Научно-техническая революция стимулирует спрос на вычисления. Последние полвека прогресс шёл в основном за счёт совершенствования железа. Но чипы приближаются к физическому пределу. Чтобы не снижать темпы развития, нужно улучшать программный код, повышая производительность вычислений. Требуют оптимизации в том числе базовые алгоритмы, такие как сортировка или хэширование, которые выполняются каждый день триллионы раз [1].
В то же время машинное обучение (нейросети) всё чаще используются для улучшения кода, созданного человека, а также для генерации собственного кода и для улучшения кода, сгенерированного им самим. Вот несколько примеров.
❯ Google AlphaDev ускорил сортировку
На Хабре упоминали эту новость. Если в двух словах, то в статье Nature, описывается — искусственный интеллект (ИИ) AlphaDev, разработанный инженерами Google Deepmind. Он использует обучение с подкреплением (reinforcement learning) для создания усовершенствованных алгоритмов. Руководит проектом Дэниел Манковиц (Daniel Mankowitz).
AlphaDev основан на AlphaZero, игровом ИИ, который побеждал чемпионов мира в го, шахматы и сёги.
Задачу поиска лучшего алгоритма сортировки коротких последовательностей чисел представили AlphaDev как игру одного игрока под названием AssemblyGame (игра в ассемблер).
Исследователи сосредоточились на улучшении алгоритмов сортировки коротких последовательностей из трёх-пяти элементов. Такие алгоритмы часто вызываются другими функциями сортировки. Результатом их улучшения будет ускорение сортировки уже любого количества элементов.
По итогу AlphaDev создал новые, небольшие алгоритмы сортировки на ассемблере, которые превзошли известные до сих пор и созданные человеком.
Чтобы сделать найденный алгоритм сортировки более удобным для людей, инженеры Google Deepmind провели его реверс-инжиниринг и перевели на один из самых популярных языков — C++. В стандартной библиотеке сортировки LLVM libc++ была сделана замена на алгоритм, созданный AlphaDev [2].
Сравнение кода программ на С++ и на ассемблере
a Пример на C++, который сортирует до двух элементов.
b Соответствующее представление кода на ассемблере.

То есть алгоритм сумел улучшить крошечную микропрограмму размером всего в дюжину инструкций. Такая казалось бы незначительная оптимизация в масштабе триллионов выполнений может привести к существенной экономии ресурсов.
Написание кода на ассемблере — это искусство сродни игре в шахматы или в го, работа без гарантированного результата. У реализации на ассемблере может быть как много вариантов, так и много возможностей всё испортить. Современные языки программирования, такие как C++ или Python, маскируют рутинную работу. В 1950-х годах, когда дебютировали языки «высокого уровня», стало бытовать мнение, что проблема с программированием в основном решена. До этого программирование было такой нудной рутиной на ассемблере, что один из первых языков высокого уровня Fortran после своего выхода подавался как «Fortran автоматическая система кодирования», потому что его операторы всегда транслировались в работающий ассемблерный код (Fortran — formula translator). Целью Фортрана было выдавать код лучше, чем смогли бы люди, и без ошибок. Сегодня это звучит смешно, но это было правдой.
Чаще всего улучшение таких языков, как C++ или Fortran, — это переделка на ассемблере, исключение лишних операций для оптимизации. В ассемблере отсутствуют формальные структуры и абстракции языков высокого уровня, и единственная ошибка может привести к нерабочему алгоритму. Игра в ассемблер для ИИ будет не на шутку, а всерьёз. Он будет терпеть неудачу снова, снова и снова, пока наконец не найдёт выигрышную стратегию.
На языках высокого уровня есть всего несколько алгоритмов для сортировки нескольких чисел в порядке возрастания. ИИ смог убрать в последовательности на ассемблере несколько инструкций, используя те инструкции — к которым, вероятно, и не подумал бы прибегнуть программист-человек.
