Всем привет, меня зовут Александр Бобряков. Я техлид в команде МТС Аналитики, занимаюсь Real-Time обработкой данных. Мы начали использовать фреймворк Apache Flink, и я решил поделиться на Хабре своим опытом внедрения этой технологии в цикле статей.
В предыдущей части «Как использовать Spring в качестве фреймворка для Flink-приложений» я рассказывал, как реализовать минимальное Flink-приложение с использованием фреймворка Spring. Мы запустили первую Flink-задачу в поднятом в docker-compose кластере, а также проверили корректность результата по соответствующим логам. В этой статье решим реальную бизнес-задачу дедупликации данных в пайплайне Kafka-to-Kafka.

Список моих постов про Flink
Весь разбираемый исходный код можно найти в репозитории. Этот пост соответствует релизной ветке с названием release/2_Deduplicator_Flink_Job.
Оглавление статьи
Задача дедупликации событий
В этой статье мы решим реальную бизнес-задачу, для которой подходит Apache Flink.
Источник данных (Source): Kafka-топик «click-topic», содержащий сообщения кликов пользователей по любым размеченным сайтам. Структура ClickMessage представляет собой JSON:
{
"userId": "9b22fa1f-f03a-414b-ad43-ca3efeb3047c",
"object": "test_object",
"platform": "APP",
"productName": "test_productName",
"productTopic": "test_productTopic",
"timestamp": 123,
"data": {
"field_1": "value_1",
"field_2": "value_2"
}
}Поле platform определяет тип устройства, с которого произвели клик.
Задача: нужно дедуплицировать поступающие сообщения. Для сообщений с типом устройства platform = APP дедупликация должна происходить в окне в 7 дней.
Например, если мы уже встречали клик от пользователя userId=1 и timestamp=123 с platform=APP в течение последних 7 дней, то это сообщение не пропускаем дальше в выходной топик Kafka.
События с типом устройства «WEB» дедуплицировать не нужно, а события с других устройств не следует пропускать дальше по пайплайну. Их мы будем сразу отфильтровывать. Чтобы упростить задачу, будем считать, что дедупликация производится в разрезе id пользователя + timestamp.
Приёмник данных (Sink): Kafka-топик «product-topic», требующий сообщения ProductMessage, образованного путём прямого сопоставления полей из ClickMessage:
{
"userId": "3ad4ed72-2a36-489b-97ca-8243be793395",
"productName": "test_productName",
"object": "test_object",
"platform": "APP",
"timestamp": 123
}Уточнение: вообще, для подобной задачи нужно настроить семантику доставки Exactly Once с определением точек сохранения (checkpoints). В этой статье такую настройку рассматривать не будем, но вы можете ознакомиться со статьёй в блоке по Apache Flink, чтобы улучшить понимание темы. Вместо этого в качестве примера мы будем использовать семантику At Most Once.
Целевой пайплайн
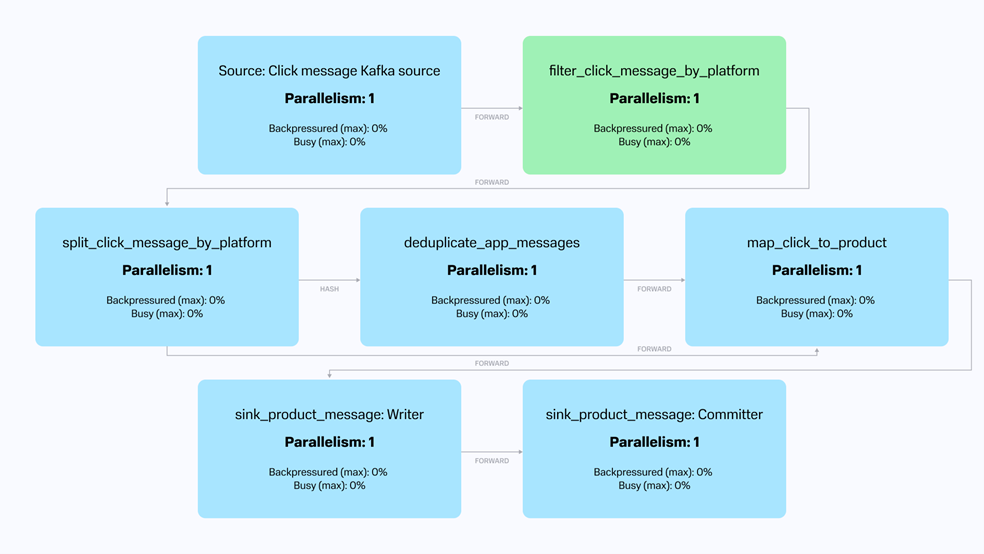
В результате построения джобы у нас должен получиться следующий граф обработки данных:

В начале идёт Source из Kafka-топика «click-topic». Затем мы фильтруем сообщения по полю «platform», пропуская дальше сообщения со значением APP или WEB. Далее разделяем поток на два по значению «platform»: получаем APP- и WEB-потоки.
