Предисловие
Всем привет! Это моя первая статья на Habr, так что не судите строго за стиль, а вот по содержанию буду рад любой конструктивной критике.
Статья основана на публикациях Confluent о том, как можно реализовать микросервисную архитектуру на основе событий с помощью Kafka Streams и KSQL.
Исходный код с примерами в статьях написан на Java без применения каких-либо фреймворков, а для запуска всех микросервисов требуется аккаунт Confluent Cloud. Я решил переписать все исходники на Kotlin + Spring Boot for Apache Kafka. Мой код доступен на Github.
Верхнеуровневое описание проекта
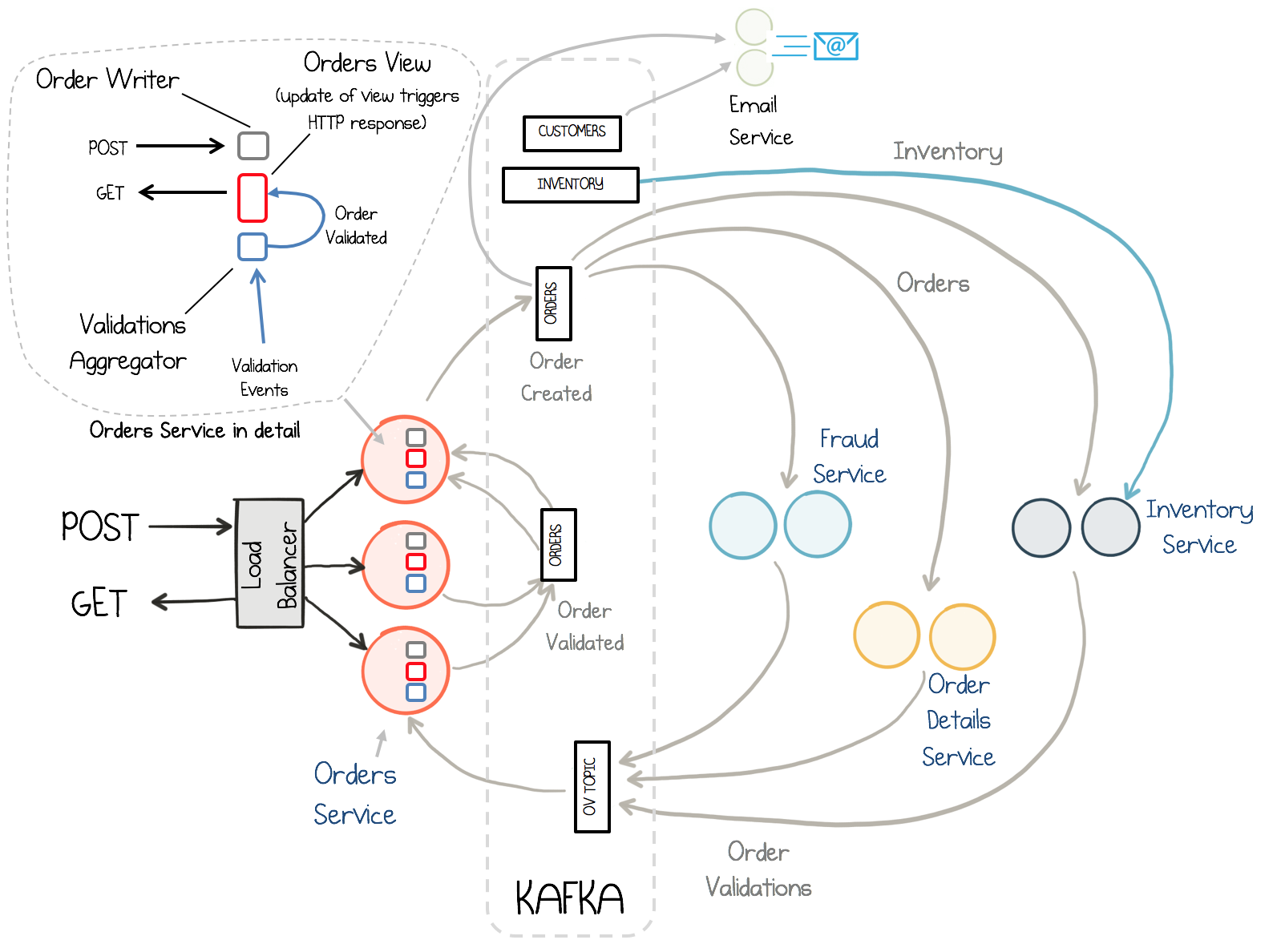
Центром системы микросервисов является Orders Service, который предоставляет клиентам возможность посылать REST запросы на:
содание заказов (POST http://localhost:8000/v1/orders)
получение заказа по его ID (GET http://localhost:8000/v1/orders/{id})
получение валидированного заказа по его ID (GET http://localhost:8000/v1/orders/{id}/validated)
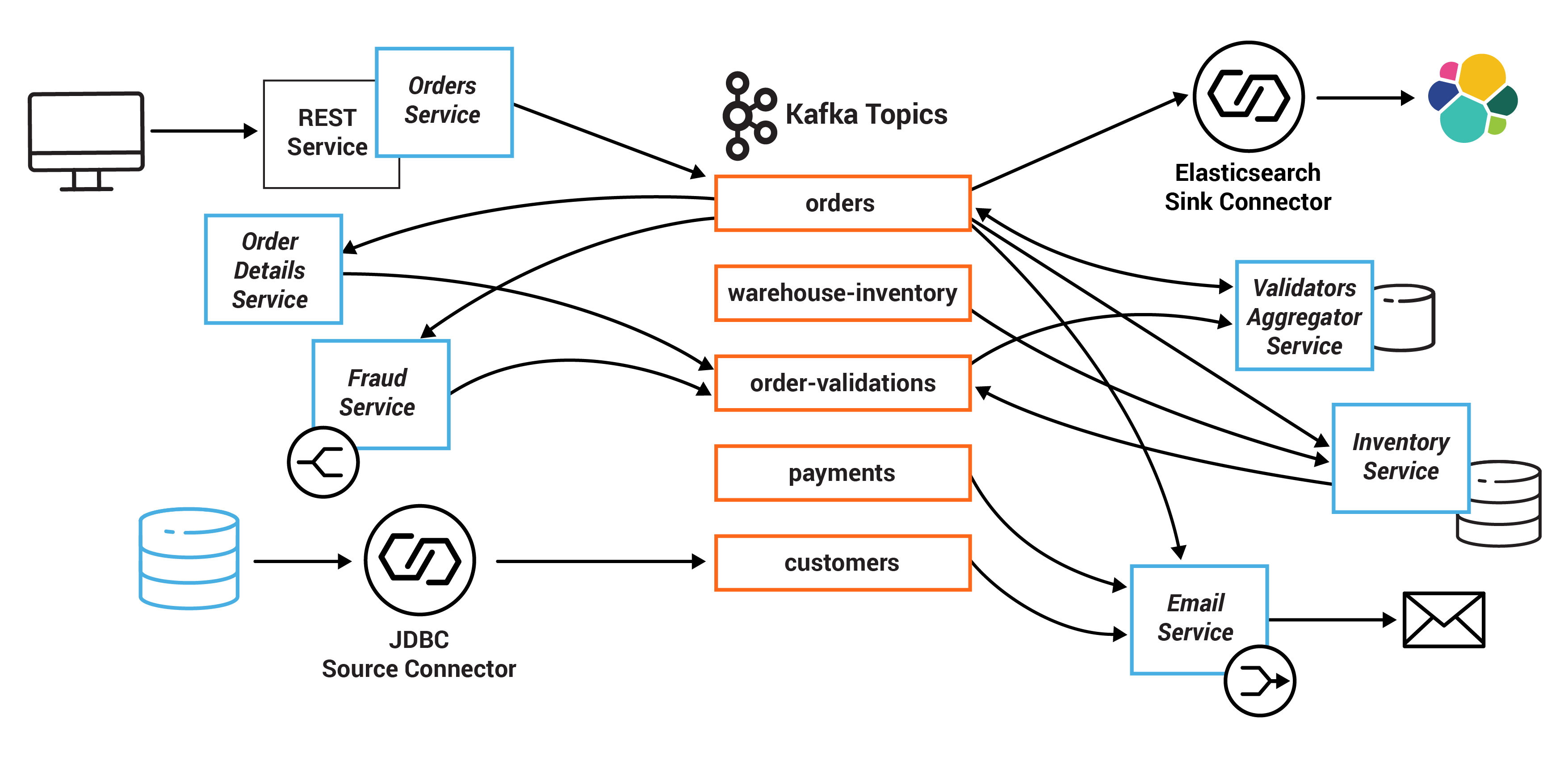
При создании заказа в Kafka топик orders.v1 посылается соответствующее событие, оно вычитывается различными сервисами, отвечающими за валидацию заказа: Inventory Service, Fraud Service и Order Details Service. Эти сервисы параллельно и независимо друг от друга осуществляют валидацию заказа, а результат PASS или FAIL записывают в топик Kafka order-validations.v1. Validation Aggregator Service вычитывает этот топик, аггрегирует результаты по каждому заказу и отправляет конечный результат в топик orders.v1.
