Документ «deducing this», принятый в последний стандарт C++, вводит новый, третий тип методов классов, сочетающий в себе свойства двух уже существующих: нестатических и статических, открывающий перед нами новые горизонты:
Дедупликация большого количества кода.
Вытеснение CRTP (Curiously Recuring Template Pattern) на свалку истории, его замена более простой и очевидно понятной записью.
Рекурсивные лямбды.
И другое.
Но прежде чем рассмотреть само нововведение и его практические применения, углубимся немного в историю и попытаемся понять, почему в нем собственно возникла необходимость.
Мотивация
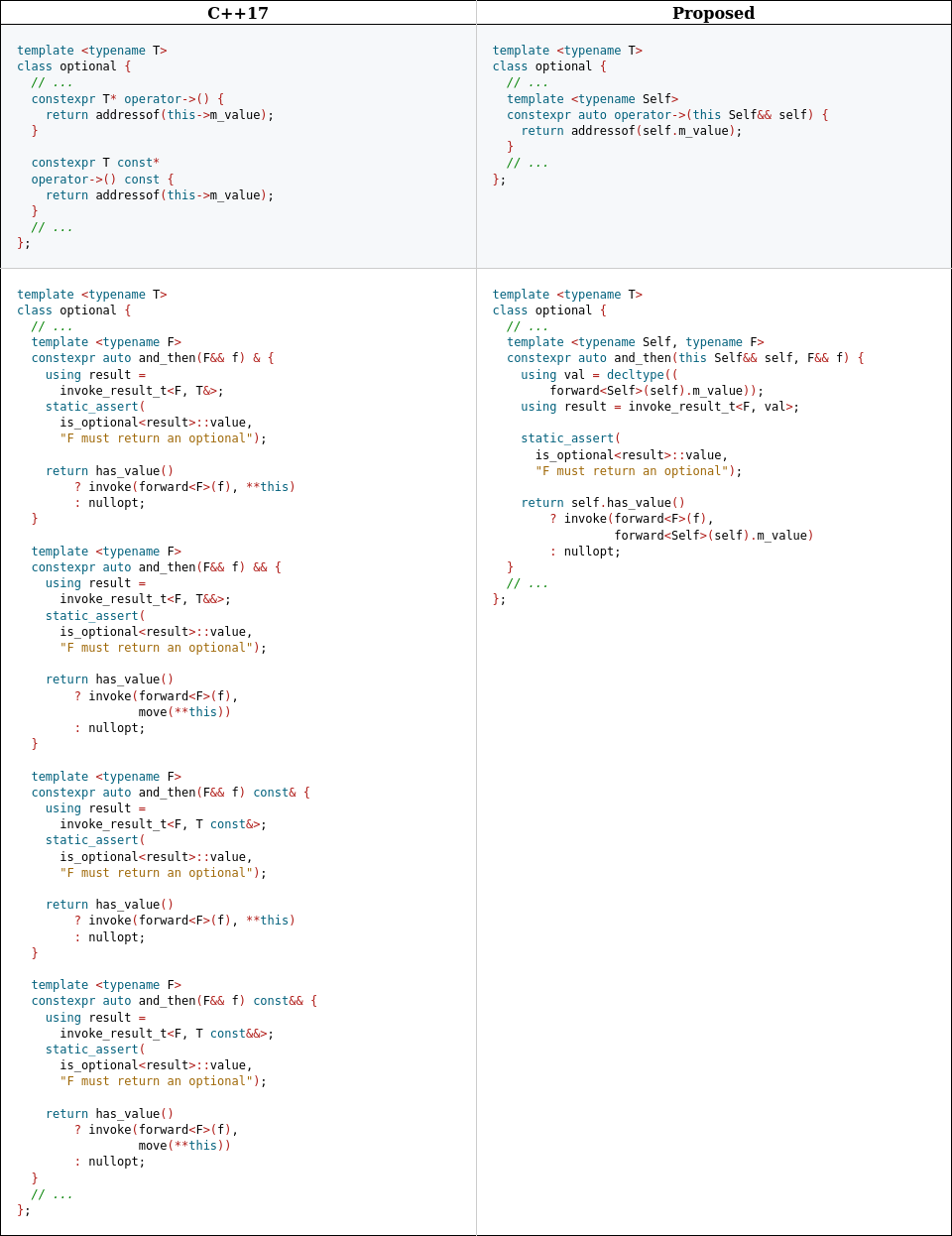
Начиная с C++03, методы могут иметь cv-квалификаторы, так что стали возможны сценарии, когда есть необходимость как в const, так и не-const перегрузке определенного метода (для краткости воздержимся от рассмотрения volatile перегрузок).
Во многих случаях между их логикой нет никакой разницы — отличаются лишь квалификаторы используемых типов, так что приходится или копировать определение, подгоняя квалификаторы, или использовать такие механизмы как const_cast:
class TextBlock {
public:
char const& operator[](size_t position) const {
// ...
return text[position];
}
char& operator[](size_t position) {
return const_cast<char&>(
static_cast<TextBlock const&>(*this)[position]
);
}
// ...
};Начиная с C++11, методы могут иметь также и ref-квалификаторы, так что теперь вместо двух перегрузок одного метода нам могут понадобиться четыре: &, const&, &&, const&&, и у нас есть три способа решить данную задачу (ссылка на код, приведенный ниже):
Писать реализацию одного метода четырежды.
Делегировать три перегрузки четвертой, используя
static_castиconst_cast.Использовать вспомогательную шаблонную функцию.

