
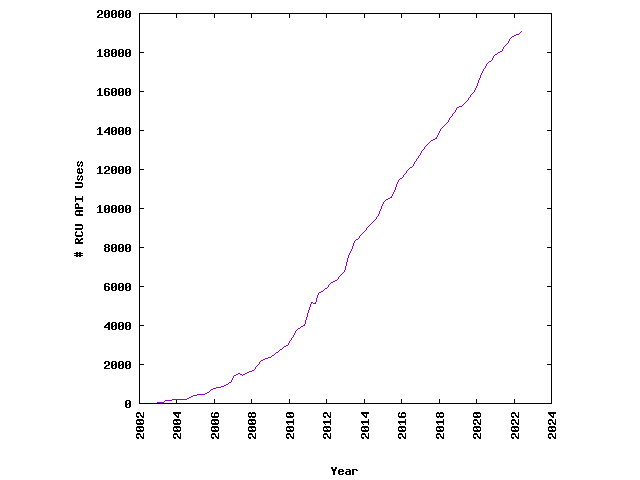
Давайте поговорим об одной из наиболее критичных по производительности программ, которой вы пользуетесь ежедневно: о вашей операционной системе. Поскольку при каждом разгоне железа вы получаете дополнительную вычислительную мощность, операционная система никогда за этим не поспевает. Поэтому постоянно доводится читать о том, как разработчики ядра и драйверов выжимают последнее из своего кода.
Кроме того, операционные системы должны быть рассчитаны на массовую конкурентность. Дело не только в том, что наша операционная система отвечает за планирование всех процессов и потоков пользовательского пространства, но и в том, что в ядре хватает собственных потоков, а также обработчиков прерываний, нужных для взаимодействия с железом. Требуется минимизировать время, которое тратится на ожидание, так как, опять же, при любой задержке вы воруете время ваших пользователей.
Объединим две эти цели – и обнаружим, сколько же существует странных и магических методов для неблокирующего совместного использования данных в разных потоках. Давайте поговорим об одном из этих методов – «чтение-копирование-запись» (RCU).
❯ RCU
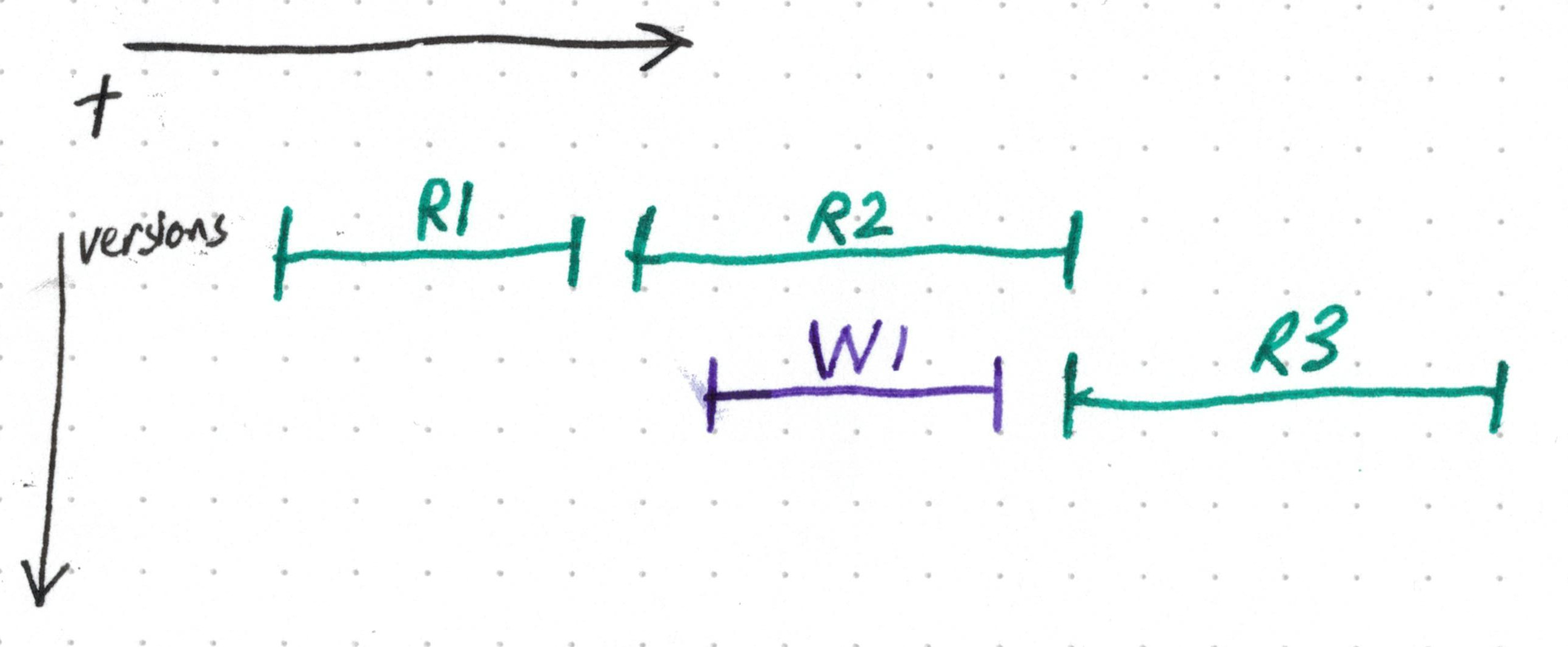
Допустим, у нас есть данные, которые считываются постоянно, но записываются редко—например, это может быть множество USB-устройств, которые в настоящее время подключены к компьютеру. В пересчёте на компьютерное время это множество меняется раз в целую эпоху, но оно может меняться. А когда такие изменения всё-таки происходят, они должны быть атомарными, то есть, не должны блокировать никаких считывателей, которые могут испытывать пиковую нагрузку.
