
Гексагональная архитектура — это архитектурный паттерн, представленный Алистером Кокберном и описанный у него в блоге в 2005 году. Основная идея заключается в том, чтобы структурировать приложение таким образом, чтобы это приложение можно было разрабатывать и тестировать в изоляции, не завися от внешних инструментов и технологий.
Вот как сам Кокберн описывает эту архитектуру одним тезисом:
Добиться, чтобы приложение в равной степени могло управляться пользователями, программами, автоматизированными тестовыми или пакетными сценариями, а также разрабатываться и тестироваться в изоляции от устройств и баз данных, на которых оно впоследствии будет выполняться. — Алистер Кокберн, 2005 г.
В этой статье мы рассмотрим некоторые задачи, как правило, решаемые в типичных программных проектах. Затем мы поговорим о гексагональной архитектуре и о том, как она призвана решить эти задачи. Мы также рассмотрим некоторые детали реализации такой архитектуры и варианты тестирования.
❯ Какие сложности могут возникать при традиционном подходе
Прежде чем подробно остановиться на гексагональной архитектуре, рассмотрим некоторые типичные задачи, с которыми мы можем столкнуться при работе с крупномасштабными приложениями.
На фронтенде бизнес-логика приложения просачивается в пользовательский интерфейс. В результате эту логику трудно тестировать, поскольку она связана с пользовательским интерфейсом. Кроме того, логика плохо поддаётся использованию в других сценариях, и трудно перейти от человеко-управляемых к программно-управляемым сценариям.
На бэкенде бизнес-логика оказывается связанной с базой данных или со внешними библиотеками и сервисами. Это опять же затрудняет тестирование логики из-за сильной связи компонентов. Также становится сложнее переходить от одной технологии к другой или обновлять технологический стек.
Чтобы решить проблему смешения бизнес-логики и технологических деталей, часто используют многоуровневую архитектуру. Предполагается, что, распределив разнородные проблемы по отдельным слоям, удастся надёжно разделить их.
Многоуровневая архитектура:
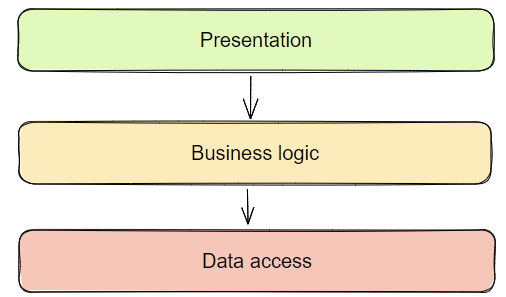
Business logic // Бизнес-логика
Data Access // Доступ к данным
Компонентам любого уровня мы разрешаем обращаться только к таким другим компонентам, которые расположены на том же уровне или ниже. Теоретически это должно защитить нас от смешения различных зон ответственности. Проблема заключается в том, что не существует четкого механизма, который позволял бы выявлять нарушения этого требования, и со временем мы обычно оказываемся в той самой ситуации, которой пытались избежать.
Когда уровень доступа к данным находится внизу, вся система проектируется на основе того, как устроена база данных. Когда мы разрабатываем сценарии использования, мы в первую очередь должны моделировать поведение, а персистентность – это, прежде всего, хранение состояния. Не лучше ли начать с бизнес-логики приложения?
Эти сущности легко просачиваются на вышестоящие уровни, из-за чего приходится менять бизнес-логику при реорганизации персистентности. Если приходится менять способ сохранения данных, то почему это должно привести к изменению бизнес-логики?
Вышеизложенное представление является предельно упрощённым, и в реальности редко бывает таковым. В реальности нам необходимо взаимодействовать с внешними службами или библиотеками, и не всегда понятно, где их место.
Многоуровневая архитектура с большим количеством компонентов:
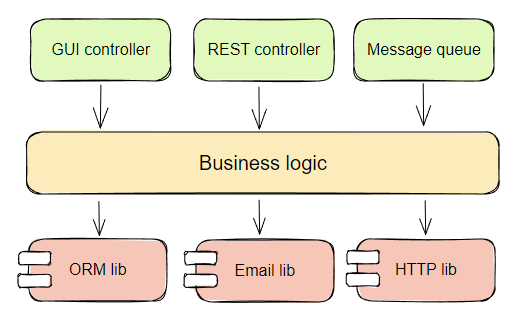
REST controller // REST-контроллер
Message queue // Очередь сообщений
Business logic // Бизнес-логика
ORM lib // Библиотека ORM
Email lib // Библиотека электронной почты
HTTP lib // Бибилиотека HTTP
При необходимости добавления новых компонентов требуется обновлять архитектурные уровни. Это чревато попытками срезать углы и утечкой технических деталей в бизнес-логику, например, при прямом обращении к сторонним API.
Всё изложенное должно побудить нас к поиску альтернатив. Может быть, есть какие-то более качественные варианты оформления архитектуры?
❯ Что такое гексагональная архитектура?
Как уже отмечалось выше, основная идея гексагональной архитектуры заключается в том, чтобы отделить бизнес-логику от внешнего мира. Вся бизнес-логика заключена внутри приложения, а все внешние сущности — за его пределами. Внутренняя часть приложения не должна знать о внешней.
Мы стремимся, чтобы приложение в равной степени поддавалось управлению и со стороны пользователей, и других программ, и даже тестов. Должна быть возможность разрабатывать и тестировать бизнес-логику безотносительно фреймворков, баз данных или внешних сервисов.
Порты и адаптеры
Чтобы отделить бизнес-логику от внешнего мира, сделаем так, чтобы приложение взаимодействовало с внешним миром только через порты. Эти порты описывают суть коммуникации между двумя сторонами. Для приложения не имеет значения, каковы технические детали реализации портов.
Адаптеры обеспечивают связь приложения с внешним миром. Они преобразуют внешние сигналы в форму, понятную приложению. Адаптеры взаимодействуют с приложением только через порты.
Разделение бизнес-логики и инфраструктуры в гексагональной архитектуре:
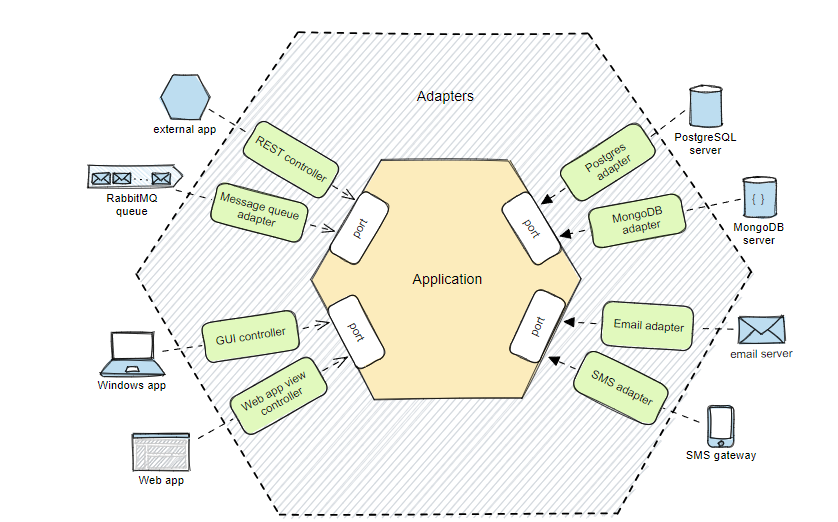
Application // Приложение
Port // Порт
External app // Внешнее приложение
RabbitMQ queue // Очередь RabbitMQ
Windows app // Приложение для Windows
Web app // Веб-приложение
PostgreSQL server // Сервер PostgreSQL
MongoDB server // Сервер MongoDB
Email server // Сервер электронной почты
SMS gateway // SMS-шлюз
REST controller // REST-контроллер
Message queue adapter // Адаптер очереди сообщений
GUI controller // Контроллер GUI
Web app view controller // Контроллер представления веб-приложения
Postgres adapter // Адаптер Postgres
MongoDB adapter // Адаптер MongoDB
Email adapter // Адаптер электронной почты
SMS adapter // Адаптер SMS
Любой порт может иметь несколько адаптеров. Адаптеры могут быть взаимозаменяемыми с обеих сторон, не затрагивая бизнес-логику. Это позволяет легко масштабировать решение для использования новых интерфейсов или технологий.
Например, в приложении для кофейни может быть пользовательский интерфейс кассы, который обрабатывает прием заказов на кофе. Когда бариста отправляет заказ, REST-адаптер принимает HTTP-запрос POST и преобразует его в форму, понятную порту. При вызове порта запускается бизнес-логика, связанная с оформлением заказа внутри приложения. Само приложение не знает, что оно работает через REST API.
Адаптеры преобразуют поступающие извне сигналы, передавая их приложению:

