
Human: how many legs does a cat have ?
Machine: four, i think .
Human: What do you think about messi ?
Machine: he ’s a great player .
Human: where are you now ?
Machine: i ’m in the middle of nowhere .
(из статьи A Neural Conversational Model. КДПВ из фильма Ex Machina)
К решению задачи самообучающихся вопросно-ответных систем IT компании и исследовательские организации подходят с разным видением первоначальной точки отсчета.
Facebook пошел по пути определения перечня 20 конкретных логических операций и генерации под них искусственного набора задач (так называемый bAbi task, детальное описание). С их точки зрения, эти операции являются необходимыми, но не достаточными для создания искусственного интеллекта [7]. Например, система должна уметь: положительно или отрицательно отвечать на вопросы, отвечать на вопросы, исходя из одного или нескольких известных фактов, считать, работать с неопределенностью и др.
Для решения предложенного набора задач была разработана оригинальная нейросетевая самообучающаяся архитектура с памятью — Memory Networks [8] и ее End-to-End реализация [9] (код от авторов, реализация на tensor flow).
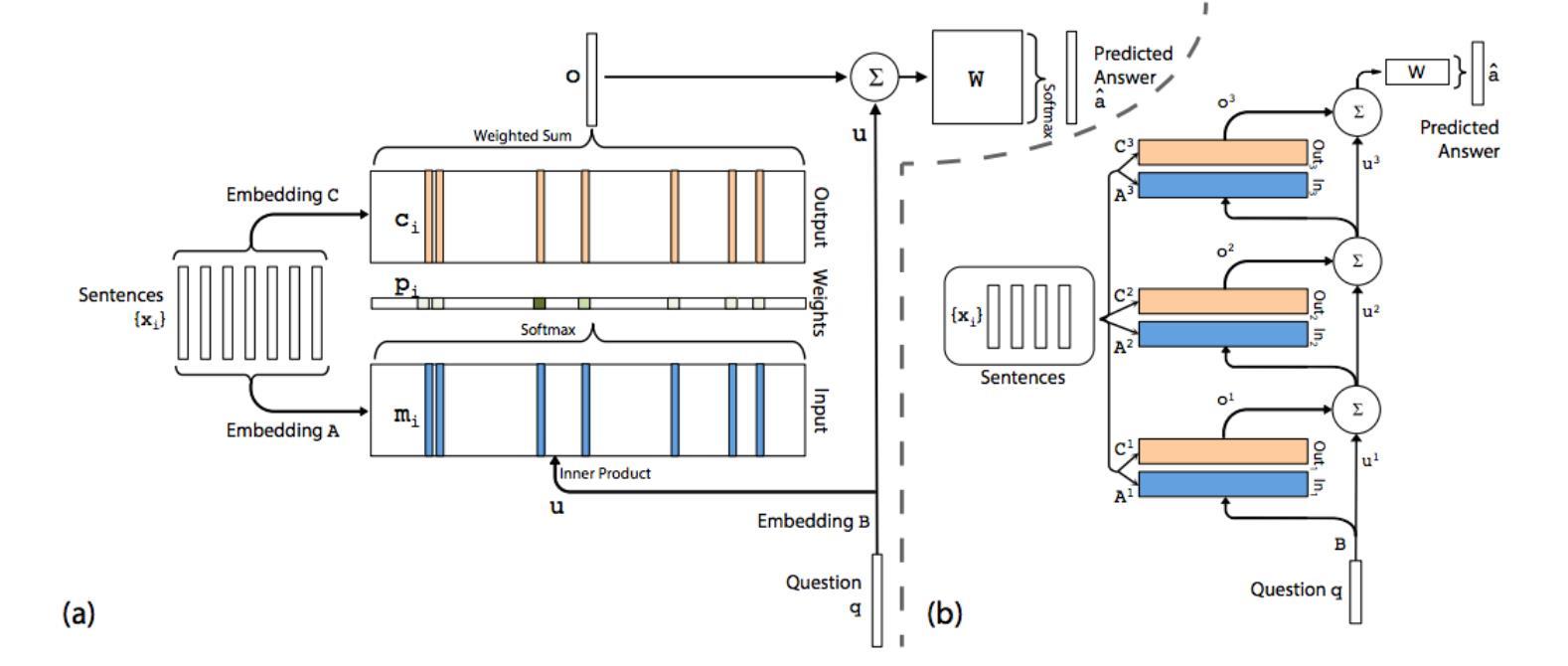
Google, разрабатывая архитектуру Neural Turing Machine [10], использует более фундаментальный подход — систему, которая самостоятельно обучается, какую информацию и когда необходимо записывать и читать из памяти для решения задачи.
