
В каждом проекте рано или поздно наступает момент, когда нужно провести нагрузочное тестирование. Чаще всего это происходит поздно: сайт уже крашится под наплывом пользователей, стартовая страница не загружается, а обработка запросов в базе данных длится больше минуты. В такие моменты в «Джире» тестировщика появляется новая задача на поиск узких мест в системе.
Конечно, в подобной ситуации уже не до проведения нагрузочного тестирования по всем правилам, но если получилось выиграть пару дней или выпал редчайший шанс провести тестирование до «пожара», то эта статья для вас. Меня зовут Алена Вахтина и я ведущий специалист по тестированию в Лиге Цифровой Экономики — поделюсь своим опытом.
Постановка целей
Начнем с постановки целей нагрузочного тестирования. Заддосить сайт, положив его спать на какое-то время — не нагрузочное тестирование. Это лишь покажет, что вы можете открыть инструмент и поставить большое количество потоков, не больше.
Справедливости ради скажу, что так нагрузочное тестирование тоже проводится, но подобный подход вряд ли поможет обнаружить все узкие места проекта. Поэтому рекомендую приступать постепенно. Выделю несколько возможных целей:
найти узкие места проекта, которые слабее всего держат нагрузку;
понять, как долго сайт может держать среднюю нагрузку;
выяснить максимальное число одновременных пользователей.
Исходя из целей, разделим нагрузочное тестирование на три большие группы:
Тесты запускаются на какое-то короткое время, с каждой новой итерацией увеличивается количество потоков. При таком подходе мы определяем, в какой момент сайт перестает держать нагрузку, а также можем искать узкие места.
Тестирование делаем на длительное время, например час, рабочий день или сутки. Количество потоков — чуть выше среднего. Это даст понять, как продукт будет вести себя при уменьшающейся нагрузке, найти возможные утечки памяти.
Тесты начинаем с максимальным количеством потоков. Здесь смотрим, как долго сайт сможет держать пиковую нагрузку. Кроме того, стоит проследить, как произойдет восстановление после падения.
Лучше всего, когда есть время провести все три вида тестов. Но чаще всего можно успеть только один. В таком случае лучше всего выбрать постепенное увеличение потоков.
Исследование продукта
С постановкой цели определились. Тут можно было бы открыть тот же JMeter и начать писать сценарии. Но какие запросы указывать? Покрыть весь продукт тестами обычно сложно, если не сказать, что невозможно. Для этого и нужно исследовать.
Сядьте с ручкой и листком и напишите, какие действия чаще всего производит ваш пользователь, какие сущности просматривает, а может, создает. После этого добавьте свой опыт: подумайте, где проект может максимально буксовать.
У меня это журналы и отчеты, а также поиск. Но если журналы используются постоянно, то отчеты строятся редко, поэтому их я исключу из нагрузочного тестирования, но обязательно проверю оставшиеся два пункта.
Покажите полученные сценарии аналитику и архитектору, возможно, они подскажут вам еще парочку или скажут отказаться от каких-нибудь лишних. Оставшийся список тестов и будет нагружаться.
Настройка окружения
Далее нужно понять, где будет проводиться нагрузочное тестирование — не на проде ведь. Поэтому определимся с тем, что еще понадобится для проведения исследования.
Во-первых, нужно определиться, на каком стенде запустим тестирование. В идеале тестовый стенд должен быть релевантным продуктиву, но чаще всего такое невозможно, поэтому остается использовать то, что есть, рассчитывая пропорции. Если же получится заказать отдельный стенд, то лучше заранее рассчитать удобные пропорции.
Кроме стенда нужно настроить систему мониторинга. Чаще всего используются такие:
Zabbix;
Victoria metrics;
Prometheus;
и т. д.
Эти программы нужны для получения дополнительной информации о состоянии нашей системы в момент нагрузки.
Системы мониторинга очень гибкие. В сети имеются сотни различных шаблонов для проверки малейшего шевеления системы, поэтому стоит заранее обговорить с DevOps-инженером параметры, которые стоит мониторить. Вот примерный список тех, которые я прошу настроить на отдельном комплексном экране в Zabbix, но в зависимости от продукта он может варьироваться:
cpu;
memory;
I/O internet;
kafka connection;
bd connection.
Конечно, это не все нужные параметры, а некоторые могут оказаться лишними в ваших проектах, например kafka connection, если в самом продукте не используется Kafka.
Итоговый настроенный мониторинг выглядит так:

Или так:

В случае отсутствия систем мониторинга и времени для их настройки можно воспользоваться стандартными утилитами Linux:
htop (или top);
vmstat;
ps axu;
iostat;
iotop;
atop.
Однако системы мониторинга еще не все: они лишь укажут на проблему, но не помогут зафиксировать ошибку в момент ее появления.
Рассмотрим, как происходит общение различных частей приложения:
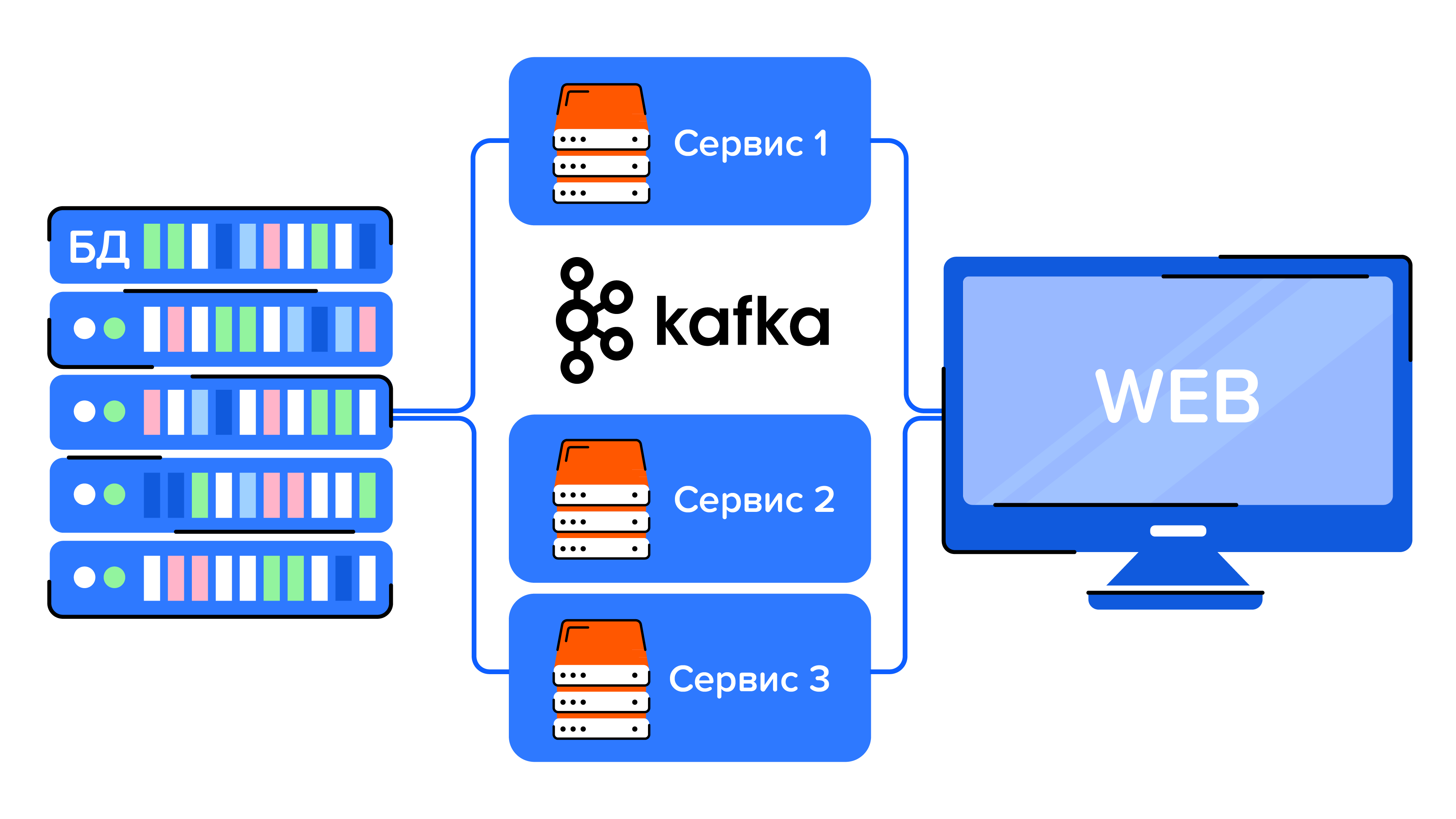
Поэтому для отлавливания проблем в различных местах приложения понадобятся: анализ логов для бэка, снятие активности базы данных для БД и Kafka Tool для Kafka.
После окончательной настройки приложения можно приступать непосредственно к нагрузке.
Выбор инструментов
Не буду подробно расписывать выбор инструментария, потому что на эту тему можно почитать статьи здесь, здесь или здесь. Я использую Apache JMeter. Не скажу, что выбрала именно его осознанно, но вполне довольна им. Перечислю положительные и отрицательные стороны.
Плюсы:
большое количество информации и статей;
возможность добавлять новые плагины;
кроссплатформенность;
удобный анализ данных;
возможность работать с ui и через терминал.
Минусы:
сильно жрет память, может повесить весь комп;
не все плагины хорошо работают.
Возможно, у кого-то этот список может отличаться.
Некоторые лайфхаки с JMeter
Раз уже сказала, что использую JMeter, то расскажу несколько интересных вещей, которые я бы хотела знать в первые попытки нагрузочного тестирования.
Нагрузочные тесты JMeter нужно запускать из консоли. Серьезно, это написано даже на стартовой странице.