Но ни один из этих способов не избавляет нас от необходимости четырежды определять практически один и тот же метод.
Если бы могли написать что-то вроде функции ниже, но ведущей себя как член класса, это решило бы все наши проблемы:
template <typename T>
class optional {
// ...
template <typename Opt>
friend decltype(auto) value(Opt&& o) {
if (o.has_value()) {
return forward<Opt>(o).m_value;
}
throw bad_optional_access();
}
// ...
};Но мы не можем. Точней, не могли. До C++23.
Мечты воплощаются в реальность
Теперь же мы можем определять методы, явно принимающие в качества аргумента объект, над которым они были вызваны:
struct X {
template <typename Self>
void foo(this Self&&) { }
};
void example(X& x) {
x.foo(); // Self = X&
move(x).foo(); // Self = X
X{}.foo(); // Self = X
}Таким образом, теперь мы можем переписать всю ту простыню кода, реализующую метод value у optional, гораздо более компактно, меньше чем в десяток строк:
template <typename T>
struct optional {
template <typename Self>
constexpr auto&& value(this Self&& self) {
if (!self.has_value()) {
throw bad_optional_access();
}
return forward<Self>(self).m_value;
}Мы подчинили своим целям механизм вывода типов во всей своей мощи! И важно отметить, что это все тот же механизм, проявляющий себя в обычных шаблонных функциях и методах.
Deducing this не вносит никаких изменений в правила вывода типов, он лишь позволяет явное объявление объектного параметра (explicit object parameter) в списке аргументов методов. Параметра, который до этого в методах присутствовал лишь неявно (implicit object parameter), в виде указателя this.
Важно отметить, что вывод типов способен выводить производные типы:
struct X {
template <typename Self>
void foo(this Self&&, int);
};
struct D : X { };
void example(X& x, D& d) {
x.foo(1); // Self=X&
move(x).foo(2); // Self=X
d.foo(3); // Self=D&
}На методы, объявленные с явным объектным параметром, также накладывается ряд ограничений:
-
Они не могут быть объявлены статическими.
Причина этого заключается в том, что хоть и внешне эти функции выглядят и ведут себя как обычные нестатические методы, но внутренне они ведут себя в точности как статические: в них недоступен указатель
this, и единственный способ взаимодействовать в них с объектом класса — через явный объектный параметр.Кроме того, указатель на такие методы — это указатель на функцию, а не член класса.
Они не могут быть объявлены виртуальными.
Они не могут быть объявлены с использованием ref или cv квалификаторов.
Так как объявление явного объектного параметра уже несет в себе всю необходимую информацию о его типе:

