Привет! Меня зовут Александр Попов, я tech lead команды маркетплейса 05.ru. Сейчас мы занимаемся бэком маркетплейса и некоторыми другими сервисами на рынке Дагестана.
При разработке серверной части маркетплейса мы сразу решили строить её в распределённой архитектуре. Эта статья о том, как хаос распределённых систем привёл нас к хореографии и почему мы в итоге маршируем в сторону оркестрации. Мы ещё на пути внедрения изменений, но я решил рассказать об этом сейчас, чтобы в следующий раз сделать вторую статью — с результатами. Заодно посмотрим, совпадут ли ожидания с реальностью. По ходу статьи будет много схем без котиков, но вы держитесь.
Определимся, что такое распределённая система
На упрощённой (для наглядности — до абсурда) схеме она выглядит так:
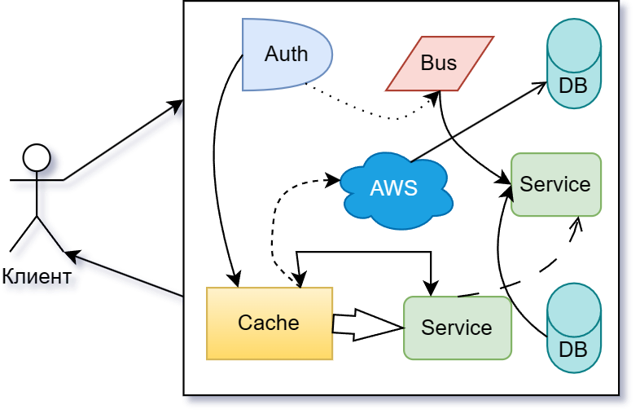
У нас есть клиент (это может быть браузер, мобильное приложение или ещё что-то), клиент отправляет запрос в систему. Внутри системы что-то откуда-то запрашивается, куда-то перенаправляется, происходит какой-то хаос и вакханалия. В итоге клиенту возвращается сформированный ответ. Откуда-то.
А теперь открою чёрный ящик и покажу на нашем примере, как там всё может быть устроено.
От дебюта к миттельшпилю
Все легенды про разработку обычно начинаются с фразы «так исторически сложилось…», и мы не исключение.
Так исторически сложилось, что на бэке маркетплейса 05.ru есть несколько сервисов и одна входная точка всей системы, которая рулит, куда какой запрос надо перенаправить. Плюс, есть отдельный сервис авторизации и кэш. У каждого сервиса своя база, общая шина. Долгое время всё это выглядело довольно логично, закономерно и управляемо.

Самое главное — над бэком маркетплейса работали два хорошо знакомых разработчика, которые мало того что понимали друг друга, так ещё и выработали общие методы.
В 2022 году проект начал стремительно развиваться. К нам подключился отдел аналитики, который выкатил новые требования, увеличилась команда разработки. Взрывной рост ожидаемо стал генерировать нестыковки.

Естественно, проблемы начались из-за постоянно растущего количества сервисов. Сервисы слушают шину, отправляют что-то в неё, работают с базами и кэшем, что-то спрашивают друг у друга. Всё это начинает походить на вермишель, следить за продуктом становится всё сложнее.
К тому же добавились проблемы при общении с аналитиками и тестировщиками. Ребята плохо понимают логику происходящего на бэке, а неизбежное появление новых сервисов только усугубляет проблему.
Ещё одна сложность — тонны документации. Её не очень хотят писать разработчики, её не очень хотят читать другие команды. Если две страницы ещё можно осилить, то у 20 страниц шансов почти нет, побеждает лень. Ситуация lose-lose — все в проигрыше.
Онбординг новых сотрудников тоже получается не лучшим образом. Им сразу нужно попытаться объяснить логику устройства хаоса, а они должны начать более-менее ориентироваться в нём.
Дальше уже организационные проблемы. Например, отсутствие чётких критериев разработки нового функционала. Когда разработчикам приходит задача на разработку какого-то сценария, очень сложно определить, где именно этот сценарий должен быть реализован. И самое главное — как его потом проверить. Как следствие, получаем большую нагрузку на отдел тестирования. Тестировщикам не меньше разработчиков надо понимать, что и где проверять, они тоже должны быть погружены в контекст происходящего.
Как результат, у нас получается очень большой промежуток времени между новой идеей и деплоем фичи, реализующей эту идею. В титрах видим довольно сильно демотивированных сотрудников, которым необходимо постоянно держать всю эту систему в голове, документировать, отвечать на миллион вопросов — где, что и как работает. Смотрели фильм «Мгла», снятый по роману Стивена Кинга? Посмотрите.
В поисках волшебной таблетки
Есть два принципиально разных подхода для управления распределёнными системами — хореография и оркестрация. У каждого есть плюсы и минусы.
Хореография

