Давайте проведем ликбез и вместе посмотрим, как же работают эти джойны, и даже сами реализуем парочку алгоритмов.
Постановка задачи
Людям, которые утверждают, что много и плотно работали с SQL, я задаю на собеседованиях вот такую задачу.
Есть SQL команда
SELECT
left.K,
left.V1,
right.V2
FROM left
JOIN right
ON left.K = right.K;
Нужно выполнить то же самое на Java, т.е. реализовать метод
<K, V1, V2> List<Triple<K, V1, V2>> join(List<Pair<K, V1>> left, List<Pair<K, V2>> right);
Я не прошу прям закодить реализацию, но жду хотя бы устного объяснения алгоритма.
Дополнительно я спрашиваю, что нужно изменить в сигнатуре и реализации, чтобы сделать вид, что мы работаем с индексами.
Давайте сначала разберемся, для чего нам вообще думать об устройстве джойнов?
- Знать теорию полезно из чисто познавательных соображений.
- Если вы различаете типы джойнов, то план выполнения запроса, который получается командой EXPLAIN, больше не выглядит для вас как набор непонятных английских слов. Вы можете видеть в плане потенциально медленные места и оптимизировать запрос переписыванием или хинтами.
- В новомодных аналитических инструментах поверх Hadoop планировщик запросов или малость туповат (см. Cloudera Impala), или его вообще нет (см. Twitter Scalding, Spark RDD). В последнем случае приходится собирать запрос вручную из примитивных операций.
Наконец, есть риск, что однажды вы попадете на собеседование ко мне или к другому зануде.Но на самом деле, статья не про собеседования, а про операцию JOIN.
Nested Loops Join
Самый базовый алгоритм объединения двух списков сейчас проходят в школах. Суть очень простая — для каждого элемента первого списка пройдемся по всем элементам второго списка; если ключи элементов вдруг оказались равны — запишем совпадение в результирующую таблицу. Для реализации этого алгоритма достаточно двух вложенных циклов, именно поэтому он так и называется.
public static <K, V1, V2> List<Triple<K, V1, V2>> nestedLoopsJoin(List<Pair<K, V1>> left, List<Pair<K, V2>> right) {
List<Triple<K, V1, V2>> result = new ArrayList<>();
for (Pair<K, V1> leftPair: left) {
for (Pair<K, V2> rightPair: right) {
if (Objects.equals(leftPair.k, rightPair.k)) {
result.add(new Triple<>(leftPair.k, leftPair.v, rightPair.v));
}
}
}
return result;
}
Основной плюс этого метода — полное безразличие к входным данным. Алгоритм работает для любых двух таблиц, не требует никаких индексов и перекладываний данных в памяти, а также прост в реализации. На практике это означает, что достаточно просто бежать по диску двумя курсорами и периодически выплёвывать в сокет совпадения.
Однако ж, фатальный минус алгоритма — высокая временная сложность O(N*M) (квадратичная асимптотика, если вы понимаете, о чем я). Например, для джойна пары небольших таблиц в 100к и 500к записей потребуется сделать аж 100.000 * 500.000 = 50.000.000.000 (50 млрд) операций сравнения. Запросы с таким джойном будут выполняться невежливо долго, часто именно они — причина беспощадных тормозов кривеньких самописных CMS’ок.
Современные РСУБД используют nested loops join в самых безнадежных случаях, когда не удается применить никакую оптимизацию.
UPD. zhekappp и potapuff поправляют, что nested loops эффективен для малого числа строк, когда разворачивать какую-либо оптимизацию выйдет дороже, чем просто пробежаться вложенным циклом. Есть класс систем, для которых это актуально.
Hash Join
Если размер одной из таблиц позволяет засунуть ее целиком в память, значит, на ее основе можно сделать хеш-таблицу и быстренько искать в ней нужные ключи. Проговорим чуть подробнее.
Проверим размер обоих списков. Возьмем меньший из списков, прочтем его полностью и загрузим в память, построив HashMap. Теперь вернемся к большему списку и пойдем по нему курсором с начала. Для каждого ключа проверим, нет ли такого же в хеш-таблице. Если есть — запишем совпадение в результирующую таблицу.
Временная сложность этого алгоритма падает до линейной O(N+M), но требуется дополнительная память.
public static <K, V1, V2> List<Triple<K, V1, V2>> hashJoin(List<Pair<K, V1>> left, List<Pair<K, V2>> right) {
Map<K, V2> hash = new HashMap<>(right.size());
for (Pair<K, V2> rightPair: right) {
hash.put(rightPair.k, rightPair.v);
}
List<Triple<K, V1, V2>> result = new ArrayList<>();
for (Pair<K, V1> leftPair: left) {
if (hash.containsKey(leftPair.k)) {
result.add(new Triple<>(leftPair.k, leftPair.v, hash.get(leftPair.k)));
}
}
return result;
}
Что важно, во времена динозавров считалось, что в память нужно загрузить правую таблицу, а итерироваться по левой. У нормальных РСУБД сейчас есть статистика cardinality, и они сами определяют порядок джойна, но если по какой-то причине статистика недоступна, то в память грузится именно правая таблица. Это важно помнить при работе с молодыми корявыми инструментами типа Cloudera Impala.
Merge Join
А теперь представим, что данные в обоих списках заранее отсортированы, например, по возрастанию. Так бывает, если у нас были индексы по этим таблицам, или же если мы отсортировали данные на предыдущих стадиях запроса. Как вы наверняка помните, два отсортированных списка можно склеить в один отсортированный за линейное время — именно на этом основан алгоритм сортировки слиянием. Здесь нам предстоит похожая задача, но вместо того, чтобы склеивать списки, мы будем искать в них общие элементы.
