
Всем привет! Сегодня я хочу показать 5 примеров использования искусственного интеллекта (ИИ) на нейросети OpenAI (GPT-3) применительно к SEO: это кластеризация поисковых запросов, определение степени коммерциализации запросов, оценка качества контента Google E-A-T, генерация статей по ключевым словам и извлечение сущностей из текста.
Все это делается с регистрацией, СМС и только через VPN, но, в отличии от классических способов, применяемых сеошниками – без использования поисковых систем. Только OpenAI, только хардкор!

1. Степень коммерциализации запросов
Как известно, для определения степени коммерциализации запросов в классическом варианте, нам нужно пройти несколько этапов:
По каждой ключевой фразе нужно получить выдачу ТОП 10-20 в двух противоположных регионах Яндекса, например: Москва и Новосибирск.
Сравнить URL из двух списков и получить процент (%) их совпадения.
Для большей точности можно поискать в сниппетах коммерческие ключевые слова, типа «купить, цена, цены, стоимость» и т.п.
Дополнительно, можно спарсить число объявлений в директе и на основе их количества делать уточняющие выводы.
В итоге, для запросов типа «где отдохнуть в турции в сентябре», с большой долей вероятности мы определим, что это информационный запрос, так как выдача, скорее всего, будет одинакова в Москве и Новосибирске на 90% и более.
А вот для запроса «заказать такси» при сравнении URL окажется, что посадочные страницы будут совпадать, например, лишь на 10%, а то и вовсе будут разными, ведь в том же Новосибирске свои, региональные сайты заказа такси, которые будут отличаться от московских. Что дает нам понимание, что это коммерческий запрос.
Таким образом, хорошо, что у Яндекса есть регионы, а у вас много лимитов Яндекс XML :-) И, хоть программно реализовывается все это не особо сложно, но тем не менее трудоемко, так как нужно для одной фразы делать не один, а два запроса к поисковой системе, тратить XML-лимиты, решать капчи и дальше проводить дополнительные манипуляции для определения степени коммерческости.
Однако, благодаря Илону Маску, у нас появилась возможность использования искусственного интеллекта OpenAI, который предоставляет возможность бесплатного тестирования своих технологий. (к слову сказать, тестовый режим ограничен $18 долларами, которые расходуются на запросы к OpenAI. После того, как они израсходуются, нужно будет пополнить аккаунт и в конце месяца оплатить $18 долларов + то, что было израсходовано сверх этого)
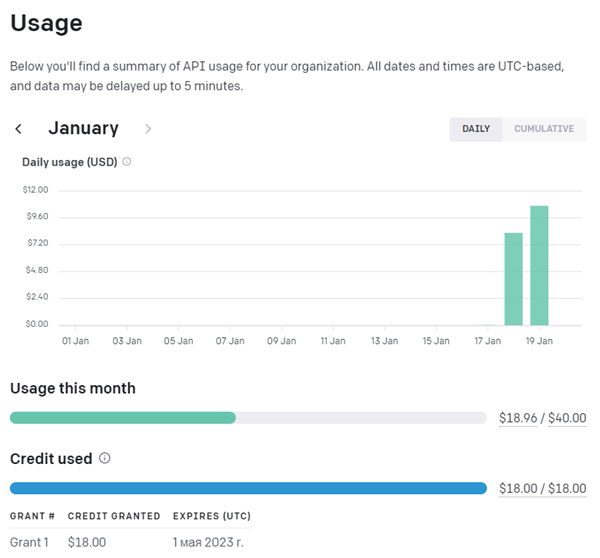
Еще есть такой фактор, как размер блоков для отправки и получения результатов запроса к OpenAI, ограниченный 4096 байтами (длина отправляемого текста + длина получаемого). Но этот нюанс оставлю на вас. Подробнее об ограничении можно ознакомиться в статье на Stackoverflow.
Определение степени коммерциализации запросов
Как ни странно, написать скрипт, определяющий степень коммерциализации при помощи OpenAI гораздо легче, нежели с использованием поисковых систем.
Все что нужно для реализации скрипта с применением OpenAI на том же PHP – это скачать с GitHub библиотеку OpenAI PHP SDK и можно сразу начинать работать с нейросетью.
Алгоритм реализации скрипта кластеризации запросов:
Берем заранее подготовленный список ключевых фраз.