Сети сортировки и алгоритмические усовершенствования, обнаруженные AlphaDev
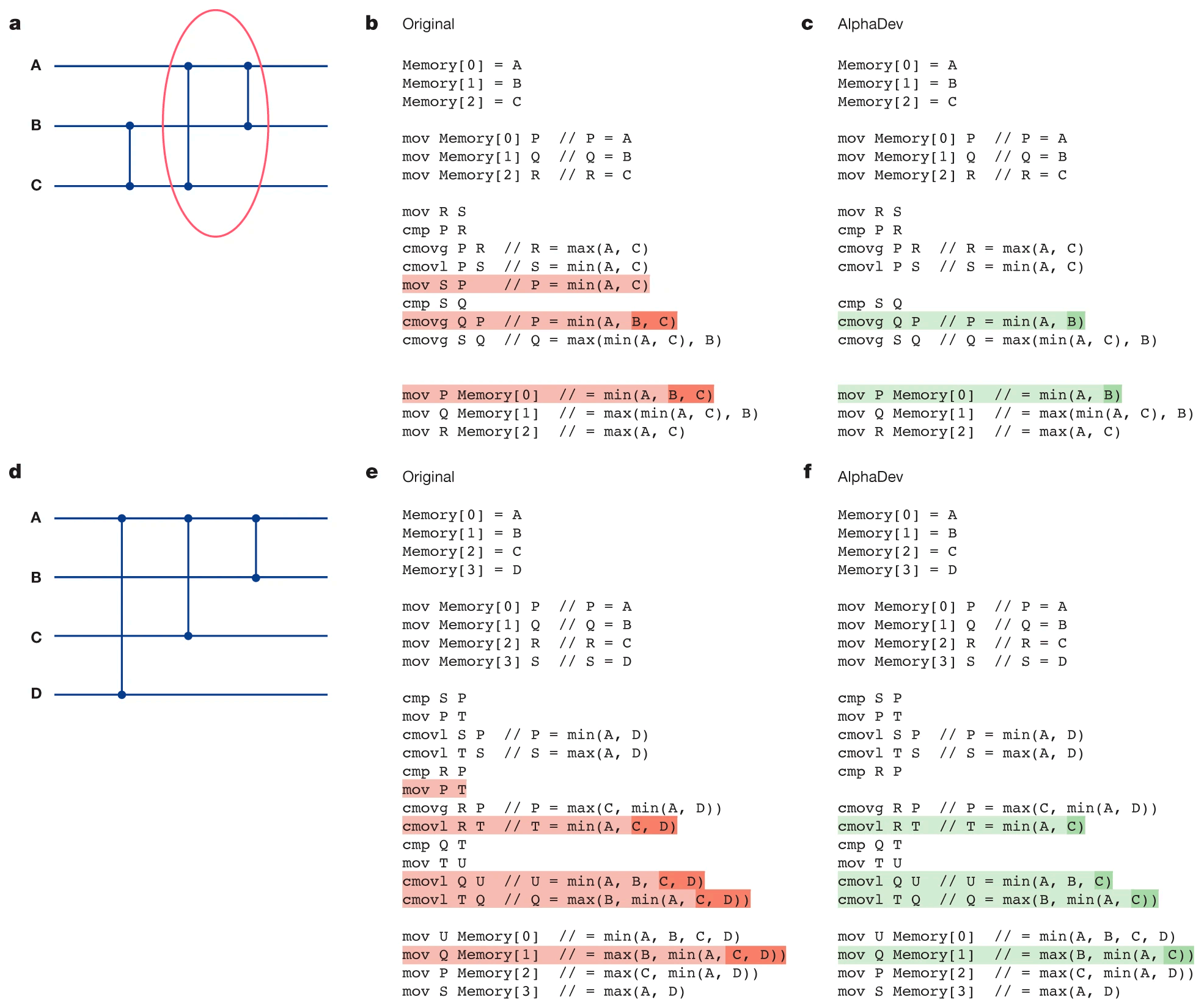
а Оптимальная классическая сортировочная сеть сортировки трёх значений. Компараторы, обведённые кружками, были улучшены AlphaDev.
b,c, Код ассемблера до применения операции своп-обмена AlphaDev и после применения операции своп-обмена AlphaDev, который привёл к удалению одной инструкции.
d Оптимальная классическая конфигурация компаратора сети сортировки, улучшенная AlphaDev.
e,f, Код ассемблера до применения копирования с перемещения AlphaDev и после применения копирования с перемещением AlphaDev, что привело к удалению одной инструкции.
