
Каждый из нас сталкивался с необходимостью настройки сложного ПО, интенсивно потребляющего ресурсы компьютера. Как правило, у такого софта довольно объёмная конфигурация, и из-за этого бывает трудно подобрать комбинацию параметров, при которой этот софт демонстрировал бы высокую производительность при минимальной утилизации железа.
Одна из наиболее ресурсоемких категорий софта сегодня — это системы хранения данных. К ним можно отнести как классические СУБД, так и хранилища различного назначения. В корпоративной почтовой системе Mailion мы используем объектное хранилище собственной разработки — Dispersed Object Store (DOS). Mailion поддерживает одновременную работу до миллиона пользователей, и подобный уровень нагрузки выдвигает существенные требования к производительности и экономической эффективности системы.
Под катом рассказываем, как мы искали оптимальную конфигурацию нашего объектного хранилища, и какие уроки извлекли из этого поиска.
Привет, Хабр! Меня зовут Виталий Исаев, я бэкенд-разработчик в МойОфис. Этой статьей я продолжаю цикл публикаций, посвященных архитектуре корпоративной почтовой системы Mailion. Ранее мы рассматривали оптимизации, помогающие эффективно хранить электронные письма, исследовали подходы к организации горизонтально масштабируемых хранилищ и погружались в детали реализации кластера DOS. Сегодня же я хочу поговорить о методике поиска оптимальной конфигурации нашего объектного хранилища.
Разработанная нами техника универсальна и может быть применена для оптимизации TCO любого программного обеспечения, написанного на языке Go. Результаты этого исследования были представлены на конференции Saint Highload 2022 компании Онтико, а здесь мы публикуем текстовый вариант выступления.
Balance-driven development
Хранение данных никогда не было бесплатным.
Для того, чтобы развернуть хранилище, нам нужны диски различных типов, оперативная память, центральный процессор и некоторые другие ресурсы. Если мы просуммируем затраты на эти ресурсы, то получим итоговую стоимость хранения данных. В статье мы будем обозначать её с помощью буквы
от слова cost ("стоимость").
У каждого ресурса есть свой собственный рынок, на котором динамически формируется цена. Накопители данных, к примеру, постоянно дешевеют, причём SSD-диски дешевеют быстрее, чем HDD. Согласно прогнозам, около 2026 года стоимость быстрых и медленных дисков сравняется, что существенно изменит ландшафт для систем хранения данных.

То же самое можно сказать в отношении оперативной памяти. Она постоянно дешевеет, но в последние 15 лет скорость изменения цены значительно снизилась — как считается, из-за тех же проблем, что вызывают нарушение закона Мура на рынке центральных процессоров.

Тем не менее, как минимум до 2016 года стоимость вычислений снижалась практически монотонно.

Поэтому мы можем констатировать, что рынок железа очень динамичен. Где-то цены падают, где-то — стагнируют, но в целом ситуация постоянно изменяется. Нам определенно стоит это учитывать при проектировании систем для хранения данных.
Если опросить экспертов по хранилищам, то окажется, что сегодня доминируют два подхода к проектированию софта такого класса. Первый заключается в экономии дискового пространства любой ценой. Мы хотим поместить как можно больше клиентских данных в диски наименьшего объема, поэтому фокусируемся на техниках устранения избыточности из данных.
Второй, и возможно, более популярный подход состоит в том, что центральный процессор объявляется наиболее ценным ресурсом, а оперативная память и дисковое пространство приносятся ему в жертву.
Но ни один из этих подходов не обладает достаточной гибкостью для реалий сегодняшнего дня, ведь нам нужно не просто сэкономить центральный процессор или диски. Истинная цель — прийти к оптимальной стоимости эксплуатации нашего продукта, а достигается она только в том случае, если мы нашли оптимальный баланс аппаратных ресурсов. Например, вчера мы могли экономить диски, сегодня пытаемся экономить CPU, а завтра будем стараться минимизировать потребление какого-то другого ресурса. Но в любом случае наши действия направлены на то, чтобы найти комбинацию аппаратных ресурсов с минимальной рыночной стоимостью.
У этого процесса есть два слагаемых успеха:
Создаваемый нами софт должен уметь за счёт применения определенных алгоритмов конвертировать на программном уровне потребление одних ресурсов в потребление других.
Мы должны научиться определять оптимальную конфигурацию — то есть тот набор настроек нашего софта, при котором достигается оптимальный баланс аппаратных ресурсов.
Наш подход к разработке можно условно назвать балансоориентированным, и именно его мы применяем при разработке корпоративной почтовой системы Mailion.
Еще на этапе дизайна мы заметили, что данные, которые обычно циркулируют в системе электронной почты, характеризуются тремя важными свойствами:
Большинство писем состоят из данных текстовых форматов, благодаря чему они хорошо сжимаются.
В корпоративной среде часто встречаются дубликаты писем — либо полные, либо частичные.
Письма иммутабельны. Содержимое письма, которое однажды было отправлено или получено, уже никогда не изменится.
Мы поняли, что оптимизации, нацеленные на эти свойства наших данных, позволят нам сэкономить существенные объемы аппаратных ресурсов, и в результате написали свое собственное распределенное объектное хранилище, которое назвали Dispersed Object Store (подробнее о его создании читайте в статьях 1, 2, 3). В его базовую функциональность мы включили поддержку алгоритмов компрессии и дедупликации.
Рассмотрим эти алгоритмы чуть более подробно в контексте поиска оптимального баланса между аппаратными ресурсами.
Компрессия
Мы написали бенчмарки, чтобы понять, какие алгоритмы компрессии подходят лучше всего для наших данных. Качество алгоритмов компрессии измеряется с помощью коэффициента сжатия
и скорости сжатия (пропускной способности алгоритма). На этих графиках пространство координат сформировано именно этими двумя метриками, а каждая точка — это результат работы какого-то конкретного алгоритма. Также мы специально разбили сжимаемые данные на шесть размерных групп.

На этих графиках видны две важные особенности, которые характерны для всех алгоритмов компрессии. Во-первых, они очень плохо сжимают маленькие данные. Это хорошо видно на первых двух размерных группах, где почти все точки попали в красную зону — туда, где коэффициент компрессии меньше единицы, то есть где алгоритмы компрессии работают себе в убыток.

Во-вторых, чем крупнее становятся сжимаемые данные, тем теснее выражена обратная пропорциональность между скоростью сжатия и коэффициентом сжатия. Алгоритм сжатия не может быть одновременно хорошо сжимающим и быстро работающим, что в точности соответствует trade-off между затратами на дисковое пространство и затратами на CPU. Если мы хотим сэкономить больше диска, мы тратим больше CPU, и наоборот.

