Доброго времени суток, уважаемые читатели!
В этой статье я хочу рассказать вам о технологии балансировки нагрузки, немного об отказоустойчивости и как все это подружить с контейнерами в OpenVZ. Будут рассмотрены основы LVS, режимы работы и настройка связки LVS c контейнерами в OpenVZ. Статья содержит в себе как теоретические аспекты работы данных технологий, так и практическую часть — проброс трафика от балансировщика внутрь контейнеров. Если это вас заинтересовало — добро пожаловать!
Для начала — ссылки на публикации по этой теме на Хабре:
Подробное описание работы LVS. Лучше не скажешь
Статья про контейнеры OpenVZ
Краткое изложение материала выше:
LVS (Linux Virtual Server) — технология, базирующая на IPVS (IP Virtual Server), которая присутствует в ядрах Linux с версии 2.4.x и новее. Является неким виртуальным свичем 4 уровня.
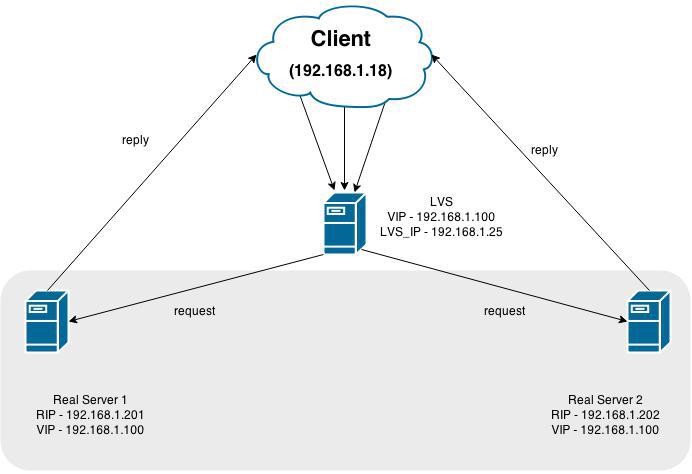
На данной картинке изображен LVS (сам балансировщик), виртуальный адрес, к которому происходят обращения (VIP) 192.168.1.100 и 2 сервера, выступающих в роли бэк-эндов: 192.168.1.201 и 192.168.1.202
В общем случае работает все так — мы делаем точку входа (VIP), куда приходят все запросы. Далее трафик перенаправляется к своим бэкэндам, где происходит его обработка и ответ клиенту напрямую (в схеме NAT — ответ через LVS обратно)
С методами балансировки можно ознакомиться здесь: ссылка. далее в статье считаем, что балансировка Round-Robin
Режимы работы:
Чуть подробнее о каждом:
В данном режиме работы обработка запроса происходит по следующему сценарию:
Клиент отправляет пакет в сеть к адресу VIP. Этот пакет ловится сервером LVS, в нем подменяется MAK адрес назначения (и только он!!) на мак адрес одного из серверов бэк-энда и пакет отправляется обратно в сеть. Его получает сервер бэк-энда, обрабатывает и отправляет запрос напрямую клиенту. Клиент получает ответ на свой запрос физически с другого сервера, но подмены не видит и радостно шуршит. Внимательный читатель конечно возмутится — как сможет Real Server обработать запрос, который пришел на другой IP адрес (в пакете адрес назначения- все тот же VIP)? И будет прав, т.к. для корректной работы следует этот адрес (VIP) куда-нибудь у бэк-энда разместить, чаще всего это вешается на loopback. Таким образом совершается самая большая афера в этой технологии.
Самый простой режим работы. Запрос от клиента приходит на LVS, LVS перенаправляет запрос бэк-енду, тот обрабатывает запрос, отвечает обратно на LVS и тот отвечает клиенту. Идеально впишется в схему, где у вас есть шлюз, через который идет весь трафик подсети. Иначе делать НАТ в части сети будет крайне неправильно.
Является аналогом первого способа, только трафик от LVS до бэкендов инкапсулируется в пакет. Именно его мы и будем настраивать ниже, поэтому сейчас всех карт я не раскрою :)
Установим сервер с LVS. Настраиваем на CentOS 6.6.
На чистой системе делаем
За собой она потащит апач, пхп и нужный нам ipvsadm. Апач и пхп ставятся для доступа к административной веб-морде, которую я советую вам один раз посмотреть, базово все настроить и больше не заходить туда :)
После установки всех пакетов делаем
задаем пароль для доступа к админке:
После этого заходим по адресу IP_LVS:3636/, вводим логин(piranha) и пароль из шага выше и попадаем в админку:
Для нас сейчас интересны две вкладки — GLOBAL SETTINGS и VIRTUAL SERVERS
Переходим на GLOBAL SETTINGS и выставим режим работы Tunneling
На вкладке VIRTUAL SERVERS создаем один Virtual Server с адресом 192.168.1.100 и порт 80
Там же на вкладке REAL SERVER зададим два бэк енда с адресами 192.168.1.201 и 192.168.1.202 с портами 80
Подробности на скриншотах под спойлером
Вкладку MONITORING SCRIPTS оставим без изменений, хотя на ней можно настроить очень гибкую работу проверки доступности узлов. По умолчанию это просто запрос типа GET / HTTP/1.0 и проверка, что нам ответил именно веб-сервер.
