Бывает такое: смотришь кино, слышишь OST или просто какую-то хорошую песню, которую решили вставить в фильм, и думаешь — а неплохо бы её добавить к себе в плейлист. Способов сделать это было несколько. Можно было пойти и поискать или сам OST к фильму, или неофициальные саундтреки к нему. Можно было посмотреть, что по названию фильма выдаётся в поиске через музыкальные стриминговые сервисы, вдруг какая-то площадка уже позаботилась о вас и собрала тематический плейлист. Отдельные граждане прямо во время фильма включали на смартфоне Shazam и распознавали трек. В общем, кто во что горазд.
Мы решили сделать для Кинопоиска функцию, которая будет (если вам это нужно) прямо во время фильма показывать, какой трек играет прямо сейчас. Выглядит это вот так.

Зачем вообще это было нужно? Многие наши пользователи регулярно используют сразу несколько наших сервисов, например, и Музыку, и Кинопоиск. Поэтому идея провязать оба сервиса показалась нам логичной.
Меня зовут Алексей Царёв, я занимаюсь развитием технологий в развлекательных сервисах Яндекса. И моя задача в том, чтобы из какой-то отдельно взятой технологии создавать рабочие продукты для конечного пользователя. Именно об этом, на примере распознавания музыки в фильмах, и будет этот пост.
Постановка задачи
Итак, у нас есть аудиодорожка из какого-то фильма на Кинопоиске, а ещё есть Яндекс Музыка с её коллекцией треков. Нужно найти, какие из них звучат в аудиодорожке фильма. Причём ещё и в конкретных интервалах — найти не только «Что звучит», но и «Когда звучит». Если совсем упрощать, то надо было по условному ID фильма на Кинопоиске сопоставить набор ID-шников из Музыки с указанием временных меток, что и когда звучит.
У нас уже есть ML-алгоритм распознавания треков, который и зашит в приложении Яндекс Музыки: когда вы кликаете на лупу и попадёте в поиск, вам предложат распознать звучащую сейчас рядом с вами музыку. Он учитывает различные особенности распознавания — на ходу, в транспорте, в кафе, с фоновыми шумами и прочее. У киношной акустики есть свои особенности — специфические звуки с явным войсовером (громким голосом поверх чисто звучащей музыки), так что для неё используется ещё и второй алгоритм, учитывающий именно эту акустику. После чего результаты работы двух алгоритмов объединяются. Если алгоритмы дают один и тот же прогноз, мы берём их объединение, если разный — отдаём предпочтение работе второго алгоритма, заточенного под киношную акустику.
Как устроен процесс разметки
Во-первых, мы собираем всю информацию, какую знаем о фильме — аудиодорожку, список саундтреков, различные метаданные и прочее. Аудиодорожки нам присылают правообладатели, на сайте Кинопоиска есть информация о саундтреках к фильму. Это всё в целом хорошо, но эта информация есть не обо всех саундтреках и не для всех фильмов, доступных на Кинопоиске, поэтому мы идём к Яндекс Музыке и просматриваем, какие из саундтреков ещё есть к этому фильму. А ещё мы забираем топ популярных треков, потому что какие-то из них могут звучать в нескольких фильмах сразу.
Затем мы детектируем в аудиодорожке фильма фрагменты, где просто звучит какая-то музыка (пока просто в формате «Да — Нет», «Звучит — Не звучит»). И уже после этого с помощью алгоритмов распознаём, что звучит, и сравниваем результаты между собой. Кроме этого, для самых сложных случаев у Кинопоиска есть специальные редакторы, которые могут проверить, что всё прошло без сбоев, на любом этапе разметки.
Поиск музыкальных фрагментов
Сразу отмечу, что алгоритм по распознаванию музыки — штука довольно тяжёлая в смысле вычислительных ресурсов, и если распознавать всю аудиодорожку целиком, мы потратим сильно больше времени, чем хочется. Так что мы решили пойти немного другим путём.
Мы экономим очень много времени и вычислительных ресурсов.
Такой подход помогает нам в аналитике. Например, мы можем измерить, какую долю музыки в фильме или сериалах мы распознаём, и отслеживать рост качества.
Это помогает идентифицировать разного рода проблемы и решать их. Например, ситуации, когда музыка на самом деле звучала, но мы её по каким-то причинам не распознали.
