Второй закон термодинамики гласит: "Невозможен процесс, единственным результатом которого являлась бы передача тепла от более холодного тела к более горячему". Это связано с тем, что вселенная стремится к повышению энтропии или меры неопределенности (равновесия, другими словами). Если, например, не убирать в квартире хотя бы неделю, то поверхности покроются пылью, накопятся разбросанные вещи и прочие результаты жизнедеятельности.
Удивительно, но в исходном коде программ происходят аналогичные процессы. Любой разработчик знает, что со временем над проектом становится все сложнее работать, реализация новых требований начинает даваться с большим трудом. А с каким страхом мы вносим изменения в то, что уже сделано? С каким отвращением и горечью иногда приходится работать с функцией, написанной разработчиком-неумехой (а иногда оказывается, что сам когда-то все это и написал)! Как исправление одного дефекта порождает несколько новых… Какие решения иногда порождает воображение лишь бы случайно, чего лишнего не сломать, но реализовать то что требуется. Смысла продолжать дальше нет. Любой сколько-нибудь опытный разработчик и так поймет, о чем речь.
Является ли данная негативная тенденция неизбежной частью жизни любого проекта и программиста? Или, быть может, инженер способен взять ситуацию в свои руки, замедлить устаревание проекта или даже повернуть данный процесс вспять? Для того чтобы ответить на данный вопрос, необходимо начать с самых основ, а именно из того из чего состоит любая программа.
Две ценности
Любую программу можно разбить на две составляющие:
Поведение — это наблюдаемые пользователем эффекты (изображение на дисплее, звуки, осязательные ощущения и т. п.), то, как воспринимается приложение, то, за что прежде всего платит заказчик, то, на что заводят дефекты при тестировании и что требуется реализовать согласно аналитике.
Структура — это скрытые от наблюдателя детали реализации, паттерны, библиотеки, структуры данных, фреймворки, другими словами это все то, что формирует поведение.
Отсюда можно вывести следующие категории сложности возникающие при разработке ПО:
Доменная — естественная сложность, присущая моделируемой области.
Структурная — приобретенная или искусственная сложность, исходящая от выбранной разработчиком структуры ПО.
Естественная сложность — неотъемлемый результат работы программиста. Если в требованиях написано, что должно быть условие с тремя исходами, значит так оно и будет, как бы инженер не пытался спрятать данный факт за различными конструкциями. Разработчик редко имеет возможность как-то повлиять на доменную сложность так как не определяет требования к поведению, которые естественную сложность и формируют. К счастью, домен редко становится основной причиной усложнения ПО.
Обычно главной причиной быстрого устаревания проектов, является приобретенная сложность. Иногда она вырастает настолько, что начинает контролировать домен, подминая требования под себя. Например, могут отклоняться куски функционала по причинам: "архитектура под такое не проектировалась", "это не планировалось" и "на перенос кнопки уйдет больше месяца работ". Насколько последнее является шуткой — решать вам.
Причин и точек влияния структуры программы на ее сложность может быть масса, при всем старании нельзя перечислить их все. Но для наглядности вот некоторые из них:
избыточность паттернов, парадигм, состояний, сущностей и структур;
хрупкость системы, где изменение, скорее всего, породит массу не очевидных дефектов, как в runtime, так и во время компиляции;
ошибки в моделировании предметной области;
несоответствие используемых подходов и компетенций разработки на проекте.
Инструмент изменения ПО
Единственный способ борьбы с ростом искусственной сложности — модификация её единственного источника, а именно структуры. Данная операция встречается настолько часто, что даже получила отдельное название - рефакторинг.
Отметим что, в случае рефакторинга наблюдаемое поведение не должно быть изменено, ведь это может привести к нежелательным отклонениям — дефектам. Ситуация, при которой ранее работоспособное поведение вдруг ломается, называется регрессом. Именно регресс делает рефакторинг непростым в применении инструментом.
Представим на секунду, что существует специальная программа с одной большой кнопкой “check”. При ее нажатии на экране одним из двух цветов загорается индикатор: зеленый, если система обладает корректным наблюдаемым поведением, и красный, если что-то сломалось. Такой инструмент под рукой существенно упростил бы процесс рефакторинга и как следствие процесс упрощения программы. Многие уже догадались что у такого помощника есть специальное имя – тесты. Давайте попробуем понять, какими свойствами они должны обладать, чтобы приносить разработчикам пользу.
4 свойства
Защита от регресса. Одной из основных функций тестов является защита от регресса. Именно она избавляет нас от страха случайно изменить поведение приложения при модифицировании деталей реализации. Вся польза от упрощения структурной ценности сведется на нет, если система при этом потеряет в поведении.
Сопротивляемость рефакторингу. Тесты не должны мешать (увеличивать время) основному методу упрощения ПО, а именно рефакторингу. Рефакторинг для тестов (как и для обычного пользователя) должен быть незаметным.
Поддерживаемость. Тесты не должны требовать больших ресурсов на своё написание и изменение, ведь в противном случае вся работа в направлении оптимизации труда потеряет смысл, так как проще будет не писать такие тесты вовсе.
Быстродействие. Если проверка требует много времени для выполнения, то она будет запускаться редко. Чем реже запуск, тем выше вероятность появления дефекта и, как следствие, тем сложнее его отыскать. В каких-то случаях запуски будут игнорироваться вовсе, сводя все усилия на нет. Это также оказывает негативное влияние на динамику и скорость рефакторинга.
Каждый из показателей можно измерить, это означает что они в сумме могут использоваться как средство оценки качества выбранного метода тестирования на проекте.
Давайте немного отвлечемся и отметим одну достаточно интересную взаимосвязь.
Связь ценности ПО и тестирования
Написание теста, на первый взгляд, имеет очевидную цель — верификация наблюдаемого поведения. На самом деле цель зависит от того, что принимается как наблюдаемое в конкретном случае. Так, например, unit-тесты отличаются достаточно сильной привязанностью к структуре системы, потому что исполняют ее в сильно ограниченном окружении и, таким образом, верифицируют не только поведение, но и саму возможность (и простоту) использования компонента в отрыве от его зависимостей. Но не все так просто, существуют программы, часть наблюдаемого поведения которых выражена в их структуре! Они будут представлены немного позднее.
Если подняться выше и задействовать больше элементов системы в проверочных кейсах, абстрагироваться от большинства элементов структуры, то получится уже менее открытая программа, больше напоминающая полупрозрачный ящик, где соотношение связи тестов со структурой и поведением будет в пользу последнего. Это характерно для интеграционных тестов.
Крайней точкой являются тесты, полностью использующие целевую среду выполнения, средства взаимодействия с программой и её восприятия. Таким образом, тесты полностью или в большей части закрываются от структуры ПО и концентрируются исключительно на его поведении.
Из этого можно сделать вывод что классическое разделение тестов на категории есть ничто иное как попытка перечислить разные соотношения ценностей ПО в стратегиях верификации (что проверяется больше, структура или поведение).
Привет, мир
В качестве отправной точки возьмем экстремум, а именно тесты, не зависящие от структуры и поэтому целиком и полностью проверяющие исключительно наблюдаемое поведение (так называемые E2E тесты). Как следствие, они не требуют ничего конкретного от структуры программы, воспринимая ее как один атомарный компонент (монолит):