Поток APP дедуплицируется в окне 7 дней, а поток WEB никак не изменяется. После этого сообщения от двух потоков преобразуются в формат ProductMessage (оператор map) и попадают в Kafka Sink — топик «product-topic».
Построение Flink Job Kafka-to-Kafka
Определение DTO для сообщений
Под заданные форматы JSON-сообщений нужно определить DTO-классы, которыми будем оперировать путём де-/сериализации через Jackson (ObjectMapper). ClickMessage:
@Data
@Builder
@Jacksonized
@JsonIgnoreProperties(ignoreUnknown = true)
public class ClickMessage {
@JsonProperty(required = true)
@JsonPropertyDescription("User id")
private UUID userId;
@JsonPropertyDescription("Clicked object")
private String object;
@JsonPropertyDescription("User platform")
@JsonDeserialize(using = Platform.Deserializer.class)
private Platform platform;
@JsonPropertyDescription("Product name")
private String productName;
@JsonPropertyDescription("Product topic")
private String productTopic;
@JsonProperty(required = true)
@JsonPropertyDescription("Timestamp")
private Long timestamp;
@JsonPropertyDescription("Additional data")
private Map<String, Object> data;
}ProductMessage:
@Data
@Builder
@Jacksonized
@JsonIgnoreProperties(ignoreUnknown = true)
public class ProductMessage {
@JsonPropertyDescription("User id")
private UUID userId;
@JsonPropertyDescription("Product name")
private String productName;
@JsonPropertyDescription("Clicked object")
private String object;
@JsonPropertyDescription("User id")
@JsonDeserialize(using = Platform.Deserializer.class)
private Platform platform;
@JsonPropertyDescription("Timestamp")
private Long timestamp;
}Обратите внимание, что поле «platform» мы определили через интерфейс Platform, создав две его имплементации:
enum Enum implements Platform {
WEB, APP, SMART_TV, CONSOLE;
...
}и через стандартный класс для всех других значений:
@Value
class Simple implements Platform {
String value;
@Override
@JsonValue
public String value() {
return value;
}
}О преимуществах такого подхода можно почитать в статье.
Определение настроек Kafka
Для настройки подключения к Kafka удобно определить стандартные свойства в application.yml:
kafka:
group-id: group_id
bootstrap-servers: localhost:29092
topics:
click-topic: 'click-topic'
product-topic: 'product-topic'Будем их мапить на наш класс KafkaProperties:
@ConfigurationProperties("kafka")
@ConstructorBinding
@RequiredArgsConstructor
@Getter
public class KafkaProperties {
@NotNull(message = "Kafka group-id cannot be null")
private final String groupId;
@NotNull(message = "Kafka bootstrap servers cannot be null")
private final String bootstrapServers;
@NotNull(message = "Topics cannot be null")
private final Topics topics;
@ConfigurationProperties(prefix = "topics")
@ConstructorBinding
@RequiredArgsConstructor
@Getter
public static class Topics {
@NotEmpty(message = "Click Topic cannot be null or empty")
private final String clickTopic;
@NotEmpty(message = "Product Topic cannot be null or empty")
private final String productTopic;
}
}Определение Kafka Source

Для создания источника данных на основе Kafka нам нужно воспользоваться Flink-классом KafkaSourceBuilder. Для этого пригодится новая зависимость:
implementation "org.apache.flink:flink-connector-kafka:${flinkVersion}"Создадим абстракцию SourceBinder. Её будем использовать, чтобы создавать и регистрировать в пайплайне источник:
public interface SourceBinder<T> {
DataStream<T> bindSource(StreamExecutionEnvironment flink);
}Реализация Kafka-источника базируется на примерах из документации и особо от них не отличается:
@Component
@RequiredArgsConstructor
class ClickMessageKafkaSourceBinder implements SourceBinder<ClickMessage> {
private final KafkaProperties kafkaProperties;
private final DeserializationSchema<ClickMessage> deserializationClickMessageSchema;
@Override
public DataStream<ClickMessage> bindSource(StreamExecutionEnvironment environment) {
final String sourceName = "Click message Kafka source";
return environment.fromSource(
KafkaSource.<ClickMessage>builder()
.setBootstrapServers(kafkaProperties.getBootstrapServers())
.setStartingOffsets(OffsetsInitializer.committedOffsets(EARLIEST))
.setGroupId(kafkaProperties.getGroupId())
.setTopics(kafkaProperties.getTopics().getClickTopic())
.setValueOnlyDeserializer(deserializationClickMessageSchema)
.build(),
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(1)),
sourceName
).name(sourceName).uid(sourceName + "_id");
}
}Этот класс будем использовать в реализации джобы обработки данных Kafka-to-Kafka. Посмотрим на его реализацию. Для начала нужно указать источник данных пайплайна в StreamExecutionEnvironment. Для этого есть множество методов: fromSource(...), addSource(...), fromCollection(...) и другие, которые понадобятся нам во время тестирования.
