Команды MLOps вынуждены развивать свои возможности по масштабированию ИИ. В 2022 году мы столкнулись со взрывом популярности ИИ и MLOps в бизнесе и обществе. В 2023 год ажиотаж, учитывая успех ChatGPT и развитие корпоративных моделей, будет только расти.
Столкнувшись с потребностями бизнеса, команды MLOps стремятся расширять свои мощности. Эти команды начинают 2023 год с длинного списка возможностей постановки ИИ на поток. Как мы будем масштабировать компоненты MLOps (развёртывание, мониторинг и governance)? Каковы основные приоритеты нашей команды?
AlignAI совместно с Ford Motors написали это руководство, чтобы поделиться с командами MLOps своим успешным опытом масштабирования.
Что значит MLOps?
Для начала нам нужно правильное определение MLOps. MLOps — это переход организации от создания разнородных моделей ИИ к надёжному созданию алгоритмов в больших масштабах. Для такого перехода требуется повторяемый и предсказуемый процесс. MLOps ведёт к увеличению объёмов ИИ и росту доходности по инвестициям. Команды получают выгоду от MLOps, если делают упор на организацию процесса, команды и инструментов.
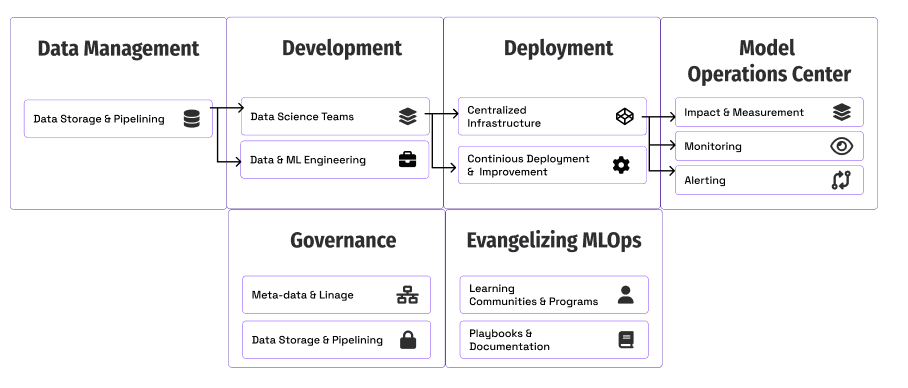
Фундаментальные компоненты MLOps для масштабирования
Давайте рассмотрим каждую область с примерами из опыта Ford Motors и идеи, которые помогут вам взяться за этот процесс.
- Измерения и оценка влияния: способ отслеживания и измерения прогресса.
- Развёртывание и инфраструктура: способы масштабирования работающих моделей.
- Мониторинг: обеспечение качества и точности моделей в продакшене.
- Governance: создание элементов управления и наблюдаемости моделей.
- Евангелизм MLOps: обучение бизнеса и других технических команд тому, зачем и как использовать методики MLOps.
Измерения и оценка влияния
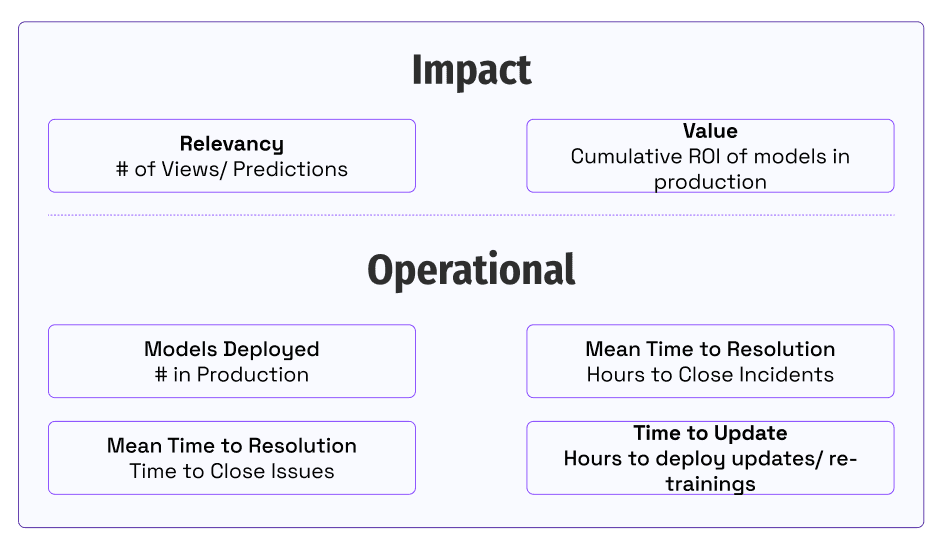
Однажды в командный центр MLOps компании Ford пришёл коммерческий руководитель. Мы оценили метрики использования модели и продуктивно обсудили причины снижения её использования. Такая наблюдаемость влияния и применения моделей критически важна для обеспечения доверия и реагирования на потребности бизнеса.