Итак, ставим по курсору в начало обоих списков. Если ключи под курсорами равны, записываем совпадение в результирующую таблицу. Если же нет, смотрим, под каким из курсоров ключ меньше. Двигаем курсор над меньшим ключом на один вперед, тем самым “догоняя” другой курсор.
public static <K extends Comparable<K>, V1, V2> List<Triple<K, V1, V2>> mergeJoin(
List<Pair<K, V1>> left,
List<Pair<K, V2>> right
) {
List<Triple<K, V1, V2>> result = new ArrayList<>();
Iterator<Pair<K, V1>> leftIter = left.listIterator();
Iterator<Pair<K, V2>> rightIter = right.listIterator();
Pair<K, V1> leftPair = leftIter.next();
Pair<K, V2> rightPair = rightIter.next();
while (true) {
int compare = leftPair.k.compareTo(rightPair.k);
if (compare < 0) {
if (leftIter.hasNext()) {
leftPair = leftIter.next();
} else {
break;
}
} else if (compare > 0) {
if (rightIter.hasNext()) {
rightPair = rightIter.next();
} else {
break;
}
} else {
result.add(new Triple<>(leftPair.k, leftPair.v, rightPair.v));
if (leftIter.hasNext() && rightIter.hasNext()) {
leftPair = leftIter.next();
rightPair = rightIter.next();
} else {
break;
}
}
}
return result;
}
Если данные отсортированы, то временная сложность алгоритма линейная O(M+N) и не требуется никакой дополнительной памяти. Если же данные не отсортированы, то нужно сначала их отсортировать. Из-за этого временная сложность возрастает до O(M log M + N log N), плюс появляются дополнительные требования к памяти.
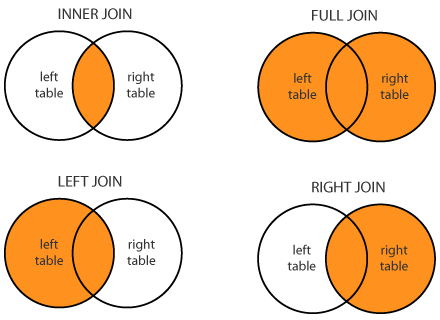
Outer Joins
Вы могли заметить, что написанный выше код имитирует только INNER JOIN, причем рассчитывает, что все ключи в обоих списках уникальные, т.е. встречаются не более, чем по одному разу. Я сделал так специально по двум причинам. Во-первых, так нагляднее — в коде содержится только логика самих джойнов и ничего лишнего. А во-вторых, мне очень хотелось спать. Но тем не менее, давайте хотя бы обсудим, что нужно изменить в коде, чтобы поддержать различные типы джойнов и неуникальные значения ключей.
Первая проблема — неуникальные, т.е. повторяющиеся ключи. Для повторяющихся ключей нужно порождать декартово произведение всех соответствющих им значений.
В Nested Loops Join почему-то это работает сразу.
В Hash Join придется заменить HashMap на MultiHashMap.
Для Merge Join ситуация гораздо более печальная — придется помнить, сколько элементов с одинаковым ключом мы видели.
Работа с неуникальными ключами увеличивает асимптотику до O(N*m+M*n), где n и m — среднее записей на ключ в таблицах. В вырожденном случае, когда n=N и m=M, операция превращается в CROSS JOIN.
Вторая проблема — надо следить за ключами, для которых не нашлось пары.
Для Merge Join ключ без пары видно сразу для всех направлений JOIN’а.
Для Hash Join сразу можно увидеть нехватку соответствующих ключей при джойне слева. Для того, чтобы фиксировать непарные ключи справа, придется завести отдельный флаг “есть пара!” для каждого элемента хеш-таблицы. После завершения основного джойна надо будет пройти по всей хеш-таблице и добавить в результат ключи без флага пары.
Для Nested Loops Join ситуация аналогичная, причем все настолько просто, что я даже осилил это закодить:
public static <K, V1, V2> List<Triple<K, V1, V2>> nestedLoopsJoin(
List<Pair<K, V1>> left,
List<Pair<K, V2>> right,
JoinType joinType
) {
// Массив для обозначения ключей из правого списка, которым не нашлось пары в левом
BitSet rightMatches = new BitSet(right.size());
List<Triple<K, V1, V2>> result = new ArrayList<>();
for (Pair<K, V1> leftPair: left) {
// Флаг для обозначения ключей в левом списке, которым не нашлось пары в правом
boolean match = false;
for (ListIterator<Pair<K, V2>> iterator = right.listIterator(); iterator.hasNext(); ) {
Pair<K, V2> rightPair = iterator.next();
if (Objects.equals(leftPair.k, rightPair.k)) {
result.add(new Triple<>(leftPair.k, leftPair.v, rightPair.v));
// Отмечаем пары
match = true;
rightMatches.set(iterator.previousIndex(), true);
}
}
// Заполняем несоответствия в левом списке
if ((joinType == JoinType.LEFT || joinType == JoinType.FULL) && !match) {
result.add(new Triple<>(leftPair.k, leftPair.v, null));
}
}
// Заполняем несоответствия в правом списке
if (joinType == JoinType.RIGHT || joinType == JoinType.FULL) {
for (int i = 0; i < right.size(); ++i) {
if (!rightMatches.get(i)) {
Pair<K, V2> rightPair = right.get(i);
result.add(new Triple<>(rightPair.k, null, rightPair.v));
}
}
}
return result;
}
Морализаторское послесловие
Если вы дочитали досюда, значит, статья показалась вам интересной. А значит, вы простите мне небольшую порцию нравоучений.
Я действительно считаю, что знания РСУБД на уровне SQL абсолютно не достаточно, чтобы считать себя профессиональным разработчиком ПО. Профессионал должен знать не только свой код, но и примерное устройство соседей по стеку, т.е. 3rd-party систем, которые он использует — баз данных, фреймворков, сетевых протоколов, файловых систем. Без этого разработчик вырождается до кодера или оператора ЭВМ, и в по настоящему сложных масштабных задачах становится бесполезен.
UPD. Несмотря на это послесловие, статья, на самом деле, про JOIN'ы.
Дополнительные материалы
- Роскошная статья про устройство РСУБД
- Роскошная книга про алгоритмы. Полезно полистать перед собеседованием.
Disclaimer: вообще-то, я обещал еще одну статью про Scalding, но предыдущая не вызвала большого интереса у публики. Из-за этого тему решено было сменить.
Комментарии (127)

Sergunka
28.02.2016 09:06-4Невольно вспомнился Лао Дзы
Keep sharpening your knife and it will blunt.
Хотя тренд беспорно правильный любое знание рентабельно. В конце концов можно кого-то порадовать на интервью смекалкой и неплохим опытом.
fogone
28.02.2016 10:12+25Он же вроде был китайским философом, а цитата почему-то на английском. Не логичнее ли было бы или по-русски её написать или по-китайски в крайнем случае?

