
Приветствуем!
На связи Глеб Кононенко и Алексей Диков, мы разработчики из Лиги Цифровой Экономики. Год назад на одном большом проекте мы с коллегами начали работать с ClickHouse и сразу столкнулись с кучей проблем и недостатком информации по их преодолению.
ClickHouse — это специфичная, очень быстрая база данных. Особенность заключается в том, как хранятся и обрабатываются данные. Для каждой таблицы указывается Engine, движок, который обрабатывает данные после загрузки в асинхронном режиме. Обработка позволяет удалять дубликаты, сортировать данные, реплицировать и т. д. Более подробно с разными движками можно ознакомиться здесь.
Продукт — с открытым исходным кодом, русскоязычной документацией и возможной поддержкой. Поэтому растущая популярность неудивительна.
Мы набрались опыта, «набив шишки» на практике, и готовы им поделиться — запускаем цикл статей о том, как правильно «готовить» ClickHouse. И начнем с того, как эффективно создавать и использовать распределенные таблицы.
Немного о проекте:
Данные грузятся каждые 15 минут
Постоянно приходит дублирующая информация
Необходимо хранить данные в течении 5 лет
В среднем в сутки приходит 150 млн строк (пик — до 3 млрд/сут)
В базе 685 млрд строк, в сжатом виде 35 Тб, в несжатом — 350 Тб
Оглавление
Конфигурация кластера
Создание таблиц
Распределение данных между узлами
Как мы перегружаем данные между таблицами
Как мы решардили данные после добавления новых узлов (шардов)
Конфигурация кластера
Для начала давайте познакомимся с нашим тестовым ClickHouse. База данных размещается на четырех виртуальных машинах: clickhouse01-clickhouse4. В нашей конфигурации описываются три кластера: main, all-sharded и all-replicated. Из системной таблицы system.clusters можно увидеть их настройки:
select cluster, shard_num, replica_num from system.clusters;
all-replicated 1 1
all-replicated 1 2
all-replicated 1 3
all-replicated 1 4
all-sharded 1 1
all-sharded 2 1
all-sharded 3 1
all-sharded 4 1
main 1 1
main 1 2
main 2 1
main 2 2Кластер all-replicated: shard_num — везде 1, в то время как replica_num имеет значения от 1 до 4. То есть таблицы, которые создаются внутри этого кластера, будут исключительно реплицируемыми (на каждом из узлов данные полностью одинаковые).
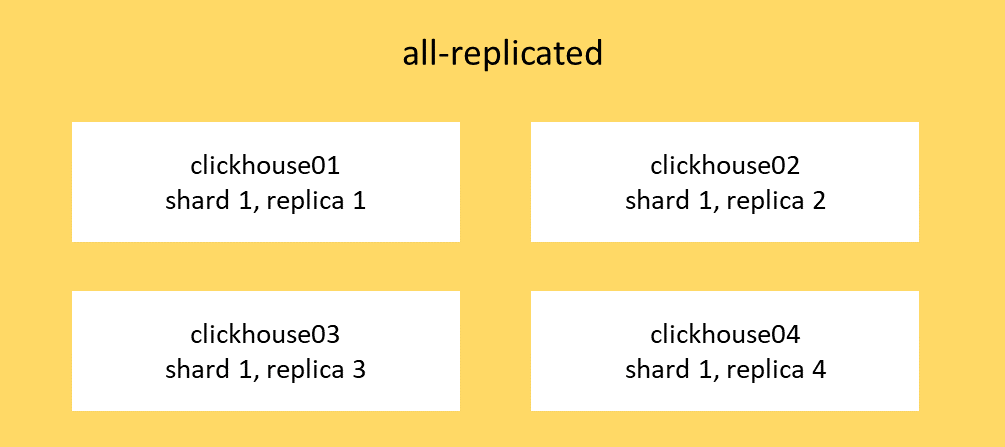
Таким образом мы храним всевозможные справочники, мелкие сущности и готовые витрины. Это позволяет нам избегать лишних передач по сети между узлами, а также сохраняет высокую доступность данных при выходе из строя одного из узлов.
Кластер all-sharded: shard_num имеет значения от 1 до 4, а вот replica_num — везде 1. В этом кластере создаются таблицы, для которых не нужна репликация, но требуется шардирование (распределение), то есть на каждом из узлов будет свой экземпляр данных (такого же куска не будет на другом узле).

