Привет, Хабр! Меня зовут Аня, и я работаю ручным тестировщиком мобильных приложений (далее – МП) в компании Tele2. В ходе работы я тестирую наше внутреннее МП «На связи». Более подробно о нём писала моя коллега тут. В этой статье я подробно опишу процесс тестирования, который провожу из спринта в спринт, а также свой опыт, полученный в ходе этого тестирования. Статья носит ознакомительный характер и подойдет новичкам в профессии, а также тем, кто интересуется процессом проверки мобильных приложений.
«На связи» создаётся как карманный помощник в работе, а в чём-то даже и замена веб-сервисов. Чтобы нашим коллегам было удобно пользоваться сервисами, не включая рабочий компьютер, мы каждый день улучшаем старую и добавляем новую функциональность. Требуется срочно узнать номер коллеги или оформить командировку, находясь вдали от рабочего компьютера? Легко! Наше приложение может и не такое. Отправка рабочих заявок, генерация заявлений и их подписание с помощью электронно-цифровой подписи (ЭЦП), справочник сотрудников, календарь отпусков и командировок команды, настраиваемый дашборд и многое другое входит в наше приложение. Есть даже фичи, которых нет на корпоративном портале, но есть в нашем МП. Поэтому объём тестирования довольно большой и с каждым релизом становится всё больше.
Как тестирование происходит у нас
Перейдём к самому интересному – процессу тестирования. Как я уже сказала, приложение довольно объёмное и многофункциональное, поэтому и тестирование назвать тривиальным и однообразным нельзя.
Каждый процесс тестирования начинается с прочтения документации или технического задания (ТЗ) и написания тестовых сценариев. Для меня в начале карьеры был необычен тот факт, что сценарии пишутся на ранних этапах задолго до технической реализации или, например, без готовых дизайн-макетов. Поэтому, когда есть уже готовый дизайн – это круто! Написание сценариев в таком случае сильно облегчается, а также сразу становится полноценным – поскольку есть дизайн, то можно учесть узкие фронтовые моменты и написать по ним тестовые сценарии. Но и написание сценариев исключительно по ТЗ не становится проблемой, когда в твоей команде работает классный аналитик.
