В начале февраля мы наградили победителей нашего IT‑чемпионата VK Cup. До финала дошли 80 человек, а общий призовой фонд в 4 млн рублей разделили 20 победителей — по четыре команды на каждый трек чемпионата. На Хабре мы решили сделать серию статей с разбором наиболее интересных решений по разным трекам.
Сегодня мы расскажем про трек по машинному обучению. Участники работали над улучшением рекомендаций для друзей и предсказанием взаимного добавления в друзья между пользователями ВКонтакте. Все мы пользуемся соцсетями и можем на собственном примере ощутить, как работают рекомендации друзей. Но что под капотом этого решения, откуда соцсеть знает, с кем мне стоит подружиться?
Во всём этом разобрался Иван Брагин, один из победителей чемпионата.
О решении
VK Cup «22/23 проходил в три этапа. Чтобы пробиться в финал, мы решали задачи по классификации групп на основе текстов и рекомендации постов в Дзен. В финале нас попросили решить задачу формата „возможно, вы знакомы“, но без использования полного графа.
Идея базового алгоритма очень простая: нужно посчитать общее количество друзей у пары пользователей, и чем их больше, тем вероятнее, что эти пользователи знакомы.
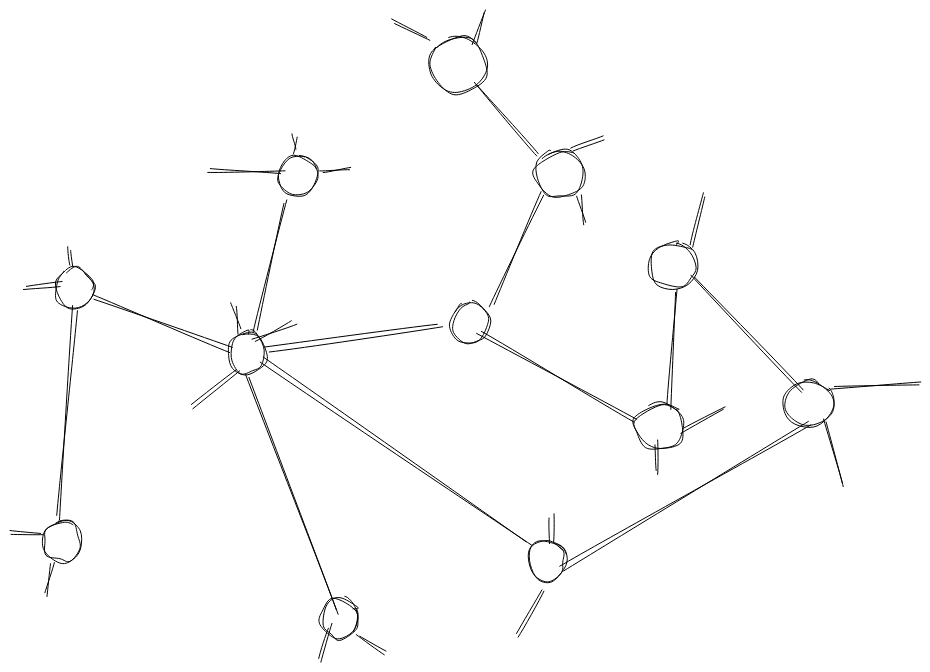
Есть огромный граф пользователей соцсети. Каждый пользователь (кружочек) в графе называется вершиной, а связь — ребром. Я предполагаю, что в графе VK более 200 миллионов вершин, каждая из которых имеет в среднем 150 рёбер. Посчитать количество общих друзей для каждой пары вершин — задача сложная, поэтому нам предложили альтернативный формат данных.
Для каждого пользователя соцсети создаётся эго‑граф — граф, состоящий из вершины этого пользователя и вершин его друзей. В эго‑графе сохраняются все рёбра.