От сортировки к хешированию в структурах данных
«Мы хотим оптимизировать весь вычислительный стек», — Дэниел Манковиц.
После быстрых алгоритмов сортировки исследователи Deepmind проверили, может ли AlphaDev обобщить и улучшить ещё один насущный алгоритм в информатике — хэширование.
Как результат, в этом году AlphaDev добавил новый алгоритм хеширования (9-16 байт) в библиотеку Abseil с открытым исходным кодом.
❯ ИИ (не) заменит программистов
ИТ-руководители в United Airlines, Johnson & Johnson, Visa, Cardinal Health, Goldman Sachs в восторге от потенциала генеративного ИИ для автоматизации процесса написания кода, ожидают значительное повышение производительности. Но выражают опасение, что использование ИИ приведёт к снижению входного барьера, к росту уровня сложности, технического долга и неразберихе, а им придётся разгребаться с управлением этим раздутым как шар ПО.
«Рост технического долга и мёртвого кода всегда будет проблемой» — говорит Трейси Дэниэлс (Tracy Daniels), директор по данным в финансовой компании Truist.
«Есть риск, что мы будем завалены большим количеством низкопробного кода, написанного машиной», — Армандо Солар-Лезама, профессор Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института.

«Это значительно усложняет задачу ИТ-директора, хотя и облегчает задачу программиста», — Вивек Джетли (Vivek Jetley), исполнительный вице-президент и руководитель отдела аналитики в EXL, компании, занимающейся анализом данных, цифровыми операциями и решениями.
Какие профессии могут исчезнуть
Адам Хьюз (Adam Hughes), разработчик программного обеспечения, доктор философии (PhD) с докторской степенью в области экспериментальной биофизики со специализацией в области нанотехнологий и разработки программного обеспечения, недавно выступил с несколькими статьями и с прогнозом, что ИИ возьмёт на себя 99% работы по программированию.
По его мнению, это произойдёт в течение десяти лет в несколько этапов:
- Прототипирование ИИ (I кв. 2023 г) — прогноз потери рабочих мест: 2%
Начавшиеся в Твиттере увольнения технических специалистов, скорее совпадение по времени.
- Масштабирование и проникновение в IDE (II-IV кв. 2023 г) — прогноз потери рабочих мест: 5%
ИИ может генерировать шаблонный код прямо из IDE, без копирования и вставки из чата.
- Расширенный инструментарий IDE и консолидация (один-два года) — прогноз потери рабочих мест: 25%
На этом этапе ИИ должен иметь возможность делать предложения по всему проекту.
Потеря работы коснётся малоэффективных или неспособных к работе с ИИ программистов.
Специалисты по виртуальной реальности или разработчики игр будут по-прежнему в безопасности.
- SaaS (Software as a service) и No-Code (2–5 лет) — прогноз потери работы: 75%
Отмирание кодирования в IDE.
Уйдут универсальные программисты полного цикла, рабочие группы (product team) и разработчики мобильных приложений.
Теперь будут под угрозой нишевые области: видеоигры и медицинское программное обеспечение.
- Превалирование нативного ИИ (5–10 лет) — прогноз потери работы: 95%
Нет необходимости оптимизировать код для человеческого понимания, поскольку поддержка кода людьми больше не осуществляется.
Отмирают модульные тесты, документация и шаблоны проектирования.
Для пользователей станет неинтересным какое работает ПО, как сейчас не задумываются какая прошивка у портативного калькулятора.
