ACM RecSys — международная конференция, на которой эксперты в области рекомендательных систем делятся своими наработками и исследованиями, задавая тренды развития технологий и подходов. Команда ОК изучила статьи конференции RecSys 2023 и сделала разбор наиболее интересных из них. Первая часть разбора — в этой статье (часть 1). Вторая выйдет в ближайшее время. Если вы хотите читать материалы, как только они появляются, подписывайтесь на канал ML-команды ОК. В канале мы выкладываем разборы интересных статей по теме ML и делимся экспертизой, которую накопили за 12 лет в этой сфере.
Augmented Negative Sampling for Collaborative Filtering
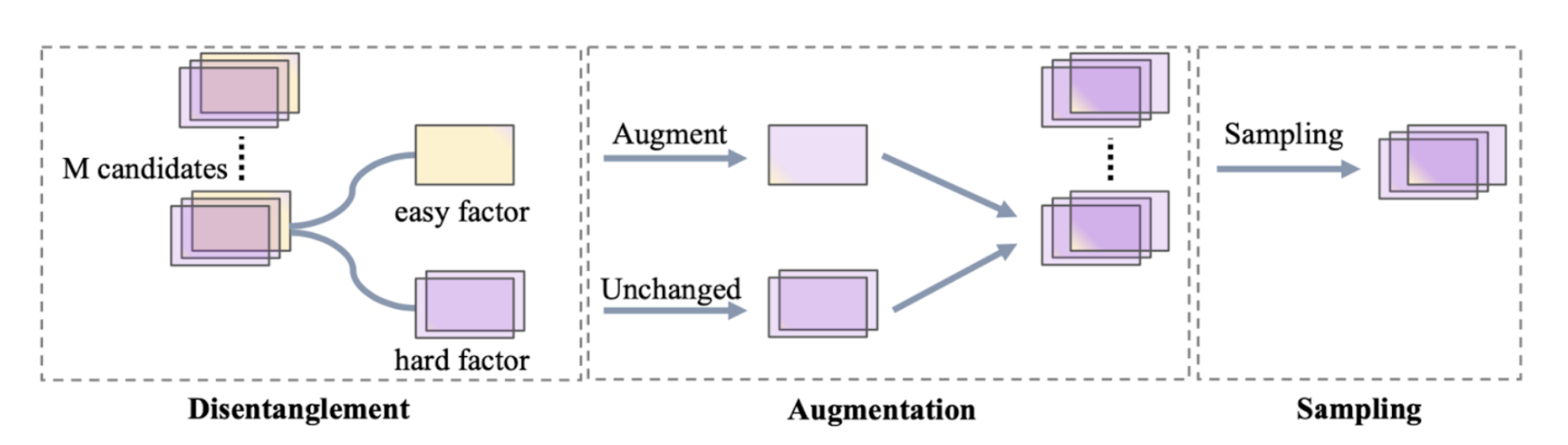
В задаче рекомендаций с неявным фидбэком данные состоят только из «положительных» пар пользователь-айтем. Например, в рекомендациях видео положительными могут считаться ролики, которые пользователь посмотрел до конца. Для того чтобы обучить модель, нужны и «отрицательные» пары – их получают с помощью процедуры семплирования негативных. Базовый вариант этой процедуры – выбирать в качестве негативных айтемы пропорционально их популярности.
Авторы статьи предлагают новый подход к семплированию негативных, основанный на аугментации данных. Факторы, которые описывают айтемы, делятся на две группы:
easy factors (легкие факторы);
hard factors (сильные факторы).
Сильные факторы положительно влияют на качество модели, в то время как легкие факторы ухудшают модель или ничего не меняют. Нужно специальным образом зашумить легкие факторы и объединить их с сильными факторами. С помощью жадного алгоритма из получившегося множества аугментированных айтемов отбирают несколько сэмплов в качестве негативных.
Авторы оценивали эффективность своего метода на трёх датасетах с использованием матричной факторизации с BPR лоссом. Почти во всех экспериментах предложенный алгоритм оказался лучше конкурентов. Недостатки подхода такие:
время обучения вдвое больше, чем при базовом семплировании негативных;
добавляется два гиперпараметра, которые нужно настраивать под конкретные данные.