Mikanor
04.03.2016 15:37+2Один из вариантов перевода на русский язык:
Стремясь заточить лезвие до предела, портишь его
Хотя в оригинале имелось введу про умеренность — не стоит выжимать из вещей их предел. Соблюдай баланс. Дао Дэ Цзин полон таких мыслей.Sergunka
06.03.2016 06:51+1Тот вариант который ближе по контексту к статье я услышал лет тридцать пять назад от представителя новосибирской научной школы. Полагаю, что перевод был сделан довольно давно и сказавший ссылался на перевод на Лорошфуко "Максимы" (Сборник афоризмов). Есть ли это в Максимах у меня не было времени проверить. Интересно, что англофонов давняя нелюбовь к франкофонам так, что фраза прижилась в английском языке как афоризм Лао Дзы.
Но тем не менее в русском языке это звучало в тот момент так, что на мой взгляд довольно ближе к англискому оригиналу с передачей ироничной коннотации присущей Лао Дзы
Если острый нож долго оттачивать он станет тупым.
michael_vostrikov
28.02.2016 09:29+36А для того, чтобы вскипятить чайник, надо в подробностях знать термодинамику. А для того, чтобы пользоваться компьютером, надо знать электротехнику и электронику. Сколько программистов может вспомнить без гугла законы Кирхгофа?
А для того, чтобы программировать, надо знать как работает защищенный режим и виртуальная память. А заодно загрузка с жесткого диска с чтением нулевого сектора и планировщик задач. А уж структуру IP-пакета точно должен знать каждый. А также уметь рассказать обо всем этом на собеседовании, и реализовать программно без IDE в Google Docs.
NLO
28.02.2016 09:32НЛО прилетело и опубликовало эту надпись здесь
michael_vostrikov
28.02.2016 10:27+18В чем именно ложность? Вы не используете ОС или сеть?
Наука и техника развиваются много лет и многими людьми. Невозможно знать все в подробностях.
Профессионал должен знать не только свой код, но и примерное устройство соседей по стеку
Вся разница в понимании слова "примерное". Например, в моем понимании "волшебные деревья и индексы" — это и есть примерное устройство (даже с учетом того, что на собеседовании код для nested loops я бы пожалуй написал). Потому что у меня есть конкретное выражение "LEFT JOIN" в синтаксисе, и влиять на его работу я не могу. Когда я пишу запрос с джойнами, я мыслю немного другими категориями, чем вложенные циклы и выражения вида "Triple<K, V1, V2>" — например, множество, тип связи, направление (с какой стороны "1", с какой "много").michael_vostrikov
28.02.2016 10:27+7Кстати, вопрос к автору. Что именно вы ожидаете услышать в устном ответе на вопрос "как внутри работает JOIN в SQL"? Приведите конкретный пример ответа, пожалуйста. Просто чтобы знать, что ожидает услышать интервьюер.
michael_vostrikov
28.02.2016 10:47+1То есть понятно, что вся статья про это, но в статье в основном код и пояснения к нему.

fediq
28.02.2016 11:54Для начала, меня устроит устное описание любого из вышеприведенных алгоритмов. Например, нормальный ответ:
"Берет все записи из левой таблицы и для каждой из них находит соответствующую запись в правой таблице."
Уже понятно, что человек не мыслит категориями волшебных коробок.
Далее я попрошу оценить асимптотику этого решения и предложить улучшения.
janson
28.02.2016 12:16+1Если вы ищете программиста, который будет работать с внутренностями БД — тогда есть смысл оценить понимание на уровне написания код для JOIN.
Если вы ищете программиста, который будет работать с БД снаружи, то навык написания кода для реализации внутренних алгоритмов БД уже не является необходимым.
Хотя, несомненно, при таком уровне погружения, цена программиста может вырасти ощутимо.
С другой стороны, для большинства проектов найти программиста, который понимает как написать запрос с использованием JOIN, чтобы получить нужный результат — это уже приемлимый результат.
Если он при этом ещё понимает, как использовать агрегирующие функции с подзапросами — вообще хорошо.
Если же при этом отсеивать тех, кто не может быстро на коленке написать код для реализации алгоритмов JOIN во всех его ипостасях — тогда, на мой взгляд, подавляющее большинство проектов так и не добралось бы до релиза.
Например, нормальный ответ:
«Берет все записи из левой таблицы и для каждой из них находит соответствующую запись в правой таблице.»
Т.е. такой человек пройдёт собеседование? Или всё же без умения написать соответствующий код у него нет шансов?fediq
28.02.2016 12:35А, так вот, что всех испугало! Дописал пояснение, спасибо.
Я не надеюсь, что кто-нибудь мне с ходу напишет код сложнее, чем nested loops. Во-первых, на собеседовании программисты-интроверты находятся в состоянии сильного стресса и "тупят". А во-вторых, на реализацию более сложного алгоритма банально не хватит времени — я писал реализацию merge join для статьи почти полчаса, хотя точно знал, что делать.
На собеседовании такой роскоши не будет, поэтому мы просто поговорим.
Что касается того, кого я ищу, то на самом деле, мне плевать на внутренности РСУБД. Я просто пытаюсь понять, насколько глубоко человек изучил те технологии, с которыми он работал. Т.е. если у вас в проекте было много low-level NIO, а с базой вы почти не работали — я не буду ожидать от вас знания Merge Join, но захочу услышать про селекторы и грин-треды.
merlin-vrn
28.02.2016 21:56+8Глубокая мудрость реляционной алгебры как раз несёт идею, что "мы определяем, что мы хотим получить, никак не фиксируя непосредственно алгоритм получения". Реальные РСУБД конечно далеки от этого идеала (уже индексы — это шаг в сторону), но всё-таки стремятся к нему.
В общем, в детстве, на паскале даже я писал этот ваш нестед лупс, я тогда не знал, что это вообще такое — рсубд. Подобный алгоритм способен для себя переизобрести и реализовать интересующийся (не хватающий звёд с неба) пятнадцатилетний подросток, когда задача встаёт в нормальном варианте, вроде: есть два списка, нужно найти все такие записи в левой таблице, для которых есть соответствующая запись в правой таблице, и вывести их вместе. Может быть, я сейчас косноязычно сформулировал, не в этом суть — суть в том, что в подобной формулировке никто не запутывает человека терминами из технологии СУБД и тем более, реляционной алгебры.
Если бы вопрос "как работает SQL JOIN" мне задали на собеседовании, именно в такой форме, я бы реально впал в ступор. Подобную формулировку я не могу расценивать иначе как попытку сбить с толку. Я вроде бы пришёл не разрабатывать СУБД, а использовать её. В таком контексте я не должен и не буду изобретать то, что, как подразумевается, за меня уже давно сделали умные люди, реализовали и оно там отлично работает. И это не признак непонимания, как оно там устроено, или неумения пользоваться инструментом, а очень плохо заданный вопрос, неуместный и некорректно сформулированный. Такие вопросы ещё называют "глупыми", и таких вопросов дурак может задать столько, что и сотня мудрецов не ответит.
