький дизассемблер длин, взяв первый попавшийся на GIT и портировав его на Delphi. Он такой — неказистый, ошибается на некоторых сложных инструкциях, впрочем, его задача попытаться подсказать коду в калбэке где может находится инструкция RET, означающая конец функции и с ней он в 98 процентов случаев справляется успешно.
Код обработчика (если подсократить проверки) будет следующий:
procedure ProcessCodeHook(const Data: TCodeHookData);
...
begin
// поиск конца функции
rawCursor := Data.Raw;
I := Data.BufSize;
while I > 0 do
begin
OpcodeLen := ldisasm(rawCursor, Data.Image64);
Dec(I, OpcodeLen);
// просто ищем инструкцию RET
if (OpcodeLen = 1) and (rawCursor^ = $C3) then
Break;
Inc(rawCursor, OpcodeLen);
end;
if CompareMem(Data.Raw, Data.Remote, Data.BufSize - I) then
Exit;
Writeln(' Expected: ' + ByteToHexStr(Data.Raw, Data.BufSize - I));
Writeln(' Present: ' + ByteToHexStr(Data.Remote, Data.BufSize - I));
end;Задача данного кода распознать конец «коротких» функций (опираясь на дизассемблер длин инструкций) и при нахождении такового выполнить повторную проверку.
Дело в том, что, когда идут две три инструкции подряд, из которых изменена только последняя, без такого дополнительного контроля длины функции все три будут выведены как измененные, а здесь идет подстраховка для такой ситуации.
И теперь, если запустить демо-пример на выполнение из под отладчика, он (будучи уже настроенным на сканирование процесса родителя) покажет состояние запущенной Delphi (ну или проводника если запуск будет из под него).
Правда придется немного подождать — сканирование такого тяжелого процесса как bds.exe, с обильным рантаймом, на который нет системного кэша, не сильно быстрое по времени и может занять секунд 20-30.
Что из неё можно получить:
1. самая первая запись говорит о том, что в rtl270.bpl в таблице импорта перехвачена запись ведущая на kernel32.RaiseException и перехватчик ведет куда-то вглубь exceptiondiag270.bpl
Это работа самой delphi, которая при возникновении исключений в DesignTime наконец то начала показывать хоть какой-то более-менее читаемый стек, ведущий к ошибке.
2. далее идут две модифицированных функции из того же rtl270.bpl, это HandleAutoException и RaiseLastOSError. Это постаралась установленная на моей машине EurekaLog установив перехватчик прямо в теле функций, ведущий куда-то вглубь EurekaLogExpert270.bpl. На скриншоте, конечно, этого не видно, т.к. показаны только модифицированные байты начала функций, но, если их обработать через дизассемблер, картина станет более понятной.
3. Ну и наконец кто-то влез в win32debugide270.bpl модифицировав начало функции TNativeDebugger.DoShowException. Это уже установленный у меня GExpert балуется, перенаправляя вызов функции вглубь GExpertsRS104.dll чтобы вместо штатного окошка показывать расширенное с кнопками «игнорировать данный тип исключения» и т.п. — кстати удобная вешь!
Если же подключить полноценный дизассемблер, то все перехваты будут выведены в более приемлемом виде:

Вот теперь на руках есть готовый инструмент, который можно в принципе даже в текущем виде спокойно подключить к своему проекту. Попробуйте с ним «поиграться» подключаясь к активным процессам и понаблюдать что именно в них происходит. Иногда встречаются очень интересные и неожиданные вещи.
Одна из них состоит в том — что половина библиотек, использующихся в составе вашего ПО могут быть заменены прямо на лету. Я даже сам не знал о таком поведении, но его легко можно воспроизвести установив редистрибутейлы от майкрософт, которые в процессе установки должны заменить часть библиотек на обновленные аналоги (ну или отработает теневое обновление не требующее перезагрузки Windows). Если в этот момент произвести сканирование памяти процесса, то можно обнаружить что часть библиотек перемаплена на их старые образы, которые ОС перенесла при обновлении в каталог C:\Config.Msi\
Например msvcp140.dll вдруг стала C:\Config.Msi\5761a70b.rbf и т.д. а вот в списках загрузчика изменений не произошло и там честно указано что по такому-то адресу лежит msvcp140.dll.
Эта ситуация не обрабатывается кодом анализатора, но о ней нужно знать, если вдруг кто захочет добавить детект изменений после обновления библиотек.
Ну а код к заключительной главе доступен для самостоятельного изучения по этой ссылке.
9. В качестве заключения
В итоге по шагам, чтобы произвести полноценный анализ изменений данных в стороннем процессе нужно:
- уметь читать данные невзирая на битность текущего и удаленного процессов
- уметь читать списки загрузчика из удаленного процесса
- уметь читать таблицы экспорта/импорта/отложенного импорта, а также точек входа и TLS калбэков
- уметь обрабатывать форвард перенаправления функций и ApiSet редиректы
Вполне вероятно, что вам пригодятся следующие ссылки:
По формату исполняемых файлов:
An In-Depth Look into the Win32 Portable Executable File Format, Part 2
PE Format
От зеленого к красному: Глава 2: Формат исполняемого файла ОС Windows. PE32 и PE64. Способы заражения исполняемых файлов.
Дополнительная информация по ApiSet:
Api set resolution/
Runtime DLL name resolution: ApiSetSchema — Part I
Runtime DLL name resolution: ApiSetSchema — Part II
https://github.com/lucasg/Dependencies/blob/master/ClrPhlib/include/ApiSet.h
Немного по работе загрузчика:
What Goes On Inside Windows 2000: Solving the Mysteries of the Loader
https://doxygen.reactos.org/d1/d97/ldrtypes_8h_source.html
LDR_DATA_TABLE_ENTRY
Подробная статья по отложенной загрузке библиотек:
Understand the delay load helper function
О порядке поиска библиотек динамической компоновки:
Dynamic-link library search order
Для любителей погрузиться в тему, информация о методе динамического переключения контекста кода:
Knockin’ on Heaven’s Gate – Dynamic Processor Mode Switching
How to Hook 64-Bit Code from WOW64 32-Bit Mode
Вообще задумка получилась достаточно удобной, полгода назад, когда я реализовал первый вариант данного фреймворка я тестировал его на многих процессах, запущенных у меня на виртуалках и он четко показывал, как тот-же офис, или браузеры делают у себя внутри «песочницу» чтобы не допустить побега кода наружу, перехватывая кучу функций на самих себя. Или как идет работа с отложеным импортом с перенаправлениями на заглушки, просто выставляющие код ошибки (в дельфи штатно такое не получится сделать — только ручками). Ну или показывал работу защиты ПО, например высвечивая перехват DbgUiRemoteBreakin с перенаправлением на TerminateProcess (типа защита от аттача отладчика к активному процессу) :)
Код для восьмой главы в принципе является абсолютно самодостаточным и его можно спокойно использовать в собственных проектах, или можно взять уже расширенную версию данного кода, которую я применяю в своих проектах.
В ней уже есть работа с внешним дизассемблером, логирование, фильтрация и многое другое.
Финальный вариант фреймворка включен в состав более обширного по возможностям опенсорсного продукта Process Memory Map (PMM), задача которого максимально знать, что происходит в удаленных процессах и выводить это в читаемом виде, кстати именно с него делались все скриншоты к статье.
https://github.com/AlexanderBagel/ProcessMemoryMap
РММ является одним из моих основных инструментов в повседневной работе и на текущий момент времени в него добавлена вся информация, которая когда-либо мне была нужна в процессе разработки. В планах, конечно, еще много что есть, потихонечку буду расширять, но не все сразу.
Засим откланиваюсь.
Если вы читаете этот текст, значит вы прочли статью внимательно и до конца.
Комментарии (24)




gogibeet
00.00.0000 00:00+1вообще выглядит интересно , но есть 2 вопроса:
1. почему именно делфи?
2. если я правильно понял суть статьи то подход живет ровно до момента пока хук не встанет на метод проверки на хуки)
Rouse Автор
00.00.0000 00:001) а почему бы и нет?
2) этот подход должен применятся в стороннем ПО, а не в том, которое будет анализироваться, и в котором живут все перехваты.