InTune: Reinforcement Learning-based Data Pipeline Optimization for Deep Recommendation Models
IT-гиганты используют большие нейросети (DLRM), чтобы строить персонализированные рекомендации для сотен миллионов пользователей. Количество обучаемых параметров у таких моделей сравнимо с количеством параметров у современных языковых моделей. При этом DLRM намного проще трансформеров с точки зрения архитектуры. Поэтому при обучении DLRM узкое место — не вычисления внутри нейронной сети, а процесс подготовки данных, который состоит из нескольких этапов:
загрузки данных с диска;
формирования батчей;
перемешивания;
преобразований данных;
загрузки данных на GPU.
Если хотя бы один из этапов «тормозит» — весь процесс замедляется, а вместе с ним замедляется и обучение. Решением в этой ситуации является распараллеливание каждого из этапов на нескольких процессорах, причем так, чтобы пропускная способность всех этапов была одинаковой.
Ключевым вопросом здесь становится выявление необходимого количества процессоров на каждом этапе. Оказывается, что для DLRM стандартные инструменты вроде AUTOTUNE работают недостаточно хорошо: процессоры используются неоптимально, переполняется память. Разработчики из Netflix предлагают собственное решение.
Представленный в статье фреймворк InTune основан на обучении с подкреплением в такой постановке:
Action. Агент InTune может увеличивать или уменьшать количество процессоров, которое выдается каждому этапу подготовки данных.
State. В качестве параметров среды агент наблюдает метрики процесса обучения — например, текущую пропускную способность и объём свободной памяти в кластере.
Reward. С помощью Q-learning агент учится выделять ресурсы так, чтобы скорость обучения была максимальной при минимальном использовании памяти.
Эксперименты показали, что под управлением InTune модель обучается в 2,3 раза быстрее, чем под управлением AUTOTUNE, а доля падений по памяти снижается с 8% до нуля. Авторы не опубликовали исходный код, но идея достаточно простая, чтобы повторить её в «домашних условиях».
Бонус: предложенный в статье фреймворк может быть полезен не только для обучения DLRM. Например, его можно прикрутить для автоматического выделения ресурсов приложениям Spark.
Leveraging Large Language Models for Sequential Recommendation
Статья предлагает три способа использования LLM для рекомендательных систем.
LLMSeqSim
Используем LLM для получения эмбеддингов айтемов на основании их описаний. Из эмбеддингов айтемов, просмотренных пользователем, формируем общий эмбеддинг сессии тремя способами:
среднее;
взвешенное среднее в зависимости от позиции айтема в последовательности;
эмбеддинг последнего айтема.
В качестве рекомендаций выбираем k айтемов, эмбеддинги которых ближе всего к эмбеддингу сессии.
LLMSeqPrompt
Дообучаем LLM предсказывать следующий айтем в последовательности. На этапе вычисления рекомендаций модель может предлагать уже просмотренный или несуществующий айтем. В таком случае рекомендуем айтем, ближайший к предложенному в пространстве эмбеддингов.
LLM2BERT4Rec
Аналогично LLMSeqSim получаем эмбеддинги айтемов из их описаний. Используем эти эмбеддинги для инициализации Bert4Rec. Если необходимо, приводим эмбеддинги из LLM к нужной размерности с помощью Principal Components Analysis (PCA).
Эксперименты
Авторы сравнили предложенные методы на двух датасетах: Amazon Beauty и Delivery Hero. Точность моделей измерялась метриками NDCG, MRR и HitRate. Помимо этого, оценивались метрики catalog coverage, serendipity и novelty.
Сравнение показало, что LLM2BERT4Rec и LLMSeqSim работают лучше, чем бейзлайны без LLM. Победила модель LLM2BERT4Rec, которая превзошла Bert4Rec по NDCG на 15-20%.
Efficient Data Representation Learning in Google-scale Systems

В больших нейросетевых рекомендерах количество уникальных значений sparse-признаков измеряется миллиардами. Из-за этого почти все обучаемые параметры содержатся в таблицах эмбеддингов. Такие таблицы занимают сотни гигабайт памяти GPU – это вызывает проблемы при обучении и применении моделей.
Для распределения значений признаков по таблицам эмбеддингов можно использовать хеш-функции. Помимо снижения необходимого объёма памяти это позволяет дообучать модели онлайн. При появлении нового значения не нужно увеличивать таблицу — достаточно посчитать хеш-значения и использовать уже существующую строку.