Вы всё ещё имеете шансы найти горе-программистов, которые ответят вам на вопрос, а потом и реализуют это всё в виде хранимой процедуры, потому, что они не осилили способность самой СУБД соединять таблицы и всегда делают соединения процедурами. А когда их спросят, что это за хрень они тут понаписали, они сошлются на вас — мол, вон, даже на собеседовании это было и надо было делать так!
А так делать не надо.
merlin-vrn
28.02.2016 22:16+11Я должен отметить, что в общем статья была бы неплоха, если бы из неё убрать весь бред c собеседованием. 100% ваших тупящих просто не поняли, чего от них хотят.
Вот просто обзор конкретных алгоритмов, которые там под капотом, с подтекстом "ну конечно всё это СУБД делает за тебя, но неплохо бы знать, как именно она это там делает" — это очень хорошо и важно.
unv_unv
01.03.2016 20:57+1Тогда лучше спрашивать не "как реализована операция соединения в СУБД", а "как бы вы реализовали операцию соединения". Это переключает мозг с паники по поводу недостатка эрудиции на творческий поиск.

Zibx
28.02.2016 14:41-3Без представления или умения на ходу прикинуть что же там внутри — программист не сможет говорить о сложности алгоритма. Без разговора о сложности, сугубо на мой взгляд, программист является профнепригодным.

bolk
28.02.2016 10:45-1Потому что у меня есть конкретное выражение «LEFT JOIN» в синтаксисе, и влиять на его работу я не могу.
Можете, конечно. Хинты, индексы, переписать запрос — вот эти способы.michael_vostrikov
28.02.2016 10:51+6Для этого надо знать особенности хинтов, индексов и анализатора запросов конкретной СУБД. Уметь реализовать join в программном коде для этого не нужно.
NLO
28.02.2016 19:42НЛО прилетело и опубликовало эту надпись здесь
michael_vostrikov
28.02.2016 20:02Что мне мешает запустить EXPLAIN, увидеть там nested loops, пойти в документацию и прочитать там, что это значит, какие могут быть варианты, и как на это влиять через синтаксис и настройки?
NLO
28.02.2016 20:06НЛО прилетело и опубликовало эту надпись здесь
michael_vostrikov
28.02.2016 20:36+7Вы, по-моему, потеряли нить разговора. Вы и автор говорите о том, что для работы с базой данных нужно обязательно знать типы джойнов и уметь реализовать их вручную, иначе разработчик это не разработчик, а оператор ЭВМ. А я говорю, что для работы с базой данных надо знать ее интерфейс, а не реализацию, и что этого достаточно во многих случаях. И что всю необходимую информацию можно узнать по ходу дела, когда это действительно понадобится. И что если человек встретился с вами на собеседовании раньше, чем со сложным запросом, для оптимизации которого надо знать типы реализации джойнов, то это не значит, что он не умеет ими пользоваться, и можно называть его оператором ЭВМ, а не разработчиком.
И да, перестаньте, пожалуйста, разговаривать с собеседником в подобном тоне. Я вас не оскорблял.
orcy
28.02.2016 17:44+1Некоторые аналогии достаточно ложные, потому как вы скачете через несколько уровней абстракции. Когда вы в своем приложение работаете с БД и вам важно выстроить правильную архитектуру приложения и модели данных для вашей нагрузки, имеет смысл инвестировать в понимание того как эта БД работает внутри. При этом не так важно знать протоколы SATA-3 по которому данные пойдут между памятью и жестким диском. Тут здравый смысл вполне помощник что нужно изучать, а что нет.
Абстракции создают комфорт работы, но забивать на их устройство можно если не предполагается никаких проблем с производительностью и ресурсами.

CGS
28.02.2016 10:00+4Если продолжить аналогии, для того что бы быть в сознании, нужно понимать как оно работает :)

musicriffstudio
28.02.2016 09:53+28Уважаемый Фёдор, а вы сами-то пройдёте собеседование с подобным экспертом?
Сейчас кризис, всё может быть. Например развалится ваша контора, пойдёте в другую, а там захотят от вас услышать чёткий ответ на простой вопрос: "Зачем использовать cross join в SQLite?". Ну ка, быстро, без гугла.
Абсолютное большинство "специалистов" проводит собеседование сходным образом — вы даже не в состоянии заранее выслать список тем о которых идёт разговор. И ожидаете ответов которые в точности совпадают с вашим мнением.
Ну и подойдёт вам только кандидат который уже проработал у вас на этой же должности два года, т.е. собственный работник который недавно уволился т.к. з/п маленькая.bolk
28.02.2016 10:42+2Я иногда спрашиваю и то, чего не знаю, особенно если вижу, что кандидат крут. Перед этим сразу говорю «я не знаю правильного ответа, мне интересно ваше мнение».
fediq
28.02.2016 12:03-4Я не требую досконального знания каких-либо деталей. Но если кандидат заявляет, что он три года оптимизировал запросы в Oracle, он должен понимать вывод EXPLAIN'а, а значит, должен различать типы JOIN'ов. Если это не так, он либо дилетант, либо лжец.
При этом я готов простить человеку даже непонимание разницы между float и double, если в остальном он молодец.
Дилетанты нам не нужны, а недостающие знания мы всегда подкачаем.musicriffstudio
28.02.2016 12:20+8вау. Ну, к собеседованиям вас точно нельзя подпускать.
orcy
28.02.2016 17:05+1А что именно вам показалось неправильным? По моему все логично. Насчет подпускать или нет — практика критерий истинности. Если автор с помощью своего метода ведения собеседований набрал людей которые его устраивают, то у него нет причин не самого себя не подпускать.
musicriffstudio
28.02.2016 17:27+1а его начальство те, кого он набрал, устраивают?
orcy
28.02.2016 18:01-1Этого я не могу знать, как впрочем и своего предположения. Все что я хотел сказать, это то что оценить мастерство ведения собеседования можно в конечном итоге по тому, как работают люди принятые на работу, ответствуют ли они ожиданиям или нет.
musicriffstudio
28.02.2016 19:06+4не согласен.
Автор предлагает оценивать степень владения азами оптимизации БД по умению рисовать какие-то циклы на Java, причём делает это в безапелляционной форме. Он ошибается в техническом плане сам, кроме того, тех кто не согласен называет дилетантами и лжецами.
