Современные облачные инструменты и пакеты Python стали настолько мощными, что с их помощью можно создать (масштабируемый) облачный API менее чем в 200 строках кода. В этом посте будет рассмотрено, как при помощи lines Google Cloud, Terraform и FastAPI развернуть в облаке полноценный API, через который можно отвечать на запросы.
Репозиторий к этому проекту находится здесь, пользуйтесь им, если захотите опробовать весь код сами.
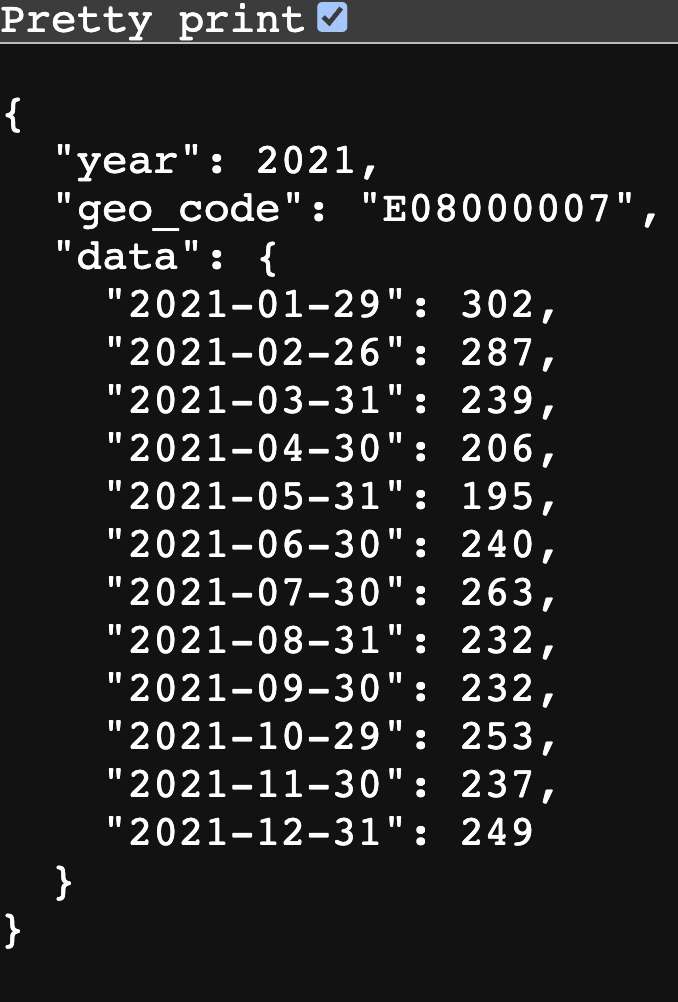
Пример API, возвращающего данные. О том, как его создать, рассказано в этом посте.
Базовая идея такова: создаём образ компьютера, обслуживающего API, привязываем его к масштабируемой облачной функции – и снимаем все ограничения, чтобы любой мог отправлять запросы на этот API.
Почему вам вообще может потребоваться развернуть API? Я рассказал об этом в другом посте. Если коротко – это отличное решение, позволяющее эффективно обслуживать запросы к данным или запросы, связанные с прогнозированием.
Сначала расскажу о некоторых подводных камнях. В этом посте я учитываю только тот код (в строках), который нужен для создания самого API и обслуживающей его облачной инфраструктуры. Ещё понадобится код для извлечения и преобразования тех данных, которые мы будем выдавать по запросу. Таким образом, я не учитываю код, применяемый для создания данных, а это весь код, лежащий в каталоге etl. Для работы я мог бы выбрать любой старый датасет. Отмечу: если вы полностью проработаете этот пост и создадите собственный масштабируемый облачный API, то вам не обойтись без аккаунта Google Cloud с настроенной тарификацией (или запасом бесплатных бонусов). Наконец, будьте внимательны и никому не раздавайте ваши ключи от облака и не сообщайте подлинные имена переменных terraform. Впрочем, всё описано в туториале, расположенном в публичном репозитории. Важные файлы я добавил в .gitignore – для тех, кто решит клонировать репозиторий. Но напоминаю, что нужно проявлять максимальную осторожность, как и всегда при работе с секретными данными. Они ни в коем случае не должны передаваться по открытым каналам.
Хорошо, теперь давайте поговорим о технологиях, которыми мы собираемся пользоваться.