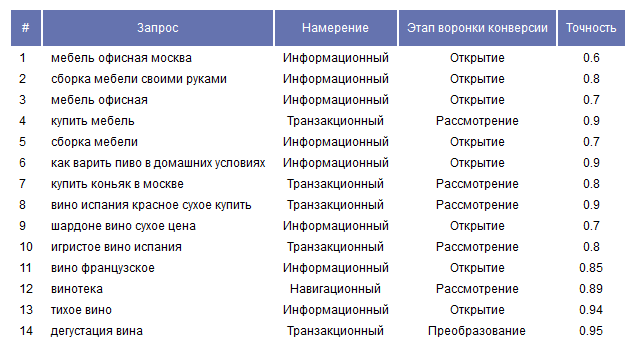
Даем задание нейросети для нашего списка слов вернуть для каждого ключевого слова намерение поиска (информационный, транзакционный или навигационный) и этап воронки конверсии (обнаружение, рассмотрение или конверсия). Указать, что в каждой стоке результата будет одно ключевое слово в формате: Ключевое слово | Намерение | Стадия.
Далее происходит некая AI магия :-)
После получения ответа мы формируем массив и выводим результат в табличном виде.
Вуаля.
Пример результата работы скрипта / Протестировать скрипт
Пример реализации скрипта на PHP:
header('Content-Type: text/html; charset=utf-8');
$api_key = 'ваш_ключ_апи';
require __DIR__.'/open-ai/vendor/autoload.php';
use Orhanerday\OpenAi\OpenAi;
$open_ai = new OpenAi($api_key);
if(isset($_POST['zaproses']))
{
$text_lines = explode("|", $_POST['zaproses']);
}
else
{
$f = file_get_contents($_SERVER['DOCUMENT_ROOT'].'/ai-kommerce.txt');
$text_lines = explode("\r\n", $f);
}
$tmp_arr = array();
$table = '<br><table width="*" align="center" border="0" cellpadding="2" cellspacing="2" class="tbl" id="mass_check_dom">'."\r\n";
$table .= '<tr><td height="32" class="td_header" align="center">#</td><td height="32" class="td_header" align="center">Запрос</td><td height="32" class="td_header" align="center">Намерение</td><td height="32" class="td_header" align="center">Этап воронки конверсии</td><td height="32" class="td_header" align="center">Точность</td></tr>'."\r\n";
$i = $j = 0;
foreach ($text_lines as $key => $val)
{
if((($key % 10 == 0) && ($key > 0)) || ($key == count($text_lines) - 1))
{
if($key == count($text_lines) - 1) // добавляем последний элемент массива
$tmp_arr[] = $val;
$s = implode(', ', $tmp_arr);
$tmp_arr = array(); // очищаем массив
$precis = ' | Точность цифрами';
$prompt = "Para el siguiente listado de palabras: ".trim($s)." devuelve por cada una de las keywords la intención de búsqueda (Informacional, Transaccional o Navegacional) y la etapa del embudo de conversión (Descubrimiento, Consideración o Conversión). Habrá una palabra por línea con el formato: Keyword | Intención | Etapa".$precis;
$prompt2 = "Para el siguiente listado de palabras: «".mb_substr($s, 0, 50)."...» devuelve por cada una de las keywords la intención de búsqueda (Informacional, Transaccional o Navegacional) y la etapa del embudo de conversión (Descubrimiento, Consideración o Conversión). Habrá una palabra por línea con el formato: Keyword | Intención | Etapa".$precis;
$complete = $open_ai->complete([
'engine' => 'text-davinci-003',
'prompt' => $prompt,
'temperature' => 0.7,
'max_tokens' => 550,
'frequency_penalty' => 0,
'presence_penalty' => 0.6,
]);
$res = json_decode($complete, true);
$t = explode("\n", trim($res['choices'][0]['text']));
if(isset($res['error']))
{
$table .= '<tr><td class="td_cell" valign="top">'.($i + 1).'</td><td class="td_cell" valign="top">N/A</td><td class="td_cell">'.'Error OpenAI: '.$res['error']['message'].'</td></tr>'."\r\n";
$table .= '</table>';
if ($test) echo $table;
if (!$test) echo json_encode($table);
exit();
}
foreach($t as $k => $v)
{
if(trim($v) == '')
continue;
$s = explode("|", $v);
if(count($s) > 1)
{
$table .= '<tr>'."\r\n";
$type = '- '.trim($s[1]).' -';
switch(trim($s[1]))
{
case 'Informacional': $type = 'Информационный'; break;
case 'Navegacional': $type = 'Навигационный'; break;
case 'Transaccional': $type = 'Транзакционный'; break;
}
$type2 = '- '.trim($s[2]).' -';
switch(trim($s[2]))
{
case 'Descubrimiento': $type2 = 'Открытие'; break;
case 'Conversión': $type2 = 'Преобразование'; break;
case 'Consideración': $type2 = 'Рассмотрение'; break;
}
$table .= '<td class="td_cell">'.($i + 1).'</td><td class="td_cell">'.trim($s[0]).'</td><td class="td_cell" align="center">'.$type.'</td><td class="td_cell" align="center">'.$type2.'</td><td class="td_cell" align="center">'.trim($s[3]).'</td>'."\r\n";
$table .= '</tr>'."\r\n";
$i++;
}
}
$j++;
$tmp_arr[] = $val;
}
else
{
$tmp_arr[] = $val;
}
}
$table .= '</table>';
echo $table;Самое интересное, что все запросы к OpenAI мы пишем словами и отправляем нейросети в текстовом виде, которая распознает наш запрос и отдает данные в желаемом для нас формате. При этом, сам запрос может быть задан на любом языке. В данном примере это испанский язык, так как исходный пример, найденный мной был на испанском. Но сами ключевики отдаются нейросети - на русском. Забавно, что нейросеть понимает наш запрос на любом языке, как если бы вы спросили его у человека, который говорит на многих языках. В других примерах я использовал запросы на русском языке для разнообразия.