Для реализации GET запросов Orders Service использует материализованное представление (materialized view), которое встроено (embedded) в каждый инстанс Orders Service. Это материализованное представление реализовано на основе Kafka Streams state store. Так как state store основан на топиках Kafka, и встроен в каждый инстанс, он хранит данные только тех партиций топика, которые вычитываются данным инстансом. Однако Kafka Streams предоставляет API (Interactive Queries) для того, чтобы "найти" инстанс, на котором хранятся данные, если их нет локально. Это позволяет реализовать гарантию для клиентов read-your-own-writes (чтение своих записей).
Также в системе есть простой сервис для отправки сообщений на почту Email Service (в текущей реализации просто осуществляется логирование отправляемых сообщений).
Сервис Order Enrichment отвечает за создание orders_enriched_stream в ksqlDB, из которого можно получить данные о покупателе и его заказе. Также этот сервис предоставляет REST ручку для получения информации о фозможных мошеннических действиях (если покупатель осуществил более 2 заказов за 30 секунд):
Данные о покупателях вычитываются из БД SQLite с помощью Kafka Connect io.confluent.connect.jdbc.JdbcSourceConnector в топик Kafka customers. Конфигурация коннектора: connector_jdbc_customers_template.config
Данные о заказах записываются из топика Kafka orders.v1 в индекс orders.v1 ElasticSearch с помощью Kafka Connect io.confluent.connect.elasticsearch.ElasticsearchSinkConnector. Конфигурация коннектора: connector_elasticsearch_template.config
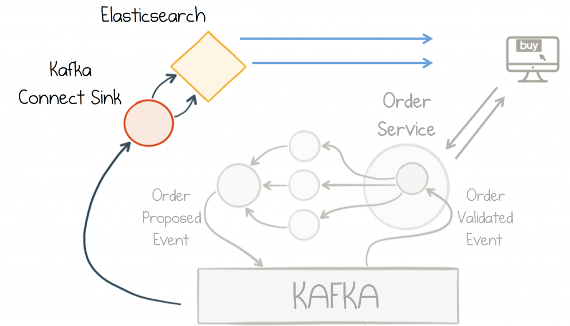
Диаграмма микросервисов и топиков Kafka:
Детали реализации
Модуль Common
Данный модуль собран как библиотека, которую используют микросервисы. Содержит сгенерированные AVRO классы а также утиллитные классы, облегчающие работу с топиками, сериализаторами и десериализаторами.
Сущности
Генерация сущностей, с которыми работает Kafka осуществляется на основе схем Avro с помощью Gradle plugin id 'com.github.davidmc24.gradle.plugin.avro' version "1.9.1", на этапе сборки библиотеки common. Ниже приведено описание сущностей без дополнительного сгенерированного кода.
class Customer(
val id: Long,
val firstName: String,
val lastName: String,
val email: String,
val address: String,
val level: String = "bronze" // possible values: platinum, gold, silver, bronze
)
enum class OrderState {
CREATED, VALIDATED, FAILED, SHIPPED
}
enum class Product {
JUMPERS, UNDERPANTS, STOCKINGS
}
class Order(
val id: String,
val customerId: Long,
val state: OrderState,
val product: Product,
val quantity: Int,
val price: Double
)
class OrderValue(
val order: Order,
val value: Double
)
class OrderEnriched(
val id: String,
val customerId: Long,
val customerLevel: String
)
enum class OrderValidationType {
INVENTORY_CHECK, FRAUD_CHECK, ORDER_DETAILS_CHECK
}
enum class OrderValidationResult {
PASS, FAIL, ERROR
}
class OrderValidation(
val orderId: String,
val checkType: OrderValidationType,
val validationResult: OrderValidationResult
)
class Payment(
val id: String,
val orderId: String,
val ccy: String,
val amount: Double
)Регистрация схем Avro в Confluent Schema Registry осуществляется с помощью Gradle Plugin: id 'com.github.imflog.kafka-schema-registry-gradle-plugin' version "1.12.0" после того, как поднят docker контейнер schema-registry. Чтобы зарегистрировать схемы необходимо настроить плагин.
Минимальная настройка в Gradle:
schemaRegistry {
url = 'http://localhost:8081'
quiet = true
register {
subject('customers-value', 'common/src/main/avro/customer.avsc', 'AVRO')
subject('orders.v1-value', 'common/src/main/avro/order.avsc', 'AVRO')
subject('orders-enriched.v1-value', 'common/src/main/avro/orderenriched.avsc', 'AVRO')
subject('order-validations.v1-value', 'common/src/main/avro/ordervalidation.avsc', 'AVRO')
subject('payments.v1-value', 'common/src/main/avro/payment.avsc', 'AVRO')
}
}При регистрации указываются:
Название схемы. Одним из паттернов наименования является TopicName-value / TopicName-key
Путь до файла со схемой
Формат сериализации, в нашем случае - AVRO.
Далее необходимо запустить таску Gradle из корневой директории проекта (не из директории common):
./gradlew registerSchemaTaskДля работы с записями в топиках приложение Kafka Streams должно знать о формате сериализации данных. Для этого настраиваются специальные org.apache.kafka.common.serialization.Serde классы, которые знают как сериализовать/десериализовать ключ/значение. Для удобства все настройки помещены в отдельный класс Schemas. Для сгенерированных AVRO классов используется io.confluent.kafka.streams.serdes.avro.SpecificAvroSerde, при настройке которого указывается адрес Schema Registry - сервера, хранящего все, в нашем случае AVRO, схемы.
fun configureSerdes() {
val config = hashMapOf<String, Any>(
AbstractKafkaSchemaSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG to topicsProps.schemaRegistryUrl
)
for (topic in ALL.values) {
configureSerde(topic.keySerde, config, true)
configureSerde(topic.valueSerde, config, false)
}
configureSerde(ORDER_VALUE_SERDE, config, false)
}
fun configureSerde(serde: Serde<*>, config: Map<String, Any>, isKey: Boolean) {
if (serde is SpecificAvroSerde) {
serde.configure(config, isKey)
}
}Orders Service
В Spring Boot нет необходимости вручную управлять жизненным циклом сущности KafkaStreams. Для этого есть абстракция org.springframework.kafka.config.StreamsBuilderFactoryBean, которая создает и управляет org.apache.kafka.streams.KafkaStreams и org.apache.kafka.streams.StreamsBuilder. Тем не менее, нам необходимо сконфигурировать бин org.springframework.kafka.config.KafkaStreamsConfiguration:
@EnableKafkaStreams
@Configuration
class KafkaConfig(
private val kafkaProps: KafkaProps,
private val serviceUtils: ServiceUtils,
private val topicProps: TopicsProps
) {
@Bean
fun outstandingRequests(): MutableMap<String, FilteredResponse<String, Order, OrderDto>> {
return ConcurrentHashMap()
}
@Bean(name = [KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME])
fun kStreamsConfig(): KafkaStreamsConfiguration {
val props = hashMapOf<String, Any>(
StreamsConfig.APPLICATION_ID_CONFIG to kafkaProps.appId,
// must be specified to enable InteractiveQueries and checking metadata of Kafka Cluster
StreamsConfig.APPLICATION_SERVER_CONFIG to serviceUtils.getServerAddress(),
StreamsConfig.BOOTSTRAP_SERVERS_CONFIG to kafkaProps.bootstrapServers,
StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG to Serdes.String().javaClass.name,
StreamsConfig.STATE_DIR_CONFIG to kafkaProps.stateDir,
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG to kafkaProps.autoOffsetReset,
StreamsConfig.PROCESSING_GUARANTEE_CONFIG to kafkaProps.processingGuarantee,
StreamsConfig.COMMIT_INTERVAL_MS_CONFIG to kafkaProps.commitInterval,
AbstractKafkaSchemaSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG to topicProps.schemaRegistryUrl,
StreamsConfig.consumerPrefix(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG) to kafkaProps.sessionTimeout
)
return KafkaStreamsConfiguration(props)
}
}Для того, чтобы работали Interactive Queries (если мы хотим запрашивать данные не только
из локального state store, но и с других инстансов), необходимо в конфигурациях указатьStreamsConfig.APPLICATION_SERVER_CONFIG - адрес текущего инстанса в формате host:port. Также мы указываем адрес Schema Registry, путь до каталога, где будет хранится state store и т.д. По умолчанию Kafka Streams использует встроенное key-value хранилище RocksDB в качестве state store.