Google Cloud Platform (GCP) предоставляет полный комплект облачных сервисов и является одним из крупнейших провайдеров такого рода. Кажется, что она просто создана для занятий data science, в ней предусмотрен отличный интерфейс для работы через командную строку. Вот конкретные компоненты GCP, с которыми мы будем работать:
Стоит отметить, что Cloud Run – это бессерверная платформа. А значит, работая с ней, не приходится возиться с ресурсами бекенда, чтобы запускать приложения. Cloud Run может масштабироваться как в сторону увеличения, так и уменьшения. В сущности, Google берёт на себя обработку всего бекендового материала, делая эту работу за вас. Как и у любого технологического решения, у этой платформы есть слабые стороны, но она всё равно отлично подходит для простого и безболезненного развёртывания небольших API, заключённых в контейнерах.
По мере повсеместного распространения облачных платформ мы рискуем вновь вернуться к кликательным интерфейсам, проблемам с воспроизводимостью, впадать в зависимость от поставщика, а также столкнуться со многими другими вещами, которых сейчас стараемся избегать при исследовании данных. Terraform – это инструмент, при помощи которого удобно представлять «инфраструктуру как код» — то есть, собирать, менять и версионировать облачные ресурсы, безопасно и эффективно управляя ими. Одно из преимуществ такого подхода заключается в следующем: однажды распланировав ресурсы в Terraform, вы можете снова и снова пользоваться этим файлом, воспроизводя инфраструктурные конфигурации по ходу работы.
FastAPI – это пакет Python, предназначенный для сборки API. У него целый букет преимуществ:
Давайте рассмотрим некоторые из этих ништяков на примерах. Во-первых, вы не представляете, насколько просто создать конечную точку API. Допустим, у нас есть кадр данных (df), в котором заключены те данные, которые мы хотим подать. Чтобы превратить в API специальную функцию Python, занимающуюся подачей данных, нам понадобится только декоратор, оператор async и подсказки типов. Ниже в упрощённом виде представлен тот пример, который мы будем разбирать в оставшейся части этого поста:
Этим простым объявлением мы добиваемся очень многого. Если вы достучитесь до конечной точки API из этого репозитория при помощи следующего запроса: /year/notanumber/geo_code/E08000007 – то есть, укажете действительный географический код, но год у вас окажется не целочисленным, то автоматически запустятся валидационные проверки, предусмотренные в pydantic, и пользователь получит следующее сообщение об ошибке:
Этому API известно, что вы не передали корректного целого числа! Часть year: int, входящая в определение функции, означает, что в любом вводе тот сегмент API, который означает год (year) обязательно должен быть целым числом.
Хорошо, мы достаточно подробно описали контекст. Теперь давайте пошагово разберём, как делается API. Весь его код доступен здесь.
Скачайте и установите terraform. То же самое проделайте с poetry и убедитесь, что у вас установлен Python (в этом руководстве используется Python 3.10, и именно эта версия включена в файл pyproject.toml, используемый в poetry — вот ссылка).
Заводим аккаунт Google Cloud.
Убедитесь, что у вас установлен Google CLI (интерфейс для работы с командной строкой), и вы в нём аутентифицированы. Как только скачаете и установите этот инструмент, выполните gcloud init, чтобы его настроить. Затем выполните gcloud auth login, чтобы гарантировать, что вы вошли в ваш аккаунт под своим логином. Выполнив эти шаги, вы сможете прямо через командную строку вносить изменения в ваш аккаунт Google Cloud.
Теперь давайте через командную строку создадим проект.
Возможно, вы решите завершить имя проекта цифрами, чтобы оно получилось уникальным, так как все наиболее очевидные имена уже разобраны (а если конкретное имя занято, то создать проект с таким именем не удастся). (Обратите внимание, что тот же самый ID проекта вам потребуется указать и в вашем файле terraform.tfvars – до этого мы дойдём чуть ниже.)
Далее переключите Google Cloud CLI на работу с данным конкретным проектом:
Теперь нам потребуется перейти в консоль Google Cloud. Выберите в ней соответствующий проект, а затем создайте новый служебный аккаунт (Service Account) под IAM. Актуальный URL приведён здесь. При помощи служебного аккаунта можно управлять доступом к сервисам Google Cloud.
В новоиспечённом служебном аккаунте щёлкните Actions (Действия), а затем Manage keys (Управление ключами). Создайте новый ключ и скачайте его как файл в формате JSON — не ставьте только его под контроль версий! Если вы выполняете этот туториал, склонировав соответствующий репозиторий, то ключ можно положить в подкаталог google_key.json, так как содержимое папки secrets также не подпадает под контроль версий — но, как всегда, всё проверяйте дважды.
Если вы ещё не настроили тарификацию, то самое время это сделать. Раздел тарификации (Billing) находится в навигационной секции слева.