Есть удивительно простое решение: обеспечить, чтобы пишущий:
- Считывал имеющиеся данные по указателю.
- Копировал их и вносил изменения, необходимые для перехода к следующей версии.
- Атомарно обновлял указатель, так, чтобы после этого он был направлен на новую версию.
Такая стратегия может называться «чтение, копирование, запись». В коде её можно выразить примерно так:
// Состояние, реализованное как огромный ком...
struct Foo {
int lots;
string o;
big_hash_map fields;
};
// ...совместно используется записывающим и всеми читающими по этому указателю.
atomic<Foo*> sharedFoo;
// Читающие просто... читают указатель.
const Foo* readFoo() { return shared_foo.load(); }
// Пишущий вызывает этот код, чтобы атомарно обновить наше разделяемое состояние.
// (Чтобы этот код можно было использовать со множественными производителями и потребителями, его нужно обернуть в мьютекс,
// но давайте предположим, что здесь мы имеем дело с обычным сценарием, в котором один производитель.)
void updateFoo() {
const Foo* old = shared_foo.load(); // Чтение
const Foo* updated = makeNewVersion(old); // Копирование
sharedFoo.store(updated); // Запись
}Красота! Этот механизм лёгок в использовании, обходится без ожидания, но здесь течёт как из ведра.