Но есть нюансы
Однако с большой силой приходит и большая ответственность. Так, используя новый тип методов, мы должны постоянно помнить о том, насколько могуществен механизм вывода типов:
struct B {
int i = 0;
template <typename Self> auto&& f1(this Self&& self) { return forward<Self>(self).i; }
};
struct D: B {
double i = 3.14;
};Тогда как B().f1() в коде выше вернет ссылку на B::i, D().f5() вернет ссылку на D::i, так как self является ссылкой на D.
Если же мы хотим получать ссылку на B::i всегда, нам необходимо явно предусмотреть это в коде:
template <typename Self>
auto&& f1(this Self&& self) {
return forward<Self>(self).B::i;
}Другой опасностью на нашем пути может служить проблема приватного наследования. Рассмотрим следующий код:
class B {
int i;
public:
template <typename Self>
auto&& get(this Self&& self) {
return forward<Self>(self).B::i;
}
};
class D: private B {
double i;
public:
using B::get;
};
D().get(); // errorМы, казалось бы, предохранились как могли. Однако недостаточно. Мы не можем получить доступ к B::i из D, так как наследование является приватным.
Но и для этой проблемы существует решение:
class B {
int i;
public:
template <typename Self>
auto&& get(this Self&& self) {
// like_t — функция, применяющая ref и cv квалификаторы
// первого переданного типа ко второму
// Например, like_t<int&, double> = double&
return ((like_t<Self, B>&&)self).i;
}
};
class D : private B {
double i;
public:
using B::get;
};
D().get(); // now ok, and returns B::iВыполнив приведение в стиле си для избежания проверки доступа, мы реализовали желаемое поведение.
Практическое применение
Итак, немножко поговорив о сущности нововведения и об опасностях, которые могут нас поджидать при его использовании, перейдем к рассмотрению некоторых из его практических приложений.
Дедупликация кода
Это первое и самое очевидное. Помимо уже рассмотренных примеров, приведу еще несколько:
Внедрение методов в классы-наследники
Да-да, вы подумали правильно. CRTP (Curiously Recurring Template Pattern) больше не нужен. И хоть код от использования deducing this в простейшем случае ниже не становится короче, но очевидно становится более простым и интуитивно понятным.

Рекурсивные лямбды
О чем я ранее еще не упоминал — это то, что теперь мы можем определять лямбды с явным объектным параметром, благодаря чему становится возможным определение рекурсивных лямбд:
auto fib = [](this auto self, int n) {
if (n < 2) return n;
return self(n-1) + self(n-2);
};struct Leaf { };
struct Node;
using Tree = variant<Leaf, Node*>;
struct Node {
Tree left;
Tree right;
};
int num_leaves(Tree const& tree) {
return visit(overload( // <-----------------------------------+
[](Leaf const&) { return 1; }, // |
[](this auto const& self, Node* n) -> int { // |
return visit(self, n->left) + visit(self, n->right); // <----+
}
), tree);
}Передача self по значению
Передача self по значению открывает для нас возможность более естественного выражения желаемой семантики, например когда смысл метода заключается в одном лишь возврате модифицированной копии:
struct my_vector : vector<int> {
auto sorted(this my_vector self) -> my_vector {
sort(self.begin(), self.end());
return self;
}
};Но, что многие справедливо посчитают более важным применением, позволяет в некоторых случаях достичь лучшей производительности.
Например, все мы знаем, что маленькие типы во избежание порождения лишних уровней косвенности (indirection) лучше передавать по значению.
К одному из таких типов относится std::string_view. Который мы можем передавать по значению всюду: в наши функции, конструкторы, другие методы. Но только не в его собственные методы. До принятия deducing this у разработчиков стандартной библиотеки не было способов избежать разыменований указателя this в собственных методах std::string_view.
Теперь же мы можем переписать все его методы, не выполняющие модификаций, с передачей явного объектного параметра по значению, практически бесплатно этим получая улучшение производительности:
template <class charT, class traits = char_traits<charT>>
class basic_string_view {
private:
const_pointer data_;
size_type size_;
public:
constexpr const_iterator begin(this basic_string_view self) {
return self.data_;
}
constexpr const_iterator end(this basic_string_view self) {
return self.data_ + self.size_;
}
constexpr size_t size(this basic_string_view self) {
return self.size_;
}
constexpr const_reference operator[](this basic_string_view self, size_type pos) {
return self.data_[pos];
}
};Заключение
На самом деле, это далеко не все, что можно сказать про deducing this, но самое главное и основное. Целью данной статьи не являлось углубление в детали.
Если вы хотите постичь все нюансы — вы можете обратиться к оригинальному документу.
Также довольно интересы и увлекательны статьи, написанные некоторыми из его авторов: «C++23’s Deducing this: what it is, why it is, how to use it» (Sy Brand), «Copy-on-write with Deducing this» (Barry Revzin).
Любите плюсы и будьте счастливы.
Комментарии (50)