После написания сценариев, проходит непосредственно само тестирование. В нашей команде нет разделения на тестировщиков backend’а и frontend’а, поэтому мы работаем все вместе. Процесс тестирования трудоёмкий и разносторонний – мы проходим несколько типов тестирования, используем разные техники тест-дизайна. В связи с расширением и улучшением функциональности новые релизы выходят часто, и общий план тестирования можно описать с помощью следующей схемы:
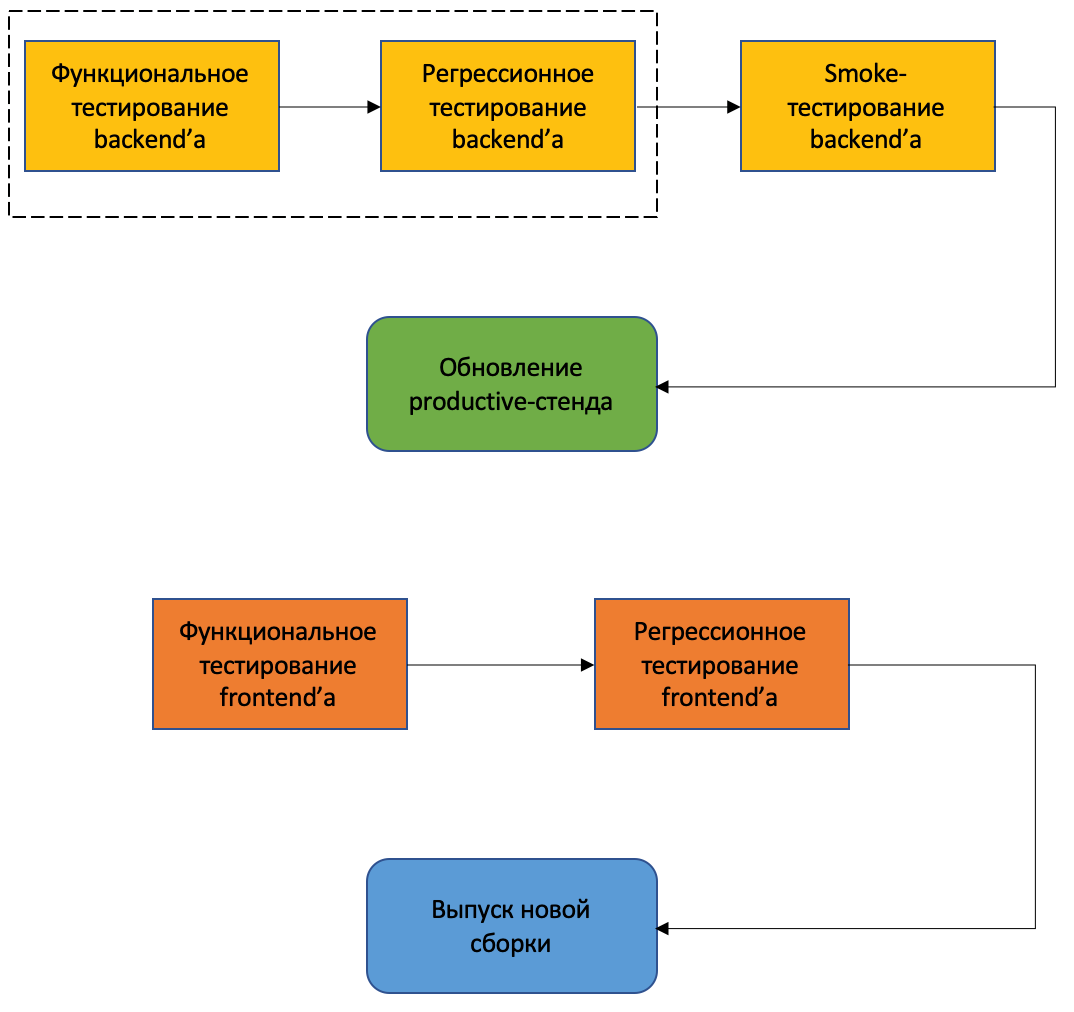
Релиз начинается с проверки backend’а и включает в себя:
функциональное тестирование новых разработок;
регрессионное тестирование;
smoke-тестирование.
На схеме я обвела функциональное и регрессионное тестирование потому, что проверка новой функциональности довольно часто проходит совместно с регрессом. Это не значит, что функциональное тестирование не проводится совсем. Как раз наоборот — перед прохождением регрессионных сценариев выполняется тестирование новых задач. Кратко говоря, в данном случае нет разбиения на отдельные итерации. В нашей команде время выполнения задач вычисляется часами, хотя мы задумывались о переходе на сторипоинты. Буда рада, если вы напишете в комментариях, как это работает у вас в компании и насколько эффективно. Может быть, кто-то переходил с часов на сторипоинты и может рассказать о процессе и каких-то подводных камнях.
Ниже я хочу более подробно описать процесс тестирования, возможно, для новичков это послужит неким чек-листом.
Функциональное тестирование
Функциональное тестирование предусматривает проверки новой функциональности. Как я говорила выше, часто мы совмещаем это тестирование с регрессом. И тут важно отметить, что несмотря на экономию времени (два тестирования проводятся одновременно), у такой практики есть много нюансов, и трудозатраты специалистов растут. Чаще всего функциональное тестирование backend’a проводится на МП, то есть на реальном устройстве. Таким образом проверяется как backend, так и frontend. Однако, бывает так, что функциональность frontend’а ещё не готова, а проверить backend нужно. Здесь на помощь приходит известный всем тестировщикам Postman, с помощью которого можно прогнать методы API.