Ключевыми настройками, которые определяют эффективность компрессии, являются:
Тип алгоритма;
Level — уровень сжатия у тех алгоритмов, в которых он может быть задан;
Минимальный размер объекта, который подвергается компрессии (как мы уже увидели выше, самые маленькие объекты сжимать нецелесообразно).
Регулируя эти настройки, мы можем балансировать затраты на дисковое пространство и затраты на CPU.
Дедупликация
К решению задачи дедупликации можно подойти с двух сторон.
Представим, что у нас есть какой-то клиент. Он хочет сохранить объект в хранилище. Затем приходит ещё один клиент со своим объектом, и ещё один. Четвертый клиент приносит тот объект, который уже когда-то встречался в нашей системе. С пятым клиентом происходит то же самое: наличие дубликатов в корпоративной переписке — это абсолютно нормальное явление.
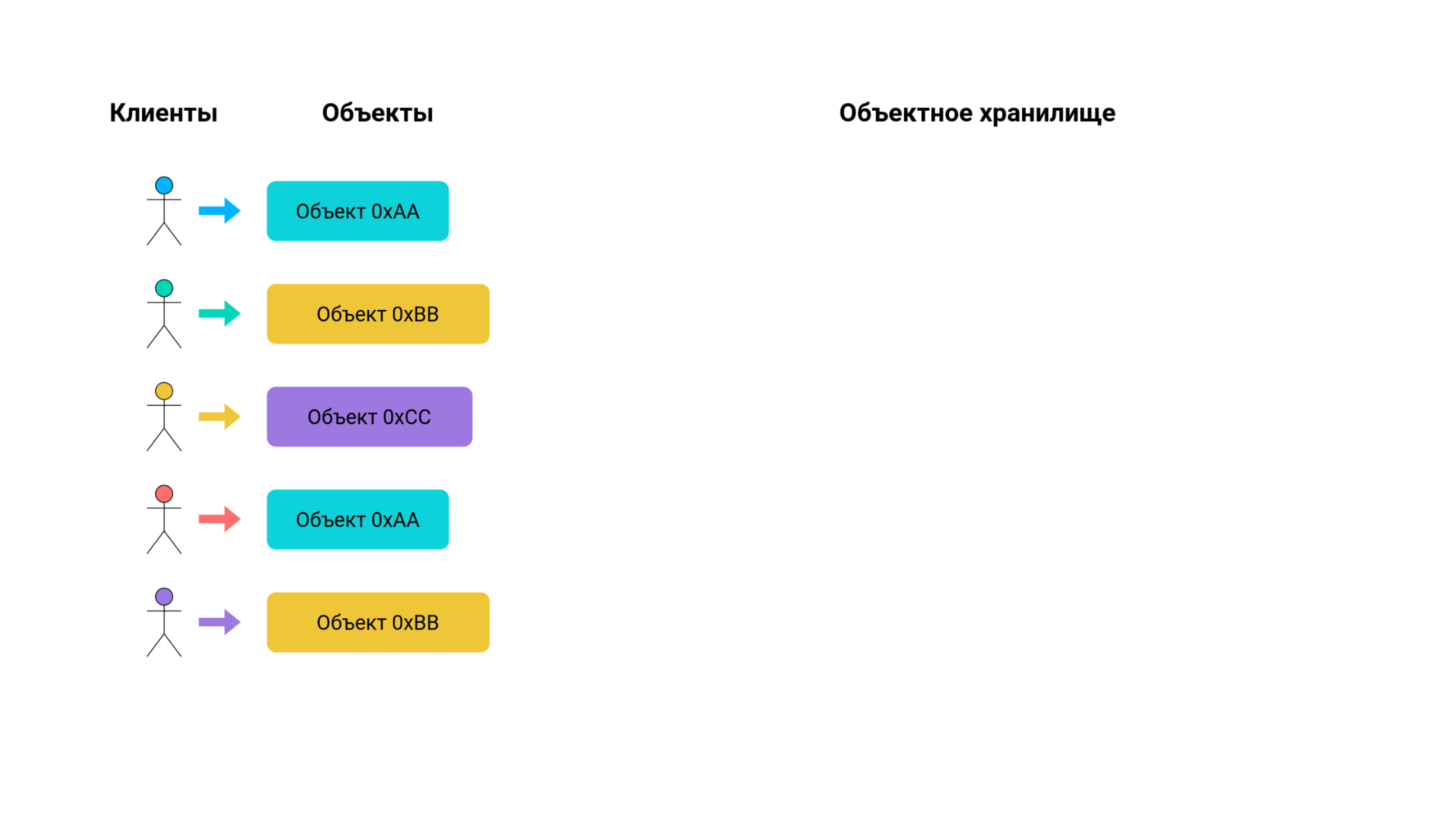
Как должно повести себя объектное хранилище, рассчитанное на такой паттерн применения? Решение очень простое — оно должно уникализировать объекты и хранить данные каждого из них в одном-единственном экземпляре. Также к каждому объекту нужно присовокупить небольшую структуру данных — счетчик копий. Он будет инкрементироваться каждый раз, когда будет выполняться повторное сохранение объекта, который уже когда-то встречался в нашей системе. Перед нами типичный пример виртуализации данных: пользовательские данные и форма, в которой они "физически" хранятся в системе, отличаются, и сделано это в целях достижения максимальной эффективности системы.

Использование счётчиков копий — очень простой, но эффективный способ экономии дискового пространства. Однако за него приходится заплатить появлением слоя метаданных, которые приходится вычитывать с диска при каждом обращении к объекту.
Можно пойти еще дальше и попытаться дедуплицировать пересечения между объектами. Для этого мы делим объекты на чанки с помощью алгоритма content-defined chunking. Местоположение границ между чанками определяется содержимым самого объекта.

Затем чанки по определенным законам делятся на сегменты, которые, в свою очередь, являются элементарными единицами хранения данных в нашем объектном хранилище. Реальные данные привязываются именно к сегментам, тогда как объекты и чанки превращаются в виртуальные сущности, содержащие ссылки на сегменты.

Также эти ссылки размещаются и в метаданных самих сегментов. Это нужно для реализации сборщика мусора по сегментам.

По сути, на этой картинке нам осталось только перекрасить объекты и чанки в красный цвет и констатировать, что в нашем объектном хранилище появилось очень много взаимосвязей и очень много метаданных. Эти метаданные часто изменяются и часто читаются, поэтому хранятся на дорогих быстрых дисках.

Но именно эта архитектура позволяет нам реализовать дедупликацию сразу на двух уровнях — уровне объектов и уровне сегментов. Оценивать эффективность дедупликации мы будем с помощью коэффициента, симметричного коэффициенту сжатия.
На верхнем уровне (уровне объектов) на наших стендах мы наблюдаем более чем десятикратное сжатие. И это не предел, потому что здесь нет никаких сложных настроек, все зависит исключительно от количества дубликатов во входящем потоке данных.