Mingun
00.00.0000 00:00+7Но есть нюансы
Комитетчики как всегда в своем репертуаре… А что ж эти нюансы в Proposed колонке не учитываются? Глядишь, преимущество в количестве и понятности кода улетучится...
Теперь же мы можем переписать все его методы, не выполняющие модификаций, с передачей явного объектного параметра по значению, практически бесплатно этим получая улучшение производительности:
Хм, неужели компилятору все еще недостаточно указания
constexprи такого коротенького тела функции, чтобы он его заинлайнил и понял, что никаких указателей быть не должно? Это что ж получается, C++ обрастает все более и более монструозным синтаксисом во имя производительности, и все зря? Тривиальнейшие конструкции все еще можно оптимизировать? Или все эти конструкции, авторы каждой из которых говорят "смотрите, как стало понятно и лаконично написано" не работают, если всю эту понятность и лаконичность не обмазать десяткомmove(forward(auto&&))?
eoanermine Автор
00.00.0000 00:00Хм, неужели компилятору все еще недостаточно указания
constexprи такого коротенького тела функции, чтобы он его заинлайнил и понял, что никаких указателей быть не должно? Это что ж получается, C++ обрастает все более и более монструозным синтаксисом во имя производительности, и все зря? Тривиальнейшие конструкции все еще можно оптимизировать? Или все эти конструкции, авторы каждой из которых говорят "смотрите, как стало понятно и лаконично написано" не работают, если всю эту понятность и лаконичность не обмазать десяткомmove(forward(auto&&))?Одно дело — оптимизации, которые компилятор может (или не может) выполнить, другое — возможность явно описать то, что ты хочешь.
Стандарт, за редкими исключениями, не говорит о возможных оптимизациях, и они — явно не то, на что следует полагаться разработчику при написании кода.
Mingun
00.00.0000 00:00+5явно не то, на что следует полагаться разработчику при написании кода.
(поперхнулся) Как же так? Чуть ли не у всех фич рефреном идет мысль, "вот, теперь оптимизатору будет где развернуться", а вы говорите, что полагаться не стоит? А зачем тогда все эти фичи? А когда вы пишите
forward()илиmove()— это тоже явно не стоит полагаться?Мда, до чего дошли...

domix32
00.00.0000 00:00Так все эти оптимизации в том или ином виде implementation specific и не могут регламентироваться стандартом. Развернуться-то может и есть где, но станет ли он это делать - вопрос отдельный.

MadL1me
00.00.0000 00:00+8Основная проблема всех последних нововведений в С++ - это «замыленность» взгляда разработчиков, которые эти фичи пилят.
Для людей, которые пишут код на плюсах последние лет 20, фичи могут казаться простыми и нужными, просто из-за огромного количества опыта во всех аспектах языка.
При этом совершенно забываются потребности новых разработчиков, которые смотря на развитие языка, будут делать предпочтение в сторону Rust/C, и т.д

Pastoral
00.00.0000 00:00+3Не думаю. Новые разработчики с удовлетворением отметят наличие новых фич и будут их игнорировать пока те не понадобятся. А в сторону Dart или Rust они, конечно, будут глядеть потому, что у С++ куча компиляторов, читай диалектов, и все разные, куча систем сборки и все разные, а у нормальных языков версия одна и cargo на всех одна и та же.

