Автор оригинала, Кейси Муратори, как он и описал себя на своем сайте — программист, специализирующийся на исследовании и разработке игровых движков. Меня очень впечатлили его рассуждения, изложенные в видео ниже. Могу нахваливать сколь угодно, но зачем, когда вы можете ознакомиться с материалом сами. Благо, у него еще и оказалась статья с транскриптом к своему видео, которую я постарался перевести. Приятного чтения!
Многие «лучшие практики» программирования, которым сегодня обучают — потенциальные катастрофы для производительности.
Это бесплатное бонусное видео из серии «Программирование с учетом производительности». Оно показывает настоящую цену следования принципам «чистого кода». Для более подробной информации о курсе можете заглянуть на страницы О нас или Оглавление.
Ниже представлен слегка отредактированный транскрипт видео.
Один из самых частых советов программистам, особенно начинающим, гласит, что они должны писать «чистый» код. Это понятие сопровождается длинным списком правил, которые указывают, что вы должны делать, чтобы ваш код был «чистым».
Большая часть этих правил фактически не влияют на скорость выполнения вашего кода. Правила такого рода не могут быть объективно оценены, и в этом даже нет нужды, потому что в этом контексте они довольно произвольны. Но в то же время, несколько правил написания «чистого» кода, некоторые из которых сильно подчеркнуты, мы вполне можем объективно оценить, потому что они налагают свое влияние на поведение кода в ходе его его выполнения.
Если мы посмотрим на сводку «чистого» кода и выделим правила, поистине влияющие на структуру кода, мы получим следующее:
Используйте полиморфизм вместо «if/else» и «switch»;
Код не должен знать о внутренностях объекта, с которыми он работает;
Функции должны быть короткими;
Функции должны выполнять одну задачу;
«DRY» — Don't Repeat Yourself (не повторяйся)
Эти правила больше касаются того, как отдельные куски кода должны быть созданы, чтобы быть «чистыми». Вопрос, который я хотел бы задать — если мы напишем код, следуя этим правилам, какова будет его производительность?
Чтобы соорудить что‑то, что я смогу назвать максимально подходящим под описание реализации чего‑либо «чистым» кодом, я использовал существующие примеры кода, содержащиеся в литературе по «чистому» коду. Таким образом, я ничего не придумываю сам, я просто оцениваю правила защитников «чистого» кода, используя примеры, которые они дают для иллюстрации этих самых правил.
Среди примеров «чистого» кода часто встречается что‑то подобное:
/* ========================================================================
LISTING 22
======================================================================== */
class shape_base
{
public:
shape_base() {}
virtual f32 Area() = 0;
};
class square : public shape_base
{
public:
square(f32 SideInit) : Side(SideInit) {}
virtual f32 Area() {return Side*Side;}
private:
f32 Side;
};
class rectangle : public shape_base
{
public:
rectangle(f32 WidthInit, f32 HeightInit) : Width(WidthInit), Height(HeightInit) {}
virtual f32 Area() {return Width*Height;}
private:
f32 Width, Height;
};
class triangle : public shape_base
{
public:
triangle(f32 BaseInit, f32 HeightInit) : Base(BaseInit), Height(HeightInit) {}
virtual f32 Area() {return 0.5f*Base*Height;}
private:
f32 Base, Height;
};
class circle : public shape_base
{
public:
circle(f32 RadiusInit) : Radius(RadiusInit) {}
virtual f32 Area() {return Pi32*Radius*Radius;}
private:
f32 Radius;
};Это базовый класс геометрической фигуры и несколько его наследников: круг, треугольник, прямоугольник и квадрат. Также у нас есть виртуальная функция, вычисляющая площадь.
Как и требовалось по правилам, мы используем полиморфизм. Наши функции выполняют только одну задачу. Они короткие. Все эти хорошие штуки. В итоге у нас получается «чистая» иерархия классов, где каждый дочерний класс знает, как вычислить свою площадь, и хранит данные, необходимые для вычисления площади.
Если представить использование этой иерархии для выполнения чего‑либо, например, для нахождения суммарной площади группы заданных фигур, скорее всего, мы увидим что‑нибудь в этом роде:
/* ========================================================================
LISTING 23
======================================================================== */
f32 TotalAreaVTBL(u32 ShapeCount, shape_base **Shapes)
{
f32 Accum = 0.0f;
for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex)
{
Accum += Shapes[ShapeIndex]->Area();
}
return Accum;
}Заметьте, что здесь я не использовал итератор, потому что в правилах нет ничего про то, что вы должны использовать именно итераторы. Поэтому, я решил дать «чистому» коду презумпцию невиновности и не добавлять никаких абстрактных итераторов, которые могли бы усложнить работу компилятора и стать причиной ухудшения производительности.
Также прошу заметить, что этот цикл проходится по массиву указателей. Это прямое последствие использования классовой иерархии: мы не знаем, насколько большой по памяти будет каждая фигура. Поэтому, если мы не собираемся добавить вызов еще одной виртуальной функции, которая бы возвращала объем данных каждой фигуры, и использовать какую‑нибудь процедуру пропуска данных для их перебора, нам будут нужны указатели, чтобы знать, где вообще начинается каждая фигура.
Так как мы имеем дело с аккумуляцией, у нас есть зависимость внутри цикла, которая может его замедлить. И раз аккумуляция может быть переупорядочена как угодно, я также просто для безопасности написал развернутую вручную версию:
/* ========================================================================
LISTING 24
======================================================================== */
f32 TotalAreaVTBL4(u32 ShapeCount, shape_base **Shapes)
{
f32 Accum0 = 0.0f;
f32 Accum1 = 0.0f;
f32 Accum2 = 0.0f;
f32 Accum3 = 0.0f;
u32 Count = ShapeCount/4;
while(Count--)
{
Accum0 += Shapes[0]->Area();
Accum1 += Shapes[1]->Area();
Accum2 += Shapes[2]->Area();
Accum3 += Shapes[3]->Area();
Shapes += 4;
}
f32 Result = (Accum0 + Accum1 + Accum2 + Accum3);
return Result;
}Запустив эти две функции с простой надстройкой для тестирования, я получаю грубую оценку количества циклов на фигуру, необходимых для выполнения данной операции:

Эта надстройка измеряет тайминг двух случаев. Первый — запуск кода единожды, при котором выясняется, что происходит в произвольном «холодном» состоянии, где данные должны хранится в L3, а L2 и L1 должны быть очищены, а предсказатель переходов не должен быть «попрактиковавшимся» на цикле.
И второй случай — многократный повторный запуск кода для выявления результатов, когда кэш и предсказатель перехода работают самым благоприятным для цикла способом. Отмечу, что никакое из наших измерений не является жестким, потому что, как вы увидите позже, разница будет настолько большой, что нам и не понадобится впихивать серьезные инструменты анализа.
По результатам видно, что между двумя функциями особой разницы нет. Получается около 35 циклов для вычисления площади одной фигуры «чистым» кодом. Иногда, если вам повезет, этот показатель может понизиться до 34.
Таким образом, мы можем ожидать от следования этим правилам 35 циклов. А что произойдет, если мы нарушим только первое правило? Что если вместо полиморфизма, мы возьмем просто switch? (Вообще, я не сказал бы, что switch по сути своей менее полиформичен нежели vtable. Это просто две разные реализации одной и той же вещи. Но правила «чистого» кода говорят использовать полиморфизм вместо конструкции switch, поэтому я просто использую их терминологию, согласно которой они, по всей видимости, не относят switch к полиморфизму)
Тут я написал точно такой же код, заменив только иерархию классов (и в рантайме, следовательно, vtable) на enum и тип фигуры, который сплющивает все в один struct:
/* ========================================================================
LISTING 25
======================================================================== */
enum shape_type : u32
{
Shape_Square,
Shape_Rectangle,
Shape_Triangle,
Shape_Circle,
Shape_Count,
};
struct shape_union
{
shape_type Type;
f32 Width;
f32 Height;
};
f32 GetAreaSwitch(shape_union Shape)
{
f32 Result = 0.0f;
switch(Shape.Type)
{
case Shape_Square: {Result = Shape.Width*Shape.Width;} break;
case Shape_Rectangle: {Result = Shape.Width*Shape.Height;} break;
case Shape_Triangle: {Result = 0.5f*Shape.Width*Shape.Height;} break;
case Shape_Circle: {Result = Pi32*Shape.Width*Shape.Width;} break;
case Shape_Count: {} break;
}
return Result;
}Это «олдскульный» способ, который бы мы использовали до «чистого» кода.
Заметьте, что теперь у нас нет отдельных типов для каждой фигуры, поэтому если у какой‑то из них нет одного из рассматриваемых значений («высоты», например), то она попросту не будет его использовать.
Теперь вместо получения площади вызовом виртуальной функции пользователь struct'а берет его из функции с switch, а это ровно то, что на лекции по «чистому» коду вам бы сказали никогда не делать. Но даже так за исключением уменьшения размеров, код остался тем же. Каждая ветка switch‑выражения представляет собой ровно тот же код, который содержится в соответствующей виртуальной функции в классовой иерархии.
Что касается циклов суммирования, вы можете увидеть, что они крайне идентичны «чистой» версии:
/* ========================================================================
LISTING 26
======================================================================== */
f32 TotalAreaSwitch(u32 ShapeCount, shape_union *Shapes)
{
f32 Accum = 0.0f;
for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex)
{
Accum += GetAreaSwitch(Shapes[ShapeIndex]);
}
return Accum;
}
f32 TotalAreaSwitch4(u32 ShapeCount, shape_union *Shapes)
{
f32 Accum0 = 0.0f;
f32 Accum1 = 0.0f;
f32 Accum2 = 0.0f;
f32 Accum3 = 0.0f;
ShapeCount /= 4;
while(ShapeCount--)
{
Accum0 += GetAreaSwitch(Shapes[0]);
Accum1 += GetAreaSwitch(Shapes[1]);
Accum2 += GetAreaSwitch(Shapes[2]);
Accum3 += GetAreaSwitch(Shapes[3]);
Shapes += 4;
}
f32 Result = (Accum0 + Accum1 + Accum2 + Accum3);
return Result;
}Единственная разница заключается в том, что вместо функции-метода для вычисления площади мы используем обычную функцию. И все.
Тем не менее, мы можем уже увидеть непосредственное преимущество использования плоской структуры по сравнению с классовой иерархией: фигуры могут быть просто в массиве, нет необходимости в указателях. Тут нет косвенности, потому что все наши фигуры имеют одинаковый размер.
Помимо этого мы получаем дополнительный плюс: компилятор теперь может видеть, что конкретно мы делаем внутри цикла, потому что он может просто заглянуть в функцию GetAreaSwitch и увидеть всю картину кода. Ему не приходится предполагать, что что-то может произойти в какой-то функции виртуализированной области, известной только во время выполнения.
Что же компилятор со всеми полученными преимуществами сможет для нас сделать? Вот результаты запуска всех четырех функций:
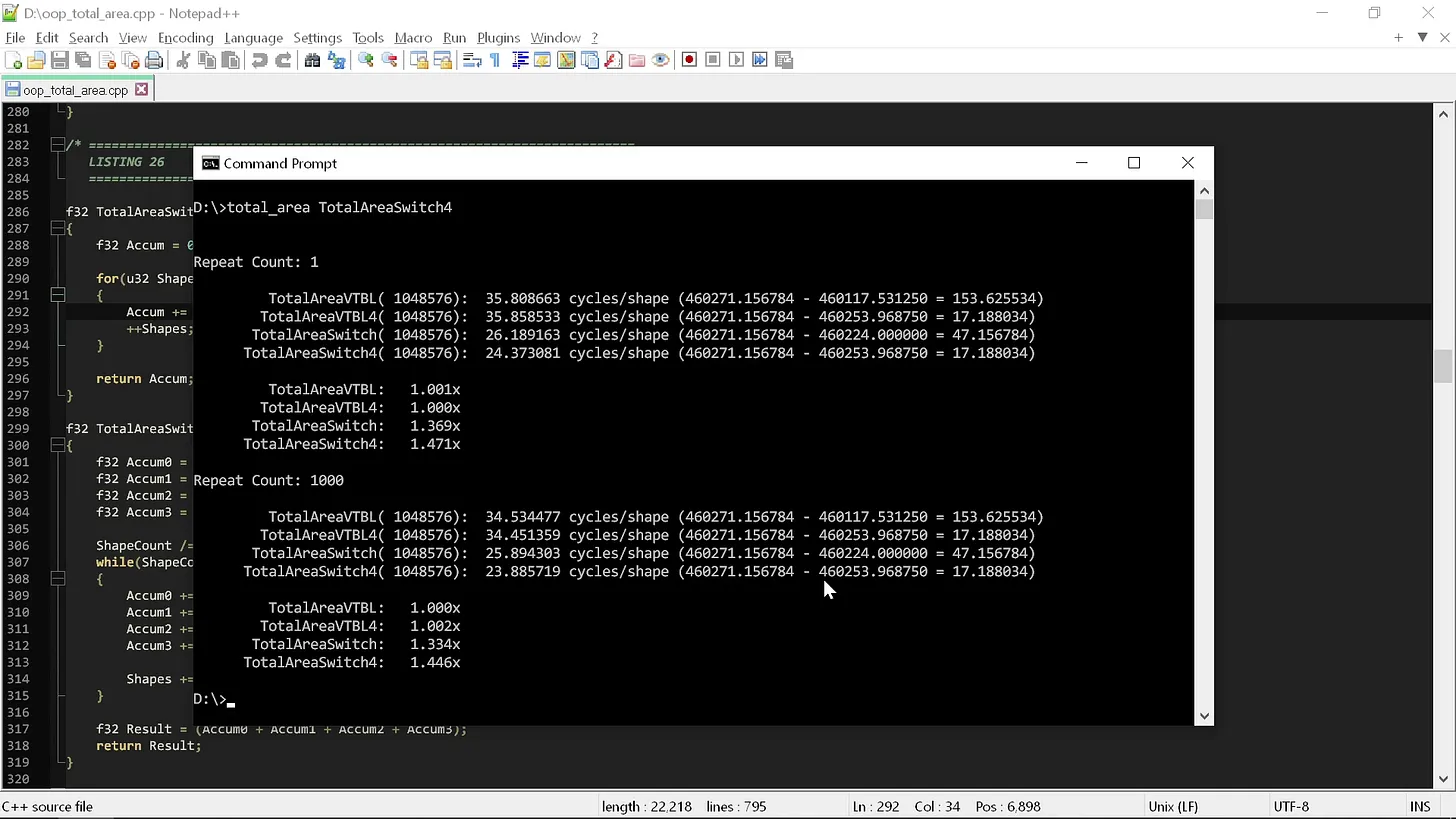
Глядя на результаты, мы видим нечто весьма примечательное: одно лишь изменение — написание кода старомодным путем нежели "чистым", — дало нам непосредственный прирост производительности в 1.5 раза. Прирост в 1.5 раза лишь из-за того, что мы удалили все посторонние вещи, необходимые для использования полиморфизма в C++.
Получается, что нарушением первого правила чистого кода, которое к тому же является одним из центральных, мы смогли добиться снижения количества циклов на фигуру с 35 до 24, выяснив, что код, следующий правилу номер один, в 1.5 раза медленнее кода, который этого не делает. Если проецировать это на аппаратное обеспечение, это как взять iPhone 14 Pro Max и понизить его до iPhone 11 Pro Max. Это вычеркивание трех или четырех лет эволюции аппаратного обеспечения просто потому что кто-то сказал использовать полиморфизм вместо switch.
Но мы только начинаем.
Что если мы нарушим больше правил? Что если мы также нарушим второе правило, "незнание внутренностей"? Что если наши функции смогли бы использовать знание о том, с чем они вообще работают, и стать более эффективными?
Если мы снова взглянем на конструкцию switch, в которой идет нахождение площади, мы увидим, что все вычисления схожи:
case Shape_Square: {Result = Shape.Width*Shape.Width;} break;
case Shape_Rectangle: {Result = Shape.Width*Shape.Height;} break;
case Shape_Triangle: {Result = 0.5f*Shape.Width*Shape.Height;} break;
case Shape_Circle: {Result = Pi32*Shape.Width*Shape.Width;} break;Они все делают что-то вроде умножения ширины на высоту, ширины на ширину, с опциональным коэффициентом. В случае с треугольником этот коэффициент равен 0.5, а с кругом — Пи. Как‑то так.
Это одна из причин, по которым я, в отличие от защитников «чистого» кода, считаю, что конструкция switch замечательна! Она делает подобные паттерны легко заметными. Когда ваш код организован по операциям, а не по типам, становится легко выявлять и выводить общие паттерны. Для сравнения, если мы снова посмотрим на версию с классами, возможно, вы никогда и не заметите подобных паттернов из‑за объема boilerplate‑кода, которым они покрыты. А сторонники «чистого» кода еще и рекомендуют класть каждый класс в отдельный файл, еще больше понижая вероятность замечания подобных вещей.
Поэтому в плане архитектуры я не одобряю иерархию классов в целом, но это уже немного не по теме. Единственное, что я сейчас пытаюсь сказать — мы можем заметно упростить switch, выявив паттерн.
И обратите внимание, это не пример, выбранный мной! Это пример, который сторонники чистого кода сами используют для иллюстрации своих целей. И я не выбирал специально такой пример, в котором мы можем выделить какой-то паттерн, напротив, очень высока вероятность, что вы сможете сделать это с большинством задач, потому что большинство вещей схожего типа имеют схожую алгоритмическую структуру, что, как ожидалось, происходит и в данном примере.
Чтобы этот паттерн эксплуатировать, мы можем добавить простую табличку, которая будет хранить коэффициент для каждого типа фигуры. Если мы еще и сделаем так, чтобы наши однопараметрические типы как круг и квадрат, продублировали свою ширину в высоту, мы можем очень резко сократить функцию площади:
/* ========================================================================
LISTING 27
======================================================================== */
f32 const CTable[Shape_Count] = {1.0f, 1.0f, 0.5f, Pi32};
f32 GetAreaUnion(shape_union Shape)
{
f32 Result = CTable[Shape.Type]*Shape.Width*Shape.Height;
return Result;
}И оба суммирующих цикла для этой версии точно такие же, в них нет необходимости менять что-то кроме замены вызова GetAreaSwitch на вызов GetAreaUnion.
Давайте посмотрим, что произойдет, если мы запустим новую версию:

Здесь вы можете видеть, что воспользовавшись тем, что мы знаем, какие типы у нас есть — эффективно переключившись с основанного на типах мышления на мышление, основанное на функциях, — мы получаем огромный прирост скорости. Мы перешли от оператора switch, который был всего в 1.5 раза быстрее, к версии с таблицей, которая справляется с ровно этой же задачей в 10 раз быстрее.
И чтобы этого добиться, мы всего лишь использовали один поиск по таблице и одну строчку кода! Получилось не просто намного быстрее, но и куда менее семантически комплексно. Меньше токенов, меньше операций, меньше строк кода.
Таким образом, объединяя нашу модель данных с желаемой операцией вместо изолирования внутренних данных от операции, мы спустились вплоть до 3.0-3.5 циклов на группу фигур. Это десятикратное повышение скорости по сравнению с версией с "чистым" кодом, следующим первым двум правилам.
10x — это настолько большой прирост производительности, что мы даже не сможем спроецировать его на iPhone, потому что тесты iPhone не уходят корнями в достаточно далекое прошлое. Если взять iPhone 6, самый старый телефон, показывающийся в современных тестах, то он медленнее iPhone 14 Pro Max всего примерно в три раза. Поэтому мы даже не сможем использовать телефоны для описания этой разницы.
Если взять однопоточный перформанс на ПК, 10-кратный прирост скорости будет аналогичен переходу с современного среднестатистического процессора на средний процессор из далекого 2010! Концепция первых двух правил «чистого кода» пожирает за раз 12 лет эволюции железа.
Как бы все это не шокировало, мы пока тестируем одну лишь простую операцию. Мы не особо трогаем правила «функции должны быть короткими» и «функции должны выполнять ровно одну задачу», потому что у нас и так одна простая задача. Что если мы добавим еще один пункт в задачу, чтобы напрямую воспользоваться этими правилами?
Тут я написал точно такую же иерархию, которая у нас была до этого, только добавив одну виртуальную функцию, которая должна возвращать количество углов каждой фигуры:
/* ========================================================================
LISTING 32
======================================================================== */
class shape_base
{
public:
shape_base() {}
virtual f32 Area() = 0;
virtual u32 CornerCount() = 0;
};
class square : public shape_base
{
public:
square(f32 SideInit) : Side(SideInit) {}
virtual f32 Area() {return Side*Side;}
virtual u32 CornerCount() {return 4;}
private:
f32 Side;
};
class rectangle : public shape_base
{
public:
rectangle(f32 WidthInit, f32 HeightInit) : Width(WidthInit), Height(HeightInit) {}
virtual f32 Area() {return Width*Height;}
virtual u32 CornerCount() {return 4;}
private:
f32 Width, Height;
};
class triangle : public shape_base
{
public:
triangle(f32 BaseInit, f32 HeightInit) : Base(BaseInit), Height(HeightInit) {}
virtual f32 Area() {return 0.5f*Base*Height;}
virtual u32 CornerCount() {return 3;}
private:
f32 Base, Height;
};
class circle : public shape_base
{
public:
circle(f32 RadiusInit) : Radius(RadiusInit) {}
virtual f32 Area() {return Pi32*Radius*Radius;}
virtual u32 CornerCount() {return 0;}
private:
f32 Radius;
};У прямоугольника четыре угла, у треугольника — три, у круга — ноль и так далее. Дальше я хочу изменить условие задачи, предложив вместо суммы площадей найти сумму взвешенных по углам площадей, которые я определю как единицу, деленную на единицу плюс количество углов.
Как и в случае с суммой площадей, здесь нет никакой причины такого выбора, я просто пытаюсь работать внутри того же примера. Я добавил простейшую вещь, которую только смог придумать, и проделал с ней некоторые крайне базовые математические вычисления.
Чтобы обновить «чистый» суммирующий цикл, добавим нужные расчеты и вызов дополнительной виртуальной функции:
f32 CornerAreaVTBL(u32 ShapeCount, shape_base **Shapes)
{
f32 Accum = 0.0f;
for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex)
{
Accum += (1.0f / (1.0f + (f32)Shapes[ShapeIndex]->CornerCount())) * Shapes[ShapeIndex]->Area();
}
return Accum;
}
f32 CornerAreaVTBL4(u32 ShapeCount, shape_base **Shapes)
{
f32 Accum0 = 0.0f;
f32 Accum1 = 0.0f;
f32 Accum2 = 0.0f;
f32 Accum3 = 0.0f;
u32 Count = ShapeCount/4;
while(Count--)
{
Accum0 += (1.0f / (1.0f + (f32)Shapes[0]->CornerCount())) * Shapes[0]->Area();
Accum1 += (1.0f / (1.0f + (f32)Shapes[1]->CornerCount())) * Shapes[1]->Area();
Accum2 += (1.0f / (1.0f + (f32)Shapes[2]->CornerCount())) * Shapes[2]->Area();
Accum3 += (1.0f / (1.0f + (f32)Shapes[3]->CornerCount())) * Shapes[3]->Area();
Shapes += 4;
}
f32 Result = (Accum0 + Accum1 + Accum2 + Accum3);
return Result;
}Я мог бы возразить, что, мол, должен перенести это в отдельную функцию, добавив еще один слой косвенности. Но, опять‑таки, я оставлю все в таком явном виде, чтобы дать «чистому» коду презумпцию невиновности.
Для обновления версии со switch, мы делаем, по сути, те же изменения. В первую очередь, добавляем еще один switch для количества углов с ветвлениями, отражающими версию с иерархией:
/* ========================================================================
LISTING 34
======================================================================== */
u32 GetCornerCountSwitch(shape_type Type)
{
u32 Result = 0;
switch(Type)
{
case Shape_Square: {Result = 4;} break;
case Shape_Rectangle: {Result = 4;} break;
case Shape_Triangle: {Result = 3;} break;
case Shape_Circle: {Result = 0;} break;
case Shape_Count: {} break;
}
return Result;
}Потом мы вычисляем то же самое, что и в иерархической версии:
/* ========================================================================
LISTING 35
======================================================================== */
f32 CornerAreaSwitch(u32 ShapeCount, shape_union *Shapes)
{
f32 Accum = 0.0f;
for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex)
{
Accum += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[ShapeIndex].Type))) * GetAreaSwitch(Shapes[ShapeIndex]);
}
return Accum;
}
f32 CornerAreaSwitch4(u32 ShapeCount, shape_union *Shapes)
{
f32 Accum0 = 0.0f;
f32 Accum1 = 0.0f;
f32 Accum2 = 0.0f;
f32 Accum3 = 0.0f;
ShapeCount /= 4;
while(ShapeCount--)
{
Accum0 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[0].Type))) * GetAreaSwitch(Shapes[0]);
Accum1 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[1].Type))) * GetAreaSwitch(Shapes[1]);
Accum2 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[2].Type))) * GetAreaSwitch(Shapes[2]);
Accum3 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[3].Type))) * GetAreaSwitch(Shapes[3]);
Shapes += 4;
}
f32 Result = (Accum0 + Accum1 + Accum2 + Accum3);
return Result;
}Точно так же, как в версии с суммой площадей, код выглядит почти одинаково между реализациями через классовую иерархию и через switch. Единственное отличие — расхождение в выборе между вызовом виртуальной функции и switch.
Перейдя к реализации через таблицу, мы видим, насколько на самом деле здорово объединять данные и операции! В отличие от остальных версий, в этой единственной вещью, подлежащей изменению, являются данные в нашей таблице!Нам не нужно получать второстепенную информацию о нашей фигуре — мы можем объединить и количество углов, и коэффициент площади прямо в таблице, а весь остальной код остается без изменений:
/* ========================================================================
LISTING 36
======================================================================== */
f32 const CTable[Shape_Count] = {1.0f / (1.0f + 4.0f), 1.0f / (1.0f + 4.0f), 0.5f / (1.0f + 3.0f), Pi32};
f32 GetCornerAreaUnion(shape_union Shape)
{
f32 Result = CTable[Shape.Type]*Shape.Width*Shape.Height;
return Result;
}Запустив эти функции "угловых площадей", мы можем наблюдать влияние добавления в фигуру нового свойства на производительность:
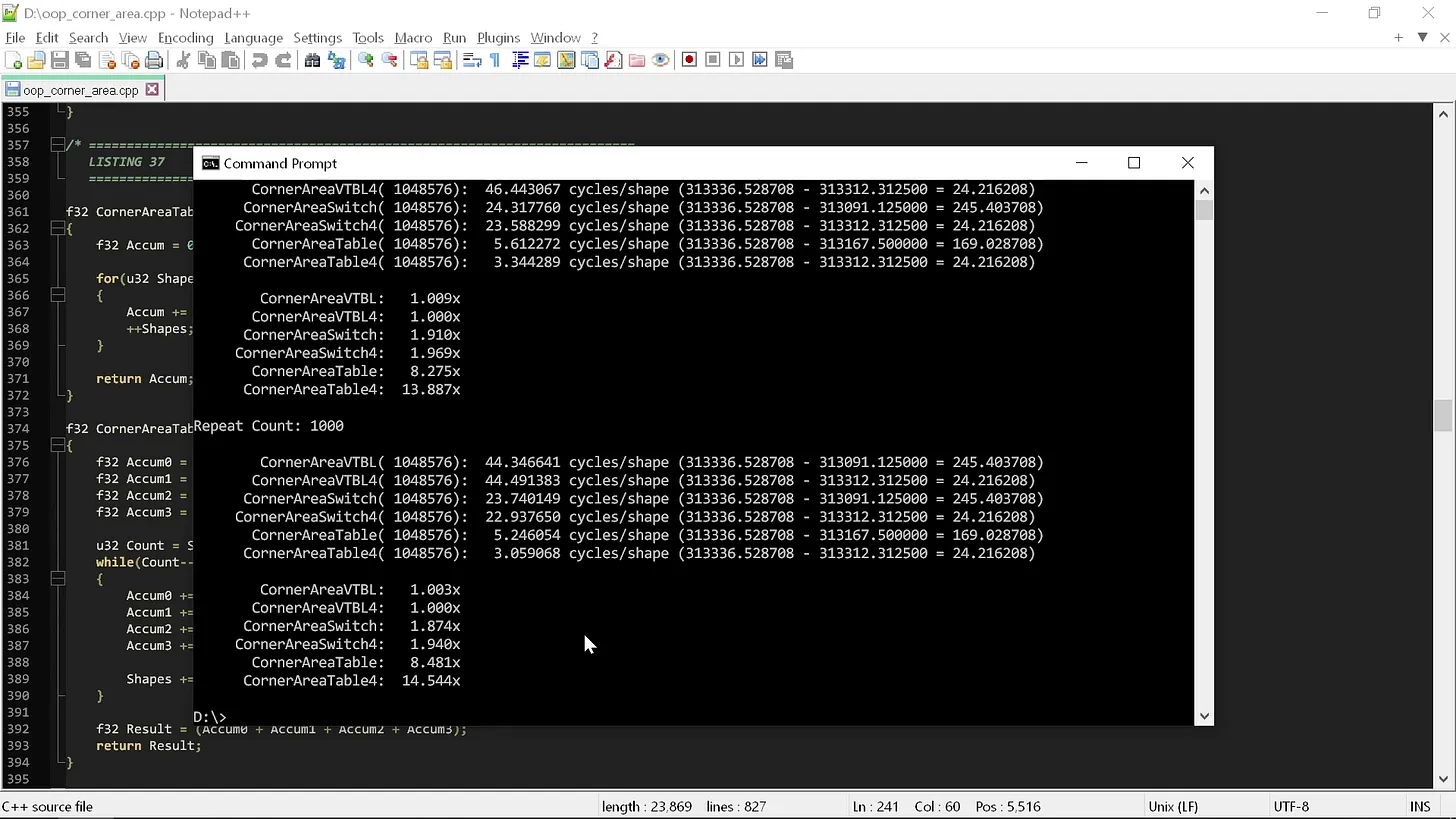
Как можем видеть, «чистый» код начал справляться еще хуже. switch‑версия, которая была лишь в 1.5 раза быстрее, теперь быстрее почти в 2 раза, а табличная версия и вовсе чуть ли не в 15 раз.
Это показывает еще более глубокую проблему «чистого» кода: чем комплекснее становится задача, тем больше эти идеи вредят производительности. Когда вы попытаетесь расширить «чистые» техники до реальных объектов с кучей полей, вы будете страдать от повсеместных ударов по производительности во всем коде.
Чем больше вы будете использовать методологию «чистого» кода, тем меньше компилятор будет понимать, что вы делаете. Все в отдельных единицах трансляции, все скрыто за виртуальными функциями и т. д. Не имеет значения, насколько компилятор хорош, он мало что сможет сделать с такого рода кодом.
И что еще хуже, с таким кодом и вы мало что сможете сделать! Как я показал ранее, простые вещи, как добавление выделенных значений в таблицу и удаление оператора switch, просты в реализации, если ваша кодовая база построена вокруг ваших функций. Если, напротив, она спроектирована вокруг типов, все становится довольно сложно, возможно, даже невозможно без дорогостоящих переделок.
Таким образом, мы с десятикратной разницы допрыгнули до разницы в 15 раз простым добавлением одного свойства в фигуры. Это как вернуться с железа 2023 года на железо аж 2008-ого! Вместо стирания 12 лет мы стираем уже 14 лет просто введением нового параметра в условие задачи.
Это само по себе ужасно, но, прошу заметить, я еще даже не упомянул оптимизацию! Не считая проверки на зависимость в цикле в целях тестирования, я не оптимизировал ничего!
Вот так выглядят результаты запуска функций с слегка оптимизированной AVX‑версией этих же вычислений:

Разница в скорости достигает 20–25 раз и, конечно, никакая часть оптимизированного под AVX кода не использует ничего, даже отдаленно напоминающего принципы «чистого» кода.
Разобрались в четырьмя правилами, что с номером пять?
Если честно, «don't repeat yourself» выглядит неплохо. Как видно из листингов, мы не особо повторялись. Можно было бы засчитать развернутые версии с четырьмя аккумуляторами, но то было лишь для демонстрации. Фактически это ни к чему, если только вы не проводите подобные оценки.
Если «DRY» означает нечто более строгое, как, например, запрет на построение двух разных таблиц, хранящих разные версии одних и тех же коэффициентов, то я могу не согласиться с этим в некоторых случаях, ибо мы можем делать подобное для ощутимого повышения производительности. Но если, в целом, «DRY» просто означает не писать ровно один и тот же код дважды, то это вполне обоснованный совет.
И что более важно, нам не нужно нарушать это правило, чтобы наш код стал заметно производительнее.
В общем, из пяти правил чистого кода, влияющих на структуру кода, я бы сказал, есть лишь одно, о котором вам стоит думать, и четыре, о которых однозначно не стоит. Почему? Потому что, возможно, вы заметили, что ПО в наши дни работает ужасно медленно. Оно справляется намного, намного хуже, чем современное аппаратное обеспечение позволило бы ему решить существующие сейчас задачи.
Если вы спросите, почему ПО медленное, тому есть несколько объяснений. Какое из них является наиболее доминирующим, зависит от конкретной среды разработки и методологии кодинга.
Но для существенного сегмента компьютерной индустрии большой долей объяснения на «почему ПО такое медленное» является ответ «из‑за „чистого“ кода». Почти все идеи, лежащие под методологией «чистого» кода, ужасны для производительности, и вы не должны им следовать.
Правила «чистого» кода были разработаны лишь потому, что кто‑то подумал, что они помогут строить кодовые базы, которые легче будет поддерживать. Даже если это было бы правдой, вам надо задаться вопросом: «Какой ценой?»
Мы не можем просто пожертвовать десятилетним или более длительным прогрессом аппаратного обеспечения, просто чтобы лишь чуточку облегчить жизнь программистов. Нашей задачей является написание программ, которые бы хорошо проявляли себя на железе, которое нам дано. Если эти правила настолько негативно сказываются на производительности, мы попросту не можем их принять.
Мы все еще можем попытаться придумать практические правила, которые помогут держать код организованным, легко поддерживаемым и легко читаемым. Это вовсе не плохие цели! Но вот эти правила таковыми не являются. Нужно перестать их продвигать без большой сопровождающей сноски, в которой бы говорилось: «...и ваш код после этого будет работать в 15 раз медленнее».
Комментарии (211)

panzerfaust
11.09.2023 10:01+103Баян https://habr.com/ru/companies/sportmaster_lab/articles/728880/
Можно бесконечно смотреть на три вещи: как горит огонь, как течет вода, и как диванные бунтари побеждают "Чистый код" через разбор Circle extends Shape.

isadora-6th
11.09.2023 10:01+2Базовый курс C++ (MIPT, ILab). Lecture 13. Проектирование
Лучший пример как разворачивать Circle extends Shape который я видел в последнее время. Неприятно, что вместо примера такой штуки (как parent reversal) нам показывают очередной свич.

shmutz
11.09.2023 10:01>диванные бунтари побеждают "Чистый код" через разбор Circle extends Shape
ну эта же "уровень хабры".
Или будешь утверждать, что например "Java Concurrency in Practice" и Clean Code: A Handbook of Agile Software Craftsmanship противоречат друг другу на те же лютые 50-80 процентов?


