Бывают ситуации, когда жизненные обстоятельства не позволяют использовать ChatGPT и приходится разворачивать LLM локально. Например бабушка не разрешает. Так можно остаться и без AI, а этого мужики точно не поймут. Есть ли какие-то способы решения этой проблемы?
Если у вас такая ситуация – можете выдохнуть, решение есть. На данный момент существуют следующие варианты:
1. Проприетарные модели:
a. Anthropic – в настоящее время сравним или превосходит по качеству ChatGPT 4.0 на некоторых задачах и обладает большим контекстным окном, давая возможность решать многие задачи, не прибегая к RAG и другим гибридным методам
b. Yandex GPT – хорошо функционирует на русском языке, поэтому если ваша бабушка еще и майор – она точно оценит этот вариант
c. GigaChat – модель от Сбера, так же хорошо работает на русском и смотри пункт выше
2. Открытые модели:
LLama 2 – оригинальная открытая модель от известной террористической организации, на базе которой уже нагородили over 100500 разных моделей, за что этой организации большое спасибо (до сих пор никто не понимает, что подвигло Марка на данное решение). По качеству не дотягивает до ChatGPT 4.
ruGPT – претрейн от GigaChat под лицензией MIT, Сбер приложил руку и тут, спасибо им. Можно использовать
Mistral – модель, разработанная выходцами из Гугла во Франции. Качество не дотягивает до ChatGPT 4, но в среднем лучше, чем Llama 2.
Falcon – модель разработана на арабские деньги европейцами. В целом, послабее Llama 2, и смысл ее использования от меня ускользает.
Grok от X – предположительно “based” модель от самого Илона. Работает пока так себе, плюс-минус на уровне ChatGPT 3.5, но Илон обещает порвать всех на тряпки и есть причины ему верить.
Оценки моделей на текущий момент выглядят примерно так (можно поглядеть тут):
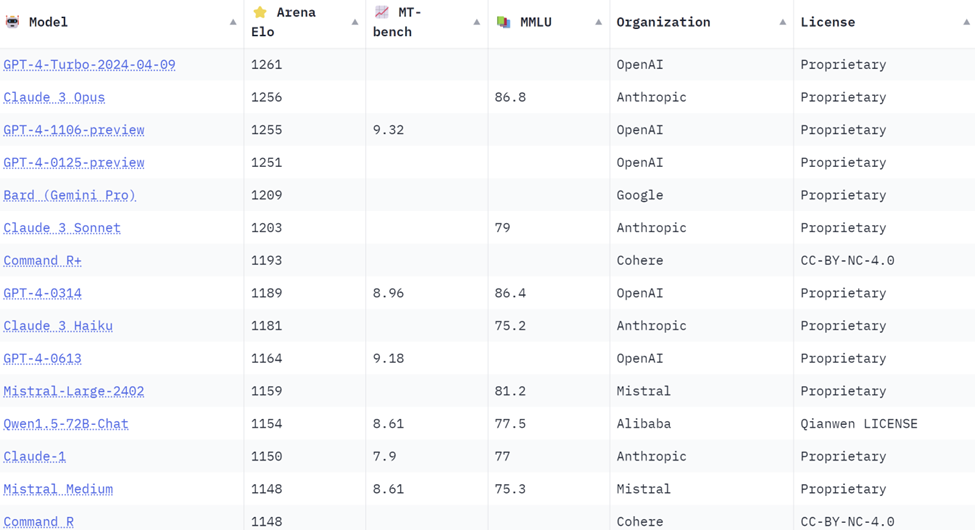
Наш опыт использования подтверждает, что модели от OpenAI и Anthropic превосходят остальные, и Anthropic даже немного выигрывает.
OnPrem
Что делать, если пользоваться облачными решениями невозможно (бабушка боится, что мошенники узнают, где спрятана заначка с пенсией). Тут два варианта:
развернуть у себя локально
Для этого потребуются видеокарты уровня NVidia A100, каждая стоит в районе $16тыс.
Сколько их нужно, зависит от того, что вы будете делать. На обучение модели с нуля может потребоваться тысячи часов и соответственно большое количество видеокарт (и соответственно от десятков тысяч до миллионов долларов). Falcon 7B, например, была натренирована с помощью 400 A100s в течении двух недель. 7B Карл!
Для использования модели (инференс) – зависит от использования и количества одновременно подключенных пользователей. Допустим, вы хотите сделать чат-бот, который будет обслуживать 100 пользователей. Консервативно, количество графических процессоров, которое понадобится для размещения модели LLAMA 2 70B для 100 пользователей, зависит от объема памяти GPU. Точные требования к памяти зависят от спецификации модели, но один NVIDIA A100 с 80 ГБ VRAM может обслуживать пару экземпляров модели.
Для 100 одновременных пользователей нужно учитывать, что не все пользователи потребуют мгновенного ответа в одно и то же время, но система должна быть достаточно надежной для обработки высоких нагрузок.
Предположим, что один NVIDIA A100 80 ГБ может удобно запускать 2 экземпляра модели. Каждый экземпляр должен быть способен обслуживать несколько пользователей, в зависимости от того, как структурирован чат-бот и как управляются запросы пользователей.
Допустим, что один GPU может обслуживать до 25 одновременных пользователей (учитывая время ожидания и обработку). Таким образом, для 100 одновременных пользователей потребуется 4х GPU. Стоимость видеокарт будет примерно $65тыс, не считая стоимости серверов, $75-90 тыс вместе со стоимостью сервера.
развернуть в дата-центре
Для примера возьмём Selectel. Один час работы сервера с конфигурацией, описанной выше (4хA100), обойдется примерно в 1200р в час. Неслабо, однако имеет смысл, если вы не собираетесь очень активно его использовать.
Оба сценария применимы в определенных ситуациях, тут нужно оценивать, что вы хотите получить на выходе.
Видеокарт нет, но вы держитесь (aka квантизация)
Если бабушка утверждает, что денег нет (а заначку вы еще не нашли), можно ли как-то сократить расходы? Да, можно использовать квантизацию. Это техника оптимизации, которая позволяет уменьшить объем памяти, необходимый для хранения и выполнения модели, и ускорить её вычисления, обычно с небольшим ухудшением качества. Это достигается за счёт уменьшения количества бит, которые используются для представления чисел в весах модели. Квантизация чаще всего включает в себя уменьшение точности данных от 32-битных чисел с плавающей запятой до 16-битных или 8-битных целых чисел. Как правило, качество падает не значительно, но нужно смотреть на ваших конкретных задачах. Это может снизить требования к железу в 2-4 раза, но нужно экспериментировать.
Это на самом деле очень большая тема и трудно описать все ньюансы в рамках одной статьи.
Ира, наш эксперт в этой области, скоро проводит вебинар по данной теме (совершенно бесплатно). Если интересно погрузиться в эту тему и задать вопросы эксперту – вот ссылка для регистрации.
Всем добра!
Комментарии (30)


MountainGoat
18.04.2024 05:38БРЕД, чушь и неправда всё сверху донизу. Всё это делается не так, с другими названиями и гораздо меньшими требованиями. Не могу даже написать, что именно неправильно, а то придётся процитировать 100% текста.
MountainGoat
18.04.2024 05:38+6Блин, пол-часа искал статью на русском, чтобы приложить ссылку - ничего не нашёл, кроме своих заметок.
Поэтому вот Roadmap.
Требования: видеокарта Nvidia c памятью от 12Гб ИЛИ аналогичная видеокарта AMD + Linux (есть ROCm - имитация CUDA на AMD) ИЛИ очень жирный процессор.
Софт: разделяется на AI-движок, где живёт матан, и интерфейс пользователя. Причём они могут быть на разных компах. Протокол де-факто стандартизировался на "косить под OpenAI". Движок: KoboldCPP или LMStudio, первый даёт доступ к важным настройкам через командную строку и имеет функциональный интерфейс пользователя, второй позволяет много кликать мышью с умным видом. Под капотом одно и то же. Интерфейс: У KoboldCPP свой неплохой. Для VSCode расширение Continue. Есть ещё SillyTaven но он не для программирования.
Модель: mixtral-8x7b-instruct-v0.1.Q5_K_M.gguf Все буквы важны, ± одна буква - уже будет существующее не то.
Если обычно в мелочах кроется дьявол, то здесь чертей будет на целый акт из Diablo. Потому что всё развивается каждый день и каких-то стандартов ещё особо не устоялось.
Мои настройки под Mixtral под 24Гб VRAM : `--model .\filename.gguf --usecublas --gpulayers 23 --contextsize 16384` Gpulayers надо подбирать от размера VRAM, но обычно работает размер VRAM в Гб - 1