Вершину основного пользователя, который связан со всеми другими вершинами, обозначим C, а две вершины, для которых мы хотим оценить вероятность создания связи, — U и V. Эго‑граф значительно меньше полного графа соцсети, и в нашей задаче он был ограничен тремястами вершинами. Посчитать любые срезы статистики очень просто на одном ядре и без использования большого объёма памяти. Поэтому решение задачи с использованием эго‑графов хорошо масштабируется парадигмой map‑reduce. На этапе map мы оцениваем шанс двух вершин подружиться, на этапе reduce — объединяем оценки со всего графа. В конкурсе мы решали задачу map.
Итак, у нас есть эго‑граф и мы должны спрогнозировать пять пар рёбер, которые образуются за следующую неделю. Базовое решение — взять пары, у которых максимальное количество общих друзей. Нам предоставили baseline, в котором поиск количества общих друзей реализован через скалярное произведение.
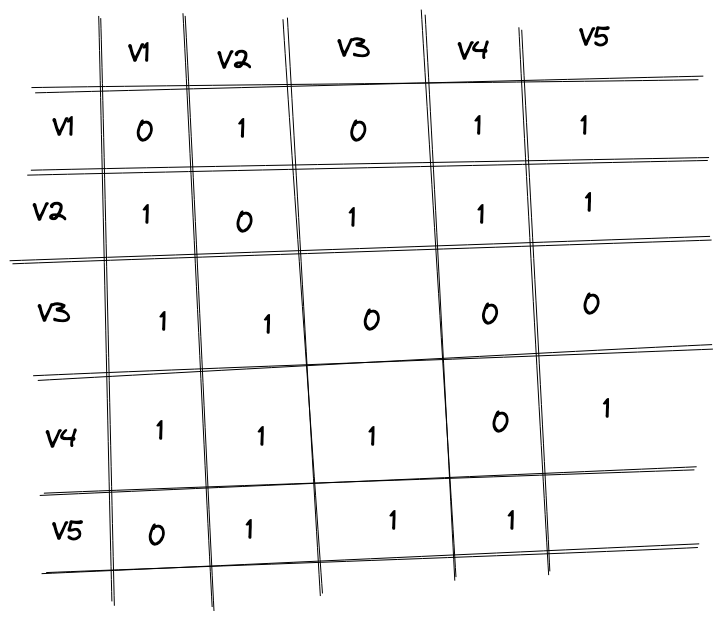
Представляем граф в виде матрицы m, вычисляем m.T.dot(m) и получаем матрицу количества общих друзей. Например, в ячейке (V1, V2) будет
то есть вершины V1 и V2 имеют двух общих друзей.
Давайте посмотрим на эго-граф выше. Две оранжевые вершины U и V имеют одного общего красного друга, а две серые вершины имеют одного общего зелёного друга. Но зелёная вершина имеет много других связей, то есть это просто активный человек, который добавляет всех, и наличие такого общего друга должно цениться ниже, чем наличие общего друга у пользователя с немногочисленными друзьями. Для этого можно взвесить одну из матриц.

Ячейка (V1, V2) теперь имеет значение перемножения первой строчки в левой матрице и второго столбца второй матрицы:
Теперь важность связи взвешена на количество друзей каждого общего друга.
Пока что я описал baseline решения, предоставленного организаторами.
В исходных данных, кроме непосредственных связей, нам предоставили информацию о дате создания дружбы и некоторых числовых характеристиках взаимодействия пользователей. Перебирая различные варианты взвешивания матриц, я пытался максимизировать качество ранжирования по метрике NDCG@5. Например, увеличить вес ячейки, если пользователи взаимодействуют, и уменьшить, если они очень давно подружились. После продолжительных страданий с настройкой матриц я понял, что надо переходить к двухстадийному ранжированию: для начала отобрать 1000 самых вероятных потенциальных рёбер по баллу от перемножаемых матриц, а потом обучить модель ранжировать этих кандидатов.
Так как я поменял себе задачу первой стадии с ранжирования на отбор кандидатов, то я сменил метрику с NDCG@5 на recall@1000 и немного ещё настроил параметры взвешивания матриц для оптимизации новой метрики. Подробности отбора кандидатов лучше посмотреть в коде (In [5]).
Теперь надо было решить совсем другую и значительно более привычную задачу. Есть пара [U, V] и бинарная разметка, где 1 — U подружится с V в ближайшие 7 дней, 0 — не подружится.

Дальше всё банально: генерируем кучу признаков, обучаем популярные модели, собираем в ансамбль и отправляем на оценку качества. Данных много, хочется рассчитать большое количество признаков, но делать это на одной машине и тем более в одном процессе слишком долго. Поэтому я перевёл все данные в Parquet и написал расчёт признаков на Spark. Не вижу смысла описывать все рассчитанные признаки, проще посмотреть в код, всё создаётся в одной ячейке. Наша конечная метрика — NDCG, а значит, надо оптимизировать не метку, а ранжирование, для этого хорошо подходит pairwise‑оптимизация. LambdaRank от lightgbm показал себя неплохо. В последний день попробовал CatBoost с QuerySoftMax‑функцией, но ничего принципиально нового не получил, кроме медленного обучения.
Огромная благодарность организаторам, которые подготовили отличные три задачи, дали полезные baseline и сделали быстрый расчёт баллов. Я два года не участвовал в конкурсах и решил вернуться. Очень рад что выбрал VK Cup, теперь хочется продолжать.
Ссылки
Отбор кандидатов и сохранение в формат Parquet
* * *
Скоро мы расскажем о других интересных решениях победителей различных треков VK Cup, следите за нашими новостями. И заглядывайте в нашу группу ВКонтакте, чтобы не пропустить регистрацию на следующий чемпионат, мы придумаем для вас много новых интересных задач.