Aquahawk
11.09.2023 10:01+27А я скопирую сюда свой коммент от прошлой версии этой статьи:
Да, да, да, и ещё раз да. Как человек плотно погружавшийся в недра компилятора и библиотек сворачивания белков, написавший графдвижок с нуля(не в стол, а работающий в продукте, окупившийся за считанные месяцы, и работающий уже третий год в продакшне без особых правок) я подтверждаю всё что здесь написано. Очень, очень часто "красота" и "чистота" кода прямо противоположны скорости и реальной понятности. Сложные вещи были и остаются сложными, нельзя взять сложный алгоритм и распилить его на миллион функций, в каждой не больше трёх if, и 10 строк кода. Нельзя распилить на бесконечное количество абстракций нижний уровень матмодели. Ну т.е. можно, но в итоге получится никому не нужный мусор.

MiraclePtr
11.09.2023 10:01+36В той статье был еще отличные комментарии:
Я надеюсь, вы понимаете, что занимаетесь софистикой. Если брать какой-то удобный для себя синтетический кусочек кода и потом прожаривать его, то можно доказать вообще любой тезис. И что чистый код вреден, и что чистый код полезен. Да хоть, что кодить китайскими иероглифами быстрее и понятнее, чем латиницей.
Реальный разговор пойдет, когда вы отрефакторите реальный сервис на 100 килострок из своего прода в соответствии с вашим мировоззрением, а потом предъявите не только метрики скорости, но и такие "незначительные" метрики как динамику багов, время на исследование одного бага, время от todo до ready и т.д.
чистый код - это не про производительность.. это про процесс(!) разработки, где есть несколько команд разработки, несколько лет поддержки сложного с точки зрения бизнес-логики кода, увольнения, найм новых сотрудников на допил кода без документации...
п.с. надеюсь вы по городу ездите со скоростью 200 км/ч. Ведь нафиг эти ПДД - можно же быстрее /s
или вот еще

MountainGoat
11.09.2023 10:01-5чистый код - это не про производительность.. это про процесс(!) разработки
Примерно с той же парадигмой и родили Electron.
MiraclePtr
11.09.2023 10:01+4Неа. В случае с "чистым кодом", если возникнут проблемы с производительностью, то можно взять и переписать по-другому те места, на которые укажет профилировщик, и проблема будет решена.
В случае с Electron придется переписывать все приложение. Правда, недавно вон появился tauri, который основан на том же принципе, что и Electron, но в десятки раз более легковесный.
MountainGoat
11.09.2023 10:01+2Из практики переписывания тех мест, которые указал профилировщик. Я весной добрался с профилировщиком до мелкой программки, которая проверяет дамп с данными в формате "как CSV, но бинарный" на
вшивостьлогичность. Было так:struct SoloUser { name: String, ... } struct VIPUser { contract_id: u64, ... } struct CompanyUser { company_name: String, } impl User for SoloUser { ... } // и так же для двух другихИ вся программа работает с данными как
Vec<Box<dyn User>>Суть программы в том, чтобы сравнить всех юзеров со всеми, но не влоб, поэтому чексуммы не помогут, надо сравнивать. Я взял и переписал:enum UserType { Solo, Company, VIP, } struct User { user_type: UserType, name: String, contract_id: u64, company_name: String, }И данные теперь в
Vec<User>Любители чистот схватились за сердце и другие места, к тому же оно теперь жрёт не 100 мб памяти, а 200. Но результат даёт в три с хвостиком раза быстрее. Не 5 минут, а полторы. Только потому что я убрал слой редиректов, существующий только ради красоты.Это речь идёт об одноразовой программке длиной в четыре экрана. Но красота подначивает нас с ходу в основе большой программы заложить несколько слоёв редирекции. И к моменту, когда мы поймём, что у нас проблема производительности - это уже не перепишешь.
panzerfaust
11.09.2023 10:01+8А при чем тут "Чистый код"? Давайте откроем одноименную книжку Мартина или "Совершенный код" Фаулера и поищем тезис типа "всегда и везде делайте длинные бесполезные иераррхии наследования"? Найдем такое?

Le0Wolf
11.09.2023 10:01+3Во первых, а нужна ли была производительность? А во вторых, новый вариант труднее для понимания, поскольку в первом варианте тип сущности говорил о том, какие в нем могут быть данные, а теперь у нас есть то, с чем работать без какой то документации (в коде или ещё как то) невозможно.
Вообще, следует понимать, что код пишется в первую очередь для разработчиков и только во вторую очередь - для компьютера. Поэтому в первую очередь он должен быть понятен и только во вторую - оптимален. Если код легко читается и при этом решает задачу за оптимальное время - рефакторить его для повышения производительности не нужно

Ilyaantipanov
11.09.2023 10:01Вообще, следует понимать, что код пишется в первую очередь для разработчиков и только во вторую очередь - для компьютера. Поэтому в первую очередь он должен быть понятен и только во вторую - оптимален.
Ага и после такого подхода мы имеем медленные приложения и игры, где ответом на всё служит покупка мощнее аппаратуры только потому что кто то увлёкся абстракциями. Почему пользователь должен каждый раз покупать всё мощнее телефон только потому что разрабы каждый раз накидывают всё больше абстракций?
Le0Wolf
11.09.2023 10:01+1Вы видимо меня неправильно поняли. Я не за отсутствие оптимизации, я ведь не зря писал про оптимальное время.
В тех же случаях, которые описали вы, дело не в абстракциях, а либо в требовании быстрее выйти на рынок (ценой даже выпуска откровенно сырого продукта), либо во всяких наворотах, типа улучшенной физики, графики и прочего. А чаще всего и того и другого сразу.

unC0Rr
11.09.2023 10:01+4Хорошо, но почему не так?
enum User { Solo(String), Company(String), VIP(u64), }MountainGoat
11.09.2023 10:01Верно, просто в реале у них было много общих полей тоже.
Я сначала написал было
enum User { Solo(SoloUser), Company(CompanyUser), VIP(VIPUser), }Но уж больно много match-ев отовсюду полезло, переписал.
isadora-6th
11.09.2023 10:01+1VSCode на электроне все еще отражает буковки быстрей VisualStudio 2019, хотя казалось бы "КАК"? И это даже не на кофеварке, а на вполне себе i7-8750H. Так что, не стоит катить бочку на электрон, не предоставив, чем же он так плох.

ksbes
11.09.2023 10:01Электрон плох только тем, что "привет мир!" - весит сотню мегабайт в памяти и на диске и что тормозит на простом почти неанимированном интерфейсе.
Ну еще тем что под него легко и непринуждённо можно написать целую цистерну еле шевелящийся лапши. Особенно, если слепо пихать "чистые" фреймворки и тупо следовать всяким аббревиатурам.Чтоб приложение работало как VSCode - там тоже много надо оптимизировать и тюнить.
MiraclePtr
11.09.2023 10:01Электрон плох только тем, что "привет мир!" - весит сотню мегабайт в памяти и на диске
см. tauri - тот же принцип, что и у Electron, но весит в десятки и сотни раз меньше, потому что переиспользует системный WebView2.

Sarukazm
11.09.2023 10:01Это не достоинство электрона, а позор студии, она всегда была одной из самых тормозных IDE.
Aquahawk
11.09.2023 10:01+2чистый код - это не про производительность.. это про процесс(!) разработки
бесполезно думать про процесс если в результате получается неработающая херня. Потому что крайне желательно сразу оценить что мы делаем, бложик на 100 юзеров, небоскрёб, внедорожник или машину для формулы 1. Для всех этих категорий продуктов нужны разные архитектуры и постановка во главу угла разных приоритетов.
У меня претензии к тому что ооочень много народу говорит про мифическую расширяемость и про "скорость разработки" утверждая что чем больше паттернов намазано тем лучше. Важно понимать что для чего и правильно выбирать инструменты. Сейчас в инфополе кратно преобладают астронавты архитектуры с чистым кодом и паттернами.
https://github.com/microsoft/TypeScript/issues/17861
Вот пример выполненного мной рефактора который не был принят потому что снижает производительность. MS готовы платить затратами на разработку, чтобы это было быстрым. И кстати, стоимость поддержки файла файла на 3 мегабайта исходников не настолько уж и велика, как многие думают.
ksbes
11.09.2023 10:01+4И кстати, стоимость поддержки файла файла на 3 мегабайта исходников не настолько уж и велика, как многие думают.
Ну это до тех пор пока этого разработчика не "собьёт автобус". После чего начинаются довольно недешёвые "археологические раскопки"
Aquahawk
11.09.2023 10:01+1Они поддерживают это уже больше 10 лет, и там много людей работает. Неприятная правда в том что никакого "останавливающего эффекта" такой файл не приносит, как бы не казалось адептам "чистого кода". Подумаешь 3 тысячи функций, в одном файле. Никто не умер.

ruslan_sverchkov
11.09.2023 10:01+1Либо в том, что никто даже не пытался измерять эффект от таких файлов, потому что если ты фаанг то проще нанять еще сотню-другую гениев)
Aquahawk
11.09.2023 10:01+3я не могу рассказать деталий из за нда, но я видел проекты где нарушено всё что можно и которые саппортятся уже второе десятилетие и всё с ними ок, нет там никакой заоблочной добавочной стоимости за фичу. И есть новые проекты где всё стильно модно молодёжно, но почему-то добавление фичи стоит в 2 раза больше чем в том древнем монстре. И я разговаривал с программистами и старых и новых проектов, и нет, идиотов среди них нет. Мой личный опыт говорит что влияние стиля кода или количества применённых паттернов на стоимость поддержки и развития проекта переоценено. Архи важно общая концептуальная архитектура приложения, чтобы каждое вносимое изменение не требовало правки десятков файлов. Остальное детали.
ruslan_sverchkov
11.09.2023 10:01+5Еще раз - никто просто ничего не меряет, в эстимейты попали? Ну норм. Не попали? Ну были объективные причины. Поймите, это тезис из серии «мой опыт показывает что гиря на ноге никак не мешает бежать». Если в вашем проекте на чтение кода тратится больше времени, чем на его написание (мой тезис в данном случае в том, что это справедливо для любого сколько нибудь долгоживущего проекта), то его нужно оптимизировать на чтение. Сам афтар зачастую этого сделать не может из-за проклятия знания, тут нам на помощь и приходят solid и прочие базворды)
Aquahawk
11.09.2023 10:01+1если вы говорите что никто ничего не измеряет, то откуда инфа что solid и прочее таки помогает?
ruslan_sverchkov
11.09.2023 10:01+2Прекрасный вопрос) я убежден в том что это выводимо логически. Самый простой способ оптимизировать чтение это не читать то, что в данный момент не нужно. Возьмем для примера простой кейс с SRP - бизнес логика перемешана с инфраструктурным кодом. Если мне для решения задачи нужно только понять логику, но при этом приходится читать и инфраструктуру просто потому что скипнуть ее физически невозможно, очевидно это меня замедляет, потому что читать больше кода это медленнее чем читать меньше кода. Весь остальной solid так же прямо или косвенно работает на скорость чтения (помимо прочего). Но я с вами полностью согласен в том, что мерять надо, давно мечтаю такое измерение запилить но руки не доходят)
Aquahawk
11.09.2023 10:01+1про tdd я видел исследования https://habr.com/ru/articles/314994/ сами почитаете что там написано. А у адептов tdd есть очень много логических аргументов за.
ruslan_sverchkov
11.09.2023 10:01Спасибо за ссылку, она полезная, но вы ведь понимаете что это в обе стороны работает)
Aquahawk
11.09.2023 10:01Я говорю о том, что нужно опираться на разум и действовать в конкретном проекте адекватным способом и применять любые правила и техники понимая задачу, потребности и ограничения этих техник и правил. А не утверждать что все методы надо распилить на маленькие и всё станет шикарно. Не всегда. Нет абсолюта. Иногда нужны тесты, иногда нет, иногда настоящий TDD, иногда нет, иногда нужны интеграционные тесты, иногда нет, иногда нужно пилить код на абстрактные фабрики полиморфных объектов, а иногда нет. Есть набор инструментов которыми хороший разработчик должен не только владеть, но и понимать границы применимости, и подобрать нужный набор для конкретной задачи. Но почему-то адепты "чистого кода" и "астронавтической архитектуры" часто утверждают что надо всегда применять рекомендуемые ими подходы и будет хорошо. И эта статья протест против такого утверждения. И мои комменты тоже. Я не говорю что это всегда плохо, я говорю что думать надо.
ruslan_sverchkov
11.09.2023 10:01Что значит «думать», выбирать те решения которые нравятся интуиции, обученной на вашем уникальном опыте? Тут надо, тут не надо, я художник, я так вижу? Это безусловно лучше чем ничего, но боюсь на одном думании мы не превратим айтишку из огромной машины по переработке ценных ресурсов на говно во что-то вменяемое. Чтобы добиться по настоящему крутых результатов надо вырабатывать матаппарат для демаркации поддерживаемого кода и неподдерживаемого, надо использовать научный метод, но раз уж всего этого у нас пока нет, то надо хотя бы логикой не пренебрегать. Что такое астронавтическая архитектура я не знаю, возможно мы с вами вообще о разных вещах говорим. Если все это время речь была о том что не надо абьюзить паттерны то с этим сложно не согласиться)

breninsul
11.09.2023 10:01+1больше строк когда - хуже читаемость. Обычно так. В примере статьи switch луше классов, 100%. В случае с массивом не очевидно соответствие фигуры и коэффициента. Лучше объявить константы, которые уже положить в массив, или обьясниться комментарием.
Иерархия классов явно проигрывает наглядности.

michael_v89
11.09.2023 10:01+5проекты где нарушено всё что можно
И есть новые проекты где всё стильно модно молодёжно, но почему-то добавление фичи стоит в 2 раза большеОбычно так получается, потому что в первых нарушено не так уж много, а во вторых стильно только на первый взгляд, а если разобраться, то "правильные" подходы применены неуместно и только создают лишнюю сложность.
Например встречал такой код. Есть главный компонент для расчета некоторых значений в заказе, есть 4 калькулятора, для калькуляторов есть интерфейс. Один калькулятор обернут в декоратор, который подменяет аргумент; в реализации калькуляторов много копи-пасты, которые расчитывают одни и те же базовые значения; в главном компоненте все 4 калькулятора находятся в 4 разных полях класса, и непонятно, зачем тут вообще интерфейс; "Go to definition" для вызовов методов всех 4 полей постоянно переходит на интерфейс, и приходится постоянно проверять, какая же из 4 реализаций нужна в этот раз. Сами по себе декоратор, интерфейс с реализациями и DI-конфиг для всего этого сделаны как бы технически правильно, но в целом это только создает проблемы.
Ну и да, в этом коде были баги, и были предыдущие задачи вида "тут поправили, там перестало работать". Перенес всё в главный компонент, общий код вынес в переиспользуемые внутренние методы, кода стало в 2-3 раза меньше, нашлась причина багов. Теперь уже несколько месяцев работает без сбоев.

sergey-gornostaev
11.09.2023 10:01+12Make it run, make it right, make it fast, как гласит народная мудрость. Ну, и полезно вспомнить про кривую Шипилёва.

beeruser
11.09.2023 10:01-1Такой подход в геймдеве обычно не работает. Если делать так, то получается, что у вас до релиза месяц (и его нельзя двигать) и при этом фреймрейт на целевой платформе 10fps (true story). Вот тогда начинается веселье.
Мифы о наличии какой-то большой горячей части в играх это заблуждение. Вот, прямо тут в коментах нашёл "реальное влияние на производительность имеет очень небольшая, но очень горячая часть кода.". Святая наивность @rjhdby
Да нет такого. В профайлере вы видите 100000 функций со временем выполнения, скажем, по 0,0001 - 0,1 мс. Что-то можно кинуть в другой поток, что-то нет. Но если мы эти функции писали абы как, то они и остаются унылым говном.
Какие там хотспоты? Просто тормозит всё сразу. И вот тут хочется всё выбросить и переписать как Кейси. Но на это потребуется 10 лет (и это не шутка).
Если это не игра - сервис, то "оптимизирую потом"(с) не будет.
В общем и целом, шанс выжить с покупным движком, который пилили такие люди как Кейси, гораздо выше, чем с самописным.

rjhdby
11.09.2023 10:01Какой процент рынка разработки занимает геймдев?
И какой процент геймдева подвержен таким проблемам?