Terraform – это способ указания ресурсов сразу для множества облаков. При помощи Terraform мы подготовим к работе пару облачных API и обустроим реестр артефактов (Artifact Registry). (Именно в этот реестр мы в конечном итоге поместим образ docker, в котором будет заключено наше приложение.)
main.tf – это главный файл Terraform (вот ссылка). В нём перечислены предоставляемые Google сервисы API, которыми мы будем пользоваться, этим сервисам даются имена, а также эти сервисы активируются. Информация в этом файле подразделяется на несколько чётко очерченных блоков:
Одна из не самых логичных черт terraform заключается в том, что он сам определяет, в каком порядке применять эти изменения. Поэтому совершенно нормально, что блоки, активирующие API, идут уже после блоков, создающих новые ресурсы для конкретных API.
В .terraform.version содержится та версия terraform, которой вы пользуетесь (чтобы это проверить, выполните terraform --version).
В файле variables.tf предоставляются метаданные по переменным, которые понадобятся вам в вашем проекте (вот ссылка).
Ещё есть дополнительный файл terraform.tfvars – он не включён в этот репозиторий и не должен быть публичным. Там содержатся настоящие имена переменных, используемых в вашем проекте Google Cloud. Содержимое этого файла выглядит примерно так:
В этом файле должно содержаться по записи на каждую переменную, содержащуюся в файле
Теперь выполните
Далее выполните terraform plan, который поможет вам решить все вопросы, поставленные перед вами в
Наконец, чтобы создать ресурсы GCP, примените terraform apply. Если всё пройдёт успешно, то вы увидите сообщение: “Apply complete! Resources: 3 added, 0 changed, 0 destroyed.” (Применено успешно! Ресурсы: 3 добавлено, 0 изменено, 0 уничтожено).
Если вы не хотите активировать все API через последний блок main.tf, то в качестве альтернативы можете сделать это через интерфейс командной строки Google Cloud CLI.
Если хотите проверить, какие сервисы вы активировали, выполните
Выполните
Выполните
В этом репозитории, чтобы добиться максимально высокого качества кода, используется команда pre-commit. Можете выполнить её при помощи
Здесь вы можете выбрать любой небольшой датасет на ваш вкус. В данном случае, поскольку так интереснее, я собрал данные по смертности, которые были рассыпаны у меня по файлам в Excel в каком-то странном формате. Именно эти данные и будет выдавать нам API. Оригинальные файлы с данными находятся здесь. При работе с более крупными датасетами вам потребуется выполнить и шаг «загрузки» (“L” в аббревиатуре “ETL”), а также обеспечить, чтобы эти данные находились именно в той базе данных GCP, в которую мы посылаем запросы через API.
Обратите внимание: эти данные не включены в репозиторий, соответствующие скрипты Python вам придётся запускать самостоятельно!
В каталоге etl содепжится несколько скриптов на Python. Вот каковы их функции:
Чтобы создать те данные, которые мы впоследствии будем подавать, нужно выполнить
Если вы хотите использовать FastAPI на локальной машине, чтобы поднять ваш API и убедиться, что он работает, то сначала вам потребуется установить окружение Python (это делается при помощи poetry).
Здесь app – это каталог, api.py – это скрипт, а второй app – это приложение FastAPI, определённое в api.py. В результате подаётся API в форме: /year/{YEAR-OF-INTEREST}/geo_code/{GEO-CODE-OF-INTEREST}. Например, если FastAPI работает на порту 0.0.0.0:8080, то 0.0.0.0:8080/year/2021/geo_code/E08000007 выдаст данные о смертности в Стокпорте за 2021 год (это город в Великобритании с локальным муниципальным кодом E08000007). Также можете попробовать 0.0.0.0:8080/docs, чтобы посмотреть, как сами собой получаются автоматические интерактивные документы для FastAPI!
При помощи Terraform мы уже подготовили к работе Cloud Run API. Теперь план таков: собрать контейнер docker, в котором будет лежать всё, необходимое для выдачи API; далее на основе этого docker-файла нужно собрать образ, загрузить этот образ в реестр артефактов, который мы ранее создали в облаке Google Cloud, и далее выдавать API через Google Cloud Run. Первым делом нужно убедиться, что наша env нормально воспроизводится в файле docker.
Можно организовать работу poetry (используемой в этом проекте) в файлах docker, но в таком случае что-то может пойти не так. Поэтому проще выполнить:
Также убедитесь, что файл docker использует requirements.txt. Обратите внимание: поскольку мы готовим файл docker именно таким образом, файл requirements.txt добавлен в .gitignore. Так мы придерживаемся правила о единственном источнике истины: если одновременно подвергнуть контролю версий и requirements.txt, и pyproject.toml, то возникнет путаница: в котором же из этих файлов определяется окружение? А при нашем подходе всё ясно: в pyproject.toml устанавливаются зависимости Python, а файл requirements.txt расположен ниже него в дереве каталогов.