Зеленым цветом будут выделяться тестируемые элементы системы (в данном случае тестируется вся система).
При таких условиях сопротивляемость рефакторингу будет максимальной, равно как и протекция от регрессии. К сожалению, есть и минусы: скорость выполнения тестов и высокая сложность их написания.
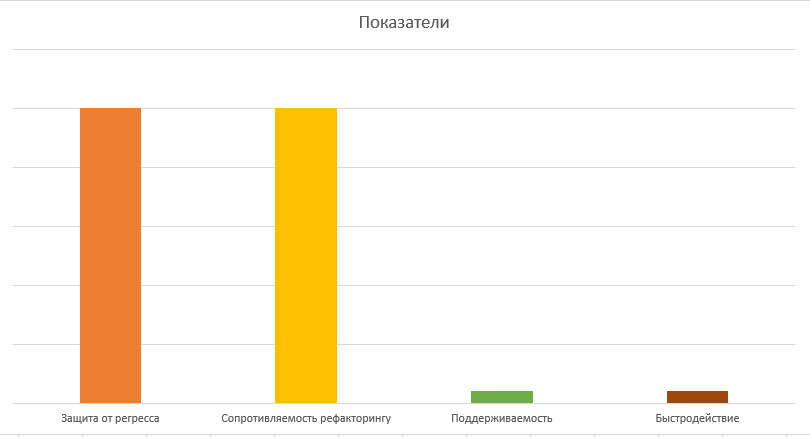
На диаграмме, чем выше столбец, тем больше “очков” оцениваемый метод тестирования набирает в данной категории. Так, E2E предоставляют отличную защиту от регресса (высокий столбец “ Защита от регресса”), но являются сравнительно медленными (низкий столбец “Быстродействие”).
Вот некоторые из причин:
Прямое использование всех или большинства компонентов системы естественным образом увеличивает время выполнения проверок, что может негативно сказаться на частоте запусков, а в некоторых случаях и вовсе тесты будут игнорироваться.
В целом встаёт проблематика методов верификации наблюдаемого поведения. Каким образом проверить что приложение издает правильный звук? Что оно заставляет телефон вибрировать в точности как и когда нужно? Запускает специальные световые индикаторы у устройств? Правильно общается со специальной периферией? Да даже кажущееся простым визуальное тестирование и то имеет множество нюансов, которые разработчики должны учитывать. Всё это негативно влияет на показатель поддерживаемости тестов.
Факт зависимости от внешних компонентов (например, сервера) также усложняет дело. Ввиду отсутствия прямого контроля, поведение таких систем не детерминировано: нет никакой гарантии, что она будет функционировать на момент запуска теста. Даже в случае работоспособности, отсутствует гарантия прогнозируемого времени и формы ответа.
В сумме данные факторы могут сделать тестирование губительным процессом с точки зрения затрат на разработку, поэтому выбор должен быть тщательно обдуман. В противном случае это может вылиться в большие затраты — и по времени, и по бюджету. Тесты станут скорее очередным источником проблемы, чем методом её решения.
Оптимизация
Сам собой встает вопрос: а каким образом можно изменить подход к тестированию так, чтобы поправить отстающие показатели, но сохранить при этом основную пользу тестов? Низкая поддерживаемость и медленная скорость выполнения — основные недостатки E2E. Соответственно, усилия разработчика должны быть направлены в первую очередь в этом направлении.
Удивительно, но данная проблема может быть решена путем разработки подходящей архитектуры приложения, но обо всем по порядку.
Источники данных
Первым и одним из самых очевидных элементов системы, тяжело поддающихся тестированию, являются запросы к данным. Это не только запросы к "удаленному серверу" в классическом понимании. Здесь подойдут любые функции, которые обладают двумя свойствами: наличие скрытых аргументов и/или внешних эффектов.
Скрытые аргументы
Функция считается зависимой от скрытых аргументов (скрытых — значит не передаваемых в аргументы функции) в случаях, например, чтения данных из БД, состояние которой может отличаться в зависимости от времени запуска тестов. Другим примером будет процедура, возвращающая текущую дату. Она также зависит от состояния внешнего окружения. С точки зрения тестов, такая функция является сложной в верификации, так как отсутствуют очевидные средства контроля результата её выполнения.