Hivemaster
11.09.2023 10:01В геймдеве и нужды в чистом коде особой нет. Парадигмы, методологии, шаблоны проектирования и прочее придумано для продуктов, которые нужно сопровождать больше десятка лет, оперативно меняя под изменения на рынке. Игра же делается одной сравнительно небольшой командой, релизится ровно один раз и потом только фикситься, да и то не долго.

nameless323
11.09.2023 10:01Зависит от игры. Некоторый синглплеер - почти fire and forget. Но например ААА игра может писаться лет 8 (см RDR2). Двиг может поддерживаться и расширяться десятилетия (Anvil, Frostbyte и т.д), а то, что каждая отдельная игра на нем выпускается, патчится год и забывается это уже детали, двиг жить продолжает. Ну и есть еще целая куча всяких ММО игр и прочих, которые живут десятилетия (Wow, WoT etc). И движки и игры должны постоянно меняться, чтоб подстраиваться под текущие реалии, новое железо, конкурентов.
В геймдеве вообще баланс между - надо чтоб быстро/надо чтоб читаемо, это очень тонкая тема.


AndreyAlin
11.09.2023 10:01+24А теперь попробуйте в свой код добавить ещё один тип фигуры - замкнутую ломаную линию, и посмотрите, как это получается сделать с чистым кодом и с "производительным" кодом. И протестируйте с -О2 опцией не только для компилятора, но и для линкера.

event1
11.09.2023 10:01+6Данная статья доказывает, что любую идею можно довести до абсурда. И что инженерам не стоит впадать в религиозное обожание той или иной концепции.
А ещё, мысль о том, что в падении производительности ПО виноват "чистый код" прекрасна сама по себе. А мужики-то не знали ⓒ
Aquahawk
11.09.2023 10:01+2Проблема в том что в инфополе идеи "чистого кода" наиболее популярны и предлагаются как ультимативно хорошие.
MiraclePtr
11.09.2023 10:01+4С этими идеями примерно как с базовыми контейнерами из стандартных библиотек языков - в 90% случаев они действительно отлично подойдут и позволят сэкономить кучу времени. А если окажется, что случай специфический, или в какой-то момент перестанет хватать производительности, то всегда можно эти узкие места переписать более эффективно.
Aquahawk
11.09.2023 10:01Иногда потом переписать. Я видел умершие продукты по этой причине. Понимать что мы строим надо сразу и заложить нормальный подход надо сразу. Нельзя написать графдвижок по канонам "чистого кода" а потом улучшить.
MiraclePtr
11.09.2023 10:01+8Нельзя написать графдвижок по канонам "чистого кода" а потом улучшить.
Ну с этим никто и не спорит. Графдвижки - это именно тот случай, когда производительность является одним из ключевых требований, и ради нее готовы поступиться очень многим другим. Это как раз те упомянутые 10% случаев.
Я видел умершие продукты по этой причине.
Я видел обратное. Встраиваемый софт (АСУ ТП), 16-битный контроллер на 20 мегагерц, 128 килобайт памяти, 256 килобайт флеша. Код писали как обычно в эмбеддеде - "экономим каждый байт и каждый такт, а то мало ли что". И за N лет в этом изделии количество различных протоколов (которые надо поддерживать), количество различных ревизий и моделей устройства (которые все надо поддерживать) и количество новых функций каждый год, которые нужно было запилить для каждого нового объекта и новых заказчиков, привели к тому, что код написанный в таком классическо-эмбеддерском стиле стало просто невозможно поддерживать - люди сбегали из проекта, количество багов росло, время на запиливание чего-то нового тоже росло, причем даже не линейно, а геометрически. В итоге было принято волевое решение часть глубоко отрефакторить, а часть переписать по-нормальному - в том числе и с использованием ряда практик того самого "чистого кода" (насколько это возможно в коде на Си и старом диалекте Си++). И в итоге работать оно стало ничуть не хуже - по-прежнему вполне вписывались в ресурсы железа, и еще даже запаса достаточно оставалось. Premature optimization is the root of all evil на практике.
Aquahawk
11.09.2023 10:01вы не представляете сколько людей в геймдеве сначала пишут всё "расширяемо, ООПшно, чисто и красиво" а потом это тормозит. Я выше приводил примеры из компиляторов, библиотек рассчётов, граф- и физ- движков. Высоконагруженный сервис на самом деле туда же, ну есть у нас сервис статистики который переваривает пару миллиардов иветов в сутки по 50 параметров в каждом и всё это хранит. И когда ты делаешь такое, ты должен думать в первую очередь о скорости, и что интересно, ничерта не портится там читаемость и поддерживаемость.
rjhdby
11.09.2023 10:01+3Справедливости ради, "когда ты делаешь такое", то реальное влияние на производительность имеет очень небольшая, но очень горячая часть кода. Остальные 99.99% кодовой базы не окажут какого либо статзначимого эффекта на производительность, хоть по заветам Бугаенко пиши.
Aquahawk
11.09.2023 10:01Ага, а потом все эти 99.99% кода весело тормозят уже ничего не сделать, как пример юнити на мобилах с aot компиляцией с косячным гц. Если у тебя вся игра постоянно аллоцирует объекты будут фризы, и никто ничего не сможет сделать, вообще. Потому что gc гавно. И ты либо экономишь объекты, либо получается херня. И зайти в существующий проект и подправить одно место не получится.
rjhdby
11.09.2023 10:01+2Ага, а потом все эти 99.99% кода весело тормозят
Значит кто-то просто не умеет в профилирование и оптимизировал не то и не там
event1
11.09.2023 10:01А ещё там же предлагаются квантовые компьютеры и искины, как решение всех проблем. Зрелый инженер понимает, что никаких "ультимативно хороших" идей не существует. Кроме тех, которые единственно существующие. Но о них никто не спорит, ибо нет альтернатив.
panzerfaust
11.09.2023 10:01+5Проблема в том что в инфополе идеи "чистого кода" наиболее популярны и предлагаются как ультимативно хорошие
Они ультимативно хорошие, если нужно писать код, вызывающий наименьшее количество "шо за нах". Если у кода задача ворочать гигабайтными файлами за O(1), то никто в здравом уме ни про какой чистый код не говорит.
У вас пруфы будут, что кто-то толкает чистый код как панацею от всего?

tenzink
11.09.2023 10:01+25О, опять перевод этой статьи на Хабре :)
Для тех, кто её ещё не читал, обратите внимание на то, насколько бредовое решение предлагает автор:
Треугольник, оказывается задаётся длиной основания и высотой. Успехов при подсчёте периметра и попытке нарисовать треугольник (ведь высота и основание его не задают однозначно)
У окружности теперь есть ширина и высота. Изобрели эллипс :)
Автор безбожно подгоняет представление фигур под ровно одну задачу - подсчёт площади, причём очень неуклюжим образом, но не догадывается хранить предвычесленную площадь в объекте. Насколько быстрее получилось бы!!!
ksbes
11.09.2023 10:01Ну только так и можно добиться большой производительности - сосредотачиваясь на конкретнейшей задаче и идя на порой довольно дикие компромиссы.
Всеобщая теория всего будет обсчитываться за время существования вселенной! (а то и дольше :) )tenzink
11.09.2023 10:01+7Правильной оптимизацией тогда будет:
struct shape { f32 Area; };Потому что то представление, которое предлагается в статье годится только для рассчёта площади. Периметр и отрисовку сделать уже невозможно (смотри представление треугольника).

DenisPantushev
11.09.2023 10:01+3Ну хорошо. А теперь в версию с массивом коэффициентов (дальше я код не анализировал) добавьте код для вычисления площади параллелограмма. Какие там данные для хранения параллелограмма? Уж точно не только ширина и высота. Сколько придется переписывать программу? Всю?
Чистый код - это про то, как поддерживать скорость разработки и далее, после того, как написал программу вычисления площадей круга и квадрата.
Орел, конечно, выявил паттерн для квадрата, круга и треугольника. А если добавить фигуру, не вписывающийся в ВАШ паттерн? Параллелограмм, у которого, как я сказал, три параметра - ширина, высота (я про стороны) и угол наклона? А если добавить еще одну операцию в интерфейс - расчет периметра? Сколько придется переписывать? Всю программу?
Нафиг, нафиг.
tenzink
11.09.2023 10:01+2Шах и мат - для площади наклон не важен :) А эта супер-программа заточена, чтобы складывать площади фигур. Будет хранить основание и высоту

osmanpasha
11.09.2023 10:01Пример неудачный, да) Но суть верна - этот "нечистый" код нерасширяем. Выше вот тоже предложили добавить замкнутую ломаную, которая не описывается двумя числами. Да хоть трапецию, для которой надо уже три числа, и код для остальных фигур придется переписывать.

cross_join
11.09.2023 10:01+6Даже первокурснику известно, что
int sum = 0;
for (int i = 0; i < 1000; ++i) {
sum += f(i);
}выполняется медленнее, чем
int sum = 0;
sum += f(0);
sum += f(1);
...
sum += f(999);А если функцию раскрыть, то еще быстрее.
Следут ли из этого, что нужно пользоваться наиболее быстро исполняемым кодом?
Споры о накладных расходах из-за таблицы виртуальных методов велись 30 лет назад. Наверное, имеет смысл просто поднять архивы и привести выводы :)

Leetc0deMonkey
11.09.2023 10:01Почему обязательно медленнее? Компилятор тоже может раскрыть цикл. И даже что-то посчитать at compile time. Но это как повезёт.
Aquahawk
11.09.2023 10:01+1Очень часто, когда вы знаете что пишете high performance код, проще и дешевле сразу написать нормально, потому что потом один хрен найдётся куски где компилятор не смог и придётся допиливать напильником.
cross_join
11.09.2023 10:01Ну, а по какой причине компилятор может раскрыть цикл? Неужели из-за большей производительности кода в цикле?

myxo
11.09.2023 10:01+2А с чего вы взяли-то? Скорее всего 2 вариант будет ещё и медленнее просто потому-что сгенерируется в тысячу раз больше кода, который вылезет из всех кешей инструкций, что перекроет затраты на if, который отлично предсказывается в процессоре.
Производительность теоретически мерить очень сложно, всегда нужно смотреть бенчи

zartarn
11.09.2023 10:01"всене однозначно") такие оптимизации идут в комплексе с чем то еще. в некоторых ситуациях компилятлр может очень эффективно оптимизировать, в некоторых он не сможет.
Взять то же обратное дискретное косинусное преобразование (одна из самых 'дорогих' операций в jpeg / mpeg.
В лоб:
double *input, *output; for (int i = 0; i < 32; i++) { double s = 0; for (int j = 0; j < 32; j++) s += input[j] * m_cos_cache[i][j]; output[i] = s; }С применением быстрого преобразования Фурье и раскладывания по регистрам
Hidden text
float *src, *dst; double v53, v58, v59, v60, v74, v78, v79, v80, v81; double v82, v83, v129, v142, v143, v144, v145, v146; double v147, v148, v149, v150, v151, v152, v153, v154; double v155, v200, v201, v202, v203, v204, v205, v206; double t0, t1, t2, t3, t4, t5, t6, t7; t0 = src[0] + src[31]; v142 = src[0] - src[31]; t1 = src[1] + src[30]; v152 = src[1] - src[30]; v74 = src[2] + src[29]; v200 = src[2] - src[29]; v146 = src[3] + src[28]; v144 = src[3] - src[28]; v81 = src[4] + src[27]; v150 = src[4] - src[27]; v79 = src[5] + src[26]; v154 = src[5] - src[26]; v201 = src[6] + src[25]; v129 = src[6] - src[25]; v82 = src[7] + src[24]; v148 = src[7] - src[24]; v53 = src[8] + src[23]; v153 = src[8] - src[23]; v60 = src[9] + src[22]; v151 = src[9] - src[22]; v202 = src[10] + src[21]; v203 = src[10] - src[21]; v204 = src[11] + src[20]; v145 = src[11] - src[20]; v205 = src[12] + src[19]; v149 = src[12] - src[19]; v58 = src[13] + src[18]; v155 = src[13] - src[18]; t2 = src[17] + src[14]; v143 = src[14] - src[17]; t3 = src[16] + src[15]; v147 = src[15] - src[16]; v83 = t0 + t3; v80 = t0 - t3; v59 = t1 + t2; v78 = t1 - t2; t0 = v74 + v58; v74 = v74 - v58; t1 = v146 + v205; v146 = v146 - v205; t2 = v81 + v204; v81 = v81 - v204; t3 = v79 + v202; v79 = v79 - v202; t4 = v201 + v60; v201 = v201 - v60; t5 = v82 + v53; v82 = v82 - v53; v53 = v83 + t5; v83 = v83 - t5; v60 = v59 + t4; v59 = v59 - t4; v202 = t0 + t3; v206 = t0 - t3; v204 = t1 + t2; v58 = t1 - t2; t0 = v53 + v204; v53 = v53 - v204; t1 = v60 + v202; v60 = v60 - v202; v202 = t0 + t1; t1 = (t0 - t1)*sincos[_sin_pi_div_4]; t2 = v53 * sincos[_cos_pi_div_8] + v60 * sincos[_sin_pi_div_8]; v53 = v53 * sincos[_sin_pi_div_8] - v60 * sincos[_cos_pi_div_8]; v60 = v83 * sincos[_cos_pi_div_16] + v58 * sincos[_sin_pi_div_16]; v83 = v83 * sincos[_sin_pi_div_16] - v58 * sincos[_cos_pi_div_16]; v58 = v206 * sincos[_sin_3pi_div_16] + v59 * sincos[_cos_3pi_div_16]; v59 = v206 * sincos[_cos_3pi_div_16] - v59 * sincos[_sin_3pi_div_16]; t3 = v60 + v58; t4 = (v60 - v58)*sincos[_sin_pi_div_4]; v58 = v83 + v59; t5 = (v83 - v59)*sincos[_sin_pi_div_4]; v59 = t4 + t5; v60 = t4 - t5; t4 = v80 * sincos[_cos_pi_div_32] + v82 * sincos[_sin_pi_div_32]; v80 = v80 * sincos[_sin_pi_div_32] - v82 * sincos[_cos_pi_div_32]; t5 = v201 * sincos[_sin_3pi_div_32] + v78 * sincos[_cos_3pi_div_32]; v78 = v201 * sincos[_cos_3pi_div_32] - v78 * sincos[_sin_3pi_div_32]; t6 = v74 * sincos[_cos_5pi_div_32] + v79 * sincos[_sin_5pi_div_32]; v74 = v74 * sincos[_sin_5pi_div_32] - v79 * sincos[_cos_5pi_div_32]; v79 = v81 * sincos[_sin_7pi_div_32] + v146 * sincos[_cos_7pi_div_32]; v146 = v81 * sincos[_cos_7pi_div_32] - v146 * sincos[_sin_7pi_div_32]; v81 = t4 + v79; v83 = t4 - v79; v79 = t5 + t6; v82 = t5 - t6; t4 = v81 + v79; t5 = (v81 - v79)*sincos[_sin_pi_div_4]; t6 = v83 * sincos[_cos_pi_div_8] + v82 * sincos[_sin_pi_div_8]; v83 = v83 * sincos[_sin_pi_div_8] - v82 * sincos[_cos_pi_div_8]; t7 = v80 + v146; v80 = v80 - v146; v146 = v78 + v74; v78 = v78 - v74; v74 = t7 + v146; v82 = (t7 - v146)*sincos[_sin_pi_div_4]; v146 = v80 * sincos[_cos_pi_div_8] + v78 * sincos[_sin_pi_div_8]; v80 = v80 * sincos[_sin_pi_div_8] - v78 * sincos[_cos_pi_div_8]; v78 = t6 + v80; v79 = t6 - v80; v80 = t5 + v82; v81 = t5 - v82; v82 = v83 + v146; v83 = v83 - v146; t5 = v142 * sincos[_cos_pi_div_64] + v147 * sincos[_sin_pi_div_64]; v142 = v142 * sincos[_sin_pi_div_64] - v147 * sincos[_cos_pi_div_64]; t6 = v143 * sincos[_sin_3pi_div_64] + v152 * sincos[_cos_3pi_div_64]; v152 = v143 * sincos[_cos_3pi_div_64] - v152 * sincos[_sin_3pi_div_64]; v143 = v200 * sincos[_cos_5pi_div_64] + v155 * sincos[_sin_5pi_div_64]; v200 = v200 * sincos[_sin_5pi_div_64] - v155 * sincos[_cos_5pi_div_64]; v155 = v149 * sincos[_sin_7pi_div_64] + v144 * sincos[_cos_7pi_div_64]; v144 = v149 * sincos[_cos_7pi_div_64] - v144 * sincos[_sin_7pi_div_64]; v149 = v150 * sincos[_cos_9pi_div_64] + v145 * sincos[_sin_9pi_div_64]; v150 = v150 * sincos[_sin_9pi_div_64] - v145 * sincos[_cos_9pi_div_64]; v145 = v203 * sincos[_sin_11pi_div_64] + v154 * sincos[_cos_11pi_div_64]; v154 = v203 * sincos[_cos_11pi_div_64] - v154 * sincos[_sin_11pi_div_64]; v203 = v129 * sincos[_cos_13pi_div_64] + v151 * sincos[_sin_13pi_div_64]; v129 = v129 * sincos[_sin_13pi_div_64] - v151 * sincos[_cos_13pi_div_64]; v151 = v153 * sincos[_sin_15pi_div_64] + v148 * sincos[_cos_15pi_div_64]; v148 = v153 * sincos[_cos_15pi_div_64] - v148 * sincos[_sin_15pi_div_64]; v153 = t5 + v151; v146 = t5 - v151; v151 = t6 + v203; v147 = t6 - v203; t5 = v143 + v145; v143 = v143 - v145; t6 = v155 + v149; v155 = v155 - v149; v149 = v153 + t6; v153 = v153 - t6; v145 = v151 + t5; v151 = v151 - t5; t5 = v149 + v145; t6 = (v149 - v145)*sincos[_sin_pi_div_4]; v145 = v153 * sincos[_cos_pi_div_8] + v151 * sincos[_sin_pi_div_8]; v153 = v153 * sincos[_sin_pi_div_8] - v151 * sincos[_cos_pi_div_8]; v151 = v146 * sincos[_cos_pi_div_16] + v155 * sincos[_sin_pi_div_16]; v146 = v146 * sincos[_sin_pi_div_16] - v155 * sincos[_cos_pi_div_16]; v155 = v143 * sincos[_sin_3pi_div_16] + v147 * sincos[_cos_3pi_div_16]; v147 = v143 * sincos[_cos_3pi_div_16] - v147 * sincos[_sin_3pi_div_16]; v143 = v155 + v151; t7 = (v151 - v155)*sincos[_sin_pi_div_4]; v155 = v147 + v146; v146 = (v146 - v147)*sincos[_sin_pi_div_4]; v147 = t7 + v146; v151 = t7 - v146; t7 = v142 + v148; v142 = v142 - v148; v148 = v152 + v129; v152 = v152 - v129; v129 = v200 + v154; v200 = v200 - v154; v154 = v144 + v150; v144 = v144 - v150; v150 = t7 + v154; v146 = t7 - v154; t7 = v148 + v129; v148 = v148 - v129; v129 = v150 + t7; v150 = (v150 - t7)*sincos[_sin_pi_div_4]; v154 = v146 * sincos[_cos_pi_div_8] + v148 * sincos[_sin_pi_div_8]; v146 = v146 * sincos[_sin_pi_div_8] - v148 * sincos[_cos_pi_div_8]; v148 = v142 * sincos[_cos_pi_div_16] + v144 * sincos[_sin_pi_div_16]; v142 = v142 * sincos[_sin_pi_div_16] - v144 * sincos[_cos_pi_div_16]; v144 = v200 * sincos[_sin_3pi_div_16] + v152 * sincos[_cos_3pi_div_16]; v152 = v200 * sincos[_cos_3pi_div_16] - v152 * sincos[_sin_3pi_div_16]; t7 = v148 + v144; v148 = (v148 - v144)*sincos[_sin_pi_div_4]; v144 = v142 + v152; v142 = (v142 - v152)*sincos[_sin_pi_div_4]; v152 = v148 + v142; v148 = v148 - v142; v142 = v143 + v144; v143 = v143 - v144; dst[3] = (float)v142; dst[6] = (float)v78; v144 = v145 + v146; v145 = v145 - v146; dst[5] = (float)v143; dst[7] = (float)v144; dst[10] = (float)v79; dst[9] = (float)v145; dst[12] = (float)v59; v146 = v147 + v148; v147 = v147 - v148; dst[14] = (float)v80; dst[11] = (float)v146; dst[13] = (float)v147; v148 = t6 + v150; v149 = t6 - v150; dst[15] = (float)v148; dst[18] = (float)v81; dst[17] = (float)v149; dst[20] = (float)v60; v150 = v151 + v152; v151 = v151 - v152; dst[19] = (float)v150; dst[21] = (float)v151; v152 = v153 + v154; v153 = v153 - v154; v154 = v155 + t7; v155 = v155 - t7; dst[0] = (float)v202; dst[1] = (float)t5; dst[2] = (float)t4; dst[4] = (float)t3; dst[8] = (float)t2; dst[16] = (float)t1; dst[22] = (float)v82; dst[23] = (float)v152; dst[24] = (float)v53; dst[25] = (float)v153; dst[26] = (float)v83; dst[27] = (float)v154; dst[28] = (float)v58; dst[29] = (float)v155; dst[30] = (float)v74; dst[31] = (float)v129;Hidden text
По итогу во втором варианте сильно меньше операций (в первом их 1024), плюс они разнесены чтолб хорошо ложились на суперскалярность
То что код стал больше не значит что он будет медленее, все зависит от конкретного случая

