Приветствую, после того, как я научился запускать spark-submit с мастером в Kubernetes и даже получил ожидаемый результат, пришло время ставить мою задачу на расписание в Airflow. И тут встал вопрос, как это правильно делать. Во всемирной паутине предлагается несколько вариантов и мне было непонятно, какой из них стоит выбрать. Поэтому я попробовал некоторые из них и сейчас поделюсь полученным опытом. Приятного чтения!
В статье я расскажу про 3 способа с использованием следующих инструментов:
Пакет airflow-providers-apache-spark для Airflow
Сервис Apache Livy
Kubernetes оператор spark-on-k8s-operator
Весь код, который использован для этих способов запуска, можно найти тут. Также видео для тех, кто лучше воспринимает информацию в данном виде. И в нем я более подробно останавливаюсь на примерах запуска кода:
И прежде чем мы поговорим о каждом способе и осветим достоинства и недостатки каждого, хочу упомянуть пару слов о том, что вообще представляет из себя запуск Spark в Kubernetes.
Запуск Spark в Kubernetes
Для запуска Spark в Kubernetes нам понадобятся:
Kubernetes кластер
Docker registry
Машина с установленными openjdk и Spark (просто распакованный архив)
Также нам необходимо создать пространство имен и сервисный аккаунт, которому надо дать необходимые права. Теперь нужно собрать образ с вашим приложением и запушить его в Docker registry. Или же использовать публичный образ и запускать пример, как я и буду делать.
После этого запускаем команду spark-submit, в которой необходимо указать хост и порт k8s, а также docker образ:
spark-submit \
--master k8s://https://K8S_HOST>:<K8S_PORT> \
--deploy-mode cluster \
--name spark-pi \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.container.image=SPARK_IMAGE \
local:///opt/spark/examples/src/main/python/pi.pyСхематично процесс можно представить так:
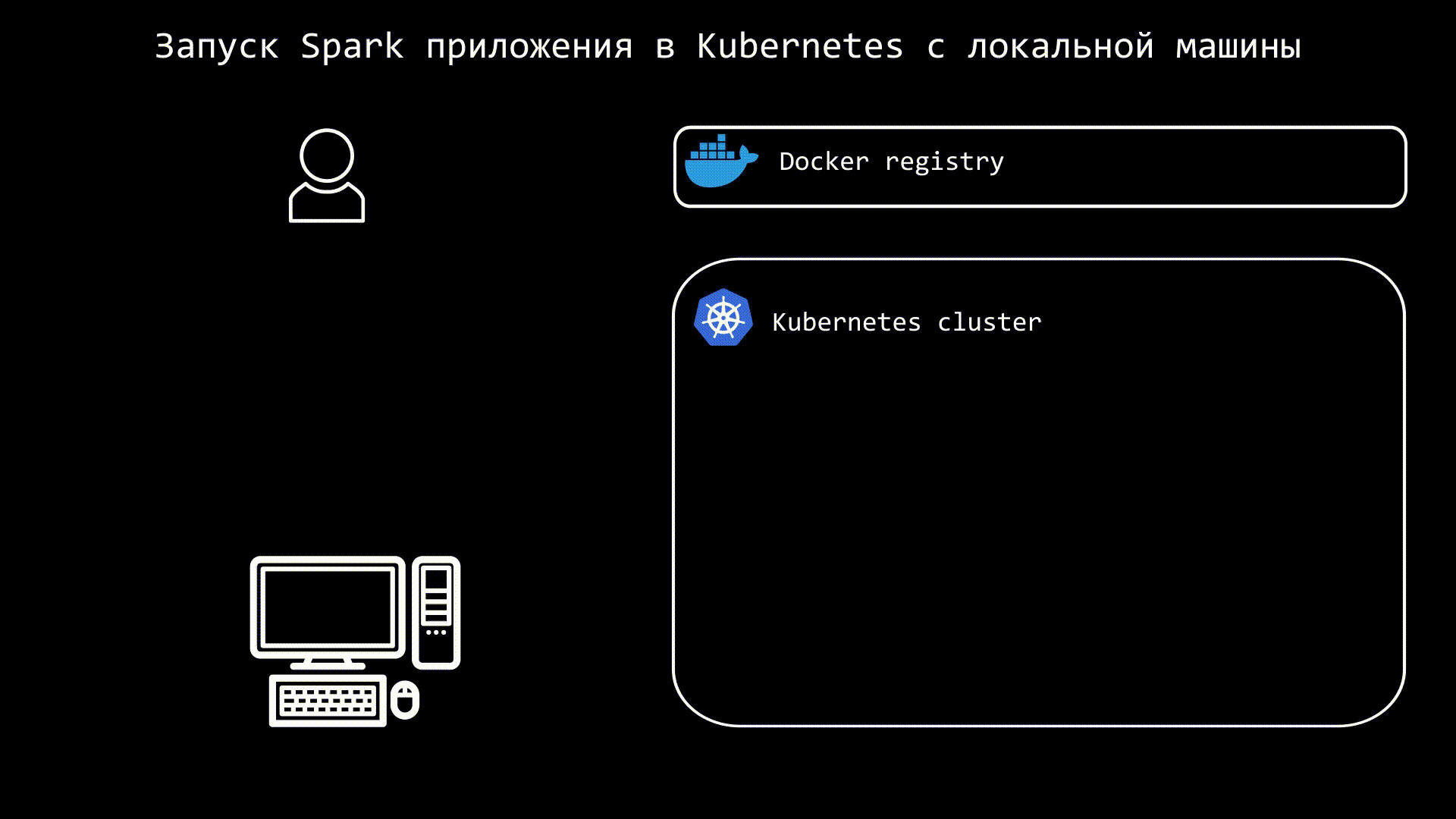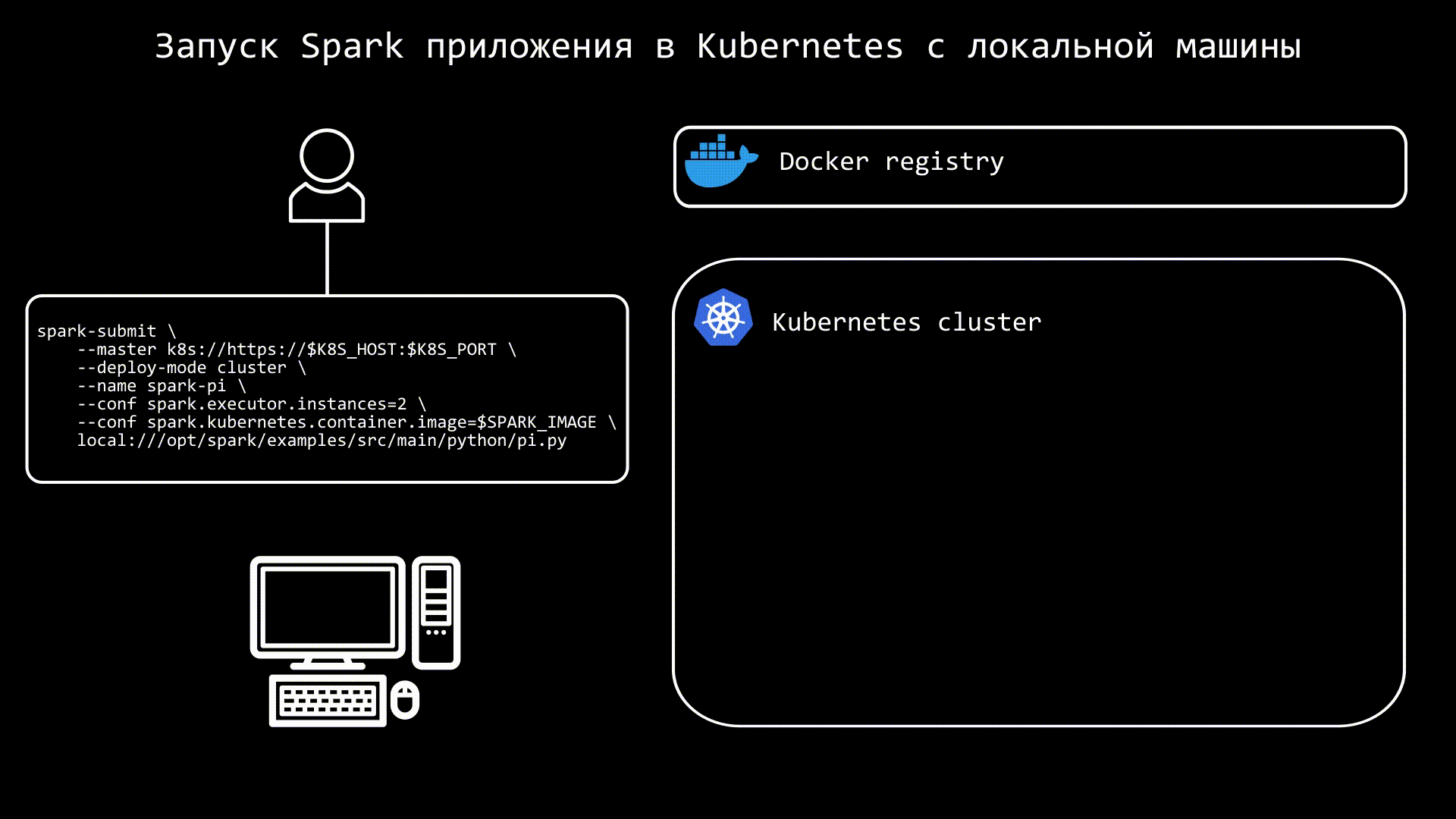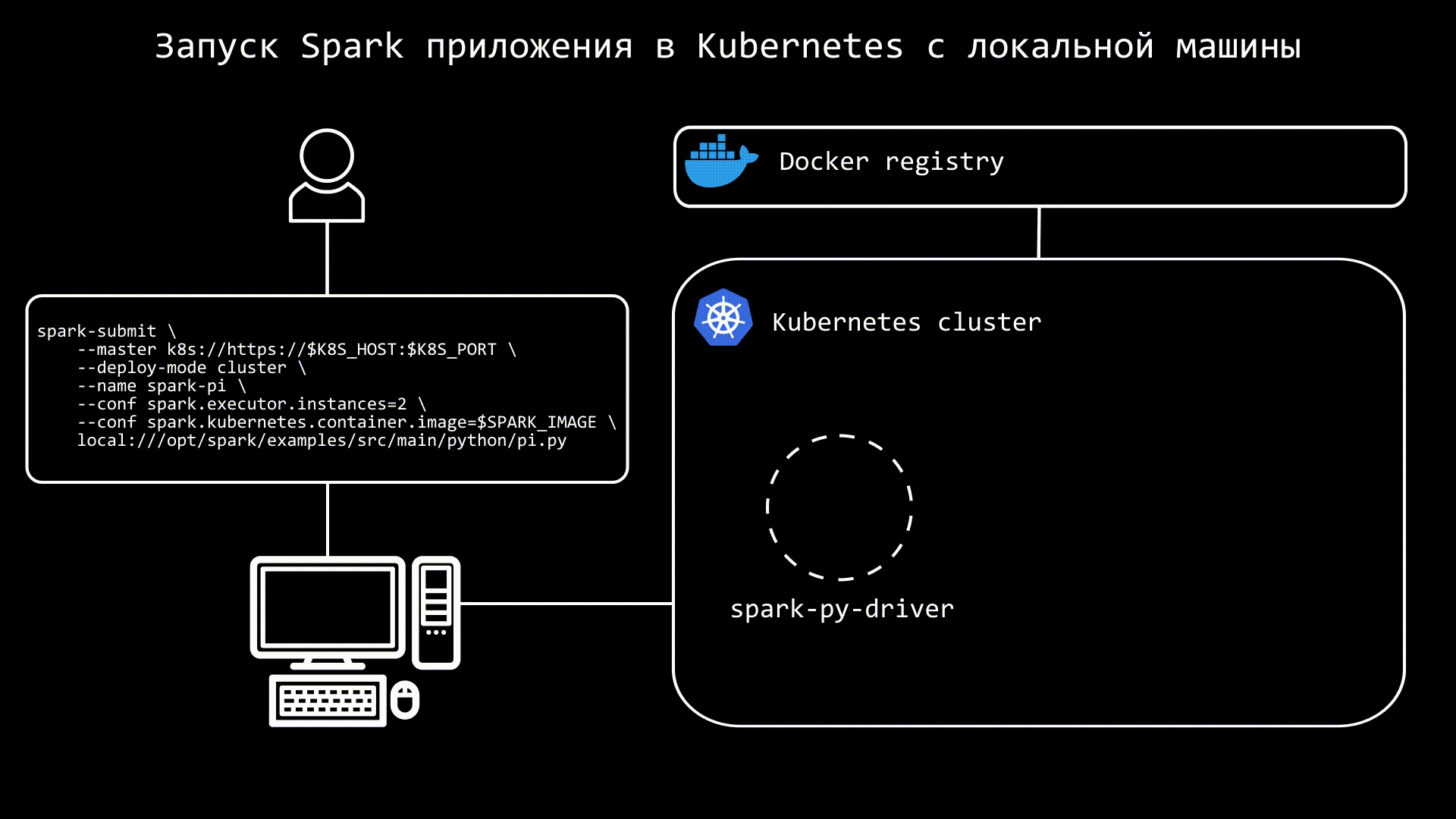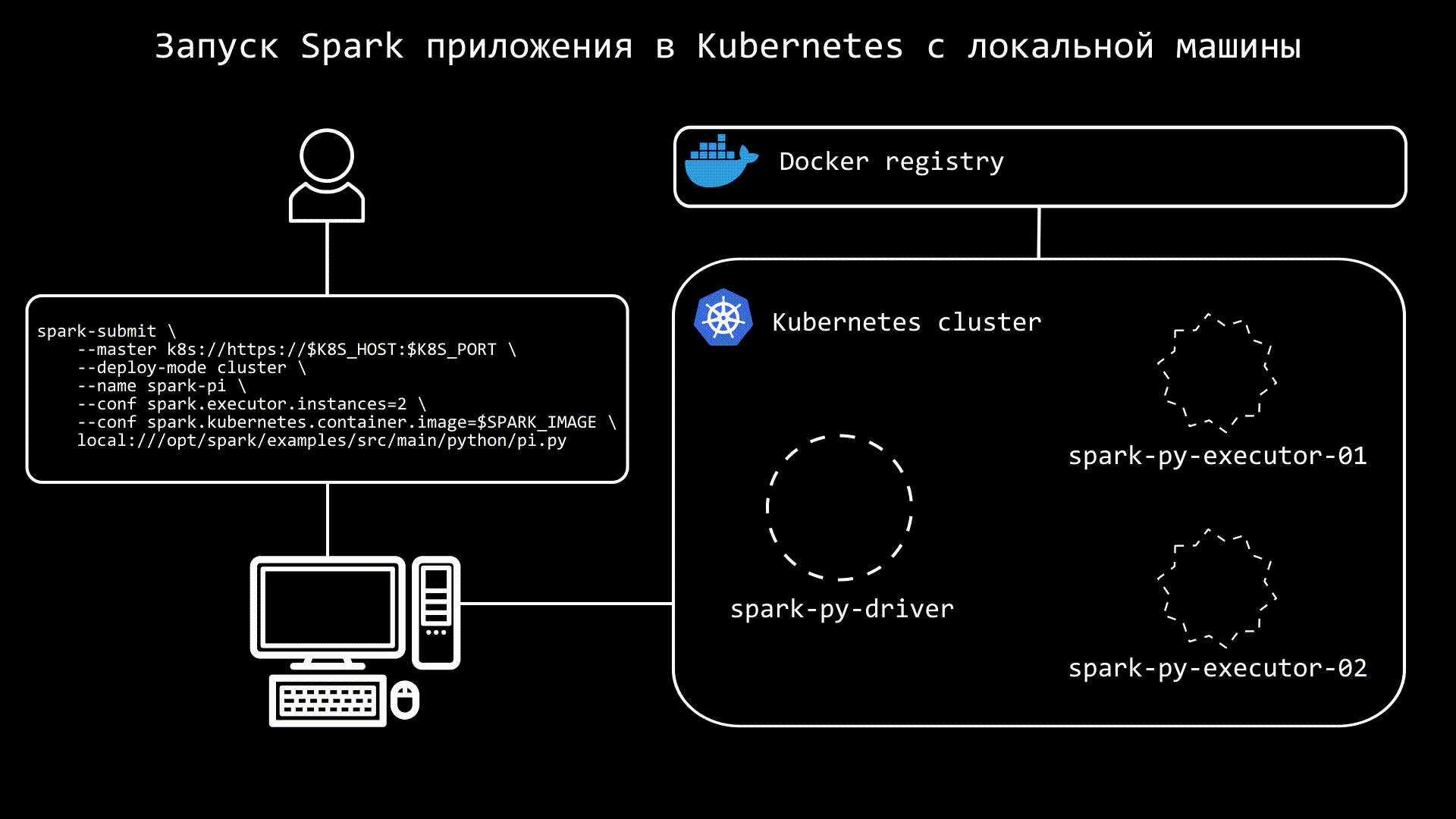
После выполнения команды, мы увидим в кластере под с driver, а также, через некоторое время, поды с executors. Стоит обратить внимание, что в кластере создаются не только поды, а также services и configmaps.
Также мы можем модифицировать submit и добавить, например, volumes. Либо, можем задать шаблоны манифестов для подов driver или executors. Все это подробно описано в документации.
Теперь, когда мы вспомнили, как запускать Spark локально, перейдем к тому, зачем мы собрались. Запустим наше приложение из Airflow.
