Без хранилища данных не заработает ни одно stateful-приложение, это известно всем. А вот как и какое хранилище развернуть - это вопрос к специалистам. На платформе dBrain.cloud объектный storage можно разворачивать на Ceph, Minio или даже внешнем хранилище клиента. Платформа dBrain позволяет работать по различным сценариям. Сегодня расскажем, как мы “готовим” Ceph и в каких случаях используем TopоLVM и Minio.
Объектное хранилище необходимо для хранения и управления большими объемами информации - аудио и видеофайлы, документы, сообщения чатов и письма. Оно позволяет связывать метаданные с каждым объектом, чтобы пользователи легко находили, извлекали и управляли данными. Объектное хранилище обеспечивает неизменность данных и многопользовательские процессы, позволяет управлять жизненным циклом данных и их архивированием.
Если мы говорим о микросервисах, то хранилища нужны и для корректной работы Kubernetes. В dBrain мы используем Ceph для больших кластеров, Minio и TopоLVM - для более мелких, чтобы не расходовать ресурсы на сущности Ceph, которые на небольших кластерах не нужны.
Самописный деплой в Kubernetes
Ceph - распределенное хранилище с простым принципом действия: расположенные на разных серверах диски объединяются в одно пространство с единой точкой входа. С помощью Ceph данные распределяются равномерно. Исключается перекос нагрузки, когда на каком-то сервере занято больше дисков, чем на других.
Разработку dBrain мы начали в 2016 году. Тогда же стал вопрос об объектном storage. На тот момент выбор среди свободных опенсорсных решений был невелик - GlusterFS и Ceph. Оба решения были довольно сырые. Подкупало то, что Ceph использовался в одной из крупнейших в мире лабораторий физики высоких энергий CERN (та самая, где построили большой адронный коллайдер). В CERN разворачивали свое большое хранилище для экспериментов, Ceph они допиливали под себя.
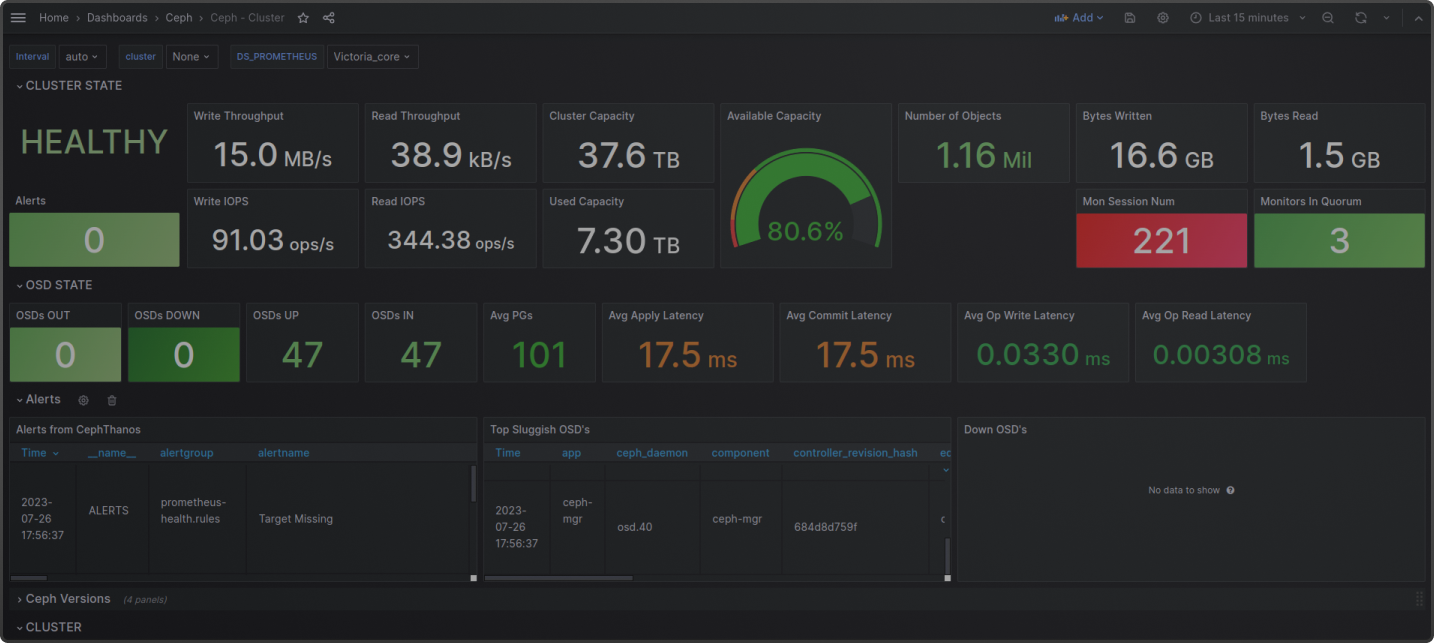
Попробовав Gluster и Ceph на нескольких виртуалках, остановились на Ceph. В нем из коробки были утилиты мониторинга, которые показывали статус хранилища, RBD, сeph df, сeph health и status, сeph osd tree, списки дисков (какой из них в апе или дауне, как идет ребаланс) и др. Кроме того, Ceph довольно просто разворачивался на больших кластерах.