Postman позволяет проверить работоспособность функций через запросы методов API. Например, разработчик создал функциональность справочника сотрудников. Нужно проверить, что МП выдаст результаты, например, по запросу ФИО. Для этого и нужен Postman – достаточно написать метод, URL, header’ы и параметры (фильтры, тело запроса, если нужны) и проверить, что результат соответствует требованиям.
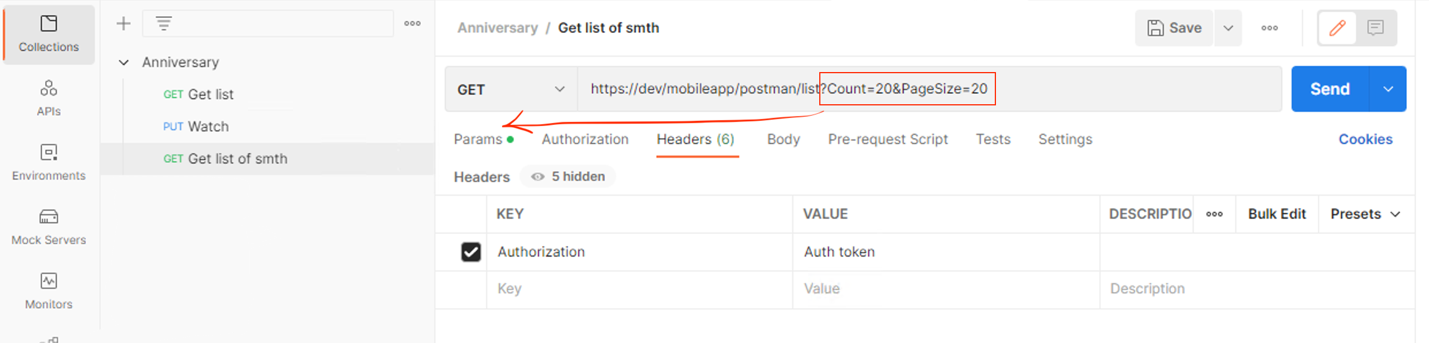
Хочу заострить внимание на том, что нужно тщательно прописывать запрос, а также параметры и тело запроса. В начале карьеры мне потребовалось какое-то время, чтобы приспособиться к работе Postman’а. Сложности могут возникнуть в, казалось бы, очень тривиальных местах, таких как написание query-параметров (обвела на рисунке), которые не всегда обязательны.
Так же в работе мы используем Swagger. Его функциональность меньше, чем у Postman’a, но в этом есть и свои преимущества. Он так же, как и Postman позволяет проверять методы API, но пользоваться им попроще. Я бы рекомендовала новичкам использовать именно его, так как он в разы облегчает написание запросов.
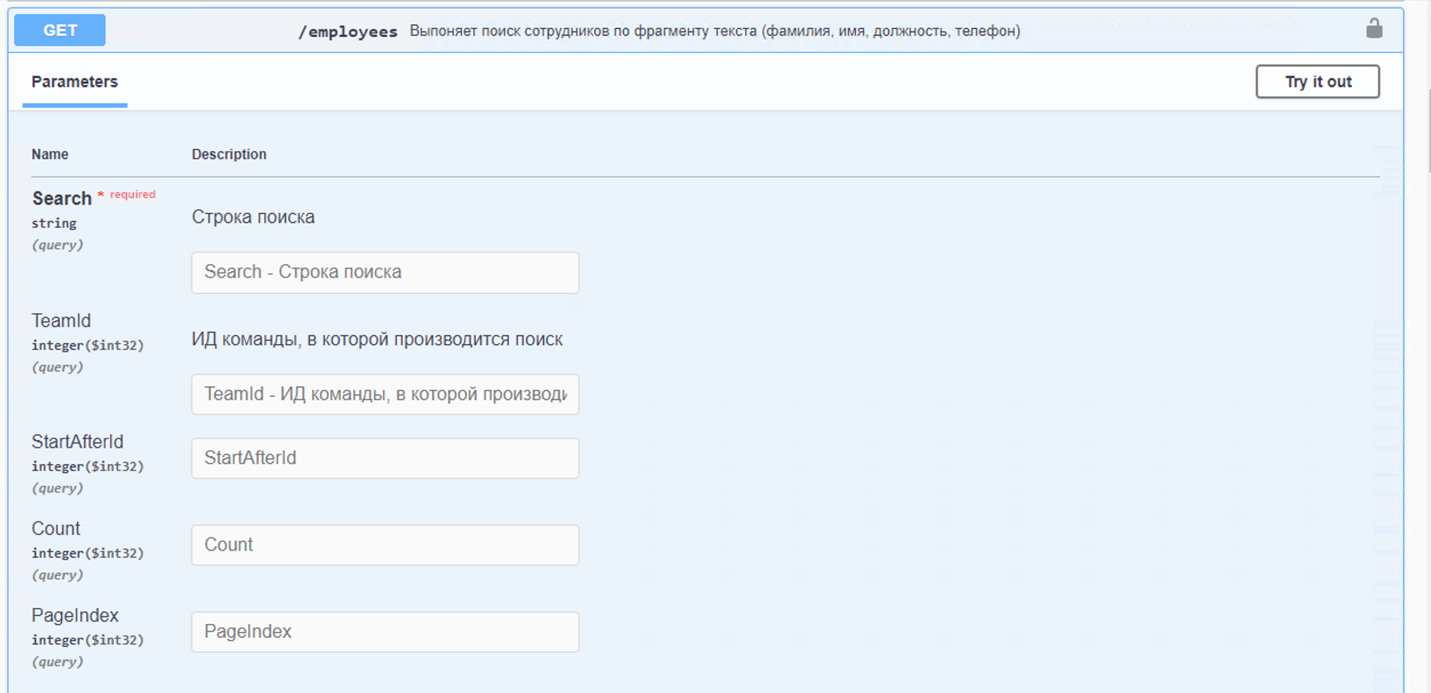
Как видно из картинки, запрос уже прописан, а параметры можно не вбивать вручную, а выбрать те, которые нужны. Для начинающих специалистов, не имеющих опыта работы с Postman’ом, Swagger – настоящая выручалка. После работы на нём прописывать запросы самостоятельно не составит труда. Просите своих backend-разработчиков добавить Swagger, если у вас его ещё нет.
Регрессионное тестирование