Путь 1. Apache-airflow-providers-apache-spark
Первое, что приходит в голову, когда нужно запустить из Airflow что-либо, это поискать нужный пакет. Для нашего случая такой тоже существует, поэтому модифицируем наш образ для Airflow и установим нужную зависимость:
FROM apache/airflow:2.8.0-python3.11
WORKDIR /opt/airflow
RUN pip install apache-airflow-providers-apache-spark
USER root
RUN sudo apt-get update -y
RUN sudo apt-get install openjdk-17-jdk -y
USER 50000Однако, как вы могли заметить, дополнительно требуется установить openjdk, т.к. без него submit не запустится. И после этих манипуляций размер образа увеличивается с 350mb до 1.5gb, что может неприятно сказаться на времени выполнения CI/CD процессов.
Сам процесс запуска можно представить следующим образом:
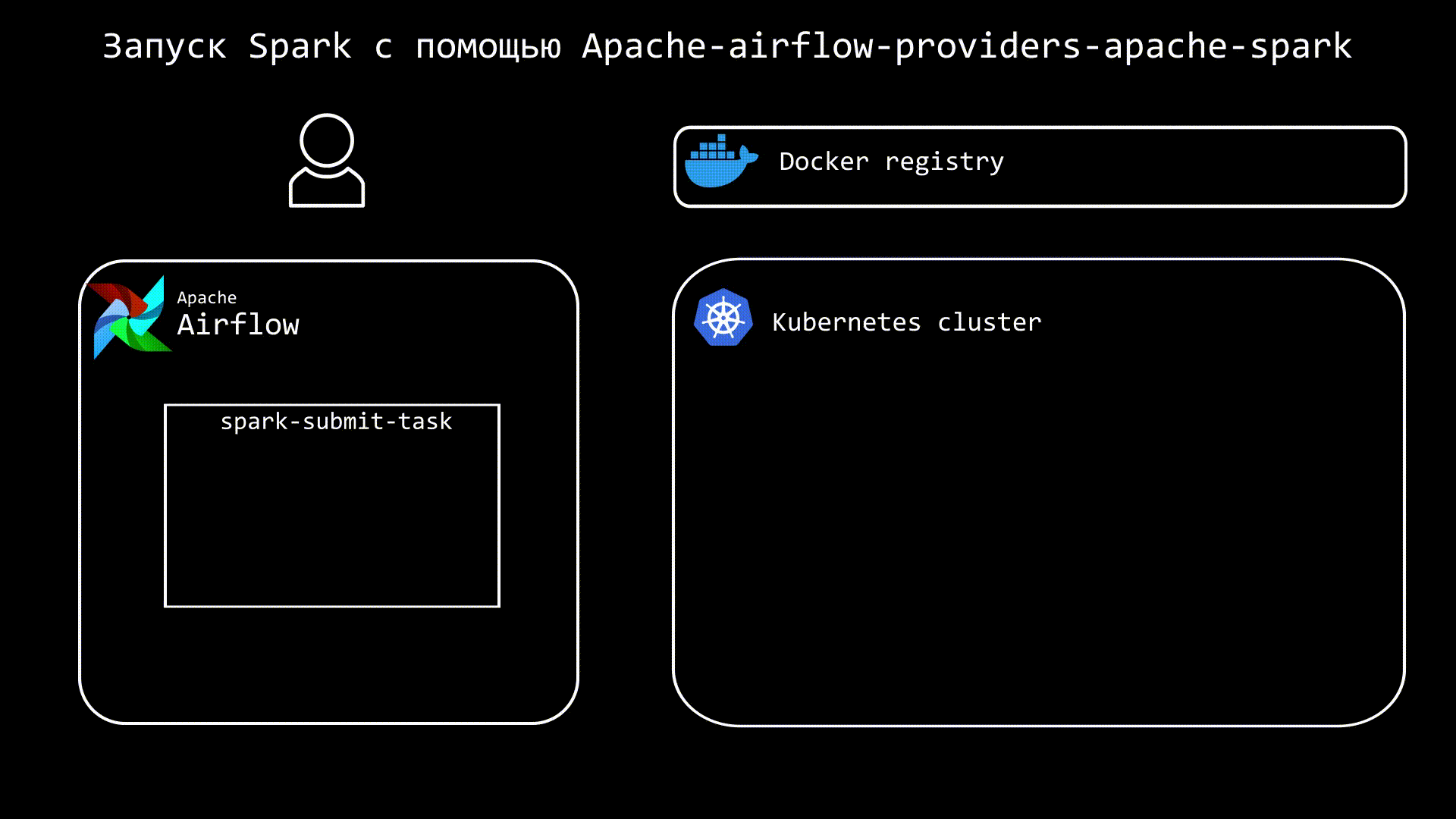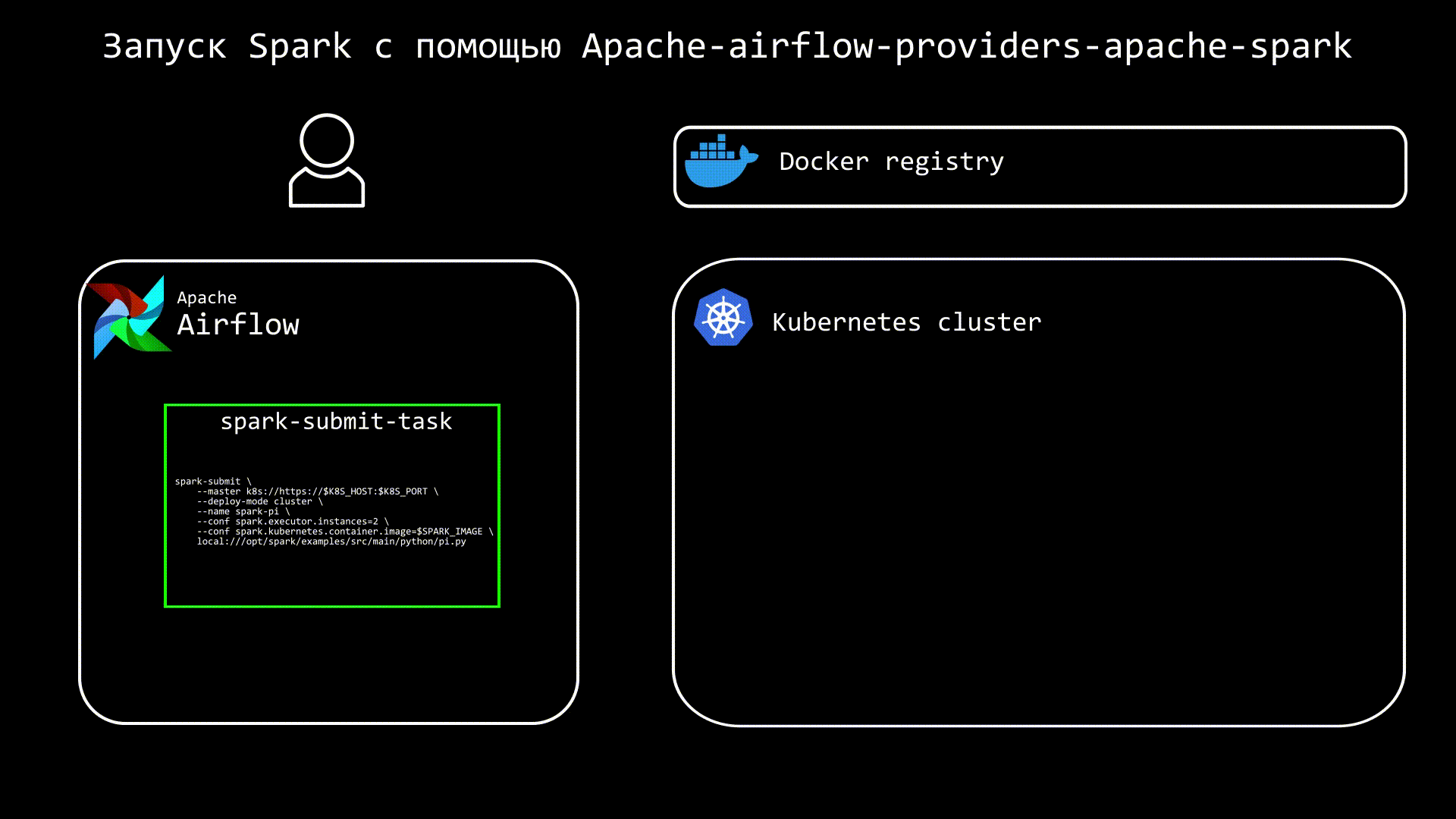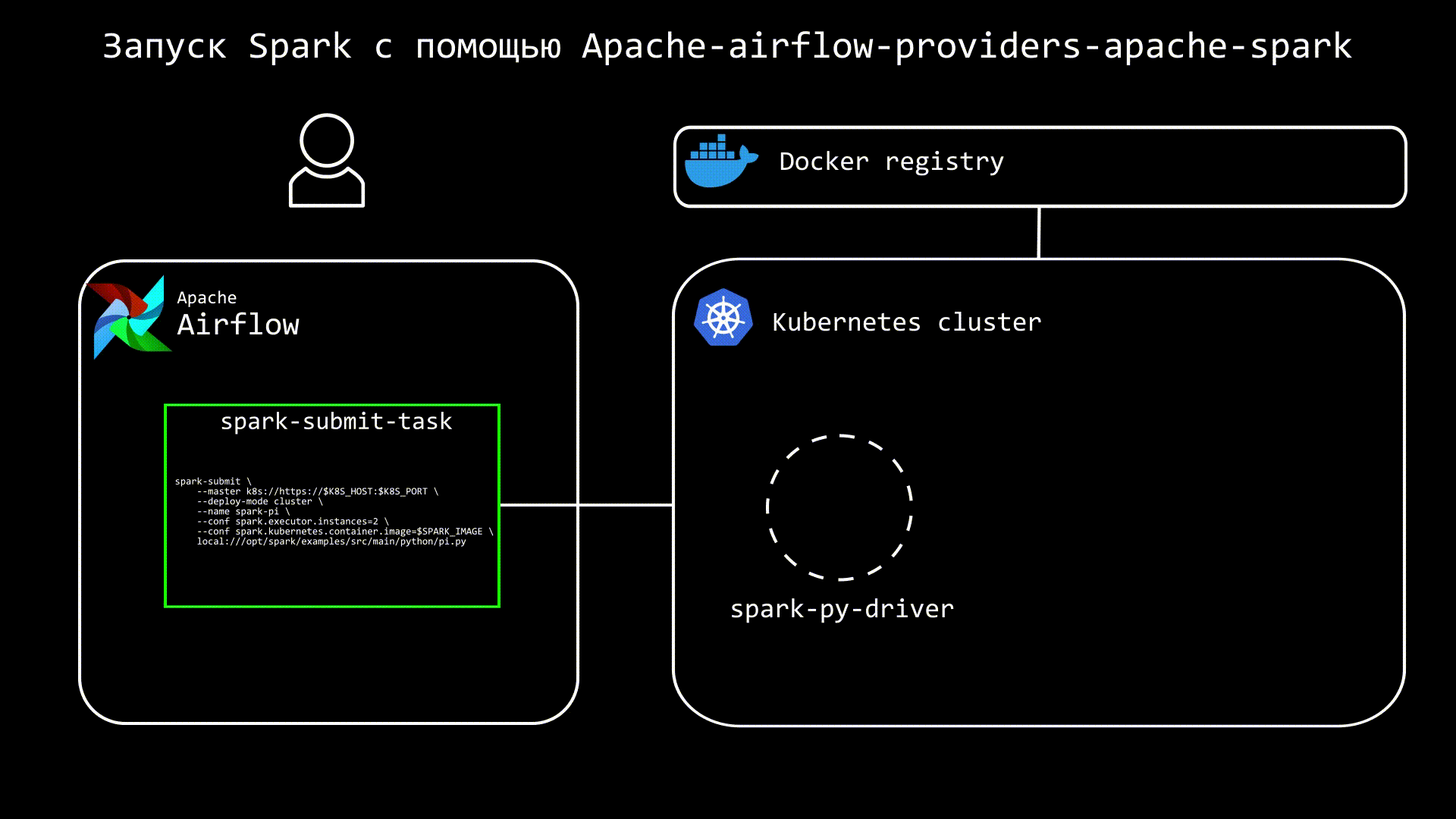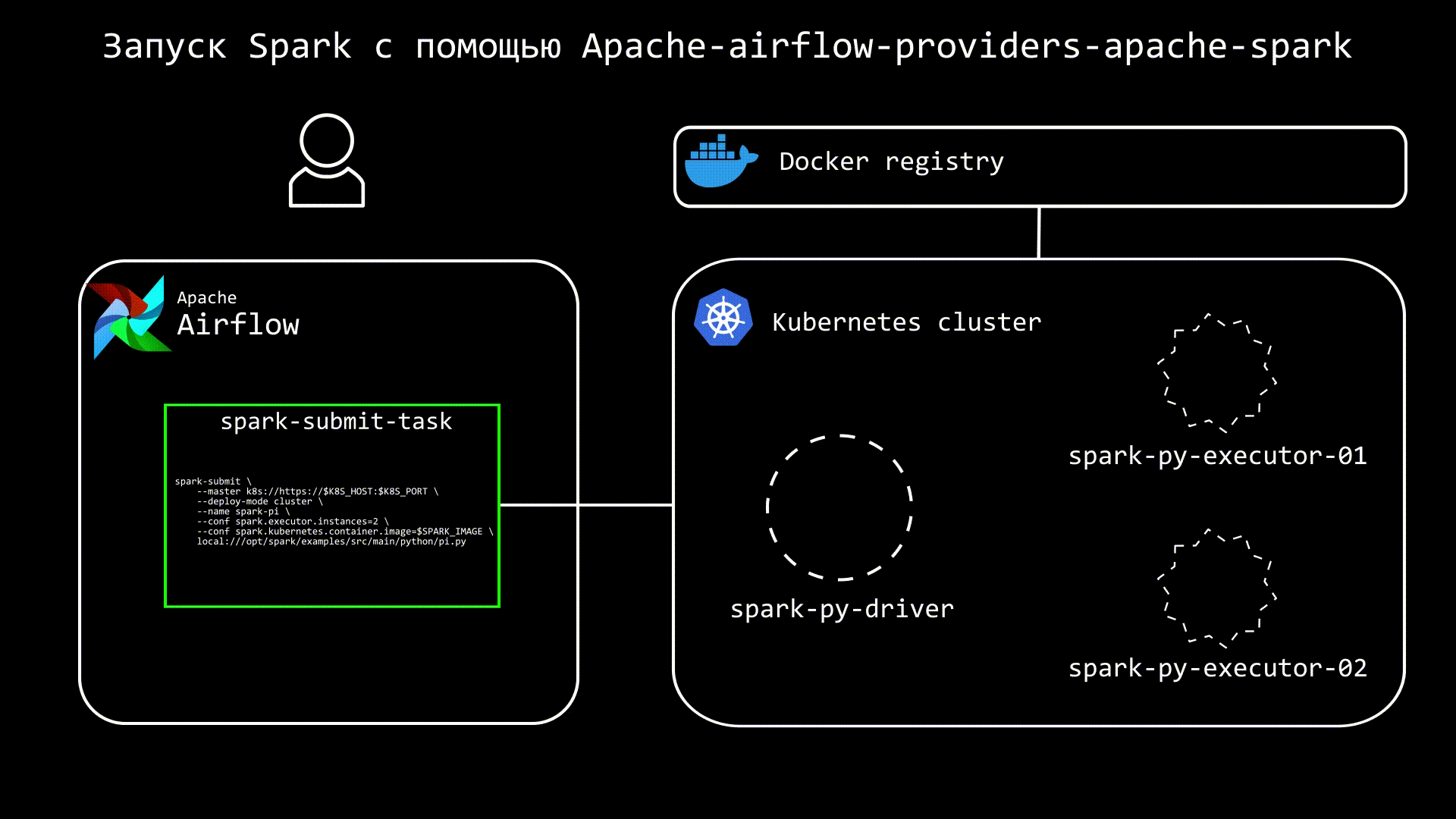
В DAG создаем подобную таску:
submit = SparkSubmitOperator(
task_id='submit',
conn_id='spark',
application='local:///opt/spark/examples/src/main/python/pi.py',
name='spark-pi',
conf={
'spark.submit.deployMode': 'cluster',
'spark.kubernetes.container.image': 'apache/spark-py',
'spark.executor.memory': '500m',
'spark.executor.instances': '1',
'spark.kubernetes.executor.request.cores': '0.1',
'spark.driver.memory': '500m',
}
)Создаем Airflow подключение:

Теперь запустим таску:

Как видите, в логах отображается лог submit, а хотелось бы увидеть лог драйвера. Также это неудобно, если таска упадет с ошибкой, за логами надо будет идти в кластер:

Поэтому можно сделать следующие выводы:
Плюсы:
Простота установки
Нужен только Airflow
Минусы:
Большой размер образа Airflow
В логах не отображается лог driver
В поисках решения, которое устранит эти недостатки, я наткнулся на инструмент Apache Livy
Путь 2. Apache Livy
Apache Livy представляет из себя отдельный сервис, который призван упрощать взаимодействие со Spark. Теперь вместо spark-submit, можно использовать REST, благодаря чему в Airflow нам нужна только библиотека requests. Кроме запуска, мы можем также отслеживать статус приложения. Грубо говоря, теперь запускать spark-submit будем не мы, а Livy, что позволяет не добавлять в образ Airflow дополнительных зависимостей.