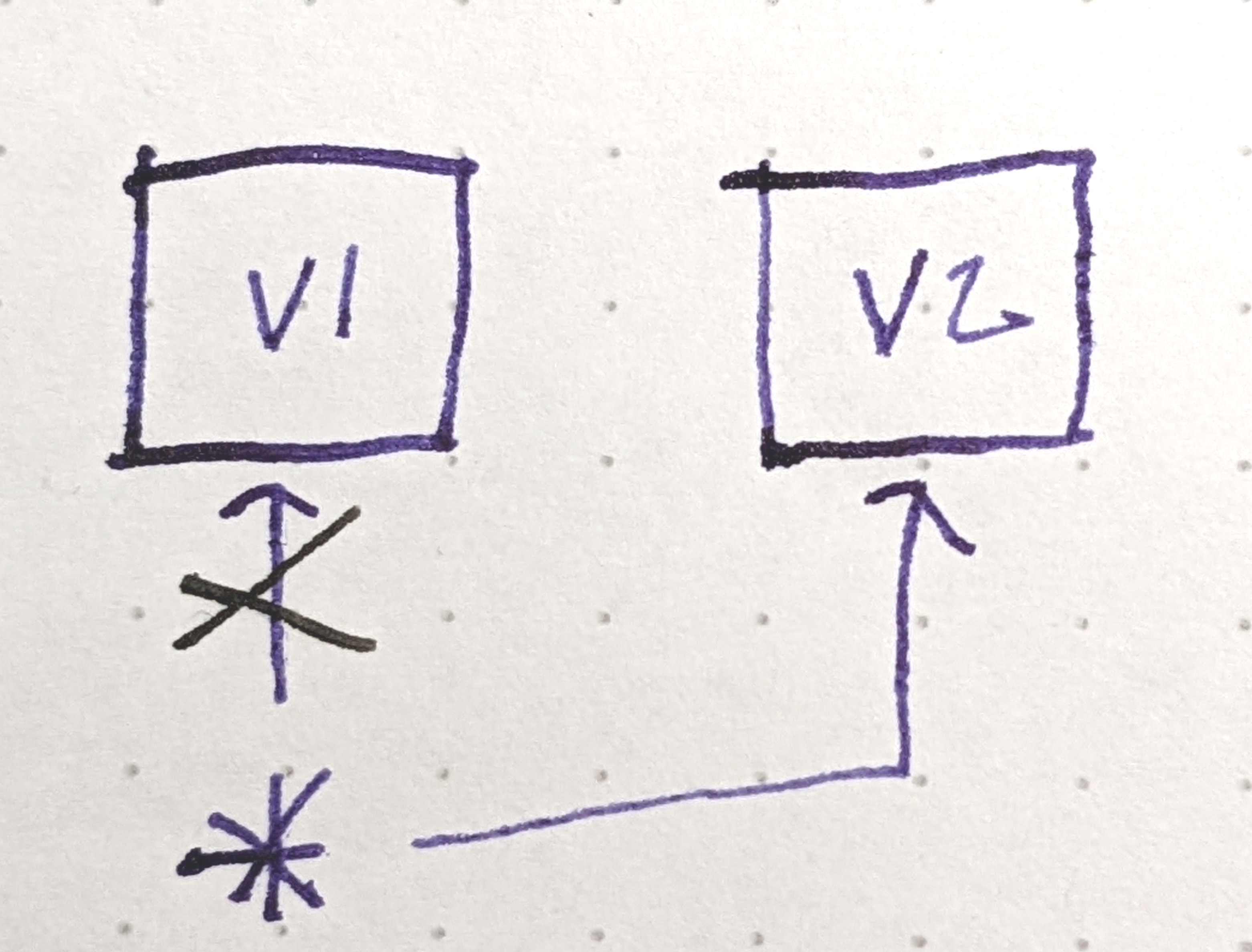
Это никуда не годится. А можно просто удалить данные?
void updateFoo() {
const Foo* old = shared_foo.load(); // Чтение
const Foo* updated = makeNewVersion(old); // Копирование
sharedFoo.store(updated); // Запись
delete old; // НУ ПОГОДИ!!!
}На самом деле, нет. Если только вы не фанат багов, связанных с использованием после высвобождения. Всё это происходит в неблокирующем режиме, так как же мы узнаем, не осталось ли у нас считывателей, которые до сих пор смотрят старую (old) версию?
На этом рисунке есть считыватель (R2, зелёный), продолжающий использовать старую версию уже после того, как пишущий (фиолетовый) обновил разделяемый указатель. Последующие считыватели (например, R3) увидят новую версию, но пишущий не будет знать, когда R2 закончит работу!
