
В этой статье я немного расскажу о такого рода сетях и познакомлю с парой классных инструментов для домашних экспериментов, которые позволят строить нейронные сети любой сложности в несколько строк кода даже школьникам. Добро пожаловать под кат.
Что такое RNN?
Основное отличие рекурентных сетей (Recurrent Neural Network, RNN) от традиционных заключается в логике работы сети, при которой каждый нейрон взаимодействует сам с собой. На вход таким сетям как правило передаётся сигнал, являющийся некоторой последовательностью. Каждый элемент такой последовательности поочерёдно передаётся одним и тем же нейронам, которые своё же предсказание возвращают себе вместе со следующим её элементом, до тех пор пока последовательность не закончится. Такие сети, как правило, используются при работе с последовательной информацией — в основном с текстами и аудио/видео-сигналами. Элементы рекурентной сети изображают как обычные нейроны с дополнительной циклической стрелкой, которая демонстрирует то, что кроме входного сигнала нейрон использует также своё дополнительное скрытое состояние. Если «развернуть» такое изображение, получится целая цепочка одинаковых нейронов, каждый из которых получает на вход свой элемент последовательности, выдаёт предсказание и передаёт его дальше по цепочке как своего рода ячейку памяти. Нужно понимать, что это абстракция, поскольку это один и тот же нейрон, который отрабатывает несколько раз подряд.

Такая архитектура нейронной сети позволяет решать такие задачи, как, предсказание последнего слова в предложении, например слово «солнце» в фразе «в ясном небе светит солнце».
Моделирование памяти в нейронной сети подобным образом вводит новое измерение в описание процесса её работы — время. Пусть нейронная сеть получает на вход последовательность данных, например, текст пословно или слово побуквенно. Тогда каждый следующий элемент этой последовательности поступает на нейрон в новый условный момент времени. К этому моменту в нейроне уже есть накопленный с начала поступления информации опыт. В примере с солнцем в качестве x0 выступит вектор, характеризующий предлог «в», в качестве x1 — слово «небе» и так далее. В итоге в качестве ht должен быть вектор, близкий к слову «солнце».
Основное отличие разных типов рекурентных нейронов друг от друга кроется в том, как обрабатывается ячейка памяти внутри них. Традиционный подход подразумевает сложение двух векторов (сигнала и памяти) с последующим вычислением активации от суммы, например, гиперболическим тангенсом. Получается обычная сетка с одним скрытым слоем. Подобную схему рисуют следующим образом:
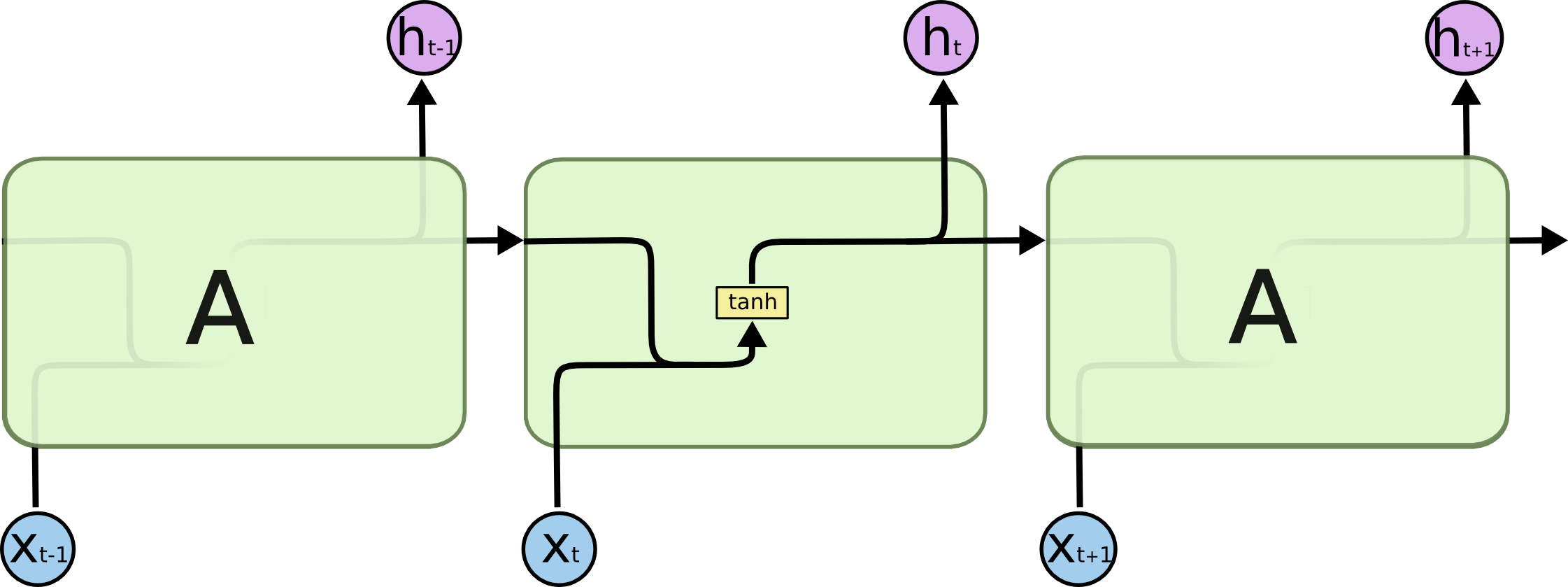
Но память, реализованная подобным образом, получается весьма короткой. Поскольку каждый раз информация в памяти смешивается с информацией в новом сигнале, спустя 5-7 итераций информация уже полностью перезаписывается. Возвращаясь к задаче предсказывания последнего слова в предложении, нужно отметить, что в пределах одного предложения такая сеть будет работать неплохо, но если речь заходит о более длинном тексте, то закономерности в его начале уже не будут вносить какой либо вклад в решения сети ближе к концу текста, также как ошибка на первых элементах последовательностей в процессе обучения перестаёт вносить вклад в общую ошибку сети. Это очень условное описание данного явления, на самом деле это фундаментальная проблема нейронных сетей, которая называется проблема исчезающего градиента, и из-за неё ни много ни мало началась третья «зима» глубокого обучения в конце XX-го века, когда нейронные сети на полтора десятилетия уступили лидерство машинам опорных векторов и алгоритмам бустинга.