Можно выполнять произвольные скрипты, например такие как под спойлером.
Сохраняем конфиг, закрываем оконце и переходим в привычную нам консоль. Если вдруг вам стало интересно, что мы там нагенерили, то конфиг службы лежит в /etc/sysconfig/ha/lvs.cf
Смотрим текущие настройки:
Не густо. Это потому что наши конечные ноды не подняты! Установка и создание контейнеров OpenVZ пропускаю, считаем что у вас волшебным образом появились два контейнера с адресами 192.168.1.201 и 192.168.1.202, а внутри любой веб сервер на 80 порту :)
Опять смотрим на вывод команды:
Идеально! То, что нужно. Если вдруг мы выключим веб сервер на одной из нод, то наш балансировщик честно не будет слать туда трафик, пока ситуация не исправится.
Давайте подробнее взглянем на наш конфиг для LVS:
Наиболее интересные параметры здесь это timeout и reentry. В приведенной конфигурации если наш бэкенд не ответит нам в течении 6 секунд — мы туда ничего отправлять не будем. Как только наш плохиш станет отвечать нам в течении 15 секунд — можем отправлять туда трафик.
Есть еще quiesce_server — если сервер возвращается в строй, то все счетчики соединений сбрасываются в ноль и соединения начинают распределяться как после запуска службы.
У LVS есть свой механиз Актив-Пассив, который в рамках данной статьи не рассматривается, и мне не очень нравится. Я бы порекомендовал использовать Pacemaker, т.к. у него есть встроенные механизмы перекидывания службы pulse (которая как раз и отвечает за весь механизм)
Но вернемся к реальности.
Наши машинки видятся, балансировщик готов отправлять на них трафик. Сделаем на LVS
и попробуем обратиться например курлом к нашему VIP:
Давайте разбираться! Причин может быть несколько, и одна из них — iptables на lvs. Хоть он и занимается переброской трафика, но порт должен быть доступен. Вооружимся tcpdump'ом и полезем на LVS.
Запускаем и видим:
Запросы пришли, что же с ними стало дальше?
Там же
А трафик то не ходит… Беда! Идем на наши ноды с OpenVZ, заходим внутрь виртуалок и смотрим там трафик. Запросы от LVS к ним дошли, но не могут быть обработаны — protocol 4 это у нас IP-in-IP
Включаем поддержку тунелей для виртуалок
Не забываем внести их в автозагрузку —
Разрешаем нашим виртуальным машинам иметь туннельные интерфейсы:
После этого рестартим контейнеры.
Теперь нам необходимо добавить на этот (tun0) интерфейс адрес внутри контейнеров. Так и сделаем:
Почему так?
Теперь запустив tcpdump мы увидим долгожданные запросы!
192.168.1.18 — это клиент.
Запрос дошел до машины! Всем печенек! Но останавливаться рано, продолжим. Почему нам никто не отвечает? Все дело в хитрющей настройки ядра, которое проверяет обратный путь до источника — rp_filter
Выключим эту проверку для нашего интерфейса внутри контейнера:
Проверяем:
Ответы! Ответы! Но чуда все еще не происходит. Извини, Марио, твоя принцесса в другом замке. Чтобы пойти в другой замок, сперва все запишем:
Отключаем проверку rp_filter и добавим интерфейс. Внутри контейнеров:
И на нодах:
Рестартимся, чтобы подтвердить что все правильно.
В результате рестарта контейнера должна быть такая картина:
А принцесса спрятана в venet, как это не печально. Технология этого устройства накладывает следующие ограничения:
Т.е. наша нода не принимает пакеты, которые идут с левым сорсом. И теперь главный костыль — добавим этот адрес контейнеру! Пусть их будет два адреса у каждой машинки!
На нодах выполним:
Получим конечно же варнинг, что такой адрес уже есть в сетке! Но балансировка требует жертв.
Зачем нам удалять роуты — чтобы мы не вещали в сеть этот адрес и другие машины про него не знали. Т.е. формально все требования соблюдены — ответ из машинки идет с адресом 192.168.1.100, такой адрес у нее есть. Работаем!