KanuTaH
00.00.0000 00:00+4у С++ куча компиляторов, читай диалектов
Ну на самом деле все не так плохо. Новые фичи стандартов та же большая тройка может реализовывать с разной скоростью, но из уже реализованного при повседневной разработке все работает довольно одинаково, на моей памяти случаи какого-то различного поведения для вещей описанных в стандарте можно пересчитать по пальцам, да и те типа "у MSVC 2017 у такого-то класса из
stdтакой-то конструктор не объявлен какnoexcept" . Оптимизации разнятся, это бывает. Плюс фичи, (пока?) отсутствующие в стандарте, уникальные для некоего компилятора, но ими пользоваться, собственно, никто не заставляет, это твой выбор - пользоваться ими или нет.куча систем сборки и все разные
Вы так говорите, как будто это что-то плохое. Иметь выбор всегда неплохо.
нормальных языков
"Нормальные языки" (хм) спасает только отсутствие желающих писать для них независимые компиляторы и тулчейны. Не факт что так будет вечно. Появится например поддержка тот же раста в gcc, и появятся определённые различия в поведении, тем более, что никакого формального стандартизованного описания языка же сейчас нет, а есть просто вот некая ad hoc имплементация на базе LLVM.

AnthonyMikh
00.00.0000 00:00+4куча систем сборки и все разные
Вы так говорите, как будто это что-то плохоеНу вообще-то плохое, зависимость, использующую другую систему сборки, сложнее добавить в уже существующий проект.
domix32
00.00.0000 00:00нормальных языков версия одна
как будто-то что-то хорошее. И нет, не одна. Как минимум в процессе есть Rust GCC. Плюс всякие cranelift фактически тоже имплементят некоторое подмножество языка.
За Dart не скажу, но допускаю, что тоже имеются альтернативы.
AnthonyMikh
00.00.0000 00:00+4как будто-то что-то хорошее
Вообще-то хорошее, не нужно ifdef-ы лепить под особенности различных компиляторов.
domix32
00.00.0000 00:00Есть разные OS и архитектуры, под которые всё равно придётся пилить эти же ifndef. В плюсах оно конечно некрасиво сделано, в отличие от Rust.

yatanai
00.00.0000 00:00Увы, я даже знаю примеры. Где у тебя программист разбирается почти во всей stl библиотеке, но при этом "очевидные" вещи даже не знает. (В моём случае человек не знал адресную арифметику и как работают ссылки, разницу между T&/T&&)

qw1
00.00.0000 00:00+3Уже было подумал, что сделают extension-методы, как в C#.
Но нет, метод должен находиться в том же классе, на котором вызывается.
Izaron
00.00.0000 00:00Придумал C#-edition этого комментария:
Уже было подумал, что сделают forward declaration, как в С++.
Но нет, тело метода должно следовать сразу за сигнатурой, вываливая бизнес-логику на читателя.
qw1
00.00.0000 00:00+1forward declaration это наследие старого C.
Попробуйте-ка отдекларировать заранее фунции в шаблонном классе.
KanuTaH
00.00.0000 00:00Попробуйте-ка отдекларировать заранее фунции в шаблонном классе.
Если набор того, что можно подставить в этот шаблон, ограничен, то принципиальных проблем с этим нет.
qw1
00.00.0000 00:00+3Это очень частный случай. В другой translation unit нельзя вынести функцию в общем виде
template <typename T> void S<T>::foo() { }KanuTaH
00.00.0000 00:00Ну конечно нельзя, ведь шаблоны "в общем виде" применяются по месту. Общий случай другого translation unit включает например бинарный .o, .so или DLL. Как применить из них шаблон? Но возможность эти шаблоны "наприменять" заранее и вынести результат в другой модуль есть. Другое дело что это не очень полезно, а иногда даже и вредно (код из другого модуля так просто без LTO не заинлайнишь), но в принципе могу себе представить ситуации, когда это может быть оправдано.
qw1
00.00.0000 00:00+1Понятно, я лишь отвечал комментатору выше, что красивого отделения деклараций от реализаций в C++ больше нет, а если хочешь почитать публичный интерфейс какого-нибудь std::unordered_map, придётся ломать глаза об реализацию.