Чтобы побороть этот недостаток, была придумана LSTM-RNN сеть (Long Short-Term Memory Recurent Neural Network), в которой были добавлены дополнительные внутренние преобразования, которые оперируют с памятью более осторожно. Вот её схема:
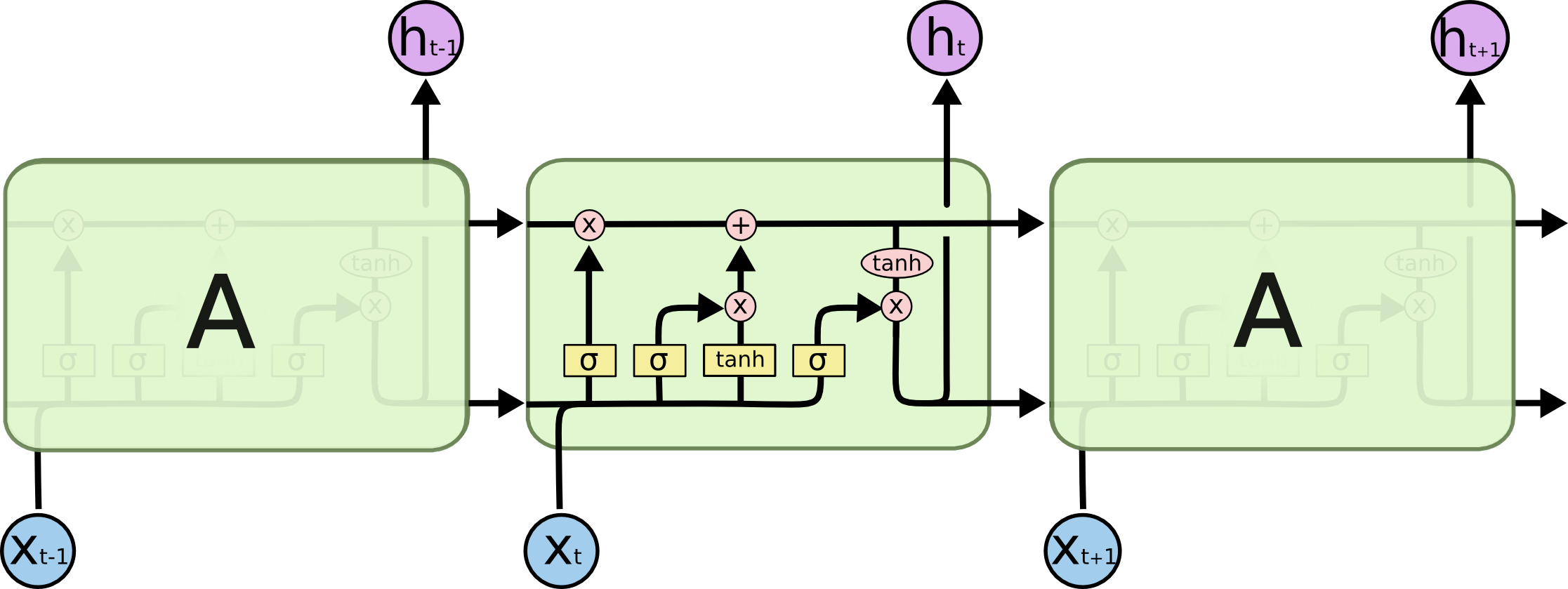
Пройдёмся подробнее по каждому из слоев:
Первый слой вычисляет, насколько на данном шаге ему нужно забыть предыдущую информацию — по сути множители к компонентам вектора памяти.
Второй слой вычисляет, насколько ему интересна новая информация, пришедшая с сигналом — такой же множитель, но уже для наблюдения.
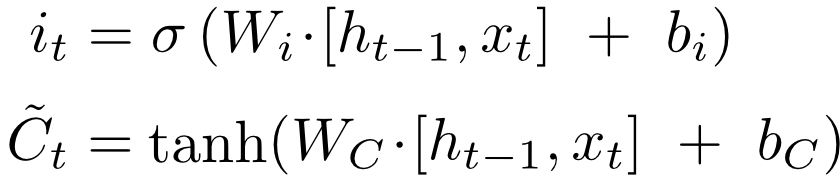
На третьем слое вычисляется линейная комбинация памяти и наблюдения с только вычисленными весами для каждой из компонент. Так получается новое состояние памяти, которое в таком же виде передаётся далее.