Обратите внимание, что у нас в dockerfile всего 16 строк кода, и этот код – абсолютный минимум, необходимый для обеспечения работоспособности API.
Также отметим, что имя deaths_data.parquet жёстко закодировано в dockerfile. Вероятно, есть способ как-то вытянуть имя файла данных из конфигурационного файла config.toml, где этот файл данных определён, но давайте не усложнять.
При желании можете сначала проверить, работает ли ваш Dockerfile на локальной машине. Для этого выполните
чтобы его собрать, а затем
чтобы запустить. Тогда в окне терминала должно появиться сообщение, включающее HTTP-адрес, по которому можно перейти. На самом деле, он находится не в Интернете… а у вас дома! Щёлкните по нему – и вы должны увидеть, как загружается ваш API. Например, с 0.0.0.0:8080 можно отправиться на 0.0.0.0:8080/docs, убедиться, что все документы загрузились, и опробовать API в действии.
Теперь начинаются осложнения. Я, например, работаю с Mac, где используется процессор с архитектурой arm64, он называется Apple Silicon. Но большинство облачных сервисов работает на базе Linux, где, как правило, применяются процессоры amd64. Если без изысков собрать образ на локальной машине и просто отправить его в Google Cloud, то получится образ, который не сможет работать на архитектуре Google. Поэтому нам потребуется мультиплатформенная сборка или же сборка, прицельно создаваемая под конкретную архитектуру. (Docker позиционируется как решение именно для этой проблемы, и при помощи Docker она действительно решается – правда, нужно немного постараться.)
Вам потребуется
чтобы создать такой сборщик, который возьмётся за построение образа. Далее потребуется волшебная команда, при помощи которой мы соберём образ и отправим в репозиторий на google:
где REPOSITORY-NAME – это имя переменной registry_id в terraform.tfvars. Обратите внимание на аргумент “platform”.
Теперь развернём приложение при помощи:
Если всё пройдёт нормально, то на экране вы должны увидеть следующее сообщение:
Действующую версию данного приложения вы можете взять в репозитории отсюда: app-qdvgjvqwza-nw.a.run.app. Здесь лежит документация. А вот пример, возвращающий данные. Обратите внимание на одно ограничение Cloud Run: если ссылкой давно не пользовались, то оно немного тормозит при запуске.
Отмечу, что, если вся работа вашего API сводится к выдаче табличных данных, то такой функционал можно организовать и проще (хотя, куда уж проще, чем собрать API при помощи FastAPI). Можно воспользоваться отличной datasette. Здесь показан рабочий пример, в котором она выдаёт порцию данных. Представляется, что FastAPI была бы гораздо полезнее с данными, которые были бы структурированы гораздо нетривиальнее. Например, если при работе с данными их требуется одновременно записывать и читать, либо когда Cloud Run должен выполнять и другие действия (например, подтягивать информацию из базы данных Google).
Чем сильнее облачные сервисы переходят в категорию потребительских решений, и чем больше классных разработок появляется на языке Python, тем проще становится создавать высококачественные API. Хотя, тут есть некоторые детали, над которыми требуется поломать голову, просто удивительно, насколько быстро можно создать рабочий API —и какой минимум кода для этого требуется.
Возможно, захочется почитать и это:
Репозиторий к этому проекту находится здесь, пользуйтесь им, если захотите опробовать весь код сами.
Пример API, возвращающего данные. О том, как его создать, рассказано в этом посте.
Базовая идея такова: создаём образ компьютера, обслуживающего API, привязываем его к масштабируемой облачной функции – и снимаем все ограничения, чтобы любой мог отправлять запросы на этот API.
Почему вам вообще может потребоваться развернуть API? Я рассказал об этом в другом посте. Если коротко – это отличное решение, позволяющее эффективно обслуживать запросы к данным или запросы, связанные с прогнозированием.
Сначала расскажу о некоторых подводных камнях. В этом посте я учитываю только тот код (в строках), который нужен для создания самого API и обслуживающей его облачной инфраструктуры. Ещё понадобится код для извлечения и преобразования тех данных, которые мы будем выдавать по запросу. Таким образом, я не учитываю код, применяемый для создания данных, а это весь код, лежащий в каталоге etl. Для работы я мог бы выбрать любой старый датасет. Отмечу: если вы полностью проработаете этот пост и создадите собственный масштабируемый облачный API, то вам не обойтись без аккаунта Google Cloud с настроенной тарификацией (или запасом бесплатных бонусов). Наконец, будьте внимательны и никому не раздавайте ваши ключи от облака и не сообщайте подлинные имена переменных terraform. Впрочем, всё описано в туториале, расположенном в публичном репозитории. Важные файлы я добавил в .gitignore – для тех, кто решит клонировать репозиторий. Но напоминаю, что нужно проявлять максимальную осторожность, как и всегда при работе с секретными данными. Они ни в коем случае не должны передаваться по открытым каналам.