StarKap
18.04.2024 05:38вопрос к производительности такого функционала, автор написал для всех возрастов и всех кошельков, а вы предлагаете квантованную модель от которой ответа будете ждать в n раз дольше, да и с качеством Бог знает что будет, в сравнении с фулл моделькой развёрнутой на 2-ух А100 ИЛИ квантованной до 8bit и развёрнутой на одной А100
Если ваше субъективное мнение, что это БРЕД, расскажите как бы в проде это работало, чтобы и на запросы отвечало быстро и по качеству не проседало до gpt-2?
Пока вижу, что для развлечения удалось запустить на домашней машинке mixtral-8x7b-instruct-v0.1.Q5_K_M.gguf и сказать, что для любой задачи это панацея...MountainGoat
18.04.2024 05:38A100 нынче почём? 1 200 000 рублей?
для всех возрастов и всех кошельков
Арендовать за 1200 рублей в час? 1200*8*22(рабочих дня) = 211000 в месяц?
Или запускать только "когда нужен" - как на практике будет выглядеть этот процесс, особенно учитывая, что такой инстанс будет минут 15 в себя приходить? Программистам оставлять заявки в бухгалтерии в пятницу на получение подсказки от ИИ на следующей неделе?
По тестам, квантизация до 4 бит - на 10-15% хуже оригинала. Например. По личным ощущениям, квантизация до 2 бит и то сочиняет код не хуже M$ Coplilot которым я сейчас пользуюсь потому, что он умеет гуглить, и видяха у меня одна.
А ещё, я не могу придумать пример стуации, когда ChatGPT использовать нельзя, а SberGPT можно. Частная компания может и ChatGPT найти как оплатить, а в компании, где есть хоть немного ДСП, и на инстанс на Selectel код нельзя заливать будет.
Вот поэтому и БРЕД. Бред - слушать музыку в 32бит, смотреть фото в TIFF и использовать 16битные LLM. Эти форматы для разработчиков, а не пользователей.

janvarev
18.04.2024 05:38Насчет 1200 р/час - конечно, смешно загнули в статье. Можно найти под за рублей 50 в час на 24 Гб VRAM, и туда нормально поставить квантованную модель.
Насчет настроек - спасибо, прочитал, все толково, у меня стоит похоже. Еще отмечу, что в принципе можно взять какую-нибудь 7B модель и засунуть её в VRAM 8GB (q5 точно) - т.е. на картах недорогого уровня.
А, еще - для koboldcpp обязательно рекомендую ставить CLBlast, который процессит ввод на GPU. Потому что иногда процессинг входа на CPU может занимать несколько десятков секунд и быть по длительности сравнимым с собственно генерацией.
я не могу придумать пример стуации, когда ChatGPT использовать нельзя, а SberGPT
Я могу - нужны юридические ГАРАНТИИ, что данные не просачиваются за пределы страны. Для крупных фирм, в общем.
MountainGoat
18.04.2024 05:38Никогда не видел таких юридических требований. Либо пофиг, либо чтобы информация не выходила за пределы территории компании. Видел, как люди обсуждали сертифицированные ФСБ VPS и решили, что ну его нафиг, формально ими всё равно нельзя пользоваться. И у них не гостайна, а просто ДСП.
MountainGoat
18.04.2024 05:38Стоп! Я попутал с Invoke. KoboldCPP на видяхах AMD и Intel работает на винде и без проблем, только медленнее.

BelerafonL
18.04.2024 05:38+2Было бы неплохо увидеть конкретные рецепты (или ссылки на них) - откуда скачать, в каком облаке что купить, как загрузить, как запустить, как сделать автокомплит кода на основе этой штуки в VScode или подобное.
MountainGoat
18.04.2024 05:38+2Обнаглею и укажу свои заметки: раз, два
Ещё есть LMStudio, типа всё делает за вас: качает модель, подбирает конфиг. Но он мне не нравится тем, что все важные настройки разбросаны чёрти где, поэтому он у пользователя часто работает в неоптимальном виде.

kroketmonster
18.04.2024 05:38Я бы еще мог посоветовать Faraday.dev, это наверное самая простая софтина для работы с локальными моделями, но она больше для чатботов-персонажей.


Araki_Satoshi
18.04.2024 05:38+3Если нужно локально и лично для себя, то выбираешь самую крупную по параметрам GGUF модель, которая влезет в видеопамять при оффлоадинге всех слоев, вплоть до Q3_K_M, и пользуешься запуская её как API через llama.cpp server или koboldcpp, подключаясь через любой фронтенд.
janvarev
18.04.2024 05:38+1Еще: для koboldcpp обязательно рекомендую ставить CLBlast, который процессит ввод на GPU. Потому что иногда процессинг входа на CPU может занимать несколько десятков секунд и быть по длительности сравнимым с собственно генерацией.

ainu
18.04.2024 05:38То же самое делает ML studio, можно даже указать, какой процент видеопамяти мы готовы дать.
Araki_Satoshi
18.04.2024 05:38Всё так, поэтому мы и оффлоадим все слои в видеопамять. В таком случае препроцессинг токенов вместе с CLBlast / cuBLAS будет в разы быстрее чем если бы это был только CLBlast / cuBLAS + лишь часть или вообще ноль слоев в оффлоаде, делая кванты моделей вполне юзабельными по скорости на домашних ПК. С 7B ещё не так заметно, а вот на 13B уже ощутимо. На 34B+ - уже критично.
MountainGoat
18.04.2024 05:38+2Всё, как всегда, сложно: для формата GGUF, если все слои загружены на VRAM, то туда же должен быть загружен и контекст, а контекст 16к сам весит 9Гб. Если последние 3 слоя не загружать в VRAM, то процентов 90 контекста так же остаётся в RAM, и можно иметь большой контекст или модель побольше взять.

Maxim_Q
18.04.2024 05:38На оффициальном сайте https://www.anthropic.com/ сказано что они сейчас не подключают новых пользователей, этот вариант не подойдет если у вас нет старого аккаунта.

moonroach
18.04.2024 05:38+1Ну так я так понимаю, что чтобы что-то конкретное узнать, надо на вебинар идти, тут по факту ниче особо не описано. Непонятно что делать

dimnsk
18.04.2024 05:38>> Для этого потребуются видеокарты уровня NVidia A100,
вот прям только она ?
Ollama с картой на 16GB за 1K$ не пойдет нет ?
PS llama3 вчера
ainu
Я бы добавил в список command r (а остальные из списка убрал). Ну, и кроме квантизации есть такие штуки, как LM Studio и GGUF, позволяющие держать модель в оперативке, а не видеопамяти. А 96 гигов оперативки несравненно дешевле, чем 96 гигов видеопамяти.
UPD: на картинке рейтинга в посте command r присутствует, и находится выше всех открытых, и даже выше, чем два ChatGPT 4
Squirrelfm Автор
да, как то забыл про самое очевидное
314159abc
Меня в Гугле забанили, поэтому не подскажете, сколько памяти нужно для запуска command-r? До какого размера придется квантовать и насколько это станет хуже mixtral 8x7b? 16GB хватит?
StarKap
https://huggingface.co/CohereForAI/c4ai-command-r-plus +- 210Gb вам понадобится, чтобы запустить полную версию(3xA100). На 2-ух A100, квантованную на 8-bit запускали, есть не большой буст по метрикам в сравнении с mixtral 8x7b, но просадка по времени ответа в 1,5-2 раза.
ainu
На полной версии gguf без квантования (вернее 16 bit, вроде как не квантованная) у меня запустилось на 12 гигабайт видео + 96 обычной ОЗУ, лагало но работало, всё сожралось в пол.
На квантованной влезло в 46 гигабайт:
ainu
По поводу сравнения с mixtral, я запускал, ещё раз, 16бит и Q8_0, и обе работают на голову выше по качеству, чем mixtral/mistral, просто несравненно лучше.
16 гигабайт не хватит, возможно какие то сильно квантованные может и влезут, но надо понимать, что такого рода чудес не бывает, как бы сила модели в количестве и точности связей.
ainu
Вот так выглядело с F16 версией. Примерно 4-6 секунд на один токен уходило.
dubrovinru
Плюсую
Antra
В оперативке, конечно, лучше, чем на диске. От безвыходноси сойдет. Но, ьоюсь, для продуктива слишком медленно будет.
Когда играл с LM Studio жутко тупило на gpu_offload 10 (часть в обычной памяти, часть в видео). При установке в MAX видеопамять стала занята практически полностью (загрузка от этой 13B модели выросла с 10ГБ почти до 20ГБ), а скорость выросла раз в 5.
Так что для себя я предпочту квантизацию, но все в видеопамять запихнуть. Иначе и качество не радует.