Общие настройки
Для создания самого источника данных из Kafka используется стандартный KafkaSourceBuilder, который настраиваем с помощью наших пропертей.
Нужно задать WatermarkStrategy, который определяет, как создавать «водяные знаки» в источнике потока данных.
В нашем случае удобно использовать стратегию BoundedOutOfOrdernessWatermarks. Она определяет ситуации, в которых записи могут поступать не по порядку, но мы устанавливаем максимальную задержку. Эта задержка — максимальная разница между отметкой времени сообщения и самой большой меткой времени из всех ранее загруженных сообщений. Подробнее об этом можно почитать в документации.Также обратим внимание на начальную установку оффсетов EARLIEST. Это значит, что мы начнём читать с оффсетов, зафиксированных ранее для текущей консьюмер-группы.
Но если таких оффсетов нет, начнём читать топик с самого начала. Важное замечание: Flink фиксирует оффсеты в Kafka только в моменты создания контрольных точек. Поэтому в случае 5-минутных чекпоинтов мы увидим на графике 5-минутные графики лага.
Десериализация
Одна из основных настроек — реализация интерфейса DeserializationSchema, определяющая, как именно нужно десериализовать сообщения, хранящиеся во входном топике. Для этого мы создадим свою реализацию ClickMessageDeserializationSchema на основе ObjectMapper.
Component
@RequiredArgsConstructor
class ClickMessageDeserializationSchema implements DeserializationSchema<ClickMessage> {
private static final long serialVersionUID = 1L;
private transient ObjectMapper objectMapper;
@Override
public void open(InitializationContext context) {
objectMapper = createObjectMapper();
}
@Override
public ClickMessage deserialize(byte[] message) throws IOException {
return objectMapper.readValue(message, ClickMessage.class);
}
@Override
public boolean isEndOfStream(ClickMessage nextElement) {
return false;
}
@Override
public TypeInformation<ClickMessage> getProducedType() {
return TypeInformation.of(ClickMessage.class);
}
}Большинство классов (например, операторы) сериализуется и десериализуется в процессе работы распределённого кластера. Это необходимо для их отправки рабочим процессам во время распределённого выполнения, поэтому метод open служит настройкой класса после десериализации в слоте TaskManager. В нём мы инициализируем ObjectMapper.
Метод deserialize используется при получении Kafka Record и десериализации значения этого рекорда. Метод isEndOfStream определяет, сигнализирует ли сообщение из Kafka об окончании потока данных.
В нашем случае сообщения из Kafka поступают бесконечно, поэтому метод всегда возвращает false, следовательно, джоба никогда сама не завершится (как мы видели в предыдущей статье на примере простой джобы). Последний метод getProducedType нужен для точного определения типов сообщений, поступающих в пайплайн. Его используют, когда тип получаемых данных может варьироваться в зависимости от дженерика интерфейса.
Flink соблюдает стандартные правила сериализации Java: он не будет сериализовать поля static или transient. В частности, ObjectMapper мы объявили как transient, поэтому при десериализации этого класса в TaskManager его нужно инициализировать. Для этого будет удобно создать единый статический метод, который мы будем использовать во всём коде проекта. В целом, можно было бы обойтись и статическим полем:
@UtilityClass
public class ObjectMapperConfig {
public static ObjectMapper createObjectMapper() {
return new ObjectMapper()
.registerModule(new JavaTimeModule())
.registerModule(new Jdk8Module());
}
}Для стандартных проектов это плохая практика, так как создание ObjectMapper — достаточно дорогая операция (Java Performance: In-Depth Advice for Tuning and Programming Java 8, 11, and Beyond).
Определение Kafka Sink

Kafka Sink реализован очень похожим образом. Но для этого используются другие Flink-абстракции. В этом случае нам нужно воспользоваться KafkaSinkBuilder, в котором и определим все Kafka-параметры.