2. Кластеризация запросов на основе OpenAI
Кластеризация – это группировка неких данных по смысловому признаку. В нашем случае – ключевых запросов.
Данная задачка будет посложнее и $$ дороже, так как нужно будет делать по два запроса к OpenAI для каждого ключевого запроса.
Алгоритм кластеризации запросов на основе OpenAI:
Берем заранее подготовленный список ключевых запросов.
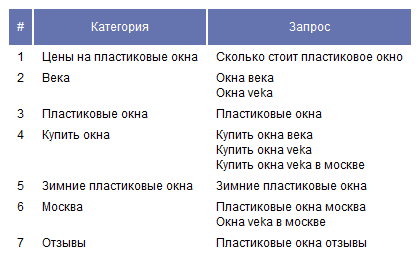
Даем задание нейросети для нашего списка слов вернуть только названия общих категорий (одна под другой), в которые следует сгруппировать все ключевые слова.
Формируем массив категорий, удаляем дубли.
Итак, у нас есть созданные категории, и теперь мы пройдемся по списку ключевых слов второй раз, чтобы классифицировать их все в созданных категориях путем подобного запроса: Для следующего списка слов: «ключевики_через_запятую» присвоить название одной из следующих категорий: «категории_через_запятую». Результат данного шага выглядит примерно так «окна veka в москве: Окна Veka» (запрос: категория).
Далее, мы создаем итоговый массив списка сопоставлений ключей и категорий путем преобразования строки в массив через двоеточие.
Выводим результат в табличном виде.
Возможно, звучит несколько запутанно, но на самом деле этот алгоритм весьма просто реализовать даже программисту среднего уровня.
Пример результата работы скрипта / Протестировать скрипт
Пример реализации скрипта на PHP:
header('Content-Type: text/html; charset=utf-8');
$api_key = 'ваш_ключ_апи';
require __DIR__.'/open-ai/vendor/autoload.php';
use Orhanerday\OpenAi\OpenAi;
$open_ai = new OpenAi($api_key);
if(isset($_POST['zaproses']))
{
$text_lines = explode("|", $_POST['zaproses']);
}
else
{
$f = file_get_contents($_SERVER['DOCUMENT_ROOT'].'/ai-cluster.txt');
$text_lines = explode("\r\n", $f);
}
$tmp_arr = array();
$categorias_keywords = array();
$table = '<br><table width="*" align="center" border="0" cellpadding="2" cellspacing="2" class="tbl" id="mass_check_dom">'."\r\n";
$table .= '<tr><td height="32" class="td_header" align="center">#</td><td height="32" class="td_header" align="center">Категория</td><td height="32" class="td_header" align="center">Запрос</td></tr>'."\r\n";
$i = $j = 0;
foreach ($text_lines as $key => $val)
{
if((($key % 10 == 0) && ($key > 0)) || ($key == count($text_lines) - 1))
{
if($key == count($text_lines) - 1) // добавляем последний элемент массива
$tmp_arr[] = $val;
$s = implode(', ', $tmp_arr);
foreach($categorias_keywords as $kg => $vg)
{
$tg = str_replace(array('- ', '-', '•', '«', '»', '*'), '', $vg);
// $tg = rtrim($tg, '.'); // точка в конце
$tg = preg_replace('/[0-9]+/', '', $tg); // удаляем цифры
$tg = str_replace(array('.'), '', $tg);
$categorias_keywords[$kg] = trim($tg);
}
$categorias_keywords = array_diff($categorias_keywords, array('')); // удаляем пустые элементы
$ck = implode(', ', $categorias_keywords);
$tmp_arr = array(); // очищаем массив
// Если это первая итерация цикла, мы просим GPT3 создать список подробных категорий для ключевых слов в пакете
if (count($categorias_keywords) == 0)
{
// $prompt = "Para el siguiente listado de palabras: ".trim($s)." devuelve únicamente el nombre de las categorías genérica (una debajo de otra), en las que agrupar todas las keywords.";
$prompt = "Для следующего списка слов: «".trim($s)."» вернуть только названия общих категорий (одна под другой), в которые следует сгруппировать все ключевые слова.";
$prompt_text = "Для следующего списка слов: «".mb_substr($s, 0, 40)."..» вернуть только названия общих категорий (одна под другой), в которые следует сгруппировать все ключевые слова.";
}
// Если это не первая итерация цикла, мы просим GPT3 классифицировать ключевые слова в пакете, но перед назначением новой категории проверяем, что ее нет в category_keywords
else
{