Для упрощения работы хочу порекомендовать механизм mount скриптов в OpenVZ, но в чистом виде он нам не поможет, т.к. роут адресов добавляется после операции mount, а скрипты start выполняются внутри контейнера.
Решение пришло с форума OpenVZ
Делаем два файла (пример для одного контейнера):
Рестартим контейнер для проверки, и теперь настал тот миг — открываем 192.168.1.100 иииии… ПОБЕДА!
Еще несколько кратких заметок:
1) Самое страшное, что бывает с этой балансировкой — когда адрес, заботливо повешенный внутрь контейнера или на lo (для режима работы Direct) начинает вещать в сеть. Для предотвращения этого сценария вам поможет два инструмента — тесты настроек и arptables. Инструмент схож с iptables, но для ARP запросов. Я активно им пользуются для своих целей — мы запрещаем определенным арпам попадать в сеть.
2) Данное решение не уровня Enterprise, т.к. изобилует костылями и узкими местами. Если у вас есть возможность — используйте NAT, Direct и только потом Tunnel. Это связано с тем, что, например, в Direct — если бэкенд активен в выводе ipvsadm, то вам трафик он получит. Здесь же он может его и не получить, хотя порт считается доступным и пакеты туда полетят.
4) В нормальной виртуализации (KVM, VmWare и прочие) — проблем не возникнет, как и не возникнет с использованием veth устройств.
5) Для диагностики любых проблем с LVS — используйте tcpdump. И просто так тоже используйте :)
Спасибо за внимание!
В этой статье я хочу рассказать вам о технологии балансировки нагрузки, немного об отказоустойчивости и как все это подружить с контейнерами в OpenVZ. Будут рассмотрены основы LVS, режимы работы и настройка связки LVS c контейнерами в OpenVZ. Статья содержит в себе как теоретические аспекты работы данных технологий, так и практическую часть — проброс трафика от балансировщика внутрь контейнеров. Если это вас заинтересовало — добро пожаловать!
Для начала — ссылки на публикации по этой теме на Хабре:
Подробное описание работы LVS. Лучше не скажешь
Статья про контейнеры OpenVZ
Краткое изложение материала выше:
LVS (Linux Virtual Server) — технология, базирующая на IPVS (IP Virtual Server), которая присутствует в ядрах Linux с версии 2.4.x и новее. Является неким виртуальным свичем 4 уровня.

На данной картинке изображен LVS (сам балансировщик), виртуальный адрес, к которому происходят обращения (VIP) 192.168.1.100 и 2 сервера, выступающих в роли бэк-эндов: 192.168.1.201 и 192.168.1.202
В общем случае работает все так — мы делаем точку входа (VIP), куда приходят все запросы. Далее трафик перенаправляется к своим бэкэндам, где происходит его обработка и ответ клиенту напрямую (в схеме NAT — ответ через LVS обратно)
С методами балансировки можно ознакомиться здесь: ссылка. далее в статье считаем, что балансировка Round-Robin
Режимы работы:
- 1) Direct Много всего про него
- 2) NAT Инфромация про этот режим работы
- 3) Tunnel И про него
Чуть подробнее о каждом:
1) Direct
В данном режиме работы обработка запроса происходит по следующему сценарию:
Клиент отправляет пакет в сеть к адресу VIP. Этот пакет ловится сервером LVS, в нем подменяется MAK адрес назначения (и только он!!) на мак адрес одного из серверов бэк-энда и пакет отправляется обратно в сеть. Его получает сервер бэк-энда, обрабатывает и отправляет запрос напрямую клиенту. Клиент получает ответ на свой запрос физически с другого сервера, но подмены не видит и радостно шуршит. Внимательный читатель конечно возмутится — как сможет Real Server обработать запрос, который пришел на другой IP адрес (в пакете адрес назначения- все тот же VIP)? И будет прав, т.к. для корректной работы следует этот адрес (VIP) куда-нибудь у бэк-энда разместить, чаще всего это вешается на loopback. Таким образом совершается самая большая афера в этой технологии.
2) NAT
Самый простой режим работы. Запрос от клиента приходит на LVS, LVS перенаправляет запрос бэк-енду, тот обрабатывает запрос, отвечает обратно на LVS и тот отвечает клиенту. Идеально впишется в схему, где у вас есть шлюз, через который идет весь трафик подсети. Иначе делать НАТ в части сети будет крайне неправильно.
3) Tunnel
Является аналогом первого способа, только трафик от LVS до бэкендов инкапсулируется в пакет. Именно его мы и будем настраивать ниже, поэтому сейчас всех карт я не раскрою :)
Практика!
Установим сервер с LVS. Настраиваем на CentOS 6.6.