Двойное попадание, тут уж никаких сомнений быть не может.fediq
28.02.2016 19:12Где я ошибаюсь?
Про дилетантов и лжецов был вполне конкретный контекст. Про согласен/не согласен я ничего не говорил.
Mixim333
28.02.2016 10:00-1А я всегда думал, что JOIN'ы работают про принципу: «Сперва соединим все со всем, а потом наложим фильтр ON». Сколько ни разговаривал с различными сертифицированными специалистами всяких Oracle, они говорили примерно следующее: «Если Table1 10млн записей, а в Table2 1тыс записей и нам нужно вывести объединенные данные Table1 и Table2, соединенные по ключу Table1.Key1=Table2.Key1, то лучше это делать не JOIN'ом, а с помощью WHERE: Table1.Key1=Table2.Key1 (+) — потребуется меньше памяти и будет работать быстрее». Они ошибались?
Throwable
28.02.2016 14:16+3Это еруйня. С верии 10 Oracle планировщик (Cost-based optimizer) не различает вообще как вы соединяете таблицы: JOIN-ом, WHERE, используете IN или SELECT FROM subquery. Также нет разницы между порядком указания таблиц, даже если их объем сильно различается. Планировщик все приводит к стандартному виду и оптимизирует на основе статистики. Если Вы старую версию Oracle, либо указываете в запросе явно использовать Rule-based optimizer, тогда да — запросы выполняются на основе списка правил. В редких случаях это имеет смысл.
Optik
28.02.2016 14:43+1Причем в 11ом rule-based уже и нет совсем, если правильно помню.
Throwable
29.02.2016 11:42Он там все еще есть, но отключается автоматически, если в запросе используется какая-то несовместимая с ним фича.
CBO вообще не такой умный как кажется, поэтому нам пришлось для некоторых запросов ставить /*+Rule*/, чтобы выполнение было всегда оптимальным и предсказуемым. CBO почему-то для некоторых запросов периодически выбирал неоптимальный план, а для нескольких всегда следовал неоптимальному плану, даже при собранной статистике.

Suvitruf
28.02.2016 11:04+32Был Петя, который пытался изучить изнутри все технологии, которые использовал в проекте. Его конкурент Бил особо никогда не задумывался над начинкой инструментов используемых, поэтому выпустил свой продукт раньше. Да, забагованный, да медленный. Но со временем он улучшил продукт, а Петя так и не закончил свой проект.
Но мне все еще не понятно, как можно годами теребить базёнку, даже не догадываясь, а что там у нее «под капотом»?
Я такое часто слышу от людей, которые никогда не участвовали в разработке больших проектов. Чтобы работать с базой мне надо знать, как с ней работать, мне нет надобности залезать внутрь, так как банально нет времени. Да, мне надо знать, какие запросы медленные, какие быстрее и т.п. Особой надобности глубоко копать, чтоб понять почему так, нет. Естественно, я это сделаю, когда (и если) у меня будет время.
Можете кидаться тапками, но эйфория и желание познать начинку используемых инструментов проходит в первые годы после окончания университета и после начала работать над огромным проектом, особенно если вы является сооснователем. Любопытство никуда не пропадает, но как у соавтора у вас есть ответственность и, банально, сроки. Клиент не будет ждать, пока вы тешите своё любопытство.fediq
28.02.2016 12:14-7Подобный подход прокатывает на ранних стадиях. На проектах посложнее однажды появляется архитектор или ведущий разработчик, который компенсирует нехватку компетенции основателя.
Suvitruf
28.02.2016 12:20+7Ведущий разработчик во всех областях? Чтобы не быть голословным, у нас в проекте, к примеру, используется как минимум 4 базы разных: Riak, Rethinkdb, Redis, MySQL. Хотел бы я посмотреть на разработчика, который бы был в курсе начинки всех этих баз. Это не говоря уже про весь остальной стек, который мы используем.
fediq
28.02.2016 12:43-1Я могу на собеседовании вести достаточно детальный разговор про устройство трех баз из вашего списка.
Базы данных — достаточно узкая область, чтобы ее можно было изучить за вменяемое время.
lair
28.02.2016 12:49+7Базы данных — достаточно узкая область, чтобы ее можно было изучить за вменяемое время.
Ну если вы ничего больше не изучаете, то может быть. Да и то — неоднозначно, слишком уж понятие "базы данных" широкое.Zibx
28.02.2016 14:50Основная характеристика базы данных — "как хранятся данные", "как оптимизируется поиск" (индекс). Зная хотя бы примерно эти два параметра — можно говорить о том насколько сложным будет выполнение запроса и как он будет отжирать память\проц, во что упрётся и что можно сделать когда данных станет слишком много.

potapuff
28.02.2016 19:50Особенности реализации конкурентной работы Вы отнести к "как оптимизируется поиск" или забыли?
Zibx
04.03.2016 14:47Скорее к "как хранятся данные". Если включить сюда и доступ к данным. А если база разрастается, то там ещё вылезает cap теорема с вершинами в консистентности, скорости и надёжности.
lair
04.03.2016 14:52+3… и вы серьезно считаете, что знать "как хранятся данные" для всех (окей, хотя бы всех распространенных) БД, включая конкурентность и распределенность — это маленький объем?
(а CAP-треугольник вообще хреново людьми осознается)
orcy
28.02.2016 17:19-5Был Петя, который пытался изучить изнутри все технологии, которые использовал в проекте. Его конкурент Бил особо никогда не задумывался над начинкой инструментов используемых, поэтому выпустил свой продукт раньше.
Кого вы возьмете на следующий проект, человека который знает лучше детали СУБД или для которого это волшебная SQL-коробочка? Такого рода Петя и Билл напишут проект за одно время, только Биллу понадобится еще полгода что это заработал в продакшене с нормальной производительностью, так что ему придется по любому осваивать тоже самое, и не факт еще что Билл это осилит.
По моему это абсолютно нормально знать как устроенно то с чем ты непосредственно работаешь как профессионал. Я также спрашиваю на собеседование сложность вставки элемента в середину списка, массива, хэш-таблицы.
sapl
28.02.2016 12:44+3Парадокс в том — что Join-ы вообще нельзя использовать на продакшене с большим числом хитов.
Да и это скорее всего просто невозможно по причине сложного шардинга данных и архитектуры не
позволяющей такой связанности.