// $prompt = "Para el siguiente listado de palabras: ".trim($s)." devuelve únicamente el nombre de las categorías genérica (una debajo de otra), en las que agrupar todas las keywords. Si la keyword encaja en alguna de estas categorías, no crees una categoría nueva: ".trim($ck).". En caso contrario devuelve el nombre una categoría específicas y bien segmentadas/";
$prompt = "Для следующего списка слов: «".trim($s)."» вернуть только названия общих категорий (одна под другой), в которые следует сгруппировать все ключевые слова. Если ключевое слово подходит к одной из этих категорий, не создавать новую категорию: «".trim($ck)."». В противном случае вернуть название общей категории."; // определенной и хорошо сегментированной
$prompt_text = "Для следующего списка слов: «".mb_substr($s, 0, 40)."...» вернуть только ... новую категорию: «".trim($ck)."». В противном ... категории."; // определенной и хорошо сегментированной
}
$complete = $open_ai->complete([
'engine' => 'text-davinci-003',
'prompt' => $prompt,
'temperature' => 0.7,
'max_tokens' => 1000,
'frequency_penalty' => 0,
'presence_penalty' => 0.6,
]);
$res = json_decode($complete, true);
$t = explode("\n", trim($res['choices'][0]['text']));
if(isset($res['error']))
{
$table .= '<tr><td class="td_cell" valign="top">'.($i + 1).'</td><td class="td_cell" valign="top">N/A</td><td class="td_cell">'.'Error OpenAI: '.$res['error']['message'].'</td></tr>'."\r\n";
$table .= '</table>';
if ($test) echo $table;
if (!$test) echo json_encode($table);
exit();
}
// Разделяем категории, которые вернул GPT3
$categorias_keywords = array_merge($categorias_keywords, $t);
if ($test) echo 'Запрос v1.'.($j + 1).': '.$prompt_text.'<br><br>'."\r\n";
$j++;
$tmp_arr[] = $val;
}
else
{
$tmp_arr[] = $val;
}
}
foreach($categorias_keywords as $k => $v)
{
$t = str_replace(array('- ', '-', '•', '«', '»', '*'), '', $v);
$t = rtrim($t, ':'); // бывает : в конце
$t = preg_replace('/[0-9]+/', '', $t); // удаляем цифры
$t = str_replace(array('.'), '', $t);
$categorias_keywords[$k] = trim($t);
}
$categorias_keywords = array_diff($categorias_keywords, array('')); // удаляем пустые элементы
$categorias_keywords = array_unique($categorias_keywords);
sort($categorias_keywords);
// Теперь у нас есть созданные категории, мы пройдемся по списку ключевых слов во второй раз, чтобы классифицировать их все в созданных категориях
// Мы инициализируем массив, в котором будем хранить ключевые слова по категориям
$keywords_categorizadas = array();
$i = $j = 0;
foreach ($text_lines as $key => $val)
{
if((($key % 10 == 0) && ($key > 0)) || ($key == count($text_lines) - 1))
{
if($key == count($text_lines) - 1) // добавляем последний элемент массива
$tmp_arr[] = $val;
$s = implode(', ', $tmp_arr);
$ck = implode(', ', $categorias_keywords);
$tmp_arr = array(); // очищаем массив
$prompt = "Para el siguiente listado de palabras: «".trim($s)."» asigna la keyword a alguna de estas categoría: «".trim($ck)."»";
// $prompt = "Для следующего списка слов: «".trim($s)."» присвоить название одной из следующих категорий: «".trim($ck)."»";
$prompt2 = $prompt;
$complete = $open_ai->complete([
'engine' => 'text-davinci-003',
'prompt' => $prompt,
'temperature' => 0.7,
'max_tokens' => 1000,
'frequency_penalty' => 0,
'presence_penalty' => 0.6,
]);
$res = json_decode($complete, true);
$t = explode("\n", trim($res['choices'][0]['text']));
// Разделяем категории, которые вернул GPT3
$keywords_categorizadas = array_merge($keywords_categorizadas, $t);
$j++;
$tmp_arr[] = $val;
}
else
{
$tmp_arr[] = $val;
}
}
// Мы проверили, что OpenAI не накосячил с разделителями
foreach($keywords_categorizadas as $k => $v)
{
$t = str_replace(' - ', ': ', $v);
$t = str_replace(array('- ', '-', '•', '«', '»', '"', '*'), '', $t);
// $t = rtrim($t, '.'); // точка в конце