Это подход, при котором участники обмениваются событиями без централизованного управления. Есть какие-то входные данные или запрос. Он приходит в Service 1, происходит какое-то действие. После чего в шину отправляется событие о завершении этого действия. Другие сервисы асинхронно подхватывают это событие, выполняют что-то у себя и шлют событие в шину о завершении своей работы. Потом, например, Service 1 подхватывает события о завершении работы предыдущих сервисов и выдаёт какой-то результирующий ответ.
Плюсы
Главный — минимальная связность сервисов. То есть каждый сервис в целом вообще не в курсе того, слушает ли его кто-то, кто и что делает с его событиями и так далее. Единственная их точка связи — это контракты, по которым работают события. В эту цепочку легко встроить новые сервисы или исключить существующие.
Также большим плюсом является неплохая скорость работы, особенно при наличии параллельных выполнений.
Минусы
Главный — сложное управление. Нет единой точки, из которой можно управлять процессом от начала и до конца, сценарий «размазан» по всем сервисам. Как следствие, имеем довольно сложную отладку кода.
Поиск источника ошибки, например на последнем этапе, может занимать неопределённое время, потому что придётся отслеживать каждое событие, каждый сервис: что он отдал, что он прослушал.
Оркестрация

При этом подходе есть единый оркестратор, который управляет всем сценарием по шагам. Он принимает запросы, рулит тем, куда что отправить, откуда что запросить. И он же собирает все данные и выдаёт ответ.
Большой и жирный плюс довольно очевиден — это наглядное централизованное управление всем сценарием: он описан в одном месте.
Минусы являются следствием главного плюса
Так как у нас появляется единая точка входа и выхода, то эта же точка одновременно является и возможной точкой отказа всей системы. Отказывает оркестратор — вся система падает.
Хореография в случае отказа одного из сервисов или каких-то ошибок ведёт себя намного лучше, потому что система в целом продолжает работать.
Вторым недостатком является чуть большая связность сервисов друг с другом, потому что здесь от ответа сервиса зависит непосредственно работа оркестратора.
У нас всё не так. Хотя погодите…
Вы уже видели, как реализована наша система:

Текущая схема нашей системы больше напоминает хореографию, немножко хаотичную и с некоторыми доработками, но тем не менее. Есть шина, есть прослушивание событий, есть отправка событий в шину.
В целом сервисы работают независимо друг от друга. Но, как я упомянул в начале, количество сервисов начало расти, а общаться с отделами аналитики и тестирования становилось всё сложнее. Так мы поняли, что хореография нам не подходит, и стали смотреть в сторону оркестрации.
И первый же вопрос: что же выбрать в качестве оркестратора. Делать что-то самописное в нашем случае — плохая идея. У нас нет опыта и квалификации в подобных разработках — это более низкоуровневое ПО, чем сервисы, которые мы пишем. Вероятность вместо оркестратора написать неработоспособную дичь стремится к бесконечности.
Мы остановили свой выбор на Temporal, и сейчас расскажу почему.
Сразу приложу ссылки на материалы, где несложным языком объяснены основные концепции и подходы к работе с распределёнными системами на базе Temporal:
Fault tolerant workflow orchestration on PHP
Оркестрируй это! Описываем сложные бизнес-процессы на PHP
Оркестрация и закон Мёрфи: обрабатываем ошибки-бизнес процессов