К этому сам приходишь — да и послушав/почитав об архитектуре нагруженных проектов (таких как соцсети)fediq
28.02.2016 12:50+1Согласен.
Меня Join'ы интересуют больше в разрезе офлайн аналитики, различных SQL поверх Hadoop. Там криво написанное условие превращается в лишние каскады map-reduce'ов и множественные OOM'ы.
Throwable
28.02.2016 14:42+4И как это у вас получается? Дизайн реляционной базы отличается от NoSql тем, что все сущности нормализованы и распеханы по разным таблицам, тогда как NoSQL может разные сущности иерархически в одной коллекции. И чтобы получить мало-мальски релевантную информацию, всегда приходится запрашивать данные сразу из нескольких таблиц. Чтобы получить список заказов, придется запрашивать также таблицу клиентов, т.к. нам хочется показать его имя, а не FK ID. Без JOIN-ов это можно сделать лишь для каждого заказа запрашивать клиента из таблицы (проблема N+1 query), либо объединить необходимых клиентов в один запрос: SELECT… FROM Clients WHERE id IN(?,?,...). Но в любом случае JOIN будет быстрее на порядки.
Так что если Вы пользуетесь реляционной базой, глупо не пользоваться стандартным функционалом в угоду предрассудкам. Другое дело, если реляционная модель уже не подходит решаемой задаче.michael_vostrikov
28.02.2016 19:11Для каждого заказа и запрашивать. Только не из базы, а из кеша в оперативной памяти. Из этого же кеша смогут запрашивать и другие списки или отчеты. Уж что-что, а ФИО клиента не меняется практически никогда.
Throwable
28.02.2016 20:02Размер таблицы клиентов может быть сравним с заказами и в общем случае не помещаться в память. Любой кеш сильно усложняет архитектуру, особенно когда хотите кешировать запросы. Кстати, многие RDBMS умеют делать materialized views для медленных запросов, который по сути и есть кеш. Для любого решения, которое вы сможете придумать, JOIN-ы будут работать проще и быстрее, пока не встанет проблема горизонтального масштабирования…
michael_vostrikov
28.02.2016 20:53-2Ну вам же не всю таблицу надо держать, а только ФИО в данном случае. Допустим, у нас миллион клиентов. Длина полного имени примерно 30-40 символов. То есть такой кеш будет занимать примерно 60-80 Мб для двухбайтовой кодировки, плюс 4 Мб на интовый ключ. После запроса делаем пост-обработку, где идем по строкам, дергаем кеш и добавляем к результату поле full_name. Никакой сложной архитектуры, один дополнительный цикл, зато минус 1 джойн из всех запросов с ФИО и связанные с ним чтения с диска и передача через сеть.
mayorovp
28.02.2016 12:49+3Как-то тихо пропустили случай когда по нужному полю имеется индекс. А ведь при наличии индекса Nested Loops Join превращается из самого медленного в едва ли не самый быстрый способ! Ведь он — единственный алгоритм, который умеет не делать полную выборку записей из таблицы (т.е. работать за сублинейное относительно размера БД время).
musicriffstudio
28.02.2016 13:51+2автор дал ссылку на прекрасную статью Как работает реляционная БД, собственный же его текст это очень упрощённый взгляд.
Непонятно зачем это вообще такое постить если приводится ссылка на, практически, образец точного и доступного описания работы SQL-сервера с данными.
fediq
28.02.2016 19:55+1По-моему, алгоритм для данного случая называется Index Join. Да, я про него забыл, моя оплошность.
mayorovp
28.02.2016 20:46+1MS SQL Server называет обе операции "Nested Loops". Кстати, соединение индекса и той таблицы, по которой он построен — тоже называется "Nested Loops", то есть для соединения двух таблиц по индексу в плане выполнения окажется две операции Nested Loops...
splav_asv
28.02.2016 22:16То, что MS SQL хочеть запутать следы, называя две вещи одним термином — скорее можно отнести к недостаткам(не критичным) MS SQL.
P.S. Про сам MS SQL ничего плохого сказать не могу, по отзывам база довольна приятная в использовании, сам не имел дело.mayorovp
28.02.2016 23:17+1Напротив, они называют вещи своими именами. Вложенный цикл — это и есть вложенный цикл, чтобы там ни было внутри.
splav_asv
28.02.2016 23:40В данном случае важна не схема реализации, а тип и сложность операции.
mayorovp
28.02.2016 23:47Тип операции виден в другом месте. Без индекса там стоит Clustered Index Scan или Table Scan. С индексом — Nonclustered Index Seek + Clustered Index Seek (как оно выглядит без кластерного индекса — не помню). А снаружи в обоих случаях — Nested Loops, и это правильно.
splav_asv
29.02.2016 00:17Значит просто более детально расписываются вложенные операции. Возможно это и хорошо.
Lol4t0
28.02.2016 12:57+2Я считаю, что изучать то, как работает JOIN совсем не обязательно
С другой стороны, для человека, знакомого с алгоритмами и структурами данных, и который запускал EXPLAIN пару раз и видел надписи FULL SCAN, MERGED JOIN и HASH JOIN, все эти подходы и так очевидныfediq
28.02.2016 19:16+1Согласен. Фундаментальные познания в алгоритмике снимают большую часть проблем.
vsb
28.02.2016 13:46Спасибо за статью, освежил знания в голове. Согласен с вашими выводами: если работаешь с SQL, всё, что описано в этой статье, знать очень желательно.
zhekappp
28.02.2016 14:41Современные РСУБД используют nested loops join в самых безнадежных случаях
Я бы всже же уточнил, что речь идет о чем-то DataWareHouse-подобном.
В OLTP системах все в точноти до наоборот.fediq
28.02.2016 20:15+1Да, есть случаи, когда nested loops будет быстрее. Добавил в статью. Спасибо!

saggid
28.02.2016 15:27+11Базы данных — это конечно хорошо, знать как они устроены, как они обрабатывают данные, и так далее. Но ваша мысль о проведении собеседований таким образом изначально неверна. Вы ищете себе в команду fullstack-ниндзей, которые знают и умеют всё? Во-первых, таких людей совсем немного в мире. Во-вторых, даже самый крутой подобный ниндзя всё равно проиграет узкому специалисту, долгое время работающему лишь в отдельной области. Или вам просто нравится выпендриться своим объёмом знаний в какой-то области ПО? В любом случае, мотивы некорректные.