При старте приложения Orders Service на основе топика Kafka orders.v1 создается KTable - абстракция Kafka Streams, которая представляет из себя snapshot состояния (можно провести аналогию с compacted topic) - хранятся последние записи по ключу в топике. При поступлении новых записей данные в KTable обновляются, фактически производится операция UPSERT - если ключ есть в таблице, данные обновляются, если нет - создаются, если приходит ключ - null - то это означает удаление данных, более они не будут использоваться при выборке по ключу или соединении таблицы с другими сущностями Kafka Streams (KStream, GlobalKTable). При этом Kafka Streams гарантирует, что в случае падения инстанса, данные не будут потеряны, так как они помимо локального state store, хранятся в change log топике Kafka - для сокращения потребления ресурсов по памяти этот топик - compacted.
Для того, чтобы приложение имело возможность получать данные из state store, необходимо его материализовать, указав название, по которому в дальнейшем к нему можно обращаться.
@Component
class OrdersServiceTopology(
private val orderProps: OrdersProps,
private val mapper: OrderMapper,
private val schemas: Schemas,
private val outstandingRequests: MutableMap<String, FilteredResponse<String, Order, OrderDto>>
) {
@Autowired
fun ordersTableTopology(builder: StreamsBuilder) {
log.info("Calling OrdersServiceTopology.ordersTableTopology()")
builder.table(
orderProps.topic,
Consumed.with(schemas.ORDERS.keySerde, schemas.ORDERS.valueSerde),
Materialized.`as`(orderProps.storeName)
).toStream().foreach(::maybeCompleteLongPollGet)
}
private fun maybeCompleteLongPollGet(id: String, order: Order) {
val callback = outstandingRequests[id]
if (callback?.asyncResponse?.isSetOrExpired == true) {
outstandingRequests.remove(id)
} else if (callback != null && callback.predicate(id, order)) {
callback.asyncResponse.setResult(mapper.toDto(order))
outstandingRequests.remove(id)
}
}
}Метод OrdersServiceTopology.maybeCompleteLongPollGet(String, Order) получает приходящие в KTable данные о заказах, и если новый заказ хранится в ConcurrentHashMap, и он удовлетворяет условию FilteredResponse.predicate, то тогда мы комплитим DeferredResult и удаляем его из ConcurrentHashMap.
Класс org.springframework.web.context.request.async.DeferredResult позволяет асинхронно обработать REST запрос. В Orders Service он используется следующим образом: в качестве возвращаемого значения в контроллере используется DeferredResult. Поток, принявший запрос можно освободить, а проставить значение в DeferredResult можно из другого потока. При этом можно указать таймаут, после которого DeferredResult вернет ошибку. При получении заказа - getOrder(id) - если ни в локальном state store, ни в state store на других инстансах нет заказа с нужным ID, мы помещаем DeferredResult в ConcurrentHashMap - возможно заказ с таким ID появится в созданной KTable до истечения таймаута, тогда метод OrdersServiceTopology.maybeCompleteLongPollGet(String, Order) проставит результат в DeferredResult и вернет его пользователю.
Пример метода в контроллере:
@GetMapping("/{id}")
fun getOrder(
@PathVariable("id") id: String,
@RequestParam("timeout", defaultValue = "2000") timeout: Long
): DeferredResult<OrderDto> {
log.info("Received request to GET order with id = {}", id)
val deferredResult = DeferredResult<OrderDto>(timeout)
ordersService.getOrderDto(id, deferredResult, timeout)
return deferredResult
}Пример работы с DeferredResult:
fun getOrderDto(id: String, asyncResponse: DeferredResult<OrderDto>, timeout: Long) {
initOrderStore()
CompletableFuture.runAsync {
val hostForKey = getKeyLocationOrBlock(id, asyncResponse)
?: return@runAsync //request timed out so return
if (thisHost(hostForKey)) {
fetchLocal(id, asyncResponse) { _, _ -> true }
} else {
val path = Paths(hostForKey.host, hostForKey.port).urlGet(id)
fetchFromOtherHost(path, asyncResponse, timeout)
}
}
}
private fun fetchLocal(
id: String,
asyncResponse: DeferredResult<OrderDto>,
predicate: (String, Order) -> Boolean
) {
log.info("running GET on this node")
try {
val order = orderStore.get(id)
if (order == null || !predicate(id, order)) {
log.info("Delaying get as order not present for id $id")
outstandingRequests[id] = FilteredResponse(
asyncResponse = asyncResponse,
predicate = predicate
)
} else {
asyncResponse.setResult(mapper.toDto(order))
}
} catch (e: InvalidStateStoreException) {
log.error("Exception while querying local state store. {}", e.message)
outstandingRequests[id] = FilteredResponse(asyncResponse, predicate)
}
}
private fun fetchFromOtherHost(
path: String,
asyncResponse: DeferredResult<OrderDto>,
timeout: Long
) {
log.info("Chaining GET to a different instance: {}", path)
try {
val order = webClientBuilder.build()
.get()
.uri("$path?timeout=$timeout")
.retrieve()
.bodyToMono<OrderDto>()
.block() ?: throw NotFoundException("FetchFromOtherHost returned null for request: $path")
asyncResponse.setResult(order)
} catch (swallowed: Exception) {
log.warn("FetchFromOtherHost failed.", swallowed)
}
}Для того, чтобы обратиться к state store, нам необходимо запросить его из Kafka Streams. Тут стоит обратить внимание на то, что нам предоставляется только read-only хранилище.
private lateinit var orderStore: ReadOnlyKeyValueStore<String, Order>
fun initOrderStore() {
if (!::orderStore.isInitialized) {
val streams = factoryBean.kafkaStreams
?: throw RuntimeException("Cannot obtain KafkaStreams instance.")
orderStore = streams.store(
StoreQueryParameters.fromNameAndType(
ordersProps.storeName,
QueryableStoreTypes.keyValueStore()
)
)
}
}Для получения информации о том, на каком инстансе хранятся данные о заказе с конкретным ID, Kafka Streams предоставляет API:
fun <K> streamsMetadataForStoreAndKey(
store: String,
key: K,
serializer: Serializer<K>
): HostStoreInfo {
// Get metadata for the instances of this Kafka Streams application hosting the store and
// potentially the value for key
val metadata = factoryBean.kafkaStreams?.queryMetadataForKey(store, key, serializer)
?: throw NotFoundException("Metadata for store $store not found!")
return HostStoreInfo(
host = metadata.activeHost().host(),
port = metadata.activeHost().port(),
storeNames = hashSetOf(store)
)
}При создании заказа, Orders Service отправляет сообщение в топик Kafka orders.v1 с помощью KafkaTemplate<String, Order>. Настройки KafkaProducer в данном случае указываются в application.yml файле:
spring:
application:
name: order-service
kafka:
bootstrap-servers: ${kafkaprops.bootstrapServers}
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: io.confluent.kafka.serializers.KafkaAvroSerializer
bootstrap-servers: ${kafkaprops.bootstrapServers}
acks: ${kafkaprops.acks}
client-id: ${kafkaprops.clientId}
properties:
enable.idempotence: ${kafkaprops.enableIdempotence}
schema.registry.url: ${kafkaprops.schemaRegistryUrl}
auto.register.schemas: false
use.latest.version: trueОсобое внимание стоит обратить на настройки auto.register.schema: false и use.latest.version: true. По умолчанию они выставлены наоборот. И если оставить их без изменения, то могут возникнуть ошибки при сериализации / десериализации данных из-за возможной невосместимости схем AVRO. Confluent рекомендует в проде не предоставлять возможность продъюсерам автоматичски регистрировать схему.
Order Details Service
Сервис отвечает за проверку деталей заказа:
количество товаров не меньше 0
стоимость заказа не меньше 0
товар присутствует в заказе
Сообщения вычитываются из топика Kafka orders.v1, заказ проверяется, а результат проверки отправляется в топик Kafka order-validations.v1. В этом сервисе не используется Kafka Streams, а используются стандартные Kafka Producer / Consumer.
Конфигурация Kafka Consumer:
@Bean
fun kafkaListenerContainerFactory(
consumerFactory: ConsumerFactory<String, Order>
): ConcurrentKafkaListenerContainerFactory<String, Order> {
val factory = ConcurrentKafkaListenerContainerFactory<String, Order>()
factory.consumerFactory = consumerFactory
return factory
}
@Bean
fun consumerFactory(): ConsumerFactory<String, Order> {
return DefaultKafkaConsumerFactory(consumerProps())
}
private fun consumerProps(): Map<String, Any> {
val props = hashMapOf<String, Any>(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG to kafkaProps.bootstrapServers,
ConsumerConfig.GROUP_ID_CONFIG to kafkaProps.appId,
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG to kafkaProps.autoOffsetReset,
ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG to !kafkaProps.enableExactlyOnce,
ConsumerConfig.CLIENT_ID_CONFIG to kafkaProps.appId,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG to schemas.ORDERS.keySerde.deserializer()::class.java,
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG to schemas.ORDERS.valueSerde.deserializer()::class.java,
AbstractKafkaSchemaSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG to kafkaProps.schemaRegistryUrl,
"specific.avro.reader" to true
)
return props
}Здесь важно обратить внимание на конфигурацию specific.avro.reader: true. Она сообщает консъюмеру, что он вычитывает не обобщенный AVRO тип записи (GenericAvroRecord), а конкретный тип SpecificAvroRecord, и имеет возможность получать доступ к полям и методам без необходимости кастить к конкретному типу.