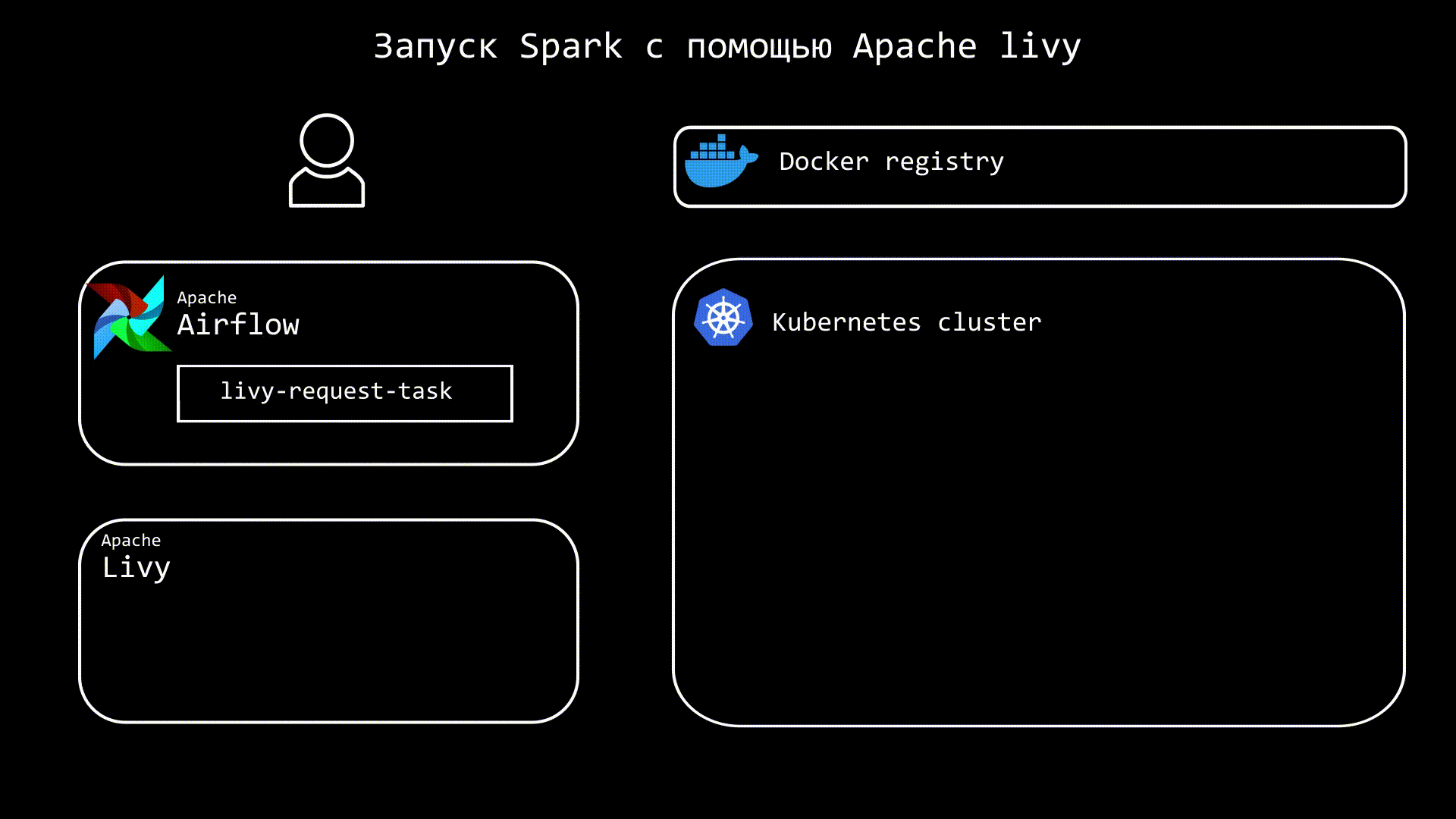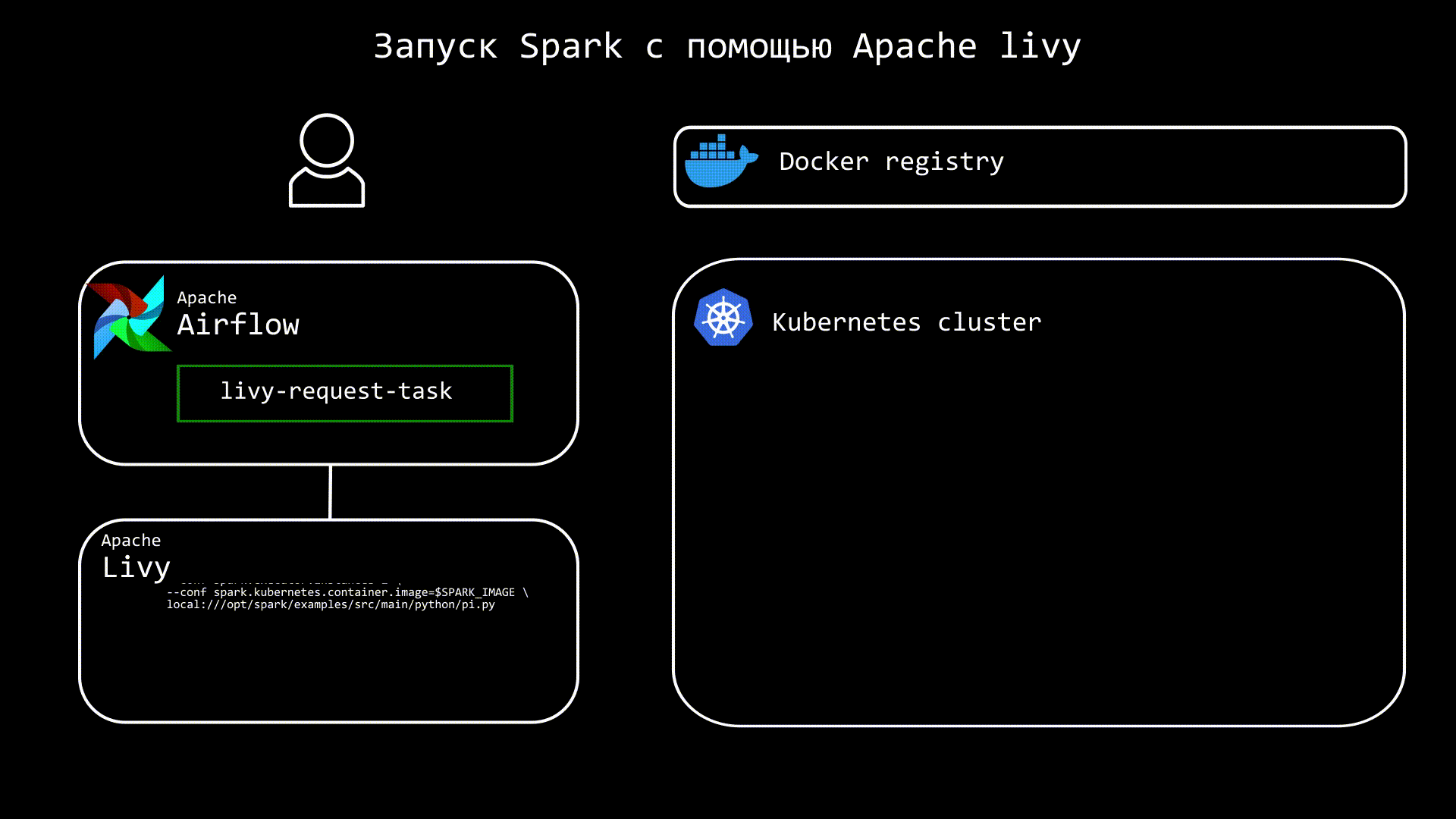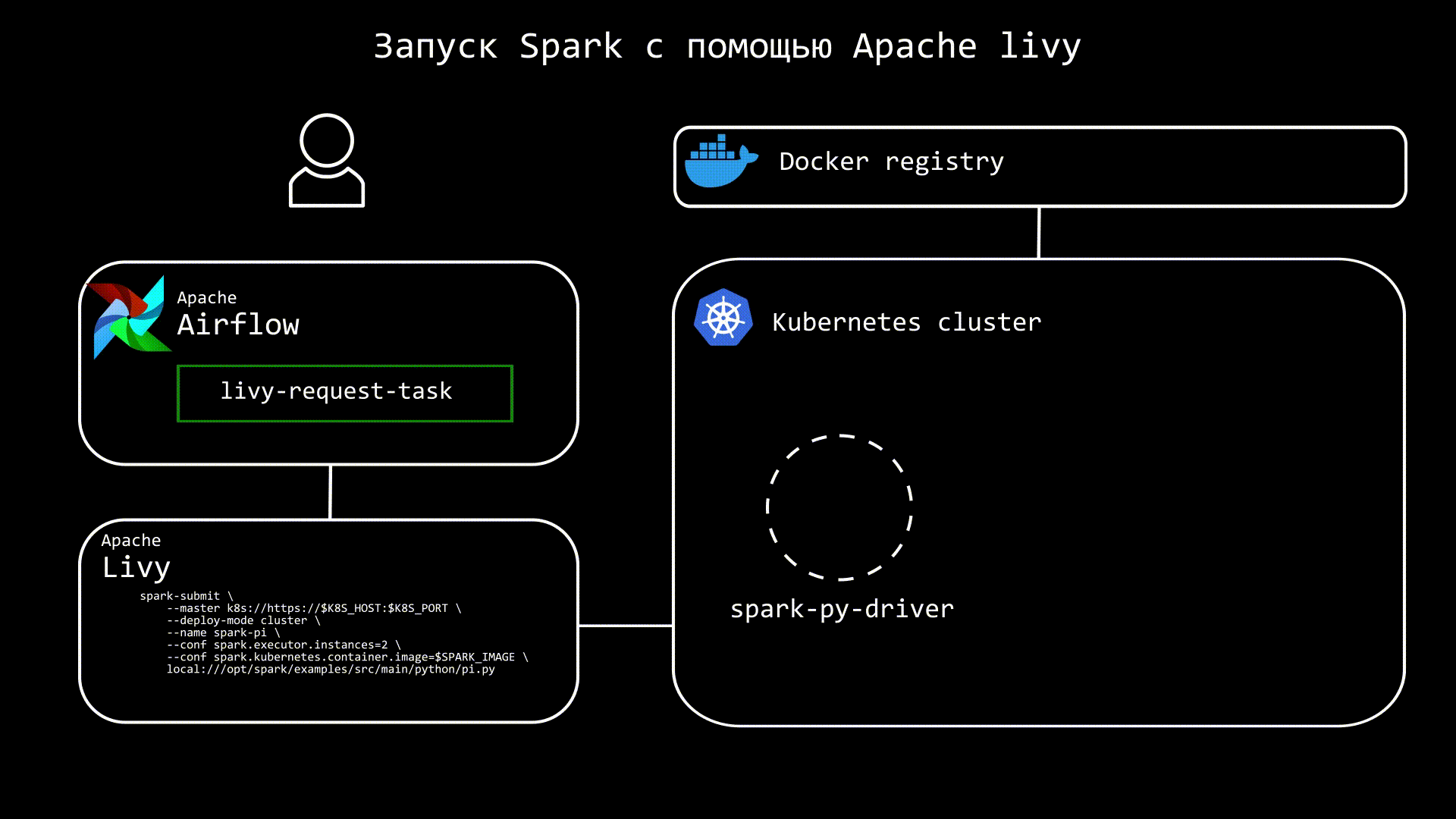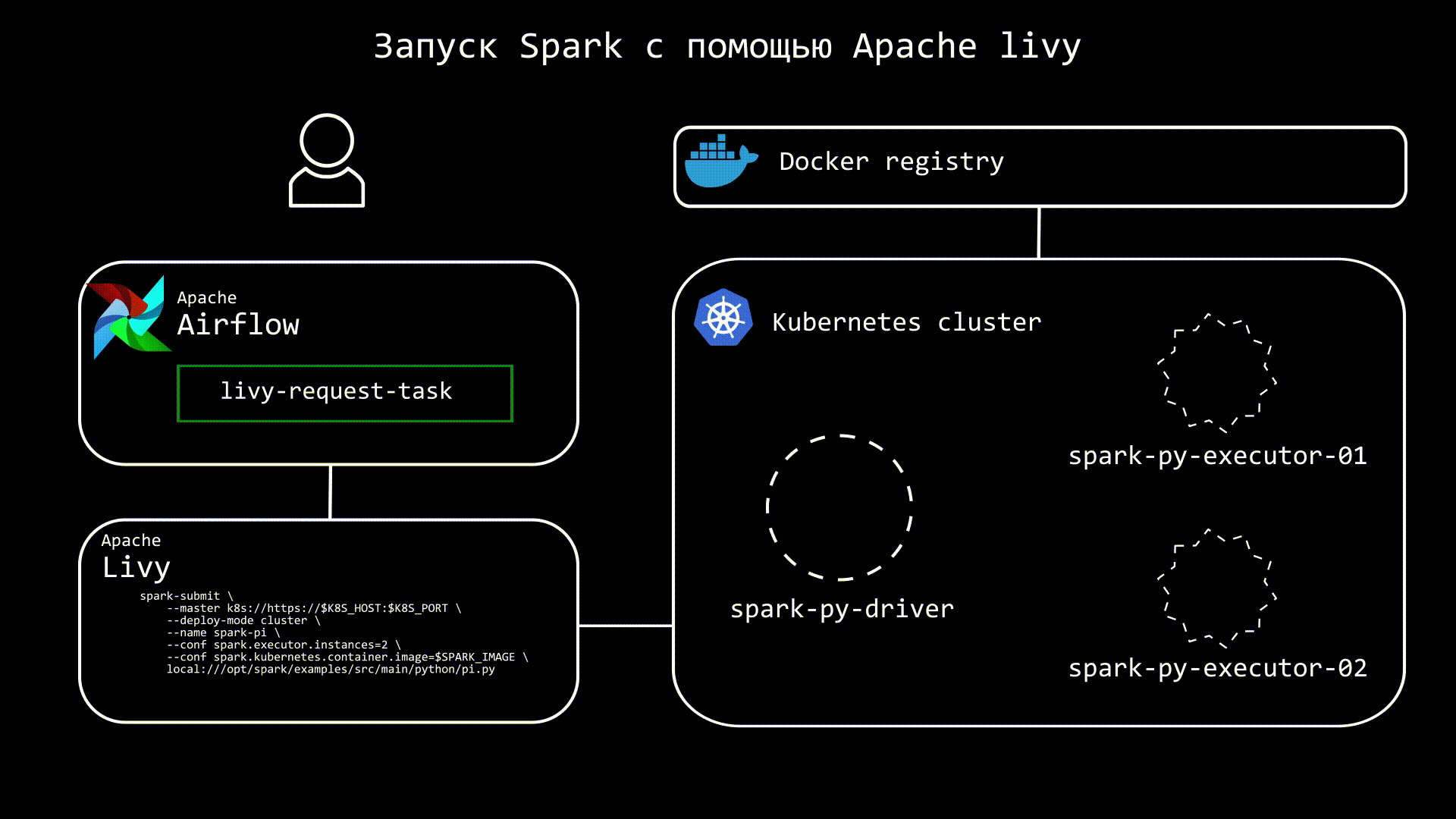
Еще одно преимущество Apache Livy
Кроме этого в сервисе есть возможность создавать сессии, которые будут сохранять Spark Context, что позволяет взаимодействовать со Spark сессией из разных тасок Airflow. Потенциально полезная штука, о которой уже писали вот тут
Но стоит учесть, что данный проект находится в статусе инкубации Apache, что несет за собой определенные риски:
While incubation status is not necessarily a reflection of the completeness or stability of the code, it does indicate that the project has yet to be fully endorsed by the The Apache Software Foundation .
Кроме этого, в гите проекта нет ни одного упоминания о Kubernetes. Однако, соблазн запускать Sspark приложения с помощью HTTP запроса достаточно высок, чтобы проверить этот инструмент на практике. Для этого я немного переписал образ из официального репозитория и написал небольшой k8s манифест.
Теперь напишем простой DAG:
@task()
def submit():
headers = {
'Content-Type': 'application/json',
}
data = '''{
"name": "test-001",
"className": "org.apache.spark.examples.SparkPi",
"numExecutors": 1,
"file": "local:///opt/spark/examples/src/main/python/pi.py",
"conf": {
"spark.kubernetes.driver.pod.name" : "spark-pi-driver-001",
"spark.kubernetes.container.image" : "apache/spark-py",
"spark.kubernetes.namespace" : "airflow"
}
}'''
response = requests.post('http://livy:8998/batches/', headers=headers, data=data)
passПосле запуска этого DAG мы увидим, что в интерфейсе Livy появился новый batch. А приложение успешно отработало.