В современном мире IT столько разных областей знаний, что вы не сможете знать всё сразу. У вас просто сил и времени на это не хватит. Поэтому правильно разделять людей на специалистов по фронтенду, бэкенду, базам данных, системному администрированию, дизайну, вёрстке, мобильным приложениям, и так далее. Вполне нормально, если человек прекрасно знает область фронтенда, но при этом не понимает, каким образом ему приходят данные с серверного API. Ему это и не надо понимать, в его задачу это не входит.
Я сам являюсь fullstack-ниндзей, прекрасно знаю и вёрстку, и JS использую как на фронтенде, так и на бекенде с нодой, и с базами данных постоянно работаю, и сервера настраиваю и поддерживаю, и скрипты на баше пилю, и ботов пишу для мессенджеров — но всё равно я прекрасно знаю, что отдельный профессиональный верстальщик в вёрстке будет шарить намного лучше, чем я. Человек, который много работал с базами данных, будет знать их работу лучше, чем я. И нет в этом ничего удивительного, и я не считаю себя от этого плохим разработчиком, как и никогда не буду считать плохим разработчиком кого-то другого из-за этого.
Тем более вопрос оптимизации каких-то отдельных частей приложения всегда можно решить уже тогда, когда проблема эта действительно возникнет. Зачем решать несуществующие проблемы?5HT
28.02.2016 17:44Есть еще другая манифестация фулстек-ниндзи — не размазанная по языкам и инструментам, а сосредоточенная в одном языке или окружении (Smalltalk например). И вот в таком окружении, которое по сложности как игровая реальность, вполно можно неплохо ориентироваться на полном фулстеке — от виртуальной машины до валидаций форм ввода.
fediq
28.02.2016 19:19-1В статье нет ничего про подход к собеседованиям. Эта статья — про операцию JOIN и веру в магию.
Как я писал в комментах выше:Что касается того, кого я ищу, то на самом деле, мне плевать на внутренности РСУБД. Я просто пытаюсь понять, насколько глубоко человек изучил те технологии, с которыми он работал. Т.е. если у вас в проекте было много low-level NIO, а с базой вы почти не работали — я не буду ожидать от вас знания Merge Join, но захочу услышать про селекторы и грин-треды.

gleb_kudr
28.02.2016 18:14+5Не надо спрашивать "как работает?".
Надо спрашивать "как бы вы написали?".
Ибо первое — ссылка на память и знание неких правильных способов, а второе — на умение придумать решение на месте. И разработчику в 90% случаев нужно второе.splav_asv
28.02.2016 22:37+1В 99% случаев есть доступ к достижениям всего человечества в этой области и в реальности придумывать в рабочем проекте свою версию скорее плохо, чем хорошо.
Если уж спрашивать, то спрашивать про какие алгоритмы человек слышал(быстрее найдет подходящий, если понадобится). Возможно про особенности этих алгоритмов(умение выбирать походящий). Можно попросить выбрать алгоритм под задачу с полным доступом к интернету — посмотреть как будет искать решение и что получится в итоге.
И можно попросить написать реализацию тривиального алгоритма — посмотреть как и что человек напишет (можно даже при этом дать полное чёткое описание, как этот алгоритм работает). (умение собственно реализовывать алгоритм в коде)

igrishaev
28.02.2016 19:02+9Компания совершила ошибку, доверив вам собеседования.
fediq
28.02.2016 19:21-2Эта статья не про собеседования, а про операцию JOIN.
Про собеседования мысль вот:Что касается того, кого я ищу, то на самом деле, мне плевать на внутренности РСУБД. Я просто пытаюсь понять, насколько глубоко человек изучил те технологии, с которыми он работал. Т.е. если у вас в проекте было много low-level NIO, а с базой вы почти не работали — я не буду ожидать от вас знания Merge Join, но захочу услышать про селекторы и грин-треды.
igrishaev
29.02.2016 08:57+8Материал подан под видом "кто не знает, тот дурак". Сквозь статью фонит высокомерие. Отсюда апелляция к половым органам ("теребить базенку"). Кстати, насколько подробно вы изучили устройство мочеполовой системы? Ведь согласно вашей теории, прежде чем что-то теребить, нужно глубоко изучить внутреннее устройство =)
Dronopotamus
28.02.2016 22:14+3Я конечно недавно на хабре и может чего не вкуриваю, но ИМХО рассуждать о том, надо ли или не надо разработчику знать алгоритмы работы джойна может только тот, кто никогда не сталкивался с оптимизацией запросов в БД.

gleb_l
28.02.2016 22:35+9Это извечный вопрос — должен ли разработчик цифровых схем детально знать, как работает транзистор?
И следствие из него — существуют ли хорошие разработчики, не имеющие детального понятия о работе кирпичиков, из которых они строят системы?
Теперь посмотрим, зачем вообще человеку абстракции? В силу того, что в сложных областях/системах качественно и детально держать всю вертикаль очень сложно — либо немасштабируемо по HR-размерности (вундеркинд может, инженер — нет), либо ненадежно по временной оси (пока проект идет, все более-менее охвачено — прошел год, два, пять — тонкости утрачены, все грабли — опять наши)
Далее, знания и навыки специалистов, как и функционал систем, стоят денег. Соответственно, брать нужно того, чье множество навыков хорошо ложится на требуемое. Другое дело, что материал на входе сейчас идет аховый, и чтобы хоть как-то отфильтровать, приходится задавать подобные вопросы.
Но в любом случае имхо лучше (хотя и хлопотнее/сложнее в оценке) — дать задания, соответствующие основной области — если это бакендщик — пусть спроектирует модель данных, покажет эффективные выборки, разрулит вопросы эффективных изменени (втч конкурентных), правильно организует бизнес-транзакции итд. В конце концов, какой именно способ иннер джойна применить, решает движок БД, и практика показывает, что он ошибается гораздо реже, чем человек на том конце провода, который пытается его обхитрить )
А насчет типов джойнов — в самих их названиях есть подсказка, имея конечно более-менее внятный IT-бэкграунд, можно догадаться, даже увидя execution plan первый раз в жизни.

dimview
28.02.2016 23:35+1Судя по плюсам-минусам, аудитория разделилась на два лагеря — кто знает, что внутри у JOIN (и считает это важным знанием), и кто не знает (и не считает это важным знанием, но боится провалить следующее собеседование).
musicriffstudio
29.02.2016 00:45+4код многих sql-серверов открыт, можно скачать и посмтреть. В том числе и на Java, тот же Derby из JDK.
Там нет циклов подобных приведенным в статье, все гораздо сложнее, но в то же время логичней.
