Задержка и пропускная способность
При обсуждении производительности часто встречаются термины «задержка» (latency) и «пропускная способность» (throughput) для описания характеристик программного компонента.
Мы можем дать следующее толкование этим терминам:
Задержка — это мера времени, затрачиваемого на выполнение одного действия. Например, это может быть время, необходимое, чтобы отреагировать на изменение цены финансового инструмента, и такое изменение может повлиять на решение о покупке или продаже. Это может быть время, необходимое компоненту, управляющему каким-либо внешним устройством, чтобы отреагировать на изменение состояния этого устройства (например, изменение температуры, о котором сообщает термостат).
Можно применить понятие задержки и к областям, не связанным с IT. Представьте, что вы посещаете свой любимый фаст-фуд. В данном случае, задержка — это время, которое требуется для того, чтобы сделать заказ, собрать его, оплатить и затем получить. Очевидно, что чем меньше задержка — тем лучше.
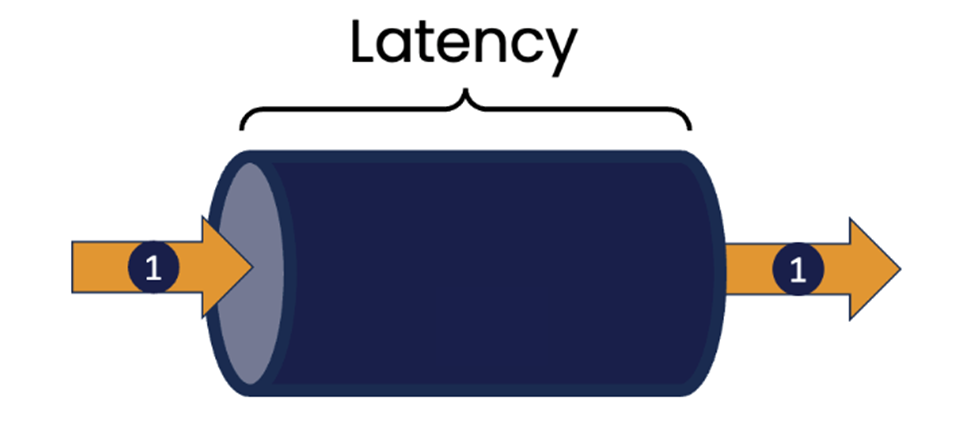
Пропускная способность — это показатель, означающий, сколько работы может быть выполнено за определенный промежуток времени, например, сколько транзакций можно обработать за секунду. Все мы видели примеры систем, которые с трудом справляются с высокой нагрузкой на запросы, например веб-сайты, которые перестают реагировать на запросы в определенное время, когда количество запросов внезапно возрастает, например в начале или конце рабочего дня или при выпуске билетов на очень популярный концерт.
В контексте ресторана быстрого питания пропускная способность позволяет измерить количество клиентов, обслуженных за определенный период времени, и очевидно, что чем больше клиентов — тем лучше.

Обычно для увеличения пропускной способности компонента предлагается хорошо распараллелить систему, чтобы одновременно обрабатывать более одной задачи. Это можно сделать внутри экземпляра компонента, введя несколько потоков выполнения, каждый из которых может обрабатывать один запрос.
Можно утверждать, что во время обработки одной задачи, скорее всего, будет несколько «пауз», потому что текущая задача ждет, пока что-то произойдет (возможно, операция чтения или записи данных или взаимодействие данного компонента с другим компонентом). Когда один поток по какой-то причине не может выполнить задание, другой может его продолжить.

Мы также можем внедрить несколько инстансов компонента в кластере различных систем — это один из подходов, который часто используется для обоснования использования облачной архитектуры приложений.
Современная облачная инфраструктура позволяет динамически создавать новые инстансы компонентов на разных системных платформах, когда этого требует рост нагрузки, и отключать эти экземпляры, когда пик нагрузки миновал, чтобы минимизировать дополнительные издержки.
Общий термин для именования такого подхода — «масштабирование», или «горизонтальное масштабирование».