Конфигурация Kafka Producer:
@Bean
fun producerFactory(): ProducerFactory<String, OrderValidation> {
return DefaultKafkaProducerFactory(senderProps())
}
private fun senderProps(): Map<String, Any> {
val props = hashMapOf<String, Any>(
ProducerConfig.BOOTSTRAP_SERVERS_CONFIG to kafkaProps.bootstrapServers,
ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG to kafkaProps.enableIdempotence,
ProducerConfig.RETRIES_CONFIG to Int.MAX_VALUE.toString(),
ProducerConfig.ACKS_CONFIG to kafkaProps.acks,
ProducerConfig.CLIENT_ID_CONFIG to kafkaProps.appId,
ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG to schemas.ORDER_VALIDATIONS.valueSerde.serializer().javaClass.name,
ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG to schemas.ORDER_VALIDATIONS.keySerde.serializer().javaClass.name,
AbstractKafkaSchemaSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG to kafkaProps.schemaRegistryUrl,
AbstractKafkaSchemaSerDeConfig.AUTO_REGISTER_SCHEMAS to false,
AbstractKafkaSchemaSerDeConfig.USE_LATEST_VERSION to true,
)
if (kafkaProps.enableExactlyOnce) {
// attempt to provide a unique transactional ID which is a recommended practice
props[ProducerConfig.TRANSACTIONAL_ID_CONFIG] = "${kafkaProps.appId}-${applicationProps.port}"
}
return props
}
@Bean
fun kafkaTemplate(
producerFactory: ProducerFactory<String, OrderValidation>
): KafkaTemplate<String, OrderValidation> {
return KafkaTemplate(producerFactory)
}Тут стоит обратить внимание на две вещи. Первая, как уже было сказано выше - мы запрещаем продъюсеру автоматически регистрировать схемы в Schema Registry, а также указываем использовать последнюю версию схемы при сериализации данных. Второй момент касается настройки ProducerConfig.TRANSACTIONAL_ID_CONFIG,
эта настройка должна быть уникальной для каждого инстанса приложения, чтобы Kafka могла гарантировать корректную работу с транзакциями в случае падения приложения. При этом важно понимать, что уникальный - не значит рандомный. То есть, за инстансом должен быть закреплен свой TRANSACTIONAL_ID. В данном случае для простоты реализации я использую суффикс в виде порта, на котором поднято приложение. Однако, эта лишь демо реализация.
Email Service

Сервис вычитывает данные из нескольких топиков Kafka: customers, payments.v1, orders.v1, объединяет их с помощью Kafka Streams, и отправляет сообщение через интерфейс Emailer. Кроме того, данные о заказе и покупателе отправляются в топик Kafka, совпадающий с рейтингом покупателя: platinum, gold, silver, bronze.

Настройки Kafka Streams тут аналогичны Orders Service.
Класс EmailService отвечает за создание и обработку KStream и KTable. Для того, чтобы после старта приложения создалась и заработала топология стримов Kafka Streams, необходимо ее настроить с помощью StreamsBuilder. Для этого достаточно в класс, помеченный аннотацией @Component или @Service в один из методов заинжектить StreamsBuilder и в этом методе выстроить нужную топологию.
@Service
class EmailService(
private val emailer: Emailer,
private val schemas: Schemas
) {
@Autowired
fun processStreams(builder: StreamsBuilder) {
val orders: KStream<String, Order> = builder.stream(
schemas.ORDERS.name,
Consumed.with(schemas.ORDERS.keySerde, schemas.ORDERS.valueSerde)
)
//Create the streams/tables for the join
val payments: KStream<String, Payment> = builder.stream(
schemas.PAYMENTS.name,
Consumed.with(schemas.PAYMENTS.keySerde, schemas.PAYMENTS.valueSerde)
)
//Rekey payments to be by OrderId for the windowed join
.selectKey { s, payment -> payment.orderId }
val customers: GlobalKTable<Long, Customer> = builder.globalTable(
schemas.CUSTOMERS.name,
Consumed.with(schemas.CUSTOMERS.keySerde, schemas.CUSTOMERS.valueSerde)
)
val serdes: StreamJoined<String, Order, Payment> = StreamJoined
.with(schemas.ORDERS.keySerde, schemas.ORDERS.valueSerde, schemas.PAYMENTS.valueSerde)
//Join the two streams and the table then send an email for each
orders.join(
payments,
::EmailTuple,
JoinWindows.ofTimeDifferenceWithNoGrace(Duration.ofMinutes(1)),
serdes
)
//Next join to the GKTable of Customers
.join(
customers,
{ _, value -> value.order.customerId },
// note how, because we use a GKtable, we can join on any attribute of the Customer.
EmailTuple::setCustomer
)
//Now for each tuple send an email.
.peek { _, emailTuple ->
emailer.sendEmail(emailTuple)
}
//Send the order to a topic whose name is the value of customer level
orders.join(
customers,
{ orderId, order -> order.customerId },
{ order, customer ->
OrderEnriched(order.id, order.customerId, customer.level)
}
)
//TopicNameExtractor to get the topic name (i.e., customerLevel) from the enriched order record being sent
.to(
TopicNameExtractor { orderId, orderEnriched, record ->
orderEnriched.customerLevel
},
Produced.with(schemas.ORDERS_ENRICHED.keySerde, schemas.ORDERS_ENRICHED.valueSerde)
)
}
}В данном примере следует обратить внимание на несколько моментов.
KStream<String, Payment>создается на основе топикаpayments.v1,в котором ключом является ID платежа, при этом в информации о платеже присутствует полеorderId, которое фактически ссылается на сущностьOrder. Kafka Streams поддерживает объединениеKStreamпо ключу топика, из которого вычитываются сообщения. Это называется equi join. Но так как в исходных топиках разные ключи, приходится провести re-keying - выбор нового ключа в "правом" стриме с помощью методаKStream.selectKey(), в нашем случае вKStream<String, Payment>. Под капотом Kafka Streams пометит данный KStream как подлежащий репартиционированию, и если среди последующих операций со стримами будет объединение или аггрегация, то произойдет репартиционирование: Kafka Streams создаст служебный топик с таким же количеством партиций, как и в исходном топике и будет отправлять данные из первоначального топика (payments.v1) в новый топик. Теперь этотKStream, основанный на служебном топике можно спокойно объединять со стримомKStream<String, Order>, так как у них одинаковые ключи записей.
NB! ВАЖНО Тут есть один очень важный ньюанс: для того, чтобы Kafka Streams могла провести объединение данных исходные топики должны быть ко-партиционированы:
должны быть одинаковые ключи
должны иметь одинаковое количество партиций
должны иметь одинаковую стратегию партиционирования
Подробнее об этом в статье Co-Partitioning with Apache Kafka.
Информация о покупателях собирается в
GlobalKTable<Long, Customer>. Это означает, что каждый инстанс приложения Email Service будет иметь в своем распоряжении данные обо всех покупателях, в отличие от обычной KTable, которая хранит на инстансе только данные из вычитываемых этим инстансом партиций. Таким образом мы можем объединять KStream с GlobalKTable по любому полю, плюс нет необходимости соблюдать правило о ко-партиционировании топиков. Однако теперь наш инстанс может быть перегружен как по памяти, так и по сетевому трафику, если топикcustomersбудет хранить очень много данных и постоянно пополняться. Также стоит отметить, что GlobalKTable инициализируется на старте приложения, то есть вычитываются все данные из соответствующего топика. До того, как произойдет инициализация, объединение KStream с GlobalKTable не начнется.При объединении двух стримов важно понимать, что данные в топики, на основе которых создаются стримы могут попадать не одновременно. Поэтому при объединении стримов используются "окна" объединения. В нашем случае при объединении стримов orders и payments мы используем окно в 1 минуту, без какого-либо грейс периода.
JoinWindows.ofTimeDifferenceWithNoGrace(Duration.ofMinutes(1))Это означает, что записи, timestamp которых в пределах 1 минуты друг от друга, могут быть объеденины, то есть мы подразумеваем, что создание заказа и его оплата по времени не различаются на +-1 минуту. Записи, которые не попадают в это окно, не будут учитываться при объединении стримов.
/**
* Specifies that records of the same key are joinable if their timestamps are within {@code timeDifference},
* i.e., the timestamp of a record from the secondary stream is max {@code timeDifference} before or after
* the timestamp of the record from the primary stream.