Осталось вычислить output. Но поскольку часть входного сигнала уже в памяти, не нужно считать активацию по всему сигналу. Сначала сигнал проходит через сигмоиду, которая решает, какая его часть важна для дальнейших решений, затем гиперболический тангенс «размазывает» вектор памяти на отрезок от -1 до 1, и в конце эти два вектора перемножаются.

Полученные таким образом ht и Ct передаются далее по цепочке. Безусловно, существует множество вариаций того, какие именно функции активации используются каждым слоем, немного модифицируют сами схемы и прочее, но суть остаётся прежней — сначала забывают часть памяти, затем запоминают часть нового сигнала, а уже потом на основе этих данных вычисляется результат. Картинки я взял отсюда, там также можно посмотреть несколько примеров более сложных схем LSTM.
Не буду здесь подробно рассказывать про то, как такие сети обучаются, скажу только, что используется алгоритм BPTT (Backpropagation Through Time), который является обобщением стандартного алгоритма на случай, когда в сети есть время. Почитать про этот алгоритм можно здесь или здесь.
Использование LSTM-RNN
Рекурентные нейронные сети, построенные на подобных принципах очень популярны, вот несколько примеров подобных проектов:
Есть также успешные примеры использования LSTM-сеток в качестве одного из слоёв в гибридных системах. Вот пример гибридной сети, которая отвечает на вопросы по картинке из серии «сколько изображено книжек?»:

Здесь LSTM-сеть работает в связке с модулем распознавания образов на картинках. Вот здесь доступно сравнение разных гибридных архитектур для решения этой задачи.
Theano и keras
Для языка Python существует много очень мощных библиотек для создания нейронных сетей. Не задаваясь целью привести хоть сколько-нибудь полный обзор этих библиотек, хочу познакомить вас с библиотекой Theano. Вообще говоря, из коробки это очень эффективный инструментарий по работе с многомерными тензорами и графами. Доступны реализации большинства алгебраических операций над ними, в том числе поиск экстремумов тензорных функций, вычисление производных и прочее. И всё это можно эффективно параллелить и запускать вычисления с использованием технологий CUDA на видеокарточках.
Звучит здорово, если бы не тот факт, что Theano сам генерирует и компилирует код на C++. Может это мой предрассудок, но я с большим недоверием отношусь к подобного рода системам, поскольку, как правило, они наполнены невероятном числом багов, которые очень сложно находить, возможно из-за этого я долгое время не уделял должного внимания этой библиотеке. Но Theano был разработан в канадском институте MILA под руководством Yoshua Bengio, одного из самых знаменитых специалистов в области глубокого обучения нашего времени, и за свой пока что недолгий опыт работы с ней, никаких ошибок я, разумеется, не обнаружил.
Тем не менее, Theano это только библиотека для эффективных расчётов, на ней нужно самостоятельно реализовывать backpropagation, нейроны и всё остальное. Например, вот код с использованием только Theano той же сети LSTM, о которой я рассказывал выше, и в нём около 650 строк, что совсем не отвечает заголовку этой статьи. Но может быть я бы никогда и не попробовал поработать с Theano, если бы не удивительная библиотека keras. Являясь по сути только сахаром для интерфейса Theano, она как раз и решает задачу, заявленную в заголовке.
В основе любого кода с использованием keras лежит объект model, который описывает то, в каком порядке и какие именно слои содержит ваша нейросеть. Например, модель, которую мы использовали для оценки тональности твитов про Звёздные войны, принимала на вход последовательность слов, поэтому её тип был
model = Sequential()
После объявления типа модели, к ней последовательно добавляются слои, например, добавить LSTM-слой можно такой командой:
model.add(LSTM(64))
После того, как все слои добавлены, модель нужно скомпилировать, при желании указав тип функции потерь, алгоритм оптимизации и ещё несколько настроек:
model.compile(loss='binary_crossentropy', optimizer='adam', class_mode="binary")
Компиляция занимает пару минут, после этого у модели доступны всем понятные методы fit(), predict(), predict_proba() и evaluate(). Вот так просто, по-моему это идеальный вариант для того, чтобы начать погружаться в глубины deep learning. Когда возможностей keras будет не хватать и захочется, например, использовать собственные функции потерь, можно опуститься на уровень ниже и часть кода написать на Theano. Кстати, если кого-то тоже пугают программы, которые сами генерируют другие программы, в качестве бэкенда к keras можно подключить и свеженький TensorFlow от Google, но работает он пока что заметно медленнее.
Анализ тональности твитов
Вернёмся к нашей первоначальной задаче — определить, понравились Звёздные войны российскому зрителю, или нет. Я использовал простенькую библиотеку TwitterSearch, как удобный инструмент для того, чтобы итерироваться по результатам поиска от Twitter. Как и у всех открытых API крупных систем, Twitter имеет определённые ограничения. Библиотека позволяет вызывать callback после каждого запроса, так что очень удобно расставлять паузы. Таким образом выкачалось около 50 000 твитов на русском языке по следующим хештегам:
- #starwars
- #звездныевойны
- #star #wars
- #звездные #войны
- #ПробуждениеСилы
- #TheForceAwakens
- #пробуждение #силы
Пока они выкачивались, я занялся поиском обучающей выборки. На английском языке в свободном доступе находятся несколько размеченных корпусов твитов, самый крупный из них — стэнфордская обучающая выборка упомянутого в самом начале sentiment140, также есть список небольших датасетов. Но все они на английском языке, а задача ставилась именно для русского. В этой связи хочу высказать отдельную благодарность аспирантке (наверное уже бывшей?) Института систем информатики им. А.П.Ершова СО РАН Юлии Рубцовой, которая выложила в открытый доступ корпус из почти 230 000 размеченных (с точностью более 82%) твитов. Побольше бы нашей стране таких людей, которые на безвозмездной основе поддерживают коммьюнити. В общем, с этим датасетом и работали, почитать о нём и скачать можно по ссылке.