Подобные таблицы могут потребоваться для сырых данных, для промежуточных расчетов или для любых других ситуаций, когда не нужна высокая доступность данных (если случится сбой 1 из 4 узлов, у нас будет доступно только 75% от всего объема данных).
Кластер main: и shard_num, и replica_num имеют значения от 1 до 2. В этом кластере создаются распределенные таблицы, которые будут иметь реплики. Основными шардами выступят узлы clickhouse01 и clickhouse03, а clickhouse02 и clickhouse04 будут их репликами соответственно.

В таком кластере мы размещаем крупные таблицы, которые требуют распределения данных, а также для них необходима высокая доступность (если один из узлов выйдет из строя, пользователям будет доступен полный объем данных).
Кроме того, нам понадобится настроить макросы на каждом из узлов для указания, каким шардом и/или репликой он является. Они будут вызываться в путях сервиса-координатора ZooKeeper при создании таблиц. Примерно вот так:
<macros>
<cluster>main</cluster>
<shard>1</shard>
<replica>1</replica>
</macros>Создание таблиц
Так как мы используем балансировщик нагрузки, наш запрос методом round-robin отправляется для выполнения на один из узлов. Другими словами, отправляя команду в ClickHouse, мы не знаем, на каком узле она выполнится.
Что будет, если создать таблицу следующим образом?
create table db.users (
uid Int16,
name String,
age Int16
)
ENGINE = MergeTree
ORDER BY (uid);Ответ простой — ничего хорошего. Таблица будет создана на одном случайном узле, и при последующем insert/select мы с вероятностью 75% получим ошибку о том, что таблица не создана, т. к., скорее всего, запрос отправится на узел, где ее действительно нет. Нам нужно создать таблицу вручную на всех узлах, либо воспользоваться опцией on cluster, которая автоматически отправит нашу команду на все узлы кластера.
create table db.users on cluster 'cluster-name'...;Но и этого на самом деле будет недостаточно. Необходимо корректно указывать движки таблиц. Движок MergeTree из примера выше — самый распространенный: он хранит данные в отсортированном по ключу виде, позволяет производить очень быстрый поиск. Подробнее можно почитать в документации.
Если таблица реплицируется, то есть ее копия записывается на несколько узлов, следует указать подвид этого движка с названием ReplicatedMergeTree. При этом в параметрах движка следует указать путь создания таблицы для Zookeeper.
Для таблиц в кластере all-replicated путь будет следующим:
ENGINE =ReplicatedMergeTree('/clickhouse/tables/all-replicated/TABLE_NAME', '{replica}')
В фигурных скобках указывается переменная, которая будет возвращена макросом, размещенным на каждом из узлов, — например, {replica} вернет нам значение 1 (см. пример макроса выше). Таким образом Zookeeper формирует у себя уникальные пути для распределения данных. Для all-replicated используются только реплики без шардирования. Подробнее про репликацию таблиц здесь.
Для таблиц в кластере main путь будет следующим:
ENGINE =ReplicatedMergeTree('/clickhouse/tables/{shard}/TABLE_NAME, '{replica}')
Макросом для {shard} будет подставлен номер шарда в Zookeeper, для {replica} — номер реплики.
Пример создания таблицы в кластере main:
create table db.users on cluster 'main'(
uid Int16,
name String,
age Int16
)
ENGINE =ReplicatedMergeTree('/clickhouse/tables/{shard}/users', '{replica}')
ORDER BY (uid);
Распределение данных между узлами
Большинство сущностей мы храним в кластере main. Наличие реплик данных обеспечивает отказоустойчивость, а шардирования — возможность горизонтального масштабирования.
Допустим, мы создали таблицу на всех узлах кластера main. Команда insert выполнится на каком-то случайном узле, и все данные останутся только на одном шарде. При этом данные автоматически реплицируются в реплику шарда, если настроена репликация. Для того чтобы данные распределились по всем шардам, нам потребуется создать таблицу с аналогичной структурой, другим названием и с движком Distributed. Такая таблица не содержит данных, она — своего рода представление (view), которое объединяет данные таблиц со всех шардов кластера.
create table db.users_distributed on cluster 'main' as db.users;
ENGINE = Distributed('main', 'db', users, rand())При вставке данных в эту таблицу данные будут распределяться уже равномерно и появляться на всех узлах, но случайным образом.