Обратным здесь можно выделить процедуры, которые являются идемпотентными. Т. е. такими, результат которых полностью предсказывается их внешними видимыми аргументами.
Внешние эффекты
Внешний эффект в общем случае это любой наблюдаемый результат работы функции, существующий за пределами её возвращаемого значения. Это может быть выброшенное исключение, изменение данных в БД, изменение читаемой глобальной переменной и так далее. Возьмем, к примеру, local storage. Запись значения в это хранилище может повлиять на работу системы, тем самым усложняя процесс верификации поведения, но при этом функция, исполняющая саму запись может вернуть просто undefined (т. е. сигнатура функции не отражает её полного поведения).
Возьмем два сценария: добавления пользователя и отображения списка пользователей. Очевидно, что результат будет разным в зависимости от порядка выполнения этих тестов, так как первый выполняет сайд эффект, влияющий на результат второго.
Важно отметить что функции, содержащие сайд эффекты, являются конечным звеном во всех процессах, результатом которых является наблюдаемое поведение. Наблюдаемое поведение – это именно то, что должно верифицироваться при тестировании, это означает что мы не можем в полной мере избавиться от таких функций при тестировании, иначе сам процесс станет бессмысленным.
Влияние на тестирование
Оба признака в совокупности формируют общее (или глобальное) состояние в системе, что делает невозможным параллельное или селективное выполнение тестов. Порядок и содержание всегда задается строгим образом. Это негативно влияет на время выполнения сценариев тестирования и увеличивает стоимость их поддержки. Также усложняются и сами методы верификации поведения, так как результат тестового сценария может отличаться время от времени (не идемпотентность).
План А
Проблемы, вызываемые грязными (не идемпотентными и/или содержащими сайд эффекты) функциями можно попытаться решить, реализуя механизм ручной установки и сброса целевого состояния (setup и teardown) функции. При этом глобальное состояние необходимо изолировать в рамках конкретного потока выполнения тестов. Это требует полного контроля над таким состоянием, что не всегда возможно. Примером могут служить rand-функции или неизменяемые данные (например, история изменений бизнес-сущности).
Реализация предикатов на корректность поведения может отличаться от случая к случаю. Зачастую, поведение верифицируется не полностью чтобы избежать проблем с не детерминированным поведением. Вместо честной визуальной верификации, например, в виде снимка, используются низкоуровневые проверки наличия элементов на странице, основанные на селекторах UI дерева, что выражается в сниженной защите от регресса и, зачастую, повышенной хрупкости таких тестов.
Такие методы решают только часть проблем при этом слабо маскируя остальные. Множество остальных недостатков, связанных с использованием реальных компонентов системы, остаются по-прежнему не решенными и выражаются в негативных свойствах, рассмотренных ранее.
План Б
Можно ли каким-то образом ограничить негативное влияние грязных функций на процесс тестировании, но при этом сохранить тесты полезными? Для этого попробуем выделить не идемпотентные или обладающие внешними эффектами функции во внешний компонент системы и назовем его Источники данных (также известные как репозитории). Далее можно сказать, что, все то, что находится в этой области структуры не должно покрываться тестами.