Как мы рассказывали раньше, у нас есть свой описанный деплой Kubernetes, процесс полностью автоматизирован. Ceph мы деплоим в Kubernetes самостоятельно, не используя готовые решения. Это обеспечивает централизованное управление хранилищем. Наш деплой описан на Ansible Playbooks. Мы разворачиваем Ceph внутри кластера Kubernetes, потому что так проще управлять его сущностями. Например, при большом количестве Ceph-OSD для рестарта одной из них нужно зайти на конкретный сервер и перезапустить службу. Когда все находится в Kubernetes, можно из консоли dBrain сделать рестарт пода, который работает с OSD - и она перезапустится. Таким же образом можно остановить под, если диск, например, вышел из строя, Это весьма удобно при обслуживании и обновлении кластера Ceph.

В своей работе на больших кластерах мы столкнулись с тем, что Ceph может быть очень чувствителен к качеству сетевой инфраструктуры. В 21 веке кажется очевидным, что сеть должна корректно работать, но как показала практика, иногда это не может гарантировать оператор связи/ЦОД. Поэтому, конечно, для бесперебойной работы любого решения необходимо хорошее сетевое оборудование, без потерь и ретрансмитов пакетов, с низкими сетевыми задержками, особенно внутри приватной сети Ceph.
А что с репликацией данных? Мы храним несколько копий одних и тех же данных. Это позволяет при выходе из строя каких-либо дисков не останавливать работу, а отдавать данные с других копий и в это время проводить процедуру восстановления и балансировки на других серверах. Ceph позволяет этим очень гибко управлять, из одной точки (некого админского пода) можно видеть всю структуру хранилища. Если на какой-то ноде возникает проблема с диском, то с этой же машины можно выбросить диск из кластера, чтобы он не влиял на работу.
Используя большое распределенное сетевое хранилище данных, мы получаем единое пространство как для выделения дисков в виде блочных устройств RBD через CSI K8s, так и для произвольных пулов под S3 storage. Так, можно создавать нужное количество storage-классов. При этом не будет привязки к конкретным нодам, а выделенный через Ceph-CSI Persistent Volumes можно динамически монтировать к нужным нодам, в зависимости от того, куда переедет рабочая нагрузка.
Структура Ceph сильно завязана на быстродействие доступа к дискам. Сетевое хранилище работает как единое целое, если какие-то узлы начинают тормозить или выдавать ошибки, это замедляет работу всего хранилища в целом.