wataru
11.09.2023 10:01Вообще, есть промежуточный вариант. fft можно написать циклами. Будет чуть-чуть длинее наивного кода и возможно чуть-чуть медленнее вот этого сверх оптимального.
cross_join
11.09.2023 10:01Проверьте оба варианта, если есть какие-то сомнения. Только компилируйте без оптимизации.
nameless323
11.09.2023 10:01+1Может медленнее, может быстрее. Может компилятор векторизует цикл, может нет, может функция заинлайнится, может нет, может там еще что с -О3 заоптимайзится. Надо мерять, если место критичное смотреть, а так на глаз бесполезно гадать.
isadora-6th
11.09.2023 10:01Без замеров оратора...
Контринтуитивно, но как компилятор ваш костыль сможешь векторизовать?
std::count вообще SIMD использует и считает быстрее форов, да настолько, что 2 пробегания по массиву быстрей, чем одно с if внутри.
А как же спекулятивное выполнение и прочие прелести которые приросли к нам с времен pentium 3? А потом бранчи сверху мажем и миссы в кеш.
Branchless Programming in C++ - Fedor Pikus - CppCon 2021
Перф это не то, что можно намерять глазами. И люди очень склонны ошибаться в этом вопросе.
cross_join
11.09.2023 10:01Если это была реплика ко мне, то цитата чужая.
Расширение темы называется флудом. Если уж расширять, так с музыкой! Возьмем SMP на 1000 ядер и запустим на каждом по строчке. Попробуйте так с циклом.

pewpew
11.09.2023 10:01+8А где и кто обещал, что хорошо читаемый и поддерживаемый код, написаный по всем канонам будет выполняться производительнее лапшекода с множеством спецефических трюков, но оптимизированного для решения конкретной задачи на конкретном окружении?
Хорошо структурированный, чистый и красивый код пишется для удобной поддержки любыми другими разработчиками, минимально вникающими в проект. И наоборот, хорошо оптимизированный код можно написать понятно, но глубокое понимание оптимизаций возникает только после вдумчивого разбора (как пример — быстрое извлечение обратного корня в quake), на которое не всегда найдётся ресурс в виде программисточасов. Строго говоря есть задача — есть решение. Задача чистого кода отличается от задачи оптимизированного кода. Это как бы очевидно же. Так что идея статьи провальная.


iburanguloff
11.09.2023 10:01+4При написании кода нужно оценивать несколько факторов - производительность, читаемость, гибкость и т.п. Если терять эту нить и уходить в избыточную производительность или в избыточную читаемость - получится примерно вот это.
Если фактор производительности критичен - код должен писаться с упором на производительность, но подавляющая часть кодовой базы (на мой взгляд) требует поддерживаемости, что и дает чистый код. После того, как вы напишите читаемый код - другой разработчик потратит минимум времени для понимания того, как это работает. И добавление функционала не заставит переписывать кучу кода.
Слепое следование принципам чистого кода так же вредит.
И в большинстве случаев бизнесу нужно не чтобы код работал не 4мс, а 2мс (в 2 раза быстрее!), а чтобы код был написан нормально и вы уже приступили к другой задаче, а не тратили на эту целый день бенчмарков и тестов
fomiash
11.09.2023 10:01-2Во всем вебе код должен писаться с упором на производительность и безопасность. Читаемость при "чистом коде" (как его преподносит автор) тоже хуже, больше символов и логики. Другой разработчик всё равно будет тратить время на то, чтобы понять чужой код, даже если он по всем стандартам. Естественно, нужно искать золотую середину.
И добавление функционала не заставит переписывать кучу кода.Это по учебнику OOП, типа вот модель двигателя, а вот запчасти, красиво выходит, а потом добавляется второй двигатель (в реальности есть и такие автомобили, как камень еще в огород DDD) и переписывать все равно заново. Если бы бизнес шел проторенными шагами, условно не добавляя "вторые двигатели", то он скоро бы накрылся. Эти правила написания кода не учитывают реалии, которыми оперирует заказчик, не программист.fomiash
11.09.2023 10:01PS Кстати, могу же и мнение поменять, приглашайте на работу в реальный проект (по технологиям обсудим), если все-все так ровно там, как вы защищаете, без спешки сделано, по канонам, работает шустро, все довольны. А то уже насмотрелся всякого, на техсобесе OOП, DDD, TDD и тд, а потом в коде жуть... Это в общем, а не к комментатору выше ответ.

lair
11.09.2023 10:01+1Во всем вебе код должен писаться с упором на производительность и безопасность.
Нет, не должен. Он должен писаться с упором на то, что нужно владельцу.
fomiash
11.09.2023 10:01Что вы имеете в виду под "владельцем"(?), фаундеров компании, отдыхающих на островах и не имеющих представления о технических подробностях? А раз так, то специалисты по безопасности начальниками отделов не назначаются? Преобладающая часть веба это сайты, если сайт грузится более 5 сек, то по статистике его просто не существует. Приведите, пожалуйста, в пример ситуацию когда владельцу нужно, чтобы сайт адски тормозил и мог быть взломан проходящим школьником. В угоду чего? Обсуждаемой здесь "чистоты" кода? Чтобы когда его в даркнете выложат, стыдно не было?) Хотя в конце своего сообщения за то и топлю, чтобы учитывать интересы заказчика, надо было просто дочитать.
lair
11.09.2023 10:01Что вы имеете в виду под "владельцем"
Человека или группу людей, принимающих решения о целях и задачах сайта/продукта.
А раз так, то специалисты по безопасности начальниками отделов не назначаются?
Начальниками каких отделов? Где? Зачем?
Преобладающая часть веба это сайты, если сайт грузится более 5 сек, то по статистике его просто не существует.
"Сайт должен грузиться не более x секунд" и "сайт должен быть разработан с упором на производительность" - это два разных требования.
Приведите, пожалуйста, в пример ситуацию когда владельцу нужно, чтобы сайт адски тормозил и мог быть взломан проходящим школьником.
Вы путаете "сайт не должен тормозить" и "сайт должен быть самым быстрым любой ценой".
В угоду чего? Обсуждаемой здесь "чистоты" кода?
Например, в угоду тому, чтобы его можно было быстро выкатить в прод, а потом так же быстро развивать. А безопасностью иногда жертвуют в пользу удобства.
Хотя в конце своего сообщения за то и топлю, чтобы учитывать интересы заказчика
Так в том-то и дело, что вы себе противоречите: сначала заявляете, как надо, а потом упоминаете заказчика (которому на самом деле может быть надо совсем другое).
fomiash
11.09.2023 10:01Владельцу нужно, например, больше фич, но начальник отдела не забыл назначить человека, ответственного за безопасность - вот что имел ввиду. Быстродействие и безопасность - это базовые правила для веб-разработки, это конечно, не касается многих исключений, но в целом по индустрии это минимальные правило выживания. Можно привести большое количество примеров, когда заказчик попросит разработать быстро и тяп-ляп, покажет одному человеку и прибьет проект, и можно ли это относить к общей массе полноценных работающих проектов, вопрос другой. Мне кажется, такие наброски не стоит считать.
быстро выкатить в прод, а потом так же быстро развиватьЭто из области фантастики, так как или то или другое.А безопасностью иногда жертвуют в пользу удобства.Мы же об одной и той-же безопасности? Если в проекте есть БД, например, то не защитить её как минимум от инъекций... Возможно, что первый, кто её обнаружит, сделает работу совсем уж неудобной)lair
11.09.2023 10:01Владельцу нужно, например, больше фич, но начальник отдела не забыл назначить человека, ответственного за безопасность - вот что имел ввиду.
Я надеюсь, этот начальник отдела сделал это из своего кармана?
Быстродействие и безопасность - это базовые правила для веб-разработки, это конечно, не касается многих исключений, но в целом по индустрии это минимальные правило выживания.
Поддерживаемость кода (то, что вы зачем-то сводите к "чистый код") - это тоже базовое правило.
Мы же об одной и той-же безопасности?
Да, мы об одной и той же безопасности.
Я еще напомню, что в ряде случаев стоит выбор "производительность или безопасность".
Если в проекте есть БД, например, то не защитить её как минимум от инъекций...
А за это должен отвечать используемый фреймворк, чтобы не надо было в каждом проекте не забывать это делать и делать это правильно. Вот и абстрации появились, вот и производительность стала уменьшаться.
fomiash
11.09.2023 10:01По иерархии ответственности, воображаемый начальник отдела не взял из собственного воображаемого кармана, а использовал лимит средств на разработку. Есть вещи, такие как производительность и безопасность, которые само собой разумеются, особенно в Веб. Ну кстати и в десктопных играх fps тоже немаловажно, но там это может быть на третьем плане. Но желание делать прямо все, что требует начальство, кажется беспринципным. Писать лапшекод, использовать незаконный контент и тд, это не рабочие обязанности, а выбор разраба, который решает, идти на компромисс или нет. Касаемо "чистого" кода - это то определение, что описывается в статье, от себя ничего не придумал.
lair
11.09.2023 10:01По иерархии ответственности, воображаемый начальник отдела не взял из собственного воображаемого кармана, а использовал лимит средств на разработку.
Ну тогда ему потом и объяснять, почему несмотря на разумный выделенный бюджет разработка не двигается с той скоростью, которую ожидают.
Есть вещи, такие как производительность и безопасность, которые само собой разумеются
Да. Вот например поддерживаемость тоже "сама собой разумеется". Но вы ее в своих оценках игнорируете.
Но желание делать прямо все, что требует начальство, кажется беспринципным.
Я не советую делать все, что требует начальство. Я советую делать то, что выгодно работодателю (с учетом разных перспектив).
Писать лапшекод, использовать незаконный контент и тд, это не рабочие обязанности, а выбор разраба, который решает, идти на компромисс или нет.
Рабочие обязанности - это то, что описано в рабочих обязанностях. У кого-то и производительность/безопасность там отсутствует. А у кого-то и обязанность писать поддерживаемый код есть.
fomiash
11.09.2023 10:01Ну а где я противопоставляю скорость работы (что не всегда производительность, кстати) безопасности?
Ну если кто-то ради бюрократии впишет в договор поддерживаемость, это очень сомнительная юридическая вещь, так как любой код поддерживаемый, но можно опровергнуть это различными известными практиками написания кода, что опять таки не доказывает юридически, что эти практики во всех случаях сработают именно так.
lair
11.09.2023 10:01Ну а где я противопоставляю скорость работы (что не всегда производительность, кстати) безопасности?
Вы - нигде. А мне очевидно, что чем больше внимания уделяется безопасности, тем медленнее будет идти разработка и тем менее производительным будет результат.
Ну если кто-то ради бюрократии впишет в договор поддерживаемость, это очень сомнительная юридическая вещь
...так то же самое можно и про безопасность сказать, не правда ли?
fomiash
11.09.2023 10:01Не соглашусь, у безопасности более четкие критерии, были похищены данные или нет, имел ли посторонний доступ к данным, была ли нарушена работа сервиса извне, etc. В сравнении к сугубо сравнительном описании практик правильного написания кода для его дальнейшей поддержки. Но, как уже написал, поддерживать можно любой код, зависит от средств и времени.
lair
11.09.2023 10:01у безопасности более четкие критерии, были похищены данные или нет, имел ли посторонний доступ к данным, была ли нарушена работа сервиса извне
Это критерии последствий. А пока нет последствий, оценка того, безопасный ли код - это те же самые "практики". Грубо говоря, вот есть уязвимость X, но возможно ли реальная ее эксплуатация, сколько стоит эту уязвимость закрыть, и какие потери от эксплуатации - это все вопросы оценки, а не абсолют.
Так что с точки зрения обязанностей разработчика что требование "писать поддерживаемый код", что требование "писать безопасный код" - одинаковая фикция.
fomiash
11.09.2023 10:01Не понимаю причин вашей категоричности, так вы докажете, что NDA не существует в природе) Перечень критериев для безопасности, типа вот выше, легко внедрить в трудовой договор. В то же время гарантировать, что код будет легко поддерживаем новыми разработчиками заявление весьма размытое. То есть можно определить некие правила, и место им не в трудовом договоре а code-style, но будет он в действительности таковым зависит от разработчиков, а не правил. В обшем, если хотите что-то мне доказать, способ выше я указал.

Ndochp
11.09.2023 10:01Перечень критериев для безопасности, типа вот выше, легко внедрить в трудовой договор.
И после этого любая утечка будет только в результате нарушения одного из критериев, или все таки это будет что то типа "не пишите код без ошибок"?
Кажется эти критерии безопасности внедренные в договор остануться на уровне кодстайла. — кто-то меняет пароли раз в месяц, а кто-то на постоянно теряемые физические токены всех перевел.Про требования именно к используемым в коде конструкциям направленным на безопасность я уж не говорю, им точно место в кодстайле, и они точно будут рекомендательными, если вы не пишете код для АЭС
lair
11.09.2023 10:01Не понимаю причин вашей категоричности, так вы докажете, что NDA не существует в природе
NDA работает как раз за счет того, что в нем можно четко прописать, чего нельзя делать сотруднику.
Перечень критериев для безопасности, типа вот выше, легко внедрить в трудовой договор.
И что же конкретно вы туда напишете, приведите пример?
В то же время гарантировать, что код будет легко поддерживаем новыми разработчиками заявление весьма размытое.
Гарантировать нельзя почти ничего. В том числе безопасность или производительность.