Давайте на конкретном примере. Допустим, у нас с вами есть какой-то фрагмент музыки с 0 по 20 секунду. Мы нарезаем его на отрезки по 5 секунд каждый с шагом в 1 секунду, то есть получаются вот такие промежутки:
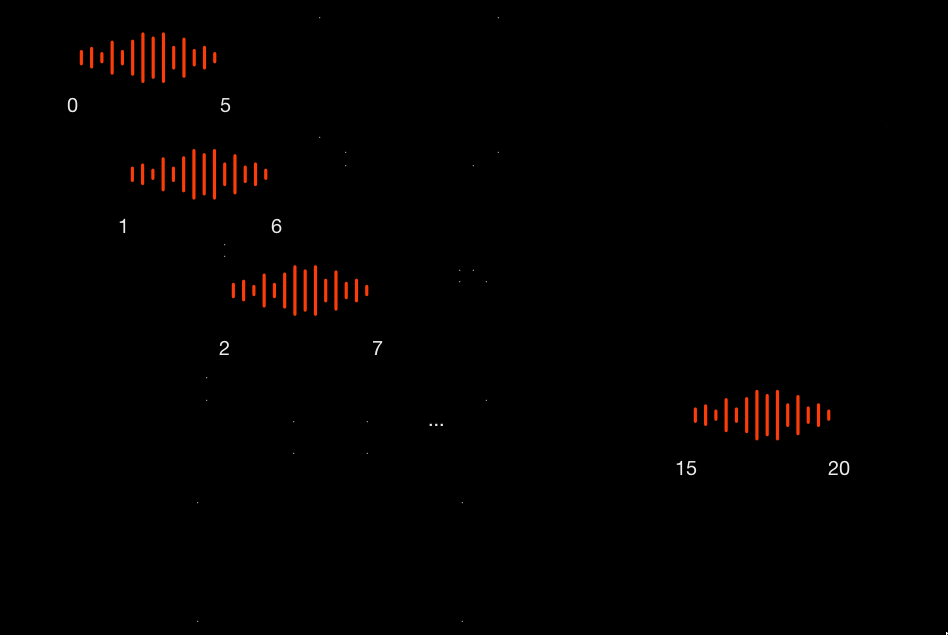
Затем эти кусочки мы подаём на вход нейросетевому классификатору.

Классификатор возвращает нам только те фрагменты, в которых звучит музыка. Скажем, он вернёт нам промежутки «1-6», «2-7», «10-15», …, «14-19». Значит, в остальных промежутках музыки не было. Затем мы агрегируем эти промежутки, а если у них есть пересечения, как на моём примере, тогда мы их склеиваем — с 1 по 7 и с 10 до 19.
Сейчас наш классификатор находит музыку довольно хорошо, но время от времени всё же что-то пропускает: его полнота 98%, а точность — 86%.
По итогу, если музыка звучит в фильме, то мы почти наверняка найдём её (полнота 98%). Но иногда то, что мы находим, не является музыкой в полном смысле этого слова (точность 86%). Например, очень часто как музыка идентифицируется пение птиц, а также звуки, которые издаёт поднимающееся из колодца ведро на вороте. Подобные случаи необходимо тщательно валидировать, чтобы уменьшать объёмы фрагментов, которые мы подаём на вход алгоритмам распознавания, а также для оценки качества работы самого классификатора и более корректной оценки качества работы всего процесса разметки.
Проверка результата
На этом этапе опознано лишь наличие музыки в принципе, но не сама музыка. После работы классификатора у нас на руках есть длинные и уверенные фрагменты детектированной музыки, а также короткие и неуверенные. И эти короткие кусочки мы отдаём на проверку асессорам.

Итак, музыка найдена, теперь нужно её распознавать.
Распознавание музыки
После работы классификатора и проверки со стороны асессоров мы с уверенностью можем утверждать, что на конкретных фрагментах аудиодорожек звучит какая-то музыка. Я не случайно пишу «хоть какая-то», потому что мы успешно распознаём звук как музыку, включая рингтоны мобильников в фильмах, задушевное (или не очень) пение главного героя в душевой кабине, мелодии на вокзалах, музыкальное радио в такси, в котором герой фильма куда-то едет, и подобные штуки.
Механизм распознавания музыки, то есть её соотношения с каким-то реально существующим треком из каталога Яндекс Музыки, примерно похож на механизм нахождения музыки, описанный в предыдущих частях. Мы берём аудио, и точно так же, по кусочкам фиксированной длины и с фиксированным шагом, подаём его на вход уже другому чёрному ящику. Отличие только в том, что в этом процессе появляется новое действующее лицо под названием «индекс» — база треков, среди которых мы и пытаемся найти тот самый заветный трек, звучащий в фильме.