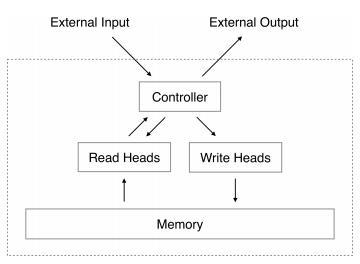
Однако результаты этого подхода пока менее конкурентноспособны при решении реальных задач. Neural Turing Machine решает задачи сортировки и получения информации из памяти, оперируя при этом небольшим размером памяти в 128 ячеек. Чуть большую функциональность демонстрирует Neural Programmer [11].
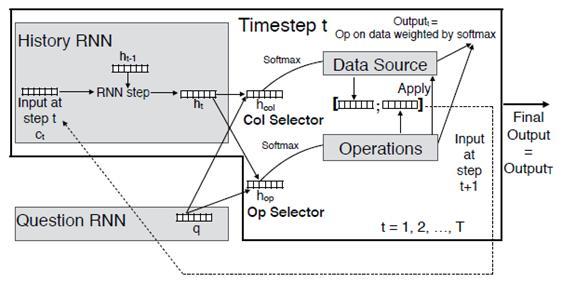

Система способна обучаться выполнять базовые логические и арифметические операции над таблицей с данными. Задача ставится таким образом: есть набор столбцов с данными, есть набор базовых операций, и система самостоятельно обучается необходимой последовательности действий — выбора данных и применения к ним операции, для получения требуемого решения.
Allen Institute for Artificial Intelligence для проекта создания вопросно-ответной системы об окружающем мире (система ARISTO) использует онтологический подход [12], в том числе с возможностью обучения системы за счет взаимодействия с пользователем [13]. Проект разбит на 3 этапа — решение тестов для 4, 8 и 12 классов американской школы. Если с 4-м классом, более или менее, удалось справиться, то для 8-го задачка оказалась непростая, и институт решил привлечь мировое сообщество data scientists на Kaggle для ее решения — The Allen AI Science Challenge.
Участникам даны обучающая (2 500 вопросов) и тестовая (8 132 вопроса) выборки вопросов в текстовой форме с 4-мя вариантами ответа. Для обучающей выборки правильные ответы известны, для тестовой — нет. Из-за небольшого объема обучающая выборка скорее предназначена не для обучения системы, а для использования при работе над решением для оценки его качества в целом и степени “покрытия” им основных тем физики, биологии, географии и прочих предметов для 8-го класса.
Конкурс имеет ряд особенностей (здесь можно найти обзор-выжимку с форума конкурса) — например, итоговое решение должно работать без доступа к интернету, поэтому применить столь долгожданный Google Knowledge Graph API не получится.
Ниже в таблице* приведен сравнительный обзор современных походов к созданию вопросно-ответных систем, подготовленный в рамках семинара Memory and Q&A systems группы Deep Learning Moscow (в группе есть полная версия презентации с ссылками на источники).