* <p>
* CAUTION: Using this method implicitly sets the grace period to zero, which means that any out-of-order
* records arriving after the window ends are considered late and will be dropped.
*
* @param timeDifference join window interval
* @return a new JoinWindows object with the window definition and no grace period. Note that this means out-of-order records arriving after the window end will be dropped
* @throws IllegalArgumentException if {@code timeDifference} is negative or can't be represented as {@code long milliseconds}
*/
public static JoinWindows ofTimeDifferenceWithNoGrace(final Duration timeDifference) {
return ofTimeDifferenceAndGrace(timeDifference, Duration.ofMillis(NO_GRACE_PERIOD));
}Использование "окон" также обусловлено необходимостью поддерживать буфер для объединения данных. Если бы не было "окон" этот буфер мог бы поглотить всю память. "Окна" хранят свои данные в windowing state store, старые записи в котором удаляются после настраиваемого window retention period, который по умолчанию равен 1 дню. Изменить это значение можно с помощью: Materialized#withRetention().
Более подробно о том, какие бывают виды объединений можно прочитать в документации.
Fraud Service
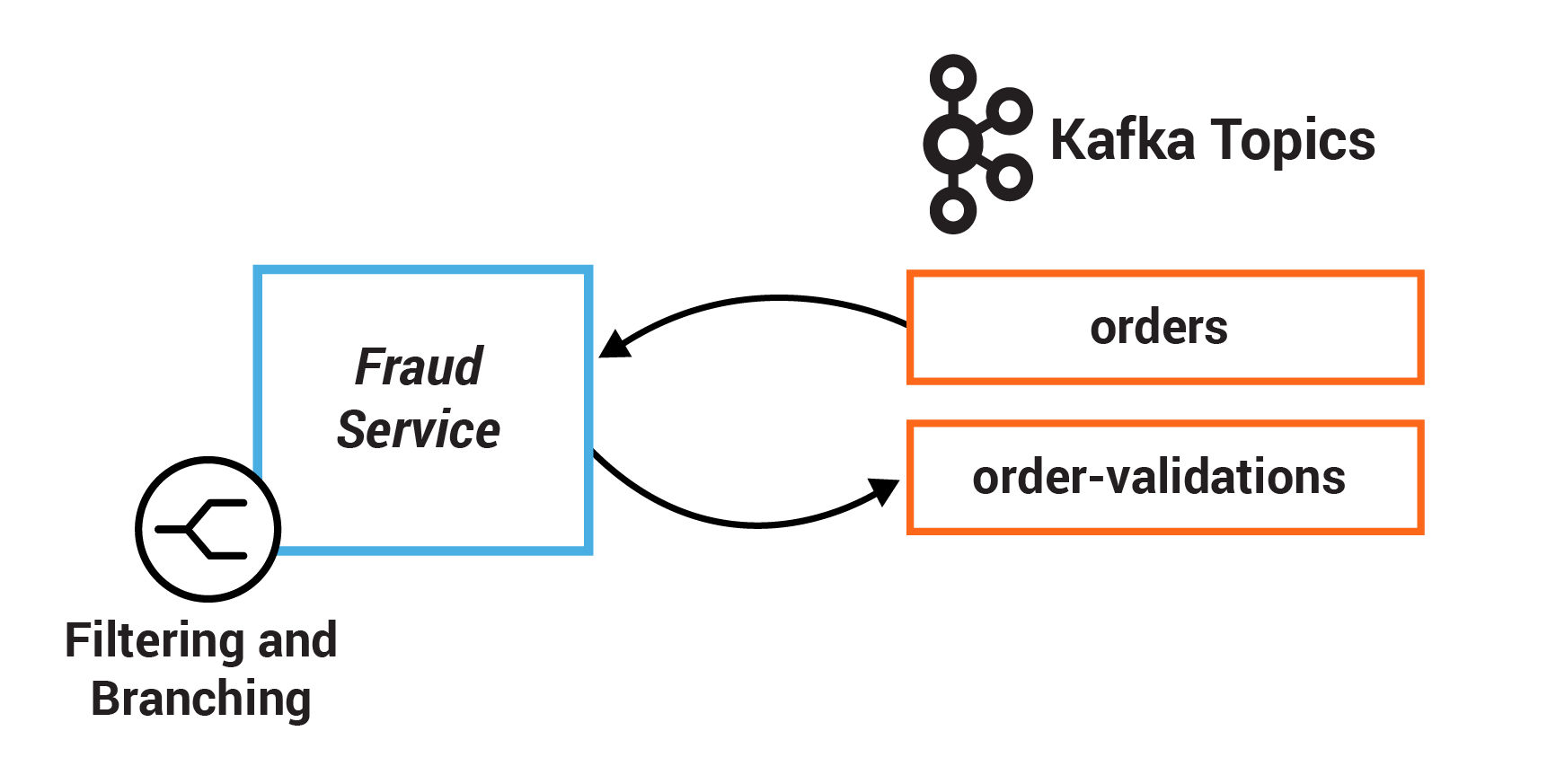
Сервис отвечает за поиск потенциально мошеннических транзакций: если пользователь сделал заказы на более чем 2 тыс в течение сессии взаимодействия с сервером (подробнее ниже по тексту), то все такие заказы не проходят валидацию.
Конфигурация Kafka Streams немного отличается от предыдущих:
@Bean(name = [KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME])
fun kStreamsConfig(): KafkaStreamsConfiguration {
val props = hashMapOf<String, Any>(
StreamsConfig.APPLICATION_ID_CONFIG to kafkaProps.appId,
// must be specified to enable InteractiveQueries and checking metadata of Kafka Cluster
StreamsConfig.APPLICATION_SERVER_CONFIG to serviceUtils.getServerAddress(),
StreamsConfig.BOOTSTRAP_SERVERS_CONFIG to kafkaProps.bootstrapServers,
StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG to Serdes.String().javaClass.name,
// instances MUST have different stateDir
StreamsConfig.STATE_DIR_CONFIG to kafkaProps.stateDir,
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG to kafkaProps.autoOffsetReset,
StreamsConfig.PROCESSING_GUARANTEE_CONFIG to kafkaProps.processingGuarantee,
StreamsConfig.COMMIT_INTERVAL_MS_CONFIG to kafkaProps.commitInterval,
AbstractKafkaSchemaSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG to topicProps.schemaRegistryUrl,
StreamsConfig.consumerPrefix(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG) to kafkaProps.sessionTimeout,
// disable caching to ensure a complete aggregate changelog.
// This is a little trick we need to apply
// as caching in Kafka Streams will conflate subsequent updates for the same key.
// Disabling caching ensures
// we get a complete "changelog" from the aggregate(...)
// (i.e. every input event will have a corresponding output event.
// https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=186878390
StreamsConfig.STATESTORE_CACHE_MAX_BYTES_CONFIG to "0"
)
return KafkaStreamsConfiguration(props)
}Стоит пояснить, что в этом сервисе будет использоваться аггрегация данных, вследствие чего Kafka Streams будет задействовать state store для хранения состояния аггрегированных данных. В нашем случае мы отключаем кэширование данных на инстансе, так как кэширование может привести к объединению последовательных событий при работе со state store во время аггрегации данных, в то время как мы хотим обрабатывать каждую запись в процессе аггрегации. Более подробно об этом в статье Kafka Streams Memory Management.
На первом этапе работы сервиса создается узел аггрегации стрима KStream<String, Order>:
val orders: KStream<String, Order> = builder
.stream(
schemas.ORDERS.name,
Consumed.with(schemas.ORDERS.keySerde, schemas.ORDERS.valueSerde)
)
.peek { key, value ->
log.info("Processing Order {} in Fraud Service.", value)
}
.filter { _, order -> OrderState.CREATED == order.state }
// Create an aggregate of the total value by customer and hold it with the order.
// We use session windows to detect periods of activity.
val aggregate: KTable<Windowed<Long>, OrderValue> = orders
// creates a repartition internal topic if the value to be grouped by differs from
// the key and downstream nodes need the new key
.groupBy(
{ id, order -> order.customerId },
Grouped.with(Serdes.Long(), schemas.ORDERS.valueSerde)
)
.windowedBy(SessionWindows.ofInactivityGapWithNoGrace(Duration.ofHours(1)))
.aggregate(
::OrderValue,
{ custId, order, total ->
OrderValue(order, total.value + order.quantity * order.price)
},
{ k, a, b ->
simpleMerge(a, b)
},//include a merger as we're using session windows.,
Materialized.with(null, schemas.ORDER_VALUE_SERDE)
)Стоит обратить внимание на то, что при группировке по ключу, отличающемуся от ключа исходного топика будет создан внутренний служебный топик Kafka, с таким же количеством партиций, что и исходный топик. В нашем примере используется еще один тип окна для аггрегации данных - SessionWindows.ofInactivityGapWithNoGrace(Duration.ofHours(1))
Это означает, что данные будут попадать в аггрегацию в течение сессии активности пользователя. Сессия закрывается, когда в топик не поступают данные в течение указанного периода времени. Более подробно в статье Create session windows.