На чистой системе делаем
yum install piranha
За собой она потащит апач, пхп и нужный нам ipvsadm. Апач и пхп ставятся для доступа к административной веб-морде, которую я советую вам один раз посмотреть, базово все настроить и больше не заходить туда :)
После установки всех пакетов делаем
/etc/init.d/piranha-gui start ; /etc/init.d/httpd start
задаем пароль для доступа к админке:
piranha-passwd
После этого заходим по адресу IP_LVS:3636/, вводим логин(piranha) и пароль из шага выше и попадаем в админку:
Так сказать админка

Для нас сейчас интересны две вкладки — GLOBAL SETTINGS и VIRTUAL SERVERS
Переходим на GLOBAL SETTINGS и выставим режим работы Tunneling
Маленькое лирическое отступление про OpenVZ
Как вы уже наверно знаете, если работали с OpenVZ, пользователю предоставляется выбор из двух типов интерфейсов — venet и veth. Принципиальная разница между ними в том, что veth это по сути виртуальный сетевой интерфейс для каждой виртуальной машины со своим мак адресом. Venet — некий огромный свич 3 уровня, в который подключены все ваши машины.
Более подробно почитать можно вот тут
Сравнительная таблица интерфейсов со ссылки выше:
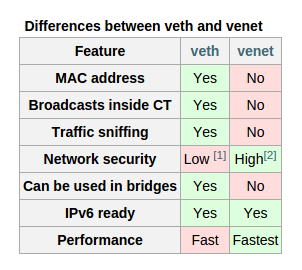
Так сложилось, что у меня на работе повсеместно используется venet, поэтому настройка производится именно на нем.
Сразу скажу — настроить LVS-Direcrt для этого типа интерфейса мне не удалось. Все стопорится на том, что нода с виртуальными машинами получает трафик, но не знает, в какую машину его отправить. Об этом я чуть подробнее остановлюсь при пробросе трафика внутрь контейнера
Более подробно почитать можно вот тут
Сравнительная таблица интерфейсов со ссылки выше:

Так сложилось, что у меня на работе повсеместно используется venet, поэтому настройка производится именно на нем.
Сразу скажу — настроить LVS-Direcrt для этого типа интерфейса мне не удалось. Все стопорится на том, что нода с виртуальными машинами получает трафик, но не знает, в какую машину его отправить. Об этом я чуть подробнее остановлюсь при пробросе трафика внутрь контейнера