Save order // Сохранение заказа
Web app // Веб-приложение
REST adapter // REST-адаптер
Port // Порт
Application // Приложение
Flow of control // Поток управления
Database adapter // Адаптер базы данных
Database // База данных
С другой стороны, приложение взаимодействует с портом, который позволяет сохранять заказы. Если бы мы хотели использовать в качестве хранилища информации реляционную базу данных, то подключение к ней было бы реализовано через адаптер базы данных. Адаптер принимает информацию, поступающую из порта, и преобразует её в SQL-запрос для хранения заказа в базе данных. Само приложение не знает, как реализован данный функционал, и какие технологии при этом используются.
Во многих статьях, рассказывающих о гексагональной архитектуре, упоминаются уровни (layers). Однако в оригинальной статье об уровнях ничего не говорится. Есть только внутренняя и внешняя части приложения. Также ничего не говорится о том, как реализуется внутренняя часть. Определим ли мы свои собственные уровни, организуем компоненты по признакам или применим паттерны DDD (предметно-ориентированного проектирования) — всё зависит от нас.
Первичные и вторичные адаптеры
Как мы убедились, некоторые адаптеры вызывают сценарии использования приложения, а другие реагируют на действия, выполняемые приложением. Адаптеры, которые управляют приложением, называются первичными или управляющими адаптерами, они обычно изображаются в левой части схемы. Адаптеры, управляемые приложением, называются вторичными или управляемыми адаптерами, которые обычно располагаются в правой части схемы.
Первичный и вторичный адаптеры с вариантами использования на границе приложения:
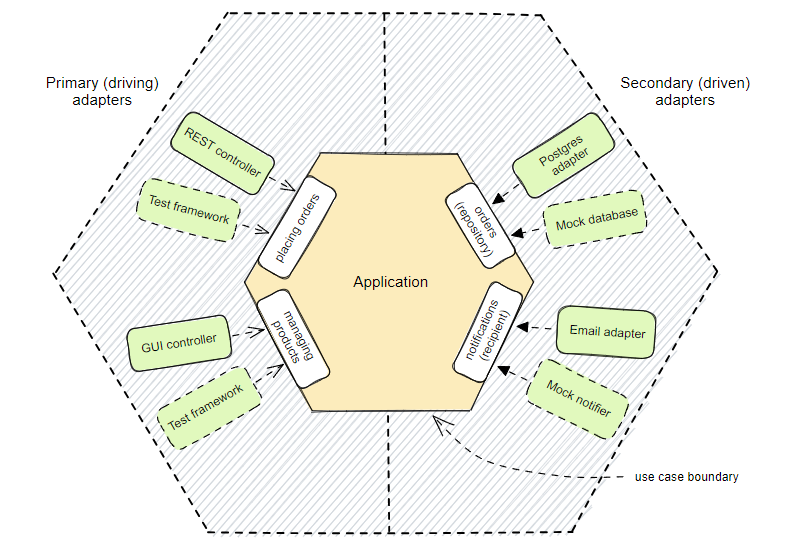
Secondary (driven) adapters // Вторичные (управляемые) адаптеры
REST controller // REST-контроллер
Test framework // Фреймворк тестирования
GUI controller // GUI-контроллер
Placing orders // Размещение заказов
Managing products // Управление продуктами
Application // Приложение
Orders (repository) // Заказы (репозиторий)
Notifications (recipient) // Уведомления (получатель)
Postgres adapter // Адаптер Postgres
Mock database // Фиктивная база данных
Email adapter // Адаптер электронной почты
Mock notifier // Фиктивный уведомитель
Use case boundary // Границы вариантов использования
Различие между первичными и вторичными участниками основано на том, кто инициирует взаимодействие. Такая метафора проистекает из примеров, в которых выделяются главные и второстепенные действующие лица.
Первичный агент — это агент, выполняющий одну из функций приложения. Поэтому порты приложения естественным образом подходят для описания вариантов использования приложения. Вторичный агент — это участник, от кого приложение получает отклики или которого оно уведомляет. Таким образом, вторичные порты можно грубо подразделить на две категории: репозитории и получатели.
Варианты использования должны быть описаны на границе приложения. Вариант использования не должен содержать подробной информации о технологиях, не присутствующих в пределах приложения. Гексагональная архитектура может повышать качество описания примеров использования.
Типичная ошибка заключается в том, что мы пишем сценарии использования, держа в уме конкретные технологии. Такие сценарии использования не излагаются на языке предметной области, тесно увязываются с используемыми технологиями, и поэтому их сложнее поддерживать.
❯ Реализация
До сих пор мы говорили только о том, что технические детали должны оставаться за пределами приложения. Связь между адаптерами и приложением должна идти только через порты. Давайте посмотрим, как это воплощается на практике.
Инверсия зависимостей
Когда мы реализуем первичный адаптер на стороне ведущего, адаптер должен сообщить приложению, что нужно сделать. Поток управления идет от адаптера к приложению через порты. Зависимость между адаптером и приложением направлена вовнутрь, поэтому приложение не знает, «кто» вызывает сценарии его использования.
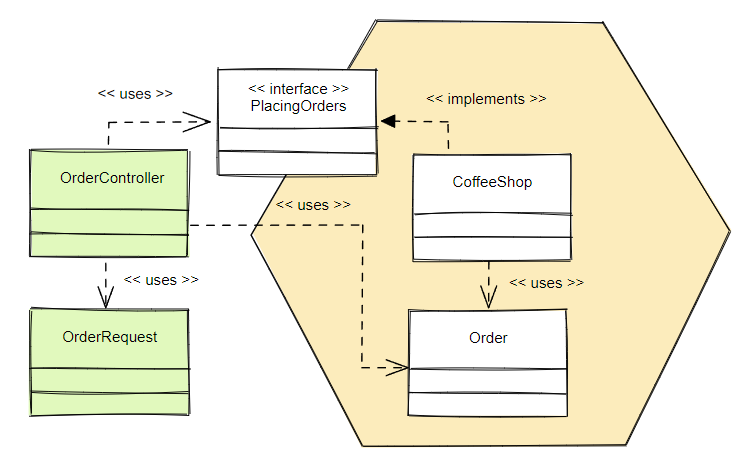
Реализация первичных адаптеров:

Flow of control // Поток управления
Dependencies // Зависимости
В нашем примере кофейни OrderController – это адаптер, который вызывает сценарий использования, определенный портом PlacingOrders. Внутри приложения CoffeeShop — это класс, реализующий функционал, описанный портом. Приложение не знает, «кто» вызывает его сценарии использования.
Когда мы реализуем вторичный адаптер на управляемой стороне, поток управления выходит за пределы приложения, поскольку мы должны приказать адаптеру базы данных сохранять заказ. Однако наш архитектурный принцип гласит, что приложение не должно быть осведомлено о деталях внешнего мира.
Для этого необходимо применить принцип инверсии зависимостей.
Высокоуровневые модули не должны зависеть от низкоуровневых. И те, и другие должны зависеть от абстракций (например, интерфейсов). Абстракции не должны зависеть от деталей реализации. Детали (конкретные реализации) должны зависеть от абстракций. — Robert C. Martin, 2003
В нашем случае это означает, что приложение не должно напрямую зависеть от адаптера базы данных. Вместо этого приложение должно использовать порт, а адаптер должен реализовать этот порт.
Реализация вторичных адаптеров:
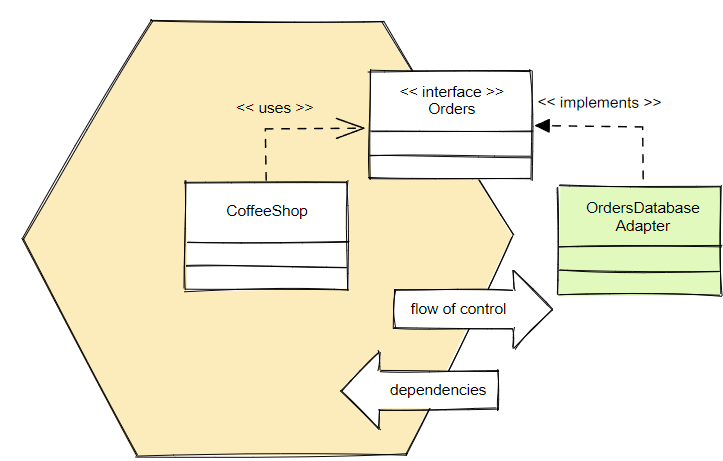
Flow of control // Поток управления
Dependencies // Зависимости
Реализация CoffeeShop не должна напрямую зависеть от реализации OrdersDatabaseAdapter, а должна использовать интерфейс Orders и позволить OrdersDatabaseAdapter реализовать этот интерфейс. Так инвертируется зависимость и, фактически, отношения диаметрально меняются.
Можно также сказать, что CoffeeShop имеет настраиваемую зависимость от интерфейса Orders, который реализуется OrdersDatabaseAdapter. Аналогично, OrderController имеет настраиваемую зависимость от интерфейса Orders, реализуемого CoffeeShop. Для настройки этих зависимостей мы можем использовать инъекцию зависимостей в качестве паттерна реализации.
Отображение в адаптерах
Адаптеры должны переводить сигналы внешнего мира в вид, понятный приложению, и наоборот. Практически это означает, что адаптеры должны отображать любые модели приложения на модель адаптера и наоборот.
В нашем примере для разграничения внешней и внутренней модели можно ввести модель OrderRequest, которая представляет данные, поступающие в адаптер в виде REST-запроса. Контроллер OrderController теперь отвечает за отображение OrderRequest в модель Order, понятную приложению.
Отображение моделей в первичных адаптерах:
Аналогичным образом, когда адаптеру необходимо ответить вызывающему его агенту, мы можем ввести модель OrderResponse и позволить адаптеру отобразить модель Order из приложения в модель ответа.
Может показаться, что это лишняя работа. Мы могли бы просто возвращать модели из приложения напрямую, но тогда создаётся несколько проблем.
Во-первых, если нам нужно, например, отформатировать данные, то мы должны записать в приложение знания, специфичные для конкретной технологии. Это нарушает архитектурный принцип, согласно которому приложение не должно знать о деталях внешнего мира. Если другому адаптеру потребуется использовать те же данные, переиспользование модели может оказаться невозможным.
Во-вторых, мы усложняем рефакторинг внутри приложения, поскольку наша модель теперь открыта внешнему миру. Если кто-то будет полагаться на предоставляемый нами API, то мы будем вносить разрушающие изменения при каждом заходе на рефакторинг нашей модели.
С другой стороны, в описываемом здесь приложении мы могли бы ввести модель OrderEntity для описания деталей, необходимых для сохранения данных. Теперь специфичный для данной технологии OrdersDatabaseAdapter отвечает за преобразование модели Order из приложения в сущность, способную работать с уровнем персистентности.
Отображение моделей во вторичных адаптерах:
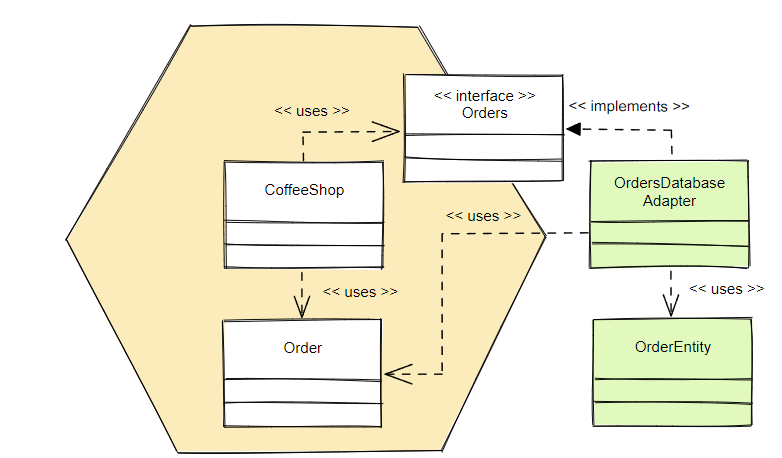
Опять же, использование единой модели для сущностей базы данных и приложения может быть заманчивым, но такой подход сопряжен с определенными издержками. Нам придется учесть в модели приложения детали, специфичные для конкретной технологии. В зависимости от используемого технологического стека, это может означать, что теперь вам придется учитывать в рамках бизнес-логики и такие детали, как транзакции и ленивая загрузка.
❯ Тестирование
При создании гексагональной архитектуры одной из целей постулировалось возможность тестирования бизнес-логики безотносительно внешних инструментов и технологий. Это естественным образом вытекает из принципа разделения ответственности, реализованного с помощью портов и адаптеров. Без такого разделения возможности тестирования значительно сужаются, и возникает тенденция к расширению тестов.
Тестирование бизнес-логики
Первым шагом в реализации практического сценария будет тест, описывающий его. Мы начинаем с приложения, работающего по принципу «чёрного ящика» и разрешаем тесту вызывать приложение только через его порты. Также следует заменить все вторичные адаптеры на имитационные.
Модульное тестирование бизнес-логики:
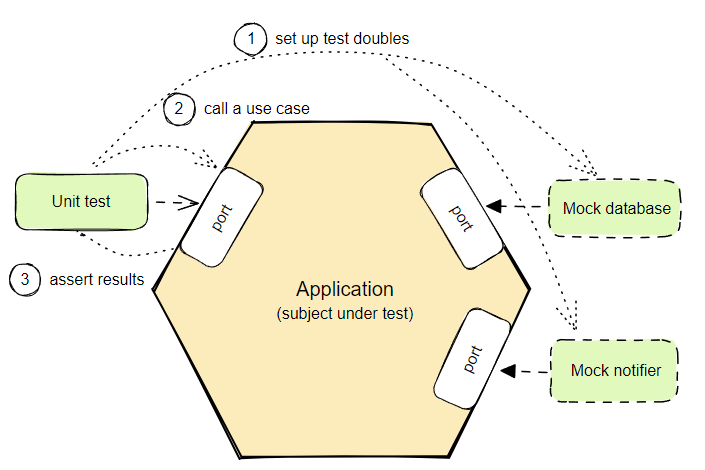
Call a use case // Вызов практического сценария
Assert results // Утверждение результатов
Unit test // Модульный тест
Mock database // Фиктивная база данных
Mock notifier // Фиктивный уведомитель
Port // Порт
Application (subject under test) // Приложение (то самое, которое мы тестируем)
Хотя здесь можно использовать фреймворк mocking, написание собственных mocks или stubs окажется полезным в дальнейшем. Для любых адаптеров репозиториев эти имитаторы могут быть простыми картами значений.
Tестирование первичных адаптеров
Следующий шаг — подключение к приложению нескольких адаптеров. Обычно мы начинаем со стороны основного адаптера. Так мы обеспечим, чтобы приложением могли управлять реальные пользователи.
Для вторичных адаптеров можно и далее использовать имитационные варианты, созданные на предыдущем этапе. Затем наши узкие интеграционные тесты будут вызывать первичный адаптер для тестирования. Фактически, мы можем поставлять первую версию нашего решения с вторичными адаптерами, реализованными в виде заглушек.
Тестирование первичных адаптеров:

Make an HTTP request // Выполнение HTTP-запроса
Integration test // Интеграционный тест
REST controller (subject under test) // REST-контроллер (тестируемый объект)
Assert HTTP response // Утверждение HTTP-отклика
Mock database // Фиктивная база данных
Mock notifier // Фиктивный уведомитель
Port // Порт
Application // Приложение
Например, интеграционный тест может выполнять некоторые HTTP-запросы к REST-контроллеру и утверждать, что ответ соответствует нашим ожиданиям. Хотя REST-контроллер вызывает приложение, приложение не является тестируемым объектом.
Если в этих тестах мы будем использовать тестовый двойник приложения, то нам придется тщательнее проверять взаимодействия между адаптером и приложением. Если мы имитируем только адаптеры, изображённые справа, то можем сосредоточиться на проверке состояния после прохождения модульного теста (state-based testing).
В этих тестах мы должны проверить только обязанности контроллера. Каждый сценарий использования приложения можно протестировать в отдельности.
Тестирование вторичных адаптеров
Когда приходит время реализовать адаптеры изображённые справа, требуется удостовериться, что интеграция со сторонней технологией прошла корректно. Можно не подключаться к удаленной базе данных или сервису, а контейнеризировать базу данных или сервис и настроить тестируемый объект так, чтобы он к ним подключался.
Тестирование вторичных адаптеров:

Call an adapter // Вызов адаптера
Assert results // Утверждение результатов
Port // Порт
Integration test // Интеграционный тест
Postgres adapter (subject under test) // Адаптер Postgres (тестируемый объект)
Database test container // Тестовый контейнер базы данных
Например, в Java для замены реальной удаленной базы данных или сервиса можно использовать что-то вроде Testcontainers или MockWebServer. Так мы сможем использовать базовую технологию локально, не завися от доступности внешних сервисов.
Сквозные тесты
Хотя и можно покрыть различные части системы модульными и интеграционными тестами, для искоренения всех проблем этого недостаточно. Для комплексного тестирования нам пригодятся сквозные тесты (также именуемые широкими интеграционными или системными).
Сквозное тестирование системы:
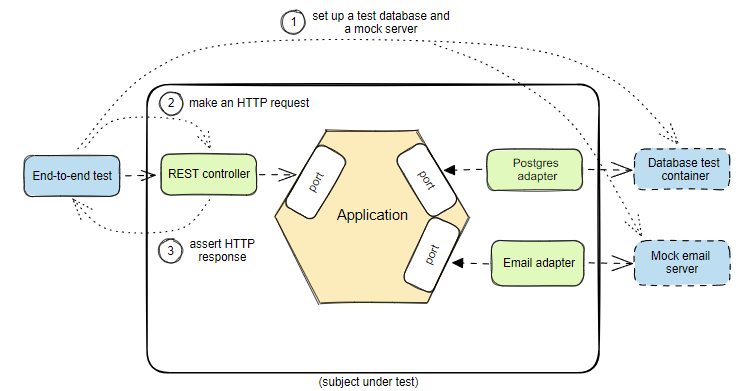
Make an HTTP request //Выполнение HTTP-запроса
Assert HTTP response // Утверждение HTTP-отклика
End-to-end test // Сквозной тест
Rest controller // REST-контроллер
Port // Порт
Application // Приложение
Postgres adapter // Адаптер Postgres
Email adapter // Адаптер электронной почты
Database test container // Тестовый контейнер базы данных
Mock email server // Фиктивный почтовый сервер
(subject under test) // (тестируемый объект)
Мы по-прежнему можем изолировать систему от внешних сервисов, но при этом тестировать ее как единое целое. Эти сквозные тесты охватывают целые фрагменты системы — от первичных адаптеров до приложения и вторичных адаптеров.
В этих тестах мы стремимся проверить основные пути, по которым выполняется приложение. Цель состоит не в проверке функциональных сценариев использования, а в том, правильно ли скомпоновано приложение и работает ли оно как надо.
Очевидно, что такой подход приведет к появлению взаимно дублирующих тестов. Чтобы избежать многократного тестирования одних и тех же сущностей, на разных уровнях, важно продумать зону ответственности тестируемого субъекта.
❯ Преимущества и недостатки
Хорошая архитектура позволяет постоянно менять программное обеспечение с минимальными усилиями со стороны разработчика. Цель – минимизировать эксплуатационные издержки системы и максимизировать её производительность.
Гексагональная архитектура обладает рядом преимуществ, способствующих достижению этих целей:
- Мы можем начать работу, а о конкретных деталях определиться позже (например, о том, какой фреймворк или базу данных использовать).
- Мы можем менять бизнес-логику, не трогая адаптеры.
- Мы можем заменять или обновлять инфраструктурный код, не затрагивая бизнес-логику.
- Мы можем подробно описывать сценарии использования, не вдаваясь в технические детали.
- Информативно именуя порты и адаптеры, можно качественнее разграничить зоны ответственности и снизить риск просачивания технических деталей в бизнес-логику.
- Мы получаем возможность тестировать части системы как в отдельности друг от друга, так и группируя их.
Как и у любого решения, у гексагональной архитектуры есть свои недостатки.
- Для простых решений (например, CRUD-приложений или технических микросервисов) она может оказаться переусложнённой (оверинжиниринг).
- Требуется прилагать усилия, создавая отдельные модели и отображения между ними.
В конечном итоге решение об использовании гексагональной архитектуры зависит от того, насколько сложна создаваемая система. Всегда можно начать с относительно простого подхода и развивать архитектуру по мере необходимости.
❯ Итоги
Основная идея гексагональной архитектуры заключается в том, чтобы отделить бизнес-логику от деталей реализации. Это достигается путем разграничения проблем с помощью интерфейсов.
С одной стороны приложения мы создаём адаптеры, использующие предоставляемые приложением интерфейсы. Это могут быть, например, контроллеры, управляющие работой приложения. С другой стороны приложения создаются адаптеры, реализующие интерфейсы приложения. Это могут быть, например, хранилища, из которых приложение получает отклики.
Возможно, захочется почитать и это:
- ➤ Гиковский КПК за копейки: как китайцы сделали ARM-ноутбук за 40$ с железом от… навигатора?
- ➤ Data-Oriented архитектура
- ➤ Скромное обаяние ClimateGuard CG Mini
- ➤ Web-сервер с двухуровневой иерархией ЦС. Авторизация по SSL
- ➤ Как создавалась Mount & Blade

Комментарии (37)

Zenitchik
02.11.2023 09:12+11Я так понял, что автор проспорил желание и должен был включить в свою разработку слово "шестиугольник"?
Гексагонального в гексагональной архитектуре столько же, сколько пигвинного в пигнвинной диаграмме.

piton_nsk
02.11.2023 09:12+4Когда уровень доступа к данным находится внизу, вся система проектируется на основе того, как устроена база данных.
А если доступ к данным на картинке не снизу, а сбоку, то все хорошо становится? Смысл отдельного уровня доступа данным как раз в абстракции. Как "нахождение снизу" этому мешает?
Не лучше ли начать с бизнес-логики приложения?
Если лучше начать с бизнес-логики, то как многоуровневая архитектура этому мешает?
Port // Порт
Информативное описание, без перевода тут никак.
Основная идея гексагональной архитектуры заключается в том, чтобы отделить бизнес-логику от деталей реализации. Это достигается путем разграничения проблем с помощью интерфейсов.
В обычной трехслойной архитектуре идея та же самая. Так в чем разница?

AlexViolin
02.11.2023 09:12+4Уже много лет читаю про гексогональную литературу и мне совершенно очевидно, что она совершенно легко и просто трансформируется в обычную многослойную архитектуру. Не могу понять зачем надо так упорно говорить отдельно о гексогональной и отдельно о многослойной архитектуре???
piton_nsk
02.11.2023 09:12+2Полностью согласен, от того что 3 слоя свернули суть не меняется. Хотел узнать про разницу от автора статьи. Но автор похоже просто переводчик и переводит все подряд.