Также с помощью API мы можем отслеживать статус, который отображается в интерфейсе на скрине выше. Но давайте проверим, корректен ли этот статус. Для этого запустим приложение с ошибкой:
")
Как видите, статус у таски test-002 - success, поэтому ориентироваться на статус, который приходит из Livy, нельзя.
Чтобы корректно отслеживать статус, можно использовать REST API самого Spark приложения, подробнее можно прочитать про это тут. Также автор этой статьи написал оператор и сенсор для Airflow, которые позволяют запускать и отслеживать статус задач в Livy. Однако их работу я не проверял, т.к. схема с Livy показалась мне достаточно сложной по сравнению со следующим способом запуска.
Плюсы:
Нет необходимости в дополнительных зависимостях
Есть готовые Airflow операторы
Минусы:
Некорректный статус приложения в Livy. Чтобы получать корректный статус, требуются дополнительные действия
В логах не отображается лог driver
Низкая поддержка проекта
Spark Operator
Kubernetes позволяет создавать пользовательские ресурсы. Именно это и представляет из себя spark-operator, документация и исходники которого лежат тут. Проект также имеет статус beta, однако есть страница с компаниями, которые используют его в продуктивной среде и их достаточно много.
В репозитории имеется Chart, который можно легко установить. Также для запуска необходимо установить в Airflow пакет apache-airflow-providers-cncf-kubernetes, который нужен для взаимодействия с kubernetes кластером. Он достаточно небольшой по сравнению с apache-airflow-providers-apache-spark из 1-го пункта.