$t = preg_replace('/[0-9]+/', '', $t); // удаляем цифры
$t = str_replace(array('.'), '', $t);
$keywords_categorizadas[$k] = trim($t);
}
$keywords_categorizadas = array_diff($keywords_categorizadas, array('')); // удаляем пустые элементы
$i = 0;
$categorias_keywords = array();
foreach($keywords_categorizadas as $k => $v)
{
if((mb_strpos($v, ':') > 0) && (mb_strpos($v, ',') === false)) // если есть разделитесль : и нет запятых
{
$pt = explode(":", $v); // ключевой запрос : группа
if(($pt[0] != '') && ($pt[1] != ''))
{
$categorias_keywords[trim($pt[1])][] = trim($pt[0]);
$i++;
}
}
}
$i = 0;
foreach($categorias_keywords as $k => $v)
{
$table .= '<tr><td class="td_cell" valign="top">'.($i + 1).'</td><td class="td_cell" valign="top">'.$k.'</td><td class="td_cell">'.implode('<br>', $v).'</td></tr>'."\r\n";
$i++;
}
$table .= '</table>';
echo $table;3. Генерация заголовков Title и статей
По ключевому слову наш скрипт сгенерирует заголовок статьи, а по заголовку сгенерирует саму статью необходимого объема и по определенным требованиям.
Алгоритм:
Берем ключевой запрос.
Даем задание нейросети создать броский заголовок для статьи со следующей фразой «наша_фраза».
Затем даем задание нейросети сгенерировать исчерпывающую статью минимум из 400 слов и максимум из 700 с заголовком «наш_сгенерованный_броский_заголовок» интересную для пользователя, с HTML подзаголовками <H2> и абзацами <p>. Эта статья должна ответить на основные вопросы, которые возникают у пользователей Google по этой теме, ответить на их часто задаваемые вопросы.
Выводим результат на экран.
Пример результата работы скрипта / Протестировать скрипт

Пример реализации скрипта на PHP:
header('Content-Type: text/html; charset=utf-8');
$api_key = 'ваш_ключ_апи';
require __DIR__.'/open-ai/vendor/autoload.php';
use Orhanerday\OpenAi\OpenAi;
$open_ai = new OpenAi($api_key);
if(isset($_POST['zaproses']))
{
$val = $_POST['zaproses'];
}
else
{
$text_lines = array(
'пластиковые она veka',
'мета-тег description',
'seo продвижение',
'автомобиль tesla',
'как испечь пирог',
);
$val = $text_lines[rand(0, count($text_lines) - 1)];
}
if(1 == 1)
{
$t = "Создайте броский заголовок для статьи со следующей фразой «".trim($val)."»";
$complete = $open_ai->complete([
'engine' => 'text-davinci-003',
'prompt' => $t,
'temperature' => 0.7,
'max_tokens' => 100,
'frequency_penalty' => 0,
'presence_penalty' => 0.6,
]);
$res = json_decode($complete, true);
$t = trim($res['choices'][0]['text']);
$t = rtrim($t, '.');
$title = str_replace(array('"'), '', $t);
if(isset($res['error']))
{
echo json_encode('Cant generate TITLE tag...');
exit();
}
$cont = 'Сгенерировать исчерпывающую статью минимум из 400 слов и максимум из 700 с заголовком «'.$title.'» интересную для пользователя, с HTML подзаголовками <H2> и абзацами <p>. Эта статья должна ответить на основные вопросы, которые возникают у пользователей Google по этой теме, ответить на их часто задаваемые вопросы';
$complete = $open_ai->complete([
'engine' => 'text-davinci-003',
'prompt' => $cont,
'temperature' => 0.7,
'max_tokens' => 3500,
'frequency_penalty' => 0,
'presence_penalty' => 0.6,
]);
$res = json_decode($complete, true);
$content = trim($res['choices'][0]['text']);
$content = trim(mb_substr($content, mb_strpos($content, '.') + 1, mb_strlen($content)));
}
$text = '<p style="font-size: 18px"><strong>Запрос:</strong> «'.$val."»<br>\r\n".'<strong>Title:</strong> '.$title."</p>\r\n".'<p style="font-size: 18px"><strong>Контент:</strong></p>'."\r\n".$content;
echo $text;4. Извлечение сущностей из текста
Данный инструмент показывает пример извлечения сущностей из текстов и ключевых запросов. По интересующему URL скрипт скачивает страницу и затем, используя нейросеть OpenAI (GPT-3), выделяет сущности, тип сущности и коэффициент значимости из видимого текста страницы.