Может быть, нам об этом расскажут, хм, считыватели?
void someReader() {
// Сообщить пишущему, что сейчас информацию кто-то читает.
rcu_read_lock();
const Foo* f = readFoo();
doThings(f);
// Сообщить пишущему, что дело сделано.
rcu_read_unlock();
}Так определяется своеобразная «критическая секция для считывания» — считыватели так и не блокируются, но они могут заставить пишущего обрубить все данные, которые пока рассматриваются.
void updateFoo() {
const Foo* old = shared_foo.load(); // Чтение
const Foo* updated = makeNewVersion(old); // Копирование
sharedFoo.store(updated); // Обновление
// Дожидаемся, пока актуальные считыватели "разблокируются"
// и покинут свои критические секции.
rcu_synchronize();
delete old;
}Итак,
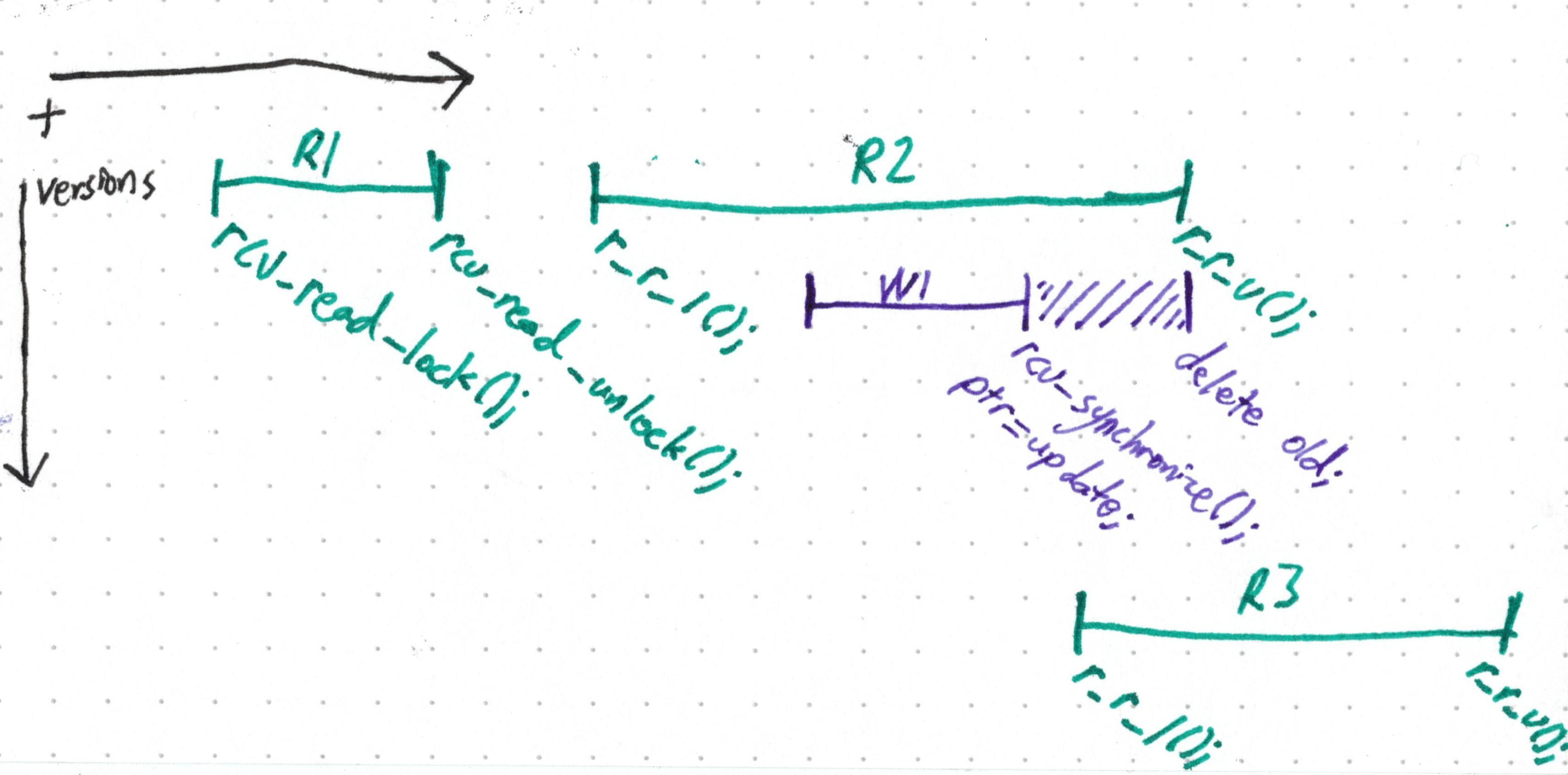
Обратите внимание: здесь мы не дожидаемся, пока количество считывателей станет равно нулю — опять же, R3 получает новую версию данных, поэтому его не волнует, что будет со всеми более ранними данными.