Сделать это легко:
jmeter -n -t <JMETER_PATH>/<FILE_NAME>.jmx
-
Тесты, запущенные из-под консоли, лучше распределяют нагрузку и имеют более релевантные результаты.
Тесты можно не только создавать руками, собирая отдельно каждый REST-запрос, но и записать их, воспользовавшись Recorder-ом. Однако совет спорный: мне больше нравятся тесты, написанные самостоятельно, потому что они более подконтрольные, их легче править, и тестировщик лучше понимает, что происходит. Но стоит признать, что работа с Recorder-ом на порядок быстрее. Как это сделать, можно прочитать здесь.
Не нужно с самого начала посылать максимальное количество потоков. Кажется, я об этом уже говорила. Если вам лень запускать и останавливать руками, меняя постепенно количество пользователей, то в JMeter есть плагины Stepping Thread Group и/или Ultimate Thread Group. Используйте их.
Стоит подружить JMeter с Allure. В дальнейшем, когда будете писать отчет по нагрузочному тестированию, станет подспорьем. Как это сделать, можно прочитать в статье.
Удобно использовать переменные и прямое обращение в БД.
Кроме этого есть и другие удобные вещи. Не зря сам JMeter выпустил статью Best Practices.
Написание отчета
Допустим, нагрузочное тестирование проведено. Здесь я пропустила, как это делалось, потому что информации на эту тему великое множество, на крайний случай всегда можно почитать документацию.
Пришло время писать отчет. Зачем это делать?
Во-первых, чтобы не потерять то, что вы уже сделали. Как сравнить результаты после исправления проблемы, если не были сохранены никакие записи?
Во-вторых, не каждый разработчик, архитектор или аналитик готовы воспринимать ваши графики. Обязательно нужно проанализировать результаты и сделать выводы.

В-третьих, нагрузочное тестирование все чаще включается в перечень документов по сдаче продукта, поэтому с опытом написания отчетов будет легче предоставить ответ в момент дедлайна.
В любом случае, писать отчет или нет — ваш выбор. Но если все же решили это делать, то вот несколько советов.
Заранее придумайте удобную для вас структуру. Наш шаблон для отчета по нагрузочному тестированию выглядит следующим образом:

Поверхностно пройдусь по каждому заголовку отчета:
Цели — для чего проводим именно это тестирование.
Сценарии тестирования — какие сценарии были выбраны для нагрузки в этот раз. Помогает объяснить заказчику на примерах реальных шагов пользователей.
-
Тестовая среда — описание среды, в которой будет проводиться нагрузка.
Настройки продукта — какие настройки выставлены в БД, Kafka (количество соединений, время ожидания и т. д.) и других местах.
Параметры стенда — таблица мощностей для стенда (место, память и т. д.).
Описание графиков — памятка по графикам JMeter.
Ход тестирования — скрины графиков JMeter и Zabbix на каждый отдельный запуск.
Выводы и комментарии — что можно сказать о системе, какие узкие места были найдены во время нагрузочного тестирования, как изменились показатели по сравнению с предыдущей нагрузкой.
Расшифровка результатов
Расшифровка полученных результатов — это кульминация нагрузочного тестирования. Нагрузка стенда, чтобы он просто упал, смысла не имеет. Нужно правильно объяснить, как и почему это произошло, найти проблемы и дать возможные советы по исправлению ошибок.
Результаты нагрузочных тестов могут быть получены из графиков самого JMeter и из систем мониторинга. Начнем с первых.
Summary Report
Суммарный отчет по прохождению теста. Сводная таблица, показывающая max/min/avg время (время указано в миллисекундах) для каждого запроса, количество ошибок в процентах и другие параметры.
Метка (Label) — метка для запроса.
Количество запросов (# Samples) — количество запросов с такой меткой.
Среднее (Average) — среднее время.
Min — минимальное время запроса.
Max — максимальное время запроса.
Error % — процент запросов с ошибкой.
Производительность (Throughput) — количество запросов в секунду.
Получено (Received) KB/sec.
Отправлено (Sent) KB/sec.