На втором этапе мы избавляемся от данных об "окнах" и делаем re-keying записей по orderId:
val ordersWithTotals: KStream<String, OrderValue> = aggregate
.toStream { windowedKey, orderValue -> windowedKey.key() }
//When elements are evicted from a session window they create delete events. Filter these out.
.filter { k, v -> v != null }
.selectKey { id, orderValue -> orderValue.order.id }На третьем этапе мы формируем две "ветки" стримов:
одна содержит значения больше FRAUD_LIMIT
вторая - меньше FRAUD_LIMIT
//Now branch the stream into two, for pass and fail, based on whether the windowed
// total is over Fraud Limit
val forks: Map<String, KStream<String, OrderValue>> = ordersWithTotals
.peek { key, value ->
log.info("Processing OrderValue: {} in FraudService BEFORE branching.", value)
}
.split(Named.`as`("limit-"))
.branch(
{ id, orderValue -> orderValue.value >= FRAUD_LIMIT },
Branched.`as`("above")
)
.branch(
{ id, orderValue -> orderValue.value < FRAUD_LIMIT },
Branched.`as`("below")
)
.noDefaultBranch()На следующем этапе значения из каждой "ветки" будут отправлены в топик order-validations.v1, с соответствующим результатом: FAIL или PASS.
val keySerde = schemas.ORDER_VALIDATIONS.keySerde
val valueSerde = schemas.ORDER_VALIDATIONS.valueSerde
val config = hashMapOf<String, Any>(
AbstractKafkaSchemaSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG to topicProps.schemaRegistryUrl,
AbstractKafkaSchemaSerDeConfig.AUTO_REGISTER_SCHEMAS to false,
AbstractKafkaSchemaSerDeConfig.USE_LATEST_VERSION to true,
)
keySerde.configure(config, true)
valueSerde.configure(config, false)
forks["limit-above"]?.mapValues { orderValue ->
OrderValidation(
orderValue.order.id,
OrderValidationType.FRAUD_CHECK,
OrderValidationResult.FAIL
)
}?.peek { key, value ->
log.info("Sending OrderValidation for failed check in Fraud Service to Kafka. Order: {}", value)
}?.to(
schemas.ORDER_VALIDATIONS.name,
Produced.with(
keySerde,
valueSerde
)
)
forks["limit-below"]?.mapValues { orderValue ->
OrderValidation(
orderValue.order.id,
OrderValidationType.FRAUD_CHECK,
OrderValidationResult.PASS
)
}?.peek { key, value ->
log.info("Sending OrderValidation for passed check in Fraud Service to Kafka. Order: {}", value)
}?.to(
schemas.ORDER_VALIDATIONS.name,
Produced.with(
schemas.ORDER_VALIDATIONS.keySerde,
schemas.ORDER_VALIDATIONS.valueSerde
)
)Примечание.
В процессе тестирования реализации у меня возникла проблема с тем, что в некоторых случаях Kafka Streams пыталась отправить данные в топик, предварительно автоматически зарегистрировав новую схему данных в Schema Registry, при этом новая схема была несовместима со старой, что останавливало Kafka Streams. Попытки отключить автоматическую регистрацию схем для сериализаторов / десериализаторов Kafka Streams также приводили к остановке приложения из-за того, что Kafka Streams регулярно под капотом создает служебные топики и должна иметь возможность регистрировать их схемы. При этом стоит заметить, что остановка приложения Kafka Streams не приводит к падению инстанса - он-то как раз и продолжает работать, поэтому в проде придется настраивать отдельный мониторинг жизнеспособности приложений Kafka Streams, чтобы в случае остановки стримов перезапустить инстанс.
Путем долгих мытарств решение (скорее заплатка) было найдено: там, где Kafka Streams отправляет аггрегированные или объединенные данные в уже созданный топик Kafka с зарегистрированной в Schema Registry схемой, я отключил возможность Serdes автоматически регистрировать новые схемы.
Inventory Service
Вычитывает данные о заказах из топика orders.v1 и валидирует на предмет наличия требуемого количества товаров в заказе. Валидация учитывает как те товары, которые есть на "складе", так и те, которые зарезервированы (на них есть действующие заказы). На текущий момент, не реализована логика снижения количества товаров на "складе" - это должно происходить, например, при отправке заказа покупателю через службу доставки. "Склад" - представляет из себя топик Kafka warehouse-inventory.v1, где ключом записи является название товара, а значением - количество.
Основной сервис InventoryKafkaService создает KStream<String, Order> на основе топика orders.v1:
val orders: KStream<String, Order> = builder
.stream(
schemas.ORDERS.name,
Consumed.with(schemas.ORDERS.keySerde, schemas.ORDERS.valueSerde)
)
.peek { key, value ->
log.info("Orders streams record. Key: {}, Order: {}", key, value)
}KTable<Product, Int> на основе топика warehouse-inventory.v1:
val warehouseInventory: KTable<Product, Int> = builder
.table(
schemas.WAREHOUSE_INVENTORY.name,
Consumed.with(
schemas.WAREHOUSE_INVENTORY.keySerde,
schemas.WAREHOUSE_INVENTORY.valueSerde
)
)а также материализованный KeyValueStore<Product, Long>, хранящий информацию о зарезервированных товарах:
val reservedStock: StoreBuilder<KeyValueStore<Product, Long>> = Stores
.keyValueStoreBuilder(
Stores.persistentKeyValueStore(inventoryProps.reservedStockStoreName),
schemas.WAREHOUSE_INVENTORY.keySerde, Serdes.Long()
)
.withLoggingEnabled(hashMapOf())
builder.addStateStore(reservedStock)После этого мы делаем re-keying стрима KStream<String, Order> по ключу product. Тут стоит напомнить, что под капотом Kafka Streams пометит этот KStream как подлежащий репартиционированию, и в случае необходимости (ниже будет join или аггрегация), произойдет репартиционирование. Далее в стрим попадают только заказы в состоянии CREATED, которые объединяются с таблицей зарезервированных товаров. После объединения получаем новый KStream, каждая запись которого проходит валидацию и отправляется в топик order-validations.v1.
orders.selectKey { id, order -> order.product }
.peek { key, value ->
log.info("Orders stream record after SELECT KEY. New key: {}. \nNew value: {}", key, value)
}
// Limit to newly created orders
.filter { id, order -> OrderState.CREATED == order.state }
//Join Orders to Inventory so we can compare each order to its corresponding stock value
.join(
warehouseInventory,
::KeyValue,
Joined.with(
schemas.WAREHOUSE_INVENTORY.keySerde,
schemas.ORDERS.valueSerde,
Serdes.Integer()
)
)
//Validate the order based on how much stock we have both in the warehouse
// and locally 'reserved' stock
.transform(
TransformerSupplier {
InventoryValidator(inventoryProps)
},
inventoryProps.reservedStockStoreName
)
.peek { key, value ->
log.info(
"Pushing the result of validation Order record to topic: {} with key: {}. \nResult: {}",
schemas.ORDER_VALIDATIONS.name, key, value
)
}
//Push the result into the Order Validations topic
.to(
schemas.ORDER_VALIDATIONS.name,
Produced.with(
orderValidationsKeySerde.apply { configureSerde(this, true) },
orderValidationsValueSerde.apply { configureSerde(this, false) }
)
)Полная реализация класса:
private val log = LoggerFactory.getLogger(InventoryKafkaService::class.java)
@Service
class InventoryKafkaService(
private val schemas: Schemas,
private val inventoryProps: InventoryProps,
private val topicProps: TopicsProps
) {
@Autowired
fun processStreams(builder: StreamsBuilder) {
// Latch onto instances of the orders and inventory topics
val orders: KStream<String, Order> = builder
.stream(
schemas.ORDERS.name,
Consumed.with(schemas.ORDERS.keySerde, schemas.ORDERS.valueSerde)
)
.peek { key, value ->
log.info("Orders streams record. Key: {}, Order: {}", key, value)
}
val warehouseInventory: KTable<Product, Int> = builder
.table(
schemas.WAREHOUSE_INVENTORY.name,
Consumed.with(
schemas.WAREHOUSE_INVENTORY.keySerde,
schemas.WAREHOUSE_INVENTORY.valueSerde
)
)
// Create a store to reserve inventory whilst the order is processed.
