Привет, Хабр! Меня зовут Сергей Кулабухов, я работаю над ИТ-проектами компании Fix Price, в частности, занимаюсь внедрением ИИ в бизнес‑процессы. С появлением моделей обработки естественного языка (natural language processing) изменился и подход к реализации подобных задач. Теперь мы не программируем и не обучаем, а просто объясняем, что необходимо сделать.
В этой статье мы затронем тему перевода специфических текстов, таких как описание товара со всеми сокращениями и аббревиатурами, на не менее специфичные языки, такие как арабский или монгольский. Именно с ними я решил поэкспериментировать и посмотреть, на сколько ИИ лучше справится профессиональных переводчиков.
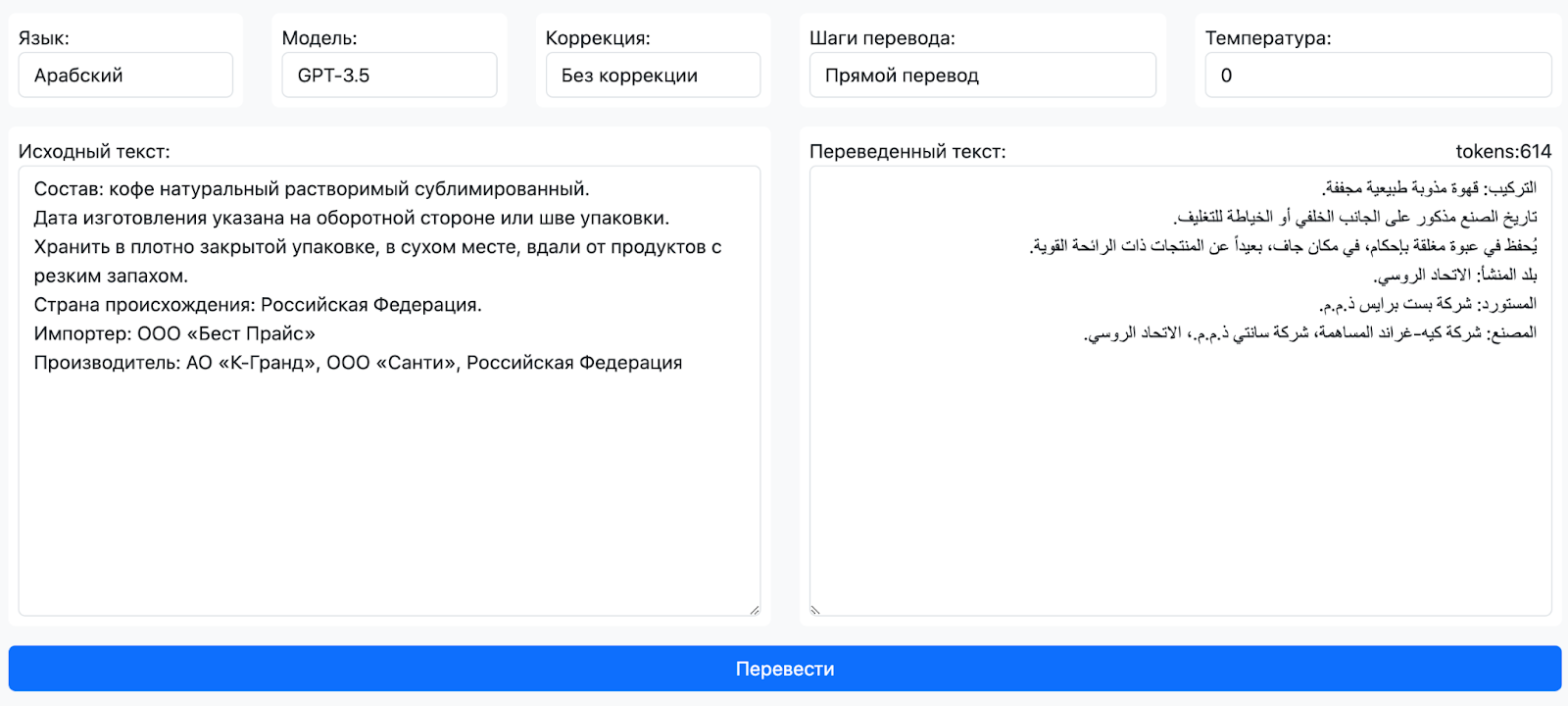
Итак, мы для эксперимента мы взяли тысячи сложных текстов с характеристиками и составом продукта на нескольких языках (ценники) и начали тестировать различные гипотезы с целью получить на выходе переведенные тексты, которые бы не отличались от качественного перевода агентством, в котором работают носители языка.