@Component
@RequiredArgsConstructor
public class ProductMessageKafkaSinkProvider implements SinkProvider<ProductMessage> {
private final KafkaProperties kafkaProperties;
private final SerializationSchema<ProductMessage> serializationProductMessageSchema;
@Override
public Sink<ProductMessage> createSink() {
return KafkaSink.<ProductMessage>builder()
.setBootstrapServers(kafkaProperties.getBootstrapServers())
.setRecordSerializer(KafkaRecordSerializationSchema.<ProductMessage>builder()
.setTopic(kafkaProperties.getTopics().getProductTopic())
.setValueSerializationSchema(serializationProductMessageSchema)
.build())
.setDeliveryGuarantee(NONE)
.build();
}
}Тут всё интуитивно понятно: базовые настройки подключения к выходному топику Kafka. Важной настройкой является гарантия доставки, которую мы установили в NONE. Она также известна под названием at most once и говорит, что сообщение будет доставлено не более одного раза (либо 0, либо 1). В полностью рабочем состоянии сообщение вероятнее доставится один раз, но если брокеры Kafka дадут сбой или произойдёт другая редкая/нестандартная ситуация, мы можем потерять сообщение при отправке.
Для промышленного решения можно выставить гарантию Exactly once, но это потребует дополнительных настроек, глубокого анализа возможных нестандартных случаев в работе stateful-операторов, а также компромисса для обеспечения необходимого latency. Подробнее о том, как Flink гарантирует доставку с Kafka, можно почитать в статье.
Теперь рассмотрим абстракцию для сериализации выходных сообщений. Она очень похожа на описанный ранее десериализатор ClickMessageDeserializationSchema
@Component
@RequiredArgsConstructor
class ProductMessageSerializationSchema implements SerializationSchema<ProductMessage> {
private static final long serialVersionUID = 1;
private transient ObjectMapper objectMapper;
@Override
public void open(InitializationContext context) {
objectMapper = createObjectMapper();
}
@Override
@SneakyThrows
public byte[] serialize(ProductMessage element) {
return objectMapper.writeValueAsBytes(element);
}
}Дедупликатор

Основной оператор пайплайна — это дедупликатор. Он должен понять, встречали ли мы в потоке сообщение с таким же userId и timestamp. Так как окно дедупликации для APP-событий должно составлять 7 дней, удобно использовать встроенный механизм TTL для сохранения состояния. Поэтому логично передавать этот TTL в аргументы конструктора дедупликатора.
Чтобы понять его устройство, нужно познакомиться с понятием ключевого состояния в Flink. Оно вытекает из потоковой обработки данных с отслеживанием состояния, о которой мы говорили в первой из этих статей. Поэтому дедупликатор — это stateful-оператор.
По сути Keyed State — это хранилище вида «ключ-значение». Ключ мы определяем с помощью вызова метода .keyBy(...) в описании пайплайна обработки данных. В этом случае все события с одним и тем же ключом будут попадать на один определённый для них экземпляр оператора.

На картинке выше из документации Flink у источника и stateful-оператора параллельность, равная 2. Но мы уверены, что события с ключом А всегда попадают на верхний экземпляр stateful-оператора. Это важно, так как Keyed State хранится локально у каждого оператора, чтобы не было лишних затрат на согласованность состояния и передачу данных по сети.
В случае дедупликатора нам нужно хранить информацию, встречали ли мы сообщение с таким же userId и timestamp за последнее время TTL.
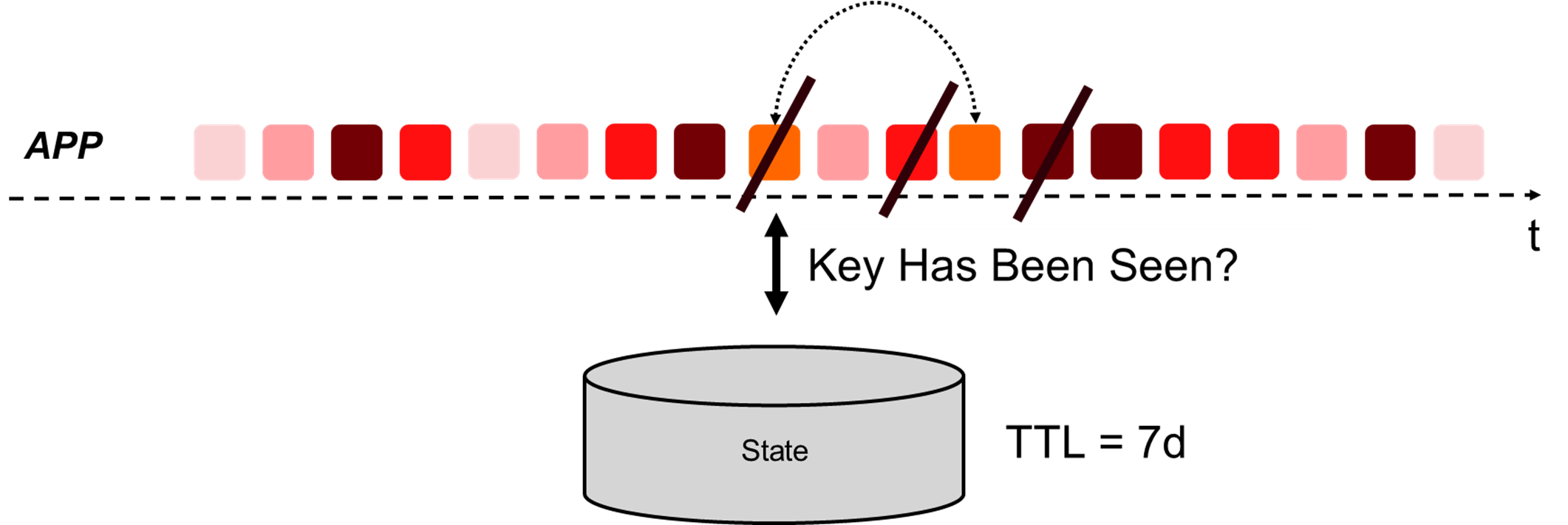
Поэтому в качестве keyBy нужно вот так передать связку userId + timestamp перед последующим вызовом дедупликатора:
sourceBinder.bindSource(env)
.keyBy(click -> click.getUserId().toString() + click.getTimestamp())
.flatMap(new Deduplicator<>(ttl)))Для вызова дедупликатора мы используем метод flatMap, потому что для входящего сообщения можно получить на выходе либо его одного, либо ни одного (в случае срабатывания механизма дедупликации). Давайте перейдём к реализации дедупликатора:
public class Deduplicator<T> extends RichFlatMapFunction<T, T> {
private static final long serialVersionUID = 1L;
private final Time ttl;
private ValueState<Boolean> keyHasBeenSeen;
public Deduplicator(Time ttl) {
this.ttl = notNull(ttl, "Deduplicator TTL is null");
}
@Override
public void open(Configuration parameters) {
final var descriptor = new ValueStateDescriptor<>("keyHasBeenSeen", Types.BOOLEAN);
final var ttlConfig = StateTtlConfig
.newBuilder(ttl)
.setUpdateType(UpdateType.OnCreateAndWrite)
.setStateVisibility(NeverReturnExpired)
.cleanupFullSnapshot()
.build();
descriptor.enableTimeToLive(ttlConfig);
keyHasBeenSeen = getRuntimeContext().getState(descriptor);
}
@Override
public void flatMap(T event, Collector<T> out) throws Exception {
if (keyHasBeenSeen.value() == null) {
out.collect(event);
keyHasBeenSeen.update(true);
}
}
}Для начала обратим внимание на наследование от класса RichFlatMapFunction. В api Flink есть множество rich-функций, которые отличаются от не rich-функций доступом к методам open() и getRuntimContext().
Метод open используется один раз для настройки оператора (его инициализации) перед началом обработки данных, но после десериализации.
Метод getRuntimeContext() переопределять не нужно, но мы можем вызывать его, когда нужно получить информацию о контексте выполнения (настройки Flink) и открыть доступ к метрикам, состоянию и т. д.
В нашем случае в конструктор передаём настроенный в application.yml TTL, который успешно сериализуется (т. к. Flink-класс Time поддерживает сериализацию) и используется в методе open для создания состояния ValueState. ValueState — это как раз состояние, в котором мы будем хранить boolean-флаг, встречали мы уже сообщение с этим ключом или нет.
Для настройки состояния под наши бизнес-требования нужно создать ttlConfig, который определяет ряд важных настроек:
UpdateType — настраивает поведение, когда обновляется отметка времени последнего доступа, продлевающая TTL состояния.
Политика OnCreateAndWrite говорит, что обновлять метку последнего доступа к записи нужно не только при создании записи, но и при последующих обновлениях по этому ключу методом state.update().
Есть ещё две политики: Disabled — когда TTL отключается и записи никогда не истекают по времени, пока сами их не удалим через state.clear(); OnReadAndWrite — когда метка последнего доступа к записи обновляется ещё и при чтении записи по её ключу.StateVisibility — указывает, можно вернуть просроченное значение или нет. Flink позволяет это сделать, но только если оно ещё не успело удалиться, ведь запись с истёкшим TTL удаляется не мгновенно.
В нашем случае записи, истёкшие по TTL, не нужны, поэтому выбрана политика NeverReturnExpired. Но есть и противоположная политика — ReturnExpiredIfNotCleanedUp.Метод cleanupFullSnapshot необходим при настройке механизма checkpoint. Этот метод Flink очистит все просроченные данные перед созданием каждого checkpoint.
Имея такую настройку, можно создать самый простой вид состояния ValueState с использованием контекста. Если логика приложения сложнее, можно использовать и другие состояния — например, ListState, MapState, AggregatingState, ReducingState и т. д.