Новое оборудование и компиляторы будут предназначены для операторов ИИ.
- «Тепловая смерть» (10+ лет) — прогноз потери работы: 99%
Программное обеспечение становится неузнаваемым, бизнес-правила на базе ИИ поддерживаются малыми и средними предприятиями.
Код больше не находится в статических репозиториях — он эфемерен и динамичен.
Конечно, всё ещё останутся кодеры-любители, но их деятельность не будет иметь большого значения.
Правда, не все согласны с таким пессимистическим сценарием. По крайней мере, если смотреть на текущие возможности автоматической генерации кода в Copilot и ChatGPT, то в нём по-прежнему много ошибок и полностью доверять ему нельзя.
Например, по статистике Github, пользователи принимают около 30% кода, который предлагает Copilot. Интересно, что процент принятия растёт с увеличением времени использования этого инструмента.
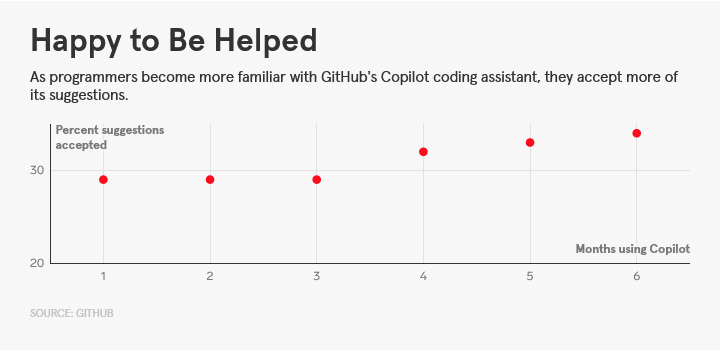
Однако исследование Стэнфордского университета показало, что у программистов, которые прибегают к помощи ИИ, количество ошибок в коде увеличивается. Так что всё не так однозначно, как говорится…
❯ Литература:
- Amazon. Amazon S3—two trillion objects, 1.1 million requests/second. AWS (2013).
- Gelmi, M. Introduce branchless sorting functions for sort3, sort4 and sort5. LLVM.org https://reviews.llvm.org/D118029 (2022).
- Deepmind’s AI Is Learning About the Art of Coding
- AlphaDev discovers faster sorting algorithms
- LLVM. LLVM users https://llvm.org/Users.html (LLVM, 2022).
- Richard Eisenberg. The Future of Programming
- Adam Hughes, ChatGPT Will Replace Programmers Within 10 Years
- Adam Hughes, Nervous ChatGPT Will Steal Your Programming Job?
- Andrej Karpathy. Software 2.0
- Ask HN: Those with success using GPT-4 for programming – what are you doing?
- The Future of Programming – Interview with Richard Eisenberg | Hacker News
Возможно, захочется почитать и это:
- ➤ Искусственный интеллект как React-разработчик
- ➤ Есть проблемы гораздо сложнее, чем NP-Complete
- ➤ Stable vs Photoshop: сравнение генераций
- ➤ MiniGPT-4, ты что за зверь такой?
- ➤ Восстание машин или как человек противостоял компьютеру за шахматной доской

Комментарии (23)

lazy_val
03.07.2023 09:11+1Что в таком случае мешает нанять лучших разработчиков по каждому языку
Очевидно, мешать будет их отсутствие. Если мы 99% сократили, остались только 1% "кодеров-любителей" - откуда возьмутся "лучшие разработчики"? Из "кодеров-любителей"?

OlegZH
03.07.2023 09:11+2Страшно не само сокращение. Всё-равно, потом придётся нанимать тех же для того. чтобы разгрести образованные ИИ завалы. Страшно то, то имеется безоглядная вера в ИИ, который сделает жизнь красивой. А тут нужна корректная постановка практически значимой задачи. А ИИ нужен для того, чтобы упорядочить накопленный опыт. Другими словами, результатом работы ИИ должна быть большая глобальная компонентная библиотека ПО. Вот такая библиотека и способна оставить без работы кучу программистов. Ведь, тогда, при разработке любой системы будет достаточно определить её класс и автоматически получить готовый код.