Почему бы не воспользоваться обычным онлайн-переводчиком? Дело в том, что они имеют ряд недостатков:
Переведенные тексты не выглядят естественными. Это связано с особенностями конструкций каждого языка и устойчивыми выражениями.
Не всегда правильно подбираются слова согласно контексту. Термины и омонимы в разных языках могут вовсе перевернуть суть предложения.
Сокращения и аббревиатуры либо не переводятся, либо переводятся неправильно. Чего стоит одна только транслитерация сокращения «асс» (в ассортименте) на английский язык…
Путаница во временах, падежах, именах собственных и многое другое.
Есть, конечно, вариант заказа перевода у специалистов, но даже без учета стоимости это занимает много времени. Поэтому мы обратились за помощью к нашим «цифровым» братьям.
В эксперименте участвовали:
Модель от YandexGPT
Модели GPT-3.5 и GPT-4 от OpenAI
Многочисленные модели с портала HuggingFace
Мы подготовили несколько текстов на русском и английском языках, выполнили их перевод через все сервисы с различными вариантами настроек «температуры» и точности, после чего передали на проверку носителям языка. Результат одновременно и подтвердил наши ожидания, и удивил. С одной стороны, я и делал ставку на OpenAI, но то, что GPT-3.5 в задаче перевода текстов окажется лучше чем GPT-4, для меня оказалось сюрпризом. Скорее всего, это связано с тем, что GPT-4 как более «умная» модель, несмотря на настройки, так и норовил добавить что‑то от себя либо изменить в тексте, в то время как GPT-3.5 работал четко в рамках задачи.
Ну, оно и к лучшему: генерирует быстрее, расценки приятнее ????
Стоит упомянуть, что еще один критерий, который был определяющим для нас — это возможность управлять качеством и форматом перевода не через обучение и тюнинг моделей, а путем изменения постановки задачи на русском языке.
Теперь перейдем к примеру и деталям реализации.
Код получения перевода на языке программирования Python выглядит так:
import openai
import requests
client = OpenAI(api_key=«your key»)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": INSTRUCTION},
{"role": "user", "content": TEXT}
],
temperature=0,
max_tokens=2048,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
Поясним каждый параметр:
model — “мозг” нашей операции, модель, которая будет обрабатывать запрос.
messages — так как OpenAI использует концепцию чата для генерации текста, необходимо передать набор сообщений по ролям. В нашем случае мы передаем сообщение с ролью “system” для передачи инструкции и с ролью “user” для передачи самого текста.
INSTRUCTION — инструкция, что именно нужно сделать с переданным текстом, на какой язык перевести, что учесть при обработке и т.д. Работу по подготовке инструкции обсудим отдельно ниже.
TEXT — исходный текст для перевода.
temperature — этот параметр контролирует «творческую» свободу модели при генерации ответа. 0 означает, что модель будет стремиться давать более предсказуемые и последовательные ответы, а с повышением ближе к 1 будет использовать больше ”креатива”.
max_tokens — определяет максимальное количество токенов (слов, символов, знаков пунктуации) в ответе.
top_p — этот параметр управляет разнообразием возможных ответов, которые модель может сгенерировать. 1 означает, что модель будет использовать только самые вероятные варианты.
frequency_penalty и presence_penalty — эти параметры, используются для уменьшения или увеличения вероятности повторения определенных слов или информации в ответе. 0 означает, что никаких штрафов или изменений в повторении не будет.