Я очистил все твиты от лишнего, оставив только непрерывные последовательности кириллических символов и чисел, которые прогнал через PyStemmer. Затем заменил одинаковые слова на одинаковые числовые коды, в итоге получив словарь из примерно 100000 слов, а твиты представились в виде последовательностей чисел, они готовы к классификации. Чистить от низкочастотного мусора я не стал, потому что сетка умная и сама догадается, что там лишнее.
Вот наш код нейросети на keras:
from keras.preprocessing import sequence
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import LSTM
max_features = 100000
maxlen = 100
batch_size = 32
model = Sequential()
model.add(Embedding(max_features, 128, input_length=maxlen))
model.add(LSTM(64, return_sequences=True))
model.add(LSTM(64))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
class_mode="binary")
model.fit(
X_train, y_train,
batch_size=batch_size,
nb_epoch=1,
show_accuracy=True
)
result = model.predict_proba(X)
За исключением импортов и объявлений переменных вышло ровно 10 строк, а можно было бы и в одну написать. Пробежимся по коду. В сети 6 слоёв:
- Слой Embedding, который занимается подготовкой фичей, настройки говорят о том, что в словаре 100 000 разных фичей, а сетке ждать последовательности из не более, чем 100 слов.
- Далее два слоя LSTM, каждый из которых отдаёт на выход тензор размерность batch_size / length of a sequence / units in LSTM, а второй отдаёт матрицу batch_size / units in LSTM. Чтобы второй понимал первого, выставлен флаг return_sequences=True
- Слой Dropout отвечает за переобучение. Он обнуляет случайную половину фичей и мешает коадаптации весов в слоях (верим на слово канадцам).
- Dense-слой это обычный линейный юнит, который взвешенно суммирует компоненты входного вектора.
- Последний слой активации загоняет это значение в интервал от 0 до 1, чтобы она стала вероятностью. По сути Dense и Activation в таком порядке это логистическая регрессия.
Для того, чтобы обучение происходило на GPU при выполнении этого кода нужно выставить соответствующий флаг, например так:
THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python myscript.py
На GPU эта самая модель у нас обучалась почти в 20 раз быстрее, чем на CPU — порядка 500 секунд на датасете из 160 000 твитов (треть твитов пошли на валидацию).
Для подобных задач нет каких-то чётких правил формирования топологии сети. Мы честно потратили полдня на эксперименты с различными конфигурациями, и данная показала лучшую точность — 75%. Результат предсказания сетки мы сравнивали с обыкновенной логистической регрессией, которая показывала 71% точности на том же датасете при векторизации текста методом tf-idf и примерно те же самые 75%, но при использовании tf-idf для биграмм. Причина того, что нейросеть почти не обогнала логистическую регрессию скорее всего в том, что обучающая выборка была всё-таки маловата (по-честному для такой сети нужно не меньше 1 млн твитов обучающей выборки) и зашумлена. Обучение проходило всего за 1 эпоху, так как далее мы фиксировали сильное переобучение.
Модель предсказывала вероятность того, что твит позитивный; мы считали положительным отзыв с этой вероятностью от 0.65, отрицательным — до 0.45, а промежуток между ними — нейтральным. В разбивке по дням динамика выглядит следующим образом:
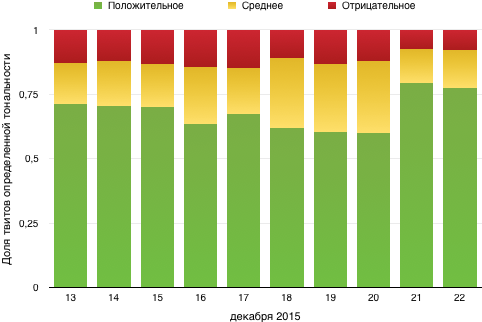
В целом видно, что людям фильм скорее понравился. Хотя лично мне не очень :)
Примеры работы сети
Я выбрал по 5 примеров твитов из каждой группы (указанное число — вероятность того, что отзыв положительный):
Позитивная тональность
0,9945:
Можно выдыхать спокойно, новые Star Wars олдскульно отличные. Абрамс — крутой, как и всегда. Сценарий, музыка, актёры и съемка — идеально.— snowdenny (@maximlupashko) December 17, 2015
0,9171:
Всем советую сходить на звездные войны супер фильм— николай (@shans9494) December 22, 2015
0,8428:
СИЛА ПРОБУДИЛАСЬ! ДА ПРИБУДЕТ С ВАМИ СИЛА СЕГОДНЯ НА ПРЕМЬЕРЕ ЧУДА, КОТОРОЕ ВЫ ЖДАЛИ 10 ЛЕТ! #TheForceAwakens #StarWars— Vladislav Ivanov (@Mrrrrrr_J) December 16, 2015
0,8013:
Хоть и не являюсь поклонницей #StarWars, но это исполнение чудесно! #StarWarsForceAwakens https://t.co/1hHKdy0WhB— Oksana Storozhuk (@atn_Oksanasova) December 16, 2015
0,7515:
Кто сегодня посмотрел звездные войны? я я я :))— Anastasiya Ananich (@NastyaAnanich) December 19, 2015