Аудитория делится на тех кто это понимает и на тех кто этого не понимает.
SkidanovAlex
29.02.2016 07:15+4К всем трем вашим Join на самом деле есть нарекания.
Например, вы говорите, что Nested Loop Join — это для каждой строки в левой таблице надо пройтись по всем строкам правой таблицы. Это не более чем частный случай Nested Loop Join. Другой частный случай Nested Loop Join — это для каждой строки в левой таблице найти равные ей строки в правой таблице используя индекс, и по ним пройтись используя nested loop. И это уже достаточно эффективный способ делать Join, потому что его сложность для индексов на деревьях O(N log M + размер ответа), и константа памяти. А если ключик еще и в виде хештаблицы а не дерева, то логарифм из сложности тоже улетает, оставляя O(N + размер ответа), и константу памяти, что никакой другой джоин превзойти не может.
Ваш Hash Join делает неоговоренное заранее предположение, что ключи для Join уникальны, причем только с одной стороны. Это, вообще, очень странно поведение, потому что уникальные значения в столбце обычно форсируются индексом, а если есть индекс, то зачем HashJoin, можно использовать Nested Loop Join, описанный выше (потеряем логарифм времени в худшем случае, сэкономим линию памяти).
Ваш Merge Join просто неправильный. Если первая пара совпадает, она добавится дважды, потому что зачем-то в начале есть специальный случай. Я бы, собеседуя человека, предпочел чтобы он мог два списка слить без ошибок, чем чтобы он знал как joins работают :)
upd: заметил что внизу статьи упоминается про уникальные ключики, поэтому эта претензия отзываетсяfediq
29.02.2016 10:30Merge Join исправил, спасибо.
Про Index Join мне уже напомнили в комментах выше, но добавлять его в статью уже не хочется. Тем более, его код будет выглядеть почти как у HashJoin, только без построения хеша.
Так же я не написал про джойн по не-равенству, алгоритм sort join, anti join и еще много всяких редких штук.
Rupper
29.02.2016 18:28-1Линейная ассимптотическая сложность поиска в массиве это прорыв.
На самом деле там O(NlogM) где M — меньший список. Это про hash-joinmayorovp
29.02.2016 22:39+2Откуда берется логарифм в хеш-таблицах?
Rupper
29.02.2016 22:47-4А как определяется сложность алгоритма? Напишите машину Тьюринга, которая это сделает быстрее ?
mayorovp
29.02.2016 22:50+1Машину Тьюринга я писать не буду. А вот реальные хеш-таблицы сотню раз писал.
Rupper
29.02.2016 23:01-3Ну тогда да, извините, куда мне спорить с такими суровыми аргументами.
mayorovp
29.02.2016 23:12+2Хм. Я еще аргументов не приводил, а вы уже спорить отказываетесь :)
PS https://habrahabr.ru/post/128457/ — неплохой обзор структур данных. Как видно, никаких логарифмов у хеш-таблицы нет.
lair
01.03.2016 00:43+2А как определяется сложность алгоритма?
Как-как, анализом. Bottom line (Wikipedia): O(1) в среднем, O(n) в худшем случае.
Зависит от качества хэширующей функции и от соотношения числа ячеек (k) к количеству элементов (n). Но логарифму там взяться неоткуда: при равномерном распределении у вас в каждой ячейке будет n/k элементов. Стоимость доступа к ячейке, очевидно, константна, стоимость дальнейшего перебора линейно зависит от n/k. Если n > k (а это условие эффективной применимости хэш-таблиц), то вы получите константный общий доступ.dimview
01.03.2016 02:28Есть кукушкино хеширование с константным худшим случаем.
lair
01.03.2016 09:40У него вставка более тяжелая: чтобы получить среднее O(1), надо иметь n < k/2.
merlin-vrn
01.03.2016 09:46+1Какое среднее O(1)? Константа там в худшем случае, а не в среднем.
lair
01.03.2016 11:19Это на чтение константа в худшем случае. А на вставку — вероятностное O(1): "The expected time used per insertion is
O(1), so the total expected time for trying to insert all keys is O(n)."dimview
01.03.2016 16:04Если вероятностное O(1) на вставку не устраивает, существует деамортизированный вариант: "In this work we follow Kirsch and Mitzenmacher and present a de-amortization of cuckoo hashing that provably guarantees constant worst case operations."
lair
01.03.2016 16:17Specifically, the dictionary utilizes 2(1 + ?)n + n? words [? > 0]
Я не к тому, что алгоритм плохой, я к тому, что почти всегда неизбежно какой-то компромис.
Rupper
01.03.2016 09:13-4удивительная "средняя асимптотическая сложность". При идеальной реализации хещ-функции (сложность вычисления которой тоже не ноль) в среднем, для поиска элемента потребуется константное число операций.
Однако, асимптотическая сложность O(logN) потому как я МОГУ поддерживать список сортированным и для этого достаточно логарифма.merlin-vrn
01.03.2016 09:30Какая бы ни была сложная функция хеширования, сложность вычисления хеша каждого конкретного элемента никак не зависит от числа этих элементов. Константа. Какая бы она большая ни была. Поэтому в O-нотации никак не проявляется.
lair
01.03.2016 09:35+3Еще раз: асимптотическая сложность обращения к хэш-таблице — O(1). Спорить с этим достаточно бессмысленно, это подтверждается и анализом и практикой. Разница между константой и логарифмом (на самом деле, конечно, NlogN, не забывайте, что вам надо сортировку сформировать и поддерживать) достаточно велика, чтобы использование хэш-таблиц было выгодным даже при большой константе.
mayorovp
01.03.2016 09:39+2Отличный аргумент!
Ваша хеш-таблицы работают за константу, а моя будет работать медленее, потому что я МОГУ!
Вспоминаю свои достижения в седьмом классе — быструю сортировку односвязных списков за N2logN :)
leremin
А насколько примерно?
fediq
Настолько, чтобы использовать его эффективно и без очевидных ошибок.
Например, избегать nested loops join в запросах.
Не создавать каждый раз новый ObjectMapper в Jackson и не гонять по кругу сериализацию.
Буферизовать IO и не злоупотреблять seek'ами в RandomAccessFile.
potapuff
nested loops join достаточно эффективный способ, если строк мало. Иначе затраты на сортировку могут быть значительно больше затрат на само соединение.
fediq
Да, есть случаи, когда nested loops будет быстрее. Добавил в статью. Спасибо!