Фундаментальный вопрос для команд, использующих ИИ и вкладывающихся в мощности MLOps, заключается в следующем: как мы поймём, есть ли у нас прогресс?
Самое важное здесь — всей командой сосредоточиться на том, как мы обеспечиваем выгоду для наших клиентов и владельцев бизнеса. Команды делают упор на численную оценку своей производительности с точки зрения влияния на бизнес и на операционные метрики. Измерение влияния позволяет составить общую картину развития.
Вопросы, с которых стоит начать:
- Как вы сегодня измеряете ценность моделей в разработке и продакшене? Как отслеживаете использование и вовлечённость владельцев бизнеса?
- Каковы сегодня эксплуатационные или проектные метрики моделей в продакшене? Кто отвечает за улучшение этих метрик? Как вы представляете пользователям доступ для просмотра этих метрик?
- Как люди узнают об изменениях в пользовательском поведении или в использовании решения? Кто реагирует на такие проблемы?
Развёртывание и инфраструктура
Первая проблема, с которой сталкивается команда в MLOps — это развёртывание моделей в продакшен. С ростом количества моделей команды должны создать стандартизованный процесс и общую платформу для того, чтобы справляться с возросшими объёмами. Управление двадцатью моделями, развёрнутыми с помощью двадцати разных паттернов, может сильно замедлить процесс. Корпоративные команды обычно создают централизованные инфраструктурные ресурсы, связанные с X моделями. Выбор подходящей архитектуры и инфраструктуры для разных моделей и команд может быть сложной задачей. Однако после создания системы она становится мощным фундаментом для развития возможностей мониторинга и governance.
Мы в компании Ford создали стандартную функцию развёртывания при помощи Kubernetes, Google Cloud Platform и поддерживающей их команды.
Вопросы для нашей команды:
- Как мы централизуем развёртывание моделей? Можно ли создать или выделить централизованную команду и ресурсы для управления развёртываниями?
- Какие паттерны развёртывания использовать (REST, пакетный, потоковый и так далее)?
- Как сделать их доступными другим командам?
- Какие самые длительные или сложные аспекты, с которыми нужно справляться командам разработчиков моделей, чтобы вывести модель в продакшен? Как спроектировать централизованную систему развёртывания, чтобы решать эти проблемы?
Мониторинг
Уникальный и сложный аспект машинного обучения заключается в возможности дрейфа и изменения моделей в продакшене. Для того, чтобы владельцы бизнеса доверяли применению моделей, критически важно создать систему мониторинга. В правилах машинного обучения Google рекомендуется «практиковать хорошую гигиену алертов, например, делать так, чтобы на алерты можно было реагировать сразу». Для этого команды должны определить области мониторинга и способы генерации таких алертов. Проблемой становится возможность мгновенного реагирования на такие алерты. Необходимо наладить процесс исследования и устранения проблем в продакшене.

У компании Ford есть Model Operations Center — централизованное пространство с информацией и данными для того, чтобы почти в реальном времени отслеживать то, дают ли модели нужные нам результаты.
Выше показан упрощённый пример дэшборда, исследующего падение количества обращений или записей ниже заданного значения.
Метрики мониторинга
Вот метрики мониторинга, которые следует учитывать в своих проектах:
- Задержка: время, необходимое для возврата прогноза (например, суммарное время обработки 100 записей).
- Статистическая точность: способность модели делать точные или близкие прогнозы на тестовом датасете (например, Mean Squared Error, F2 и так далее).
- Качество данных: количественная величина полноты, точности, валидности и актуальности прогнозов или обучающих данных (например, процент записей прогнозов с отсутствующим признаком).
- Дрейф данных: изменения в распределении данных по времени (например, изменения в освещении для модели компьютерного зрения).
- Обращения к модели: частота использования прогнозов модели для решения задач бизнеса или пользователей (например, количество прогнозов модели, развёрнутой как конечная точка REST).
Вопросы для команды:
- Как нужно мониторить все модели?
- Какие метрики нужно отслеживать для каждой модели?
- Существует ли стандартный инструмент или фреймворк для генерации метрик?
- Как управлять алертами и проблемами мониторинга?
Governance
Инновации неизбежно создают риски, особенно в среде бизнеса. Поэтому для успешного внедрения инноваций необходимо встраивать в системы элементы управления для снижения риска. Проактивность позволяет избавиться от проблем и сэкономить время. Команды MLOps должны проактивно предвидеть риски, рассказывать о них и способах их устранения владельцам бизнеса.
Разработка проактивного подхода к governance помогает избежать реактивной работы с потребностями бизнеса. Два основных элемента стратегии: управление доступом к уязвимым данным и фиксация исторических данных и метаданных для наблюдаемости и аудита.