Обратите внимание что блок не окрашен в зеленый, так как намеренно не покрывается автоматизированными проверками.
Humble object
То, что источники данных не покрываются тестами, неизбежно приводит к пониженной защите от регресса (ведь кода теперь выполняется меньше). Это можно частично нивелировать, упрощая нетестируемые компоненты. Такая техника имеет особое название — Humble object (скромный объект).
Под скромностью здесь понимается отсутствие комплексной логики внутри компонента. Чаще всего такие компоненты характеризуются своей конкретностью (тяжело поддаются расширению, так как ссылаются на конкретные реализации) и простотой (содержат только тривиальные элементы, в основном обычное делегирование внешним функциям). Они тривиальны и у разработчика нет причин изменять их структуру, это и делает бессмысленным их тестирование.
Таким образом, программист должен обратить особое внимание на отсутствие управляющих конструкций в репозиториях и убедиться, что внутри нет ничего, что потребовало бы дополнительного тестирования.
Прежде чем продолжить определимся с некоторыми понятиями.
Зависимость от конкретной реализации
Зависимость в общем случае выражается в коде как явная ссылка на компонент. Компонент может быть обычной переменной, классом, функцией, типом, библиотекой и так далее.

В примере ниже функция UserList напрямую ссылается на конкретную реализацию getAllUsers. getAllUsers скрыто ссылается на изменяемый источник данных, а значит не является идемпотентной.

Заставить компонент использовать иной источник данных (например, более удобный для тестирования), нельзя не меняя при этом исходного кода UserList
Таким образом, можно сказать, что компонент UserList не является расширяемым с точки зрения данного требования. Это и определяет зависимость от конкретной реализации. В данном случае конкретной функции getAllUsers.
На схеме такая связь отображается следующим образом:

Зависимость от интерфейса
Теперь рассмотрим тот же компонент, но уже с несколько иной структурой:

Теперь функция UserList ссылается не на конкретную реализацию функции, а на ее интерфейс. Это позволяет подменять поведение getAllUsers без изменения исходного кода UserList. Компонент становится расширяемым в данной плоскости.
Изобразить это можно следующим образом:

getAllUsers (часть блока источников данных) реализует (или удовлетворяет) интерфейс GetAllUsers (часть блока интерфейса источников данных), который в свою очередь используется в UserList (часть блока программы).
Заглушки
Расширяемость тестируемого компонента можно использовать следующим образом: можно создать отдельную функцию getAllUsersMock, которая вместо реального запроса к api будет брать данные из локального, неизменяемого источника. Функция легко поддается тестированию, так как лишена проблем, перечисленных ранее. Она является "чистой".

