Работая с местным госпиталем, специалисты Массачусетского технологического института создали вычислительную модель, направленную на автоматическое определение онкологического заболевания путем изучения тысяч данных из предыдущих отчетов о патологии.

Исследователи сфокусировались на трех типах лимфомы, самого распространенного вида онкологического заболевания, имеющего 50 различных подтипов, сложных для определения. По данным одного из соавторов исследования, от 5% до 15% случаев лимфому не ставят или неправильно классифицируют, что ставит под угрозу правильность выбранного лечения.
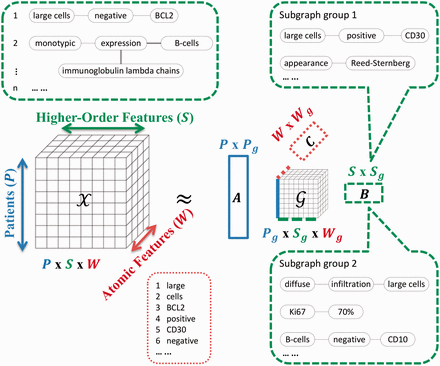
Извлечение медицинских данных из электронных записей требует автоматизированного подхода и борьбы с ограничениями масштабируемости. Система должна работать с любым количеством данных, быть понятной для врача — в идеале без дополнительного обучения, то есть выдавать результат на естественном языке. Метод SANTF (subgraph augmented non-negative tensor factorization) включает в себя создание объёмной таблицы, в которую вносятся данные из сотен медицинских записей для поиска синтаксических/семантических зависимостей, часто встречающихся слов и понятий, соответствующих результатам анализов, чтобы связать записи с конкретным подтипом лимфомы.
Конечная цель проекта — получить возможность обрабатывать с помощью компьютерной модели миллионы случаев, чтобы автоматически определять шанс наличия заболевания у пациента.
Исследователи сфокусировались на трех типах лимфомы, самого распространенного вида онкологического заболевания, имеющего 50 различных подтипов, сложных для определения. По данным одного из соавторов исследования, от 5% до 15% случаев лимфому не ставят или неправильно классифицируют, что ставит под угрозу правильность выбранного лечения.
Извлечение медицинских данных из электронных записей требует автоматизированного подхода и борьбы с ограничениями масштабируемости. Система должна работать с любым количеством данных, быть понятной для врача — в идеале без дополнительного обучения, то есть выдавать результат на естественном языке. Метод SANTF (subgraph augmented non-negative tensor factorization) включает в себя создание объёмной таблицы, в которую вносятся данные из сотен медицинских записей для поиска синтаксических/семантических зависимостей, часто встречающихся слов и понятий, соответствующих результатам анализов, чтобы связать записи с конкретным подтипом лимфомы.
Конечная цель проекта — получить возможность обрабатывать с помощью компьютерной модели миллионы случаев, чтобы автоматически определять шанс наличия заболевания у пациента.
Комментарии (2)

Vinchi
27.04.2015 20:08Есть еще каталог генов. Думаю с этим инструментом будет точнее.
elementy.ru/news/432446
sergehog
Sparse overcomplete representations в действии. Только не понятно, они что данные лабараторных тестов (анализов крови/мочи и пр.) игнорируют? Анализируют только слова в анамнезе?
В любом случае такая система должна работать лучше чем «Доктор Хаус» или любой другой маститый профессор медецины. Доказательная медицина — это круто!