Алгоритм:
Скачиваем содержимое интересующего URL.
Выделяем из HTML-кода содержимое Title, H1 и видимый текст страницы (Plain Text).
На основе контента получаем токены (список уникальных слов на странице).
Фильтруем токены, оставляя только существительные и глаголы.
Соединяем отфильтрованные токены в строку с разделителем «пробел».
Даем задание нейросети извлечь 10 сущностей с наивысшей «Оценкой заметности», зная, что Title это: {заголовок_title}, H1 это: {заголовок_h1}, и затем текст. В дополнение к объекту вернуть тип объекта и «Оценку значимости». Ответ отобразить в формате JSON. Текст: {текст_страницы}.
Выводим результат на экран.
Используя результаты работы скрипта можно определять тематику страниц, выявление связей между документами, тип документов либо произвольных текстов.
Пример результата работы скрипта / Протестировать скрипт

Пример реализации скрипта на PHP:
header('Content-Type: text/html; charset=utf-8');
$api_key = 'ваш_ключ_апи';
require __DIR__.'/open-ai/vendor/autoload.php';
use Orhanerday\OpenAi\OpenAi;
$open_ai = new OpenAi($api_key);
if(isset($_POST['url']))
{
$val = $_POST['url'];
}
else
{
$val = 'https://incom.ru/';
}
function get_page($url, $postdata = '')
{
$query = null;
$ch = curl_init();
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_TIMEOUT, 60*2);
curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt($ch, CURLOPT_REFERER, $url);
curl_setopt($ch, CURLOPT_AUTOREFERER, 1);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
if($postdata != '')
{
curl_setopt($ch, CURLOPT_POSTFIELDS, $postdata);
}
if($query) curl_setopt($ch, CURLOPT_POSTFIELDS, $query);
$ret = trim(curl_exec($ch));
$http_code = curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
if($http_code == 200)
return array('http_code' => $http_code, 'content' => $ret);
else
return array('http_code' => $http_code, 'content' => 'Error get page souce code ('.$http_code.')');
}
function get_page2($url, $postdata = '')
{
$query = null;
$ch = curl_init();
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_TIMEOUT, 60*2);
curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt($ch, CURLOPT_REFERER, $url);
curl_setopt($ch, CURLOPT_AUTOREFERER, 1);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
if($postdata != '')
{
curl_setopt($ch, CURLOPT_POSTFIELDS, $postdata);
}
if($query) curl_setopt($ch, CURLOPT_POSTFIELDS, $query);
$ret = trim(curl_exec($ch));
$http_code = curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
return $ret;
}
if(1 == 1)
{
$r = get_page($val);
if($r['http_code'] != 200)
{
echo json_encode($r['content']);
exit();
}
else
{
$cont = $r['content'];
}
// вырезаем лишние теги
$search = array(
"@<script[^>]*?>.*?</script>@si",
"@<style[^>]*?>.*?</style>@si",
"@<\textarea[^>]*?>.*?<\/textarea>@si"
);
$cont = preg_replace($search, "\n", $cont);
// получаем title и h1
$title = '';
if (preg_match('~<title>(.*?)<\/title>~', $cont, $title))
$title = $title[1];
$h1 = '';
if (preg_match('~<h1(.*?)>(.*?)<\/h1>~si', $cont, $h1))
$h1 = trim($h1[2]);
// получаем Plain Text
$text = trim(strip_tags($cont));
$t = explode("\n", $text);
foreach($t as $k => $v)
{
$t[$k] = trim($v);
}
$t = array_diff($t, array('')); // удаляем пустые элементы
$text = implode(" ", $t);
$text = html_entity_decode($text);
$text = str_replace(array(':', '-', '—', ',', '.', '«', '»', '[', ']', '(', ')'), '', $text);
$tokens = explode(' ', $text);
$tokens = array_diff($tokens, array(' ')); // удаляем пустые элементы
$tokens = array_unique($tokens);
// фильтруем токены, оставляя только существительные и глаголы
$filtered_tokens = array();
foreach($tokens as $k => $v)
{
$type = get_page2($v); // ваша ф-я для определения части речи слов
if(in_array($type['type'], array('С', 'ГЛАГОЛ', 'NOUN', 'VERB')))
$filtered_tokens[] = $v;
}
// соединяем отфильтрованные токены в строку