Хорошо, теперь давайте поговорим о технологиях, которыми мы собираемся пользоваться.
Google Cloud Platform
Google Cloud Platform (GCP) предоставляет полный комплект облачных сервисов и является одним из крупнейших провайдеров такого рода. Кажется, что она просто создана для занятий data science, в ней предусмотрен отличный интерфейс для работы через командную строку. Вот конкретные компоненты GCP, с которыми мы будем работать:
- Реестр образов. В нём можно сохранить образ конкретного компьютера, который сможет выдавать хранящиеся на нём данные через API
- Google Cloud Run – тот механизм, который и предоставляет в пользование образ конкретного компьютера
Стоит отметить, что Cloud Run – это бессерверная платформа. А значит, работая с ней, не приходится возиться с ресурсами бекенда, чтобы запускать приложения. Cloud Run может масштабироваться как в сторону увеличения, так и уменьшения. В сущности, Google берёт на себя обработку всего бекендового материала, делая эту работу за вас. Как и у любого технологического решения, у этой платформы есть слабые стороны, но она всё равно отлично подходит для простого и безболезненного развёртывания небольших API, заключённых в контейнерах.
Terraform
По мере повсеместного распространения облачных платформ мы рискуем вновь вернуться к кликательным интерфейсам, проблемам с воспроизводимостью, впадать в зависимость от поставщика, а также столкнуться со многими другими вещами, которых сейчас стараемся избегать при исследовании данных. Terraform – это инструмент, при помощи которого удобно представлять «инфраструктуру как код» — то есть, собирать, менять и версионировать облачные ресурсы, безопасно и эффективно управляя ими. Одно из преимуществ такого подхода заключается в следующем: однажды распланировав ресурсы в Terraform, вы можете снова и снова пользоваться этим файлом, воспроизводя инфраструктурные конфигурации по ходу работы.
Python и FastAPI
FastAPI – это пакет Python, предназначенный для сборки API. У него целый букет преимуществ:
- Очень высокая производительность.
- Возможность быстро писать код, допуская минимум багов, поскольку в инструменте активно используются подсказки типов и декораторы.
- Полная поддержка по автозавершению кода.
- Автоматическое создание интерактивной документации.
- FastAPI основан на следующих открытых стандартах создания API (и полностью совместим с ними): OpenAPI (ранее именовался Swagger) и JSON Schema.
Давайте рассмотрим некоторые из этих ништяков на примерах. Во-первых, вы не представляете, насколько просто создать конечную точку API. Допустим, у нас есть кадр данных (df), в котором заключены те данные, которые мы хотим подать. Чтобы превратить в API специальную функцию Python, занимающуюся подачей данных, нам понадобится только декоратор, оператор async и подсказки типов. Ниже в упрощённом виде представлен тот пример, который мы будем разбирать в оставшейся части этого поста:
@app.get("/year/{year}/geo_code/{geo_code}")
async def read_item(year: int, geo_code: str):
json_data = df.loc[
(df["year"] == year) & (df["geo_code"] == geo_code), "deaths"
].to_dict()
return {"year": year, "geo_code": geo_code, "data": json_data}Этим простым объявлением мы добиваемся очень многого. Если вы достучитесь до конечной точки API из этого репозитория при помощи следующего запроса: /year/notanumber/geo_code/E08000007 – то есть, укажете действительный географический код, но год у вас окажется не целочисленным, то автоматически запустятся валидационные проверки, предусмотренные в pydantic, и пользователь получит следующее сообщение об ошибке:
{
"detail": [
{
"type": "int_parsing",
"loc": [
"path",
"year"
],
"msg": "Input should be a valid integer, unable to parse string as an integer",
"input": "notanumber",
"url": "https://errors.pydantic.dev/2.4/v/int_parsing"
}
]
}Этому API известно, что вы не передали корректного целого числа! Часть year: int, входящая в определение функции, означает, что в любом вводе тот сегмент API, который означает год (year) обязательно должен быть целым числом.
Хорошо, мы достаточно подробно описали контекст. Теперь давайте пошагово разберём, как делается API. Весь его код доступен здесь.
❯ Первичная подготовка
Установка кода
Скачайте и установите terraform. То же самое проделайте с poetry и убедитесь, что у вас установлен Python (в этом руководстве используется Python 3.10, и именно эта версия включена в файл pyproject.toml, используемый в poetry — вот ссылка).
Создаём проект Google
Заводим аккаунт Google Cloud.