forthuse
03.07.2023 09:11+1Игра в ассемблер для ИИ будет не на шутку, а всерьёз. Он будет терпеть неудачу снова, снова и снова, пока наконец не найдёт выигрышную стратегию.
Интересно, что и достаточно формализованный язык Форт (Forth), к тому же имеющий принятые стандарты и по модели его построения и использования близкий к естественным языкам за счёт использования в коде концепции конкатенации кода, тоже ещё не особо
по "зубам" AI ввиду того, что, вероятно, методология создания на нём кода не типовая задача. и ПО для обучения AI на нём, возможно, специально не размечалось для алгоритмов обучения.P.S. Мой любимый вопрос к AI по Форт (Forth):
Показать код на Форт (Forth) примеров метапрограммирования. :)
Forth в скобках к слову Форт желательно использовать т.к. AI, может путать его с Фортраном.

event1
03.07.2023 09:11+5Правда, не все согласны с таким пессимистическим сценарием.
Но они не получат просмотры и цитирование за своё несогласие. А автор апокалиптических прогнозов получит.

novoselov
03.07.2023 09:11Авторы не учитывают социальные факторы, уменьшение зарплат программистов приведет к падению качества программистов. Зачем учиться чему-то сложному, когда за более простую работу (физическую, сервисную, менеджерскую, научную) платят больше. Можно иметь среднее образование, средние навыки, а код AI как-нибудь сгененерируют за тебя.
"Нам не нужно много программистов, нам нужна кучка самых умных", а откуда возьмутся самые умные если они всем сразу будут нужны? Как итог еще большая конкуренция за топовых специалистов и рост зарплат. С учетом уменьшения новых кадров, спрос на старые будет только расти, а значит будет расти и разрыв в зарплате между junior и top senior.
При этом AI будет отбирать все больше простой работы и создавать потребность в решении более сложных задач (рост сложности технологий никто не отменял). Единственный вариант преодоления пропасти между желающими стать программистами и тем уровнем который будет реально востребован, это обучение с помощью AI. Пока я даже близко не вижу прогресса в этом направлении, EdTech очень запаздывает.

MyWave
03.07.2023 09:11+2Может есть какой-нибудь плагин для хрома чтобы таких вот авторов не видеть на главной никогда в жизни?

semennikov
03.07.2023 09:11+1Помнится когда появился AutoCAD тоже был вопль что конструкторам конец, однако да, исчезли чертежники, копировщики и другие профессии однако конструктора как были так и остались, их даже больше стало

3263927
03.07.2023 09:11мне очень интересно посмотреть на клиента который будет писать ч0ткое ТЗ для искусственного интеллекта для проекта который он хочет получить. а потом когда какая-нибудь маленькая штука будет работать немного не так как он хочет, как он будет объяснять что вот это не совсем так работает как я хочу, измените это пожалуйста... интересно было бы посмотреть на это. похожие истории были с PHP и 1С - все думали что на вот щас бизнес будет программировать сам, так легко же! в итоге всё только усложнилось и программистов стало только на порядок больше
lazy_val
Простой вопрос.
В язык программирования X добавлена фича Y (например, в Go 1.18 добавлены generics). Откуда ИИ (Copilot, ChatGPT, ...) узнает что это такое и как с ним работать? Сейчас все, что предлагает ИИ, основано на уже имеющемся коде и примерах его использования. А если фича новая, и примеров кода еще нет? По крайней мере в количестве, достаточном для обучения модели ИИ.
holodoz
Видится два варианта: ждать или сгенерировать корпус текстов с новой фичей самостоятельно.
lazy_val
Совершенно верно. И для этого нам понадобятся разработчики (много) применяющие фичу в реальных задачах. А мы 99% этих разработчиков сократили уже за ненадобностью.