Helltraitor
11.09.2023 10:01Мне одному кажется, что листинг 24, где "раскрыли" цикл
forотработает неправильно если количество фигур< 4?А так статью видел, про нее много было сказано и без меня

offline268
11.09.2023 10:01
Я не сильно внимательно читал, но реализация CornerAreaTable почему-то выдает результат отличный от других реализаций. Что намекает на неэквивалентность решений.

sergeperovsky
11.09.2023 10:01+10Тридцать лет назад мне приходилось писать ассемблерные вставки в код на Паскале, чтобы повысить производительность в 15 раз. Но уже следующая версия компилятора генерировала код, аналогичный моему.
Если имеет место заметная разница в производительности, то это означает недоработку авторов компилятора. Это не головная боль прикладного программиста. Его дело выбрать эффективный АЛГОРИТМ и реализовать его максимально прозрачным образом.
Actaeon
11.09.2023 10:01-12Эта методология "чистого кода" - я извиняюсь - это для программистов в блокноте, пережиток 90, когда не было нормальных средств рефакторинга. Вот это функция не должна быть длинней чем в один экран, 3000 функций в файле - плохо это ,извиняюсь, бред эпохи дос и терминалов. В 2023 году меня вообще не должно волновать в каком там файле какая там функция, берем , например , understand scitools - и сразу видим, и её интерфейс, и все места из которых она вызывается, и где меняются глобальные переменные буде они есть - можно читать спагетти-код и не мучится, можно писать спагетти код и чувствовать себя хорошо. Чистый код - для убогих средств разработки.

programmerjava
11.09.2023 10:01+3Одно другому же часто не мешает.
Хорошо, когда кода не много и в команда мала.. А вот попробуйте что-то такое написать, где и перфоманс нужен, и структурированность правильная, покрытие тестами, понятное разделение слоев.. чтобы годами можно было более менее работать: добавлять новые фичи, разделять ответственность по слоям архитектуры, баги\уязвимости править в срок.
Как-то приходилось писать Dependency Injection framework, ORM с генерацией всего нужного на этапе компиляции, большое количество каких-то библиотек в помощь команде... Благодарен этому опыту. А ведь много всяких таких программных продуктов, где чистая архитектура и перфоманс задействованы вместе. Попробуйте, стоит того.
А вот плохой лапшеподобный и неказистый код часто хрупок и приводит к каскадным изменениям, покрывать тестами его тяжело.. взаимодействовать с коллегами тоже. Один баг закрываешь - появляется вновь старый :) Вливаться тяжело и не хочется. И если менять никому не нужно из начальства, то только увольняться инженерам из этого болота :) И не факт кстати, что работать быстро будет. Скорее даже плохо, потому что среди такого рода деятельности редко появляются высокооптимизированные программные продукты. Скорее наоборот.. 90% протухшее мамонта сами знаете чего, а остальные 10% написаны уже действительно первоклассными инженерами и это какая-то утилитарная вещь скорее всего :)

ooki2day
11.09.2023 10:01+2т.е. вы предлагаете мне, как разрабу из вашей команды, платить дополнительно 100-120$ в месяц чтобы понимать ваш спагетти-код? а ревьювить на условном гитхабе это как, если до некоторых мест может добраться только дорогостоящий инструмент?
Daddy_Cool
11.09.2023 10:01+2Я так понимаю, идет перепись ситхов?
https://www.youtube.com/watch?v=Uyveh_j_NTM
nameless323
11.09.2023 10:01+4Каждому свое - пишете игру, не можете выжать 30/60фпс - в критическом для перформанса месте можете забыть на читаемость немного и сделать все реально оптимально для компьютера, а не программиста и будет радость.
Пишете условно сайтик (не писал сайтики, но мне кажется что лишнее 0.1мс на отображение странички дела часто не делают) или запрашиваете профиль игрока с сети - сделайте так, чтобы читать и расширять код было хорошо и просто, а то что пользователь подождет не 0.7с, а 0.8с условно в этом месте никого волновать не будет.
Ну и все что между. Головой надо думать когда настолько критически нужна перфа, а когда читаемость и все вариации между, а не тупо - везде пишем нечитаемый код или все пишем через 100500 паттернов и адаптеров.

klounader
11.09.2023 10:01+1Говорят, что один моддер недавно фоллаут для пк разогнал оптимизацией тысяч функций, улучшив алгоритмы и юзая новейшие компиляторы, т.к. большая часть кода была написана с учётом ограничений памяти игровых консолек.
И какое совпадение к этой статье, там тоже указывается, что разрабы игры предпочли более медленный, но компактный код, что и было ускорено и раздуто, в результате чего игруля должна заработать быстрее.
Похоже ли это на заговор рептилоидов или нет, но как минимум сходство имеется.

funca
11.09.2023 10:01-5Clean Code это такой же базвод как и SOLID. Вообще у Дяди Боба есть талант сочинять книжки, которые общественность тут же растаскивает на цитаты потому, что звучат красиво. На практике эффект такой же как когда архитектуру системы вам рисуют дизайнеры. Только во втором случае как-то проще переобуться, если всем становится очевидным, что креативное решение не работает. А в первом уже 30 лет продолжают этим наполнять инфополе, отвлекая недешевые умы от действительно важных дел.
panzerfaust
11.09.2023 10:01+5Clean Code это такой же базвод как и SOLID
Любая технология - баззворд, если в ней не шаришь, но рассуждаешь с видом знатока. Что, в общем-то, и демонстрирует автор.
funca
11.09.2023 10:01-2Автор показал ситуации, когда тупое следование рекомендациям Clean Code только ухудшает качество решения.
Инженерные задачи всегда решаются в ограничениях. Поэтому любые фремворки (включая логические) должны четко обозначать область своей применимости, и не претендовать на звание истины в последней инстанции.
Zanozus
11.09.2023 10:01+9Видел оригинал этой статьи еще на английском.
Во-первых, если перевести оценку производительности из кратности в количество циклов, то разница уже будет не "1.5-2.0 раза", а несколько десятков циклов, что уже не так кричаще звучит. И при усложнении общего кода эта разница так и будет оставаться в несколько десятков циклов.
Во-вторых, представим, что у нас не несколько фигур, а несколько десятков или сотен. И работает над ними не один человек, а десять. Страшно представить во что превратится такой считч-кейс и мерж-конфликты и командной разработке.
В-третьих, типы фигур могут появляться из разных кодовых баз. И не только из разных комманд, но вообще из разных организаций.
В-четвертых, потом могут появиться фигуры, площадь которых считается совершенно другим способом, например через интегрирование.
Еще стоит упомянуть, что помимо динамического полиморфизма существует еще и статический полиморфизм, который по назначению и функционалу ближе к свитч-кейсу. Динамический же решает куда больший круг задач.

titan_pc
11.09.2023 10:01-3Самый читаемый код - самый долго работающий. Самый не читаемый код - самый быстро-работающий.
Пример максимально читаемого кода: "Привет компьютер. Сходи в кафку, достань данные, положи в базу". Для запуска нужен чат жпт, ещё гора нейронок и сервисов под капотом ... Очень легко читается.
Пример самого производительного кода "01101101111.... 1000 000 строк спустя 001111011". Вообще не читается. Включить можно на куске из дерева
unC0Rr
11.09.2023 10:01+2Самый читаемый код — тот, над которым легче рассуждать. Как человеку, так и компилятору. В результате, его легче менять человеку и легче оптимизировать компилятору. Что легче оптимизировать: "Сходи в кафку, достань данные, положи в базу" или "01101101111… 1000 000 строк спустя 001111011"? То, что компилятор может пока не уметь оптимизировать настолько высокоуровневый код, не имеет отношения к самому коду, его свойства от этого не зависят.

tertiumnon
11.09.2023 10:01+3Вы не понимаете простую вещь - там, где нужен сверх-производительный код, приглашают специальных людей, которые пишут на специальных языках. Но это касается, в основном, узких участков кода.
Во всех остальных случаях, главная проблема - разобраться, что написал предыдущий программист, понять концепцию и не испортить ничего. Для этого и нужен "чистый код", чтобы быстро понимать, что происходит в коде.
nameless323
11.09.2023 10:01+1А специальные языки это С, С++ и ASM? У меня просто все вокруг плюсовики рядом (как и я) и никто никого не приглашает - всё сами. Все проще - пишешь чтобы всем понятно было, профилируешь, если уж реально прям сильно критичное место и профайлер показывает его как таковое, пишешь максимально оптимально (обычно плюсов и сей, интринсиков и всяких аттрибутов хватает, асм прям ну очень редко), желательно комментируя почему так написал, что и насколько это улучшило (не обязательно в коде, можно в пул реквесте).

SpiderEkb
11.09.2023 10:01+1Нет. Специальные языки, это специальные языки. Ориентированные на решение конкретного (узкого) круга задач наиболее удобным образом.
Например, если речь идет о каки-то коммерческих расчетах, то язык будет нативным образом поддерживать типы данных с фиксированной точкой и всю арифметику с ними, включая всякие операции с округлением (когда, к примеру, в переменную с двумя знаками после запятой присваивается значение переменной с тремя знаками после запятой).
Также там будет поддержка типов даты и времени, арифметика для работы с ними, представление их в нужном визуальном формате (с поддержкой множества разных форматов).
Там будут средства работы с БД. Как на уровне прямой работы с таблицами и индексами, так и возможностью имплементировать SQL непосредственно в код (естественно с использованием хост-переменных). Еще и с вариантами - статический, когда план запроса строиться в compile time и хранится где-то в коде или динамический когда запрос строится и планируется в run time (более гибко, но менее производительно).
И все это будет реализовано средствами языка, а не внешними библиотеками.
Не устаю приводить аналогию - когда вам надо застелить пол фанерой и для этого резать листы на ровные прямоугольники, это можно делать лобзиком, но очень неудобно. А можно циркуляркой - быстрее и ровнее. А вот попилить поленья быстрее и удобнее цепной пилой. А лобзиком можно вырезать сложные контуры...
nameless323
11.09.2023 10:01+2Я работаю в области где перфа сильно важна и в общем-то все обходятся плюсами и сями, авионика и авто тоже вроде сями обходятся, операционки в основном на сях и асме написаны. Конечно айти большое и где-то кого-то и приглашают и пишут на каких-то супер экзотических языках, но это не очень повсеместно.
SpiderEkb
11.09.2023 10:01Я работаю в области где перфа сильно важна и в общем-то все обходятся плюсами и сями,
Да, во многих областях так и есть
Конечно айти большое и где-то кого-то и приглашают и пишут на каких-то супер экзотических языках, но это не очень повсеместно.
И это тоже верно. Но, тем не менее, есть нишевые области где более удобны другие инструменты.
В свое время IBM предложила middleware решение для среднего бизнеса - System/36. Еще не мейнфремы (System/370), но уже достаточно мощные сервера. Потом была System/38, потом Advansed System 400 (AS/400). И вот эта платформа оказалась очень удачной и масштабируемой. Настолько, что стала использоваться не только в малом и среднем бизнесе, но и в крупном.
Там была цепочка "ребрендингов" - в разные времена она называлась iSeries, ePower (по-моему). Пока не устаканилось IBM i (мейнфреймы сейчас называются IBM z).
Достаточно распространена в мире в банках, страховых и т.п. У нас знаю что такие машинки были в ПФР (не знаю остались или нет), есть в РЖД. Как минимум три банка - Росбанк, Альфа (включая Альфа-Беларусь), Райффайзен на ней работают.
Высокопроизводительная, очень надежная, включает в себя сразу все что надо - интегрированная БД (DB2 for i), компиляторы (RPG, COBOL, C, C++, CL), все необходимые средства администрирования. Т.е. полное "коробочное" решение.
Очень специфичная, конечно - "объектная", "все есть объект". Абсолютно не похожа на остальные.
Устойчиво развивается - я в банк пришел в 17-м году, тогда стояла версия 7.3 (16-го года) В19-м появилась 7.4 (мы сейчас на ней). Сейчас текущая 7.5 (мы уже не успели). Это не считая регулярных Technical Refresh (TR) между версиями в которых тоже каждый раз что-то новое появляется.
Аналогично железо - в 17-м у нас были сервера на Power8, потом успели Power9 купить. Сейчас уже Power10 вышли.
Т.е. к "легаси" ее не отнести.
Так вот, более 80% кода на ней написано и пишется на языке RPG. Появился он примерно в одно время с COBOL как эмулятор табуляторов. Но с тех времен преобразился до неузнаваемости - сейчас это нормальный процедурный язык со статической типизацией. Отличительная особенность - поддержка прямой работы с таблицами и индексами БД (чтение-запись, поиск по индексу и т.п.) плюс возможность имплементации SQL непосредственно в код программы (в т.ч. и с использованием хост-переменных). Есть поддержка типов с фиксированной точкой и арифметика с этими типами. Вообще там есть все типы данных, которые есть в SQL - char, varchar, decimal (packed в RPG), numeric (zoned). Т.е. никаких преобразований не требуется - прочитали запись в буфер и работаем.
Да, здесь есть С/С++. И даже есть расширения в виде типа данных Decimal (DecimalT в С++). Есть библиотека Recio для прямой работы с таблицами и индексами, есть возможность имплементации SQL в С/С++ код. Но, тем не менее, наш опыт показывает что использование С/С++ тут нерационально - писанины больше (подавляющее большинство вещей на RPG будет проще и лаконичнее), а эффективность не выше (а если сильно увлекаться плюсовыми штуками типа исключений, "безопасных копий объектов" и т.п., то еще и ниже получается за счет активного выделения уровней стека и динамической памяти - все это не бесплатно). Это объективные данные PEX (Performance EXplorer) которые у нас снимаются на нагрузочном тестировании (быстродействие и эффективность использования ресурсов для нас весьма критична т.к. объемы данных очень большие, одновременно на сервере работает очень много процессов, а ресурсы, как ни крути, все одно ограничены и всегда должно держать запас производительности на периоды пиковых нагрузок).
Очень сильно спасает такая вещь как ILE (интегрированная языковая среда). В двух словах - она позволяет писать разные части кода на разных языках, а потом объединять их в один программный объект. Например, тот кусок, что отвечает за бизнес-логику (а он тут бывает очень нетривиальна) пишется на RPG, а там, где нужно что-то низкоуровневое, на уровне системных объектов, или просто видишь что тут на С/С++ проще, пишем на С/С++. Каждый кусок своим компилятором компилируется в "модуль" (аналог объектного файла), а потом модули собираются (bind) в один программный объект. Так же из RPG кода можно вызывать любую функцию С-шных библиотек просто прописав ее прототип со ссылкой на имя внешней функции. Биндер сам потом найдет и подцепит.
Если вернуться к аналогии с пилами - крупные листы нарезаем циркуляркой, потом сложные контуры дорезаем лобзиком. Максимально удобно и эффективно.
Поработав в такой системе некоторое время, пришел к выводу что этот подход - использовать для каждой задачи наиболее подходящий инструмент - действительно эффективен как с точки зрения разработки, так и с точки зрения конечного результата.
Даже когда с БД работаем. Если нужно из одной таблицы по индексу выбрать десяток-сотню записей, эффективнее сделать это используя прямой доступ - открыли файл, спозиционировались на начало выборки и read в цикле пока условие выполняется. Никаких тебе планов запроса, никаких лишних затрат времени.
Но когда речь идет о сотнях тысяч а то и миллионах записей, которые нужно собрать из нескольких таблиц да со сложными условиями - тут уже SQL будет эффективнее. И хорошо что есть возможность выбирать что использовать в каждом конкретном случае.