С дедупликацией сегментов всё интереснее и сложнее. В идеале коэффициент дедупликации сегментов зависит от количества объектов, то есть чем больше данных мы запишем в объектное хранилище, тем эффективнее будет работать дедупликация. Но происходит это только в том случае, если чанкинг был правильно настроен. В этом случае во всем диапазоне размеров наблюдаем аккуратные 70-байтные чанки.

Если же он был настроен неправильно, то средний размер чанка, к примеру, может вырасти уже до нескольких килобайт. При этом дисперсия размеров чанков становится просто чудовищной. Как итог, коэффициент дедупликации еле-еле отрывается от единицы, то есть дедупликация фактически не работает.
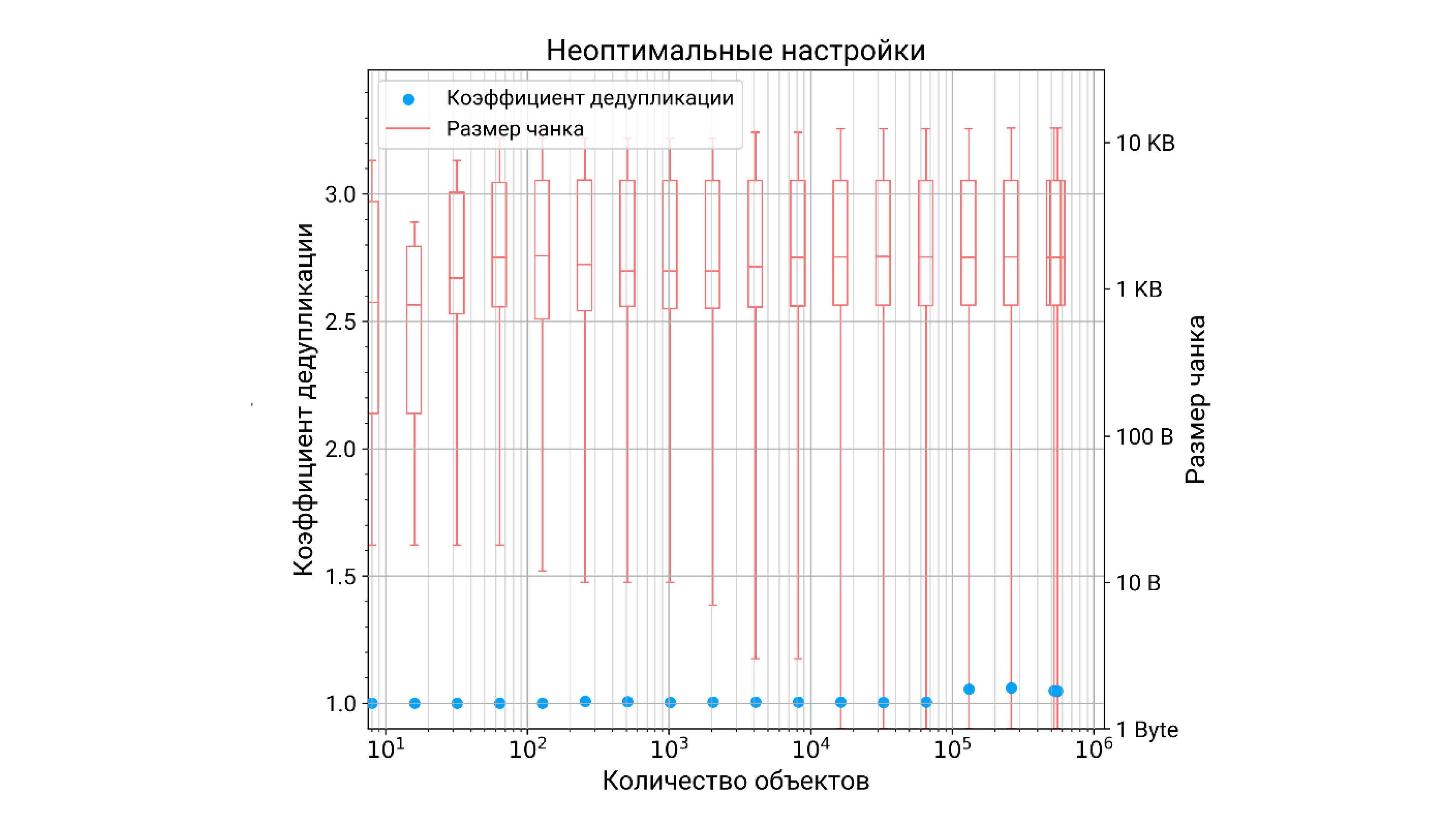
Из этих двух графиков можно сделать следующий вывод: чтобы дедупликация стала эффективным средством снижения избыточности данных, её требуется грамотно настраивать под контретный поток входящих данных.
Чем еще хороша дедупликация сегментов? Дело в том, что популярные сегменты востребованы при чтении самых разных объектов, поэтому эффективной стратегией было бы размещение этих сегментов в кэше. Благодаря этому мы можем сэкономить один из самых дефицитных типов аппаратных ресурсов для систем хранения данных — операции ввода/вывода на медленных дисках.
Чтобы получить эмпирическое подтверждение этому, мы поместили перед дисками LRU-кэш для тел сегментов, объём которого составлял 10% от количества исходных данных, и использовали его в режиме write-through/read-through. Затем мы однократно записали и прочитали из хранилища некоторый объём данных и измерили итоговый hit rate.