Смешанная тональность
0,6476:
Новые Звездные войны лучше первого эпизода, но хуже всех остальных— Igor Larionov (@Larionovll1013) December 19, 2015
0,6473:
Хан Соло умрёт. Приятного просмотра. #звездныевойны— Nick Silicone (@nicksilicone) December 16, 2015
0,6420:
У всех вокруг Звездные войны. Я одна что ли не в теме? :/— Olga (@dlfkjskdhn) December 19, 2015
0,6389:
Идти или не идти на Звездные Войны, вот в чем вопрос — annet_p (@anitamaksova) December 17, 2015
0,5947:
Звездные войны оставили двоякие впечатления. И хорошо и не очень. Местами не чувствовалось что это те самые… что-то чужое проскальзывало— Колот Евгений (@KOLOT1991) December 21, 2015
Негативная тональность
0,3408:
Вокруг столько разговоров, неужели только я не фанатею по Звёздным войнам? #StarWars #StarWarsTheForceAwakens— modern mind (@modernmind3) December 17, 2015
0,1187:
они вырвали мое бедное сердце из грудной клетки и разбили его на миллионы и миллионы осколков #StarWars— Remi Evans (@Remi_Evans) December 22, 2015
0,1056:
ненавижу дноклов, проспойлерили мне звездные войны— пижамка найла (@harryteaxxx) December 17, 2015
0,0939:
Проснулась и поняла, что новый Star Wars разочаровал.— Tim Frost (@Tim_Fowl) December 20, 2015
0,0410:
Я разочарован #пробуждениесилы— Eugenjkee; Star Wars (@eugenjkeee) December 20, 2015
P.S. Уже после того, как исследование было проведено, наткнулись на статью, в которой хвалят сверточные сети для решения этой задачи. В следующий раз попробуем их, в keras они также поддерживаются. Если кто-то из читателей решит проверить сам, пишите в комментарии о результатах, очень интересно. Да пребудет с вами Сила больших данных!
Комментарии (47)

Stas911
11.01.2016 19:55+1Очень интересная статья, спасибо! А остальной код где-то на гитхабе?

ser0t0nin
11.01.2016 20:06+1И вам спасибо за отзыв. Остальной код ничего хитрого из себя не представляет — стемминг и замена одинаковых слов числами по словарику, поэтому я не стал его оформлять. Если интересно — могу выложить,

BelBES
11.01.2016 23:22+7Было бы просто отлично, если бы вы выложили код вместе с туториалом, как воспроизвести ваши результаты.
Вообще тема рекурентных сетей выглядит очень перспективно, особенно в связи со своей Тьюринг-Полнотой.
ZlodeiBaal
11.01.2016 23:36+1А вы видели где-нибудь вразумительно доказательство? Пока всё что я читал это: «есть мысли что оно всё же Тьюринг-полно». Скорее всего это действительно так, но любопытно было бы увидеть разумное обоснование.
BelBES
11.01.2016 23:57+1На самом деле прямо формального доказательства полноты по Тьюрингу я не видел, но неоднократно встречал упоминания того, что оно вроде бы существует в природе. Возможно, в учебнике по DL от Бенджио что-то такое есть, но я его еще не прочитал. В статьях встречал только вот такое творчество от DeepMind, где попытались создать модель МТ на основе DL.
Durham
12.01.2016 16:05+2Классическое доказательство, см. Siegelmann and Sontag, «On the computational power of neural nets»
Что не значит, однако, что любая рекуррентная сеть обладает этим свойством.
ser0t0nin
12.01.2016 13:16+4Хорошо, постараюсь до выходных найти время привести код в божеский вид и поделиться с вами :)

intet
11.01.2016 20:27+20Пробуждение силы и так продукт нейронной сети. К тому же нейронную сеть явно переобучили на главной выборке.
goodok
11.01.2016 20:34+3Спасибо за статью. Комментарий и вопрос:
1.
>«Результат предсказания сетки мы сравнивали с обыкновенной логистической регрессией, которая показывала [...] примерно те же самые 75%, но при использовании tf-idf для биграмм.»
Ну а так как «принципы действия» этих методов (RNN и bags of bigrams) несколько различаются и они дают не совсем коррелированные предсказания, то при объединении их в ансамбль результат предсказания скорее всего можно заметно улучшить
Скорее всего Вы уже читали статью Миколова и Ко по этому поводу: Ensemble of Generative and Discriminative Techniques for Sentiment Analysis of Movie Reviews Там же есть ссылка (Baselines and Bigrams: Simple, Good Sentiment and Topic Classification) на то, что достаточно простые модели (bags of n-grams + Naive Bayes, SVM и даже NB-SVM) на некоторых датасетах показывают таки лучшие результаты по сравнению с различными вариантами RCC.
2.