Для нас этот вариант не подходит, потому что при проектировании хранилища мы стараемся минимизировать передачу данных по сети и свести все расчеты к локальным внутри одного узла.
Для этой цели мы хотим использовать распределение данных по определенному полю или полям. Ограничение ClickHouse — поле распределения должно иметь тип данных int. Если необходимо распределить по полю другого типа, можно использовать хэш-функции, возвращающие целочисленное значение (например, murmurHash/cityHash/xxHash).
Вот пример создания таблицы с ключом распределения по хэшу от определенного поля таблицы.
create table db.users_distributed on cluster 'main' as db.users;
ENGINE = Distributed('main', 'db', users, murmurHash3_32(name))Теперь данные будут распределяться по значению
mod(murmurHash3_32(name), X), где X — количество шардов.
В ClickHouse есть возможность распределять данные неравномерно между шардами. Например, если при добавлении новых узлов мы не планируем делать перераспределение данных (решардинг), то можем отправлять большее количество данных на новые узлы. Для этого в настройках шарда мы можем прописать его вес:
<shard>
<weight>10</weight>
<replica>
<host>clickhouse01</host>
<port>9000</port>
</replica>
</shard>
<shard>
<weight>15</weight>
<replica>
<host>clickhouse03</host>
<port>9000</port>
</replica>
</shard>
В таком случае данные будут распределяться не от количества шардов, а от их веса, т. е. mod(murmurHash3_32(name), X), где X будет равен общему весу. И 10/25 данных будет отправляться на первый шард, а 15/25 — на второй (10 и 15 — это вес шардов из настройки выше).
Как мы перегружаем данные между таблицами
Перегрузка внутри одного узла
Специфика проекта — приходится несколько раз перекладывать данные между таблицами с некоторой трансформацией. Сперва мы делали «в лоб», брали distributed таблицы и выполняли одну команду:
insert into db.target_distributed
select * from db.source_distributed;
Но, как показала практика, это крайне медленно. Гораздо эффективнее пускать перегрузку данных локально внутри каждого из шардов с прямым подключением к требуемому узлу:
insert into db.target
select * from db.source;
Таким образом мы избавляемся сразу от двух операций: передачи данных по сети и повторного распределения данных между узлами.
Если же возможности подключаться к узлам нет, например, используется балансировщик нагрузки, то мы можем выполнять локальную переливку через функцию remote:
insert into function remote('clickhouse01', 'db.target')
select * from remote('clickhouse01 ', 'db.soure');
При использовании функции remote можно использовать как ip-адрес узла, так и его hostname (если узлы находятся в одной сети).
Передача данных между узлами
Такой вариант может быть необходим, например, при решардинге данных (в случае добавления новых узлов).
Простой вариант — опять же из distributed в distributed таблицу. Или же параллельно запустить заливку данных с каждого из шардов в целевую distributed таблицу:
insert into db.target_distributed select * from db.source;
Есть более продвинутый вариант: заранее отобрать куски данных, рассчитать, в какой целевой шард они должны будут попасть, и напрямую отправить их туда.
insert into function remote('clickhouse02', 'db.target')
select * from remote('clickhouse01', 'db.soure')
where mod(distributed_field, X) = 1;
Т. е. с первого шарда мы заливаем данные на второй шард, при этом отбираем с первого шарда записи, остаток от деления по полю распределения на X (количество шардов) равен номеру шарда за вычетом единицы.
Как мы решардили данные после добавления новых узлов (шардов)
Количество наших данных растет и нам надо расти вместе с ними — ClickHouse позволяет делать это как вертикально, так и горизонтально. В случае горизонтального масштабирования, таблицы в кластере all-replicated автоматически реплицируются на новые узлы. А остальные таблицы нам надо шардировать вручную.
Проблема заключалась в том, что после добавления шарда менялось условие:
mod(murmurHash3_32(name), X)Количество шардов стало больше, новые данные с каким-то ключом распределения теперь могут попадать на новый шард (X в формуле поменялся!). А для поддержки локальности расчетов это недопустимо. Вывод один — переливаем данные с использованием временных таблиц.