На вкладке VIRTUAL SERVERS создаем один Virtual Server с адресом 192.168.1.100 и порт 80
Там же на вкладке REAL SERVER зададим два бэк енда с адресами 192.168.1.201 и 192.168.1.202 с портами 80
Подробности на скриншотах под спойлером
Скриншоты настройки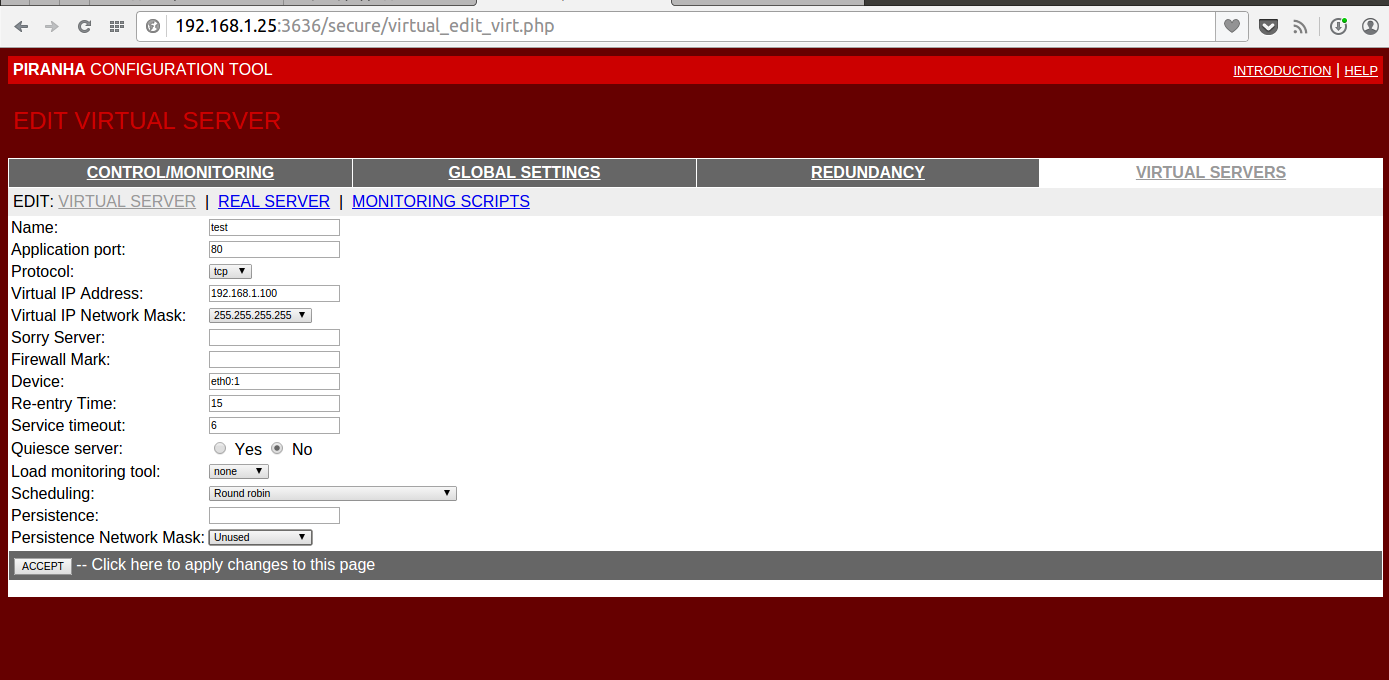
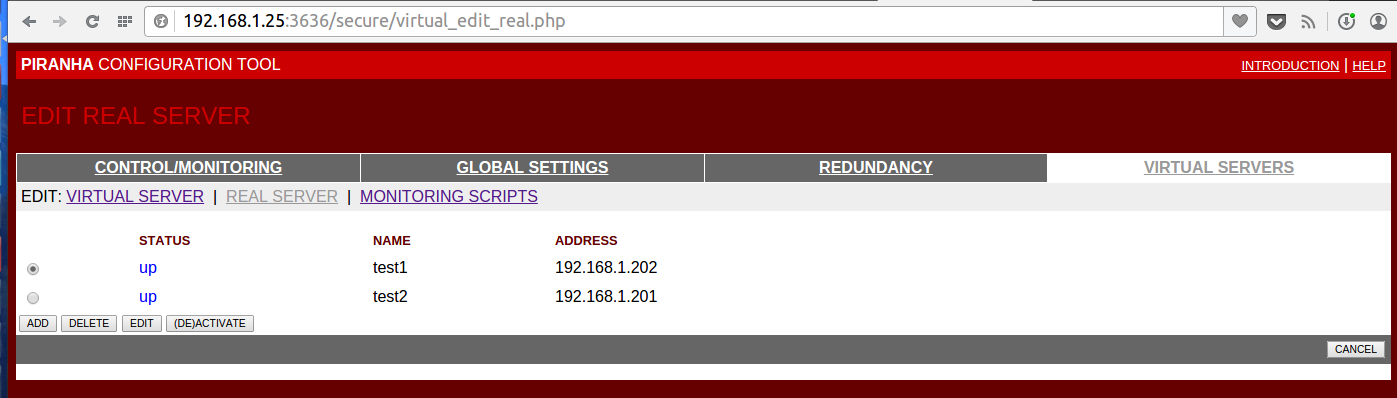


Вкладку MONITORING SCRIPTS оставим без изменений, хотя на ней можно настроить очень гибкую работу проверки доступности узлов. По умолчанию это просто запрос типа GET / HTTP/1.0 и проверка, что нам ответил именно веб-сервер.
Можно выполнять произвольные скрипты, например такие как под спойлером.
Скрипты проверки различных сервисов
Например мускуль
И проверка в LVS считается удачной, если скрипт вернул UP и не удачной, если DOWN. Сервера он выводит по результатам теста
Кусок конфига для этой проверки
#!/bin/sh
CMD=/usr/bin/mysqladmin
IS_ALIVE=`timeout 2s $CMD -h $1 -P $2 ping | grep -c "alive"`
if [ "$IS_ALIVE" = "1" ]; then
echo "UP"
else
echo "DOWN"
fi
И проверка в LVS считается удачной, если скрипт вернул UP и не удачной, если DOWN. Сервера он выводит по результатам теста
Кусок конфига для этой проверки
expect = "UP"
use_regex = 0
send_program = "/opt/admin/mysql_chesk.sh %h 9005"
Сохраняем конфиг, закрываем оконце и переходим в привычную нам консоль. Если вдруг вам стало интересно, что мы там нагенерили, то конфиг службы лежит в /etc/sysconfig/ha/lvs.cf
Смотрим текущие настройки:
ipvsadm -L -n
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.1.100:80 wlc
Не густо. Это потому что наши конечные ноды не подняты! Установка и создание контейнеров OpenVZ пропускаю, считаем что у вас волшебным образом появились два контейнера с адресами 192.168.1.201 и 192.168.1.202, а внутри любой веб сервер на 80 порту :)
Опять смотрим на вывод команды:
ipvsadm -L -n
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.1.100:80 wlc
-> 192.168.1.201:80 Tunnel 1 0 0
-> 192.168.1.202:80 Tunnel 1 0 0
Идеально! То, что нужно. Если вдруг мы выключим веб сервер на одной из нод, то наш балансировщик честно не будет слать туда трафик, пока ситуация не исправится.