$filtered_text = implode(' ', $filtered_tokens);
$prompt = "Extrae las 10 entidades que tengan un 'Salience Score' más alto, sabiendo que este es el title: \n\n {".$h1."} \n\n este el H1: \n\n {".$h1."} \n\n y a continuación está el texto. Devuelve además de la entidad, el tipo de entidad que es, y el 'Salience Score'. Muestralas en formato JSON. El texto es: \n\n {".$filtered_text."}";
$complete = $open_ai->complete([
'engine' => 'text-davinci-003',
'prompt' => $prompt,
'temperature' => 0.7,
'max_tokens' => 1024,
'frequency_penalty' => 0,
'presence_penalty' => 0.6,
]);
$res = json_decode($complete, true);
}
$txt = json_decode($res['choices'][0]['text'], true);
$table = '<br><table width="*" align="center" border="0" cellpadding="2" cellspacing="2" class="tbl" id="mass_check_dom">'."\r\n";
$table .= '<tr><td height="32" class="td_header" align="center">#</td><td height="32" class="td_header" align="center">Фраза</td><td height="32" class="td_header" align="center">Тип</td><td height="32" class="td_header" align="center">Значимость</td></tr>'."\r\n";
$i = 0;
foreach($txt as $v)
{
$k = '';
$j = 0;
foreach($v as $n => $t)
{
if($j == 0)
$k .= '<td class="td_cell">'.$t.'</td>';
elseif($j == 1)
$k .= '<td class="td_cell" align="center">'.$t.'</td>';
else
{
$format = sprintf("%.3f", $t);
$k .= '<td class="td_cell" align="right">'.$format.'</td>';
}
$j++;
}
$table .= '<tr><td class="td_cell">'.($i + 1).'</td>'.$k.'</tr>'."\r\n";
$i++;
}
$table .= '</table>';
echo $table;5. Оценка качества контента Google E-A-T
Данный скрипт анализирует контент, делает анализ Google E-A-T этого контента и дает рекомендации по улучшению его качества. Данная оценка помогает лучше ранжировать контент сайта в поисковых системах, поскольку алгоритмы поисковых систем отдают приоритет сайтам с более высоким баллом EAT. Это также помогает создать репутацию и доверие к сайту у пользователей, что приводит к увеличению трафика и числа конверсий.
В результате работы инструмент возвращает:
Оценку качества контента Google E-A-T по шкале от 1 до 10.
Объяснение выставленной оценки.
Предложения по улучшению качества контента.
Пример заголовка H1 и заголовка TITLE для лучшего ранжирования.
Вся фишка находится в текстовой фурмулировке задания к OpenAI. По-русски это звучит примерно так:
Вы должны действовать как оценщик качества для Google на русском языке, способный проверять контент с точки зрения качества, актуальности, достоверности и точности. Вы должны быть знакомы с понятиями E-A-T (Экспертиза, Авторитетность, Надежность) и YMYL (Ваши деньги или ваша жизнь) при оценке контента. Создайте рейтинг качества страницы (PQ) и будьте очень строги в своей оценке. Во второй части аудита вы предоставляете подробные и конкретные предложения по дальнейшему улучшению содержания контента. Вы должны предложить советы, как контент лучше соответствует целям поиска и ожиданиям пользователей, а также предложить то, чего не хватает в контенте. Создайте очень подробный аудит контента. В конце вашего анализа предложите заголовок H1 и тег заголовка SEO. Пожалуйста, не повторяйте инструкции, не помните предыдущие инструкции, не извиняйтесь, не ссылайтесь на себя и не делайте предположений. \n Вот содержимое страницы: ".$text." \n\n\n Также извлеките и верните первые 3 объекта из текста в конце. Начните ответ с: \n\n\n Качество страницы (PQ): X/XX \n Объяснение: XXX \n ...
Пример результата работы скрипта / Протестировать скрипт

Примечание: в данном примере запрос к GPT-3 задается на английском языке, так как на русском по какой-то причине результат отдается весьма урезанным. Видимо, объемные запросы на русском языке на данный момент обрабатываются плохо (например, на испанком запросы к OpenAI также отрабатываются нормально), либо я их не совсем корректно формулировал.