Принцип работу Spark Operator следующий. Мы из Airflow отдаем команду на создание custom kubernetes ресурса - SparkApplication, который уже запускает и отслеживает состояние Spark приложения. Также в Airflow запускаем сенсор, который отслеживает статус SparkApplication:
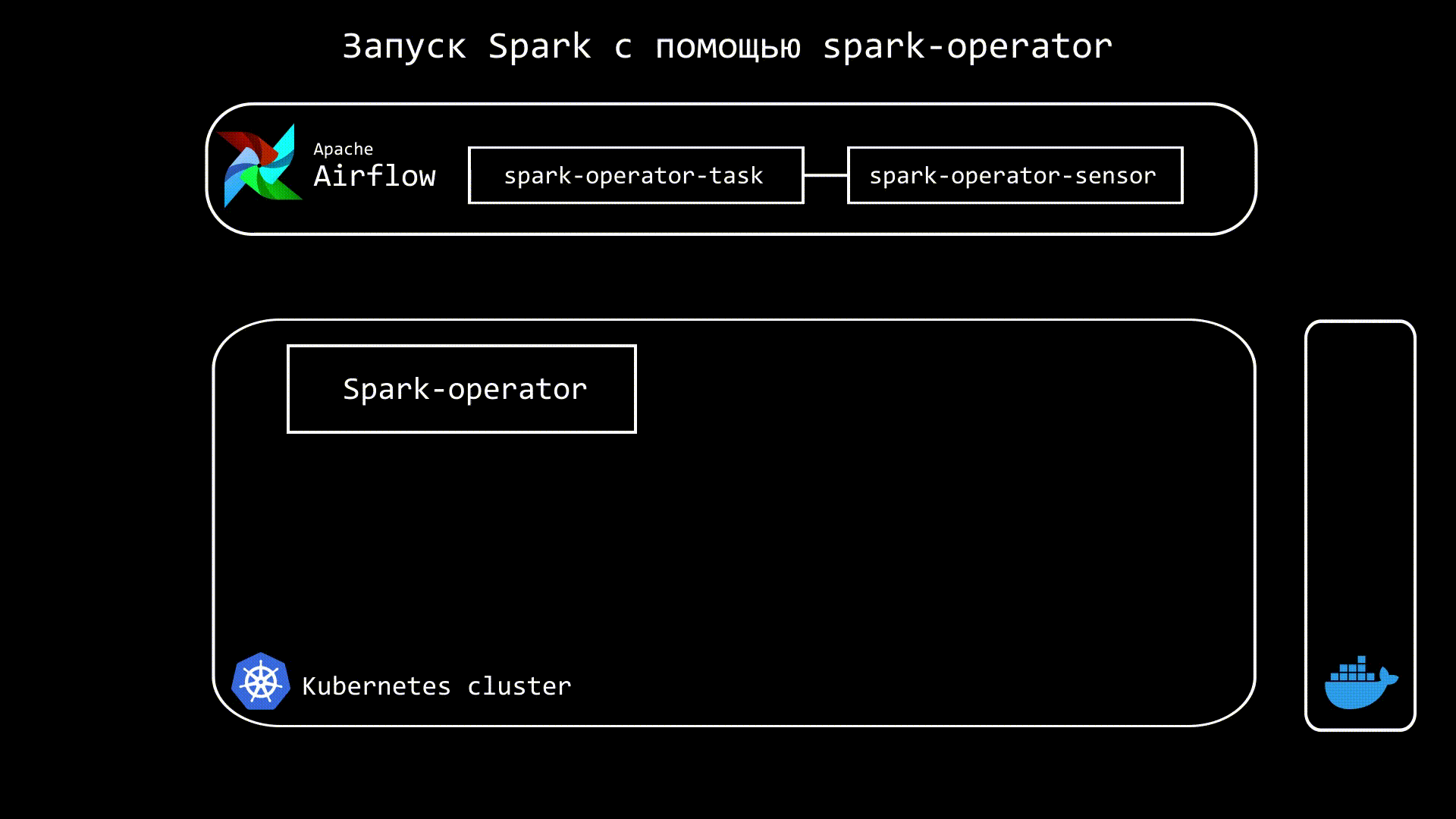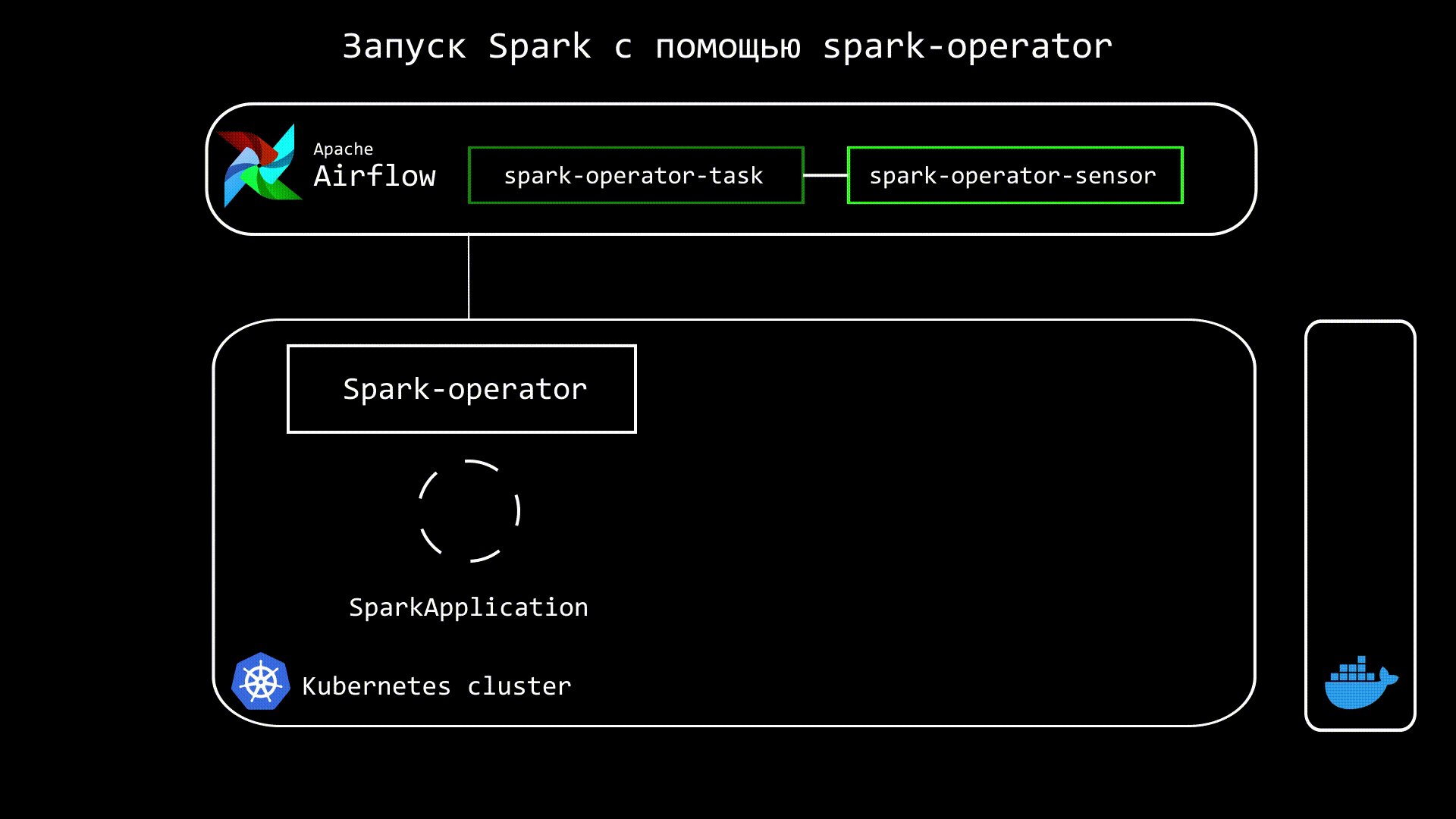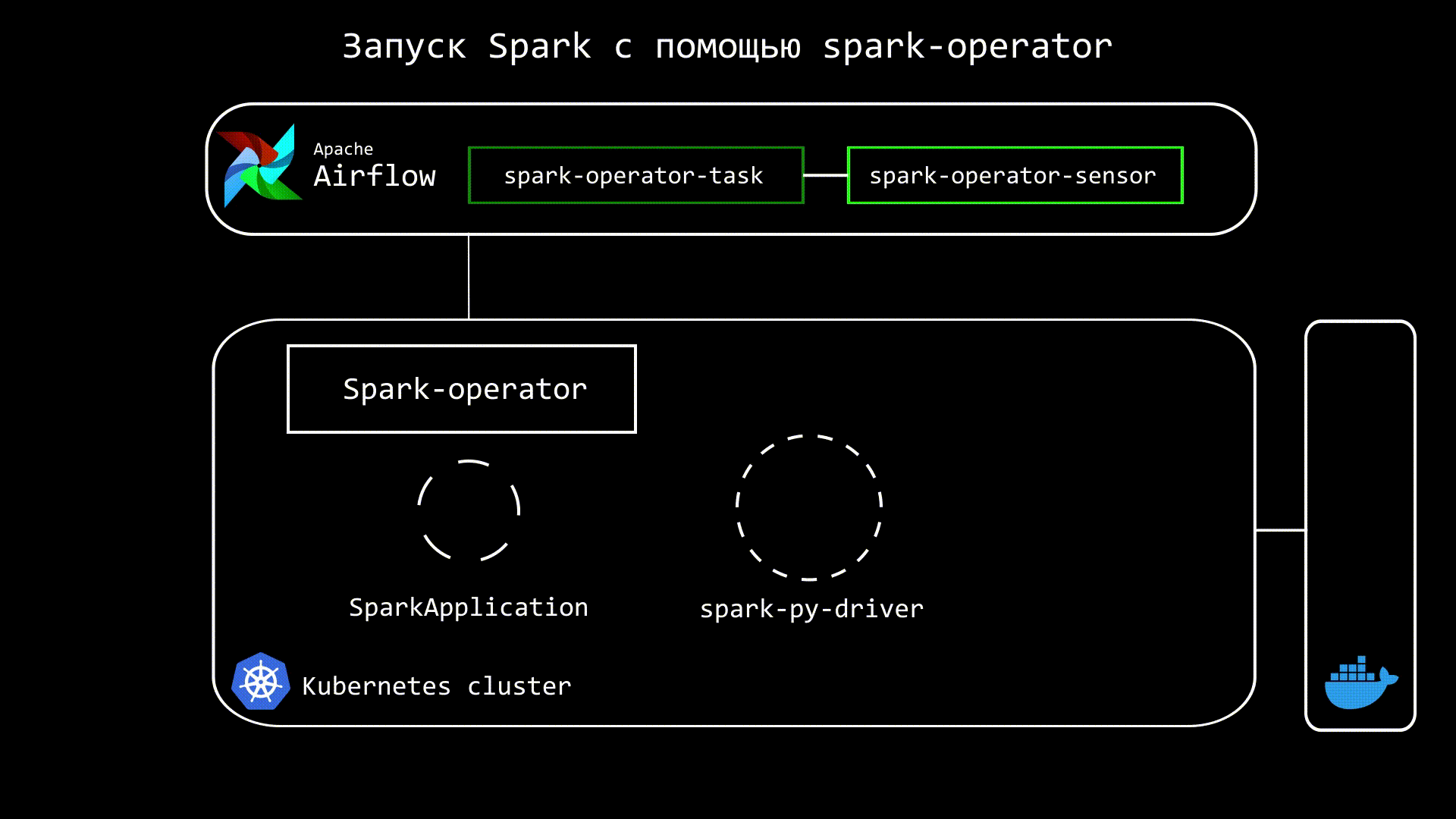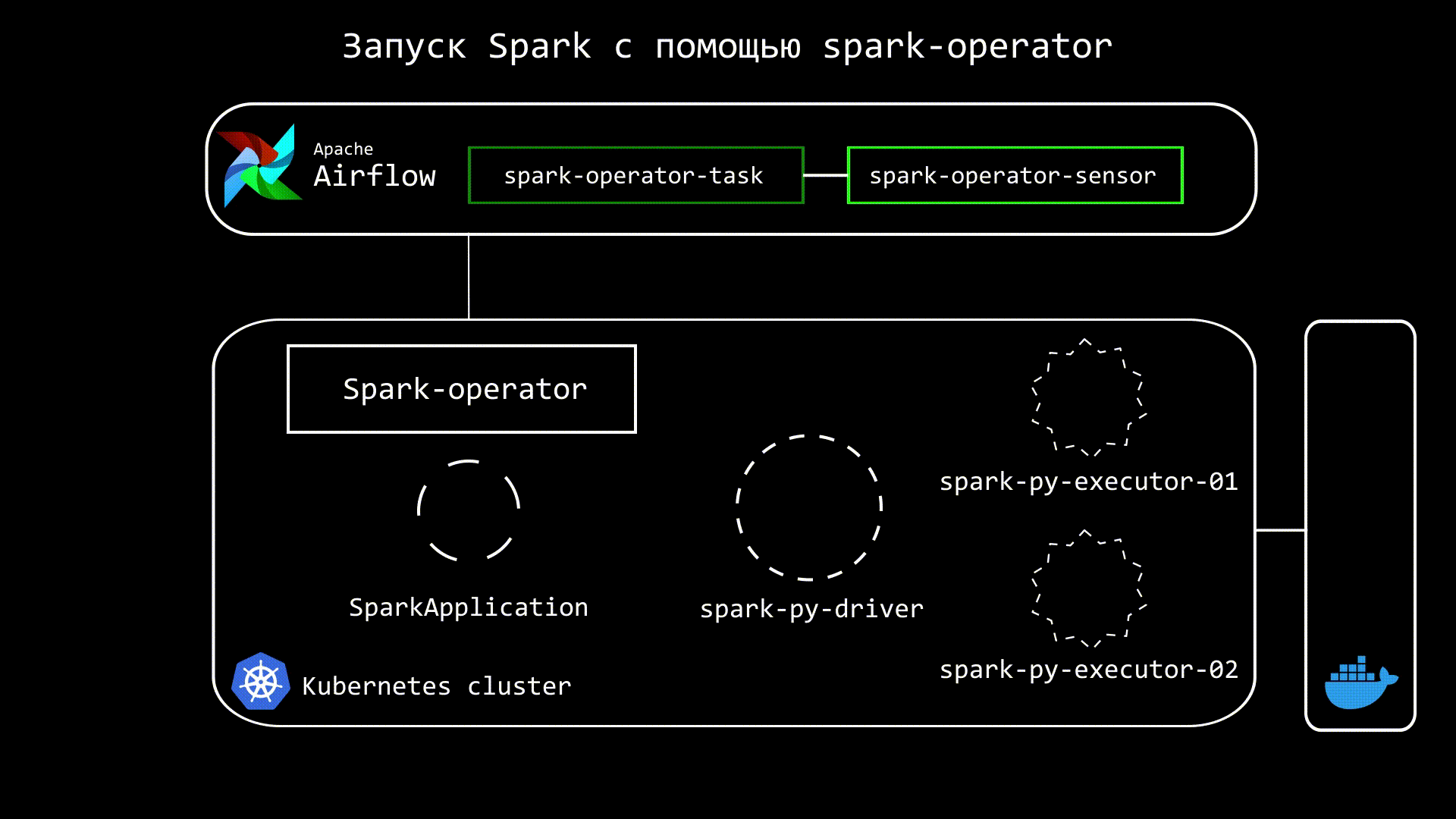
Код Airflow DAG этого процесса будет выглядеть следующим образом:
@dag(
schedule=None,
start_date= datetime(2024, 3, 1),
)
def spark_operator():
submit = SparkKubernetesOperator(
task_id="submit",
namespace="airflow",
application_file="spark-application.yaml",
do_xcom_push=True,
params={"app_name": "spark-pi"},
)
submit_sensor = SparkKubernetesSensor(
task_id="submit_sensor",
namespace="airflow",
application_name="{{ task_instance.xcom_pull(task_ids='submit')['metadata']['name'] }}",
attach_log=True,
)
submit >> submit_sensor
spark_operator()Также радом нужно положить файл spark-application.yaml с k8s манифестом в котором указываем нужны параметры.
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-pi
spec:
type: Python
pythonVersion: "3"
timeToLiveSeconds: 1800
mode: cluster
image: "apache/spark-py"
imagePullPolicy: Always
mainApplicationFile: local:///opt/spark/examples/src/main/python/pi.py
sparkVersion: "3.4.0"
driver:
coreLimit: "100m"
coreRequest: "100m"
memory: "500m"
executor:
coreLimit: "100m"