Давайте подробнее взглянем на наш конфиг для LVS:
/etc/sysconfig/ha/lvs.cf
serial_no = 4
primary = 192.168.1.25
service = lvs
network = tunnel
debug_level = NONE
virtual habrahabr {
active = 1
address = 192.168.1.100 eth0:1
port = 80
send = «GET / HTTP/1.0\r\n\r\n»
expect = «HTTP»
use_regex = 0
load_monitor = none
scheduler = wlc
protocol = tcp
timeout = 6
reentry = 15
quiesce_server = 0
server test1 {
address = 192.168.1.202
active = 1
weight = 1
}
server test2 {
address = 192.168.1.201
active = 1
weight = 1
}
}
primary = 192.168.1.25
service = lvs
network = tunnel
debug_level = NONE
virtual habrahabr {
active = 1
address = 192.168.1.100 eth0:1
port = 80
send = «GET / HTTP/1.0\r\n\r\n»
expect = «HTTP»
use_regex = 0
load_monitor = none
scheduler = wlc
protocol = tcp
timeout = 6
reentry = 15
quiesce_server = 0
server test1 {
address = 192.168.1.202
active = 1
weight = 1
}
server test2 {
address = 192.168.1.201
active = 1
weight = 1
}
}
Наиболее интересные параметры здесь это timeout и reentry. В приведенной конфигурации если наш бэкенд не ответит нам в течении 6 секунд — мы туда ничего отправлять не будем. Как только наш плохиш станет отвечать нам в течении 15 секунд — можем отправлять туда трафик.
Есть еще quiesce_server — если сервер возвращается в строй, то все счетчики соединений сбрасываются в ноль и соединения начинают распределяться как после запуска службы.
У LVS есть свой механиз Актив-Пассив, который в рамках данной статьи не рассматривается, и мне не очень нравится. Я бы порекомендовал использовать Pacemaker, т.к. у него есть встроенные механизмы перекидывания службы pulse (которая как раз и отвечает за весь механизм)
Но вернемся к реальности.
Наши машинки видятся, балансировщик готов отправлять на них трафик. Сделаем на LVS
chkconfig pulse on
и попробуем обратиться например курлом к нашему VIP:
Результат
curl -vv http://192.168.1.100
* Rebuilt URL to: http://192.168.1.100/
* About to connect() to 192.168.1.100 port 80 (#0)
* Trying 192.168.1.100...
* Adding handle: conn: 0x7e9aa0
* Adding handle: send: 0
* Adding handle: recv: 0
* Curl_addHandleToPipeline: length: 1
* - Conn 0 (0x7e9aa0) send_pipe: 1, recv_pipe: 0
* Connection timed out
* Failed connect to 192.168.1.100:80; Connection timed out
* Closing connection 0
curl: (7) Failed connect to 192.168.1.100:80; Connection timed out

Давайте разбираться! Причин может быть несколько, и одна из них — iptables на lvs. Хоть он и занимается переброской трафика, но порт должен быть доступен. Вооружимся tcpdump'ом и полезем на LVS.
Запускаем и видим:
tcpdump -i any host 192.168.1.100
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 65535 bytes
13:36:09.802373 IP 192.168.1.18.37222 > 192.168.1.100.http: Flags [S], seq 3328911904, win 29200, options [mss 1460,sackOK,TS val 2106524 ecr 0,nop,wscale 7], length 0
13:36:10.799885 IP 192.168.1.18.37222 > 192.168.1.100.http: Flags [S], seq 3328911904, win 29200, options [mss 1460,sackOK,TS val 2106774 ecr 0,nop,wscale 7], length 0
13:36:12.803726 IP 192.168.1.18.37222 > 192.168.1.100.http: Flags [S], seq 3328911904, win 29200, options [mss 1460,sackOK,TS val 2107275 ecr 0,nop,wscale 7], length 0
Запросы пришли, что же с ними стало дальше?