Таким образом у нас образуется два отдельных слоя или группы методов:
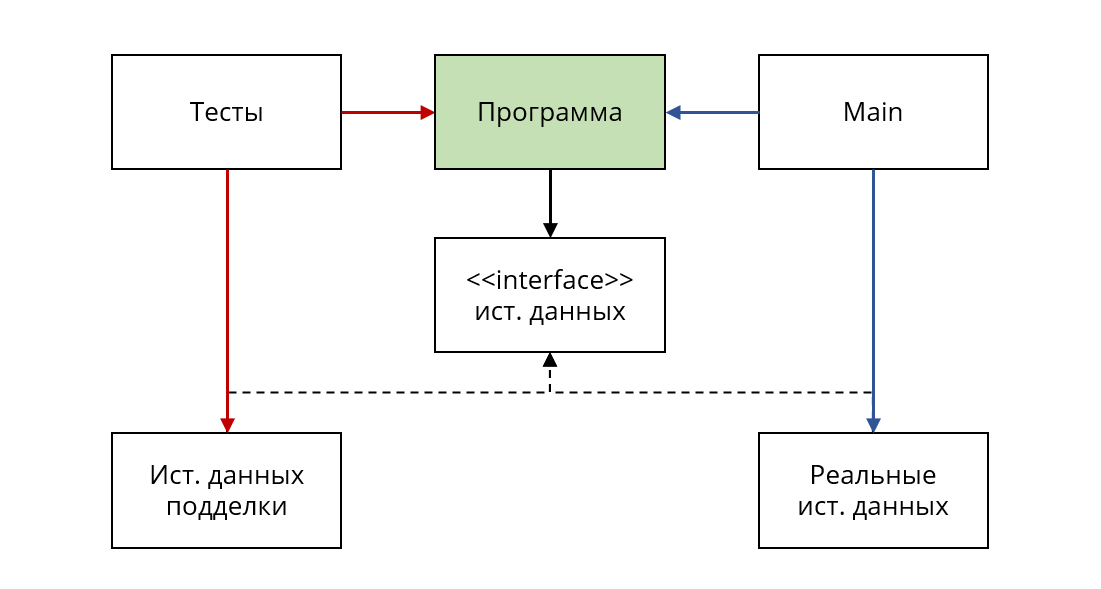
Реальные источники данных – методы, работающие с настоящими компонентами/хранилищами в системе, тем самым обладающие негативными свойствами, от которых мы стараемся избавиться. Они используются в реальном окружении (компонент Main на диаграмме).
Источники данных подделки – чистые функции (с некоторыми оговорками, которые мы рассмотрим позднее), которые реализованы таким образом, чтобы максимально упростить процесс тестирования, путем улучшения показателей поддерживаемости и скорости выполнения.
Какими свойствами обладает получившаяся структура? Являются ли источники данных конечным звеном в формировании наблюдаемого поведения, иными словами, каким образом они должны тестироваться и должны ли вообще? Что насчет верификации так называемой бизнес логики? На эти и многие другие вопросы мы ответим с последующих частях постепенно приближаясь к той самой тестируемой архитектуре.
Комментарии (12)