Масштабирование кажется привлекательным методом, позволяющим увеличить пропускную способность системы. Однако за преимущества, которые дает масштабирование, приходится платить, и это важно понимать. Основной подход заключается в следующем: сделать так, чтобы несколько независимых инстансов компонента выглядели со стороны так, как будто он существует только в одном экземпляре. Такой подход иногда называют «односистемным». Хотя такое решение может показаться привлекательным, создание такой абстракции и управление ею вносит сложность, которая может серьёзно замедлить выполнение отдельных задач.
1. Необходимо предусмотреть возможность маршрутизации для распределения задач между доступными инстансами компонента. Она может быть неявной при применении одного инстанса с несколькими потоками или явной при использовании кластерного подхода. При неявном подходе используется некоторая форма общей рабочей очереди для сбора входящих запросов, и по мере освобождения экземпляров, работающих в потоках, они забирают первый из них из очереди.
При кластерном подходе явно реализованный компонент- маршрутизатор решает, к какому инстансу следует направить запрос. Решение принимается в соответствии с некоторым алгоритмом; простейший такой алгоритм просто перебирает доступные инстансы (иногда это подход называется «карусель», но возможны и другие варианты. Например, маршрутизация к инстансу, который, определенно, способен обработать запрос быстрее всего, или всегда направлять запросы из одного источника к одному и тому же инстансу.
Все эти варианты сопряжены со своими сложностями, которые необходимо учитывать. Доступ к общей рабочей очереди должен быть синхронизирован, что приводит к потенциальному увеличению задержки при выполнении запроса. Хотя отдельный компонент маршрутизатора позволяет настраивать решения о том, какой инстанс должен получить запрос, это само по себе влияет на задержку, не говоря уже о введении дополнительного сетевого перехода перед доставкой сообщения.
2. Вполне вероятно, что возникнет потребность разделять состояние между экземплярами. Результат обработки запроса может зависеть от данных, которые хранятся в компоненте и значение которых накапливается определенным образом с течением времени. Примером может служить корзина для покупок, где запросы включают добавление или удаление товаров перед оформлением заказа.
В одном инстансе это общее состояние будет храниться в памяти, которую смогут видеть все потоки, выполняющие отдельные экземпляры компонентов. Однако доступ к этой общей памяти требует синхронизации для обеспечения согласованности данных.
При кластерном подходе есть разные способы решения этой проблемы. Состояние, относящееся к одному клиенту, может храниться в определенном экземпляре, но теперь все запросы, требующие доступа к общей информации, должны направляться к этому экземпляру. Это суть модели «сеансов» HTTP, и для ее реализации требуется обработка на уровне маршрутизатора.
В качестве альтернативы можно использовать отдельный компонент базы данных для хранения такой информации, которая требуются нескольким инстансу. Тогда любой инстанс сможет обработать конкретный запрос, но ценой увеличения издержек на чтение и запись этих данных из базы данных при обработке запроса. В крайнем случае, база данных может стать точкой конкуренции между инстансами, что еще больше замедлит обработку запросов. Если мы используем современную распределенную базу данных, то можем столкнуться с проблемами согласованности данных (между инстансами базы данных).
Все это вносит дополнительные сложности в цикл обработки запросов.

Во многих случаях можно повысить пропускную способность компонента, не прибегая к масштабированию. Этот подход основан на простом наблюдении. Если мы можем сократить время обработки одного запроса, то в итоге мы сможем обработать больше запросов за заданный промежуток времени.
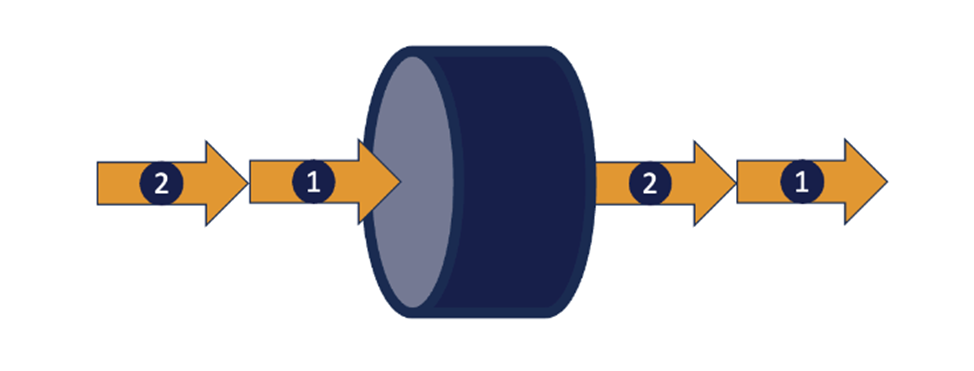
Программное обеспечение на Java с низкой задержкой, например, Chronicle Software, создается с использованием универсальных рекомендаций, которые помогают минимизировать, а в идеале и устранить паузы, часто влияющие на обычное выполнение Java.