Там же
tcpdump -i any host 192.168.1.201 or host 192.168.1.202
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 65535 bytes
13:37:08.257049 IP 192.168.1.25 > 192.168.1.201: IP 192.168.1.18.37293 > 192.168.1.100.http: Flags [S], seq 1290874035, win 29200, options [mss 1460,sackOK,TS val 2121142 ecr 0,nop,wscale 7], length 0 (ipip-proto-4)
13:37:08.257538 IP 192.168.1.201 > 192.168.1.25: ICMP 192.168.1.201 protocol 4 unreachable, length 88
13:37:09.255564 IP 192.168.1.25 > 192.168.1.201: IP 192.168.1.18.37293 > 192.168.1.100.http: Flags [S], seq 1290874035, win 29200, options [mss 1460,sackOK,TS val 2121392 ecr 0,nop,wscale 7], length 0 (ipip-proto-4)
13:37:09.256192 IP 192.168.1.201 > 192.168.1.25: ICMP 192.168.1.201 protocol 4 unreachable, length 88
А трафик то не ходит… Беда! Идем на наши ноды с OpenVZ, заходим внутрь виртуалок и смотрим там трафик. Запросы от LVS к ним дошли, но не могут быть обработаны — protocol 4 это у нас IP-in-IP
Включаем поддержку тунелей для виртуалок
На нодах:
modprobe ipip
Видим в выводе lsmod | grep ipip модули
Не забываем внести их в автозагрузку —
cd /etc/sysconfig/modules/
echo "#!/bin/sh" > ipip.modules
echo "/sbin/modprobe ipip" >> ipip.modules
chmod +x ipip.modules
Разрешаем нашим виртуальным машинам иметь туннельные интерфейсы:
vzctl set 201 --feature ipip:on --save
vzctl set 202 --feature ipip:on --save
После этого рестартим контейнеры.
Теперь нам необходимо добавить на этот (tun0) интерфейс адрес внутри контейнеров. Так и сделаем:
ifconfig tunl0 192.168.1.100 netmask 255.255.255.255 broadcast 192.168.1.100
Почему так?
Direct, Tunnel и адреса
Общее у этих двух методов то, что в конечной системе (бэкенд) добавляются VIP адреса для корректной работы. Почему так? Ответ простой: клиент обращается к фиксированному адресу и ждет от него же ответ. Если ему ответит кто-то с другого адреса, то клиент посчитает такой ответ ошибкой и просто проигнорирует его. Представьте, что вы просите позвать к телефону милую девушку Оксану, а отвечает вам сиплый голос Валентина Яковлевича.
Для Direct этапы обработки пакета выстраиваются в цепочку:
Клиент делает ARP запрос к адресу VIP, получает ответ, формирует запрос с данными, отправляет его на VIP, LVS эти пакеты поймал, поменял там MAK, отдал обратно в сеть, сетевое оборудование доставило по маку пакет бэкенду, тот стал его разворачивать начиная со второго уровня. МАК мой? Да. А IP мой? Да. Обработал и ответил с source VIP (пакет то ему предназначен) и на destination клиенту.
Для Tunnel ситуация почти аналогичная, только без подмены МАК, а полноценный инкапсулированный трафик. Бэкенд получил пакет предназначенный конкретно ему, а внутри запрос на адрес VIP, который бэкенд должен обработать и ответить.
Для Direct этапы обработки пакета выстраиваются в цепочку:
Клиент делает ARP запрос к адресу VIP, получает ответ, формирует запрос с данными, отправляет его на VIP, LVS эти пакеты поймал, поменял там MAK, отдал обратно в сеть, сетевое оборудование доставило по маку пакет бэкенду, тот стал его разворачивать начиная со второго уровня. МАК мой? Да. А IP мой? Да. Обработал и ответил с source VIP (пакет то ему предназначен) и на destination клиенту.
Для Tunnel ситуация почти аналогичная, только без подмены МАК, а полноценный инкапсулированный трафик. Бэкенд получил пакет предназначенный конкретно ему, а внутри запрос на адрес VIP, который бэкенд должен обработать и ответить.
Теперь запустив tcpdump мы увидим долгожданные запросы!
tcpdump -i any host 192.168.1.18
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 65535 bytes
14:03:28.907670 IP 192.168.1.18.38850 > 192.168.1.100.http: Flags [S], seq 3110076845, win 29200, options [mss 1460,sackOK,TS val 2516581 ecr 0,nop,wscale 7], length 0
14:03:29.905359 IP 192.168.1.18.38850 > 192.168.1.100.http: Flags [S], seq 3110076845, win 29200, options [mss 1460,sackOK,TS val 2516831 ecr 0,nop,wscale 7], length 0
192.168.1.18 — это клиент.