Перейдём к методу flatMap. Его задача — перекинуть входящее событие на выход из оператора дедупликации методом out.collect(), когда событие с текущим ключом встретилось впервые за TTL. Для этого сначала обращаемся к состоянию keyHasBeenSeen.value(), спрашивая, есть ли в нём флаг о том, что это событие уже встречалось. Тут может возникнуть вопрос: а где определяется сам ключ и разве api не должно выглядеть вот так — keyHasBeenSeen.value(<event_key>)?
На самом деле так и происходит, но Flink держит ключ события у себя под капотом в контексте и не позволяет его получить напрямую. Если состояние для текущего ключа равно null, то сообщение встретили «впервые». Поэтому добавляем его в выходной поток и обновляем состояние методом keyHasBeenSeen.update(true), чтобы дальше дедуплицировать аналогичное событие. Благодаря этому метод keyHasBeenSeen.value() начнёт возвращать true.
Фильтрация событий
При обработке событий нам нужно сделать фильтр, который будет пропускать только ивенты с определёнными значениями поля Platform: WEB или APP. Это делается очень просто: в Flink API есть метод filter(), который можно вызвать в пайплайне обработки данных. В него можно передать как Java-лямбду, так и объект класса, реализующего FilterFunction:
public class ClickMessageWithPlatformFilter implements FilterFunction<ClickMessage> {
private static final long serialVersionUID = 1L;
@Override
public boolean filter(ClickMessage message) {
return Optional.ofNullable(message.getPlatform())
.map(platform -> WEB.equals(platform) || APP.equals(platform))
.orElse(false);
}
}Трансформация событий в новый формат

Последний этап обработки событий — трансформация событий из класса ClickMessage в класс ProductMessage, который отображает формат данных в выходном Sink-топике. Для этого можно воспользоваться преобразованием flatMap() как в дедупликаторе, но без Rich-контекста. Доступ к контексту нам не нужен:
@Slf4j
@RequiredArgsConstructor
public class ClickMessageToProductSinkMessageMapFunction implements FlatMapFunction<ClickMessage, ProductMessage> {
private static final long serialVersionUID = 1L;
@Override
public void flatMap(ClickMessage clickMessage, Collector<ProductMessage> out) {
try {
final var productMessage = ProductMessage.builder()
.userId(clickMessage.getUserId())
.productName(clickMessage.getProductName())
.object(clickMessage.getObject())
.platform(clickMessage.getPlatform())
.timestamp(clickMessage.getTimestamp())
.build();
out.collect(productMessage);
} catch (Exception e) {
log.error("Error converting ClickMessage to ProductMessage", e);
}
}
}Здесь мы имплементируем интерфейс FlatMapFunction, для которого нужно реализовать единственный метод flatMap. Он вызывается для каждого события, поступающего в потоке данных. Внутри мы производим трансформацию между двумя классами, обрабатывая исключения, которые может порождать билдер для ProductMessage, учитывающий правила валидации полей.
Разделение потока событий

Раз наш поток данных должен разветвляться на два — WEB и APP, нужен и соответствующий сплиттератор.
Flink для этого предоставляет механизм Side Outputs. С ним можно создать любое количество побочных выходных потоков (даже содержащих новый тип выходных данных) из таких операторов:
ProcessFunction
KeyedProcessFunction
CoProcessFunction
KeyedCoProcessFunction
ProcessWindowFunction
ProcessAllWindowFunction
Чтобы им воспользоваться, нужно определить теги OutputTag — по одному на каждый новый побочный выходной поток. В нашем случае их будет два: webTag и appTag. В стандартном случае код разделения потока будет выглядеть вот так:
final var webTag = new OutputTag<>("WEB", TypeInformation.of(ClickMessage.class));
final var appTag = new OutputTag<>("APP", TypeInformation.of(ClickMessage.class));
final var splittedByWebAndAppStream = stream.process(new ProcessFunction<ClickMessage, Object>() {
@Override
public void processElement(ClickMessage clickMessage, ProcessFunction<ClickMessage, Object>.Context ctx, Collector<Object> out) {
if (Platform.Enum.WEB.equals(clickMessage.getPlatform())) {
ctx.output(webTag, clickMessage);
}
if (Platform.Enum.APP.equals(clickMessage.getPlatform())) {
ctx.output(appTag, clickMessage);
}
// no op for out
}
});
final var webStream = splittedByWebAndAppStream.getSideOutput(webTag);
final var appStream = splittedByWebAndAppStream.getSideOutput(appTag);Сначала мы задаём вышеупомянутые теги. Затем создаём новую реализацию process(). Её цель — запись всех событий с определённым значением поля Platform в соответствующий тег через ctx.output(). Иными словами, в побочный поток. Заметьте, что мы не вызываем методы над объектом out, например out.collect(...), который добавляет событие в выходной поток. Поэтому в нашем основном потоке splittedByWebAndAppStream данных не будет. Мы закинули события только в побочные выходные потоки по тегам. Наконец, можем получить побочный выходной поток по соответствующему тегу с помощью метода getSideOutput(...) над результирующим потоком данных.