rcu_synchronize() всего лишь требуется дождаться, пока закончат работу предыдущие считыватели — те, которые до сих пор видят перед собой old.Обычного человека такое решение бы устроило, но разработчики ядра – не самые обычные люди. В данной ситуации получаем блокирование пишущего и, хотя мы и не оптимизируем сторону записи, эта блокировка всё равно выглядит очень печально.
Допустим, мы не хотим дожидаться, пока наша функция обновления высвободит старые данные. Наш код корректен, если в конечном счёте это высвобождение произойдёт, верно? Что, если «отложить» эту операцию?
void updateFoo() {
const Foo* old = shared_foo.load(); // Чтение
const Foo* updated = makeNewVersion(old); // Копирование
sharedFoo.store(updated); // Обновление
// Наша крутая библиотека может высвободить `old` в любой момент после того, как
// считыватели, которые сейчас работают, покинут свои критические секции.
rcu_defer(old);
}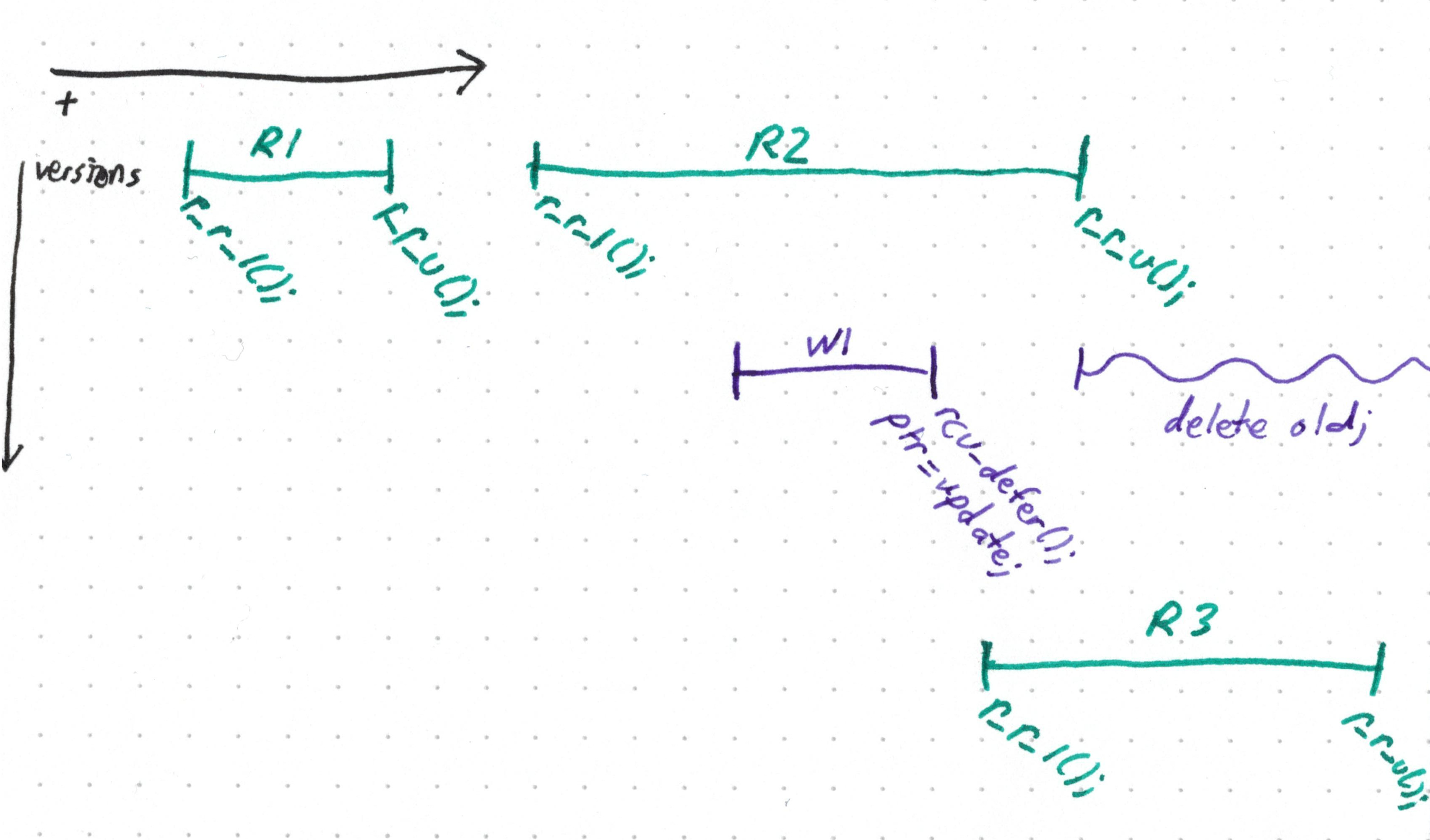
Всё будет нормально, если мы высвободим old, улучив где-нибудь момент. Мы даже могли бы предусмотреть на локальной машине выделенный поток, который бы время от времени подметал все старые версии данных, те, на которые не стоят ссылки и…
…подождите, а не построили ли мы тут поколенческий сборщик мусора? Состоящий из неизменяемых структур данных, ни больше, ни меньше?
❯ Что?
Это не какой-нибудь мысленный эксперимент — практика RCU совершенно реальна и, кстати, очень полезна. Эта практика используется в Linux десятки тысяч раз. Чтобы ею было удобнее пользоваться, есть специальная библиотека — Folly на C++.
В Rust эта возможность реализована при помощи crossbeam-epoch, на неё опираются самые популярные библиотеки для программирования конкурентности.
Врач: Сборка мусора в ядре – это фантазия, она не реальна и не может вам навредить.
Сборка мусора в ядре:
Вот здесь меня обычно начинают бомбить не-аргументами о том, будто это «ненастоящая» сборка мусора. Ведь, уф, вы вручную размечаете мусор! Я не хочу тут вдаваться в классификационные споры – как ни назови RCU, эта техника структурно точно такая же, как и сборка мусора: память очищается в конечном счёте, в зависимости от того, используется сейчас данная память или нет. Причём, это интересный пример, идущий вразрез с общепринятым мнением, что сборка мусора:
- Медленнее, чем ручное управление памятью.
- При написании системного софта лишает нас детализированного контроля, который так нужен.
В контексте RCU эти аргументы не выдерживают никакой критики, так как операции RCU обоснованы целевыми показателями производительности и задержек, а не используются ради удобства, несмотря на то, во сколько это обходится. Причём, мы не выполняем никакой дополнительной работы, мы просто выносим эту работу в сторону от критического пути.
…Может быть, и эти аргументы – просто чушь какая-то?
❯ Не такая уж медленная эта сборка мусора ИЛИ: не такой уж быстрый этот malloc()
Распространено мнение, будто сборщики мусора по природе своей менее эффективны, чем традиционное/ручное управление памяти. Но этот тезис быстро разваливается, если детально рассмотреть, как именно устроены эти вещи. Посудите сами:
-
free()не даётся даром. Аллокатор памяти общего назначения должен поддерживать массу внутреннего глобального состояния. Какие страницы мы получаем из ядра? Как мы распределяем их по корзинам, рассчитанных на выделение участков разного размера? Какие из этих корзин используются? В результате то и дело случается конкуренция между потоками, каждый из которых пытается заблокировать состояние аллокатора. Также это может делаться при помощи jemalloc: мы поддерживаем локальные пулы потоков, которые нужно синхронизировать, а для этого требуется ещё больше кода.