Под спойлером расписал немного про Temporal
Концепция Temporal — это пошаговое выполнение сценариев и сохранение состояний. Код выполняется с сохранением каждого своего состояния, то есть по шагам: выполнился шаг — состояние сохранено, выполнился следующий шаг — состояние снова сохранено. Такое поведение позволяет в случае отказа, ошибки или даже какого-то технического сбоя продолжить выполнение сценария, стартуя именно с той точки, где он остановился. То есть каждый шаг — это условно атомарная операция, после её выполнения считается, что состояние изменено, и больше эта операция выполняться не будет.
В Temporal есть два основных понятия. Workflow — это сценарий, который пишется на языке программирования, и activity — атомарная операция, которая либо выполняется полностью, либо не выполняется. Activity может представлять из себя либо запрос в базу, либо какое-то вычисление, либо, как в нашем случае, обращение к сервису. Также есть понятие «сигнал» — это внешней запрос, который точно так же может менять состояние сценария (workflow). Например, workflow может ожидать какого-то конкретного сигнала для продолжения работы либо конкретный сигнал может прервать выполнение workflow.
Основное преимущество Temporal — феноменальная отказоустойчивость за счёт подхода event sourcing, то есть сохранения состояния. Добавим к этому практически неограниченную горизонтальную масштабируемость: сам workflow не хранит никаких данных, он хранит только сценарий и его состояния. Можно поднять неограниченное количество процессов workflow, нагрузка между которыми будет распределяться каким-то внешним балансировщиком.
Эти два преимущества компенсируют главный недостаток оркестрации, её самое узкое место — точку отказа.
Не побоюсь такого заявления, что Temporal является самым надёжным местом всей системы. Потому что даже в случае каких-то внешних сбоев сценарий выполнения никуда не исчезнет, не выдаст какую-то критическую ошибку. Temporal относительно легко переживёт даже «казус уборщицы», то есть выдернутую вилку из розетки. При исправлении проблемы сценарий начнёт выполняться с того места, на котором остановился.
Также большим преимуществом являются готовые SDK под разные языки программирования: PHP, Go, Java, TypeScript, Python — выбирай на свой вкус. Temporal является заметно развивающимся продуктом и имеет довольно активное комьюнити, в том числе и русскоязычное. Есть где искать ответы, задавать вопросы, обсуждать.
Глупые сервисы — умный оркестратор
Мы хотим применить все плюсы оркестратора для решения проблем в бэкенде маркетплейса.