imanushin
11.09.2023 10:01+2Например, если речь идет о каки-то коммерческих расчетах, то язык будет нативным образом поддерживать типы данных с фиксированной точкой и всю арифметику с ними, включая всякие операции с округлением (когда, к примеру, в переменную с двумя знаками после запятой присваивается значение переменной с тремя знаками после запятой).
Зачем? Завести тип Money с операторами намного легче, чем иметь еще одну технологию ради более корректных вычислений.
Собственно, потому и будет опять JVM язык.
Также там будет поддержка типов даты и времени, арифметика для работы с ними, представление их в нужном визуальном формате (с поддержкой множества разных форматов).
Вроде, практически во всех сколько-нибудь распространенных технологиях это есть (Java, .Net, Go, и так далее).
так и возможностью имплементировать SQL непосредственно в код (естественно с использованием хост-переменных)
Это решается на базовом уровне библиотеками - https://github.com/JetBrains/Exposed . А далее уже начнется реальный SQL.
Еще и с вариантами - статический, когда план запроса строиться в compile time и хранится где-то в коде или динамический когда запрос строится и планируется в run time
Вы же про SQL говорите (MsSql, Postgre, Oracle и так далее)? Вы же понимаете, что запросы
select t.a from T t where t.b = 1иselect t.a from T t where t.b = 10влегкую могут иметь разные планы запросов (если представить, что мы всегда выбираем самый эффективный)?Не устаю приводить аналогию
Вы описали так детально, так что мне даже стало интересно - а что это за такая чудная технология, которая популярна в финансах, и объемы кода на которой не падают от года в год из-за постепенного отказа от legacy (как в случае с Cobol)?
SpiderEkb
11.09.2023 10:01-1Зачем? Завести тип Money с операторами намного легче, чем иметь еще одну технологию ради более корректных вычислений.
Сложно объяснить слепому как выглядит зеленый цвет :-)
Поверьте, это ничуть не проще. И уж точно не эффективнее.
Простой пример - есть таблица. В ней есть поля DECIMAL и NUMERIC. И то и другое - фиксированная точка. Разница в представлении в памяти (в подробности вдаваться не буду).
В вашем варианте будет что? Прочитали запись в буфер, потом нужные куски буфера передаем в конструктор вашего объекта (что само по себе требует некоторых затрат процессорного времени, создания как минимум одного уровня стека...).
В нашем варианте всего этого нет. У нас есть типы данных, сооветвующие DECIMAL и NUMERIC. Для нас запись в буфере - просто структура в которой есть поля типа packed (аналог DECIMAL) и zoned (аналог NUMERIC). Т.е. мы сразу работаем с этими полями, не создавая никаких дополнительных "объектов" (не преумножайте сущности сверх необходимого - Оккам). Аналогично для типов char, varchar, date, time, timestamp - эти типы есть в SQL, эти же типы есть у нас в языке.
Это решается на базовом уровне библиотеками - https://github.com/JetBrains/Exposed . А далее уже начнется реальный SQL.
Зачем натягивать сову на глобус, когда все это уже есть в языке. Без лишних библиотек, зависимостей. И SQL тут более чем реальный.
Вы описали так детально, так что мне даже стало интересно - а что это за такая чудная технология, которая популярна в финансах, и объемы кода на которой не падают от года в год из-за постепенного отказа от legacy (как в случае с Cobol)?
В нашем случае - IBM i.
Можно ли назвать легаси систему, которая постоянно развивается?
https://www.encora.com/insights/ibm-as400-historical-journey-and-future
https://www.nalashaa.com/future-of-ibm-as400/
И это не считая регулярных TR (Technical Refresh в которых тоже появляются новые фичи) между версиями.
База данных (DB2 for i), компиляторы языков (RPG, C/C++...) интегрированы в систему. Т.е. каждая новая версия или TR несет в себе что-то новое в плане языков тоже.
Основной язык - RPG

https://www.itjungle.com/2022/02/09/marketplace-study-shows-how-ibm-i-language-use-evolves/
Но, как написал выше, система поддерживает концепцию ILE, позволяющую использовать одновременно несколько языков для наиболее эффективной реализации каждой часть задачи наиболее подходящим для этого инструментом.
Да, это поначалу непривычно, но потом понимаешь что это удобно и эффективно со всех точек зрения.
michael_v89
11.09.2023 10:01В нашем варианте всего этого нет. У нас есть типы данных, сооветвующие DECIMAL и NUMERIC.
Неправда. Чтобы создать в оперативной памяти значение типа DECIMAL или NUMERIC, нужно вызвать конструктор. Даже если его вызываете не вы, а движок языка, он все равно вызывается. С затратами процессорного времени, созданием как минимум одного уровня стека, и всем остальным.
https://www.ibm.com/docs/en/SSQ2R2_15.0.0/com.ibm.tpf.toolkit.hlasm.doc/dz9zr006.pdf
"There are no decimal-arithmetic instructions which operate directly on decimal numbers in the zoned format; such numbers must first be converted to the signed-packed-decimal format."https://www.ibm.com/docs/en/zos/2.1.0?topic=statements-decimal-instructions
"Decimal instructions treat all numbers as integers. For example, 3.14, 31.4, and 314 are all processed as 314. You must keep track of the decimal point yourself."Вот код в библиотеках вашего языка, который делает "converted" и "keep track", это и есть конструктор.
https://www.ibm.com/docs/en/i/7.1?topic=type-zoned-decimal-format
"Zoned-decimal format means that each byte of storage can contain one digit or one character."Каждая цифра хранится в отдельном байте, то есть сложение значений делает цикл по каждой цифре с несколькими процессорными командами.
С обычным int и типом Money была бы одна инициализация в конструкторе, и одна процессорная команда для сложения. Точность одного int конечно меньше, но для большинства случаев этого достаточно, а для остальных можно написать другой класс. С дополнительными классами в обычных языках получается примерно то же, что и с вашим. Разница только в расположении программного кода классов-типов, но не в производительности.
Зачем натягивать сову на глобус, когда все это уже есть в языке. Без лишних библиотек, зависимостей.
Затем, что в вашем варианте у языка есть одна большая зависимость в виде специфичного сервера, а это обычно никому не нужно.
Для нас запись в буфере — просто структура в которой есть поля типа packed
Т.е. мы сразу работаем с этими полями
Аналогично для типов char, varchar, date, time, timestamp — эти типы есть в SQL, эти же типы есть у нас в языке.Это всё в том или ином виде есть в любом языке, для которого есть библиотеки для работы с базой данных. Integer конвертируется в integer, varchar в string, datetime в datetime или string.
Только работать с сырыми структурами считается плохим тоном, потому что нет типизации, которая предотвращает многие ошибки. Поэтому обычно структура конвертируется в объект некоторого класса, который используется в арументах функций и полях других классов. Неlogin(record $user), аlogin(User $user). А раз конвертируем в объект, то и поля структуры можно конвертировать.Чтение данных с диска с учетом декодирования внутренних структур БД и драйвера файловой системы занимает сотни инструкций и ожидание ввода-вывода. На этом фоне вызов конструктора с единицами инструкций-присваиваний практически ничего не стоит. Возможно этот специализированный сервер работает быстрее распространенных, но за счет железа и оптимизации ввода-вывода, а не языка.



Portnov
11.09.2023 10:01+4Тут ещё надо учитывать конкретный язык и версию компилятора. В java, мелкие методы будут заинлайнены вместо вызова автоматически. В дотнете, насколько я понял, есть sealed class optimization, которая для специально помеченных классов позволяет заменить vtable lookup на switch. В java, если этого нет прямо сейчас, может появиться в следующей версии. В той же java, если экземпляр класса создаётся, передаётся в другой метод и там используется только для чтения полей (не забываем что тривиальные геттеры будут заинлайнены), то в рантайме после jit объект создаваться не будет — будут просто переданы отдельные поля через стек. Я не удивлюсь, если часть этих оптимизаций есть в некоторых компиляторах C++ последних версий. Возможно там есть другие оптимизации, которых нет в java.
Так что, если уж действительно так "упарываться" по производительности, то надо учитывать наличие каждой отдельной оптимизации в конкретной версии компилятора под конкретную аппаратную платформу. Это, вероятно, оправдано, если вы делаете какие-то вычисления на embedded-платформе, где ни железо, ни сам софт никогда не будет меняться. Ну я не знаю, на зонд к Юпитеру залили софт, запустили его и всё, как улетит за орбиту Марса - прошивку уже не перезальёшь.

aegoroff
11.09.2023 10:01+5Вот что хочется сказать автору статьи
Грубо, весь код можно поделить на 2 класса - CPU bound и IO bound - второго кода, в реальной системе, подавляющее большинство, т.е. по факту, процессор в современном приложении большую часть времени ждет (сеть, диск итд). IO bound коду будет параллельно насколько циклов процессора будет быстрее считаться маленький кусочек кода, но подобная лапша окажет ОЧЕНЬ существенное влияние на производительность программиста.
Первое правило оптимизации - сначала профайлер! И именно не профилирование конкретного изолированного кусочка кода, а приложения в целом.
Всегда работает правило паретто (80/20), а в таких вещих, коэффициенты еще более экстремальны, вплоть до 100/1 - те только 1% кода СУЩЕСТВЕННО влияет на производительность
И вот только тогда, когда профайлер покажет что именно вот этот CPU bound код вызывает реальные проблемы с производительность - только тогда стоит применять фокусы описанные в этой статье.
Идем далее - даже в CPU bound коде, очень существенное влияние на производительность оказывают аллокации памяти и в первую очередь смотреть стоит в эту сторону

Ivan22
11.09.2023 10:01По сути все верно. Но маленькое уточнение - в общем случае ничто не мешает и IO bound оптимизировать отходя от Clean code
aegoroff
11.09.2023 10:01вопрос только - зачем? Оптимизация IO кода это скорее минимизация запросов к медленным источникам, например используя тот же фильтр Блума, но это совсем не то, о чем говорится в статье.

oragraf
11.09.2023 10:01+7Правила гигиены учат нас - мойте руки перед едой! Вроде все понятно и справедливо. Но что произойдет, если мы НЕ БУДЕМ мыть руки перед едой, как советует непонятно кто? Смотрите, 2минуты на мытье по три раза в день. Пусть в течение 50лет. Это получается, что если не мыть руки - мы сэкономим 76.6 дней. Это время можно потратить на разглядывание котиков! /s

nivorbud
11.09.2023 10:01+6В подобных спорах часто имеется элемент демагогии. Например, доказательство общего на частном примере и пр.
А реальный принцип есть только один - здравый смысл. Любую методику надо применять не фанатично, а основываясь на здравом смысле. Поэтому мне не нравятся не сами принципы чистого кода, а доведение их до абсурда. Типа: строго не более 5 строк кода и подобное.
Недавно пришлось копаться в коде, строго следующим принципам чистого кода - малюсенькие функции и классы по 2-3-4 строчки, раскинутые по тысячам файлов... Я задолбался скакать по десяткам функций и файлов, чтобы просто детально понять, что делает интересующая меня функция. Уж лучше один файл на десяток тысяч строк разбирать, чем это...
В общем знание и соблюдение принципов чистого кода - это хорошо, но... не должно быть фанатичного формализма (типа: 5 строк кода и ни строкой более!). И если возникает необходимость отклоняться от этих принципов, то разумней будет следовать необходимости, а не принципам.
SpiderEkb
11.09.2023 10:01+1А реальный принцип есть только один - здравый смысл.
Согласен. На мой взгляд, если говорить о "чистоте кода" (как лично я ее понимаю) - код должен быть читаемым. Во всех смыслах. И форматирование, и нужное количество вменяемых комментариев, и вот это все вот.
Т.е. по коду должно быть легко понять не только что он делает, но и как он это делает. Ну "легко", может быть не совсем то слово, если речь идет о каких-то сложных алгоритмах, скорее, тому не должно быть лишних препятствий.
И вместе с тем, код всегда должен быть эффективным. Если все эти модные полиморфизмы и абстракции оказываются в ущерб эффективности, наверное, стоит пересмотреть подход и как-то подсократить "концептуальность", поискать разумный баланс.
Недавно пришлось копаться в коде, строго следующим принципам чистого кода - малюсенькие функции и классы по 2-3-4 строчки, раскинутые по тысячам файлов... Я задолбался скакать по десяткам функций и файлов, чтобы просто детально понять, что делает интересующая меня функция.
Да, это очень сильно мешает. Кроме того, это может повлечь за собой излишнее количество зависимостей что тоже несет в себе определенные риски. Кто-то что-то поменял в одном месте, и в совершенно другом все разъезжается. И пока найдешь причину можно кукухой поехать. Особенно это касается очень больших систем с огромным количеством взаимосвязей.

mclander
11.09.2023 10:01-1Есть одно правило чистого кода - не оптимизируй то, что и так работает быстро )
И вывод из него: не парься что люди не поймут твой код с оптимизациями - они его просто скопипастят, если что.
PS. Собеседовал на сеньора товарища, который округлил по модулю в JS не Math.floor(i / n), не (i - i % n) / n, а 1.0 * `${i/n}`.split('.').shift()
А вы математические вычисления, математические вычисления...

zuart
11.09.2023 10:01+1А если кому то код нужно будет немного изменить под свои цели, то это исключительно его геморой (проблемы индейцев шерифа не колышат).

Azizbek_PhD Автор
11.09.2023 10:01Ой кошмар ????????????
Ну, хотя бы, задокументировать особо сложные случаи, думаю, нужно. Видел недавно питоновский генератор на сервере, работавший быстрее предыдущих реализаций. Профессиональный питонист после увиденного обвинил автора в употреблении наркотических веществ)))) Ясное дело, что с редактированием при надобности будет худо
Пример упомянутого товарища с экспоненциальной записью уже барахлит, к слову)

Guul
11.09.2023 10:01+5Представил Qt где QWidget имеет вот такенный switch на обработку отрисовки, клика, тд. И никакого полиморфизма. И что если мы хотим добавить свой виджет - лезим в исходники и перекомпилируем весь Qt.
Блеванул.


W_Lander
11.09.2023 10:01+1Вопрос, что дешевле: медленное, но хорошо поддерживаемое ПО из "готовых кирпичей" плюс дорогое железо или команда разрабов, знающих от особенностей архитектуры железа, алгоритмов оптимизации, профилирования, внутренностей компилятора до высокоуровневых фреймворков и архитектуры ПО, которые вам будут точить и сопровождать специализированный код? Конечно, второй вариант вам может сэкономить сотни млн, а в случае больших ЦОД млрд. Но проблема в том, что, в большинстве случаев вы просто не соберете такие команды, а если по сусекам пометете и соберете, то в перспективе потеря узких спецов обернется катастрофой.
SpiderEkb
11.09.2023 10:01+1Здесь вопрос еще стоит так - сэкономить или потерять?
Скажем, в некой высоконагруженной системе, произошел всплеск нагрузки. И "медленное, но хорошо поддерживаемое ПО из "готовых кирпичей", встало колом, даже несмотря на "дорогое железо". И вы внезапно для себя начали нести вполне осязаемые финансовые потери (хорошо если просто финансовые, без всяких трешей и апокалипсисов).
И тогда ситуация разворачивается для вас так - или вы таки ищете соответствующую команду, или теряете в деньгах. Тут уже вопрос не об экономии, а о том, как бы в минус не уйти.
Ndochp
11.09.2023 10:01+2У вас что в лоб, что по лбу система будет крутиться на железе с запасом производительности Х. И если влетит норма + 2Х то система встанет колом.
Сумеете вы ее отмасштабировать быстрее если это плотноупакованная быстрая лапша, или медленные понятные кубики — большой вопрос.
Хотя есть немаленький шанс, что для выхода из ступора системы на кубиках нужно будет докинуть железа в конкретный кубик, а не срочно искать в полтора раза более мощную железяку.SpiderEkb
11.09.2023 10:01У вас что в лоб, что по лбу система будет крутиться на железе с запасом производительности Х. И если влетит норма + 2Х то система встанет колом.
Простой пример. Есть некоторая задача, изначально рассчитанная на нагрузку N. Время идет, количество клиентов растет. Нагрузка увеличивается. И в какой-то момент время выполнения задачи выходит за допустимые рамки. Побежите за новым железом за $100500k? Или таки посмотрите внимательно - можно ли что-то улучшить в производительности софта?
Почему вы считаете, что быстрый код - обязательно лапша? Вот на каких основаниях? Просто другого не видели? Быстрый код может быть вполне изящным и понятным. Просто там будет 1-2 уровня абстракции, а на 10-15. Плюс там будут оптимальные, с учетом специфики обрабатываемых данных, алгоритмы, а не то, что там в фреймворке "на все случаи жизни".
Ndochp
11.09.2023 10:01Или таки посмотрите внимательно — можно ли что-то улучшить в производительности софта?
А вы что будете делать, если сразу писали производительно? У меня хоть запас есть :)

dmitrii-bu
11.09.2023 10:01+2Понятие «чистый код» довольно субъективно и каждый определяет правила написания «чистого кода» у себя на проекте (в компании) сам. За 10 лет в разработке видел диаметрально противоположные подходы которые декларировались как «хорошие практики» написания кода и, соответсвенно, форсились на код ревью. От разработчиков, приходящих в компанию требовалось следование этим практикам. Приведу ряд реальных примеров с которыми столкнулся в реальных проектах сам. Не сказать чтобы я был с ними согласен, но тем не менее от разработчиков требовалось их соблюдение: «Мы не пишем явно try-catch, потому что это слишком низкоуровневая конструкция, вместо этого нужно использовать нашу «масштабируемую» обертку», «мы не используем принцип dependency injection, потомучто они добавляют сложность в проект и усложняет масштабирование», «мы используем Java stream API для повышения читаемости кода», «мы не используем Java stream API для повышения читаемости кода» и т.д.
zuart
11.09.2023 10:01+3Легко на простейших вещах и примерах разносить в пух и прах примеры, которые сокращены просто для понимания.
А если взять не классы фигур с простейшими операциями, а серьезные блоки кода со своей очень разной логикой, то эти свичи вдруг становятся неимоверно геморным вариантом. А добавление нового модуля вырастает в лотерейку "сломается/не сломается", тогда как добавление нового модуля и его присоединение тривиальная и надёжная процедура.
Не нужно впадать в крайности и преподносить специально упрощённые примеры для разгрома - выглядит так себе.
aegoroff
11.09.2023 10:01+4ну да, это по сути микробенчмаркинг и от такого вреда (за пропаганду плохого стиля) больше чем пользы, такое сработает разве что в действительно нагруженном игровом движке или например в коде брутфорса тех же паролей и то после того как профайлер покажет узкое место.


Algrinn
11.09.2023 10:01Да, для оптимизации скорости приходится отказываться от красивых и популярных решений. Собирать гоночный болид, это не тоже самое, что собирать легковушку. Но если не стоит задача собрать гоночный болид, то нужно применять красивые и популярные методы и инструменты.