// This will be prepopulated from Kafka before the service starts processing
val reservedStock: StoreBuilder<KeyValueStore<Product, Long>> = Stores
.keyValueStoreBuilder(
Stores.persistentKeyValueStore(inventoryProps.reservedStockStoreName),
schemas.WAREHOUSE_INVENTORY.keySerde, Serdes.Long()
)
.withLoggingEnabled(hashMapOf())
builder.addStateStore(reservedStock)
val orderValidationsKeySerde = Serdes.String()
val orderValidationsValueSerde = SpecificAvroSerde<OrderValidation>()
//First change orders stream to be keyed by Product (so we can join with warehouse inventory)
orders.selectKey { id, order -> order.product }
.peek { key, value ->
log.info("Orders stream record after SELECT KEY. New key: {}. \nNew value: {}", key, value)
}
// Limit to newly created orders
.filter { id, order -> OrderState.CREATED == order.state }
//Join Orders to Inventory so we can compare each order to its corresponding stock value
.join(
warehouseInventory,
::KeyValue,
Joined.with(
schemas.WAREHOUSE_INVENTORY.keySerde,
schemas.ORDERS.valueSerde,
Serdes.Integer()
)
)
//Validate the order based on how much stock we have both in the warehouse
// and locally 'reserved' stock
.transform(
TransformerSupplier {
InventoryValidator(inventoryProps)
},
inventoryProps.reservedStockStoreName
)
.peek { key, value ->
log.info(
"Pushing the result of validation Order record to topic: {} with key: {}. \nResult: {}",
schemas.ORDER_VALIDATIONS.name, key, value
)
}
//Push the result into the Order Validations topic
.to(
schemas.ORDER_VALIDATIONS.name,
Produced.with(
orderValidationsKeySerde.apply { configureSerde(this, true) },
orderValidationsValueSerde.apply { configureSerde(this, false) }
)
)
}
private fun configureSerde(serde: Serde<*>, isKey: Boolean) {
val serdesConfig = hashMapOf<String, Any>(
AbstractKafkaSchemaSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG to topicProps.schemaRegistryUrl,
AbstractKafkaSchemaSerDeConfig.AUTO_REGISTER_SCHEMAS to false,
AbstractKafkaSchemaSerDeConfig.USE_LATEST_VERSION to true,
)
schemas.configureSerde(serde, serdesConfig, isKey)
}
}Order Enrichment Service
Сервис использует Java клиент ksqlDB, для того, чтобы создать в ksqlDB stream, который содержит информацию как о покупателе, так и о заказе. Данные из этого стрима можно получить, непосредственно обратившись к ksqlDB как через Java клиент, так и другими способами, например через ksqlDB CLI.
private val CREATE_ORDERS_STREAM = "CREATE SOURCE STREAM IF NOT EXISTS ${ksqlDBProps.ordersStream} (" +
"ID STRING KEY, " +
"CUSTOMERID BIGINT, " +
"STATE STRING, " +
"PRODUCT STRING, " +
"QUANTITY INT, " +
"PRICE DOUBLE) WITH (" +
"kafka_topic='${topicProps.ordersTopic}'," +
" value_format='AVRO'" +
");"
private val CREATE_CUSTOMERS_TABLE = """
CREATE SOURCE TABLE IF NOT EXISTS ${ksqlDBProps.customersTable} (
CUSTOMERID BIGINT PRIMARY KEY,
FIRSTNAME STRING,
LASTNAME STRING,
EMAIL STRING,
ADDRESS STRING,
LEVEL STRING
) WITH (
KAFKA_TOPIC='${topicProps.customersTopic}',
VALUE_FORMAT='AVRO'
);
"""
private val CREATE_ORDERS_ENRICHED_STREAM = """
CREATE STREAM IF NOT EXISTS ${ksqlDBProps.ordersEnrichedStream}
AS SELECT ${ksqlDBProps.customersTable}.CUSTOMERID AS customerId,
${ksqlDBProps.customersTable}.FIRSTNAME,
${ksqlDBProps.customersTable}.LASTNAME,
${ksqlDBProps.customersTable}.LEVEL,
${ksqlDBProps.ordersStream}.PRODUCT,
${ksqlDBProps.ordersStream}.QUANTITY,
${ksqlDBProps.ordersStream}.PRICE
FROM ${ksqlDBProps.ordersStream}
LEFT JOIN ${ksqlDBProps.customersTable}
ON ${ksqlDBProps.ordersStream}.CUSTOMERID = ${ksqlDBProps.customersTable}.CUSTOMERID;
"""Помимо этого также создается таблица, содержащая информацию о потенциально мошеннических действиях клиентов:
private val CREATE_FRAUD_ORDER_TABLE = """
CREATE TABLE IF NOT EXISTS ${ksqlDBProps.fraudOrderTable}
WITH (KEY_FORMAT='json')
AS SELECT CUSTOMERID,
LASTNAME,
FIRSTNAME,
COUNT(*) AS COUNTS
FROM ${ksqlDBProps.ordersEnrichedStream}
WINDOW TUMBLING (SIZE 30 SECONDS)
GROUP BY CUSTOMERID, LASTNAME, FIRSTNAME
HAVING COUNT(*)>2;
"""Сервис выставляет наружу REST endpoint, по которому можно получить данные о потенциальных мошенниках:
data class FraudDto(
val customerId: Long,
val lastName: String,
val firstName: String,
val counts: Long
)
@RestController
@RequestMapping("/fraud")
class FraudController(
private val fraudService: FraudService
) {
@GetMapping
fun getFraudulentOrders(
@RequestParam(name = "limit", defaultValue = "10") limit: Int
): List<FraudDto> {
log.info("Received request to GET $limit number of fraudulent orders.")
return fraudService.getFraudulentOrders(limit)
}
}
@Service
class FraudServiceImpl(
private val client: Client,
private val ksqlDBProps: KsqlDBProps
) : FraudService {
override fun getFraudulentOrders(limit: Int): List<FraudDto> {
log.info("Executing getFraudulentOrders stream query.")
val frauds = client.executeQuery("SELECT * FROM ${ksqlDBProps.fraudOrderTable} LIMIT $limit;").get()
return frauds.map(::mapRowToResponse)
}
private fun mapRowToResponse(row: Row): FraudDto {
log.info("Mapping ksqlDB Query row: {}", row)
val cusId = row.getLong("CUSTOMERID")
val lastName = row.getString("LASTNAME")
val firstName = row.getString("FIRSTNAME")
val count = row.getLong("COUNTS")
return FraudDto(cusId, lastName, firstName, count)
}
}Validation Aggregator Service
Простой сервис, отвечающий за вычитывание данных из топика order-validations.v1, куда отправляют сообщения сервисы проверки заказов: Inventory Service, Fraud Service и Order Details Service. После того, как от каждого валидатора будет получен ответ по конкретному заказу, в топик orders.v1 отправляется сообщение с обновленным статусом заказа.
Настройки Kafka Streams аналогичны Orders Service.
Реализация класса ValidationAggregatorService:
@Service
class ValidationAggregatorService(
private val schemas: Schemas,
private val topicProps: TopicsProps
) {
private val serdes1: Consumed<String, OrderValidation> = Consumed.with(
schemas.ORDER_VALIDATIONS.keySerde,
schemas.ORDER_VALIDATIONS.valueSerde
)
private val serdes2: Consumed<String, Order> = Consumed
.with(schemas.ORDERS.keySerde, schemas.ORDERS.valueSerde)
private val serdes3: Grouped<String, OrderValidation> = Grouped
.with(schemas.ORDER_VALIDATIONS.keySerde, schemas.ORDER_VALIDATIONS.valueSerde)
private val serdes4: StreamJoined<String, Long, Order> = StreamJoined
.with(schemas.ORDERS.keySerde, Serdes.Long(), schemas.ORDERS.valueSerde)
private val serdes5: Grouped<String, Order> = Grouped
.with(schemas.ORDERS.keySerde, schemas.ORDERS.valueSerde)
private val serdes6: StreamJoined<String, OrderValidation, Order> = StreamJoined
.with(schemas.ORDERS.keySerde, schemas.ORDER_VALIDATIONS.valueSerde, schemas.ORDERS.valueSerde)
// disables auto registering schemas for specified Serde<*>
private fun configureSerdes(serde: Serde<*>, isKey: Boolean) {
val config = hashMapOf<String, Any>(
AbstractKafkaSchemaSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG to topicProps.schemaRegistryUrl,
AbstractKafkaSchemaSerDeConfig.AUTO_REGISTER_SCHEMAS to false,
AbstractKafkaSchemaSerDeConfig.USE_LATEST_VERSION to true,
)
schemas.configureSerde(serde, config, isKey)
}
@Autowired
fun aggregateOrderValidations(builder: StreamsBuilder) {
// 1. Количество проверок, которые проходит каждый заказ. Для простоты реализации захардкожено.
val numberOfRules = 3
// 2. Настройка Serdes, которые будут участвовать в отправке сообщений в топик orders.v1.