Как и ожидалось, эта величина оказалось тесно связана с коэффициентом дедупликации сегментов: чем лучше настроена дедупликация, тем эффективнее работает кэш, и тем выше его hit rate. Получается, что кэш, объем которого составляет всего лишь 10% от исходных данных, может демонстрировать hit rate более чем в 60%. Это означает, что за счёт внедрения совсем не большого кэша мы можем более чем в два раза снизить IO на наших медленных дисках.
К сожалению, в алгоритме content-defined chunking мы не можем напрямую управлять коэффициентом дедупликации. Есть несколько настроек, которые лишь косвенно влияют на статистическое распределение чанков по размерам:
ChunkLowerBound — минимально возможный размер чанка;
ChunkUpperBound — максимально возможный размер чанка;
AverageBits — параметр, отвечающий за частоту выделения чанков;
Limit — минимальный размер объекта, начиная с которого выполняется деление на чанки.
При этом средний размер чанка играет ключевую роль в балансе между данными и метаданными в нашей системе. Если чанки большие, то дедупликация работает плохо, но зато и метаданных мало. Мы экономим быстрые диски, которые потребовались бы для размещения этих метаданных, но увеличиваем затраты на медленные диски, где хранятся сами тела сегментов.
Если же чанки маленькие, то дедупликация работает хорошо, но ценой большего объёма метаданных. У нас увеличиваются расходы на SSD, но при этом мы экономим HDD.
В поисках баланса
Итак, мы рассмотрели два алгоритма, которые объединены в конвейер и которые обрабатывают входящий поток данных в наше объектное хранилище. Каждый из них регулирует какой-то свой trade-off между определёнными типами аппаратных ресурсов и обладает собственным набором настроек.
Ситуация осложняется тем, что настройки одного из алгоритмов опосредованно влияют на результативность другого алгоритма, поскольку данные, которые выходят из чанкинга, отправляются на вход в компрессию. Получается, что в нашей системе появляются какие-то сложные, неявные взаимосвязи, которые тяжело проанализировать и заранее просчитать.
Как же нам найти набор настроек, соответствующий оптимальному балансу аппаратных ресурсов? Есть два пути:
Интуитивный. Опираясь на свою экспертизу, мы выдвигаем какую-то гипотезу, и, как правило, не проверяя её, идём вместе с ней сразу в продакшн. К примеру, мы могли бы предположить, что объектное хранилище рассмотренной выше архитектурой будет максимально эффективно, если максимальную дедупликацию помножить на максимальную компрессию для всех объектов, кроме самых маленьких — именно эта комбинация настроек позволяет максимально устранить всю избыточность во входящем потоке объектов, и поэтому нам можно будет сохранить гораздо меньшее количество данных на HDD.
Экспериментальный. Мы должны провести какие-то опыты, извлечь новые знания о нашей системе, и уже на основании этих знаний определить её оптимальную конфигурацию. Конечно, этот путь точнее и дороже. Именно его мы выберем.
Мы будем рассматривать нашу систему как черный ящик с определенным количеством входов и выходов. Вход номер один — это конкретные значения настроек тех алгоритмов, которые мы только что рассмотрели. Вход номер два — это нагрузка, которую мы подаем на нашу систему.
На выходе мы будем снимать статистику, которая будет свидетельствовать о потреблении тех или иных видов аппаратных ресурсов. Для дисков это количество данных и IOPS, для центрального процессора — утилизация ядер, для оперативной памяти это просто объем.

Пользуясь рыночными ценами на ресурсы, мы получаем денежное выражение потребления того или иного ресурса. Затем мы суммируем эти показатели и получаем финальную стоимость хранения данных в нашем объектном хранилище.

Только что мы с вами определили стоимостную или целевую функцию, как ее еще принято называть. Что мы о ней знаем? Она определена в многомерном пространстве, которое задается параметрами конфигурации S и нагрузки L.

Заметим, что нам неизвестен аналитический вид этой функции. И даже если бы мы захотели его узнать, скорее всего, у нас бы ничего не получилось.
Но мы точно знаем, что эта функция ограничена снизу, потому что из своего опыта мы понимаем, что для любой системы можно определить какой-то минимальный набор железа, на котором она выдержит определённый уровень нагрузки.
Чтобы символизировать это, мы рисуем здесь весьма условную параболу ветвями вверх. Наша задача — найти точку оптимума, тот набор параметров целевой функции, при которой достигается её минимальное значение на области определения.

Чрезвычайно важно понимать, что вызов целевой функции стоит дорого. В нашем случае для того, чтобы рассчитать одно значение целевой функции, нужно развернуть чистый стенд, загрузить данные, подать нагрузку, снять метрики и обработать их. Получается, что весь наш стенд превращается в гигантский программно-аппаратный калькулятор целевых функций. Одно вычисление может занять минуты, часы, в худшем случае — дни.
Разумеется, в этих условиях нечего и думать о том, чтобы найти точку оптимума путем грубого перебора всех комбинаций параметров. Нам нужно сделать это за минимальное количество шагов, и в этом нам помогут методы математической оптимизации.
Выбор оптимизатора
К настоящему моменту придумано огромное количество методов оптимизации на все случаи жизни: безусловная оптимизация ищет оптимум на всей области определения, условная — только в какой-то ограниченной её части. Локальные методы ищут локальный оптимум, тогда как другие нацелены на то, чтобы найти оптимум глобальный.
Многое зависит от параметров целевой функции. Они могут быть непрерывными (рациональные числа), дискретными (натуральные и целые числа) и даже категориальными. За каждым из этих вариантов скрывается какая-то своя область математики, свой набор техник оптимизации.
Для выбора метода важное значение имеют свойства целевой функции. Если она известна, то есть известен её аналитический вид, значит, мы можем её продифференцировать и воспользоваться таким популярным методом математической оптимизации, как градиентный спуск.
Если функция дешевая, значит можно безболезненно вызывать ее много раз и найти оптимум с высокой точностью. Если же она дорогая, то о высокой точности, скорее всего, придется забыть, потому что оценку значения функции получится выполнить лишь несколько раз.
Наша задача — поиск оптимальной конфигурации объектного хранилища — является примером условной глобальной оптимизации неизвестной и очень дорогой функции. Чтобы решить эту задачу, мы воспользовались оптимизатором RBFOpt. Эта библиотека появилась несколько лет назад; она заточена на оптимизацию сложных целевых функций из реального мира и пытается найти приближенное значение глобального оптимума за ограниченное количество шагов.
Кроме того, RBFopt не опирается на вычисление производных и потому не требует указания аналитического вида целевых функций, что для нас крайне важно.
Единственная трудность, с которой мы столкнулись, была связана с языком программирования. Как и многие другие инструменты из мира data science, оптимизатор написан на Python, тогда как мы используем Go, поэтому нам пришлось написать небольшую обёртку rbfopt-go, в которой мы реализовали API для оптимизации на Go, а также несколько функций для визуализации результатов работы оптимизатора. Некоторые из графиков, которые вы увидите дальше, реализованы в нашем враппере.
Методика поиска оптимума
Итак, у нас появился инструмент для исследования, и сейчас мы попытаемся найти оптимум у пяти разных целевых функций. Мы будем двигаться от простого к сложному и наблюдать за тем, как изменяются параметры оптимальной конфигурации хранилища в зависимости от формулировки целевой функции.
Сначала пару слов об окружении. Все эксперименты выполнялись на обычном десктопном компьютере с 8-ядерным процессором и 32 Гб RAM. Все данные размещались в оперативной памяти, потому что у нас не было задачи протестировать производительность диска на этом компьютере.
Несмотря на скромные характеристики стенда, на нём удалось развернуть отказоустойчивую инсталляцию объектного хранилища. Это трехнодовый кластер с репликацией метаданных в количестве 3 экземпляров и кодированием Рида-Соломона для тел объектов в конфигурации «2 + 2». Таким образом, мы реализуем тройную избыточность для метаданных и двойную избыточность для данных. В такой конфигурации кластер может пережить потерю любого из узлов и продолжить обрабатывать запросы как на чтение, так и на запись.
Стенд |
Модель |
|
- AMD Ryzen 7 2700X 8 x 3.7 ГГц - 32 GB DIMM DDR4 2933 МГц - Все данные — на tmpfs |
- Кластер из 3 узлов - Метаданные: RF = 3 - Тела объектов: d + p = 2 + 2 |
В качестве исходных данных использовались объекты, которые были извлечены с одного из наших тестовых стендов, где письма друг другу отправляют тестировщики. Медианный размер объекта совсем небольшой, около 1.5 Кбайт, но среднеквадратическое отклонение просто гигантское — 90 Кбайт. Это связано с тем, что некоторые объекты отличались друг от друга по размеру более чем на семь порядков (минимальный размер — 1 байт, максимальный — 23 Мбайт). Это очень много. В условиях такого разброса подобрать универсальную и оптимальную конфигурацию хранения будет довольно трудно.