Регрессионное тестирование проходит каждые 2 недели, так как каждый спринт мы обновляем production стенд (далее – прод). Кто-то может сказать, что это очень часто, но на это есть свои причины. «На связи» — очень динамичное мобильное приложение, и, поскольку мы работаем по методологии Scrum, новая функциональность появляется быстро. Каждый спринт создаётся новая фича или происходит доработка существующих функций. Если регрессионное тестирование проводить редко, то объём проверки увеличится, как и количество ошибок (это было уже проверено на практике). Поэтому всей командой было решено обновлять прод каждый спринт.
Тестирование проводится на пуле регрессионных сценариев, описывающих критически важную функциональность для проверки. С каждым выходом новой фичи сценарии пополняются, соответственно увеличивается и время тестирования. Во время регресса я также пользуюсь Postman’ом, но основные проверки проходят в МП. На этом использование программ не заканчивается. Во время тестирования очень часто приходится имитировать разные случаи, скажем, сделать себя руководителем или установить себе день рождения на текущую дату. Тут на помощь приходит база данных, где можно изменять данные, как душе угодно. Уточню, что все изменения в рамках тестирования проводятся исключительно на тестовой базе данных, никакого влияния на прод нет. В моей работе достаточно использовать простые запросы, типа SELECT, UPDATE и т.д.
Умение запускать даже простые запросы очень полезно, так как база данных может использоваться для сбора статистики. Может случиться так, что для имитации бага потребуется выборка по какому-то признаку, или к вам может прийти коллега с запросом по данным из базы для презентации. Из недавнего: нужно было получить список не удаленных из базы сотрудников с определённой локацией. Тут достаточно отфильтровать данные по нескольким полям и выгрузить их в excel. Этот документ уже можно приложить к багу или отправить коллегам.