Запрос дошел до машины! Всем печенек! Но останавливаться рано, продолжим. Почему нам никто не отвечает? Все дело в хитрющей настройки ядра, которое проверяет обратный путь до источника — rp_filter
Выключим эту проверку для нашего интерфейса внутри контейнера:
echo 0 > /proc/sys/net/ipv4/conf/tunl0/rp_filter
Проверяем:
tcpdump -i any host 192.168.1.18
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 65535 bytes
14:07:03.870449 IP 192.168.1.18.39051 > 192.168.1.100.http: Flags [S], seq 89280152, win 29200, options [mss 1460,sackOK,TS val 2570336 ecr 0,nop,wscale 7], length 0
14:07:03.870499 IP 192.168.1.100.http > 192.168.1.18.39051: Flags [S.], seq 593110812, ack 89280153, win 14480, options [mss 1460,sackOK,TS val 3748869 ecr 2570336,nop,wscale 7], length 0
Ответы! Ответы! Но чуда все еще не происходит. Извини, Марио, твоя принцесса в другом замке. Чтобы пойти в другой замок, сперва все запишем:
Отключаем проверку rp_filter и добавим интерфейс. Внутри контейнеров:
echo "net.ipv4.conf.tunl0.rp_filter = 0" >> /etc/sysctl.conf
echo "ifconfig tunl0 192.168.1.100 netmask 255.255.255.255 broadcast 192.168.1.100" >> /etc/rc.local
И на нодах:
echo "net.ipv4.conf.venet0.rp_filter = 0" >> /etc/sysctl.conf
Рестартимся, чтобы подтвердить что все правильно.
В результате рестарта контейнера должна быть такая картина:
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: venet0: <BROADCAST,POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN
link/void
inet 127.0.0.1/32 scope host venet0
inet 192.168.1.202/32 brd 192.168.1.202 scope global venet0:0
3: tunl0: <NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN
link/ipip 0.0.0.0 brd 0.0.0.0
inet 192.168.1.100/32 brd 192.168.1.100 scope global tunl0
cat /proc/sys/net/ipv4/conf/tunl0/rp_filter
0
А принцесса спрятана в venet, как это не печально. Технология этого устройства накладывает следующие ограничения:
Venet drop ip-packets from the container with a source address, and in the container with the destination address, which is not corresponding to an ip-address of the container.
Т.е. наша нода не принимает пакеты, которые идут с левым сорсом. И теперь главный костыль — добавим этот адрес контейнеру! Пусть их будет два адреса у каждой машинки!
Иллюстрация такого решения

На нодах выполним:
vzctl set 201 --ipadd 192.168.1.100 --save
vzctl set 202 --ipadd 192.168.1.100 --save
и тут же на обоих нодах
ip ro del 192.168.1.100 dev venet0 scope link
Получим конечно же варнинг, что такой адрес уже есть в сетке! Но балансировка требует жертв.
Зачем нам удалять роуты — чтобы мы не вещали в сеть этот адрес и другие машины про него не знали. Т.е. формально все требования соблюдены — ответ из машинки идет с адресом 192.168.1.100, такой адрес у нее есть. Работаем!
Для упрощения работы хочу порекомендовать механизм mount скриптов в OpenVZ, но в чистом виде он нам не поможет, т.к. роут адресов добавляется после операции mount, а скрипты start выполняются внутри контейнера.
Решение пришло с форума OpenVZ
Делаем два файла (пример для одного контейнера):
cat /etc/vz/conf/202.mount
#!/bin/bash
. /etc/vz/start_stript/202.sh &
disown
exit 0
cat /etc/vz/start_stript/202.sh
#!/bin/bash
_sleep() {
sleep 4
status=(`/usr/sbin/vzctl status 202`)
x=1
until [ $x == 6 ] ; do
sleep 1
if [ ${status[4]} == "running" ] ; then
ip ro del 192.168.1.100 dev venet0 scope link
exit 0
else
x=`expr $x + 1`
fi
done
}
_sleep
И делаем исполняемыми:
chmod +x /etc/vz/start_stript/202.sh
chmod +x /etc/vz/conf/202.mount
Рестартим контейнер для проверки, и теперь настал тот миг — открываем 192.168.1.100 иииии… ПОБЕДА!
Еще несколько кратких заметок:
1) Самое страшное, что бывает с этой балансировкой — когда адрес, заботливо повешенный внутрь контейнера или на lo (для режима работы Direct) начинает вещать в сеть. Для предотвращения этого сценария вам поможет два инструмента — тесты настроек и arptables. Инструмент схож с iptables, но для ARP запросов. Я активно им пользуются для своих целей — мы запрещаем определенным арпам попадать в сеть.
2) Данное решение не уровня Enterprise, т.к. изобилует костылями и узкими местами. Если у вас есть возможность — используйте NAT, Direct и только потом Tunnel. Это связано с тем, что, например, в Direct — если бэкенд активен в выводе ipvsadm, то вам трафик он получит. Здесь же он может его и не получить, хотя порт считается доступным и пакеты туда полетят.
4) В нормальной виртуализации (KVM, VmWare и прочие) — проблем не возникнет, как и не возникнет с использованием veth устройств.
5) Для диагностики любых проблем с LVS — используйте tcpdump. И просто так тоже используйте :)
Спасибо за внимание!