Работа с инструкцией – это отдельный вид искусства.
Вариант 1:
|
Переведи следующий текст на стандартный литературный арабский язык. Дай только переведенный текст на арабский язык без пояснений. |
Важно не только обозначить задачу, но и описать формат ожидаемого ответа, иначе модель может добавить предисловие или вывод.
Вариант 2:
|
Переведи следующий текст на стандартный литературный арабский язык. Сохрани отступы и переносы строк. Учти тематику товарных этикеток и описания товара для арабских потребителей. Для сокращений и аббревиатур подбери характерные для арабского языка аналоги. Дай только переведенный текст на арабский язык без пояснений. |
Проанализировав тексты своими силами, пришли к добавлению в инструкцию информации о тематике, отступах и подбору аналогов сокращений. С такой инструкцией были подготовлены переводы для проверки у специалистов.
Вариант 3
|
Переведи следующий текст на стандартный литературный арабский язык. Сохрани отступы и переносы строк. Учти тематику товарных этикеток и описания товара для арабских потребителей. Для сокращений и аббревиатур подбери характерные для арабского языка аналоги. Перевод должен быть естественным и легко читаем на арабском языке. Переведи технические детали и инструкции, обеспечивая точность и однозначность. Адаптируй фразы и выражения с учетом культурных особенностей арабского языка. Дай только переведенный текст на арабский язык без пояснений. |
Когда мы получили скорректированные тексты, то попросили ChatGPT самостоятельно поработать над своими же ошибками, сравнив свой перевод и перевод от носителя языка. Для человека эти последние 3 строчки, которые нейросеть попросила добавить, могут показаться весьма «абстрактными», но эффект был поразительный. Результаты получились идентичными эталонным переводам носителями языка.
Дальнейшие шаги по совершенствованию инструмента
На данном этапе переводы уже достаточно высокого качества. Безусловно есть еще над чем поработать. Мы продолжим оттачивать инструкцию, а также собирать датасет для дальнейшего тюнинга модели. Параллельно ведется добавление новых языков в систему: армянского, белорусского, грузинского, казахского, латышского, монгольского и узбекского.
Насколько цель оправдывает средства
Инновация ради инновации — не наш метод! Поэтому мы произвели примерный расчет выгоды по срокам и стоимости выполнения работ при использовании ИИ. Для перевода 1 страницы сложного текста на арабский язык потребуется:
профессиональному переводчику — 30–60 минут при средней цене 1000–1500 ₽
носителю языка — 30–60 минут и около 3000 ₽
ИИ — до 2-х минут и 0,3 ₽
Таким образом, получаем стоимость перевода при помощи ИИ примерно в 4000 раз дешевле, чем у профессиональных переводчиков, и в 10 000 раз дешевле, чем у носителей языка, а времени при этом затрачивается в 15–30 раз меньше.
P.S. Для тех кому интересен бэкстейдж
Помимо прямого перевода текстов с русского на иностранный мы пробовали также перевод после предварительной подготовки текста и постобработку результата. Из личного опыта использования онлайн‑переводчиков я вынес понимание, что лучше всего они справляются, когда либо исходный текст на английском языке, либо целевой язык английский. Собственно предварительная подготовка заключалась в переводе текста на русском (с такой же инструкцией) на английский язык, а потом уже на арабский. Таким образом, я встраивал в цепочку перевода посредника, который мог в теории нивелировать сложности обоих языков. К сожалению, этот метод не оправдал ожиданий.
Также командой была предпринята попытка постобработки перевода с инструкцией, в которой разными способами описывался процесс исправления ошибок и адаптации текста для носителей языка. Переводы действительно становились более «интересными», но теряли свою точность и обзаводились несуществующими в оригинальных текстах подробностями.
На этом мы оставили попытки усложнять механизм.