mentin
00.00.0000 00:00+2Часто ограничиваются одним translation unit, но всё равно - сначала краткая декларация функций внутри класса, для читателей, потом уже после завершения декларации класса - inline методы для компилятора. Это пока не убили.

slonopotamus
00.00.0000 00:00+11Таким образом, теперь мы можем переписать всю ту простыню кода, реализующую метод value у optional, гораздо более компактно, меньше чем в десяток строк
Какая же жесть. Комитет реально считает что вот в таком вот стиле люди будут писать код и считать это удобным?

stepsoft
00.00.0000 00:00+1Развиваю библиотеку "умных" оберток https://habr.com/ru/post/650701/ и для меня это нововведение весьма полезно. Сейчас код представляет собой большую портянку макросов (например, здесь https://gitlab.com/ssoft-scl/module/feature/-/blob/main/src/Detail/Operator.h), от которых теперь можно легко избавиться.
Не думаю, что такой стиль будет распространён в прикладных программах, а вот инструментальные библиотеки типа std, boost и др. обязательно это будут использовать.domix32
00.00.0000 00:00+1mein gott. Почему вы решили неймспейс по-серьёзному назвать верблюжьим кейсом? Я б понял scl или sc_l там..
stepsoft
00.00.0000 00:00Так исторически сложилось. Такое соглашение о форматировании кода в большинстве проектов, в которых я участвовал. Похоже, Qt оказал влияние). Но всегда для удобства можно использовать псевдонимы для пространств имен.
namespace scl = ScL;