DExploN
02.11.2023 09:12+1Все же это с разных углов. Когда мы говорим о многослойности, то говорим о том, что есть слой контроллеров, слой логики, слой БД. Еще какие ровные слои бутерброда.
Когда говорим о гексагональной архитектуре, то основное - это блоки, у которых есть порты входа и выхода. Интерфейсы (контракты), через которые идет общение с этими блоками и никак иначе.
При этом если мы делаем гексагональную, у нас может и не быть правильного бутерброда, потому что внутри блока может быть лапша логики и БД.
С другой стороны мы можем делать слои, но при этом общаться в приложении как угодно, не имея нормальных контрактов и отдельных блоков, модулей как таковых. Например из сервиса одного модуля, вызвали репозиторий другого и работем с его сущностями. Вроде бы бутерброд слоев соблюдается,а гексагоналка нет.
Но никто не мешет использовать их обе, и это идеально.
Думаю можно еще так разделить:
Гексагональная архитектура больше про coupling и cohesion.
Слоистая, луковая - про инверсию зависимостей.
funca
02.11.2023 09:12В DDD это обозначается другими словами:
Primary adapters -> Application layer
Secondary adapters -> Infrastructure layer
Hexagon -> Domain model layer
Знать про гексагональную архитектуру полезно. Но это скорее архитектурный паттерн, чем конкретная архитектура, не смотря на название, чтобы использовать при разработке приложения.
DExploN
02.11.2023 09:12Наше всё приложение - это не 1 гексагон. Наше приложение - это куча гексагончиков.
piton_nsk
02.11.2023 09:12Когда говорим о гексагональной архитектуре, то основное - это блоки, у которых есть порты входа и выхода. Интерфейсы (контракты), через которые идет общение с этими блоками и никак иначе.
Как может быть иначе? У любого модуля есть некий интерфейс через который с ним общаются.
Вот такой на лету выдуманный пример. Есть несколько разных блоков/модулей. А выход один - пдф, как тут быть? Считаем что у каждого блока свой выход? Но выход-то один.
Например из сервиса одного модуля, вызвали репозиторий другого и работем с его сущностями.
Непонятно. Что такое модуль в данном случае? Репозиторий это слой данных, как репозиторий может принадлежать какому-то модулю?
DExploN
02.11.2023 09:12+2В том то и дело, что в слоенной архитектуре нет понятия модулей. Там только слои. В этом как раз и разница: луковая архитектура про разделение на слои, гексагональная про модули, а главное про сохранение их границ.
Например у нас есть кейс оформить заказ и доставку.
И в луковой вы вполне спокойной делаете подряд в одном методе
order = ...
orderRepository.add(order)
delivery = ...
deliveryRepository.add(delivery)
Вроде все по слоям, слой БД, слой логики.
Если бы мы сюда пригнали еще гексагональную, то скорее всего был бы модуль доставки и модуль заказов. А главное, что в модуле заказов нельзя работать с сущностями доставки напрямую. Было бы или два независимых вызова модулей или бы создание доставки через контракт этого модуля, но никак не создании сущности в другом модуле.
order = ...
orderRepository.add(order)
deliveryModule.create(deliveryCreateDto).
Поидее много разных архитектур говорят об одном и том же.
Например берем тот же DDD.
Слоистая архитектура - это разделение на Infrastructure, Domain, Application
А гексагональная - это разделение на контексты.
Слова вроде разные, а смысл в реализации почти один.piton_nsk
02.11.2023 09:12А главное, что в модуле заказов нельзя работать с сущностями доставки напрямую. Было бы или два независимых вызова модулей
Вот. А где были бы эти два вызова? Это какой-то отдельный модуль, что это за сущность, где вот этот код
order = ...orderRepository.add(order)deliveryModule.create(deliveryCreateDto).
DExploN
02.11.2023 09:12Это можно сделать как отдельно в своих модулях, так и в модуле заказа.
Основное, что нельзя просто взять класс/функционал из другого модуля и работать с ней где угодно. Работать только по публичным контрактам модуля. В этом смысл гексагоналки.
Т.е. допустим мы создали два модуля : Orders, Users
А потом взяли, и в orders заизжектили репозиторий юзера и достали сущность юзера и как то с ней начали работать, менять именно в моделк Orders - всё, гексагональная архитектура сломана.piton_nsk
02.11.2023 09:12Работать только по публичным контрактам модуля.
Это вообще от архитектуры не зависит. Как можно работать не по публичным контрактам модуля? Ковыряться в сырой памяти или reflection использовать?
Это можно сделать как отдельно в своих модулях, так и в модуле заказа.
Получается нужно три модуля, заказов, доставки и некий общий модуль.
Т.е. допустим мы создали два модуля : Orders, Users
А потом взяли, и в orders заизжектили репозиторий юзера и достали сущность юзера и как то с ней начали работать, менять именно в моделк Orders
Опять вопрос - что такое модуль? И в данном примере, если модуль Orders (или любой другой) использует модуль Users, это получается нормально?
DExploN
02.11.2023 09:12+1Это вообще от архитектуры не зависит. Как можно работать не по публичным контрактам модуля? Ковыряться в сырой памяти или reflection использовать?
Берутся и используются классы другого модуля напрямую. Кто может этому помешать? Модуль - это логическая единица.
Допустим мы разделили проект на модуль Orders (тут работает команда,которая работает с заказами), и модуль Users (Тут работает команда отвечающая за регистрацию и профили). Без каких либо привязок к языку. Просто папочки и классы.
И вот команде Orders понадобился email пользователя. И тут есть 2 способа (берем самые простые, естественно есть другие с дубликатом емейла):
1) Дергается репозиторий usersRepository.get(userId).getEmail. Команда Users об этом ничего не знает, потом они каким то образом меняют getEmail на getMail - все крашится.
2) Дергается публичный контракт, где UserDto. usersModule.query.get(userId). Команда отвечающая за юзеров сама его предоставила и знает что он публичный, отвечает за его поддержку. Но она отвечает только за поддержку контрактов, а не любого публичного метода любого класса.
Тут опять все смешивается к тому, что это похоже на anticorruption layer. Но в целом так и есть. Многие вещи и термины говорят о решениях одних и тех же проблем, но разным языком.
Все это про инкапсуляцию, только на уровне модулей и связей подссистем.piton_nsk
02.11.2023 09:12Берутся и используются классы другого модуля напрямую. Кто может этому помешать? Модуль - это логическая единица.
Теперь понятно что имеется в виду, спасибо.
funca
02.11.2023 09:12+1order = ...
orderRepository.add(order)
delivery = ...
deliveryRepository.add(delivery)
По-моему гексагональная архитектура это больше про контакты с внешним миром и зависимости. Вот здесь (адаптеры) дёргают нас (за primary ports), вот здесь (адаптеров) дергаем мы (через secondary ports) - и контракты (сами ports), которые всегда на нашей стороне (у гексагона).
Гексагон хранит ссылки на всех secondary adapters. Поэтому в теории может общаться с ними как угодно - архитектура не накладывает на внутренние устройство гексагона ограничений. Здесь решение остаётся за разработчиком.
DExploN
02.11.2023 09:12+1Про любые контракты, не важно внешние или внутренние. Мы делим свой код на блоки-гексагоны, которые общаются исключительно контрактами друг с другом. Блок - внешняя апи, или же другой контекст DDD - не имеет значение.
Основной поинт и смысл всего этого - это low coupling. Чтобы границы были четко определены, тем самым можно легко следить за изменениями и расширениями. Иначе кто то просто что-то заюзал из внутренней реализации, и как за этим можно следить? Да никак. А за четко определенными контрактами - можно.
Upd. Какая например разница, кто вызвал создание заказа cli, http, или другой модуль? Почему другой модуль не такая же абстракция как cli или http ?funca
02.11.2023 09:12Мы делим свой код на блоки-гексагоны, которые общаются исключительно контрактами друг с другом.
Гексагоны не могу общаться непосредственно друг с другом, поскольку каждый гексагон выставляет наружу свои контракты (ports) на только одному ему понятном языке.
Учить языки друг друга в их мире запрещено - чтобы не было соблазна случайно обзавестись на стороне порочными связями или вредными зависимостями.
Чтобы как-то общаться, они отращивают снаружи себе адаптеры, которые переводят с одного языка на другой (возможно даже через третий, на котором принято передавать сообщения на расстояние). В итоге простое и приятное в принципе занятие - перекинуться со знакомым парой слов - превращается в бюрократический ад.
Идея выглядит жизнеспособнной, когда у вас гексагон наделен богатым внутренним миром и есть что охранять. Если же задача системы состоит в основном в передаче друг другу каких-нибудь отчётов, то вся логика уходит в адаптеры, а гексагон оказывается голым прокси-менеджером. Тогда у стороннего наблюдателя возникает резонный вопрос: и ради чего весь этот огород?
DExploN
02.11.2023 09:12+1Давайте проведем мысленный эксперимент:
По вашей логике у нас есть только приложение, у которого есть контракты входа и выхода (порты адаптеры). К ним подключаются контроллеры, cli, базы, мейл сервисы. Это все нарисовано на картинках, думаю с этим всё ок.
Возьмем для примера, что мейл сервис - это тоже наше приложение, мы реализовали свой сервис с 0 по отправке емейлов. Мы этот сервис тоже пишем в гексагональной архитектуре. И вот у нас уже 2 гексагона общаются между собой через порты адаптеры :)
А чем мейл сервис отличается от микросервиса авторизации, который лежит на соседнем сервере? У него такое же апи и мы так же с ним общаемся. Почему бы нас не сделать тоже его в гексагональной архитектуре? И вот у нас уже 3 гексагона общаются между собой и все наши.
А потом мы подумали, а почему авторизация это микросервис? Это дополнительные сетевые накладки. Мы втягиваем его в свой монолит отдельным модулем, а меняем только протокол общения с HTTP на локальный, просто подменив адаптеры/anticoruption layer. Но авторизация осталась таким же гексагоном, внутри нашего же проекта, но отдельным модулем.
И вот мы получили два гексагона (основной проект и авторизация) в одном проекте.
Далее мы дробим основной проект на подмодули - более мелкие гексагоны по такому же принципу как авторизация.
В чем я ошибаюсь?
Опять же, если говорить, что зависим только от абстракций, какая разница мы подключаемся к БД или другому нашему модулю? На то это и абстракция, что мы не знаем что находится на другой стороне, но нам это и не нужно.funca
02.11.2023 09:12+1Ни в чем. Просто HA это как правила личной гигиены для отдельно взятого гексагона, а не - организации взаимодействия в их системе. Там просто по дедукции получается, что для взаимодействия нужно что-то придумывать, но эти вопросы уже за рамками.