Каждая оптимизационная сессия проходила с тремя разными наборами объектов, но в любом случае их было не очень много, иначе стоимость нагрузочного стенда оказалась бы заоблачной. Для того, чтобы смоделировать с помощью небольшого количества объектов тот уровень утилизации ресурсов, который был бы вызван нагрузкой из реального мира, пришлось экстраполировать результаты с помощью масштабных коэффициентов. Это достаточно скользкий путь, который может привести к ошибкам в силу того, что мы не всегда можем учесть масштабные эффекты, которые обычно присущи тем системам, с которыми мы работаем, но разумной альтернативы этому нет.
Количество объектов |
Суммарный размер, МБ |
2^10 (1024) |
3.12 |
2^14 (16384) |
50.5 |
2^18 (262144) |
913 |
Еще несколько важных нюансов. Фактически в ходе работы оптимизатора мы фиксировали нагрузку
то есть искали оптимальную конфигурацию системы для конкретного режима нагрузки:
В каждой оптимизационной сессии оптимизатор выполнял по 100 вычислений целевой функции. Разумеется, в ходе поиска оптимума оптимизатор мог предлагать далеко не самые оптимальные комбинации параметров, с которыми система демонстрировала крайне низкую производительность. Мы защищались от таких конфигураций с помощью тайм-аутов: запись и чтение любого объекта в объектное хранилище должны были уложиться в 10 секунд. Если этого не происходило, то мы отметали эту конфигурацию как заведомо неоптимальную.
На следующей таблице представлены диапазоны вариации параметров. Они описывают ту часть области определения целевой функции, в которой будет выполняться поиск оптимума Четыре переменные параметризуют алгоритм content-defined chunking, ещё две — алгоритм компрессии, при этом все параметры являются целочисленными.

Параметр |
Min |
Max |
Chunking.AverageBits |
1 |
25 |
Chunking.ChunkLowerBound |
1 Б |
1 МБ |
Chunking.ChunkUpperBound |
1 Б |
1 МБ |
Chunking.SingleChunkLimit |
1 Б |
1 МБ |
Compression.ZSTD_Level |
1 |
20 |
Compression.Limit |
1 Б |
1 МБ |
Наибольший интерес представляют параметры Chunking.SingleChunkLimit и Compression.Limit. Они изменялись в пределах от 1 Б до 1 МБ. Именно они определяли, для какой доли объектов выполнялись чанкинг и компрессия.
Также для простоты мы зафиксировали один алгоритм компрессии — ZSTD, хотя наше хранилище поддерживает и другие алгоритмы. Поэтому оптимизатор варьировал только его уровнем сжатия.
ЦФ №1: HDD Capacity
Первая целевая функция устроена очень просто. Здесь только одно слагаемое — стоимость HDD дисков, на которых мы храним тела сегментов. Мы как будто на время забываем о том, что у нас есть метаданные, и хотим сконцентрироваться только на оптимизации количества медленных дисков.
где:
— удельная стоимость HDD-носителей, отнесённая на 1 байт;
— объем фактически хранимых данных.
Каждая целевая функция должна быть сформулирована так, чтобы отвечать на какой-то вопрос. Для первой целевой функции он звучит так:
«Каковы минимальные затраты на HDD-диски для хранения одного 1 ТБ клиентских данных?»
Подчеркнём, что в данном утверждении имеется в виду уже не размер данных в их внутреннем представлении, а размер исходных клиентских данных, поступивших в нашу систему снаружи.
Оптимизатор определил, что минимальное значение этой функции составляет $18.7, и достигается оно при максимальном уровне компрессии — 20. В этом нет ничего удивительного: компрессия действительно нужна для того, чтобы сэкономить дисковое пространство.
Параметр |
Значение |
Chunking.AverageBits |
25 |
Chunking.ChunkLowerBound |
1 КБ |
Chunking.ChunkUpperBound |
1 МБ |
Chunking.SingleChunkLimit |
1 КБ |
Deduplication Ratio |
1.08 |
Compression.ZSTD_Level |
20 |
Compression.Limit |
1 Б |
Оптимальный конфиг |
$18.7 |
Неоптимальный конфиг |
$37.8 (+102%) |
Любопытно, что эмпирически наблюдаемый коэффициент дедупликации при такой комбинации параметров лишь немногим больше единицы. Судя по настройкам content-defined chunking параметров, дедуплицироваться будут только самые крупные объекты.
Кроме полученных параметров оптимума, оптимизатор позволяет нам прикинуть, сколько будет стоить неоптимальная конфигурация — почти 38 долларов. Иными словами, если мы неправильно настроим компрессию и content-defined chunking, то только за жесткие диски мы переплатим в два раза.
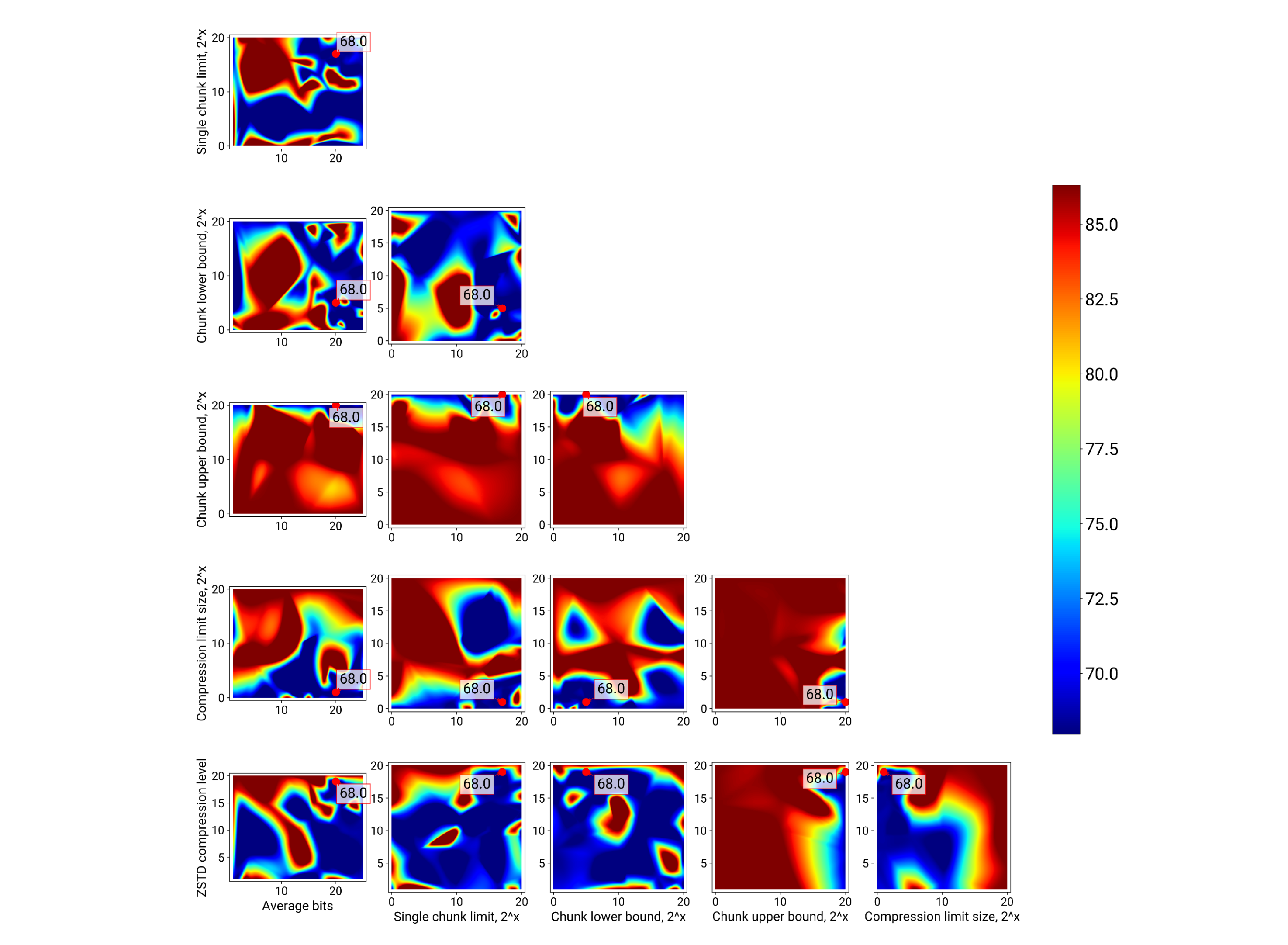
Благодаря разработанным нами средствам визуализации оптимизатор приоткрывает завесу тайны над внешним видом целевой функции. Поскольку она многомерная, посмотреть на нее можно, только спроецировав ее значения на плоскости, сформированные парами параметров. Те из вас, кто будет использовать оптимизатор для решения своих задач, найдут в этих графиках много интересного.