Batalmv
14.11.2023 09:27Мне кажется, что автору просто "повезло" жить в проекте с плохой архитектурой и кучей антипаттернов в коде. Я так и не понял, черезз все эти витееватые рассуждения и новые термины - с чем в итоге боремся?
В начале много теста посвящено "сложности" которая очень плохо влияет на проект. Ну так чуда нет. Правильная декомпозиция, четко прописанные "контракты" с этим борются. Не тесты. Тесты уже сугубо вторичны, так как они не меняют архитектуру :)
Теперь
4 свойства
Защита от регресса. Одной из основных функций тестов является защита от регресса. Именно она избавляет нас от страха случайно изменить поведение приложения при модифицировании деталей реализации. Вся польза от упрощения структурной ценности сведется на нет, если система при этом потеряет в поведении.
Сопротивляемость рефакторингу. Тесты не должны мешать (увеличивать время) основному методу упрощения ПО, а именно рефакторингу. Рефакторинг для тестов (как и для обычного пользователя) должен быть незаметным.
Поддерживаемость. Тесты не должны требовать больших ресурсов на своё написание и изменение, ведь в противном случае вся работа в направлении оптимизации труда потеряет смысл, так как проще будет не писать такие тесты вовсе.
Быстродействие. Если проверка требует много времени для выполнения, то она будет запускаться редко. Чем реже запуск, тем выше вероятность появления дефекта и, как следствие, тем сложнее его отыскать. В каких-то случаях запуски будут игнорироваться вовсе, сводя все усилия на нет. Это также оказывает негативное влияние на динамику и скорость рефакторинга.
Полезные свойства. Смотрим по одному.
Регресс: нет никакого страха, если вы четко прописали контракт сервиса и его и тестируете в точке публикации API. Все просто. Понятно относительно просто, но тем не менее
Сопротивляемость рефакторингу: чуда нет, если делаем рефакторинг, а значит меняет структуру API и его контракты - тесты надо переписывать.
Поддерживаемость: ну тут все просто. Следуйте за структурой ПО и будете одновременно счастливы (или нет) с разработчиком
Быстродействие: это чисто вопрос автоматизации. Можем - делаем
----------------
Теперь внешние эффекты. Ну да, но опять же. Если сервисы спроектированы корректно - их влияние минимально и часто описано в том же "контракте".
Есть зависимость на источники данных. Ну то же как бы понятно. Всегда есть ГРАНИЦА между вами и внешним миром (зонами ответственности других). Мокать точки соприкосновения человечество научилось давно. Классика: фронт получить спеку и примеры - идет "пилить" свою часть на статике без живого бэкенда. Потом сводят вместе. Как часто - зависит от подхода. Тоже самое на внешние системы. В большом enterprise вы всегда будете иметь кучу связанных с вашим решением систем, которые не ваши, которые непонятно когда доступны, нет нужных тестовых данных и т.д. И это нормально. Еще до тестов с этом проблемой столкнуться разрабы и успешно ее победят

khaimov Автор
14.11.2023 09:27Я так и не понял, черезз все эти витееватые рассуждения и новые термины - с чем в итоге боремся?
Боремся с растущей сложностью в программе с помощью организации подходящего метода тестирования. Что не менее важно отмечаем роль архитектуры в данном процессе.
Правильная декомпозиция, четко прописанные "контракты" с этим борются.
Какая декомпозиция правильная, а какая нет? Что такое контракт? Возможно тест и есть один из инструментов описания контакта? Вы идете в правильном направлении, но моя задача не заключается в том чтобы поверхностно перечислить как догмы всем знакомые понятия в одной статье, а наоборот, объяснить понятным, где то строгим и для кого то занудным языком те концепции, с которыми многие инженеры работают на бессознательном уровне, на уровне "все так делают и я буду"
если делаем рефакторинг, а значит меняет структуру API и его контракты
Рефакторинг это далеко не всегда изменение внешних контрактов, следовательно одно из другого обязательно не следует.
Поддерживаемость: ну тут все просто.
К сожалению нет :)
Быстродействие: это чисто вопрос автоматизации.
Это вопрос прежде всего ресурсов, ресурсов иногда настолько больших, что весь смысл от таких быстрых тестов может сойти на нет. В следующих частях будет показано как с помощью не сложных манипуляций с архитектурой можно достичь достойных показателей в данной категории.
Теперь внешние эффекты. Ну да, но опять же. Если сервисы спроектированы корректно - их влияние минимально
Их влияние не может быть минимальным или максимальным, оно должно быть ровно таким каким это требуется аналитикой.
В вашем выводе подчеркивается очевидность далеко не очевидных и комплексных понятий. Я вам это обязательно докажу в следующих частях серии статей. Спасибо за комментарий!
Batalmv
14.11.2023 09:27Боремся с растущей сложностью в программе с помощью организации подходящего метода тестирования. Что не менее важно отмечаем роль архитектуры в данном процессе.
Будет интересно посмотреть, как вы с помощью тестирования сможете побороть "сложность в программе" :) Программа то не изменится :)
Очень тяжело менятьб ничего не меняя, но мы будем. Жванецкий (с)
Какая декомпозиция правильная, а какая нет? Что такое контракт?
Ну, я как архитетор могу рассказать подробнее :) Контракт - описание сервиса:
где он есть (точка деплоя)
как к нему получить доступ (авторизация)
что передать на вход
что можно получить на выходе
что он "полезного" делает
...
Возможно тест и есть один из инструментов описания контакта?
Нет, именно в силу первичногости проектирования ПО. На момент когда QA еще может не быть, это описание уже может быть :) Т.е. тут даже нет парадокса "яйца и курицы"
Рефакторинг это далеко не всегда изменение внешних контрактов, следовательно одно из другого обязательно не следует.
Тогда вообще нет проблем. Локальное изменение и жизнь прекрасна :)
----------------
Мне кажется, вы пытаетесь, меняя что-то с помощью тестирования, поставить "телегу впереди лошади". Ну при всем желании :) Но будет интересно посмотреть дальше :)
khaimov Автор
14.11.2023 09:27Ответы на ваши замечания потребуют выложить все остальные части серии прямо тут в комментариях :)
Прошу набраться терпения и дождаться оставшийся материал, надеюсь по итогу от недопонимания не останется и следа, спасибо что комментируете!

