Введение
Способность обрабатывать большой объем запросов и данных в реальном времени является ключевым аспектом надежности и производительности современных информационных систем. Одним из способов повышения надежности, снижения нагрузки и, как следствие, расходов на сервера, является применение системы эффективного кэширования на уровне приложения. В этой статье я расскажу о возможных подводных камнях и эффективных стратегиях построения такой системы.
Что такое кэширование
Кэширование — это процесс временного хранения копий данных в промежуточном хранилище, – кэше, – для ускорения доступа к данным и уменьшения нагрузок на сервера. Кэш реализуют на разных уровнях, включая программное обеспечение (например, веб-кэш), аппаратное обеспечение (например, кэш процессора) или даже в виде отдельного слоя распределенной системы.
Как используется кэширование
Рассмотрим пример: новостной сайт, который хранит список последних новостей. Без системы кэширования, сервер должен обращаться к базе данных для получения списка новостей при каждом запросе пользователя к главной странице сайта. Это занимает время и ресурсы. Кэширование как раз помогает их сэкономить: актуальный список новостей сохраняется в быстродоступном кэше после первого запроса. При последующих запросах сервер извлекает список из кэша, значительно ускоряя отображение страницы для пользователей и снижая нагрузку на базу данных.
Что может пойти не так
Кэширование не панацея, и при неаккуратном проектировании, оно может приводить к ряду проблем. Рассмотрим ключевые проблемы и их причины:
Неэффективное наполнение кэша
Предположим, перед тем как предоставить пользователю новости, мы хотим обогатить их дополнительной информацией, например, о погоде. Для получения этой информации мы используем отдельную систему, которая предоставляет HTTP-эндпоинты для получения данных о погоде. Чтобы избежать излишней нагрузки на эту систему, мы решаем сохранять данные о погоде в кэше. Однако, высокая задержка (latency) на бекенде погоды будет приводить к высокой задержке на нашем приложении. Для предотвращения такой ситуации мы устанавливаем низкое время ожидания (timeout) на HTTP-запросы к системе, предоставляющей данные о погоде. Таким образом, если система погоды не успевает ответить в установленный интервал времени, мы просто не включаем информацию о погоде в новости для пользователя. Однако, при этом данные о погоде не сохраняются в кэше, что означает, что при каждом запросе мы вынуждены обращаться к бекенду, пытаясь получить эти данные. Это может привести к дополнительной нагрузке на бекенд и ухудшению его производительности.
Недоступность данных во время сбоев
Во время недоступности некоторого бэкенда или базы данных, пользователь не заметит эту недоступность, если мы будем отдавать ему данные из кэша. Однако, если время жизни (TTL) записей в кэше истекло, а бэкенд к этому времени еще не восстановился, данные для пользователя окажутся недоступными. Но в большинстве случаев предпочтительнее стратегия, при которой пользователь видит устаревшие данные, чем не видит данных вовсе. В таких случаях полезно иметь возможность переиспользовать устаревшие данные в кеше в течение некоторого расширенного интервала времени, чтобы бэкендам было больше времени на восстановление.
Дублирование HTTP-запросов
Система может сталкиваться с множеством идентичных запросов к серверу или базе данных, когда несколько пользователей запрашивают одни и те же данные одновременно. Это приводит к повторной обработке одних и тех же данных, что увеличивает нагрузку на инфраструктуру и может замедлить обработку запросов для всех пользователей. В некоторых сценариях доля идентичных запросов может достигать десятков процентов. Для таких кейсов важно, чтобы система кэширования перенаправляла все повторные запросы на ожидание результата первого запроса.
Как предотвратить типичные проблемы
Я перечислю современные решения для создания продвинутые стратегии кэширования, которые помогут избежать перечисленные выше проблемы.
Singleflight в качестве отдельного уровня кэширования
Singleflight - это паттерн, при котором идентичные запросы к бекенду дедублицируются на лету по определенному ключу. В системе кэширования можно реализовать singleflight как первый слой в многоуровневом кэше, который использует ключ кэширования для дедубликации запросов. Создание такого слоя оптимизирует обработку идентичных запросов, обеспечивая выполнение только одного запроса за раз, в то время как остальные потребители просто ожидают результата первого запроса. Применение singleflight эффективно в сценариях, где вероятно одновременное поступление идентичных запросов. Это особенно полезно для веб-сервисов с высокой нагрузкой, где данные всех пользователей должны быть обогащены одинаковой информацией, но долгосрочное кэширование этой информации недопустимо по бизнес-правилам.
До
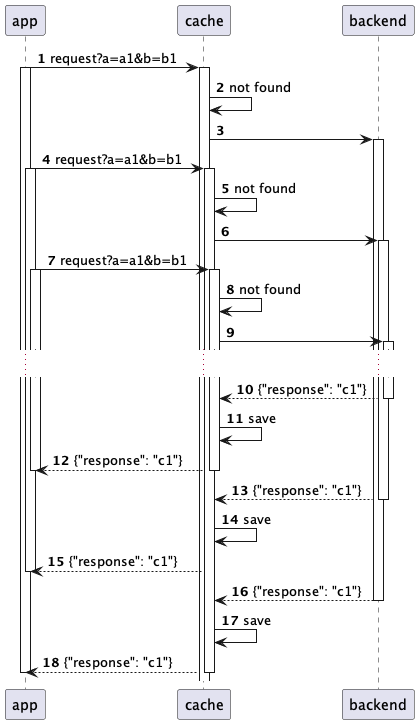
После