Я же сейчас просто хочу акцентировать ваше внимание на том, как много в этих тепловых картах красного цвета, соответствующего высоким значениям целевой функции, и на том, как велика вероятность "не угадать" с параметрами, выбрать неправильную конфигурацию и получить завышенную стоимость эксплуатации системы.
ЦФ №2: (HDD + SSD) · Capacity
Во второй целевой функции мы вспоминаем о том, что у нас есть метаданные, которые надо хранить на SSD, и пытаемся ответить на вопрос:
«Каковы минимальные затраты и на медленные, и на быстрые диски, необходимые для хранения 1 ТБ клиентских данных?»
где:
— удельная стоимость SSD-носителей, отнесённая на 1 байт;
— объем фактически хранимых данных и метаданных.
Ответ — 68 долларов — достигается примерно при тех же параметрах, что и параметры оптимума целевой функции. Это максимальная компрессия при посредственной дедупликации — коэффициент стал еще ниже, чем в первом случае, и почти сравнялся с единицей.
Параметр |
Значение |
Chunking.AverageBits |
20 |
Chunking.ChunkLowerBound |
32 Б |
Chunking.ChunkUpperBound |
1 МБ |
Chunking.SingleChunkLimit |
128 КБ |
Deduplication Ratio |
1.01 |
Compression.ZSTD_Level |
19 |
Compression.Limit |
2 Б |
Оптимальный конфиг |
$68.0 |
Неоптимальный конфиг |
$86.3 (+27%) |
Целевая функция №3. (HDD + SSD) · Capacity + CPU
В третьей целевой функции мы вспоминаем о том, что для обработки данных нам требуются ресурсы центрального процессора. Компрессия — это вычислительно сложный алгоритм, поэтому нам надо добавить к предыдущей целевой функции стоимость вычислений. Для простоты будем считать, что мы записываем данные только один раз, и поэтому мы арендуем в каком-нибудь облачном сервисе CPU по цене около $0.02 за одно ядро за один час.
Instance name |
On-Demand hourly rate |
vCPU |
a1.medium |
$0.0255 |
1 |
Итоговый вариант целевой функции выглядит так:
где:
— рыночная стоимость аренды одного ядра в облачном сервисе;
— продолжительность нагрузочной сессии;
— средняя утилизация CPU во время записи данных.
Будем отвечать на вопрос:
«Каковы минимальные затраты на диски и аренду облачного CPU, необходимые для однократной записи и последующего хранения 1 ТБ клиентских данных?»
Параметр |
Значение |
Chunking.AverageBits |
20 |
Chunking.ChunkLowerBound |
1 Б |
Chunking.ChunkUpperBound |
1 МБ |
Chunking.SingleChunkLimit |
1 МБ |
Deduplication Ratio |
1.01 |
Compression.ZSTD_Level |
1 |
Compression.Limit |
1 Б |
Оптимальный конфиг |
$153 |
Неоптимальный конфиг |
$178 (+16%) |
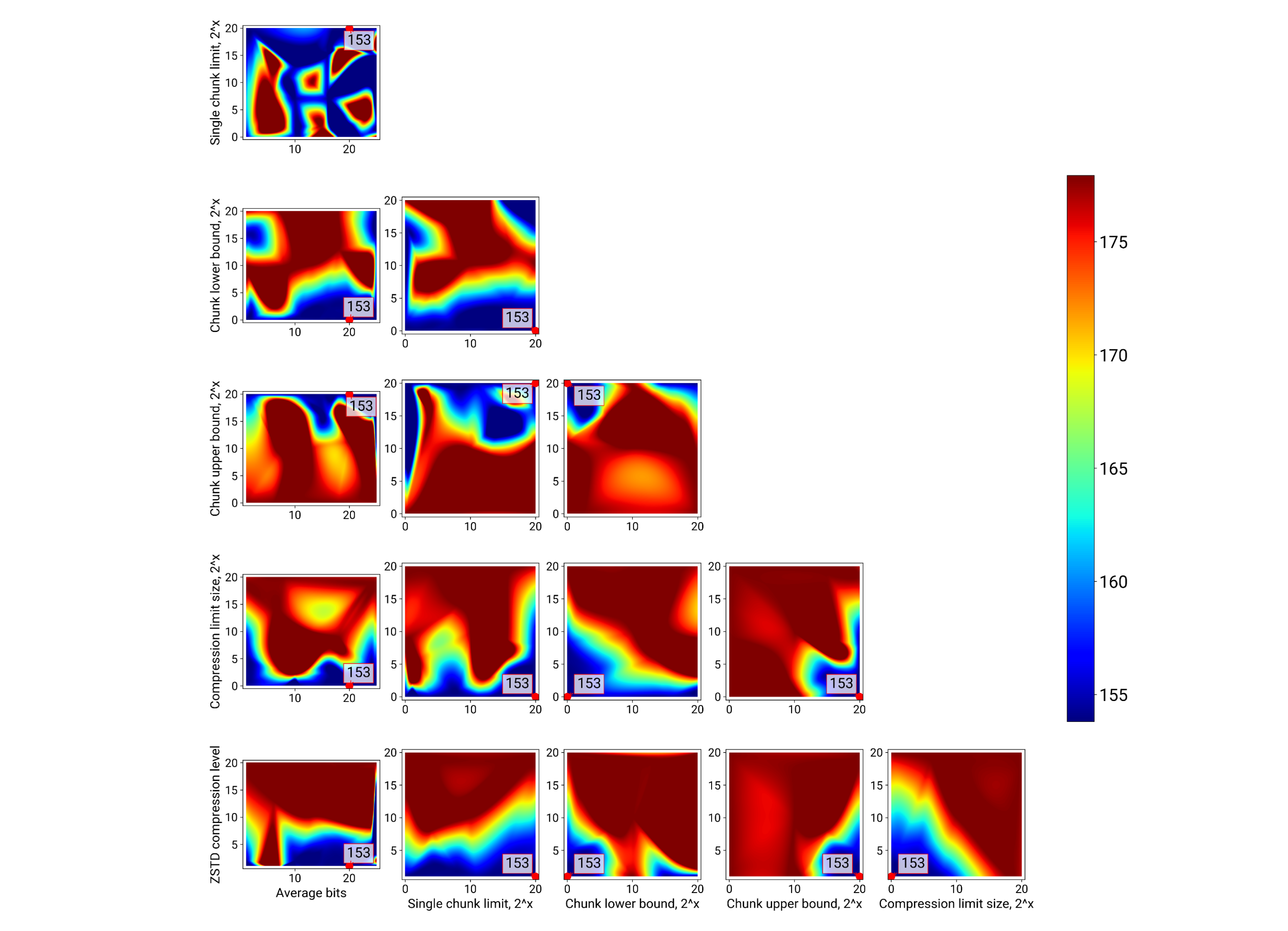
В такой формулировке целевой функции значение оптимума сразу же выросло до 153 долларов. Настройки (и результат) дедупликации примерно такие же, как и были раньше. А вот уровень компрессии оптимизатор снизил до единицы. Он определил, что те затраты, которые мы понесли на работу CPU, не компенсируются той экономией, которую мы получили на дисках, и помог нам выбрать сторону в балансе между затратами на дисковое пространство и затратами на CPU.
ЦФ №4: (HDD + SSD) · (Capacity + IO) + CPU
В четвертой целевой функции мы попробуем разобраться с таким важным фактором, определяющим стоимость хранения данных в любой СХД, как операции ввода/вывода. Сейчас мы ответим на вопрос:
«Каковы минимальные затраты на железо, которые нужны не только для хранения 1 ТБ данных, но и для постоянного приема и отдачи этих данных на скорости 1 Гбит/с?»
Подобная постановка вопросов заставляет нас существенно пересмотреть подход к конструированию целевой функции. Во-первых, теперь мы говорим не о периодической почасовой аренде облачного CPU, а о постоянном выполнении вычислительно сложных задач. Соответственно, мы должны купить нужное количество процессоров, которые будут работать непрерывно.
Во-вторых, при выборе дисков нам надо учитывать не только их объем, но и пропускную способность. В предыдущих трех целевых функциях мы отталкивались исключительно от средней стоимости 1 Тбайт дискового пространства. Но сейчас мы должны выбрать тот набор дисков, который будет подходить нам и по объему, и по пропускной способности, и при этом будет дешевле любого другого набора дисков, который удовлетворяет первым двум пунктам.
Третий методологический момент связан с тем, что работа оптимизатора выполняется на десктопном компьютере и, вследствие этого, на ограниченном объёме данных. В связи с этим существует риск, что данные окажутся полностью закэшированными в оперативной памяти. Если это произойдёт, мы не сможем увидеть истинный объём IO, генерируемый нашей системой, поэтому мы полностью отключаем все кэши, которые есть в объектном хранилище. Поскольку не буферизированный ввод/вывод через O_DIRECT мы так и не осилили, мы не можем полностью избежать размещения данных с дисков в page cache операционной системы и периодически, в начале каждой сессии, сбрасываем его вручную.
От чего же зависит стоимость HDD- и SSD-дисков? С HDD дисками все просто. Чем больше емкость диска и чем выше скорость вращения, тем выше стоимость.