Response Time Graph
На графике времени отклика можно увидеть разноцветные линии. Эти строки показывают время ответа отдельной транзакции или запроса вместе со временем.

Анализируя форму графика, можно понять, насколько стабильно продукт работает. Чем прямее линия и чем она сооснее оси абсцисс, тем лучше. Краевые точки из такого графика нужно выбрасывать, потому что на них влияет сам JMeter в момент его запуска и отключения.
Так, если видны резкие колебания, то они показывают, что производительность продукта может время от времени меняться. Лучше уточнить, должно ли приложение так работать.

Агрегированный отчет представляет собой сводную таблицу со статическими показателями выполнения каждого уникального сэмплера в тестовом плане.
Одни из основных показателей этого элемента, которые отличают его от других отчетов такого типа, — перцентили (Percentile/Line) — время, за которое отклик получает соответствующая доля запросов:
Метка (Label) — метка для запроса.
Количество запросов (# Samples) — количество запросов с такойиметко.
Среднее (Average) — среднее время.
Медиана (Median) — время, за которое гарантированно выполняетсят50% запросов.
90% Line — время, за которое гарантированно выполняется 90%тзапросов (90th percentile).
95% Line — время, за которое гарантированно выполняется 95%тзапросов (95th percentile).
99% Line — время, за которое гарантированно выполняется 99%тзапросов (99th percentile).
Min — минимальное время запроса.
Max — максимальное время запроса.
Error % — процент запросов с ошибкой.
Производительность (Throughput) — количество запросов в секунду.
Получено (Received) KB/sec.
Отправлено (Sent) KB/sec.
Aggregate Report

Этот график показывает отношение n-й сэмплеров ко времени отклика.
No of Samples — общее количество запросов.
Latest Sample — время ответа последнего запроса.
Average — среднее время ответа на все запросы.
Deviation — изменение времени отклика, величина измерения дисперсии, то есть отклонение распределения данных.
Throughput (Пропускная способность) — число запросов, обрабатываемых сервером в минуту.
Median — время, за которое гарантированно выполняется 50% запросов.
Graph Results

Так на нем можно посмотреть суммарное поведение всех вопросов по времени: как растут ошибки суммарно для всех вопросов, увеличивается ли среднее время отклика, меняется ли пропускная способность и т. д. без привязки к конкретному тесту.
На этом с графиками JMeter все. При желании можно изучить их более глубоко. Вся информация есть в документации.
Следующими в пункте исследования стоят показатели систем. Ведь JMeter снимет показатели, связанные с REST-ами. Но что происходит в самом приложении? Как распределяется нагрузка? Насколько проседает CPU? Правильно ли указано максимально разрешенное количество коннекшенов к БД? На все эти вопросы поможет ответить работа с показателями систем метрик. Если их нет, то можно прибегнуть к запуску различных полезных утилит (смотрите выше) во время работы JMeter.
Например, на этом графике CPU виден четкий пик, хотя нагрузка была линейной. Почему так?
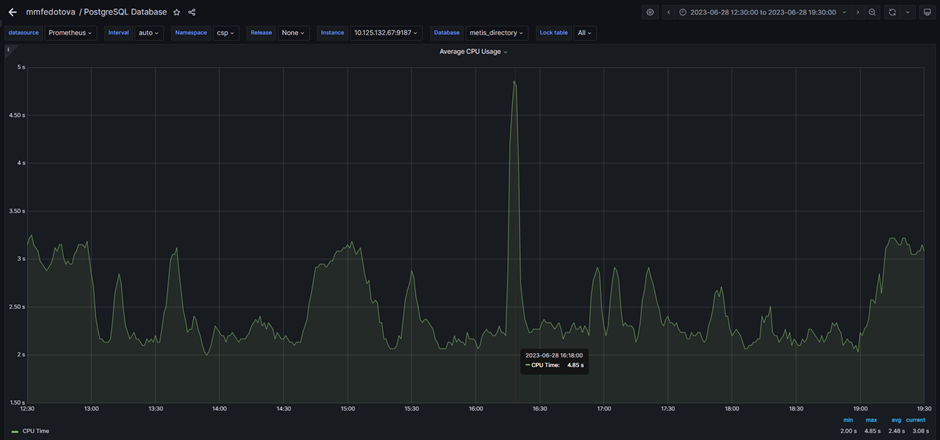
Для того, чтобы это понять, нужно дополнительно посмотреть логи.
А вот еще подозрительные пики на графике:

Понимание причины также требует исследования.
Я не буду рассматривать подробно все эти случаи, потому что каждая ситуация индивидуальна. Анализировать поведение системы в том или ином случае нужно отдельно или с опорой на опыт прошлого нагрузочного тестирования этой же системы на тех же стендах.
Дополню только, что в моменты нагрузки полезно запускать запросы в pg_stat_activity. Если запросы не оптимизированы, то в pg_stat_activity можно увидеть следующую картину:
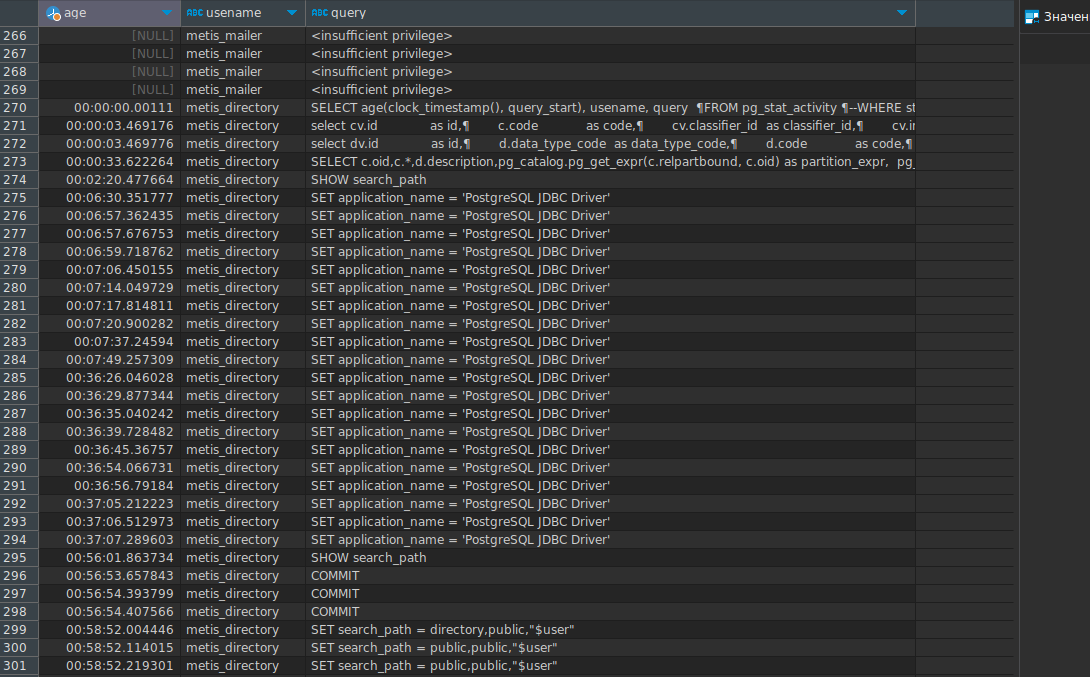
Для получения этих данных я выполняю следующий запрос:
SELECT age(clock_timestamp(), query_start), usename, state, query
FROM pg_stat_activity
WHERE state != 'idle'
ORDER BY query_start desc;
Или воспользоваться утилитой pg_activity:
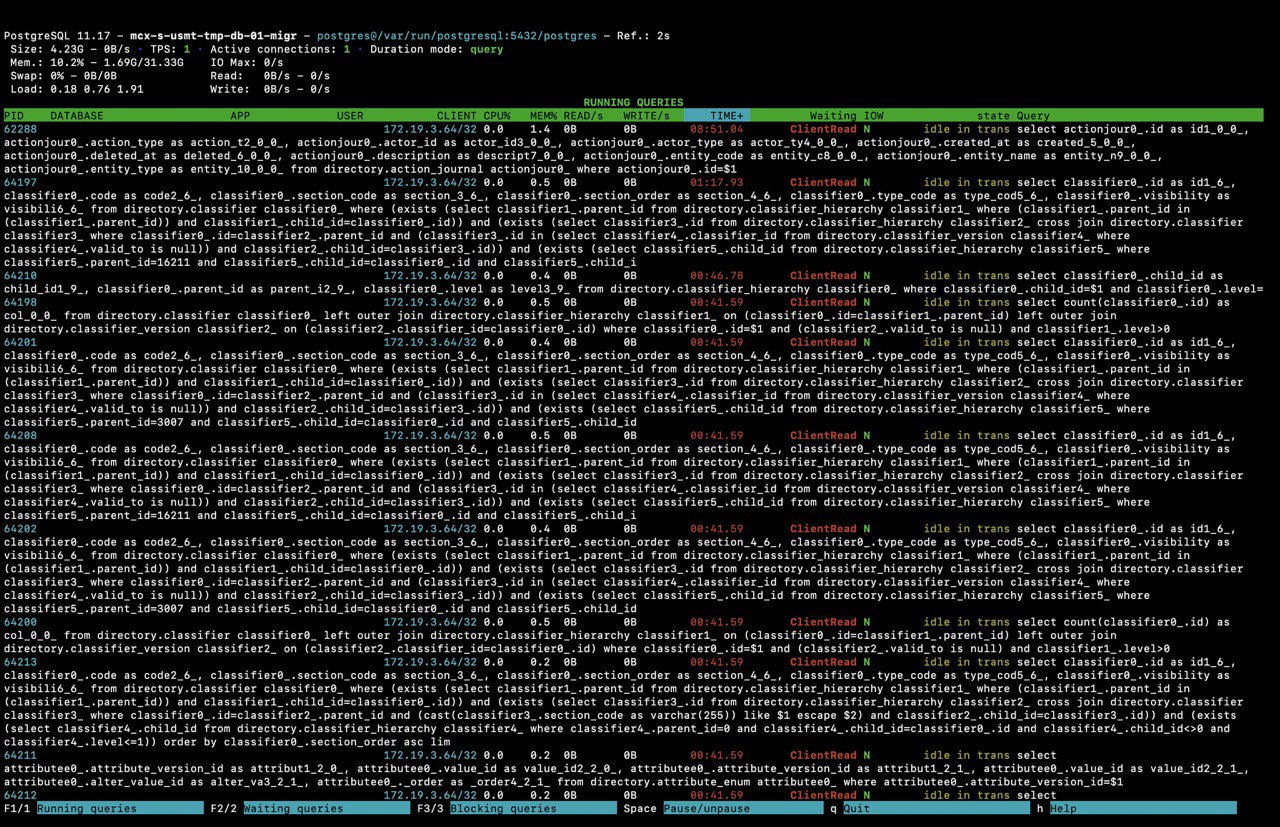
Как видим, некоторое количество запросов выполняется слишком медленно — это узкое место. В будущем оно может вызвать проблемы.
Подытожу
В заключение хочется сказать, что нагрузочное тестирование — полезная практика для любого проекта. Его можно проводить как на стадии разработки, так и на момент сдачи. Стоит только помнить, что нагрузочное тестирование — это не просто написать несколько запросов в JMeter и запустить их на максимальном возможном числе пользователей. Это комплексное исследование всего продукта, включающее в себя множество дополнительных инструментов. Ведь просто получить графики недостаточно, их нужно объяснить. Не стоит недооценивать такие исследования, в будущем они могут спасти от аварии.
Здесь собраны не все удобные фишки. Их гораздо больше. Пробуйте, ищите свои собственные лайфхаки. Удачи!
tuxi
Я наверное не открою Америки, но для стресс тестов вебприложения, мы берем access логи за 1..2 месяца и на их базе формируем список ресурсов для тулзы, которая обеспечивает нагрузку при стресс тестировании. 2 основных кейса обычно:
1) as is , то есть все дневные логи объединяются в один и все это запускается неким кол-вом потоков в сторону тестового стенда
2) согласно целям теста, логи отфильтровываются по каким-либо правилам, исключаются какие то разделы или например оставляем только те запросы, которые в логах имеют код ответа не равный 200 и т.д.
Варьируя кол-во потоков и случайность задержки между ними, можно имитировать нарастающую нагрузку, постоянную нагрузку, пиковую нагрузку и так далее
Минус - нельзя автоматизировать воспроизведение POST запросов для создания нагрузки максимально приближенной к реальной. Это да. Но это зависит от вебприложения уже.