sswwssww
02.11.2023 09:12+4Вот что пишет сам автор этой "концепции" об этом:
Многие приложения имеют только два порта: диалог на стороне пользователя и диалог на стороне базы данных. Это придает им асимметричный вид, что делает естественным создание приложения в одномерной, трех-, четырех- или пятиуровневой многоуровневой архитектуре.
С этими рисунками есть две проблемы. Первое и самое худшее то, что люди склонны не воспринимать всерьез «линии» в многослойном рисунке. Они позволяют логике приложения выходить за границы уровней, вызывая проблемы, упомянутые выше. Во-вторых, в приложении может быть более двух портов, поэтому архитектура не умещается в одномерный чертеж слоя.
Шестиугольная архитектура, или архитектура портов и адаптеров, решает эти проблемы, отмечая симметрию ситуации: внутри находится приложение, взаимодействующее через некоторое количество портов с внешними объектами. С элементами вне приложения можно обращаться симметрично.
Шестиугольник призван зрительно выделить
(а) асимметрия внутри и снаружи и подобная природа портов, чтобы уйти от одномерной многослойной картины и всего, что она вызывает, и
(б) наличие определенного количества различных портов – двух, трех или четырех (четыре – это больше всего, с которыми я столкнулся на сегодняшний день).
Шестиугольник не является шестиугольником, потому что число шесть важно, а скорее позволяет людям, рисующим рисунок, иметь место для вставки портов и адаптеров по мере необходимости, не ограничиваясь одномерным многослойным рисунком. Термин «шестиугольная архитектура» произошел от этого визуального эффекта.

Rukis
02.11.2023 09:12А если доступ к данным на картинке не снизу, а сбоку, то все хорошо
становится? Смысл отдельного уровня доступа данным как раз в абстракции.
Как "нахождение снизу" этому мешает?"Внизу" имеется ввиду "внизу схемы слоёв", а схема такая предполагает направление зависимостей от верхних к нижним слоям. Таким образом "нахождение снизу" мешает тем, что слой с бизнес логикой будет иметь прямую зависимость от слоя доступа к данным.
piton_nsk
02.11.2023 09:12Какая разница снизу слой доступа к данным на картинке или сбоку? Зависимость от этого никуда не девается.
Таким образом "нахождение снизу" мешает тем, что слой с бизнес логикой будет иметь прямую зависимость от слоя доступа к данным.
Не совсем понял что имеется в виду под "прямой" зависимостью, но ничего не мешает добавить интерфейс.
Rukis
02.11.2023 09:12Так вот я и объяснил какая разница, схема так организована - сверху то, что зависит от низа.
ничего не мешает добавить интерфейс
ещё раз, эта схема зависимостей слоёв организованная по принципу снижения зависимостей от верха к низу. Если мы введём абстракцию для слоя доступа к данным и сделаем инверсию зависимости, то и на схеме слой перестанет быть нижнем.
То есть когда мы вводим абстракцию слоёв и начинаем представлять архитектуру приложения в виде слоёного пирога или слоёв донных отложений =) или чего то подобного, то в лексикон автоматически входят фразы типа "эту логику следует переместить на нижние слои". Но мне больше нравится представление слоёв в виде концентрических окружностей, тогда, например, уже говорим, что бизнес логика "в глубине", а компонент доступа к данным "на периферии".
Круги и слои

piton_nsk
02.11.2023 09:12+5Потыкавшись по интернетам я нашел обсуждение данной архитектуры от автора.
I am a symmetrist at heart. I wish everything to be symmetric at some moment, and work the differences from there. So I create a symmetric version of the layered model, in which the UI is not the front and the DB the back, but both are simply OUTSIDE.
Вся эта гексагональная архитектура не более чем "symmetric version of the layered model".
Еще из забавного от автора
Finally, after many years, I understood better what this architecture is about, and have shifted to calling it PortsAndAdaptersArchitecture
Автор после многих лет понял что правильное название архитектура портов и адаптеров. А народ статьи пишет. Кто-то поди еще и внедряет новинку 2005 года.
To break up perceptions about top and bottom and left and right, I drew it with a hexagonal shape, and came up with the rather stupid name HexagonalArchitecture - because I could not think of what the 'hexagon' meant.
because I could not think of what the 'hexagon' meant. Разве не прекрасно?
funca
02.11.2023 09:12+1Ну сам термин Hexagonal Architecture за это время стал узнаваем и часто мелькает в связке с Domain Driving Design (DDD) и Onion Architecture. Самая монументальная статья на эту тему из тех, что мне попадались https://herbertograca.com/2017/11/16/explicit-architecture-01-ddd-hexagonal-onion-clean-cqrs-how-i-put-it-all-together/.
Идея отделить логику приложения от остального мира выглядит заманчиво. Но PortsAndAdapters это слишком просто, чтобы быть правдой. Как повод лишний раз задуматься о том, чтобы вынести IO по максимуму наружу это ок. Но дальше все сводится к конвенциям, которые на практике нарушить ни чего не стоит, а поддерживать - сложно и дорого.