С SSD дисками все немного посложнее. Помимо емкости и IOPS, существует еще один фактор стоимости — параметр надежности SSD-диска DWPD.

Как же нам выбрать ту модель диска, которая лучше всего подойдет для нашей инсталляции и сделает эксплуатацию хранилища наименее затратной? Может быть, нам купить топовые Intel Optane? Или за те же деньги приобрести Micron — в восемь раз более объемный, но в четыре раза более медленный? Или мы можем за те же деньги купить целую кучу десктопных SSD от Hikvision (насчет последнего я, конечно, шучу, потому что они не подходят для использования в серверных СХД с точки зрения надежности).

Решение этой задачи кроется в интеграции оптимизатора и модуля подбора дисков, который мы пока ещё не выложили в open source. Модуль подбора дисков итерируется по этой тепловой карте, и для каждой i-ой модели диска, потенциально подходящей под наши требования, рассчитывает:
— количество дисков модели i, достаточное для размещения нужного объёма данных;
— количество дисков модели i, достаточное для обеспечения нужной полосы пропускания.
Затем мы вычисляем максимум этих двух значений и получаем оценку количества дисков данной модели, которое удовлетворяет нас как по объему пространства, так и по пропускной способности:
Перемножая количество дисков i-ой модели на стоимость одного диска, мы получаем совокупную стоимость набора дисков данной модели:
Точно таким же образом мы формируем массив стоимостей для всех возможных моделей дисков и выбираем среди них минимальную.
Проделывая эту операцию по отдельности для HDD и SSD дисков, мы получаем итоговую формулу целевой функции:
Результат оптимизации этой целевой функции перед вами.
Параметр |
Значение |
Chunking.AverageBits |
3 |
Chunking.ChunkLowerBound |
1 Б |
Chunking.ChunkUpperBound |
1 МБ |
Chunking.SingleChunkLimit |
512 КБ |
Deduplication Ratio |
1.01 |
Compression.ZSTD_Level |
1 |
Compression.Limit |
1 Б |
Оптимальный конфиг |
$97 911 |
Неоптимальный конфиг |
$350 119 (+257%) |

Цифры получились достаточно внушительные, но они не должны вас смущать, потому что мы специально сконструировали такую конфигурацию системы, при которой фактически отказались от использования оперативной памяти. Мы сделали так, чтобы оптимизатор увидел реальное количество IO, которое генерируется нашей системой, и смог его оптимизировать. Тем не менее, параметры оптимума не отличаются от параметров оптимума предыдущей целевой функции.
В качестве приятного побочного эффекта оптимизатор выдал нам рекомендации по выбору дисков.
Рекомендации по дискам:
- HDD Western Digital WD5000 LPS 7200 RPM 0.5 ТБ — 227 шт.
- SSD Micron 5300 MAX 480 ГБ — 3 шт.
Оптимизатор предлагает купить большое количество самых маленьких nearline HDD-дисков со средней скоростью вращения. Таким образом, перед нами классическая проблема хранилищ, использующих традиционные накопители с низкой плотностью ввода-вывода (о связи IO Density и TCO можно подробнее почитать в статье Seagate о причинах появления HDD с двумя актуаторами). Мы «уперлись» в IO и вынуждены бороться с этим путем покупки большого количества шпинделей.
С SSD-дисками, напротив, никаких проблем нет — просто покупаем три штуки по числу реплик метаданных в нашем кластере.
ЦФ №5: (HDD + SSD) · (Capacity + IO) + CPU + RAM
В пятой целевой функции мы попытаемся учесть экономический эффект от использования оперативной памяти. Удельная стоимость хранения данных в DRAM гораздо выше, чем у SSD и HDD. При этом в любой системе у DRAM будет много разных потребителей. Здесь для простоты мы примем, что объектное хранилище может размещать в кэшах 20% от исходных данных, и добавим стоимость этого объёма оперативной памяти в нашу целевую функцию.
Как видно из таблицы, покупка заведомо более дорогого ресурса — оперативной памяти — неожиданно привела к снижению стоимости эксплуатации на 8% по сравнению с предыдущей целевой функцией. Что еще более интересно, оптимизатор увидел, что мы используем оперативную память и сумел вывести более оптимальную конфигурацию для дедупликации. В результате эмпирически определенный коэффициент дедупликации возрос до 1,08 (о связи дедупликации и эффективности работы кэша сегментов мы говорили выше).
Параметр |
Значение |
Chunking.AverageBits |
25 |
Chunking.ChunkLowerBound |
2 КБ |
Chunking.ChunkUpperBound |
1 МБ |
Chunking.SingleChunkLimit |
256 Б |
Deduplication Ratio |
1.08 |
Compression.ZSTD_Level |
1 |
Compression.Limit |
1 Б |
Оптимальный конфиг |
$90 798 |
Неоптимальный конфиг |
$340 505 (+275%) |
Таким образом, мы сэкономили на слое блочной дедупликации 8% — это уже хотя бы что-то. В качестве приятного дополнения появляется ещё и экономия на серверах и дисковых полках, ведь благодаря снижению IO нам теперь достаточно купить не 227 HDD-дисков, а всего лишь 153, для размещения которых потребуется гораздо меньше места в ДЦ.

Интерпретация результатов
Давайте вспомним, с чего мы начинали. Мы ожидали, что объектное хранилище, построенное по рассмотренной выше архитектуре, должно работать эффективно, если в его настройках одновременно включить максимальную дедупликацию сегментов и максимальную компрессию для всех объектов, кроме самых маленьких. Этот приём должен был устранить избыточность данных, сэкономить дисковое пространство и привести к снижению TCO хранилища.
Однако оптимизатор с помощью численных экспериментов показал нам, что несмотря на то, что эти меры действительно помогают снизить количество используемых HDD-дисков, общего снижения стоимости хранения данных не происходит. Чтобы оптимизировать TCO хранилища, мы должны ограничиться дедупликацией только самых крупных объектов, и при этом включить легкую компрессию.
Почему так получилось? Проблема в том, что мы использовали единые настройки чанкинга и компрессии для объектов всех размеров. Иными словами, и объекты размером 1 Кбайт, и объекты размером 1 Мбайт мы «нарезали» на чанки примерно одинакового размера.
Из-за того, что настройки чанкинга в сущности оказались слишком грубыми для нас, мы оказались перед трудным выбором. Использование маленьких чанков означает очень хорошо работающую дедупликацию и большую утилизацию процессорного времени на компрессию (вплоть до тайм-аутов при записи или чтении крупных объектов). Баланс в этом случае слишком сильно смещается в сторону экономии дискового пространства ценой неоправданных расходов на CPU.
С крупными чанками тайм-ауты не наблюдаются, но при этом и компрессия с дедупликацией практически не работают: здесь баланс сдвинут в сторону экономии CPU, и в силу того, что тайм-ауты для нас неприемлемы, оптимизатор избрал именно этот вариант настроек, фактически отключив блочную дедупликацию.
Очевидно, нам надо переходить к классам размеров и внедрять более тонкие настройки алгоритмов дедупликации и компрессии. Концепция класса размеров часто встречается в продвинутых аллокаторах памяти, например, в аллокаторе рантайма языка Go. Благодаря этому мы сможем подобрать оптимальные балансы потребления аппаратных ресурсов отдельно для каждого класса размеров и тем самым минимизировать стоимость хранения данных в системе.

Надеюсь, что в данной работе мне удалось раскрыть преимущества балансоориентированного подхода к проектированию софта, а также продемонстрировать широкие возможности современных методов оптимизации. Применение оптимизаторов, подобных RBFopt, позволяет в разумные сроки определить конфигурацию системы, при которой минимизируются затраты на её эксплуатацию. С помощью незначительных доработок оптимизатор превращается в мощный инструмент, позволяющий подобрать железо под конкретную нагрузку, а вдумчивый анализ результатов его работы может даже подсветить архитектурные проблемы, как это вышло и в нашем случае.
***
Если вас привлекают сложные инженерные задачи, приходите работать в МойОфис! Мы будем с радостью делиться собственным опытом и искать возможности для взаимного развития.
remendado
Остается надеяться, что минимизация затрат на эксплуатацию не затрагивает бэкапы.
codecity
Вопрос бекапов неплохо бы раскрыть, если таковые имеются
на табло.