Инструменты, позволяющие автоматизировать «фактическое высвобождение памяти», например, времена жизни в Rust и RAII в C++, не решают этих проблем. Зато они более чем обеспечивают корректность, о которой в противном случае пришлось бы крепко задумываться именно вам. Но при этом ничего не делается для упрощения всех этих механизмов. Во многих сценариях также требуется предусмотреть резервный сценарий отката к shared_ptr/Arc, а такие сценарии, в свою очередь, требуют ещё больше метаданных (в рамках подсчёта ссылок), которые курсируют между ядрами и кэшами.
- Современная сборка мусора предлагает варианты оптимизации, которые при альтернативных подходах невозможны. При динамичной поколенческой сборке мусора куча периодически перекомпоновывается. Так достигается просто безумная пропускная способность, поскольку для выделения памяти требуется всего лишь бросить указатель! Также в таком случае последовательные операции выделения памяти ложатся очень компактно, что способствует высокой производительности кэша.
❯ Иллюзия контроля
Многие разработчики, негативно относящиеся к сборке мусора, создают «мягкие» системы, работающие в режиме реального времени. Они стремятся добиться максимальной скорости: ещё больше кадров в секунду в моей видеоигре! Давайте ещё повысим сжатие в моём стриминговом кодеке! Но у них нет жёстких требований к задержке. Если система случайно провозится лишнюю миллисекунду – ничего не сломается и никто не умрёт.
Но, даже если мы не служим в ночном дозоре, никому ведь не хочется то и дело ставить мир на паузу, чтобы дать поработать сборщику мусора, правда?
❯ Та ложь об управлении памятью, в которую вы верите
- Программист сам может решать, когда будет происходить управление памятью. У операционной системы есть одно чудесное свойство: она абстрагирует наши взаимодействия с железом. Есть у операционной системы и ужасное свойство: она абстрагирует наши взаимодействия с железом. Если запросить у Linux память, то по умолчанию он почти ничего не делает, а выдаёт вам её, только когда вы фактически пытаетесь её использовать. В зыбком мире madvise(), отображаемого в память ввода/вывода и файловых системных кэшей нет простого ответа на вопрос «что именно выделяется и когда»? Можно только намекнуть операционной системе на наши намерения и надеяться, что она справится как можно лучше. Как правило, у неё действительно всё получается хорошо, но в неудачный день даже простое обращение к указателю может превратиться в дисковый ввод/вывод!
-
Программисту виднее, когда лучше приостановить выполнение и поуправлять памятью. Иногда очевидно, что именно сейчас этим уместно заняться – например, пока в ходе загрузки игры демонстрируется экран-заставка. Но на один такой очевидный ответ приходится множество совсем не очевидных, сводящихся к «пока мы не заняты более важной работой». Увереннее судить об этом нам могли бы помочь наши друзья
shared_ptrиArc– так как в отдельных фрагментах кода, в каждом из которых содержится указатель с подсчётом ссылок, невозможно априори знать, не окажется ли именно этот код последним фрагментом, в котором застопорится очистка. Если бы это можно было знать, то никакой подсчёт ссылок вообще бы не требовался! - Вызывая free(), мы возвращаем память операционной системе. Память выделяется из операционной системы постранично, и аллокатор зачастую придерживает эти страницы до тех пор, пока программа не завершит работу. Он пытается многократно их использовать, чтобы не тревожить операционную систему чаще, чем это необходимо. Не говоря уже о том, что ОС не может забирать страницы, выгружая их из памяти…
❯ Выводы
Я не утверждаю, что сборка мусора пойдёт на пользу любой программе. В некоторых она определённо не нужна. Но мы уже почти дожили до 2024 года, а любое упоминание о сборке мусора – в особенности, среди системных программистов — по-прежнему тонет в ложных дихотомиях, страхе, неуверенности и сомнениях. Сборка мусора – для дураков, слишком ленивых или некомпетентных, поэтому неспособных написать «явно» более быструю версию кода на языке, где управление памятью происходит вручную.