Говоря о базе данных, хочется посоветовать не привязываться к какой-то определенной системе. В своей практике я пользовалась такими инструментами как MS SQL Server Management и DBeaver. Обе программы имеют как преимущества, так и недостатки – например, в MS SQL Server Management довольно удобный интерфейс, а также синтаксис запросов, а DBeaver позволяет работать со множеством популярных СУБД. После MS SQL Server Management, DBeaver кажется слегка неудобным, но это дело привычки. Зато после того, как вы научитесь им пользоваться, будете спокойно писать и запускать скрипты, вы сможете пользоваться почти любой базой данных, и переход на новую будет не такой болезненный.

Smoke-тестирование
После того, как закончилось регрессионное тестирование, и прод обновлён, я приступаю к smoke-тестированию, которое подразумевает проверки критически важных функций уже на проде. Здесь я обычно пробегаюсь по важнейшей функциональности (например, проверяю авторизацию, поиск и т.д.), чтобы убедиться, что всё хорошо, и ничего не поломалось с переездом на прод. В идеале на данном этапе ошибок быть не должно, но что делать, если ошибки всё же нашлись? В таком случае нужно очень оперативно их исправить, чтобы влияние на пользователей было минимально. Во время smoke-тестировании я не использую никаких программ, достаточно скачать приложение из стора и выполнить нужные проверки.
Правила фиксации багов
Кстати об ошибках. Очень важно фиксировать баги на любых этапах тестирования. Баг-репорты нужно оформлять как можно тщательнее, чтобы для коллег из группы разработки описание было понятным и прозрачным, а исправление – корректным и быстрым. Давайте на своём примере чуть подробнее расскажу, что должен иметь хороший баг-репорт.
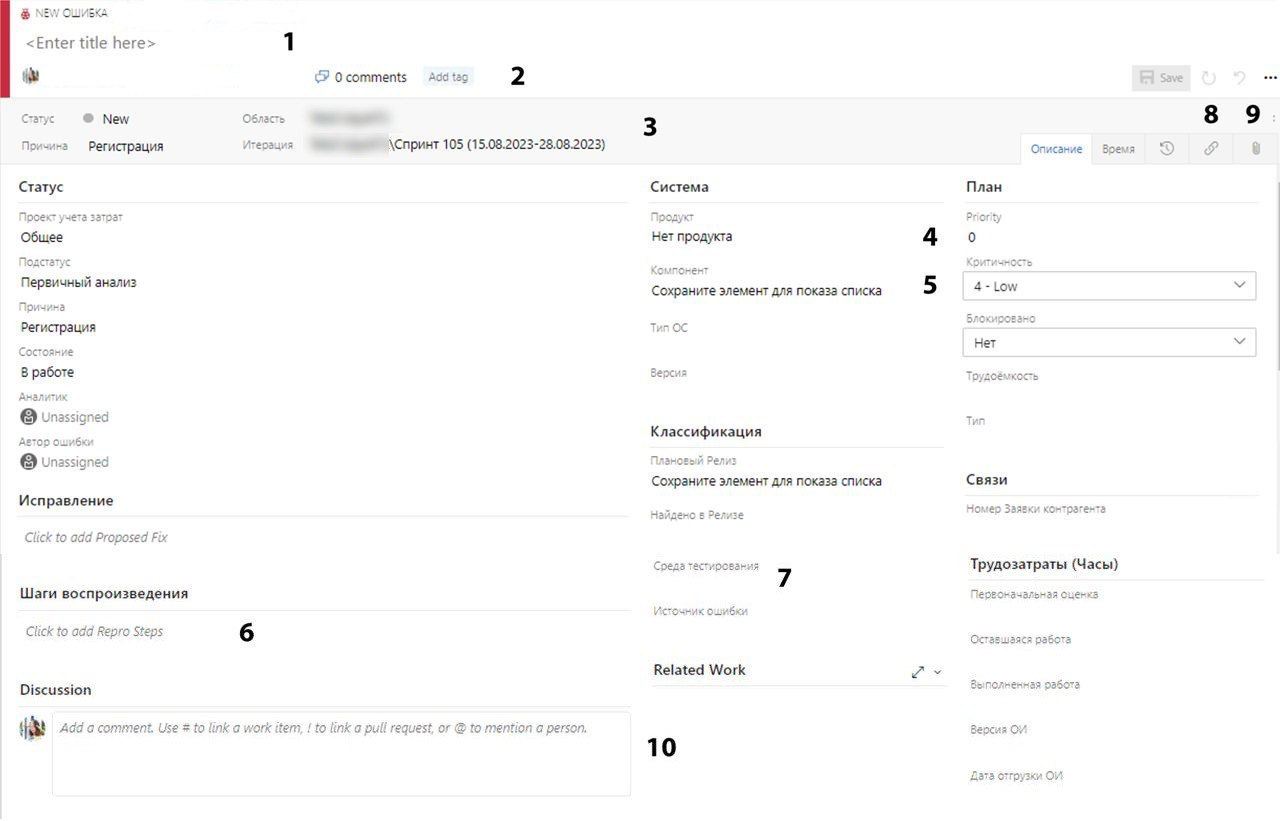
1 – Название. У некоторых бывают сложности и с названиями, поэтому скажу так – название должно передавать суть проблемы, кратко и понятно.
2 – Теги. Теги можно ставить любые, они нужны для понимания истории бага из списка задач, а также для сбора статистики. Сюда можно написать, например, «Frontend» или «Регресс».