С увеличением масштабов команд governance обеспечивает великолепные возможности автоматизации. Ожидание данных замедляет работу проектов data science. В компании Ford модель с точностью 97% автоматически определяет, есть ли в данных позволяющая установить личность информация. Модели машинного обучения также помогают с запросами доступа и в 90% случаев позволяют снизить время обработки с недель до минут.
Второй элемент — это отслеживание метаданных на протяжении жизненного цикла модели. Для масштабирования машинного обучения необходимо масштабировать уровень доверия к самим моделям. Масштабные MLOps требуют встроенного контроля качества, безопасности и управления, чтобы избегать проблем и перекосов в продакшене.
С governance связано множество теорий и мнений, в которых можно запутаться. Лучше всего начинать с обеспечения чёткого контроля пользовательского доступа.
Дальше важнее всего становятся фиксация метаданных и автоматизация. В таблице ниже перечислены сферы сбора метаданных. По возможности используйте конвейеры и другие системы автоматизации для автоматической фиксации этой информации, чтобы избежать ручной обработки и рассогласованности.
Собираемые метаданные
Вот элементы, собираемые для каждой модели:
- Версия/обученная модель: уникальный идентификатор обученной модели.
- Обучающие данные: данные, использованные для создания обученной модели
- Код обучения: Git hash или ссылка на исходный код.
- Зависимости: библиотеки, использованные при обучении.
- Код прогнозирования: Git hash или ссылка на исходный код.
- Исторические прогнозы: хранение выводов с целью аудита.
Вопросы для команды:
- С какими проблемами мы сталкивались в проектах?
- С какими проблемами сталкиваются владельцы бизнеса или что их беспокоит?
- Как нам управлять запросами доступа к данным?
- Кто их утверждает?
- Есть ли возможности для автоматизации?
- Какие уязвимости создают наши конвейеры или развёртывания моделей?
- Какие элементы метаданных мы должны сохранять?
- Как они хранятся и как к ним выполняется доступ?
Евангелизм MLOps
Многие технические команды ошибочно считают, что после создания системы всё остальное приложится само. Однако для решения задачи нужно нечто большее. Для этого также нужно рассказывать о решении и продвигать его, чтобы оно оказало влияние на всю организацию. Командам MLOps необходимо делиться успешным опытом, рассказывать о решении уникальных проблем инструментов, данных, моделей и руководителей организации.
Любой участник команды MLOps может стать евангелистом, объединив свои усилия с владельцами бизнеса для демонстрации их историй успеха. Демонстрация примеров из вашей организации помогает чётко иллюстрировать преимущества и возможности.
Сотрудники организации, желающие поставить ИИ на поток, требуют обучения, документации и поддержки. Можно начать с программ Lunch and Learn, онбординга и менторства. При увеличении масштаба организации более формализованные программы обучения и онбординга со справочной документацией могут ускорить преобразование организации.
Вопросы для команды:
- Как можно создать сообщество или систему обучения для MLOps?
- Какие новые должности и характеристики мы должны создать?
- О каких решённых нами задачах можно рассказать?
- Как вы обеспечиваете обучение или документацию, чтобы рассказывать о своём опыте и историях успеха с другими командами?
- Как можно создать обучающие программы или чеклисты для дата-саентистов, дата-инженеров и владельцев бизнеса с целью обучения работе с ИИ-моделями моделями?
С чего начать
Команды и руководители MLOps в процессе балансирования постановки на поток моделей сталкиваются с огромным количеством возможностей. У каждой организации возникают собственные сложности, зависящие от её данных, моделей и технологий.
Сложность всегда заключается в расстановке приоритетов.
Надеемся, это руководство поможет вам генерировать новые идеи и искать новые области для исследования. Первый шаг заключается в создании большого списка возможностей для вашей команды в 2023 году. Затем нужно безжалостно расставлять приоритеты в зависимости от того, что окажет наибольшее влияние на клиентов. Команды также могут определять и замерять свой прогресс при помощи создаваемых в процессе бенчмарков. В этом руководстве Google можно найти структуру и этапы развития для своей команды.
Вопросы для команды:
- Как лучше всего развивать и усложнять систему при помощи MLOps?
- Как замерять и отслеживать прогресс в развивающихся проектах?
- Сгенерировать список задач для этого руководства и команды. Расставить приоритеты в зависимости от времени реализации и ожидаемой выгоды. Создать стратегический план.
Ссылки
- https://www2.deloitte.com/content/dam/insights/articles/7022_TT-MLOps-industrialized-AI/DI_2021-TT-MLOps-industrialized-AI.pdf
- https://proceedings.neurips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
- https://developers.google.com/machine-learning/guides/rules-of-ml
- https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning