Крупный продукт со множеством сервисов и большим количеством задействованных команд — это всегда сложно. Причем, чем больше продукт, тем больше специалистов над ним работают. Следовательно, тем меньше зона ответственности каждого конкретного специалиста. Поэтому, глядя на одну и ту же фичу, разные специалисты могут видеть весьма разные нюансы.
Меня зовут Мочалин Евгений. Я работаю в технической команде фронтенда медицинской компании СберЗдоровье. В этой статье я хочу поделиться историей, как мы выстроили процессы внутри команды, чтобы работа со всеми продуктами компании была прозрачной, стандартизированной и очевидной для всех сотрудников.
Наш контекст
СберЗдоровье — один из самых популярных медицинских сервисов в России. Компания предоставляет услуги на стыке медицины и ИТ. В том числе:
онлайн-консультации с врачами разного профиля, в том числе узких специализаций;
оперативные онлайн-консультации с дежурными терапевтами и педиатрами — связаться с ними можно в течение нескольких минут;
запись в несколько кликов на очный прием к нужному врачу, на диагностические мероприятия, медицинские процедуры и сдачу анализов;
мониторинг пациентов с хроническими заболеваниями для непрерывного контроля их показателей здоровья и оперативного реагирования на любые изменения.
Над развитием всего пула доступных сервисов у нас работает:
более 10 продуктовых команд;
около 30 фронтенд-разработчиков, которые работают с более чем 60 фронтовыми репозиториями.
Такая большая команда дает нам больше возможностей для улучшения собственных сервисов.
Для каждого продукта есть своя кросс-функциональная команда, а для большого продукта их может быть несколько. Такое разделение помогает каждому сотруднику эффективно концентрироваться на своём продукте.
В горизонтальном плане есть деление по специальностям: фронт, бек, анализ и другим. Это позволяет организовывать гильдии и делиться знаниями между командами, а также вырабатывать лучшие практики в использовании технологий и решении задач.
Вместе с тем, в некоторых аспектах это может создавать и ряд трудностей: чем больше продуктов и событий, тем сложнее их отслеживать.
Для наглядности рассмотрим простой пример.
Разбор близкого к реальности примера
Один из наших основных сервисов — сайт, на котором пользователи могут изучить информацию о враче и записаться к нему на прием.
Предположим, продакт-менеджер обнаружил, что на смартфонах с небольшим дисплеем (например, iPhone SE или подобные) на первом экране не умещается кнопка записи на прием. Из этого продакт может предположить: «Пользователи, которые переходят из браузера и сразу видят кнопку, записываются на прием активно, а те, кому кнопка не видна, скорее всего, просто возвращаются в поисковик и переходят по следующей ссылке». На основе этого сценария у продакта появляется гипотеза: «Если на первом экране будет кнопка, то конверсия в заказ вырастет». Продакт молодец, но видит ли он всю картину?.
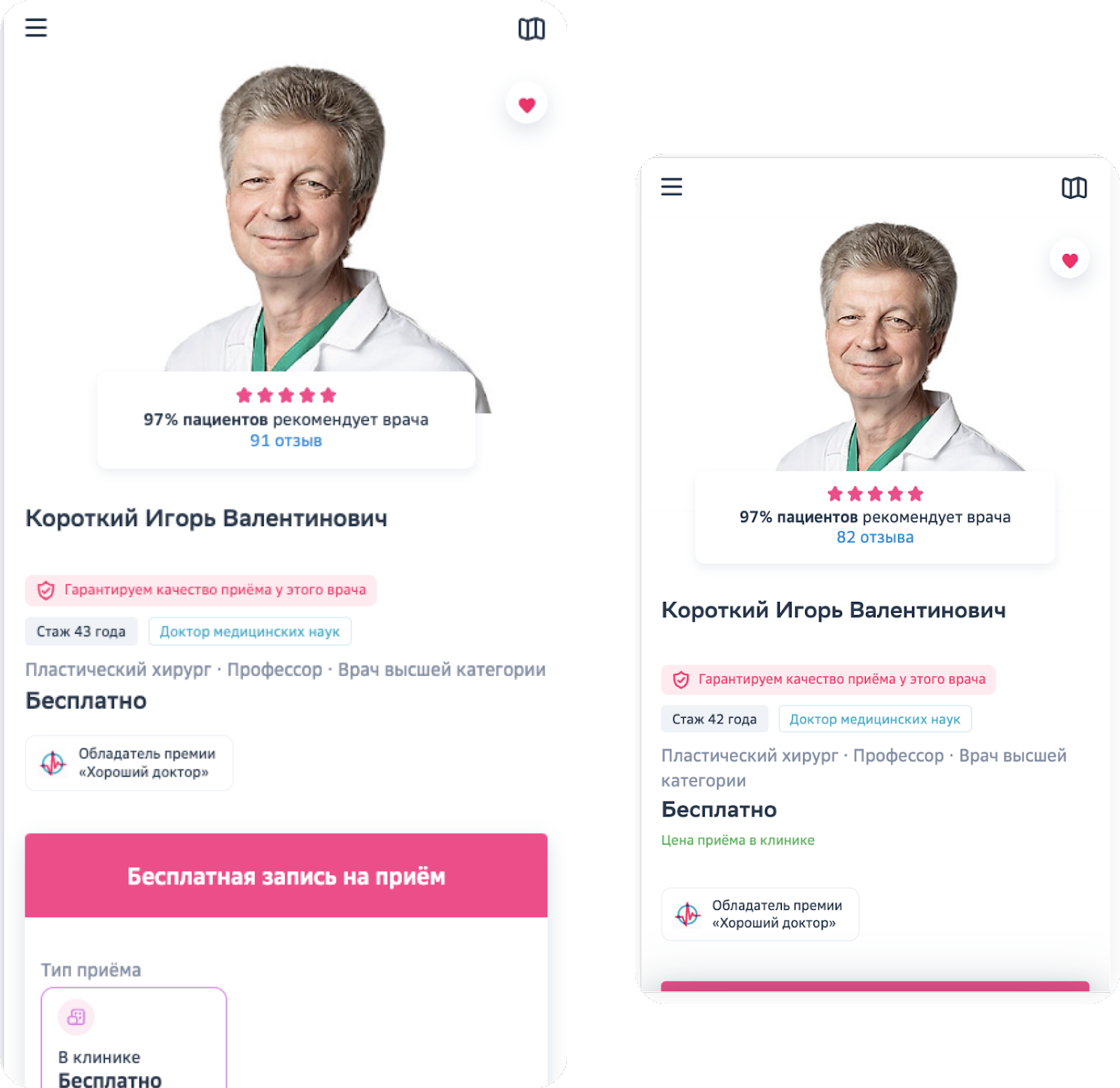
С идеей добавления кнопки продакт идет к дизайнеру. Как один из вариантов решения — добавить большую зеленую кнопку, чтобы пользователю она точно попалась на глаза.
Но что, если пользователь приходит на знакомый ему ресурс, чтобы выбрать врача, почитать комментарии, увидеть стаж, отметки об обучении? Он уже знает, как записаться, и не хочет, чтобы его на всех страницах отвлекала эта большая зелёная кнопка. Из этого следует вторая гипотеза: «Конверсия будет больше, если добавить кнопку в углу, но сделать ее маленькой и серой – так она не будет надоедать». Оба варианта имеют право на жизнь, поэтому рассматриваются на равных.

Так появляются две гипотезы и два макета с разными кнопками. Далее к обсуждению подключается аналитик, который решает, что клики по кнопкам будут отправлять событие ‘click_button’ с атрибутом ‘type: big’ и ‘type: small’.

Затем проджект-менеджер запускает типовую задачу на разработку, в которой описывает, что по клику на кнопку надо отправить событие ‘click-button’.
Разработчик читает доку и добавляет отправку события.
<button
onClick={() => {
window.ym(12345678, 'reachGoal', 'clickButton', {
category: 'request',
type: 'big',
})
}}
>
Записаться
</button>Далее QA проверяет, что всё в порядке: по клику на эту кнопку отправляется событие ‘click’.
После этого запускается недельное A/B-тестирование, чтобы проверить гипотезу и выбрать наиболее удачный вариант.
Предположим, изначально конверсия была 10%, то есть из 100 человек, пришедших на страницу, 10 нажимают на кнопку и записываются на приём. Но после добавления большой зеленой кнопки мы ожидаем, что на неё будут кликать намного чаще и конверсия поднимется — например, до 30% (да, не скромничаем). При этом на маленькую серую сильно не надеемся, так как вероятно она привлекает меньше внимания. Ожидания по кликам не завышаем, даже предполагаем, что конверсия упадет до 7%.

Ждём результатов, формулируем ожидания.
Смотрим на реальные данные и испытываем некоторый шок — событий по нулям.

Почему так? Что случилось? Неужели наша гипотеза не такая классная?
Какие трудности? О чем речь?
Причин подобного поведения может быть несколько:
люди вообще не нажимают (возможно, но маловероятно);
метрики неправильные (более реалистично).
Причем проблемы с метриками — это не всегда именно ошибка. Вполне возможно, что просто каждый специалист, работающий над задачей, смотрел на реализацию по-разному. Например, банально могут отличаться названия событий и метрик:
аналитик использует «click_button»;
проджект при постановке задачи указал «click-button»;
фронтенд-разработчик в коде написал «clickButton».
В итоге все всё сделали правильно, но ничего не работает.
Таким образом, мы выявили два узких места:
единая точка истины — нет единого общедоступного хранилища, где четко описано, как должны называться события и какие у них должны быть атрибуты, чтобы на любой стадии разработки любой заинтересованный мог зайти и проверить, что он правильно понял и запомнил договорённости;
ручной труд — чем больше операций выполняется вручную, тем выше риск человеческого фактора, в том числе банальных опечаток, невнимательности, привычек и баннерной слепоты.
Таким образом, чтобы не допускать проблем, описанных в упомянутом кейсе, нужно бороться с их первопричинами.
Для этого мы решили спроектировать свою систему.
Проектируем систему
При проектировании системы нам нужно было ответить на вопросы по поводу:
формата данных;
системы хранения;
клиентской либы;
кодогенерации;
CI;
CD.
Формат данных
Мы хотим иметь возможность менять используемую систему аналитики, поэтому будем хранить некоторые конфиги, по которым сможем генерировать события для конкретной системы аналитики (yaMetrika, ga, snowplow, …). Именно эти конфиги и будут нашей основной, единой точкой истины.
Писать конфиги можно в любом удобном формате: JSON, YAML, TOML. В нашей реализации мы остановились на YAML. При этом сразу определили, что в событии обязательно должны быть:
description — понятное описание для людей, что это за событие и как планируется его использовать;
id — уникальный идентификатор, который позволяет однозначно идентифицировать событие (в нашем случае это event_category + event_action);
attributes: — атрибуты конкретного события (название, тип, признак необходимости и список возможных вариантов).
description: "Клик на кнопку записи на приём"
definition:
event_category: request
event_action: clickButton
attributes:
type:
description: "Тип кнопки"
options: ["big", "small"]
type: str
required: true
Система хранения
Мы определили, что работаем с YAML-конфигами. Нам важно, чтобы они были доступны для чтения и добавления. Самым простым и очевидным вариантом в нашем случае стал git, ведь в нем из коробки есть все необходимые нам вещи:
хранение и версионирование;
обсуждение изменений в Merge Request и Pull Request;
удобная интеграция CI/CD.
Клиентская либа
На фронтенде мы хотим получить клиентскую либу, которая будет содержать все доступные события, чтобы разработчики могли их использовать без излишней кастомизации. Наиболее очевидный формат для фронта — npm пакет, откуда можно импортировать JS-объекты событий. А ещё лучше использовать typescript. Но у нас есть проекты, в которых фронт на чистом JS — они висят и не особо требуют поддержки. Поэтому наиболее подходящий для нас вариант — иметь в результате билда .js файлы, а рядом d.ts для типизации.
const clickButtonEvent = {
category: 'request',
action: 'clickButton',
attributes: {
type: {
value: 'big',
},
},
}
Кодогенерация
У нас есть конфиги событий в yaml формате, но из них нужно сделать .ts с описанием интерфейсов. Часть с хранением событий и кодогенерацией либ находится в зоне ответственности аналитиков, поэтому наиболее удобно реализовать на Python + Jinja2. Для фронта главное получить typescript, чтобы можно было его сбилдить в .js + d.ts.
export interface IProps {
{%- if attributes.attributes %}
{%- for attribute in attributes.attributes %}
{{attribute.name | to_lower_camel}}
{%- if (attribute.required != true)
or (attribute.options and attribute.options | length == 1)
%}?{%- endif %}:
{%- if attribute.options %}
{%- for option in attribute.options %} '{{option}}'
{%- if not loop.last %} |{% endif %}
{%- endfor %}
{%- elif attribute.type == 'int' %} number
{%- else %} string
{%- endif %},
{%- endfor %}
{%- endif %}
}
...
Стоит отметить, что в данной статье разговор идёт про фронтенд в контексте web и браузеров, но подобным образом можно генерировать код для любого языка, поэтому концепция отлично ложится на либы для iOS и Android.
CI
Чтобы сократить рутину, подключаем CI:
validate — валидируем YAML-конфиги, все зафиксированные договоренности;
generate — генерируем код фронтовой либы из YAML-конфигов;
lint — прогоняем линтеры (тут автогенерация, поэтому подобные проблемы маловероятны, но и ресурсов требуют немного, поэтому пусть будут);
build — собираем из .ts файлов .js и .d.ts;
test — прогоняем необходимые тесты.
stages:
- validate
- generate
- lint
- build
- test
CD (nmp publish)
В части Continuous Delivery нам нужно положить npm пакет во внутренний registry и проставить ему правильную версию по semver.

Такая реализация со всем набором описанных этапов и компонентов дает нам:
Единую точку истины. Есть git репозиторий с YAML-конфигами, из которых генерируется клиентская либа. Поэтому мы можем гарантировать, что во всех проектах используются только эти события и никакие другие.
Сокращение ручного труда. CI убирает 90% рутины, сокращая риск появления ошибок, связанных с человеческим фактором.
Реализация фронтовой либы

Events
Ядро системы — готовые объекты, которые мы можем использовать для отправки стандартизованных событий в разные системы аналитики. В нашем примере с кнопкой есть событие «clickButton». Событие нажатия на кнопку имеет один атрибут «type», и он либо «big» либо «small». Для формирования такого объекта подойдет следующая функция:
interface IProps {
type: 'big' | 'small'
}
export const clickButton = ({ type }: IProps) => ({
category: 'request',
action: 'clickButton',
attributes: {
type: {
value: type,
},
},
})
В данном случае TypeScript сразу при написании кода будет подсказывать, если мы ошиблись в наименовании свойств, или пытаемся использовать невалидные значения.
Adapters
Далее встает вопрос отправки событий. Раньше мы работали с Google Аналитикой и GTM, они нас полностью устраивали. Некоторые проекты работали с Яндекс Метрикой, что тоже нас устраивало. Со временем мы стали ощущать нехватку доступа к сырым данным, потому что оба этих инструмента предоставляют доступ только к данным в агрегированном виде. Чтобы добиться этого, мы переехали на собственное решение на базе Snowplow.
Итого типовой фронтовый проект может работать:
с одной из перечисленных систем;
с несколькими системами аналитики;
быть в состоянии миграции с внешнего решения на внутреннее.
Поэтому нам было важно выделить слой с адаптерами.
Суть адаптера — две функции: init и pushEvent.
init инициализирует адаптер, подгружает скрипт, устанавливает необходимые параметры.
Например, адаптер для Google Antalytics может выглядеть так:
const initGA = (id) => {
!(function (i, s, o, g, r, a, m) { i['GoogleAnalyticsObject'] ...);
window.ga('create', id, 'auto')
window.ga('send', 'pageview')
}
Для Яндекс Метрики так:
const initYaMetrika = (id, enableWebvisor = false) => {
!(function (m, e, t, r, i, k, a) { m[i] = m[i] || function () {...} );
window.ym(id, 'init', {
id,
clickmap: true,
trackLinks: true,
accurateTrackBounce: true,
webvisor: enableWebvisor,
childIframe: true,
});
};
pushEvent отправляет события в выбранную систему аналитики.
Например, для GA:
const pushEvent = (event) => {
window.ga('send', {
hitType: 'event',
eventCategory: event.category,
eventAction: event.action,
...event.attributes,
})
}
Для Яндекс Метрики:
const pushEvent = (id, event) => {
const goalParams = {
event: {
[event.category]: {
[event.action]: {
attributes: JSON.stringify(event.attributes),
},
},
},
}
event.yaGoalNames.forEach((goalName) => {
window.ym(id, 'reachGoal', goalName, goalParams)
})
}
Actions
У нас получились несколько систем аналитик и для каждой из них есть свой адаптер. Теперь полученную конструкцию надо закрепить. Для этого изобретаем некоторые стандартные действия, которые гарантированно есть в каждом адаптере.
Это те самые init и pushEvent (или может быть какие-либо ещё). Назовем их Actions. Суть экшена init — инициализировать все подключенные адаптеры, если их несколько, а pushEvent — отправить события в каждый адаптер, если их несколько.
Выглядеть в упрощенном виде это может так:
const initAllAdapters = (adapters) => {
adapters.forEach((adapter) => {
setTimeout(() => {
adapter.init()
}, 0)
})
}
Таким образом, реализация фронтовой либы закрепляет решения фундаментальных проблем:
Дает единую точку истины — есть npm пакет, где лежат события, которые нужно использовать. Что-то излишне кастомизировать или использовать вне этого пакета лучше не стоит.
Минимизирует ручной труд — события и адаптеры под все необходимые системы уже написаны, их нужно просто импортировать и использовать.
Либа в проекте
В проекте реализованная клиентская либа работает примерно следующим образом.
Установка
Ставим npm пакет любым стандартным способом:
$ npm install @sh/analytics
$ yarn add @sh/analytics
$ bun install @sh/analytics
Инициализация
Нужно собрать набор необходимых адаптеров, при необходимости каждый можно сконфигурировать. Например, для проекта, который находится в процессе миграции с GA на Яндекс Метрику, инициализация может быть такой:
import { init, createYaAdapter, createGAAdapter } from '@sh/analytics'
export const initAnalytics = (yaId: string, gaId: string) => {
init({
adapters: [
createGAAdapter(gaId),
createYaAdapter(yaId, { webVisor: true })
],
})
}
В 90% случаев этого достаточно. В остальных 10% могут потребоваться дополнительные параметры, которые можем передать с объектом опций.
Все это передается в action под названием init, который инициализирует все адаптеры.
При этом когнитивная нагрузка на разработчиков минимальна — реализация написана один раз и стабильно работает без необходимости изучения всего, что «под капотом».
Использование
У нашей кнопки три основные переменные:
цвет: зеленый (green) или серый (gray);
размер: большой (big) или маленький (small);
дизайн: с надписью («Записаться») или знаком вопроса.
import { pushEvent, clickButton } from '@sh/analytics'
export const ProjButton = ({ type }: IProps) => {
const className = type === 'big' ? 'green' : 'gray'
const buttonText = type === 'big' ? 'Записаться' : '?'
const handleClick = () => {
pushEvent(clickButton({ type }))
}
return (
<button className={className} onClick={handleClick}>
{buttonText}
</button>
)
}
Таким образом, с либой в проде мы также получаем искомые:
единую точку истины в виде .js + .d.ts файлов для каждого YAML конфига в репозитории;
минимизацию ручного труда за счет готовых адаптеров, автокомплита, типизации и CI/CD-проекта.
Саммари
Раньше мы нередко сталкивались с эффектами сложного продукта и большой команды: писали много кода, использовали массу маленьких xls-ек, из-за копеечных ошибок в релизах были вынуждены возвращаться и заново проходить весь флоу с привлечением большой команды специалистов.
Внедрение унификации с помощью проектирования системы помогло нам уйти от этих проблем. Так, наша система в работе уже больше двух лет и сейчас у нас:
единая, понятная, общедоступная точка истины (YAML в GIT);
нет очевидных ошибок, в чем помогает type-check во время разработки, а также CI/CD для сокращения рутины, yaml validator, codegen, lint, test;
простая архитектура, открытая для расширений (event, adapter, action);
понятные и известные технологии (js, d.ts, lint, npm).
Примечательно, что у подобной системы нет жесткой привязки к компании: ее можно гибко расширять, изменять и дорабатывать под нужды конкретного продукта. Поэтому, используя выработанные нами паттерны, каждый может попробовать реализовать нечто подобное в своей компании.