Наиболее очевидными из них являются паузы, возникающие при полной остановке сборки мусора по принципу «stop the world». Уже проведено немало исследований, направленных на минимизацию пауз такого типа, и они увенчались значительным успехом. Однако они все еще могут возникать недетерминированно. Методы Java с низкой задержкой направлены на полное устранение пауз путем уменьшения количества объектов в куче Java до уровня ниже порогового для даже незначительных сборок мусора. Более подробно данная тема разобрана в этой статье.
Пожалуй, самым существенным недостатком внедрения нескольких потоков в Java-компонент является блокировка синхронизации доступа к разделяемым ресурсам, в частности к общей памяти. Блокировки различных типов позволяют защитить изменяемое состояние от одновременного доступа, который может привести к повреждению, но большинство из них основано на идее, что если блокировка не может быть получена, то запрашивающий поток должен блокировать доступ к ресурсу до тех пор, пока он не станет доступен.
В настоящее время появление многоядерных процессорных архитектур позволяет потоку «крутиться», неоднократно пытаясь получить блокировку, без контекстного переключения с ядра, как это происходит при блокирующей синхронизации. Как ни странно, синхронизация таким неблокирующим способом заметно быстрее традиционного подхода, поскольку аппаратные кэши, специфичные для ядра, не нужно промывать и перезагружать после переключения контекста.
Однако на выходе эффект от этих подходов заключается в устранении большей части дополнительных сложностей, возникающих при горизонтальном масштабировании.
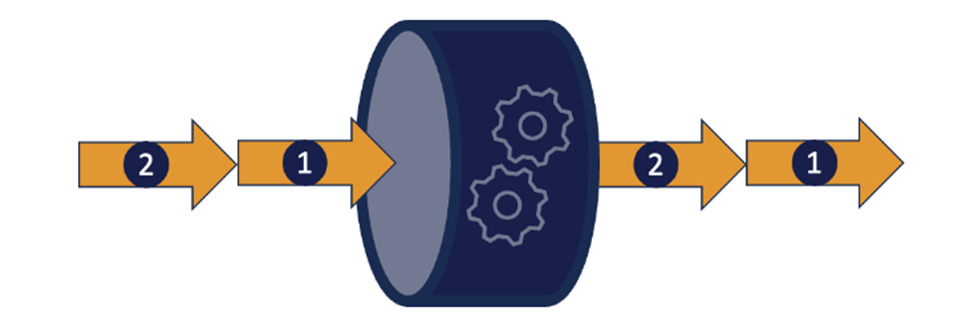
Методы программирования с минимизацией задержек предназначены для того, чтобы ядро процессора было максимально загружено, работало на пределе своих возможностей и выполняло работу как можно быстрее. Это позволяет оптимизировать пропускную способность компонентов.
В Chronicle мы создали набор продуктов и библиотек, которые реализуют эти идеи и используются в финансовых учреждениях по всему миру. Например, Chronicle Queue — это Java-библиотека с открытым исходным кодом, которая поддерживает очень высокоскоростные межпроцессные коммуникации на основе общей памяти. Chronicle Queue поддерживает пропускную способность в миллионы сообщений в секунду с задержкой в пределах микросекунды.
При обсуждении производительности часто встречаются термины «задержка» (latency) и «пропускная способность» (throughput) для описания характеристик программного компонента.