Убедитесь, что у вас установлен Google CLI (интерфейс для работы с командной строкой), и вы в нём аутентифицированы. Как только скачаете и установите этот инструмент, выполните gcloud init, чтобы его настроить. Затем выполните gcloud auth login, чтобы гарантировать, что вы вошли в ваш аккаунт под своим логином. Выполнив эти шаги, вы сможете прямо через командную строку вносить изменения в ваш аккаунт Google Cloud.
Теперь давайте через командную строку создадим проект.
gcloud projects create YOUR-PROJECT-IDВозможно, вы решите завершить имя проекта цифрами, чтобы оно получилось уникальным, так как все наиболее очевидные имена уже разобраны (а если конкретное имя занято, то создать проект с таким именем не удастся). (Обратите внимание, что тот же самый ID проекта вам потребуется указать и в вашем файле terraform.tfvars – до этого мы дойдём чуть ниже.)
Далее переключите Google Cloud CLI на работу с данным конкретным проектом:
gcloud config set project YOUR-PROJECT-IDТеперь нам потребуется перейти в консоль Google Cloud. Выберите в ней соответствующий проект, а затем создайте новый служебный аккаунт (Service Account) под IAM. Актуальный URL приведён здесь. При помощи служебного аккаунта можно управлять доступом к сервисам Google Cloud.
В новоиспечённом служебном аккаунте щёлкните Actions (Действия), а затем Manage keys (Управление ключами). Создайте новый ключ и скачайте его как файл в формате JSON — не ставьте только его под контроль версий! Если вы выполняете этот туториал, склонировав соответствующий репозиторий, то ключ можно положить в подкаталог google_key.json, так как содержимое папки secrets также не подпадает под контроль версий — но, как всегда, всё проверяйте дважды.
Если вы ещё не настроили тарификацию, то самое время это сделать. Раздел тарификации (Billing) находится в навигационной секции слева.
Терраформирование компонентов Google Cloud
Terraform – это способ указания ресурсов сразу для множества облаков. При помощи Terraform мы подготовим к работе пару облачных API и обустроим реестр артефактов (Artifact Registry). (Именно в этот реестр мы в конечном итоге поместим образ docker, в котором будет заключено наше приложение.)
main.tf – это главный файл Terraform (вот ссылка). В нём перечислены предоставляемые Google сервисы API, которыми мы будем пользоваться, этим сервисам даются имена, а также эти сервисы активируются. Информация в этом файле подразделяется на несколько чётко очерченных блоков:
- Метаданные terraform
- Регион провайдера и информация о проекте
- Блок, в котором представлен API реестра контейнеров
- (последние два блока) код, активирующий API реестра и команд для работы в облаке
Одна из не самых логичных черт terraform заключается в том, что он сам определяет, в каком порядке применять эти изменения. Поэтому совершенно нормально, что блоки, активирующие API, идут уже после блоков, создающих новые ресурсы для конкретных API.
В .terraform.version содержится та версия terraform, которой вы пользуетесь (чтобы это проверить, выполните terraform --version).
В файле variables.tf предоставляются метаданные по переменным, которые понадобятся вам в вашем проекте (вот ссылка).
Ещё есть дополнительный файл terraform.tfvars – он не включён в этот репозиторий и не должен быть публичным. Там содержатся настоящие имена переменных, используемых в вашем проекте Google Cloud. Содержимое этого файла выглядит примерно так:
# Настройки GCP
project_id = "YOUR PROJECT ID"
region = "YOUR REGION"
# Реестр артефактов
registry_id = "YOUR ARTIFACT REGISTRY NAME"В этом файле должно содержаться по записи на каждую переменную, содержащуюся в файле
variables.tf.Теперь выполните
terraform init. Если всё пройдёт успешно, то на экране должно появиться сообщение “Terraform has been successfully initialized!” (Инициализация Terraform прошла успешно).Далее выполните terraform plan, который поможет вам решить все вопросы, поставленные перед вами в
main.tf.Наконец, чтобы создать ресурсы GCP, примените terraform apply. Если всё пройдёт успешно, то вы увидите сообщение: “Apply complete! Resources: 3 added, 0 changed, 0 destroyed.” (Применено успешно! Ресурсы: 3 добавлено, 0 изменено, 0 уничтожено).