Недостаток использования хеш-функций – снижение метрик из-за возникающих коллизий. Однако можно подобрать компромисс, при котором потери в качестве модели будут малы, а количество места, занимаемого эмбеддингами, снизится в несколько раз.
Авторы статьи предлагают подход к построению таблиц эмбеддингов, который называется Feature Multiplexing Framework. Идея в том, чтобы использовать одну таблицу для представления разных признаков. Переиспользование параметров позволяет уменьшить требования к памяти и время поиска. При этом качество предсказаний не страдает, так как модели проще научиться работать с коллизиями между разными признаками, чем с коллизиями внутри одного признака. Это происходит из-за того, что обработка разных признаков происходит разными частями модели, каждая со своим набором обучаемых параметров. В качестве такой модели можно использовать DCN-V2.
Авторы приводят результаты применения предложенного подхода к пяти задачам. Во всех экспериментах увеличились как офлайн, так и онлайн метрики (см. таблицу в начале поста). Более того, Feature Multiplexing Framework уменьшает количество гиперпараметров: раньше нужно было выбирать размерность таблиц эмбеддингов каждого признака, а теперь только одной. Кажется, в том, что предлагают исследователи из DeepMind, одни плюсы и никаких минусов.
Trending Now: Modeling Trend Recommendations

В статье рассматривается задача построения рекомендаций «Сейчас в тренде». Она состоит в определении айтемов рекомендательной системы, которые быстрее других набирают популярность у пользователей. Чтобы формализовать определение трендовых айтемов, авторы вводят несколько определений:
Временной шаг — временной интервал с предопределенной длительностью Δt (например, 1 час).
Скорость роста популярности айтема W(t) — количество взаимодействий пользователей с айтемом за один временной шаг.
Ускорение роста популярности айтема A(t) — разность скорости айтема в текущий временной шаг с его скоростью в предшествующий временной шаг.
Авторы предлагают для каждого айтема прогнозировать его ускорение в следующем временном шаге A(t+1) и считать трендовыми айтемы с наибольшим предсказанным ускорением. Так как количество взаимодействий в текущий и все предшествующие временные шаги известно, задача сводится к прогнозированию временного ряда.
Кроме данных о количестве взаимодействий в рекомендательных системах доступна информация о пользователях, совершающих эти взаимодействия. Гипотеза статьи состоит в том, что если аудитория двух айтемов сильно пересекается, то они будут следовать одинаковым трендам. Для учета коллаборативной информации авторы предлагают архитектуру TrendRec, которая состоит из двух компонентов (см. рисунок):
коллаборативный компонент, реализованный с помощью стандартной two-tower модели на GRU4Rec, решает задачу next item prediction;
авторегрессионный компонент предсказывает ускорение айтемов с помощью модели DeepAR и эмбеддинга айтема.
Таким образом коллаборативный и авторегрессионный компоненты уточняют друг друга, деля между собой общий эмбеддинг айтема.
Для оценки качества предсказания трендовых айтемов авторы разработали две собственные метрики. В экспериментах на пяти датасетах по предложенным метрикам TrendRec победил все бейзлайны.
Uncovering User Interest from Biased and Noised Watch Time in Video Recommendation

При работе с рекомендациями видео часто стоит задача спрогнозировать время, в течение которого пользователь будет просматривать ролик (watch time). На этот показатель, помимо собственно интереса пользователя к видео, влияют и другие факторы:
Duration Bias. Чем больше длительность видео, тем больше будет watch time. Это приводит к тому, что рекомендер будет чаще предлагать длинные видео, вне зависимости от реального интереса пользователя.
Noisy Watching. Пользователям нужно некоторое время, чтобы понять, нравится видео или нет. Поскольку пользователи доверяют рекомендательным системам и вообще падки на кликбейт, то часто наблюдается такой паттерн: пользователь запускает рекомендованное видео, далее в течение нескольких секунд понимает, что оно не нравится, и закрывает его. При этом в системе залогируется ненулевой watch time, на котором потом будет учиться рекомендательная модель.
На графиках проиллюстрированы эти эффекты. Слева – рост watch time при увеличении duration для понравившихся видео, а справа – существенно отличные от нуля времена просмотров для непонравившихся видео.