Но и тут оказалось много подводных камней. Не будем затягивать — вот как мы действовали:
Получаем список команд на создание таблиц, которые должны быть решардированы:
with
trim(TRAILING '_' from trim(TRAILING 'distributed' from name))
as table_name
select concat('show create ', database, '.', table_name ,';') from system.tables
where engine = 'Distributed';Запускаем по очереди отобранные команды, берем скрипт на создание таблицы и редактируем его. Добавляем в наименование постфикс ‘_tmp’, после наименования таблицы прописываем опцию ‘on cluster’, а также редактируем путь для Zookeeper: точно так же добавляем постфикс _tmp к имени таблицы . Вот что у нас получается:
create table db.users_tmp on cluster 'main'(
uid Int16,
name String,
age Int16
)
ENGINE =ReplicatedMergeTree('/clickhouse/tables/{shard}/users_tmp', '{replica}')
ORDER BY (uid);Создаем временные таблицы для решардинга данных.
Поверх делаем распределенную таблицу:
create table db.users_tmp_distr on cluster 'main' as db.users_tmp;
ENGINE = Distributed('main', 'db', users_tmp, murmurHash3_32(name))-
Теперь с каждого шарда нужно запустить вставку в распределенную таблицу. Чтобы ускорить этот процесс, мы фильтровали данные и заливали их сразу в нужный шард. Для этого мы отбираем остаток от деления нашего поля, по которому происходит шардирование, на количество всех шардов в кластере. Остаток должен быть равен номеру шарда за вычетом единицы. Т. е. на первый шард остаток 0, на второй шард равен 1, на третий 2 и т. д. В конце запроса прописываем настройку, которая пишет данные на указанный нами шард.
Пример запуска загрузки данных, которые должны оказаться на первом шарде (подобную команду с изменением условия where выполняем на всех узлах):
insert into db.users_tmp_distr
select * from remote('clickhouse01', 'db.users')
where mod(murmurHash3_32(name), X) = 0 – X -новое количество шардов
settings insert_shard_id = 1;
insert into db.users_tmp_distr
select * from remote('clickhouse02', 'db.users')
where mod(murmurHash3_32(name), X) = 0 – X -новое количество шардов
settings insert_shard_id = 2;Так мы проходим по всем новым узлам, меняя параметры, чтобы перелить все данные в новую таблицу. Если было 2 узла, а стало 3, то получается, что нам нужно выполнить 6 команд insert.
Проверяем, что все данные на своих шардах:
select distinct shardNum(),
mod(murmurHash3_32(name),3)
from db.users_tmp_distr;
1 0
2 1
3 2
В запросе не должен повториться ни один шард — это означает, что все данные распределены корректно.
Меняем таблицы местами и удаляем временные таблицы:
exchange tables db.users and db.users_tmp on cluster 'main';
drop table db.users_tmp on cluster 'main' sync;
drop table db.users_tmp_distr on cluster 'main' sync;
_____________________
Итак, в этом материале мы рассказали про разные кластеры в ClickHouse:
all-sharded — максимально быстрая обработка без репликации, временные данные;
all-replicated — нет передачи по сети, ключ распределения не важен, справочники;
main — шарды и репликация, баланс между доступностью и производительностью, основная масса таблиц.
Грамотное проектирование распределения данных — залог успеха! Позднее вы сможете использовать локальные заливки и расчеты, что значительно их ускорит. Мы сократили время перегрузки почти в 6 раз по сравнению с нашими первыми экспериментами. Кроме того, научились эффективно перераспределять данные в случае добавления новых узлов.
Далее планируем рассказать, как мы боролись с нехваткой памяти, тюнингом запросов и самого кластера и, самое классное, — как мы запилили бэкап распределенной СУБД.
Комментарии (2)

Roman2dot0
07.09.2023 02:24Для быстрой переливки данных из distributed в distributed есть parallel_distributed_insert_select.
mentin
Познавательно, спасибо. Но ещё больше стал ценить системы нацеленные на пользователя, а не разработчика, где подобные выборы за вас делает система. Вроде BigQuery, где всё на что можно повлиять это указать PARTITION BY и CLUSTER BY , за остальной оптимизацией и корректностью следит система.