Мы можем дать следующее толкование этим терминам:
Задержка — это мера времени, затрачиваемого на выполнение одного действия. Например, это может быть время, необходимое, чтобы отреагировать на изменение цены финансового инструмента, и такое изменение может повлиять на решение о покупке или продаже. Это может быть время, необходимое компоненту, управляющему каким-либо внешним устройством, чтобы отреагировать на изменение состояния этого устройства (например, изменение температуры, о котором сообщает термостат).
Можно применить понятие задержки и к областям, не связанным с IT. Представьте, что вы посещаете свой любимый фаст-фуд. В данном случае, задержка — это время, которое требуется для того, чтобы сделать заказ, собрать его, оплатить и затем получить. Очевидно, что чем меньше задержка — тем лучше.
Пропускная способность — это показатель, означающий, сколько работы может быть выполнено за определенный промежуток времени, например, сколько транзакций можно обработать за секунду. Все мы видели примеры систем, которые с трудом справляются с высокой нагрузкой на запросы, например веб-сайты, которые перестают реагировать на запросы в определенное время, когда количество запросов внезапно возрастает, например в начале или конце рабочего дня или при выпуске билетов на очень популярный концерт.
В контексте ресторана быстрого питания пропускная способность позволяет измерить количество клиентов, обслуженных за определенный период времени, и очевидно, что чем больше клиентов — тем лучше.
Масштабирование для улучшения пропускной способности
Обычно для увеличения пропускной способности компонента предлагается хорошо распараллелить систему, чтобы одновременно обрабатывать более одной задачи. Это можно сделать внутри экземпляра компонента, введя несколько потоков выполнения, каждый из которых может обрабатывать один запрос.
Можно утверждать, что во время обработки одной задачи, скорее всего, будет несколько «пауз», потому что текущая задача ждет, пока что-то произойдет (возможно, операция чтения или записи данных или взаимодействие данного компонента с другим компонентом). Когда один поток по какой-то причине не может выполнить задание, другой может его продолжить.
Мы также можем внедрить несколько инстансов компонента в кластере различных систем — это один из подходов, который часто используется для обоснования использования облачной архитектуры приложений.
Современная облачная инфраструктура позволяет динамически создавать новые инстансы компонентов на разных системных платформах, когда этого требует рост нагрузки, и отключать эти экземпляры, когда пик нагрузки миновал, чтобы минимизировать дополнительные издержки.
Общий термин для именования такого подхода — «масштабирование», или «горизонтальное масштабирование».
Проблемы с масштабированием
Масштабирование кажется привлекательным методом, позволяющим увеличить пропускную способность системы. Однако за преимущества, которые дает масштабирование, приходится платить, и это важно понимать. Основной подход заключается в следующем: сделать так, чтобы несколько независимых инстансов компонента выглядели со стороны так, как будто он существует только в одном экземпляре. Такой подход иногда называют «односистемным». Хотя такое решение может показаться привлекательным, создание такой абстракции и управление ею вносит сложность, которая может серьёзно замедлить выполнение отдельных задач.
1. Необходимо предусмотреть возможность маршрутизации для распределения задач между доступными инстансами компонента. Она может быть неявной при применении одного инстанса с несколькими потоками или явной при использовании кластерного подхода. При неявном подходе используется некоторая форма общей рабочей очереди для сбора входящих запросов, и по мере освобождения экземпляров, работающих в потоках, они забирают первый из них из очереди.
При кластерном подходе явно реализованный компонент- маршрутизатор решает, к какому инстансу следует направить запрос. Решение принимается в соответствии с некоторым алгоритмом; простейший такой алгоритм просто перебирает доступные инстансы (иногда это подход называется «карусель», но возможны и другие варианты. Например, маршрутизация к инстансу, который, определенно, способен обработать запрос быстрее всего, или всегда направлять запросы из одного источника к одному и тому же инстансу.
Все эти варианты сопряжены со своими сложностями, которые необходимо учитывать. Доступ к общей рабочей очереди должен быть синхронизирован, что приводит к потенциальному увеличению задержки при выполнении запроса. Хотя отдельный компонент маршрутизатора позволяет настраивать решения о том, какой инстанс должен получить запрос, это само по себе влияет на задержку, не говоря уже о введении дополнительного сетевого перехода перед доставкой сообщения.