Если вы не хотите активировать все API через последний блок main.tf, то в качестве альтернативы можете сделать это через интерфейс командной строки Google Cloud CLI.
gcloud services enable artifactregistry.googleapis.com
gcloud services enable run.googleapis.comЕсли хотите проверить, какие сервисы вы активировали, выполните
gcloud services list --enabled. Если вы занимаетесь огромным проектом и хотите их немного отфильтровать, то, разумеется, можете при помощи grep добраться до интересующей вас информации. Так, gcloud services list --enabled | grep run позволяет проверить, есть ли в списке run.googleapis.com.❯ Python и API
Предварительная настройка
Выполните
poetry config virtualenvs.in-project true, чтобы виртуальные окружения оказались установлены в локальной папке с вашим проектом.Выполните
poetry install, чтобы установить окружение Python. Если всё сработает, то в проекте появится папка .venv. Если станете ею пользоваться, то Visual Studio Code может спросить вас, хотите ли вы выполнять в этом новоиспечённом окружении код Python. (Обратите внимание: poetry config virtualenvs.in-project true не всегда гладко взаимодействует с conda; по этому поводу в Poetry заявлена проблема, но кажется, что всё работало, если выбиралось окружение base от conda.)В этом репозитории, чтобы добиться максимально высокого качества кода, используется команда pre-commit. Можете выполнить её при помощи
poetry run pre-commit run --all-files. Поскольку это несущественно, а соответствующая спецификация пакетов – строго говоря, не код, я не включил в репозиторий файл .pre-commit-config.yaml с проверками, которые следовало бы проводить перед коммитом. В заявленном общем количестве строк кода он также не учитывается.Подготовка данных
Здесь вы можете выбрать любой небольшой датасет на ваш вкус. В данном случае, поскольку так интереснее, я собрал данные по смертности, которые были рассыпаны у меня по файлам в Excel в каком-то странном формате. Именно эти данные и будет выдавать нам API. Оригинальные файлы с данными находятся здесь. При работе с более крупными датасетами вам потребуется выполнить и шаг «загрузки» (“L” в аббревиатуре “ETL”), а также обеспечить, чтобы эти данные находились именно в той базе данных GCP, в которую мы посылаем запросы через API.
Обратите внимание: эти данные не включены в репозиторий, соответствующие скрипты Python вам придётся запускать самостоятельно!
В каталоге etl содепжится несколько скриптов на Python. Вот каковы их функции:
- etl/extract.py — скачивает со страницы ONS данные о смертях, распределённые по географическому принципу (на странице ONS есть Excel-файлы за каждый год). Скрипт скачивает их все. Вот ссылка.
- etl/transform.py – принимает скачанные файлы, открывает их, находит релевантные листы, очищает их, а затем складывает в столбики в чистом формате в специальном паркетном файле. Ссылка. Вот какие проблемы здесь возникают:
-
Имена рабочих листов со временем меняются
Форматы (расширения) файлов меняются
В новый файл могут быть добавлены новые данные. Например, если новые данные относятся к январю или добавляются в уже существующий файл, то впоследствии они будут связаны уже не с январём, а с другим месяцем.
- etl/main.py — это скрипт, вызывающий другие скрипты, предназначенные для извлечения и преобразования данных, а далее – для создания окончательного датасета scratch/deaths_data.parquet. Ссылка.
Чтобы создать те данные, которые мы впоследствии будем подавать, нужно выполнить
poetry run python etl/main.pyЗапуск API на локальной машине (опционально)
Если вы хотите использовать FastAPI на локальной машине, чтобы поднять ваш API и убедиться, что он работает, то сначала вам потребуется установить окружение Python (это делается при помощи poetry).
poetry run uvicorn app.api:app --reloadЗдесь app – это каталог, api.py – это скрипт, а второй app – это приложение FastAPI, определённое в api.py. В результате подаётся API в форме: /year/{YEAR-OF-INTEREST}/geo_code/{GEO-CODE-OF-INTEREST}. Например, если FastAPI работает на порту 0.0.0.0:8080, то 0.0.0.0:8080/year/2021/geo_code/E08000007 выдаст данные о смертности в Стокпорте за 2021 год (это город в Великобритании с локальным муниципальным кодом E08000007). Также можете попробовать 0.0.0.0:8080/docs, чтобы посмотреть, как сами собой получаются автоматические интерактивные документы для FastAPI!
❯ Развёртывание API в облаке
При помощи Terraform мы уже подготовили к работе Cloud Run API. Теперь план таков: собрать контейнер docker, в котором будет лежать всё, необходимое для выдачи API; далее на основе этого docker-файла нужно собрать образ, загрузить этот образ в реестр артефактов, который мы ранее создали в облаке Google Cloud, и далее выдавать API через Google Cloud Run. Первым делом нужно убедиться, что наша env нормально воспроизводится в файле docker.
Сборка образа docker
Можно организовать работу poetry (используемой в этом проекте) в файлах docker, но в таком случае что-то может пойти не так. Поэтому проще выполнить:
poetry export -f requirements.txt --output requirements.txtТакже убедитесь, что файл docker использует requirements.txt. Обратите внимание: поскольку мы готовим файл docker именно таким образом, файл requirements.txt добавлен в .gitignore. Так мы придерживаемся правила о единственном источнике истины: если одновременно подвергнуть контролю версий и requirements.txt, и pyproject.toml, то возникнет путаница: в котором же из этих файлов определяется окружение? А при нашем подходе всё ясно: в pyproject.toml устанавливаются зависимости Python, а файл requirements.txt расположен ниже него в дереве каталогов.