3 – Область и Итерация. Да-да. Иногда закинешь баг в неправильный спринт и всё, его никто не увидит, и все забудут. Особенно это касается ситуаций, когда переводишь баг на другую команду.
4 – Приоритет. Приоритет влияет на скорость исправления. Баги с продуктива чаще всего приоритетные.
5 – Критичность (или Серьёзность). Параметр, отвечающий за влияние на функциональность. Вспомните, серьёзный и неприоритетный баг или наоборот?
6 – Шаги воспроизведения. Здесь нужно описать проблему целиком – шаги, ожидаемый и фактический результат, данные того, кто воспроизвёл баг, время, логи и т.д. Всё, что можно рассказать о баге для того, чтобы разработчик лучше понял ситуацию.
7 – Среда тестирования. Обязательно нужно указывать среду, на которой был найден баг, чтобы разработчик смог его найти, воспроизвести и пофиксить. К багам, обнаруженным на prod-стенде, нужно особое внимание.
8 – Ссылки. Если баг был найден в релизе или в процессе функционального тестирования определённой задачи, очень важно прикреплять ссылку на этот релиз или задачу к багу. Так будет проще их находить, а остальным членам команды понимать количество ошибок и их статус.
9 – Вложения. Для некоторых багов надо прикладывать фото или видео. Как правило это нужно делать для багов frontend’а.
10 – Комментарии. После того, как баг исправлен и проверен, желательно оставить запись о том, где была проведена проверка, и статус бага.
Можно также указывать и другие параметры – тип оси, версию. Но помните, нет ничего идеального! Лучше быстро завести понятный и лаконичный баг, чем полдня сидеть, скрупулезно заполняя все поля.
Ещё немного важных моментов
Ещё очень важно общаться с разработкой, порой им нужно давать более детальные комментарии для воспроизведения бага. Такая обратная связь позволяет быстро починить баг. Поэтому имейте в виду – soft-скиллы важны всем, даже технарям.
Ещё одним из важных факторов заполнения баг-репорта являются логи. Без логов достаточно трудно понять, что пошло не так. Любой тестировщик должен уметь читать логи, это сильно облегчит работу devops-инженеров!