Конечно же, у каждого такого трека есть собственный размер в байтах, и мы используем компактное представление (так называемые фингерпринты или отпечатки), из которых затем строится индекс для быстрого поиска по ним. При этом мы не можем просто засунуть вообще все треки Яндекс Музыки в этот индекс, потому что тогда он станет весить сильно больше, чем стоило бы. Да и поиск по нему будет осуществляться долго. Очень долго. А нам хотелось делать всё более или менее оперативно. Поэтому мы собирали индекс вот так:
Сначала берём все треки, про которые мы на базе хотя бы одного источника (Кинопоиска, Яндекс Музыки, редакторской разметки и прочего) можем сказать — да, они могут звучать в хотя бы одном фильме на Кинопоиске.
Затем берём из Яндекс Музыки топ саундтреков, на случай, если у нас всё-таки не оказалось информации о связи фильма и трека.
А также берём просто топ треков из Яндекс Музыки, потому что популярные композиции могут в том или ином виде звучать во множестве фильмов сразу.
Так что наш чёрный ящик получает на вход пятисекундный аудиофайл, с помощью которого пытается найти среди имеющегося списка нужный нам трек. Результаты агрегируются аналогично, как и в случае работы музыкального классификатора. Только в отличие от классификатора, мы агрегируем результаты по наиболее вероятному trackId.

Проверка результатов распознавания
После распознавания мы отдаём на валидацию лишь часть результатов. Например, если мы распознали трек, который входит в полученный от правообладателя список саундтреков фильма, то мы доверяем алгоритму. Или если мы уверенно и на протяжении долгого времени распознаём один и тот же трек.
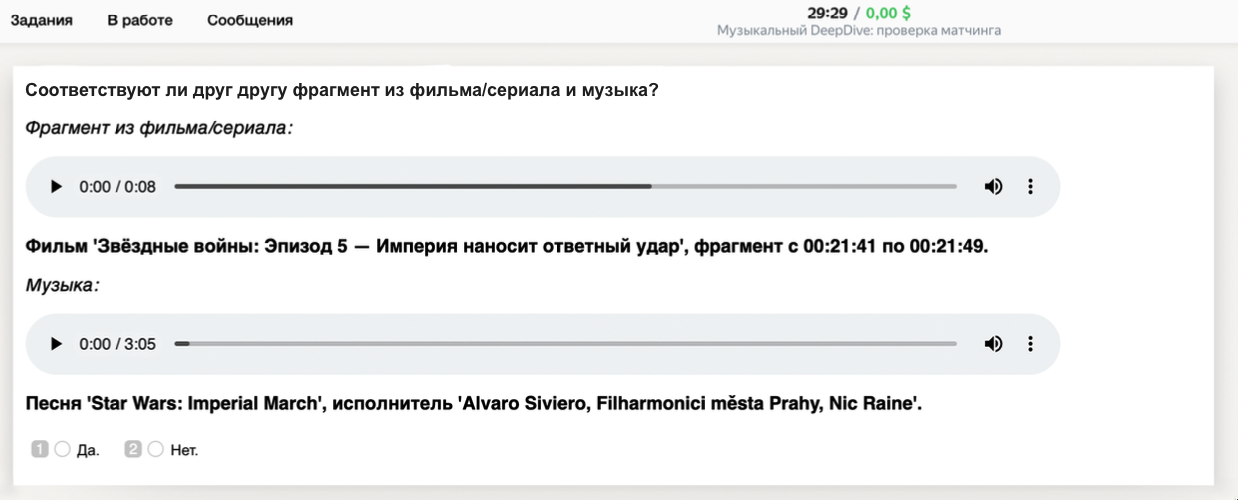
Но какие-то спорные вещи мы снова отправляем асессорам. Просто ставим им задачу вида «Послушайте аудиофрагмент из фильма и трек, проверьте, звучит ли конкретно этот трек на выбранном отрезке фильма». Мы даём им сам трек, который распознал алгоритм, и снабжаем их всей необходимой мета-информацией о том, что это за фильм, с какой по какую секунду звучит аудиофрагмент, что это за трек и кто его исполняет.
Знания о том, в каких фильмах какая музыка звучит, мы постоянно накапливаем.
Это полезно, потому что время от времени случается, что у какого-то фильма могут немного поменять аудиодорожку. Причём изменения могут быть незначительными, например, добавят 5 секунд тишины в самом начале, или немного урежут титры. В общем, какие-то чисто технические изменения, которые сбивают тайминг. Благодаря тому, что мы накапливаем эти знания, при повторном распознавании трека в фильме с другими таймингами мы сразу автоматически валидируем предыдущий результат.