Fallback к устаревшим данным в кэше
Для многих систем непрерывный доступ к данным важнее их актуальности. Например, в ленте социальных сетей лучше показывать аватарки и никнеймы пользователей с некоторой задержкой, чем вообще не показывать их. Для обеспечения возможности доступа к информации во время сбоя сервиса можно использовать паттерн "Fallback cache".
"Fallback cache" - это паттерн, который позволяет системе использовать менее актуальные резервные данные из кеша, когда свежие данные недоступны из-за ошибок или сбоев в источнике данных.
Функциональность "fallback" кеша может быть добавлена к обычному кешу в приложении, если вместо одного времени жизни (ttl) использовать два значения: время, в течение которого данные считаются актуальными и запрос к реальному источнику данных не требуется (cacheTtl), и время, в течение которого данные будут считаться устаревшими, но все еще могут быть использованы в качестве резервных при возникновении ошибок в источнике данных (fallbackTtl). Тогда физическое время жизни в хранилище данных будет равняться max(cacheTtl, fallbackTtl)
До

После

Дополнительный таймаут
Если нижестоящая система или база данных испытывает сбой и отвечает с задержкой, ее запросы будут отклоняться из-за таймаута и не будут попадать в кеш. Это приведет к постепенному протуханию все большего количества записей и увеличит нагрузку, что, вероятно, еще более ухудшит ситуацию. Увеличение таймаута до этого сервиса может помочь, но оно повлияет на остальных пользователей, увеличивая время ожидания ответа.
Чтобы решить эту проблему, можно ввести дополнительный таймаут - сколько дополнительно можно ожидать данных в фоне, не обрывая при этом физический запрос. В таком сценарии влияние сбоя на пользователей будет снижено, поскольку пользователь не почувствует увеличения времени отклика, но при этом система кеширования будет прилагать максимальное количество усилий для дожидания обновленных данных.
До

После

Общая схема реализации
Давайте рассмотрим, как эти предложенные решения могут функционировать на практике:
При получении запроса система сначала проверяет, не запущен ли уже запрос с таким же ключом. Если запрос уже выполняется, система просто ожидает ответа от существующего запроса.
Затем система проверяет наличие актуальной информации в кеше, которая может удовлетворить данный запрос. Если такая информация имеется, она немедленно возвращается пользователю без дальнейшей обработки.
Если в кеше нет актуальных данных, делаем запрос в реальный бекенд или базу данных.
В случае сбоя или задержек в работе бэкенда система может использовать устаревшие данные из кеша в качестве временного решения при помощи механизма Fallback. Это обеспечивает непрерывность работы сервиса и помогает снизить нагрузку на бэкенд. Важно отметить, что сам запрос при этом не прерывается, и система продолжает ожидать ответа в фоновом режиме, чтобы сохранить данные в кеше. А все новые запросы и, в том числе ретраи, не будут создавать новых сетевых запросов а будут подключаться к существующим и ожидать их результата.
Заключение
Эффективная система кэширования позволяет повысить устойчивость и доступность сервиса в условиях высоких нагрузок или сбоев, что крайне важно в современных условиях. В своем обзоре я представил действенные механизмы, включая singleflight и fallback, которые помогут избежать перегрузки системы и обеспечить высокую производительность и надежность высоконагруженных систем.
Комментарии (2)

zubrbonasus
31.03.2024 11:27Если говорить про веб - есть кеширующий http прокси который будет хранить страницы целиком и отдать готовые страницы если на сервере нет изменений. И не зачем отдельный огород городить.
Также стоит заметить что запрос к базе данных не должно быть какой-то сложностью для веб приложения и незачем отдельно кэшировать ответы СУБД. Например есть предусмотренный субд кэш где, как правило, хранятся результаты выполнения запросов.
Ну и много где ещё есть свой кеш который можно просто использовать.
dyadyaSerezha
Но все-таки прежде чем проектировать что-то свое, не лучше ли определиться с требованиями и поискать готовое решение?