coreRequest: "100m"
instances: 1
memory: "500m"Если говорить проще, то мы из Airflow выполняем команду kubectl apply -f spark-application.yaml. А после того как мы запустим таску, то мы сможем увидеть новый kubernetes ресурс с помощью команды:
kubectl get sparkapplications -n spark
Через некоторое время запустятся и привычные поды с driver и executors.
Но самое ценное то, что в логах сенсора мы увидим логи Spark driver:

А также то, что при ошибки в Spark приложении, таска с сенсором также упадет и покажет ошибку приложения, что позволяет корректно отслеживать запуски:

Но не все будет в логах
Однако при падении driver по OOM, логов об этом в сенсоре мы не увидим, хотя таска все равно упадет. Ошибки такого типа можно найти с помощью команды kubectl describe sparkapplication. Либо дописать оператор, чтобы также забирать sparkapplication events.
Плюсы:
Логи отображают лог driver
Корректные статусы Spark приложения
Минусы:
Дополнительная установка Spark-operator
Необходимо умение писать k8s манифесты
Вывод
Думаю, все три способа имеют право на существование. Если нужно быстро настроить запуск, то лучше воспользоваться 1-м способом. Если у вас уже используется Livy или вам нужно сохранять spark context между запусками, то можно воспользоваться 2-м способом, не забыв при этом о получении корректных статусов. Если же вы имеете базовые знания о Kubernetes, то 3-й вариант подойдет лучше всего, по крайней мере, я решил остановится именно на нем. Спасибо!