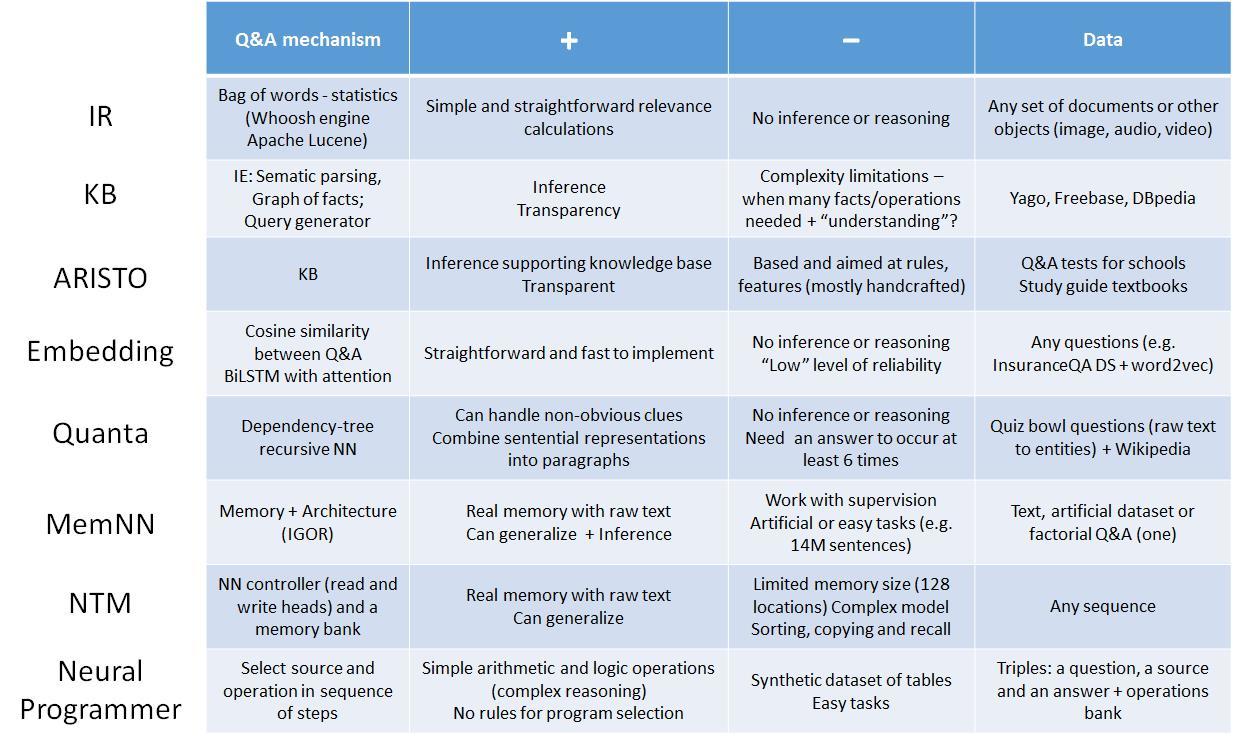
* IR — information retrieval; KB — knowledge base; IE — information extraction; BiLSTM — bidirectional long-short term memory; NN — neural net; NTM — Neural Turing Machine; IGOR — архитектура Memory Networks — Input feature map, Generalization, Output feature map, Response.
Ранее на Хабре уже упоминался новый хакатон, совмещенный с научной школой, DeepHack.Q&A, на котором можно будет опробовать в деле все вышеперечисленные классические и нейросетевые вопросно-ответные методы, а также напрямую задать вопросы их авторам.