Просто всё не так. Такова идеология. И я придерживался её более десяти лет, пока не присоединился к команде, создающей системы – такие системы, за которые их создатели головой ручаются. Задержка в этих системах не превышает микросекунд, а сборка мусора происходит на языке, где память выделяется буквально под каждую строку. Оказывается, современные системы сборки мусора дают потрясающую пропускную способность, ими не приходится жертвовать ради ручной сборки мусора просто потому, что какой-то компонент вашей системы кровь из носу должен проработать n тактов процессора. (Эти конкретные части можно делегировать в код, работающий без сборки мусора, или даже передать железу!).
Сборка мусора – не серебряная пуля. Серебряных пуль нет. Но это ещё один инструмент у нас в арсенале, и не бойтесь им пользоваться.
- Честно говоря, здесь найдётся и множество самых обычных мьютексов и спинлоков. ↩
- Можно было бы прочесть указатель, даже не пользуясь обычной семантикой «загрузка с приобретением». Чтобы упорядочить операции, можно было бы просто взять за основу очерёдность и зависимость данных в конвейере процессора – между указателем и теми значениями, на которые он направлен. Но трагедия
memory_order_consume– это тема для отдельной публикации. ↩ - В системах с действительно жёсткими требованиями к работе в режиме реального времени всё обстоит совершенно иначе. Удачи вам с латанием обработчиков прерываний через RTOS, с написанием драйверов для FPGA и с прокладкой собственных систем переключений. Причём, после запуска системы вы определённо не сможете ничего выделить. ↩
Возможно, захочется почитать и это:
- ➤ Сборка мусора в неисправных JVM, проактивный подход
- ➤ Разрабатываем десктопное приложение для заметок с помощью Tauri (React + Rust)
- ➤ Новый язык программирования
- ➤ ИОЛА (IOLANET2): уникальная ретро-сеть отечественного производителя и безуспешный эксперимент
- ➤ Рождение и проверка временем Sid Meier's Civilization II

Комментарии (5)

Kelbon
12.10.2023 10:28+2В случае RCU не упомянуты атомик шаред поинтеры, которые легко и интуитивно решают проблему с удалением(причём удалено будет как только становится не нужно, а не когда-нибудь)

Apoheliy
12.10.2023 10:28+1Так в статье и написано, что иногда очень желательно удалять объекты не когда они стали не нужны, а в некоторый "другой" момент времени (когда заставочка рисуется, когда лучше удалить много скопом и т.д.). Вроде бы atomic shared pointer это не решит ну никак.
Kelbon
12.10.2023 10:28+2ну сделай шаред поинтер который будет при удалении вызывать не free(), а вставлять блок памяти в очередь на удаление.
Но в целом это довольно бесполезное занятие, просто деаллоцировать скорее всего будет лучше, чем держать дополнительные структуры данных ради чего то там позже

Panzerschrek
12.10.2023 10:28+1Сборка мусора бывает разная. Критикуют, как я понимаю, не всякие хитрые случаи с отложенным удалением, как в вышеизложенном примере, а что-то более тяжеловесное, вроде сборщиков мусора, которые сканируют граф объектов или вообще, всю память целиком.
Как я понимаю, из проблем подобной сборки мусора вылезают различные костыли. Например, in-memory database, когда просто хранить объекты в памяти как есть уже накладно и приходится их компактно запаковывать. Или те же микросервисы - когда из-за большого количества объектов в "монолите" сборщик мусора настолько тупит, что распилка на микросервисы (даже с учётом накладных расходов на коммуникацию) обретает смысл.
jetu
Недавно был неплохой тред на reddit на схожую тематику https://www.reddit.com/r/golang/comments/173n28q/the_myth_of_go_garbage_collection_hindering/