TedDenisenko
Что в таком случае мешает нанять лучших разработчиков по каждому языку, чтобы они "объясняли", как пользоваться новой фичей?
Условно, была задача, которую можно было решить с помощью Х, теперь при помощи У она решается быстрее, пример переписывается под новый стандарт и скармливается
lazy_val
Например, по запросу "stackoverflow.com golang CRUD" гугл возвращает 219.000 результатов.
Дальше нетрудно оценить, сколько понадобится человеко-часов "лучших разработчиков" для того, чтобы переписать хотя бы каждый десятый фрагмент кода с использованием дженериков. Хорошо, пусть нам не требуется для обучения переписать 20.000 примеров, пусть будет только две тысячи.
А ведь на CRUD история не заканчивается. Например, запрос "stackoverflow.com golang k8s API" возвращает два миллиона результатов с копейками. Ну и так далее.
За скобками остается вопрос о том, сколько времени понадобится "лучшим разработчикам" на то, чтобы вкурить новые фичи, и не подъедут ли к этому времени фичи новые.
OlegZH
Наверное, считается, что генеративное машинное обучение способно само извлекать наилучшее, даже если в обучающей выборке нет наилучшего, или оно исчезающе непредставительно.
К тому же, не стоит недооценивать роль той просто лавинообразной обратной связи, которую получили в последние месяцы разработчики генеративного ИИ и которую можно считать эдаким подкреплением изначальных модельных построений.
dgoncharov
Простой ответ (и вполне серьезный): ИИ не нужно знать про эту новую фичу, т.к. он может сгенерировать вполне качественный код без ее использования.
Новые фичи в ЯП нужны для людей, а не для компьютеров и компиляторов. Фичи, т.е. новые абстракции - для того, чтобы было легче и удобнее мыслить. Если же человек исключается из процесса, то высокоуровневые ЯП становятся не нужны, и кодогенерацию можно делать сразу непосредственно в ассемблер (ну или в веб-ассемблер, или в коды Java-машины и т.п.)
Но даже если в процессе "компиляции русского языка в машинный код" и используются промежуточные языки, то степень их высоко- или низко-уровневости уже не будет иметь значения в большинстве случаев. Разве что для формальной верификации или дебага.
lazy_val
Человек из процесса исключен не может быть в принципе, для обучения ChatGPT (и предшествующих ему GPT-3.5, GPT-3 и т.д.) привлекались "разметчики" (labelers), то есть вполне живые разработчики (если говорить об обучении в части языков программирования).
Ну только если ИИ научится сам себя обучать программированию без размеченных данных, но это точно не про GPT.
dgoncharov
ОК, это уже сделано. Зачем этим заниматься еще раз? Только из-за того, что мы придумали еще один ЯП (который ничем не лучше старых, и будущая его востребованность под большим вопросом)?
Еще раз, ему не будет нужно обучаться "программированию" в том смысле, какой вкладывают в это слово современные разработчики ПО. Более вероятно, что он будет создавать работающее ПО не путем подражания мыслительным процессам человека, а иными способами. И сама эта идея не нова, эксперименты на этот счет (напр. genetic programming) были и раньше. И если все тесты будут успешно проходить, то какая разница?
lazy_val
Хотя бы затем что на ChatGPT 4 история не завершилась. Как не завершилась до этого на GPT-3, к примеру. Будут новые модели, их надо будет обучать, а как обучить бота писать код без этапа supervised learning - пока не придумали.
Да, возможно. Но таких моделей ИИ (дающих результаты, хотя бы сопоставимые с ChatGPT) еще не существует. И неизвестно - появятся ли, и если появятся, то когда? Давать прогнозы "через 5 лет потеряют работу 75% разработчиков, через 10 лет 99%" на основании того, что в марте 2023 появился ChatGPT 4 - довольно странная идея.