Тут на помощь приходит ELK – ElasticSearch + Logstash + Kibana – система, позволяющая находить логи из разных сервисов и отображать их.

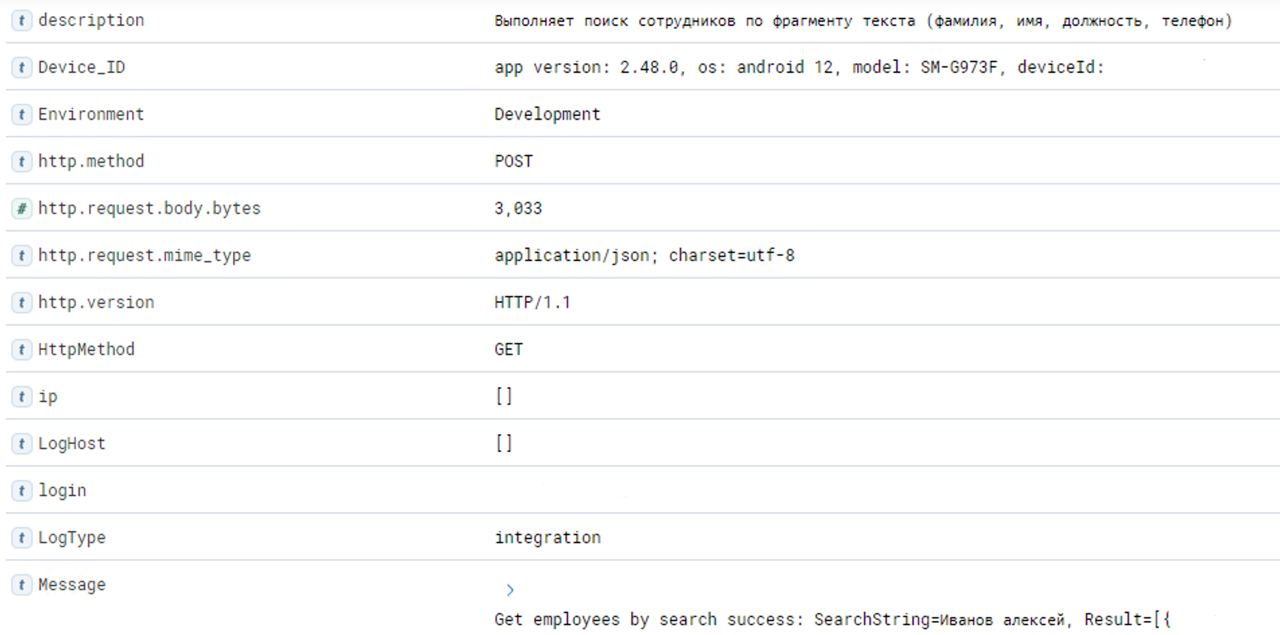
C помощью Kibana можно найти ошибки, возникшие при тестировании. Умение с ней работать – очень полезный навык, не пренебрегайте поиском логов. На картинке ниже, например, я выполнила поиск сотрудников, который выдал определённый результат. В логах указывается достаточно подробная информация, которая точно потребуется разработке при нахождении ошибки. Тренируйтесь искать логи на простеньких запросах, используйте фильтры. Постепенно это станет довольно увлекательно.
Стоит отметить, что логирование происходит только в том случае, когда backend-разработчики добавили эту возможность в коде. Так что просите разработку добавлять логи, это облегчит жизнь не только вам, но и devops-ам.
После того, как проведён smoke и новая версия на проде стабилизировалась, можно переходить к функциональному тестированию frontend’а. Обновление frontend’а МП, то есть выход новой сборки, обычно происходит примерно раз в месяц-полтора в зависимости от готовности нового функционала. Но бывает, что нужно срочно выпустить внеочередную сборку, в таком случае регресс frontend’а проходит чаще.