Обратите внимание, что у нас в dockerfile всего 16 строк кода, и этот код – абсолютный минимум, необходимый для обеспечения работоспособности API.
Также отметим, что имя deaths_data.parquet жёстко закодировано в dockerfile. Вероятно, есть способ как-то вытянуть имя файла данных из конфигурационного файла config.toml, где этот файл данных определён, но давайте не усложнять.
Тестирование контейнеризованного API на локальной машине (опционально)
При желании можете сначала проверить, работает ли ваш Dockerfile на локальной машине. Для этого выполните
docker build --pull --rm -f "Dockerfile" -t deploy-api:latest "."чтобы его собрать, а затем
docker run --rm -it -p 8080:8080/tcp deploy-api:latestчтобы запустить. Тогда в окне терминала должно появиться сообщение, включающее HTTP-адрес, по которому можно перейти. На самом деле, он находится не в Интернете… а у вас дома! Щёлкните по нему – и вы должны увидеть, как загружается ваш API. Например, с 0.0.0.0:8080 можно отправиться на 0.0.0.0:8080/docs, убедиться, что все документы загрузились, и опробовать API в действии.
Сборка образа docker для Google Cloud Run
Теперь начинаются осложнения. Я, например, работаю с Mac, где используется процессор с архитектурой arm64, он называется Apple Silicon. Но большинство облачных сервисов работает на базе Linux, где, как правило, применяются процессоры amd64. Если без изысков собрать образ на локальной машине и просто отправить его в Google Cloud, то получится образ, который не сможет работать на архитектуре Google. Поэтому нам потребуется мультиплатформенная сборка или же сборка, прицельно создаваемая под конкретную архитектуру. (Docker позиционируется как решение именно для этой проблемы, и при помощи Docker она действительно решается – правда, нужно немного постараться.)
Вам потребуется
docker buildx create --name mybuilder --bootstrap --useчтобы создать такой сборщик, который возьмётся за построение образа. Далее потребуется волшебная команда, при помощи которой мы соберём образ и отправим в репозиторий на google:
docker buildx build --file Dockerfile \
--platform linux/amd64 \
--builder mybuilder \
--progress plain \
--build-arg DOCKER_REPO=REGION-docker.pkg.dev/PROJECT-ID/REPOSITORY-NAME/ \
--pull --push \
--tag REGION-docker.pkg.dev/PROJECT-ID/REPOSITORY-NAME/deploy-api:latest .где REPOSITORY-NAME – это имя переменной registry_id в terraform.tfvars. Обратите внимание на аргумент “platform”.
Развёртывание
Теперь развернём приложение при помощи:
gcloud run deploy app --image REGION-docker.pkg.dev/PROJECT-ID/REPOSITORY-NAME/deploy-api:latest --region REGION --platform managed --allow-unauthenticatedЕсли всё пройдёт нормально, то на экране вы должны увидеть следующее сообщение:
Deploying container to Cloud Run service [app] in project [PROJECT-ID] region [REGION]
✓ Deploying new service... Done.
✓ Creating Revision...
✓ Routing traffic...
✓ Setting IAM Policy...
Done.А вот экземпляр, который я уже сделал раньше!
Действующую версию данного приложения вы можете взять в репозитории отсюда: app-qdvgjvqwza-nw.a.run.app. Здесь лежит документация. А вот пример, возвращающий данные. Обратите внимание на одно ограничение Cloud Run: если ссылкой давно не пользовались, то оно немного тормозит при запуске.
Заключение
Отмечу, что, если вся работа вашего API сводится к выдаче табличных данных, то такой функционал можно организовать и проще (хотя, куда уж проще, чем собрать API при помощи FastAPI). Можно воспользоваться отличной datasette. Здесь показан рабочий пример, в котором она выдаёт порцию данных. Представляется, что FastAPI была бы гораздо полезнее с данными, которые были бы структурированы гораздо нетривиальнее. Например, если при работе с данными их требуется одновременно записывать и читать, либо когда Cloud Run должен выполнять и другие действия (например, подтягивать информацию из базы данных Google).
Чем сильнее облачные сервисы переходят в категорию потребительских решений, и чем больше классных разработок появляется на языке Python, тем проще становится создавать высококачественные API. Хотя, тут есть некоторые детали, над которыми требуется поломать голову, просто удивительно, насколько быстро можно создать рабочий API —и какой минимум кода для этого требуется.

souls_arch
На джава спринг бут веб/флакс - да за нех петь. Можно модулями/сервисами в стопки класть.