[1] Andrew Y. Ng et al. (2014), Deep Speech: Scaling up end-to-end speech recognition
[2] Bengio Y., Cho K., Bahdanau D. (2015), Neural Machine Translation by Jointly Learning to Align and Translate, International Conference on Learning Representations 2015
[3] Blunsom P., Grefenstette E., Kalchbrenner N. (2014), A Convolutional Neural Network for Modelling Sentences, The 52nd Annual Meeting of the Association for Computational Linguistics
[4] Kumar A. et al. (2015), Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
[5] T. Mikolov et al. (2015), A Roadmap towards Machine Intelligence
[6] Serban J.V. et al. (2015), A Survey of Available Corpora For Building Data-Driven Dialogue System
[7] Jason Weston et al. (2015), Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks
[8] Jason Weston et al. (2015), Memory Networks
[9] Sainbayar Sukhbaatar et al. (2015), End-To-End Memory Networks
[10] Alex Graves et al. (2015), Neural Turing Machines
[11] Arvind Neelakantan et al. (2015), Neural Programmer: Inducing Latent Programs with Gradient Descent
[12] Clark P., et. al (2015), Automatic Construction of Inference-Supporting Knowledge Bases
[13] Hixon B., et. Al (2015), Learning Knowledge Graphs for Question Answering through Conversational Dialog
Комментарии (3)

Cybersoph
12.01.2016 12:35|| перспективность нейросетевых алгоритмов глубокого обучения в сравнении с классическими методами обработки естественного языка
Любая перспективность всегда определяется в двух ипостасях: по Форме и по Сущности. А любая Технология базируется на двух своих основополагающих компонентах — Методологии (как набор способов) и Инструментарии (как набор средств).
Итак, возьмём в качестве наглядного примера простой арифмометр начала прошлого века. Какова была его перспективность? Да никакая, если не считать его развитием тупое увеличение разрядности. Потом по законам эволюции техногенных укладов арифмометра сменил электронный калькулятор и арифмометры тут же стали бесперспективными. А какая была перспектива у калькулятора, который так и не дорос до компьютера? Максимум – это быть приложением к АйТи технологиям.
А какая перспектива у самого компьютера? Какие из вышеперечисленных четырёх факторов (Форма, Сущность, Методология и Инструментарий) могут принести машинам искомую перспективность, если под нею понимать «искусственно мыслящую машину, умеющую оперировать Знаниями»? Ведь, на сегодня ЭВМ способна оперировать исключительно лишь только Данными. А как сделать так, чтобы она смогла понимать (анализировать) Знания и создавать (синтезировать) новые Знания? Для этого мы должны рассмотреть какие именно факторы могут дать эту перспективу:
— Форма? Явно нет.
— Сущность? Скорее всего.
— Методология? Может быть.
— Инструментарий? Пока такой неизвестен.
А как вообще понять, что именно нам нужно
Что мы имеем на сегодня? Все знакомые нам лингвистические, логические, статистические, стохастические, математические (псевдо-нейросистемы), вопросно-ответные и прочие технологические ухищрения в АОТ не способны оперировать Знаниями. В АйТи нужно переходить на новый технологический уклад – ОБРАБОТКА ЗНАНИЙ!
Вот это и есть настоящая перспектива!
elingur
12.01.2016 16:30ОБРАБОТКА ЗНАНИЙ!
Ну это, как говорится, и ёжику понятно. Пока даже нет корректного определения, что считать знанием в ИИ. В настоящее время задача решается в лоб — бесконечным составлением тезаурусов. Лично я считаю, что это тупиковый путь, но другого не вижу. Все псевдо-семантические алгоритмы типа LSA / LDA больше напоминают пляски с бубном (сам этим занимаюсь), нежели реализацию семантических связей. Поэтому проблема в определении, в постановке задачи: что мы считаем знанием, каковы его границы, какими свойствами оно должно обладать?
elingur
Перспективность — возможно, да. А вот преимущества я пока не вижу. Современные статистические методы обработки естественного языка пока не только более точны, но и более гибки в настройке (хотя бы потому, что можно «руками» выбирать и настраивать нужные параметры). Мне кажется, вопрос «что лучше» пока спорный. Ведь вовсе не обязательно уподоблять ИИ мозгу человека; например, самолеты летают, но крыльями не машут.