2. Вполне вероятно, что возникнет потребность разделять состояние между экземплярами. Результат обработки запроса может зависеть от данных, которые хранятся в компоненте и значение которых накапливается определенным образом с течением времени. Примером может служить корзина для покупок, где запросы включают добавление или удаление товаров перед оформлением заказа.
В одном инстансе это общее состояние будет храниться в памяти, которую смогут видеть все потоки, выполняющие отдельные экземпляры компонентов. Однако доступ к этой общей памяти требует синхронизации для обеспечения согласованности данных.
При кластерном подходе есть разные способы решения этой проблемы. Состояние, относящееся к одному клиенту, может храниться в определенном экземпляре, но теперь все запросы, требующие доступа к общей информации, должны направляться к этому экземпляру. Это суть модели «сеансов» HTTP, и для ее реализации требуется обработка на уровне маршрутизатора.
В качестве альтернативы можно использовать отдельный компонент базы данных для хранения такой информации, которая требуются нескольким инстансу. Тогда любой инстанс сможет обработать конкретный запрос, но ценой увеличения издержек на чтение и запись этих данных из базы данных при обработке запроса. В крайнем случае, база данных может стать точкой конкуренции между инстансами, что еще больше замедлит обработку запросов. Если мы используем современную распределенную базу данных, то можем столкнуться с проблемами согласованности данных (между инстансами базы данных).
Все это вносит дополнительные сложности в цикл обработки запросов.
Увеличение пропускной способности за счет уменьшения задержки
Во многих случаях можно повысить пропускную способность компонента, не прибегая к масштабированию. Этот подход основан на простом наблюдении. Если мы можем сократить время обработки одного запроса, то в итоге мы сможем обработать больше запросов за заданный промежуток времени.
Программное обеспечение на Java с низкой задержкой, например, Chronicle Software, создается с использованием универсальных рекомендаций, которые помогают минимизировать, а в идеале и устранить паузы, часто влияющие на обычное выполнение Java.
Наиболее очевидными из них являются паузы, возникающие при полной остановке сборки мусора по принципу «stop the world». Уже проведено немало исследований, направленных на минимизацию пауз такого типа, и они увенчались значительным успехом. Однако они все еще могут возникать недетерминированно. Методы Java с низкой задержкой направлены на полное устранение пауз путем уменьшения количества объектов в куче Java до уровня ниже порогового для даже незначительных сборок мусора. Более подробно данная тема разобрана в этой статье.
Пожалуй, самым существенным недостатком внедрения нескольких потоков в Java-компонент является блокировка синхронизации доступа к разделяемым ресурсам, в частности к общей памяти. Блокировки различных типов позволяют защитить изменяемое состояние от одновременного доступа, который может привести к повреждению, но большинство из них основано на идее, что если блокировка не может быть получена, то запрашивающий поток должен блокировать доступ к ресурсу до тех пор, пока он не станет доступен.
В настоящее время появление многоядерных процессорных архитектур позволяет потоку «крутиться», неоднократно пытаясь получить блокировку, без контекстного переключения с ядра, как это происходит при блокирующей синхронизации. Как ни странно, синхронизация таким неблокирующим способом заметно быстрее традиционного подхода, поскольку аппаратные кэши, специфичные для ядра, не нужно промывать и перезагружать после переключения контекста.
Однако на выходе эффект от этих подходов заключается в устранении большей части дополнительных сложностей, возникающих при горизонтальном масштабировании.
Заключение
Методы программирования с минимизацией задержек предназначены для того, чтобы ядро процессора было максимально загружено, работало на пределе своих возможностей и выполняло работу как можно быстрее. Это позволяет оптимизировать пропускную способность компонентов.
В Chronicle мы создали набор продуктов и библиотек, которые реализуют эти идеи и используются в финансовых учреждениях по всему миру. Например, Chronicle Queue — это Java-библиотека с открытым исходным кодом, которая поддерживает очень высокоскоростные межпроцессные коммуникации на основе общей памяти. Chronicle Queue поддерживает пропускную способность в миллионы сообщений в секунду с задержкой в пределах микросекунды.