gev
02.11.2023 09:12+1Как повод лишний раз задуматься о том, чтобы вынести IO по максимуму наружу это ок
Возьмите Haskell там с этим все в полном порядке =)

vsh797
02.11.2023 09:12+1С интересом прочитал приведенную статью. Не понял, правда, момента с чтением данных. Мол, каждый компонент может читать данные любого другого. Т.е. мы разделили приложение на кучу максимально изолированных компонентов, которые сообщениями-то между собой обмениваются через посредника, чтобы друг о друге не знать. А потом создают эвент с моделями пользователя и заказа, чтобы его мог обработать компонент нотификаций? Это так и должно быть?
funca
02.11.2023 09:12+1По-моему из мира DDD у него на глобусе не хватает ещё двух важных вещей: Bound Сontext и Aggregation Root. Первое является ответом на вопрос где проходят границы полномочий между участниками? Второе определяет рамки единичной транзакции (действия).
Когда границы и действия определены, а бизнес-операция состоит из нескольких действий разных участников, то следующие вопросы:
каким образом они общаются между собой?
и как решать проблемные ситуации по пути?
Ответом будет тот или иной Integration Pattern - в этой книжке их 65, но мне кажется автор немного гнался за количеством).
Так или иначе, ивенты это один из возможных вариантов: сделал свою работу - сообщи. Ивент не содержит модели в буквальном смысле. Это просто сообщение с какими-то признаками этих моделей. Компонент нотификации получает не самого пользователя и его заказ, а лишь кусок данных про них. Таким образом пользователю ни куда выбегать (за пределы своего саб-домена) не нужно.
Неплохой обзор этой темы в трёх частях у https://vaadin.com/blog/ddd-part-1-strategic-domain-driven-design.
piton_nsk
02.11.2023 09:12+1Мне кажется что без знания типичной архитектуры начала 2000-х годов трудно понять что это и зачем. Толстые десктопные клиенты, повсеместная двухзвенка, а то и файл-серверные приложения, бизнес-логика в хранимках, bad delphi style с бизнес логикой прямо в обработчиках событий от ui типа пары сотен строк кода в онклике, dataaccess компоненты, которые самостоятельно лезут в базу, типа добавил строку в гриде, в базу insert.
Все вышеперечисленное в те времена было нормой, несло свой проблемы и поэтому смысл в разделении есть. Но отдельное название только путает людей.

olku
02.11.2023 09:12Достоинства и недостатки DDD проще продемонстрировать на сессии рефакторинга за час, чем заставлять читать книжные выкладки и заучивать новые понятия. Если когнитивная нагрузка при взгляде в папку с бизнес логикой уменьшилась, а тестам ее больше не нужны контейнеры, значит время потрачено не зря.

jakobz
02.11.2023 09:12+1Меня улыбнул кирпичик «postgresql adapter”. Сразу представил типичное бизнес-приложение, написанное по канонам. Обычно там вся логика в дата-леере, а все остальное - красивое, разделенное по слоям, и покрытое тестами - просто перекладывает все между уровнями.
Я вот так и не смог понять про какую такую бизнес-логику все в таких статьях говорят, когда ее отделяют от данных. У меня в бекендах 90% логики - это как данные положить и достать из БД, по дороге денормализуя, кешируя, агрегируя, проверяя права, и т.п. Как отделить такую логику от слоя доступа к данным, не упоров производительность - я за все годы так и не понял. Все статьи про архитектуру строятся на том что это как-то сделать можно, и поэтому для меня выглядят бессмысленными.
AlexViolin
02.11.2023 09:12В одних приложениях данные курсируют между визуальным интерфейсом и базой данных. В других огромная бизнес-логика и сохранение результатов в бд это только совсем малая часть бизнес-логики приложения. И здесь как возможен кирпичик «postgresql adapter”.

cudu
02.11.2023 09:12а что такое бизнес логика? если представить, что адаптер реализует сохранение сущности в бд, то бизнес логикой является вызов+аргументы функции адаптера.
Ну и честно сказать, я такие "прокси приложения, которые просто перекладывают" вижу только при старте проекта, а через полгода - в условном сервис слое уже увесистая лапша из вызовов других адаптеров, проверок разнообразных и т.д.
Rukis
02.11.2023 09:12+2Я вот так и не смог понять про какую такую бизнес-логику все в таких статьях говорят
Ну можно как то так понять: берем некие бизнес процессы существующие оффлайн, моделируем их через программные сущности. Правила их взаимодействий, требования к их состояниям - бизнес логика. Для такого моделирования не требуется БД, она нужна для хранения данных. И вот, прикручиваем БД так, чтоб модель про нее ничего не знала.
cudu
02.11.2023 09:12+1В конечно счете если взять типичную трехслойную архитектуру кода, запретить просачиваться ЛЮБЫМ НЕ БИЗНЕС сущностям в сервис слой(если совсем - то просто запретить импорт всех пакетов, кроме собственных и допустим java.*) и мы получим +- тоже самое.
Тогда сервис слой будет в себе содержать алгоритм, бизнес логику или что там аналитик ставит(последовательность вызовов, преобразований, проверок и т.д.) и все - это будет довольно просто тестируемо. И в таком случае мы любой из слоев можем легко заменить(допустим с хибера перейти на jooq).
И тут пытливый читатель спросит: а как же модули? А я отвечу, что тут начнется то, из за чего это все сложно стартует - чтобы работать с фичами\модулями\ддд и всем остальным, надо чтобы анализ работал над постановкой задач, надо чтобы проект имел функциональную модель(или любую другую) с границами, чтобы повторять модули за этой моделью, иначе со временем реальность разойдется с кодовой базой, появится либо дубли, либо переиспользование адаптеров из других модулей и так далее. Сложно всем будет.
maslyaev
02.11.2023 09:12Все эти прекрасные архитектурные принципы замечательно работают, пока на вдруг не приспичело добавить новое поле. Куда его повесить на фронтенде и в какую табличку в базе положить, разобрались, теперь надо одно дотянуть до другого. То есть протащить несчасное value через нутро шестиугольника. Лезем в код, а там, матерь божья, архитектура чистая как помыслы евнуха. Железобетонный SOLID. DRY суше, чем неиспользованный памперс. Короче, после трёх дней ада выкатываем PR и плачем: 50 изменённых файлов. И недоумеваем, где здесь та самая хвалёная лёгкость внесения изменений.
avf48
Шестиугольник - прикольно.
стандарт
ГОСТ Р ИСО 15704-2008 Промышленные автоматизированные системы. Требования к стандартным арх-рам и метод-ям предприятия
ГОСТ Р ИСО 19439-2008 Интеграция предприятия. Основа моделирования предприятия