Если регрессионное тестирование backend’a проходит на тестовой среде, то функциональное тестирование frontend’а можно провести и на проде. В пределах разумного, конечно. Менять в БД данные на проде нельзя, поэтому какие-то проверки придётся оставить для тестовой среды. Тестирование frontend’а включает в себя:
функциональное тестирование новых разработок;
регрессионное тестирование.
Здесь практически всё то же самое, что и при тестировании backend’а, за исключением того, что отличаются тестовые сценарии. Когда идёт проверка frontend’а, нужно обращать внимание на разные мелкие детали наподобие шрифта или отступов. Проверка орфографии, кстати, тоже сюда входит.
Также, проверяя frontend, я всегда сравниваю готовую сборку с дизайн-макетами. Бывает так, что разработчик может упустить какой-либо момент. При сверке с макетами это будет сразу заметно, и не потребуется дёргать дизайнера для уточнения каких-то деталей. Хотя такое тоже случается.

Из личного опыта: имитируйте условия пользователя. Если появляется новая функциональность для определённой категории пользователей – ставьте себя на место этих пользователей. Если в определённых условиях должна появится кнопка – создайте эти условия. Иначе может получится так, что на проде в очень ответственный момент может не появится заветная кнопочка.
Автотестирование
А теперь немного об автотестировании. К счастью, в регрессионном тестировании нам помогают автотесты. Тесты на backend’е пишет мой коллега, использует при этом фреймворк xUnit. На текущий момент автоматизировано 65% от общего числа сценариев backend’а. Благодаря автотестам время регрессионного тестирования сокращается, а количество рутинных проверок для тестировщиков уменьшается. На самом деле это хорошая практика – автоматизировать регрессионные сценарии. Это сильно помогает ручным тестировщикам минимизировать затраты на часто повторяющиеся проверки и уделить больше внимания на функциональное тестирование. Автоматизация сейчас очень популярна, и к ней прибегают всё больше компаний.
Что касается автотестов на frontend’e, то текущее покрытие пока совсем небольшое, примерно 5-10%. Их пишут разработчики в свободное от приоритетных задач время. К сожалению, эти тесты часто падают, так как на фронте появляются новые фичи, например, онбординги (приветственный экран, ознакомление с новой функциональностью), которые требуют актуализации автотестов. У меня уже был опыт написания автотестов frontend’а на Detox’е, однако этот опыт я не могу назвать 100% успешным, поскольку на тот момент фреймворк был достаточно зелёным, автотесты работали нестабильно и долго, вследствие чего было решено отказаться от этой идеи. Однако сейчас из-за стремительного роста функциональности, регрессионное тестирование frontend’а стало занимать много времени. Именно поэтому решили вернуться к идее автотестов, но выбрали более проверенный фреймворк, а именно Appium. Буду рада, если вы напишите о своём опыте в автотестировании frontend’а и поделитесь полезными советами.
Планы на будущее
Также на текущий момент помимо ручного тестирования я занимаюсь нагрузочным с помощью Apache Jmeter. Этот инструмент помогает провести нагрузку на систему и найти слабые места функциональности, чтобы в будущем при увеличении нагрузки МП могло её выдержать. Опыта в этом у меня немного, но уже видны результаты. Назвать Jmeter удобным я, пожалуй, не могу, но в целом нагрузочное тестирование иногда бывает увлекательным. Достаточно интересно наблюдать, как работает наше приложение под высокой нагрузкой, находить узкие места, анализировать графики. Полноценно заниматься нагрузочным пока не представляется возможным в связи с регулярными релизами, но мы бы хотели внедрить его в качестве постоянного тестирования с какой-то периодичностью.
На этом я бы хотела закончить свою статью. Надеюсь, мой опыт сможет помочь новичкам в освоении профессии тестировщика. Удачи!
EduardSh
Хорошая статья для тех, кто хотел бы работать ручным тестировщиком. Наглядный пример того, чем будет заниматься человек.
Вы написали про то, как правильно фиксировать баги, можно было бы еще написать в таком же ключе про чек-листы и тест кейсы, отлично бы вписалось)