Для отказоустойчивости мы применяем различные режимы репликации данных в Ceph: в виде тройной/двойной репликации (для критичных данных) и erasure coding (для менее критичных). Например, для пула hdd на многих кластерах успешно эксплуатируется конфигурация erasure coding 8+3 на уровне больших объемов данных при долгосрочном хранении. При использовании такой конфигурации допускается выход из строя до 3 из 11 дисков OSD без потери данных.
Для самых маленьких
Ceph - это общее хранилище, которое у себя может предоставлять клиентам несколько интерфейсов доступа к данным: RBD (RADOS Block Device) блочные устройства, протокол хранения данных S3, Swift и другие. На маленьких кластерах, слимах, где одна-три ноды, разворачивать Ceph нецелесообразно. Его системные компоненты используют очень много ресурсов. В таких случаях выгоднее и разумнее развернуть Minio как S3 Storage и TopоLVM для RBD.

Minio реализует один протокол - S3. В dBrain можно поставить Minio и превратить локальный диск в хранилище, у которого будет доступ по определенному протоколу извне. Minio тратит меньше вычислительных мощностей, поэтому мы используем его в рамках мелких кластеров, он проще в реализации. И хотя Minio - сервис, который реализует голый S3, известны случаи, когда разработчики собирают на нем и петабайтные хранилища.
Но нужно понимать, что Minio плохо масштабируется. Расширить сервис очень сложно - через механизм федерации кластеров. При этом их нужно сращивать друг с другом, но данные из одного кластера в другой перетекать не будут. Проще целиком пересоздать хранилище. На Minio можно создать изначально большой кластер, но обслуживать его очень сложно. По сути, для увеличения хранилища в Minio поднимается еще один кластер бОльшего размера, и со старого данные автоматически перекачиваются в новый. Ceph в отличие от Minio реализует не только S3, но еще и RBD диски для подов. Ceph легко масштабируется, автоматически ребалансит данные, восстанавливает их и т.д.
TopоLVM - метод организации локальных дисков в управляемое программное хранилище. Сервис реализует механизм хранения данных поверх Linux LVM. Если мы используем на маленьких сетапах TopоLVM, то в этом случае вынуждены привязывать Stateful-приложения к определенной ноде, на которой находится выделенный storage. И если выходит из строя нода, то данные именно этого пода становятся временно недоступны или потеряны.
Kubernetes по своей структуре, базе данных подразумевает использование распределенного отказоустойчивого сетевого хранилища данных - Ceph, Gluster или др. Но это не всегда актуально, иногда заказчики хотят, чтобы данные какой-нибудь рабочей нагрузки хранились прямо на хосте, чтобы перформанс был выше или лишний трафик не шел по сети. Платформу dBrain можно развернуть и на локальном внешнем хранилище, она будет работать, у нас есть такой опыт. Но в таком случае пользователь должен понимать: локальный storage привязан к конкретной машине, если хост выйдет из строя, то данные будут утеряны.

Все компоненты dBrain стоят на учете в системе логирования и мониторинга (о них можно почитать тут и тут). Конечно, это касается Ceph, Minio и TopоLVM. Метрики собираются и идут в дашборды Grafana. В консоли платформы есть автоматический ресайз PVC и управление S3 - создание и удаление бакетов.
Применяемые в dBrain технологии хранения данных обеспечивает лучшую масштабируемость, гибкость и надежность платформы для микросервисов в составе высоконагруженных приложений. Внедренные в dBrain решения позволяют работать по различным сценариям, обслуживать кластеры любого размера.
Какие объектные хранилища вы используете в своих проектах? С какими трудностями сталкиваетесь при развертывании Ceph, Minio, TopоLVM? Делитесь в комментариях.
V-King
Конкретно за объектное хранилище не скажу, но использовали OCFS2 в качестве кластерной fs. Т.е. шариш с СХД-шки iSCSI, на нодах моунтишь iSCSI, на LUN-е нарезаешь OCFS2 и настраиваешь моунт этого раздела на всех нодах кластера. На микропроектах до 3-5 нод, где CEPH оверкилл, glusterfs и пр. не подходят, OCFS очень даже к месту.