NeoCode
00.00.0000 00:00+6Все эти изменения... с одной стороны наверное они нужны и оправданы, но с другой ориентироваться в них все сложнее. Все эти тонкости шаблонного метапрограммирования, порождающие какие-то неоднозначности, требующие для разрешения очередные усложнения языка... В то же время простые вещи, такие как языковые расширения C/C++ https://gcc.gnu.org/onlinedocs/gcc-5.3.0/gcc/C-Extensions.html , в стандарт не попадают. Также я как-то давно предлагал на форуме isocpp расширить шаблоны возможностью использовать обычные фрагменты кода (не функции, а просто код в фигурных скобках) в качестве параметров и в качестве самих шаблонов (получилась бы удобная замена макросам для низкоуровневой кодогенерации), но отклонили.
KanuTaH
00.00.0000 00:00Также я как-то давно предлагал на форуме isocpp расширить шаблоны возможностью использовать обычные фрагменты кода (не функции, а просто код в фигурных скобках) в качестве параметров и в качестве самих шаблонов (получилась бы удобная замена макросам для низкоуровневой кодогенерации), но отклонили.
Я тоже что-то не понял светлой идеи. Ведь есть же лямбды:
template<auto f = [](){ std::cout << "DEFAULT" << std::endl; }> void foo() { f(); } int main() { foo(); foo<[](){ std::cout << "CUSTOM" << std::endl; }>(); }И гибкость выше, потому что в лямбду можно передать параметры, в отличие от "просто кода в фигурных скобках", и вопросов с захватом переменных, которые используются в "просто коде в фигурных скобках" не возникает.
NeoCode
00.00.0000 00:00Лямбды это рантайм-механизм, а иногда нужно генерировать именно синтаксические деревья определенного вида для последующей компиляции. "Фрагментом кода" может быть например просто имя (последовательность символов, допустимая для идентификатора), которое где-то в шаблоне будет использовано как имя (или даже часть имени) поля, метода, вложенного класса...
qw1
00.00.0000 00:00расширить шаблоны возможностью использовать обычные фрагменты кода (не функции, а просто код в фигурных скобках) в качестве параметров
Что-то типа такого?
#define CUSTOM_OPERATOR(y) { if (1) y } int main() { CUSTOM_OPERATOR({ return 7;}); }Оно уже работает. Ну если только в "параметре" нет запятой.
KanuTaH
00.00.0000 00:00Хм, ну к такой идее я бы тоже отнесся мягко говоря настороженно, потому что такая генерация должна например поддерживать примерно такое, потому что "а почему бы и нет" (синтаксис условный):
template<code C> some_inline_code { C else foo(); } [...] some_inline_code<{if (a == b) then bar()}>Если такое поддерживать, то первичный синтаксический анализатор с глузду съедет (можно вообще придумать что-нибудь и позамороченней с непарными кавычками, фигурными скобками и т.п.), а если не поддерживать, то будет вечное нытье "а почему нельзя так, а почему нельзя эдак" и будут все равно пользоваться макросами и скриптами-кодогенераторами (и в принципе правильно).
NeoCode
00.00.0000 00:00Непарные кавычки и скобки - это уже уровень лексических макросов, т.е. существующий препроцессор С/С++. Я предлагаю только уровень синтаксических макросов, а значит - работа с законченными нодами синтаксического дерева, там непарных скобок и кавычек быть не может. Приведенный вами пример с точки зрения синтаксического анализа совершенно корректен и никаких проблем с ним не будет. Ошибка может выявиться только если передать блок несовместимый с "else", но это будет не бред на десятки строк, как сейчас при метапрограммировании на шаблонах, а вполне конкретная ошибка компиляци - такая же, как если бы вы вручную написали "else" без "if".
KanuTaH
00.00.0000 00:00но это будет не бред на десятки строк, как сейчас при метапрограммировании на шаблонах
Да то же самое будет "syntax error блаблабла while instantiating template at блаблабла referring at блаблабла". Если такие шаблоны будут еще и вложенные, то будет соответственно бОльшая простыня. И от этой информации как правило есть польза - иначе в некоторых случаях могло бы быть непонятно, например, какой именно шаблон используется (или НЕ используется), например, если у вас там какие-нибудь хитро вложенные друг в друга пространства имен и в каждом собственный шаблон с одинаковым именем.
Приведенный вами пример с точки зрения синтаксического анализа совершенно корректен и никаких проблем с ним не будет.
Только если совсем не разбирать то что находится внутри фигурных скобок после
some_inline_code. Сейчас шаблоны все-таки разбираются и синтаксическая корректность базовых конструкций проверяется, проверяется, что там, где ожидается тип, действительно указан тип (пусть дажеtypenameаргумент шаблона), а где ожидается значение или переменная, там действительно указано значение (пусть даже это non-type template parameter). Нельзя просто взять и написать что-нибудь типаT else {...}.qw1
00.00.0000 00:00Можно добавить ограничение, что такой шаблонный параметр — синтаксически работает как блок { }, и тогда
T else {...}— запрещено,
но вот такое — можно:if (status == S_OK) { return true; } else TKanuTaH
00.00.0000 00:00"Фрагментом кода" может быть например просто имя (последовательность символов, допустимая для идентификатора), которое где-то в шаблоне будет использовано как имя (или даже часть имени) поля, метода, вложенного класса...
Так что нет, предлагается именно что безбашенная замена макросам, которым все равно, что и куда подставлять.
KanuTaH
00.00.0000 00:00+1А замена блокам
{}уже есть (и даже лучше чем просто замена), и это лямбды. Просто блоки{}- это честно говоря выглядит как туфта, потому что они не обеспечивают должного уровня обобщенности, так сказать. Например, чтобы в этом блоке использовать переменные из остальной части кода, нужно знать, как они называются, заботиться об отсутствии name clash, грубо говоря, писать не обобщенный код, а код под конкретный шаблон, и не дай бог в этом шаблоне потом что-то поменяется. ИМХО идея дохлая, понимаю комитетчиков (или кто там эту идею оценивал на isocpp).qw1
00.00.0000 00:00Лямбды не могут глобально влиять на control flow. То есть, туда не положишь break или return, что было бы полезно для генерации веток switch. Хотя, если принять, что параметр — законченный блок { }, у него тоже break сам по себе недопустим в отрыве от контекста, куда будет подстановка.
qw1
00.00.0000 00:00Лямбды работают в run-time, поэтому будет оверхед.
Гипотетический пример,template<code ERR_HANDLER> void workWithFile(const char* filename) { if (auto file = fopen(filename)) { .... } else ERR_HANDLER; } workWithFile<{ abort(); }>("1.txt"); workWithFile<{ log.warn("can't open file"); }>("2.txt");KanuTaH
00.00.0000 00:00Лямбды работают в run-time, поэтому будет оверхед.
Лямбды при сборке с включенной оптимизацией как правило инлайнятся по месту. Поэтому кстати функции и лямбды рекомендуют передавать в другие функции как шаблонные параметры, а не в качестве обычных параметров (как
std::functionили там просто как указатель на функцию), если это возможно. У некоторых линтеров даже есть диагностика на это, например, у SonarQube.