Этого уже достаточно, чтобы разделить поток. Но такой подход усложняет чтение последовательности кода пайплайна, поэтому нужна отдельная универсальная абстракция. На вход такой абстракции передаём тег и лямбду под условие, что событие попадёт в побочный поток этого тега. Это можно сделать примерно так:
@RequiredArgsConstructor
public class StreamSpliterator<I> extends ProcessFunction<I, Object> {
private static final long serialVersionUID = 1L;
private final Map<OutputTag<I>, SerializablePredicate<I>> predicatesByTags;
private final OutputTag<I> defaultTag;
@Override
public void processElement(I value, ProcessFunction<I, Object>.Context ctx, Collector<Object> out) {
for (Map.Entry<OutputTag<I>, SerializablePredicate<I>> entry : predicatesByTags.entrySet()) {
final var predicate = entry.getValue();
if (predicate.test(value)) {
final var tag = entry.getKey();
ctx.output(tag, value);
return;
}
}
ctx.output(defaultTag, value);
}
}При этом использование заметно упрощается:
final var splittedSource = stream.process(new StreamSpliterator<>(
Map.of(
tag_1, event -> false /*your predicate*/,
tag_2, event -> false /*your predicate*/
),
defaultTag
));Есть пара моментов, на которые стоит обратить внимание:
Событие при такой реализации добавится только в один побочный выход для первого сработавшего предиката. Поэтому в других сценариях можно подредактировать класс StreamSpliterator под ваши кейсы.
Этот класс де-/сериализуется так же, как и другие классы в Flink. Поэтому его поля должны быть сериализуемы, но стандартный Java-интерфейс Predicate не наследует интерфейс Serializable. Чтобы исправить ситуацию, можно создать свой интерфейс SerializablePredicate, который наследует и базовый Predicate, и Serializable:
@FunctionalInterface
public interface SerializablePredicate<T> extends Predicate<T>, Serializable {
}Этот вариант достаточно распространён в самих исходниках Flink, например в них можно найти SerializableFunction или SerializableSupplier.
Собираем Flink Job

Теперь у нас готовы отдельные абстракции, которые можно собрать вместе:
1) ClickMessageKafkaSourceBinder, чтобы прикрепить к StreamExecutionEnvironment источник данных из Kafka.
2) Фильтр ClickMessageWithPlatformFilter для фильтрации всех событий, отличающихся от WEB и APP.
3) StreamSpliterator для разделения потока на две части.
4) Оператор Deduplicator, чтобы дедуплицировать события из Kafka по ключу для потока APP.
5) ClickMessageToProductSinkMessageMapFunction, чтобы трансформировать события из формата ClickMessage в выходной формат ProductMessage.
6) ProductMessageKafkaSinkProvider, чтобы создать приёмник данных — в нашем случае другой топик Kafka.
Для начала определим бизнес-свойства новой джобы ClickToProductJob в application.yml и смапим их на property-класс ClickToProductJobProperties:
jobs:
click-to-product-job:
enabled: true
operators:
deduplicator:
ttl:
app: 7dСоответствующий класс для маппинга ClickToProductJobProperties:
@ConfigurationProperties("jobs.click-to-product-job")
@ConstructorBinding
@RequiredArgsConstructor
@Getter
public class ClickToProductJobProperties {
private final boolean enabled;
@NotNull
private final OperatorsProperties operators;
@ConfigurationProperties("operators")
@ConstructorBinding
@RequiredArgsConstructor
@Getter
public static class OperatorsProperties {
@NotNull
private final DeduplicatorProperties deduplicator;
@ConfigurationProperties("deduplicator")
@ConstructorBinding
@RequiredArgsConstructor
@Getter
public static class DeduplicatorProperties {
@NotNull
private final Map<DeduplicatorName, Duration> ttl;
public Time getTtl(DeduplicatorName name) {
return Optional.ofNullable(ttl.get(name))
.map(duration -> Time.milliseconds(duration.toMillis()))
.orElseThrow(() -> new IllegalArgumentException("Not found TTL by Deduplicator name: " + name));
}
public enum DeduplicatorName {
APP
}
}
}
}В предыдущей статье мы создали абстракцию JobStarter, которая получает все бины-реализации абстрактного класса FlinkJob и запускает их. Поэтому нам достаточно создать Spring-компонент новой джобы, который наследуется от FlinkJob, собрав весь пайплайн воедино:
@Component
@AllArgsConstructor
@ConditionalOnProperty("jobs.click-to-product-job.enabled")
public class ClickToProductJob extends FlinkJob {