Теперь в новой архитектуре есть сервисы и Temporal в качестве оркестратора с workflow и activity. Для получения данных к сервису можно обратиться напрямую, минуя оркестратор. Получить данные можно легко, быстро, без использования агрегаторов. Изменение, добавление или удаление данных происходят только через оркестратор.
По сути, схема та же (единая точка входа gateway, авторизация), но между единой точкой входа (gateway) и сервисом всегда всегда стоит фасад, который рулит порядком выполнения запросов, отвечает за связность данных между сервисами. Выполнение сценария может быть растянуто во времени на неопределённый срок (это не только минуты или часы, а даже месяцы и годы). Workflow может висеть запущенным неограниченное количество времени.
Также во всей схеме участвует шина, но она уже имеет больше вспомогательную роль для каких-то некритичных и асинхронных событий.
И самое главное — сервисы не общаются друг с другом и не слушают шину. Вся бизнес-логика вынесена исключительно в фасад. Сервисы хранят сущности, отвечают за их добавление, удаление и изменение, а также максимально быстро отдают запрошенные данные. Сервисы валидируют все входящие данные и отвечают за связанность данных внутри себя. За пределами своих сущностей сервисы ни за что ответственности не несут.
На начальных этапах правами доступа к данным будет управлять отдельный сервис, но в планах этот пункт вынести во внешнюю систему. Ну и также сервисы сообщают обо всех изменениях своих сущностей в шину, в хранилище событий, в логи.
Как оркестратор подружит нас с аналитиками
Сервисы практически полностью повторяют модели, которые выдаёт отдел аналитики с предоставляемыми рестрикшенами, связями, правами доступа. Они - просто обёртка для данных.
Как несложно заметить, в этом случае практически весь код сервисов будет идентичным. А раз так, то логично основной код сервиса вынести куда-то во внешнюю общую подключаемую библиотеку, так называемый скелет сервиса, или Service Template, а каждый конкретный сервис по сути своей будет представлять из себя описание сущностей, которые приходят от отдела аналитики.
Сразу же заметен большой бонус. У нас сервисы практически полностью соответствуют данным, пришедшим от аналитики. Их легко проверить, их легко валидировать, их очень быстро и легко разрабатывать. То есть, один раз написанный скелет позволяет разрабатывать новые сервисы буквально за пару дней, а при наличии хорошей кодогенерации — даже за пару часов.
Было — стало
Я покажу изменения на конкретном примере, но он из будущего. Внедрять будем в первом квартале 2024 года, о результатах расскажу в новой статье.
Как кейс выглядит сейчас
Это вывод среднего рейтинга товара и магазина на основе пользовательских оценок.
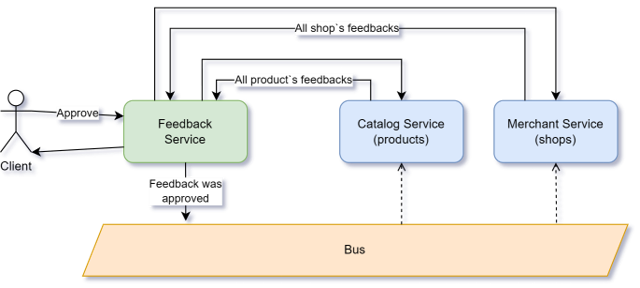
Оценки выставляются покупателями магазина вместе с отзывами. Отзыв можно оставить как на товар, так и на магазин.
У нас есть модератор, который апрувит конкретный отзыв. Дальше сервис отзывов обновляет у себя данные, отдаёт ответ модератору. При этом сервис отзывов шлёт событие в шину о том, что конкретный отзыв опубликован.
Это событие слушает сервис каталога, в котором хранятся товары, и сервис мерчантов, в котором хранятся магазины. В свою очередь, каждый из этих сервисов при получении события запрашивает все отзывы на свою сущность из сервиса отзывов, чтобы подсчитать средний рейтинг товара или магазина, обновляет данные у себя. Сценарий работает, он понятен, но имеет ряд недостатков.
Во-первых, весь кейс размазан по трём сервисам. Апрув отзывов происходит в одном сервисе, подсчёт рейтинга товаров — во втором, подсчёт рейтинга магазинов — в третьем.
Во-вторых, у нас нет централизованной обработки ошибок. Например, если ошибка произошла при запросе всех отзывов товара, то об этом мы можем узнать только из логов самого сервиса каталога. Либо из логов системы, куда сыплются все ошибки. Это, естественно, не очень удобно. Ну и самое главное — в таком случае обновление среднего рейтинга товара не произойдёт. В ситуации именно с рейтингом товаров это не критично, но кейсы бывают разные, а подход сейчас примерно одинаков.
В-третьих, событие шины в принципе можно потерять, если, например, в тот момент, когда событие было отправлено, сервис каталога был недоступен. По любой причине: происходил деплой или нода сервера упала. Такое событие мы просто-напросто потеряем. Опять же, в случае с рейтингами это не критично, но проблема всё-таки есть.
Как же подобный сценарий должен выглядеть в новой архитектуре?
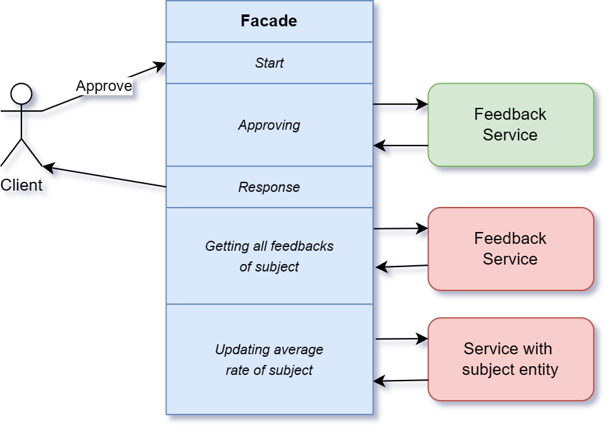
Весь сценарий описан в одном фасаде. По сути, делает он примерно то же самое, но в другом порядке.
Точно так же сначала от модератора приходит запрос на публикацию конкретного отзыва. Сценарий запускается, происходит процесс публикации — запрос в сервис отзывов.
Сервис отзывов отвечает, что публикация произошла успешно.
После этого фасад может отдать ответ модератору о том, что всё хорошо.
И уже после выдачи ответа продолжает обновление средних рейтингов в сервисе каталога или в сервисе мерчанта, то есть запрашивает все отзывы о конкретной сущности, подсчитывает среднее значение и обновляет соответствующую сущность.
В чём преимущество
Самое очевидное — весь сценарий описан в одном месте. Его легко дополнить, легко исправить, легко проверить.
Второе значимое отличие в том, что мы можем в этом сценарии обрабатывать ошибки практически любым способом.