Zhuikoff
00.00.0000 00:00+2Иногда чтобы понять самому куда идти дальше нужно "выплеснуть на бумагу". Респект!
vitokop
00.00.0000 00:00+132 процессы в 64 OS:
\system32 перенаправляется в \SysWOW64 самой OS, т.е. для Процесс- 2 \SysWOW64 самой OS представляется как \system32
для доступа к "истинной 64 разрядной" \system32 Процесс- 32 должен использовать
C:\Windows\Sysnative\
т.к. мы "залезли" из 64 в 32, то PPEB_LDR_DATA->Ldr будут ссылаться на \system32, которая
для них "истинная от самой 64 OS"
vitokop
00.00.0000 00:00+1На примере delphi32.exe Delphi 7 в Windows 10 64
Вид на delphi32.exe из 64 битного процесса (ImageBase,OEP, SizeImage)
Из 64 процесса за реальным 64-процессом delphi32.exe в 64 OS
C:\Program Files (x86)\Borland\Delphi7\Bin\delphi32.exe
base: $0000000000400000 oep: $000000000041FEB4 size: $00089000 (561152)
C:\Windows\SYSTEM32\ntdll.dll
base: $00007FFE95540000 oep: $0000000000000000 size: $001EE000 (2023424) <<-- 64 ntdll
C:\Windows\System32\wow64.dll
base: $00007FFE94850000 oep: $00007FFE948670D0 size: $00053000 (339968)
C:\Windows\System32\wow64win.dll
base: $00007FFE948B0000 oep: $00007FFE948BF030 size: $0007C000 (507904)
C:\Windows\System32\wow64cpu.dll
base: $0000000077CD0000 oep: $0000000077CD12A0 size: $00009000 (36864)<ВСЕГО 5 МОДУЛЕЙ>
а вот как это видит сама delphi32.exe и другие 32 процессы
0 delphi32.exe
00400000 0041FEB4 00089000
1 ntdll.dll
77CE0000 00000000 0019E000 <<--- 32 ntdll как и все остальные
2 KERNEL32.DLL
76AD0000 76AF0140 000E0000
3 KERNELBASE.dll
76BB0000 76CC5440 00201000
.................................268 ncryptsslp.dll
6E570000 6E57A720 0001F000
268 модулей (267 DLL)Смотрим из 64 процесса в 32 процесс
C:\Program Files (x86)\Borland\Delphi7\Bin\delphi32.exe
C:\Windows\SysWOW64\ntdll.dll
C:\Windows\SysWOW64\KERNEL32.DLL
C:\Windows\SysWOW64\KERNELBASE.dll
............................................
C:\Program Files (x86)\Borland\Delphi7\Bin\rtl70.bpl
.............................................
C:\Windows\SysWOW64\cryptnet.dll
C:\Windows\SysWOW64\ncryptsslp.dll>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
Взгляд из любого 32 разрядного процесса на процесс delphi32.exe
имена DLL по загрузке0 C:\Program Files (x86)\Borland\Delphi7\Bin\delphi32.exe
1 C:\Windows\SYSTEM32\ntdll.dll
2 C:\Windows\System32\KERNEL32.DLL
3 C:\Windows\System32\KERNELBASE.dll
.............................................................
8 C:\Program Files (x86)\Borland\Delphi7\Bin\rtl70.bpl
...............................................................
267 C:\Windows\System32\cryptnet.dll
268 C:\Windows\system32\ncryptsslp.dll267 модулей DLL

qw1
00.00.0000 00:00+1То есть, если сканер делать 64-битным, будет проблемой получить список модулей 32-битного процесса?
Rouse Автор
00.00.0000 00:00Да не должно быть, код универсальный и работать будет при любой битности как самой сборки так и исследуемого процесса.
vitokop
00.00.0000 00:00как решать
64-р сканер
создать из 64-р вспомагательный 32-р процесс => CreateProcess(...My32....)
My32 выполнит ВСЕ необходимое и вернет данные,например, через разделяемый map
file или просто файл
Т.е.нужно писать 32 - р приложение для этого: My32 - консольное (скрытое)
32-р сканер
Отметим, что из 32-р легче получить доступ к 64-р:
используем Windows API:
OpenProcess => и использовать LookupPrivilegeValueW; AdjustTokenPrivileges для получения привилегий доступа к 64-р процессу
NtQueryInformationProcess
NtWow64QueryInformationProcess64
NtWow64ReadVirtualMemory64
NtQueryInformationThreadструктуры:
PROCESS_BASIC_INFORMATION_WOW64
PEB64
RTL_USER_PROCESS_PARAMETERS64и другие
Rouse Автор
00.00.0000 00:00Зачем создавать 32 битную копию? 64 битный код спокойно получит всю необходимую информацию из 32 битного процесса.
qw1
00.00.0000 00:00Нет API. А вычитывание недокументированных структур из памяти опасно из-за неатомарности эти чтений. Что будет, если в процессе чтения списки изменятся?
Rouse Автор
00.00.0000 00:00Работа с недокументированными структурами всегда опасна, например буквально в том месяце вышло обновление под Win11 за номером KB5022845 (Build 22621.1265) в котором изменился размер структуры _RTL_HEAP_INFORMATION и что? :)
Ну подправили размеры и работаем дальше, делов то?

qw1
00.00.0000 00:00Непонятно, какой смысл в
EmptyStrв Delphi?Пустая строка в C#, например, это полноценный объект, и там
string.Emptyимеет смысл для экономии памяти. Но в Delphi пустая строка, ровно как и пустой динамический массив, это NULL-ссылка, т.е. указатель со значением 0.Rouse Автор
00.00.0000 00:00Насколько я помню она оставлена для обратной совместимости и кстати её использование дает мальца просадку по сравнению с просто указанием пустой строки кавычками, но... привычка, видимо я уже настолько стар что эта совместимость для меня и оставлена :)
perfect_genius
Перефразируя известное выражение, "Есть хорошие статьи, есть плохие, а есть про реверс/низкоуровневый доступ" :)
Но для "низкоуровневиков" как я такие статьи очень ценны, т.к. тема уж очень специфическая и не очень популярная, материалов Чак Норрис наплакал.
Rouse Автор
Угу, и поэтому старался по максимуму разжевать те участки по которым мало информации. То что доступно (по РЕ формату например) так, вскользь прошелся, чтобы общий контекст не терялся, иначе статья бы распухла неимоверно (и так хабр пишет что 98 минут на чтение - внезапно)