private final ClickToProductJobProperties properties;
private final SourceBinder<ClickMessage> sourceBinder;
private final SinkProvider<ProductMessage> sinkProvider;
@Override
public void registerJob(StreamExecutionEnvironment env) {
final var webTag = new OutputTag<>("WEB", TypeInformation.of(ClickMessage.class));
final var appTag = new OutputTag<>("APP", TypeInformation.of(ClickMessage.class));
final var splittedByAppAndWebStream = sourceBinder.bindSource(env)
.filter(new ClickMessageWithPlatformFilter())
.uid("filter_click_message_by_platform_id").name("filter_click_message_by_platform")
.process(new StreamSpliterator<>(
Map.of(
webTag, clickMessage -> Platform.Enum.WEB.equals(clickMessage.getPlatform()),
appTag, clickMessage -> Platform.Enum.APP.equals(clickMessage.getPlatform())),
new OutputTag<>("UNKNOWN", TypeInformation.of(ClickMessage.class))
)).uid("split_click_message_by_platform_id").name("split_click_message_by_platform");
final var appStream = splittedByAppAndWebStream.getSideOutput(appTag);
final var webStream = splittedByAppAndWebStream.getSideOutput(webTag);
final var deduplicatedAppStream = appStream.keyBy(clickMessage -> clickMessage.getUserId().toString() + clickMessage.getTimestamp())
.flatMap(new Deduplicator<>(properties.getOperators().getDeduplicator().getTtl(DeduplicatorName.APP)))
.uid("deduplicate_app_messages_id").name("deduplicate_app_messages");
final var sink = sinkProvider.createSink();
webStream.union(deduplicatedAppStream)
.flatMap(new ClickMessageToProductSinkMessageMapFunction())
.uid("map_click_to_product_id").name("map_click_to_product")
.sinkTo(sink)
.uid("sink_product_message_id").name("sink_product_message");
}
}В приведённом выше коде мы создаём бин только при указании свойства «jobs.click-to-product-job.enabled», а внутри инжектим другие зависимые бины. В самом пайплайне привязываем источник событий Kafka, далее фильтруем и разделяем поток на две части: APP и WEB.
Поток APP поступает на дедупликатор, а WEB без обработки двигается дальше. Так как оба эти потока попадают в один SINK и требуют одного и того же трансформатора событий ClickMessage → ProductMessage, мы можем воспользоваться методом union для «склейки» этих потоков в один.
Важные замечания по коду джобы
Мы определили UID для каждого оператора пайплайна. Это достаточно важный момент, так как мы используем Stateful-оператор. При наличии состояния в дедупликаторе и перезапуске приложения нам нужно восстановиться из предыдущего состояния, сохранив все ключи дедупликатора, чтобы он продолжал работать корректно.
Flink восстанавливает состояние как раз в привязке к UID операторов. По умолчанию Flink сам определит id, но при добавлении новых операторов предыдущие id могут измениться, и тогда состояние не восстановится.
Прямое назначение id позволит нам свободнее модифицировать пайплайн обработки, когда добавляем/удаляем другие операторы. Это замечание — одно из нескольких в памятке Production Readiness Checklist. Для автоматической проверки, что везде выставлены UID, можно добавить в определение бина StreamExecutionEnvironment такую опцию:
@Configuration
public class FlinkConfig {
@Bean
public StreamExecutionEnvironment streamExecutionEnvironment() {
final var env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().disableAutoGeneratedUIDs();
return env;
}
}Вывод
Статья получилась достаточно насыщенной, но незавершённой, потому что мы пока не проверили, работает ли получившийся код. Мы рассмотрели, как создать базовые операторы, как составить пайплайн обработки событий при потоке данных Kafka-to-Kafka. Рассмотрели реализацию дедупликации событий и состояние оператора.
В следующей статье немного дополним бизнес-сценарий, динамически определив, в какой топик нужно писать каждое сообщение. Это будет происходить по названиям топиков в самих сообщениях.
Теперь нам нужно покрыть весь код тестами. Я покажу, как это сделать в следующих статьях. Определим концепцию тестов, вспомогательные абстракции и перейдём к стандартным UNIT-тестам операторов: stateless и stateful. Конечно же, покроем полный цикл пайплайна с помощью E2E-тестов с поднятием Kafka- и Flink-кластера в TestContainers. Спасибо, что прочитали! Если возникнут вопросы, задавайте их в комментариях.