При ошибке, например, на последнем шаге (при обновлении самого значения среднего рейтинга) может быть несколько разных вариантов: либо можно откатить весь апрув отзыва, либо настроить политику ретраев таким образом, что значение будет пытаться обновиться до определённого времени, также всегда можно отправить уведомление при наступлении ошибки.
И самое главное — это то, что ошибка будет легко дебажиться, так как Temporal, помимо своей феноменальной отказоустойчивости, пишет просто нереальное количество максимально подробных и структурированных логов. То есть ошибку очень легко отследить и исправить. При правильно настроенной политике ретраев после исправления ошибки (например, в сервисе каталога) больше вообще ничего не придётся делать: сценарий сам отправит необходимый запрос, увидев, что сервис изменён, и успешно завершится.
Ещё раз хочу донести мысль, что правильно написанный и настроенный сценарий выполнится при любом раскладе. И при наступлении ошибки, и при каком-то техническом сбое, как на стороне самого фасада, так и на стороне какого-то из сервисов. Workflow может висеть в ожидании исправления сбоя или ошибки практически неограниченное время, и он гарантирует, что каждый шаг будет выполнен и успешно завершён.
Должен быть подвох, но где?
Что мы получим в итоге, когда полностью реализуем всю эту архитектуру на бэкенде маркетплейса?
Самое главное — быструю и качественную разработку новых сервисов непосредственно по артефактам от аналитики
То есть сервисы будут разрабатываться строго по моделям или объектам, которые предоставляет аналитика. Пользовательские сценарии точно так же напрямую будут реализованы по use-кейсам от аналитики.
Низкий порог входа новых сотрудников для работы с созданием и изменением существующих сервисов
Всё, что нужно изучить новому сотруднику, — тот самый Service Template. Понять, как он работает, как правильно описывать сущности, правила валидации и так далее.
Никаких новых технологий, каких-то взаимосвязей между разными сервисами новому сотруднику познавать не нужно. Ему приходит артефакт от аналитики, он берёт и описывает его терминами Service Template.
Мы сможем абсолютно независимо разрабатывать как сервисы, так и пользовательские сценарии
Причём делать это можно даже разными командами разработчиков и на разных языках. Для Temporal есть SDK на много разных языков, поэтому сценарии никто не заставляет писать строго на одном языке.
Каждый сервис может быть написан своей командой, отдельным разработчиком, на аутсорсе. Причём на удобном им языке. Самое главное, чтобы результат отвечал определённым контрактам.
Фасадов может быть несколько, их даже должно быть несколько, потому что объединять все пользовательские сценарии в одном месте тоже не очень хорошая идея. Часть сценариев может запускаться очень редко и не занимать много времени и ресурсов. Другая — наоборот, быть очень нагруженной и ресурсоёмкой. Третья часть может использовать какие-то экзотические зависимости. И в целом, когда сценариев станет очень много, будет сложно найти нужный, если все они располагаются в одном месте.
Мы получим легко валидируемую систему
То есть ни отделу аналитики, ни отделу тестирования не придётся по крупицам собирать информацию из документации каждого сервиса, как-то её сопоставлять, постоянно уточнять, спрашивать, выяснять, дополнять свои знания.
Есть один пользовательский сценарий, реализованный в диаграмме в use-кейсе, строго по этому сценарию можно проверить работу системы. И именно по этому же сценарию можно указать на ошибки, на недочёты, если конкретный сценарий работает неправильно. Открывается соответствующий workflow, правится, дорабатывается.
Мы избавляемся от рутинной работы по написанию документации
При этом уверены, что каждый сервис соответствует тому, что предоставила нам аналитика, и каждый сценарий точно так же соответствует тому, что нарисовано в диаграммах use-кейсов.
За удобство придётся заплатить
Если кто-то помнит, главный плюс хореографии — неплохая скорость работы. Чего не скажешь про оркестрацию в целом и Temporal в частности.
За свою феноменальную отказоустойчивость и подробнейший набор логов Temporal платит скоростью и пожираемыми ресурсами железа. Именно поэтому в схеме новой архитектуры на первом месте стоял прямой запрос к сервисам без использования Temporal.
Несмотря на то что Temporal очень отказоустойчив, работает он медленнее, чем сценарий, описанный на ванильном языке программирования или работающий через шину за счёт накладных расходов и по логированию, и по сохранению состояния.
Можете поспорить, но мне кажется, что накладные расходы в виде большого количества занимаемого места и некоторой просадки скорости при изменении данных — это всё-таки лучше, чем расходы на демотивированных сотрудников, постоянные созвоны и уточнения, на рассинхроны между разными отделами и ошибки несогласованности данных в разных сервисах.
Будет классно, если в комментариях похвалите или покритикуете мои планы по переходу на новую архитектуру. Сейчас мы как раз начинаем работу по внедрению оркестрации, и ваш опыт поможет избежать ошибок в будущем.
Комментарии (4)

Dobersolo
21.03.2024 10:55я верно понимаю, что сервис будет представлять из себя уже, по большей части, просто БД и в нем не будет почти никакой (читай никакой) логики?

EmperorSith Автор
21.03.2024 10:55Да, в идеале именно так. В сервисе только хранение/редактирование сущностей, валидация входных параметров запроса и ограничение прав доступа на сущности.
ilyas974
Хорошая статья, спасибо!
EmperorSith Автор
Спасибо за оценку!