Авторы анализируют существующие подходы к предсказанию времени просмотра: Play Complete Rate (PCR), Watch Time Gain (WTG), Duration-Deconfounded Quantile-based Method (D2Q). Эти методы используют эвристические модификации watch time в качестве показателя пользовательского интереса. Их недостаток в том, что они требуют выполнения условий, которые нарушаются в реальных задачах.
В статье предложен новый подход Debiased and Denoised Watch Time Correction (D2Co). Видео группируются по длительности, затем строятся распределения времени просмотра внутри каждой группы. Оказывается, что эти распределения носят бимодальный характер. Поэтому делается допущение, что watch time можно приблизить моделью гауссовой смеси (Gaussian Mixture Model) из двух компонент:
первая отвечает за duration-biased watch time;
вторая — за noisy watching составляющую.
При этом авторы делают смелое допущение (wild assumption), что эти компоненты имеют нормальные распределения. Для получения чистого пользовательского интереса к видео эти компоненты выучиваются и удаляются из watch time.
Работа модели проверялась на двух датасетах (WeChat, KuaiRand) с видео длительностью от 5 от 240 секунд. Для определения «реального» пользовательского интереса использовались лайки, комментарии, а также длинные просмотры. В качестве рекомендательных моделей брались матричные факторизации на PyTorch. Новая модель сравнивалась с упомянутыми выше (PCR, WTG, D2Q) по метрикам GroupAUC и nDCG@K.
На всех тестах новая модель показала прирост в метриках, но незначительный — в третьем знаке после запятой. Кроме того, авторы провели А/B-тестирование, которое также показало небольшой прирост.
С одной стороны, предложенный подход помогает очистить время просмотра от «мусорных» компонент и оставить в нём только чистый пользовательский интерес. Алгоритм легко реализовать, но потребуется время на подбор гиперпараметров. С другой стороны, прирост в метриках небольшой, и кажется, что в большинстве случаев можно ограничиться простой WTG-моделью, дополненной эвристиками для удаления выбросов. Теоретически этот подход применим не только к видео, но и, например, к рекомендациям длинных текстов, хотя для них гораздо сложнее определить «время просмотра».
Integrating Offline Reinforcement Learning with Transformers for Sequential Recommendation

В статье решается задача последовательных рекомендаций, в которой очередная рекомендация строится, исходя из предыдущих взаимодействий пользователя. Цель авторов – оптимизировать долгосрочную метрику рекомендера. Для этого они предлагают использовать offline reinforcement learning.
В основе подхода – алгоритм Actor-Critic, в котором обучаются две модели: actor и critic (сюрприз!).
Actor принимает на вход последовательность айтемов пользователя и выдаёт рекомендацию (policy). Для эмбеддинга последовательности используется трансформер на основе DistilGPT2.
Critic оценивает долгосрочный эффект (Q-функцию) рекомендации, которую выдал actor, также используя последовательность айтемов пользователя. Здесь последовательность эмбеддится с помощью LSTM.
Процесс рекомендаций смоделирован, как задача последовательного принятия решений RL-агентом. Оказалось, что обучать такую архитектуру только с помощью RL неэффективно, поэтому actor сперва предобучают на задаче next-item-prediction. После этого вся архитектура учится оптимизировать долгосрочный reward с помощью алгоритма CRR.
Эксперименты проводились на датасетах MovieLens 25M и Yoochoose. Предложенная архитектура сравнивалась как с бейзлайнам (SASRec, Caser), так и с собственными отдельными компонентами (Transformer-only, CRR-only). На графиках показаны кривые обучения двух этапов эксперимента на MovieLens-25M. На первом этапе претрейна Transformer-only модель быстро достигает лучших результатов. На втором этапе с помощью CRR файнтюнинга авторы улучшили модель, добившись роста метрики в 1,5 раза. В итоге предложенная модель победила бейзлайны в 11 из 12 экспериментов. Авторы не представили результаты A/B-тестов реальных рекомендеров. Так что предложенный метод пока можно считать теоретическим — он ещё требует проверок в «реальном бою».
Вторая часть разбора появится в блоге в ближайшее время. Если вы хотите читать материалы постепенно, подписывайтесь на канал ML-команды ОК
титульная картинка сгенерирована нейросетью kandinsky по запросу: "программист в оранжевой футболке читает научную статью с конференции"