noavarice
14.11.2023 09:27Не могу проголосовать кармой, так что поблагодарю комментарием. Хорошая формализация, в целом со всем согласен, интересно узнать, что дальше

arTk_ev
14.11.2023 09:27Зачем что-то выдумывать? В Data-driven все тесты примитивны их даже можно автоматически генерировать, логика уже отделена, и есть верификации с транкзациями.

Lynnfield
14.11.2023 09:27+1Хорошее начало! Кликбейтное =)
Надеюсь, что мы пытаемся рассказать не об одном и том же.
Хотя если подумать, то я даже буду рад, если кто-то ещё пришел к таким же выводам. Будет о чем поговорить =)
nin-jin
14.11.2023 09:27Давайте лучше поговорим о фрактальном тестировании. Как ваши впечатления от его внедрения?

boraldomaster
14.11.2023 09:27Позвольте несколько замечаний:
То, что Вы назвали "Зависимость от интерфейса", имеет устоявшееся в "науке" наименование "inversion of control". Для солидности неплохо было бы привести ссылку на статью об этом паттерне.
Компоненты, которые Вы назвали "Humble object" можно и даже нужно тестировать. Представьте, что у вас в репозитории написан гигантский SQL запрос с join и подзапросами. Для тестирования таких объектов существуют специальные библиотеки. В Java это testcontainers и mockserver. Наверняка что-то существует и для Вашей платформы (это вроде бы Nodejs)
Было бы неплохо хотя бы одно предложение насчёт языка программирования: какой язык используется в примерах и валидно ли всё, что Вы написали выше, для других языков тоже.
Интересно посмотреть, что Вы имеете в виду под "сопротивляемость рефакторингу". Надеюсь в следующей серии будет меньше текста и больше примеров на эту тему.
khaimov Автор
14.11.2023 09:27Благодарю за замечания!
Отвечу по пунктам:
Инверсия зависимостей будет представлена в следующей части
Стоит понимать что речь идёт не только о сервер приложениях, но и о клиентской части где источники данных это чаще всего обычные вызовы API. По поводу того что делать со сложной SQL логикой, то конечно ее нужно тестировать, тут вы правы, но в таком случае она и не попадет в не тестируемый слой уже по определению, т. е. не будет частью источников данных в данной терминологии.
Использую typescript, в следующих частях примеров будет гораздо больше. По поводу совместимости с другими языками сказать не могу, но уверен что разработчик сможет адаптировать представленные решения под свою среду разработки
Так точно :)
JordanCpp
Кода бы побольше в статью. Простыня текста и два примера случаев с кодом. Статья же не о раннем творчестве Маяковского.
khaimov Автор
В данной части в основном понятия достаточно концептуальные, но да, конкретных примеров можно добавить больше, обязательно учту в следующих частях, спасибо!