>«обучающая выборка была всё-таки маловата (по-честному для такой сети нужно не меньше 1 млн твитов обучающей выборки)»
А вы не пробовали предобучить Embedding слой на не размеченных (т.е. более доступных) данных? Или воспользоваться готовыми обученными моделями типа Word2Vec? Интуитивно кажется, что требования к размеру обучающей выборки тогда ослабеют.
alexeygrigorev
11.01.2016 22:01+1А можно про пункт 2 по-подробнее? почему это может помочь? Может у вас так же будут полезные ссылки по этому поводу?
ser0t0nin
12.01.2016 13:241. Да, разумеется читали; при решении данной задачи хотелось заодно попробовать новую для себя технологию, на лучшее решение из возможных не претендуем. Так вышло гораздо интереснее на мой взгляд. Вот как раз при сравнении с логрегом убедились, что решение неплохо.
2. Не очень очевидно, что это прям сильно улучшит качество. Да и где взять миллион русских твитов, пусть даже неразмеченных, тоже еще вопрос, я не смог найти подобных датасетов, а выгрузить столько сами мы бы не успели. Качественных предобученных прям на русских твитах-отзывах моделей Word2Vec мне тоже неизвестно. Буду багодарен, если поделитесь ссылкой на таковую или похожие.
Durham
12.01.2016 18:30+1Не очень очевидно, что это прям сильно улучшит качество
Как правило это улучшает качество существенно. Правда качество надо еще правильно измерять (см. мой комментарий ниже)
Да и где взять миллион русских твитов, пусть даже неразмеченных
Это и не нужно. вектора предобучаются на любой большой коллекции текстов, например, на википедии. Это легко сделать самостоятельно.ser0t0nin
12.01.2016 19:13+1Но ведь в википедии в обиходе совсем иная модель языка, нежели в твиттере. Это как научить ребенка читать азбуку, а потом дать читать Достоевского — прочесть прочитает, но смысл не поймет и передаст с потерями. Для подобного предварительного обучения на «левых» данных нужно использовать ту же самую модель языка, на которой происходит обучение (и с которой в дальнейшем будет работать модель), иначе веса слов будут значительно смещены
Durham
12.01.2016 19:20+1Язык все равно остается языком и очень много информации общей между твиттером и википедией. Для остального существует дообучение векторов на вашей выборке. Рассуждения о том, что
Это как научить ребенка читать азбуку, а потом дать читать Достоевского
— это философия. А критерий истины это практика. Если на то пошло, существует в определенных задачах такое явление как обобщение признаков нейронной сетью между разными языками вообще. Проблема главная предобученных векторов для анализа тональности, не условная разница между языками твиттера и вики, а то, что слова вроде «хороший» и «плохой» оказываются рядом в пространстве признаков. Но даже при этом предобученные вектора дают как правило улучшение результатов.
goodok
13.01.2016 01:451. По мотивации — солидарен.
2. Насчёт «сильно» и «улучшить», покажет только эксперимент, да и результаты будут зависить от датасета/задачи.
Интуитивно кажется, что таким образом можно «поймать» слова-синонимы, часть которых отсутствует в обучающей выборке, но присутствует в целевом множестве (будущие твиты) и, наверняка, в неразмеченном большом датасете. Полагаю, что слова синонимы будут близко расположены в векторном пространстве.
Про использование предобученного на неразмеченном датасете нижнего слоя конкретно в задаче анализа тональности текста статей не припоминаю, но у ЛеКуна в уже прошлогодней статье Text understanding from Scratch описана попытка расширить текстовый корпус (data augmentation) заменой синонимов из тезауруса. Кстати, в статье изложен любопытный способ обработки текста — текст перекодируют с уровня символов (а не слов!) в изображения, а уж к ним применяют хорошо себя зарекомендовавшую в задачах обработки изображений свёрточную сеть.
Конечно, лексика, грамматика и образы «твиттерного мышления» нексколько отличаются от таковых в развёрнутых текстах. Но… вопрос, насколько.ser0t0nin
13.01.2016 12:59Конечно, лексика, грамматика и образы «твиттерного мышления» нексколько отличаются от таковых в развёрнутых текстах. Но… вопрос, насколько.
Настолько, что при ограничении в 140 символов люди стараются как можно сильнее ужаться, а на вики наоборот стремятся писать более развернуто. Мне кажется, это значимая разница с точки зрения модели языка. И такие слова как «олдскульно», «дноклы» и «фанатею» вряд ли можно найти на Википедии, нужно в дополнение на Лурке еще обучать, что ли :)

Nashev
13.01.2016 00:33А не расскажете, как обучать оценке тональности на выборках с неуказаной оценкой тональности?
goodok
13.01.2016 01:51Речь не совсем об этом. Речь о предобучении нижнего слоя, выход из которого можно рассматривать как преобразованные (перекодированные) исходные данные.
Nashev
13.01.2016 01:57А каков на нём критерий обучения?

grossws
13.01.2016 09:58Так же как и обычно для word embeddings, скорее всего. Положительное подкрепление за замену слова на имеющее такой же контекст в рамках корпуса, штраф за замену на слово, использование которого в данном контексте не подкреплено примером из корпуса.
snapdragon
11.01.2016 21:40+4Тем не менее, Theano это только библиотека для эффективных расчётов, на ней нужно самостоятельно реализовывать backpropagation, нейроны и всё остальное.
Backpropagation как раз автоматом делается — надо только целевую функцию задать, а градиенты Theano сама посчитает. Даже и во времени.ser0t0nin
12.01.2016 13:25Ну я имел ввиду, что для этого нужно так или иначе отдельную процедуру писать, в keras про это ничего вообще нет.
Durham
12.01.2016 16:17Точность, имеется в виду accuracy или precision? Хотелось бы увидеть на самом деле F1 для каждого класса на тестовой выборке. Какова доля положительных твитов в обучающей выборке? Судя по графику, положительные твиты доминируют. Если их доля, скажем 70% то функция, которая не делает ничего, а просто возвращает положительный результат для любого твита будет иметь точность (в смысле accuracy), тоже 70% (по доле положительных твитов), поэтому сама по себе цифра 75% кажется высокой, но ни о чем еще не говорит.
ser0t0nin
12.01.2016 19:21имеется в виду Accuracy. Конечно, заранее неизвестно, сколько твитов про Звездные войны положительные, сколько нет, а вот на обучающей выборке классы были сбалансированы, так что положительных примерно 50%
Durham
12.01.2016 21:21Вы на три класса делите, положительные, нейтральные и отрицательные. Должно быть тогда примерно 33% положительных. Кстати, это Accuracy по какой выборке подсчитано?
ser0t0nin
13.01.2016 12:5575% процентов Accuracy получены при классификации на два класса с threshold = 0.5 в условиях сбалансированных выборок
Durham
13.01.2016 14:10+5То есть:
— Вы взяли набор твитов (обо всем на свете, не только о фильмах), разбитых на два класса, и искуственно сбалансированный.
— Обучили нейронную сеть, практически один в один совпадающую с учебным примером из комплекта Keras.
— Не озаботились дать на вход пре-тренированные вектора слов. Судя по комментариям, не знаете даже зачем это нужно и как работает.
— Получили результат, который почти никак не лучше чем baseline логистическая регрессия. Свалили все на малый размер, немаленькой на самом деле выборки в 160 000 штук. 160 000 это очень много! Это более 1 млн. слов. Например, у нас при определении тональности термина в этой работе, в обучающей выборке было около 3000 терминов и всего порядка 60 тыс. слов.
Далее, взяли с потолка пороговые значения и решили, что теперь у нас будет три класса. Никак не проверили оправданность этого деления. (а ведь задача разделения на три класса — она намного сложнее, и как известно результаты в ней всегда получаются хуже, чем при бинарном). Никак не проверили, что модель годится для предметной области твитов про фильмы. Никак не проверили соотношение классов в реальных выборках.
Само по себе это не плохо. Программисты часто пишут разнообразные hello world'ы только для того чтобы понять как что-то работает. Разобрать азы. Понятное и очень достойное занятие.
Но это — на минутку — исследование общественного мнения!.. Которое попало в весьма популярную газету и на основании его сделаны там еще какие-то выводы про то, какие люди когда ходили в кино. И вот это вопиющее безобразие. Собрали быстренько нечто, настроили за полдня и вперед. Мы крутые и с нами сила!
Может быть я слишком резко реагирую да.Люди не сильно пострадают, если статистика по мнениям о фильме будет не очень правильной. Просто я слишком много видел, что так же делаются и остальные более серьезные исследования. Имел несчастье лично наблюдать, что в российской медицине, например, полно работ, которые настрогали таким же образом, не обращая внимания на досадные детали люди малознакомые с темой. А потом в газетах «российские ученые открыли...» и дальше нас этим лечат, экстрактом рогов и копыт.
Поэтому, хочу призвать всех ответственно относится к данным, которые так или иначе публикуются. Отсутствие должной дисциплины исследователя в мелочах может вести к очень и очень негативным последствиям для всех.
Да, и еще. Странно читать обилие просьб к авторам статьи выложить это на github. Вообще-то это там уже есть, как пример от библиотеки keras. Без загрузки-выгрузки данных твиттера правда. Но основной код это именно он.
pro100olga
14.01.2016 11:22Скажите, а почему задача деления на три класса намного сложнее, и результаты получаются хуже? Я не спорю, просто хотелось бы узнать больше об этом. Может, поделитесь ссылками. Спасибо!
Durham
15.01.2016 18:42+2Чем больше классов мы выделяем, тем ближе они друг к другу находятся и тем хуже определена между ними граница. Это особенно верно для деления на классы непрерывных в общем-то значений, таких как отношение пользователя к чему-либо.
Посмотрите например вот здесь, это результаты тестирования систем по анализу тональности ROMIP 2011 года. Сравните значения F1 в таблице 4, 6 и 7 (два класса, три класса, и пять классов). Ухудшение весьма и весьма значительное. Тоже самое можно видеть и на материалах 2012 года. При анализе коротких фрагментов текста, результаты и того хуже.
Интуитивно можно это представить так. Допустим вам быстро (на секунду) показывают карточки белого и черного цвета и вам надо назвать цвет. Это не сложно. А теперь представьте, что карточек стало три — белый, черный и темно-синий. Число ошибок возрастет.ser0t0nin
18.01.2016 13:50В данной задаче классификатор только вычислял вероятность того, что отзыв положительный, градуировку шкалы с разбиением на 3 класса делали уже независимо, убедившись в первую очередь, что гистограмма количества твитов в разных диапазонах вероятностей более менее ровная + построив еще несколько графиков, которые не противоречили выбранной гипотезе.
Durham
18.01.2016 14:05Но без проверки результатов на тестовой выборке с тремя классами. Что тут еще сказать? Посмотрите, по ссылкам в моем комментарии выше, как плохо работают мульти-классовые классификаторы тональности у людей которые их создавали изначально на данных разбитых на n-классов. И которые потратили месяцы, а то и годы на разработку. Можно ли взять вот так пороги посмотрев на диаграммы и получить хороший результат? Да, повезти может и в лотерею. Но учитывая вышесказанное, без доказательств на тестовой выборке разбитой вручную на три класса, я лично в эти данные не верю.