// Запрещаем автоматическую регистрацию схем в Schema Registry, чтобы избежать конфликтов.
val ordersKeySerde = Serdes.String()
val ordersValueSerde = SpecificAvroSerde<Order>()
configureSerdes(ordersKeySerde, true)
configureSerdes(ordersValueSerde, false)
// 3. стрим из топика order-validations.v1
val validations: KStream<String, OrderValidation> = builder
.stream(schemas.ORDER_VALIDATIONS.name, serdes1)
// 4. стрим из топика orders.v1, в котором присутствуют только заказы в статусе CREATED
val orders = builder
.stream(schemas.ORDERS.name, serdes2)
.filter { id, order -> OrderState.CREATED == order.state }
validations
.peek { key, value ->
log.info("Starting validation for key: {}, value: {}", key, value)
}
// 5. группируем сообщения о валидации по orderId
.groupByKey(serdes3)
// 6. Сообщения также разбиваются по окнам сессионной активности с периодим неактивности
// 5 минут
.windowedBy(SessionWindows.ofInactivityGapWithNoGrace(Duration.ofMinutes(5)))
// 7. Аггрегируем данные о проверке заказов, если заказ прошел проверку (PASS),
// тогда увеличиваем счетчик проверенных заказов
.aggregate(
{ 0L },
{ id, result, total ->
if (PASS == result.validationResult) total + 1 else total
},
// так как мы используем SessionWindow, нам необходимо добавить merger для сессий
// из-за особенностей работы этих окон. По сути, когда в стрим приходит первое сообщение
// сразу создается сессия, после этого, если приходит еще обно сообщение, попадающее в
// inactivity gap первого сообщения, то для него тоже создается сессия, которая мержится
// с сессией первого сообщения. Подробнее тут:
// https://kafka.apache.org/36/documentation/streams/developer-guide/dsl-api.html#windowing-session
{ k, a, b ->
b ?: a
},
Materialized.with(null, Serdes.Long())
)
// 8. избавляемся от "окон" и формируем новый стрим, где: key = orderId, value = количество пройденных проверок
.toStream { windowedKey, total -> windowedKey.key() }
// Когда сообщения удаляются из Session Window, публикуется событие delete (null-value), избавляемся от них
.filter { _, v -> v != null }
// 9. Также берем только те записи, которые прошли все проверки
.filter { _, total -> total >= numberOfRules } // 9.
// 10. объединяем со стримом orders и обновляем статус заказа на VALIDATED
.join(
orders,
{ id, order ->
Order.newBuilder(order).setState(OrderState.VALIDATED).build()
},
JoinWindows.ofTimeDifferenceWithNoGrace(Duration.ofMinutes(5)),
serdes4
)
.peek { _, value ->
log.info("Order {} has been validated and is being sent to Kafka Topic: {}", value, topicProps.ordersTopic)
}
// 11. Отправляем заказ с обновленным статусом в топик orders.v1
.to(schemas.ORDERS.name, Produced.with(ordersKeySerde, ordersValueSerde))
// 12. также обрабатываем случай, когда заказ провалил хотябы одну проверку
validations.filter { id, rule ->
FAIL == rule.validationResult
}
// 13. объединяем со стримом orders и обновляем статус заказа на FAILED
.join(
orders,
{ id, order ->
Order.newBuilder(order).setState(OrderState.FAILED).build()
},
JoinWindows.ofTimeDifferenceWithNoGrace(Duration.ofMinutes(5)),
serdes6
)
.peek { key, value ->
log.info("Order {} failed validation. BEFORE groupByKey.", value)
}
// 14. Группируем по ключу - orderId
.groupByKey(serdes5)
// 15. так как заказ мог не пройти несколько проверок, в нашем стриме могут присутствовать
// несколько записей со статусом FAIL, тут мы избавляемся от дубликатов, так как нам
// не важно сколько проверок не прошел заказ
.reduce { order, v1 -> order }
.toStream()
.peek { key, value ->
log.info("Order {} failed validation. AFTER groupByKey.", value)
}
.to( // 16. Отправляем заказ с обновленным статусом в топик orders.v1
schemas.ORDERS.name,
Produced.with(ordersKeySerde, ordersValueSerde)
)
}
}Требования для запуска:
JDK 17
Docker + docker-compose
ОЗУ для Docker не менее 8 Гб
ОЗУ для микросервисов не менее 8 Гб. (Точно запускается на Ubuntu 22.04 с 64 Гб ОЗУ и 8 ядрами процессора)
Как запустить микросервисы
Запустить скрипт из корневой папки:
Если установлен Docker V2, то:
./prepare_script_docker_new.shЕсли более стара версия, то:
./prepare_script_docker_old.shСкрипт осуществляет следующие действия:
-
Поднимает docker контейнеры:
Zookeeper
Kafka
Schema Registry (Confluent)
Connect (Kafka Connect)
ksqlDB
Elasticsearch
SQLite
Kibana
Регистрирует Avro схему сущностей, которые будут обрабатываться в Kafka. Регистрация осуществляется с помощью Gradle Plugin:
id 'com.github.imflog.kafka-schema-registry-gradle-plugin' version "1.12.0"Проводит чистую сборку микросервисов.
Создает индекс
orders.v1в ElasticSearch-
Конфигурирует Kafka Connect для:
получения данных из SQLite (таблица customers) и записи лога изменений в Kafka (паттерн Change Data Capture)
записи данных из топика Kafka
orders.v1в индексorders.v1ElasticSearch
Настраивает Kibana для просмотра записей из ElasticSearch.
Возможные проблемы
У меня на виртуальной машине Ubuntu 22.04 изначально не запустился контейнер elasticsearch, так как требовалось установить значение vm.max_map_count не ниже 262144. Если возникает такая проблема, то можно выполнить следующую команду:
sudo sysctl -w vm.max_map_count=262144После того, как скрипт отработает, можно запускать микросервисы. Самый простой вариант - запустить в IntellijIDEA все микросервисы, кроме populator. Populator следует запустить в последнюю очередь, так как он будет постоянно генерировать данные и отправлять POST запросы в orders-service на создание заказа (1 заказ в секунду), а также посылать сообщения в Kafka топики: warehouse-inventory.v1 и payments.v1.
Можно дать сервису populator поработать несколько секунд (15-30) и после этого остановить. Чтобы прочитать содержимое топиков Kafka (последние 5 сообщений в топике) необходимо выполнить следующий скрипт (опять же в зависимости от того, какой docker установлен):
./read-topics-docker-new.shили
./read-dopics-docker-old.shВ конце необходимо остановить docker контейнеры:
docker compose downКомментарии (7)

olegchir
23.11.2023 11:07+1ОЗУ для Docker не менее 8 Гб
ОЗУ для микросервисов не менее 8 Гб. (Точно запускается на Ubuntu 22.04 с 64 Гб ОЗУ и 8 ядрами процессора)Господи, какая БОЛЬ
Тут еще нужно про процессор ноутбука и систему охлаждения минимальные системные требования
У меня сейчас стоит ноут молотит микросервисы, я боюсь к нему прикасаться, работаю на нем через удаленный рабочий стол с другого ноутбука

astamur
23.11.2023 11:07Хорошая статья, много подробностей описали. Думаю будет интересно новичкам в стримминге данных. Ну и, раз уж столько элементов не поленились реализовать, единственное, что, на мой взгляд, упущено из важного - это БД для хранения заказов.
Хранить всю историю заказов в Кафке и использовать ее как хранилище (точнее стейт сторы на основе нескольких топиков) будет не очень правильным в данном случае.
Если случится перебалансировка партиций в Kafka Streams, стейт стор будет восстанавливаться, причем довольно долго, если топик большой. А значит, получить информацию по заказу будет невозможно. Плюс надо подумать о транзакциях, заказы вещь такая. Если использовать exactly once semantics в Kafka Streams, то причин для перебалансировки будет ещё больше)) Механизм довольно прихотливый. С БД будет проще и надёжнее.
В целом, я бы первый сервис сделал со своей БД и без KS, слал бы заказы в Кафку после записи в БД, слушал бы топики с результатами от всех остальных тропиков и менял статус заказа. Вынес бы KS в отдельный сервис и это сделало бы архитектуру стабильнее.
Желаю Вам удачи!
astamur
23.11.2023 11:07Правда теперь тут появляется проблема двойной записи (Dual Writes) и нам нужна CDC (change data capture) или SAGA, например. Да, реальность сурова.

aasmc Автор
23.11.2023 11:07Спасибо за замечание! Да, действительно с таким подходом будет более стабильная архитектура. Тут можно было бы использовать, например, Postgres в качестве основной базы для заказов и Debezium в качестве source / sink Kafka connector. В статье же я придерживался того подхода, который предлагают в Confluent, где они используют саму Kafka в качестве single source of truth.

awto
23.11.2023 11:07Можно ещё сильно упростить бизенес-логику за счет workflow-as-code, которые превращает простой Java код в Kafka Stream процессор - https://github.com/javactrl/javactrl-kafka
olegchir
Привет! Крутая статья) Я бы добавил в список хабов Java. Это агрегатор всех Java-технологий, включая JVM-бэкенд.
aasmc Автор
Спасибо за совет! Добавил)