sergio_nsk
00.00.0000 00:00+4Почему так длинно?
template <typename Self> void foo(this Self&& self) { }Почему нельзя было сразу сделать короче? Кому нужен
std::forwardбудет использовать длинную запись.void foo(this auto&& self) { }Опять разбили принятие и сокращение на две итерации?
Да и вообще,
thisраньше нигде нельзя было использовать, кроме в теле метода класса, так почему бы не сделать его сразу вот таким специальным в его новом контексте?void foo(this&& self) { }qw1
00.00.0000 00:00Похоже, что краткая запись тоже работает. В статье есть пример с "рекурсивной лямбдой", там именно такой синтаксис.
eoanermine Автор
00.00.0000 00:00Краткая запись тоже работает. Чем отличается
explicit object parameterот других аргументов — тем, что перед ним стоитthis. Больше на него кроме того, что он не может бытьvariadic pack'ом, ограничений практически не накладывается.

LordCyberfox
00.00.0000 00:00+6Подобные нововведения, хоть и решают некоторые проблемы - порождают другие. Этот стиль написания кода ИМХО - нечитаем. Или во всяком случае вызывает серьезные сложности в понимании. Уже много копий было сломано о том, что лучше - более короткая и емкая реализация или та которую можно нормально читать и поддерживать. И комбинация сложности восприятия кода с пачкой не самых очевидных «нюансов» где он не будет работать как вы хотите - оптимизма человеку, который будет работать с вашим кодом не добавит (как и вам, если вы возьметесь это модифицировать через пару месяцев).
Впрочем, возможно я что-то не понимаю в этой жизни и этот синтаксис на самом деле интуитивно понятен.

DeepFakescovery
00.00.0000 00:00+3всё верно. Код должен быть быстро читаемым и поддерживаемым.
Я на С++ уже давно не кодю, сейчас у меня глаза ломаются при виде такого обилия <&&::{ }>;

lrrr11
00.00.0000 00:00с рекурсивными лямбдами вроде и раньше не было проблем, не?
auto f = [&](auto&& f, int n) → int {if (n == 0) return 1;
return n * f(f, n — 1);}qw1
00.00.0000 00:00Пользоваться немножко неудобно:
f(f, 5);Интересно, если f надо передать в метод, принимающий лямбду с одним аргументом, можно ли будет передать рекурсивную лямбду с this, или так компилятор на обманешь, у неё всё равно тип отличается от функтора с 1 аргументом, и придётся делать лямбду-обёртку https://godbolt.org/z/Khfr11vs6

Aldrog
00.00.0000 00:00Тип лямбд же в любом случае уникальный и определяемый реализацией. По сути всё, что вы можете с ней сделать — это передать её в шаблонный метод, которому всё равно что это за объект, главное, чтобы его можно было вызвать с нужными параметрами.
P.S. Сохранение лямбды в std::function это точно такой же вызов шаблонного конструктора, который выполняет type erasure.


segment
Жуть, во что превратился C++
AlexeyK77
Верните С++93!
domix32
Нет, спасибо. На 17 вполне замечательно живётся.