LifeKILLED
11.09.2023 10:01Автор сам себя дискредитировал тем, что пошел кодить критичную к производительности задачу совершенно не подходящим для этого способом. Там не только switch и c-стайл, но и ассемблер будет не лишним.
А чистый код это больше высокоуровневая архитектура и вот это вот все. Какие-нибудь сервисы, общающиеся с 1000 других сервисов. И это происходит в вэбе, в котором такие задержки, что выигрыш в паре тактов процессора вообще не принесет пользы.

Inoutcomer
11.09.2023 10:01Чистый код это не про производительность. Это про то, что ты будешь делать, когда в него потребуется вносить существенные изменения, сколько у тебя займёт это времени и сколько после этого сломается.
brick_btv
У автора оригинала проф-деформация. Чистый код это не пособие по производительности кода, это пособие по производительности разработчиков.
Если коду нужно не только считать математику, а ходить по сети, или работать с диском (читай спать в ожидании ввода-вывода), то никакие отказы от чистого кода скорость не улучшат.
Аргументы про оптимизации компилятора тоже мимо - методы чистого кода применимы не только к компилируемым языкам.
vadimr
Практически наверняка операции ввода-вывода в абстрактном коде тоже будут спланированы неоптимально. Так, совершенно необязательно спать в ожидании ввода-вывода, а можно параллельно выполнять другой ввод-вывод или другие вычисления.
ksbes
Ну так для этого существует асинхронный чистый код, который переписывать "в ручную" - точно умрёшь в жутких багах.
vadimr
Асинхронный код требует асинхронных вызовов, что уже неважно соотносится с принципом инкапсуляции. Даже банальное скользящее окно не соответствует принципу инкапсуляции передачи пакетов.
ksbes
Вы точно знаете как устроены асинхронные фреймворки? Ну там все эти корутины, промисы и т.д.? Или вы про уровень ассемблера говорите?
vadimr
Я говорю про то, что использовать асинхронный фреймворк – это сам по себе уже отход от тех принципов “чистого кода”, которые критикуются в статье.
lair
Почему?
vadimr
Потому что предположения о внутреннем устройстве объектов нарушают принцип инкапсуляции. Что это за рассуждения про “ожидание ввода-вывода”, если существует только вызов метода, за которым неважно что скрывается?
lair
А откуда вы взяли "предположения о внутреннем устройстве объектов"? Речь идет исключительно о внешнем контракте.
Ну так и не важно, что скрывается за вызовом метода, если метод по контракту асинхронный. Главное, на этапе проектирования все-таки разделить синхронные и асинхронные операции.
vadimr
Когда вы захотите спроектировать последовательность асинхронных вызовов в вашей программы таким образом, чтобы они максимально перекрывались и максимально сокращали таким образом общее время выполнения (а не просто в случайный момент дёргать асинхронный вызов), вам придётся рассматривать внутреннее устройство этих вызовов буквально вплоть до ассемблера. Другое дело, нужно это или не нужно в конкретном случае. Но вопрос выше был поставлен принципиально: “никакие отказы от чистого кода скорость не улучшат”.
lair
Подождите, я ничего не говорил про "максимально перекрывающиеся вызовы". Я спрашивал про конкретное утверждение "использовать асинхронный фреймворк – это сам по себе уже отход от тех принципов “чистого кода”, которые критикуются в статье".
Вполне очевидно, что максимальная производительность требует нарушения инкапсуляции. Но к моему вопросу это отношения не имеет.
vadimr
Давайте тогда разберёмся, зачем нужен асинхронный фреймворк в чисто синхронной по построению модели ООП?
lair
Ты перестала пить коньяк по утрам?"Модель ООП" не является чисто синхронной, так что этот вопрос не имеет смысла.
ksbes
В каком месте ООП "чисто синхронна"? Особенно в её первозданном виде, а-ля Erlang, когда все объекты сообщениями обмениваются, а не методы тягают?
vadimr
Я не знаю, как это работает в Эрланге, но в классическом Смоллтоке сообщение вполне синхронно посылается объекту и вырабатывает результат. Вся последовательность сообщений упорядочена.
Но евангелисты “чистого кода”, внезапно, в ста случаях из ста продвигают не Эрланг и не Смоллток, а процедурные языки с объектными расширениями, как в статье выше. С совершенно синхронными операциями над объектами.
Собственно, если разобраться, само понятие состояния объекта подразумевает синхронность.
ksbes
Вам точно полезно будет ознакомится с хотя бы как это С# работает. Или в javascript. Да и вообще c корутинами
Операции над объектами могут быть очень не синхронными.
vadimr
Я знаю, что такое корутины и асинхронное программирование. Но это не имеет отношения к модели ООП. Это вы взяли асинхронные процессы и стали пытаться с их помощью обрабатывать объекты (внезапно, синхронизируя их при этом с помощью всяких await; чего асинхронные модели – такие, как, например, функциональное программирование – не требуют).
Aquahawk
функциональное программирование ровно как и ООП ничего не требуют в плане синхронности или асинхронности.
vadimr
Функциональное программирование не требует, а ООП требует. Изменения состояния объекта должны быть синхронизированы. А для этого вызовы его методов и тем более конструкция-деструкция должны быть сериализованы.
lair
Про модель акторов слышали? Они одновременно асинхронны и (могут быть) полностью сериализованы. Снова благодаря message passing.
vadimr
Так после того, как они сериализованы, они перестают быть асинхронными. А до того не укладываются в модель ООП.
Message passing сам по себе – это просто механизм взаимодействия.
lair
Это почему? Каким определением асинхронии вы пользуетесь?
Вот что думает по этому поводу википедия:
То, что программа внутри себя обрабатывает внешние события последовательно, не делает ни взаимодействие с ней, ни сами эти события, синхронными.
vadimr
Ну вот с первого попавшегося сайта определение:
Текст из википедии вообще мало что объясняет, на мой взгляд, так как непонятно, что такое main program flow. Но вообще-то википедия пытается сказать то же самое.
События асинхронны друг относительно друга, когда их взаимный порядок может быть любым. А асинхронное программирование – это такой способ организации кода, при котором асинхронные события фактически обрабатываются в произвольном порядке.
Например, когда вы в фукциональном программировании применяете функцию высшего порядка map к какой-нибудь структуре данных и операции над ней, то операции над отдельными элементами данных выполняются асинхронно. Может сначала тысячный элемент обработаться, потом восьмидесятый, потом первый и т.д. Могут одновременно, если несколько процессоров. И результат от этого не изменится. А если у вас вместо этого итеративный цикл написан, то он выполняется синхронно, от первого к последнему.
Так же и в вашем примере с документом, событие окончания его обработки не может возникнуть до события начала обработки, и поэтому тут всё синхронно.
lair
Вот только в дискусси выше используется не асинхрония событий, а асинхрония операций. И несколько разных операций в асинхронной программе могут иметь произвольный порядок относительно друг друга.
Это не то определение асинхронии, которое использую я (и, думаю, все остальные ваши оппоненты) в этом обсуждении.
vadimr
Конечно. Но нам это ничего не даёт в содержательном плане, покуда эти операции не привязаны к разным событиям.
Очень часто споры, если разобраться, оказываются спорами об определениях. Тут нечего возразить.
lair
Тогда возможно, прежде, чем говорить, что "использовать асинхронный фреймворк – это [...]", неплохо бы понять, что же люди понимают под асинхронным фреймворком.
vadimr
Да фреймворк-то сам по себе - это просто способ организации кода.
Кстати, ещё хорошая мысль пришла на ум. Область, где много истинно асинхронных процессов - это РСУБД. И обратите внимание, что там сериализация в принципе возможна только на самом старшем уровне изоляции Serializable, который чрезвычайно редко используется ввиду крайней неэффективности. А на обычных уровнях изоляции у таблиц просто нет мгновенного состояния в логическом смысле.
lair
...зависит от того, как много вы вкладываете в "организация кода". А то весь .net - это framework.
"Асинхронных" в вашем понимании.
vadimr
Не имеет смысла спорить о терминах, когда проблема обозначена по существу.
А проблема состоит в том, что ООП из-за привязки к состоянию объекта требует сериализации.
lair
Во-первых, не обязательно требует.
Во-вторых, почему это проблема?
vadimr
Потому что не все алгоритмы эффективно сериализуемы. С этого же начали.
lair
Из того, что не все алгоритмы эффективно сериализуемы, никак не вытекает, что ООП всегда требует сериализации.
Поэтому я продолжаю не понимать, где проблема.
funca
Исторически, куча паттернов в ООП пришла из языков типа c++/java/object pascal - где асинхронщина изначально отсутствовала. Но современное состояние уже другое. Сейчас ни что не мешает писать асинхронный код на тех же принципах, используя все фишки ООП.
vadimr
Давайте проясним, о чём мы вообще говорим. Никто не спорит, что можно писать асинхронные программы, используя синтаксические механизмы ООП (фишки).
Но принцип ООП, как модели реализации вычислительного процесса, подразумевает синхронизм операций, выполняемых над объектом. Было у объекта состояние S1, выполнился метод (обработалось сообщение) M1, стало состояние S2. Дальше метод M2 и состояние S3. А если у вас методы выполняются параллельно и независимо друг от друга (т.е. асинхронно) и вследствие этого объект не имеет определённого состояния, то это, с точки зрения модели, не объект, а просто реализация пакета с функциями. Хотя вы вольны написать слово class в его описании.
lair
Почему не имеет-то? Он вполне себе может иметь состояние. Оно даже может меняться.
Чтобы быть асинхронным, метод не обязан ни от чего вообще не зависеть.
vadimr
Может иметь, а может и не иметь. Когда у вас параллельно выполняется несколько неатомарных методов, то состояния в общем случае можно расшить только сериализацией.
Чтобы далеко не ходить, можно взять примеры прямо из статьи наверху, которые полны race conditions при асинхронном выполнении. Там всё надо обвешивать семафорами, чтобы такие вещи:
на самом деле работали. А семафор – это и есть синхронизатор.
lair
В общем случае - да. Но в конкретных реализациях - не обязательно. Поэтому не "принцип ООП [...] подразумевает синхронизм операций, выполняемых над объектом.", а "иногда объекты могут нуждаться в синхронизации".
Вот только семафор, как и любой другой примитив синхронизации, в этом случае будет внутренней деталью реализации объекта.
vadimr
Хотите – внутренней, хотите – внешней, какая разница. Итог один – сериализация.
Пустой объект, например, точно ни в чём не нуждается.
lair
Принципиальная. Инкапсуляция же.
Если для пользователя операции асинхронны, то они асинхронны, а как система этого добилась - не очень важно.
Мне кажется, что вы обсуждаете какую-то проблему, которая существует только внутри вашего собственного терминологического поля, то есть только для ваших определений ООП и асинхронии.
ksbes
Ну вот у меня объект: Example{ private Atomic a ; private Atomic b ....} (псевдокод, если что). Его соcтояние (a b) сколь угодно асинхронно, по любому определению, никак не нарушая принципов ООП и не требуя никакой сериализации.
Я такое вполне себе писал на микроконтролёрах - там, как вы понимаете асинхронностью можно хоть с головой обмазаться. Но ООП (при желании его там использовать) это вообще никак не мешает.
sophist
Спорить о терминах не имеет смысла потому, что любое определение -- лишь способ упростить высказывание, заменив длинную формулировку коротким термином. Само по себе определение не содержит новой информации, это чисто технический приём.
Поэтому вместо спора о том, каково "истинное" содержание используемого термина, следует просто явно декларировать: "В контексте последующего высказывания (читай: обозначения проблемы по существу) я буду использовать термин <термин> в значении <формулировка>". И дальше строго придерживаться этой декларации.
В таком случае не будет иметь значения, что ваш оппонент привык называть этим термином что-то другое; не будет иметь значения даже, что есть какая-то общепринятая формулировка, отличная от вашей, -- фактически, вы просто при каждом упоминании термина неявно добавляете к нему "в том значении, которое я определил выше".
Само собой разумеется, что и ваш оппонент может сделать то же самое -- дать определение термину в контексте своего высказывания. В том числе, тому же самому термину -- здесь важно только чётко отделять, в каком именно (в чьем именно) значении термин употребляется в каждом конкретном случае. (Ясно, что таких проблем можно избежать, не используя один и тот же термин в разных смыслах, но тут уже дело вкуса).
vadimr
Кстати, чем в вашем понимании асинхронное выполнение отличается от параллельного?
lair
Параллельное идет параллельно, то есть две задачи выполняются одновременно. Асинхронное - когда угодно.
lair
В C#
await- это синтаксический сахар над моделью task (promise), которая, в свою очередь, ОО-обертка вокруг continuation passing, который в функциональном программировании как раз и используется.Сам по себе
await- это процедурный синтаксис, не объектный.vadimr
Вы правильно излагаете факты, но continuation passing не является существенной частью модели функционального программирования, а является как раз необязательной надстройкой для синхронизации вычислений.
lair
Я начинаю думать, что вы под синхронизацией понимаете что-то свое.
lair
Дадада. Сначала объект А шлет объекту Б сообщение "распознай мне вот этот документ", получая синхронный ответ "начал распознавание", а потом объект Б шлет объекту А сообщение "вот тебе результат распознавания", а тот синхронно отвечает "спасибо". Вот вам и асинхрония. Собственно, message passing для нее прекрасно подходит.
Каким образом?
vadimr
Во-первых, вы тут несколько подменяете понятия. В первом случае сообщение нужно назвать не “распознай документ”, а “начни распознавание документа”.
Во-вторых, в вашем примере код выполняется возможно и параллельно, но синхронно (многие, кстати, путают эти понятия). Сообщение “вот тебе результат распознавания” всегда приходит после сообщения “начал распознавание”. Тут нет никакой возможной последовательности событий, кроме той, которую вы же и описали в цитате.
На этот вопрос я уже ответил выше.
lair
Нет такого требования нигде.
Что вы понимаете под "синхронно" в этом случае? Для меня "синхронно" - это когда вызывающий код (объект А) принципиально не может выполнять никаких действий, пока операция (в данном случае - распознавание документа) не завершена. В этом случае операция синхронна.
vadimr
То, что вы написали – это последовательное выполнение процессов. А синхронное – это когда точки взаимодействия однозначно упорядочены во времени. Первое подразумевает второе, но не наоборот.
lair
Откуда вы берете это определение?
iburanguloff
То что писали выше - как раз и есть синхронность - передача управления вызываемой сущности и блокировка работы до возврата управления этой сущностью
vadimr
В случае блокировки, конечно, всё синхронно. Но это не единственный способ достичь синхронности. Когда у вас правое колесо паровоза едет по правой рельсе, а левое – по левой, то они едут синхронно, хотя не блокируют работу друг друга.
(Хотя, насколько я понял терминологию @lair,блокируемый код кооперативной многозадачности в стиле Windows 2.0 является асинхронным в его понимании).
lair
Я пониятия не имею, как была устроена кооперативная многозадачность в Windows 2.0, поэтому никак не могу прокомментировать это.
vadimr
Как корутины по сути. Блокируясь на любой передаче управления.
lair
Тогда нет, в моем понимании этот код не обязательно является асинхронным. Точнее сказать без конкретного примера я не могу.
zaiats_2k
Колёсная пара — элемент ходовой части рельсовых транспортных средств, представляющий собой пару колёс, жёстко посаженных на ось и всегда вращающихся вместе с осью как единое целое
vadimr
Значит, пример не очень хороший. Но суть, думаю, ясна.
Тем не менее, правое и левое колесо оба одновременно едут по своим рельсам.
lair
Если мы говорим о колесной паре конкретно, то они как раз друг друга блокируют - если вы каким-то образом остановите одно колесо, остановится и другое.
funca
Если Message Passing это OOP, тогда давайте уж и Kafka с RabbitMQ считать обектно-ориентированными. Ну может не буквально, а в смысле что у них такая вот ориентация. ;)
breninsul
так у вас максимум тип враппеоа будет типа Future<MyClass>, а то и просто отметка syspended на функции. Все прозрачно и нет никакого нарушения инкапсуляции
V1RuS
Если речь не про абстрактный чистый код, а про книгу "Clean Code", то это, как бы помягче сказать, довольно хреновое пособие.
sva89
Критика книги от чувака, который даже не осилил нормальную разметку страницы сделать, прекрасно!
Hidden text
TIEugene
Я бы "производительность разработчика" расширил до "availability продукта" (термин availability переводить не буду, взято из сисадминства).
Что включает в себя:
- производительность разработчиков
- производительность техподдержки
- документируемость, модифицируемость, понимабельность, тысячи их
yarston
Для задач вроде "поработать с сетью и диском" есть бенчмарки, которые расставляют всё по своим местам. Конечно, задача синтетическая, на реальных задачах наверно всё не так плохо будет, но вот например икона чистого кода в лице Spring там показывает производительность 3.6% от топового решения. Вряд ли такое может пройти незамеченным для производительности.
AlexSkvortsov
Серьезно? Бенчмарк фреймворков для работы с сетью и ORM на таблице с 12 строками (~2 Кб)?
Это не просто синтетическая задача, это как производительность алгоритмов сортировки на массивах в 12 ячеек мерять, абсурдно бессмысленно
breninsul
не совсем так, введение иерархии классов в примитивных вещах, не имеющих отношений к бизнес процессам ни к какой скорости не приведет, только к запутыванию. Везде есть трейдофы, радикализм не ведет к счастью