ArZr
На самом деле, сомнительные утверждения. Некоторые мысли:
Отказ от абстракций => увеличение размера программы (не всегда, но все же) => увеличение количества токенов, которых нужно сгенерировать. Последнее, в частности, ведет к увеличению затрат на 1 генерацию, увеличению кол-ва ошибок в коде и вероятным проблемам с размером контекста модели. Ну, а уж если окажется, что в сгенерированном коде найдется критическая ошибка, которую модель в упор не может исправить даже после внушительного числа запросов... не позавидуешь программистам, которым придется разгребать это чудо. Нет, можно, конечно, нафантазировать, что вот совсем скоро все эти проблемы возьмут да как-то решатся, но я в этом сомневаюсь. А до тех пор новые фичи ЯП потенциально будут способны смягчать недостатки модели, следовательно, ИИ вполне будут нужны эти фичи.
Обобщая рассматриваемую ситуацию с "обучением модели новой фиче" - положим, что каким-то образом был открыт принципиально новый алгоритм (или структура данных - неважно), который позволяет в разы эффективнее решать какие-то акутальные задачи; дополнительно положим, что в силу новизны существующие на момент открытия модели если и способны сгенерировать этот алгоритм, то делают это исключительно редко. Как заставить ИИ использовать это открытие? Или это тоже будет гарантированно не нужно?
Так что, если не вдаваться в необоснованные фантазии уровня "ИИ будет способен писать эффективный код без всего этого", то данные вопросы оказываются куда сложнее.
sabay
Машине не нужен синтаксический сахар - для нее написать для каждого типа одинаковый код не стоит ничего. Так что Дженерики в го или наследование в c++ это все для нас. Машина может держать все детали в памяти и ког генерируемый ей будет мне кажется не пригодным для людей. Да сейчас ChatGPT генерирует код привычный нам, с логичными названиями переменных и даже комментариями. Но это потому что он обучен на коде написанном людьми и к тому же цель его разработчиков пока в том чтобы код был "для людей". Дальше критерии для обучения будут меняться - так что в конечном итоге языки программирования в привычном нам виде развиваться больше не будут. Но это я думаю не так скоро все будет. А пока кодить будем сами - и думаю долго.
lazy_val
Первые два шага (из трех) в обучении GPT включают работу "разметчиков", на первом шаге они вручную завершают предложенные им фразы (ну или фрагменты кода), на втором - выбирают наиболее предпочтительные варианты продолжения из предложенных моделью ИИ, обученной на данных шага 1. Чтобы эта работа могла быть выполнена и успешно завершена ограниченной группой людей в разумные сроки, код должен быть написан на ЯП высокого уровня. Ну не машинный же код они будут сочинять и ранжировать.
Теоретически (наверное) можно результаты обучения на ЯП высокого уровня транслировать в язык ассемблера / машинный код / байткод, и шаг 3 "обучение с подкреплением" (reinforcement learning) выполнять уже для этого кода. В этом случае да, код в формате, понятном человеку, тут особо уже и не нужен. Проблема заключается в том, что даже если 99% такого кода будет работать как надо, ошибки, вызываемые оставшимся 1% надо будут как-то кому-то анализировать и исправлять. А человечество уже лет 70 как ушло от программирования в машинных кодах, и вряд ли станет к этому возвращаться.
Автор публикации (https://levelup.gitconnected.com/chatgpt-will-replace-programmers-within-10-years-91e5b3bd3676), с которой, собственно, весь это разговор и начался, на вопрос про исправление ошибок отвечает "ну живые разработчики ведь тоже ошибки допускают, и что?" А то, что в 9999 случаях из 10000 (условно) для исправления найденной ошибки не нужно лезть в машинный код или байткод, все делается средствами разработки и отладки ЯП высокого уровня.
Поэтому возможно что
но
event1
Искин будет писать напрямую на ассемблере. С goto и без классов. Но это временно. Потом он станет процессором и будет напрямую показывать людям на экране то, что они хотят видеть
lazy_val
... а потом в какой-то момент и люди станут неуместными.
Да, было такое кино