Проблемы
Проект с понятной и простой схемой разметки получился довольно масштабным, и без проблем не обошлось.
Во-первых, у нас было недостаточно информации о треках в фильмах. С музыкой в кино ведь как — есть официальные саундтреки, OST, которые пишут специально для конкретного фильма. А ещё есть просто какая-то популярная музыка, которая может звучать в фильме, но не быть для него написана. И вот она уже зачастую проскакивает мимо внесения в списки OST, её проще найти на каких-то фанатских сайтах, посвящённых конкретному сериалу или фильму. Интернет огромный, таких сайтов множество, и с их кропотливым изучением нам помогает команда редакторов.
Во-вторых, есть так называемая проблема 24 VS 25 FPS. В чём суть: в киноиндустрии есть разные стандарты по количеству кадров в секунду. Ряд правообладателей присылают нам контент в чистом «24 кадра в секунду». Другие могут прислать подобные же видео, но отметить их как снятые в «25 кадров в секунду». Для пользователя, который будет смотреть кино, разницы в целом вообще никакой. А для механики распознавания — существенная. Получается, что аудио в таких роликах немного ускоренное. Такие фильмы мы начали искусственно замедлять и потом оценивать, насколько хорошо сработало распознавание. Если распознавание сработало лучше, чем в случае без замедления, значит, мы справились с задачей.
В-третьих, некоторые треки содержат в себе определённые куски различных известных фильмов или других треков. Таким часто грешат рэперы и панки. Например, композиция одного исполнителя начинается с узнаваемой звуковой заставки студии 20th Century Studios.
В таких случаях мы переходим к ручному вмешательству в процесс разметки. Например, конкретный трек мы можем взять и выкинуть вообще из индекса, чтобы не портил нам результаты распознавания. Можем забанить именно этот трек в определённом месте фильма. А можем просто забанить все распознавания для всего фильма целиком. Чаще всего на подобное нас вынуждают именно музыканты, но в их случаях можно использовать эвристику. Например, сравнить, что сам трек от исполнителя достаточно свежий, скажем, года от 2017, а фильм старый, но что-то там всё же распознаётся. И если в этом случае стоит жанр «Панк» или «Рэп», то мы уже идём смотреть лично, руками асессоров.
Похожая проблема — explicit-треки в заведомо детском контенте. Иногда в детских сериалах используют фрагменты минусовок разных треков, у которых в оригинале есть обсценная лексика. А ещё бывает, когда в какой-то трек вставляют кусок из Смешариков. И снова ситуация, когда распознавание работает отменно. Причём что со стороны алгоритмов, что со стороны асессоров. Но показывать такое нельзя. Так что мы на всякий случай на всём детском контенте (до 12 лет) кодом перебанили все explicit-треки.
Автоматизация процесса
Мы постарались сделать весь процесс распознавания музыки максимально автоматизированным. Вот что делает код:
собирает и обрабатывает информацию о фильмах, треках и сериалах — забирает аудиодорожки, конвертирует их при необходимости;
находит в дорожках музыкальные аудиофрагменты;
подготавливает эти дорожки, мета-информацию и загружает их как задания асессорам;
получает от асессоров размеченные музыкальные фрагменты;
агрегирует эту информацию;
подготавливает данные для распознавания и распознаёт музыку;
забирает данные о валидации и учится их агрегировать;
мёрджит их между собой.
Получается набор автоматических и самостоятельных процессов, ручной труд тут задействован только на этапе асессорской разметки.
Результаты
К моменту нашего первого запуска нам удалось обработать больше половины каталога Кинопоиска. Примерно в половине мы успешно распознали музыку.