PavelMSTU
12.01.2016 16:56+3Эх… заминусуют… Но истина дороже.
There are three kinds of lies: lies, damned lies, and statistics
Немного удивлен. Сам с женой сходили на новый эпизод Звездных Войн — досидели только из-за уважения…
Мягко говоря не понравилось…
Многих знакомых поспрашивал в оффлайне. Из 23 респондентов только трое высказали нейтральное мнение и двое положительное…
Это у меня одного реальность такая?
Жаль, что к посту не приложен опрос: «а вам понравился новый эпизод Звездных Войн»?pro100olga
13.01.2016 10:28+2Да уж, ДВАДЦАТЬ ТРИ респондента из искривленной выборки ваших знакомых — это, конечно, то к чему можно аппелировать словами «истина дороже»…
VitGo
13.01.2016 10:47+2ну как бы там нибыло могу сюда прибавить еще около 10 своих знакомых (и себя тоже)…
просто неинтересный фильм, не плохой — что хочется написать гадость, и не хороший — что хочется об этом рассказать всем, а такой — что как в том анекдоте «вляпался, так не чирикай» — лень даже идти и ставить оценку…
p.s. но конечно мнения таких респондентов учесть иначе как опросом после выхода с киносеанса нельзя…pro100olga
14.01.2016 11:27Ну да, еще одна искривленная выборка из 11 человек меняет дело )
Тут ведь вопрос в том, что комментатор заявляет, что статистика — ложь, а ему истина дороже. То есть свое мнение и мнение 23 своих знакомых считает более истинным чем 160000 отзывов. Никак не озаботившись даже не только размером выборки, но и ее соответствием ген.совокупности зрителей фильма.VitGo
14.01.2016 11:32Никто не говорит что меняет,
я же объяснил в своем прошлом сообщении — очень, очень, очень многие вообще не испытали никаких эмоций к фильму, поэтому и не написали ничего…
и то что будет много отзывов молодежи от 14 до 22 и именно они положительно отзовутся сомнения ни у кого не было — тут фильм, что называется «попал в своего зрителя»… — и отзывы это подтвердили…
pro100olga
13.01.2016 10:33Прочитала с большим интересом, спасибо! Вот тут когда-то писали про сентимент-анализ русскоязычного текста.
Пару вопросов:
1) насколько я знаю, twitterSearch вытягивает данные только за последнюю неделю или около того. Вы их и анализировали?
2) почему брали только твиты с хештегами, а не просто упоминаниями?
3) правильно ли я понимаю, что это поиск по русскоязычным твитам, а не по пользователям из России?
Спасибо!ser0t0nin
13.01.2016 12:26Спасибо за отзыв! Отвечаю:
1) вообще twitter всегда отдает частично неполные данные за период не более 6 — 9 дней с момента запроса и это не зависит от способа их получения, я собирал данные в течение трех дней, таким образом набрал твиты за 10 дней
2) Вообще хештег это просто ссылка на результат поиска, а при поиске Твиттер не учитывает символ #, так что это аналогично поиску по упоминаниями
3) Поиск по русскоязычным твитам, в API Твиттера можно указать желаемый язык твита; геопозиция, к сожалению, указана у очень маленького процента твитовpro100olga
13.01.2016 13:01Насколько я понимаю, чтобы получить твиты за более длительный период, нужно использовать Streaming API, но когда я пыталась это сделать, не смогла преодолеть проблемы с аутентификацией (т.е. Search API работал, а Streaming API нет)
По поводу геолокации: по приведенной вами ссылке пишут, что ее как-то дооценивают (что могут попасть твиты без геокодов): получается, даже с этой дооценкой мало твитов?
И еще вопрос (я прошу прощения, просто тема очень интересная): почему вы брали только твиттер? Насколько я знаю, это не самая популярная в России соц.сеть.ser0t0nin
18.01.2016 13:11+2Streaming API вроде как немножко другое. В такой клиент будут пушиться новые твиты, которые подходят под заданный критерий, старые, по моему, таким образом не достать.
Получается, да. Реально наблюдал очень низкий процент.
Открытые API есть только у VK и Twitter, доступ к остальным получить несколько сложнее и ограничения там жеще. Я пытался анализировать и записи VK, но большинство из них по данным хештегам либо реклама, либо картинки, либо музыка, текстов обычных пользователей реально очень мало.

vba
14.01.2016 12:45Скажите пожалуйста,
Описанный вами подход, для данной, задачи не является ли немного избыточным? Не кажется ли вам что обычная автоматическая классификация методом, скажем, максимальной энтропии, могла бы справится блестяще с данной задачей? Если я правильно понял, то вы изначально собрали corpus по трем категориям?ser0t0nin
18.01.2016 13:16Скажем так, не я первый такой подход применил. Уже писал выше — вместе с проведением исследования заодно хотелось освоить новую технологию. Метод максимальной энтропии справился бы превосходно, я сравнивал предложенный метод с некоторыми другими более простыми методами, качество работы нейронной сети не хуже. В частности в статье указывается, что log-reg на tf-idf по биграммам слов показывает такое же качество, остальные были чуть похуже
Color
Для спойлеров есть тег spoiler, так то!
andymitrich
Так-то пишется через дефис, так-то! :)