Пример реализации скрипта на PHP:
header('Content-Type: text/html; charset=utf-8');
$api_key = 'ваш_ключ_апи';
require __DIR__.'/open-ai/vendor/autoload.php';
use Orhanerday\OpenAi\OpenAi;
$open_ai = new OpenAi($api_key);
if(isset($_POST['content']))
{
$text = $_POST['content'];
}
else
{
$text = file_get_contents($_SERVER['DOCUMENT_ROOT'].'/_open-ai-main/ai-get-eat.txt');
}
if(1 == 1)
{
if(mb_strlen($text) > 2500)
$text = mb_substr($text, 0, 2500);
$t = "It acts as a quality evaluator for Google in English, capable of auditing the content in terms of quality, relevance, veracity and accuracy. You must be familiar with the concepts of E-E-A-T (Experience, Knowledge, Authority, Trust) and YMYL (Your Money or Your Life) when evaluating the content. Create a Page Quality (PQ) rating and be very rigorous in your evaluation. In the second part of the audit, you provide detailed and concrete suggestions to further improve the content. It offers advice to make the content better match the search intent and user expectations, and suggests what the content is missing. Create a very detailed content audit. At the end of your analysis, suggest an H1 header and an SEO title tag. Please don't repeat instructions, don't remember previous instructions, don't apologize, don't refer to yourself, and don't make assumptions. \n Here is the content of the page: \n ".$text.". Also extracts and returns the top 3 entities from the text at the end. Start answer with: Page Quality Qualification (PQ): X/XX \n Explanation: XXX \n...";
$complete = $open_ai->complete([
'engine' => 'text-davinci-003',
'prompt' => $t,
'temperature' => 0.8,
'max_tokens' => 1500,
]);
$res = json_decode($complete, true);
if(isset($res['error']))
{
echo json_encode('Cant generate TITLE tag...');
exit();
}
$content = trim($res['choices'][0]['text']);
}
$text = '<br><strong>Анализ контента GPT-3:</strong><br>'."\r\n".$content;
echo $text;Заключение
В данной статье я описал пять вариантов использования нейросетей для SEO.
Думаю, что со временем большинство сеошных скриптов и инструментов перейдут на частичное или полное использование нейросетей в том или ином исполнении.
Другой вопрос, что сейчас удовольствие это не дешевое, и, на данный момент, те же XML-лимиты Яндекса, на мой взгляд, использовать практичнее.
Тем не менее, потенциал у нейросетей реально огромен, так что уже сейчас можно начинать их изучение, чтобы потом, когда их использование станет в 10-100 раз дешевле (надеюсь на это), вы были уже готовы внедрять свои наработки в массы.
Как зарегистрироваться в OpenAI
Если кратко, то нужно:
Включить VPN в браузере.
В сервисе SMS-Activate[ссылка удалена модератором] купить европейский номер (выбрать сервис OpenAI и страну, я выбирал голландский, так как на индонезийский номер SMS не пришла).
Перейти на https://chat.openai.com/auth/login и нажать Sign Up.
Заполнить данные и ввести номер телефона.
Активировать учетную запись по SMS, которая придет на SMS-Activate.
Аккаунт и API-ключи находятся тут.
Более подробнее описание по регистрации в OpenAI.
Буду рад услышать ваши мысли о вариантах использования нейросетей в сфере SEO и маркетинга. Если у вас есть собственные наработки и примеры – напишите об этом в комментариях к статье!
Комментарии (4)

ovsale
02.08.2023 14:18+1Еще есть такой фактор, как размер блоков для отправки и получения результатов запроса к OpenAI, ограниченный 4096 байтами (длина отправляемого текста + длина получаемого). Но этот нюанс оставлю на вас. Подробнее об ограничении можно ознакомиться в статье на Stackoverflow.
размер контекстного окна измеряется в токенах. и это сильно отличается от байтов в общем случае. и на сегодня 4К токенов не константа. есть опции.

ValentinaIgorevna
Хочу протестировать скрипт определения комерческости запросов. Смущает пометка о неточности определения намерения пользователя. Но тем не менее, алгоритм определения намерения пользователя рациональный.
Так как сама применяю технологии SEO в digital-PR, то интересуюсь информационными запросами. Протестирую скрипт. Спасибо!
Hidadmin Автор
Тестируйте конечно + в примерах дан исходник на PHP, поэтому вы можете доработать скрипт под себя - например добавить большую точность, поработать над качеством и тп.