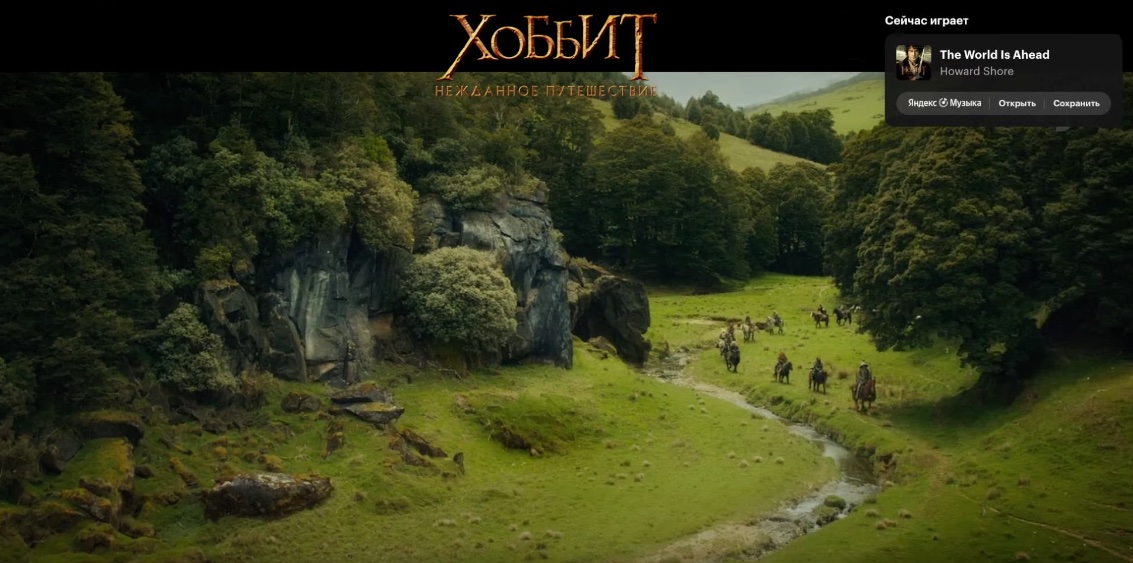
Кстати, мои коллеги посчитали, какие треки из фильмов сохраняли чаще всего. За всё время зрители Кинопоиска воспользовались этой функцией более 10 миллионов раз и распознали около 150 тысяч разных треков.
Но здесь надо учитывать ряд факторов. Например, существуют видео, в которых как таковой музыки нет вообще, скажем, некоторые выпуски National Geographic. Или видео, в которых есть музыка, существующая исключительно внутри самих этих видео — такое часто бывает со старыми фильмами. А ещё такое бывает с оригинальным контентом под конкретный стриминговый сервис — часто используют оригинальные треки и ремиксы, которые обычно не выгружают на музыкальные сервисы.
К тому же, не на все саундтреки к каким-то фильмам в данный момент могут быть авторские права.
И о цифрах. Сейчас около 95% пользователей замечают распознанную музыку при просмотре кино в 80% случаев. Полнота распознавания зависит от самих музыкальных фрагментов. Например, если мы берём фильм, про который точно знаем хотя бы один саундтрек из базы, и берём из него рандомный музыкальный фрагмент, на котором музыка звучит довольно явно, а количество посторонних шумов минимально, то мы в этом фрагменте распознаём нужный трек с вероятностью 84%.
Если фрагмент зашумлен, например, главные герои что-то громко обсуждают, или это музыка в кафе, или музыкальный трек звучит на фоне драки в кадре, то тут мы распознаём нужный трек с вероятностью 46%.
А вот различные мелодии в стиле ambient и подобные однотонные композиции распознавать сложнее всего — пока осиливаем только с вероятностью в 17%.
Сейчас мы активно занимаемся улучшением качества распознавания, стараемся распознавать музыку внутри ещё большего количества фильмов и находить больше треков в них.
Комментарии (4)

Dolios
15.08.2023 20:20+7Способов сделать это было несколько. Можно было пойти и поискать или сам OST к фильму, или неофициальные саундтреки к нему. Можно было посмотреть, что по названию фильма выдаётся в поиске через музыкальные стриминговые сервисы...
В титрах посмотрите следующий раз..

Sergei_Erjemin
15.08.2023 20:20+1Спасибо за статью.
Самый надежный способ узнать кто и что исполняет в фильме -- прочитать в титрах фильма. Зачастую, что исполнитель совсем не тот, что ожидается. Например в доцифровую эру: знаменитый Bullwinkle Part II в "Криминальном Чтиве" кто только не играл. И the Ventures -- наиболее вероятный кандидат в саундтрек, т.к. на их альбомах эта композиция мелькает часто, но версия у Тарантино от the Centurians (малоизвестная группа из 50х, и единственной пластинкой изданной на излете 15-летней творческой карьеры... интерес к творчеству группы как раз после выхода фильма).

evilaks
15.08.2023 20:20+1Интересно было бы посмотреть экономику фичи: что стало лучше после внедрения/должно было стать и как это соотносится с затратами? По идее привлечение пользователей из Кинопоиска в Я.Музыку.
All999
Сделайте видеошазам, чтобы по надёрганному видеошопером-ютубером из каких-то фильмов кусочкам находило фильм или видео, откуда был взят этот кусок.