То, о чем я попытаюсь сейчас рассказать, выглядит как настоящая магия.
Если вы что-то знали о нейронных сетях до этого — забудьте это и не вспоминайте, как страшный сон.
Если вы не знали ничего — вам же легче, полпути уже пройдено.
Если вы на «ты» с байесовской статистикой, читали вот эту и вот эту статьи из Deepmind — не обращайте внимания на предыдущие две строчкии разрешите потом записаться к вам на консультацию по одному богословскому вопросу.
Итак, магия:

Слева — обычная и всем знакомая нейронная сеть, у которой каждая связь между парой нейронов задана каким-то числом (весом). Справа — нейронная сеть, веса которой представлены не числами, а демоническими облаками вероятности, колеблющимися всякий раз, когда дьявол играет в кости со вселенной. Именно ее мы в итоге и хотим получить. И если вы, как и я, озадаченно трясете головой и спрашиваете «а нафига все это нужно» — добро пожаловать под кат.
Давайте для начала путешествия возьмем самую простую в мире нейронную сеть, состоящую аж из одного нейрона. Отпилим у него функцию активации и заставим выплевывать просто произведение входов на веса (w) плюс b, и получим то, что называется линейной регрессией.
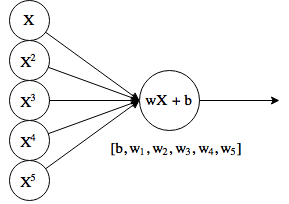
На входе дополнительно есть несколько копий оригинального X, возведенных в степень. Это иногда еще называют полиномиальной регрессией, хотя теоретически, «нейрон» по-прежнему делает линейную функцию
Ну и как в классических задачках, допустим, у нас есть какие-то точки, и нам нужно подогнать под них функцию. Напишем какой-то такой не очень красивый, зато самый простой в мире код:
И получим примерно такое:
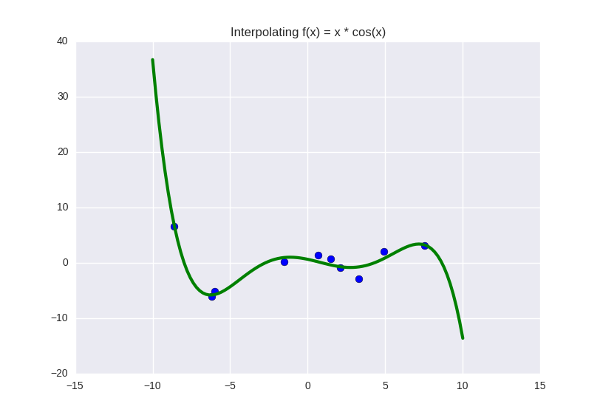
Функция, которую мы пытаемся пропихуть через синие точки, прямо сейчас задана полиномом пятой степени, а коэффициенты у нее такие: . Допустим, мы посмотрели на график, убедились, что зеленая линия не делает ничего особенно плохого и удачно подходит под данные, может быть, проверили, как она ведет себя на отдельной (предварительно спрятаной) тестовой выборке, и нас все устроило. Тогда эти шесть цифр — найденная нами почти-истина, какие-то «настоящие» параметры, управляющие законами природы (в данном случае законом функции
. Допустим, мы посмотрели на график, убедились, что зеленая линия не делает ничего особенно плохого и удачно подходит под данные, может быть, проверили, как она ведет себя на отдельной (предварительно спрятаной) тестовой выборке, и нас все устроило. Тогда эти шесть цифр — найденная нами почти-истина, какие-то «настоящие» параметры, управляющие законами природы (в данном случае законом функции  , но это детали — давайте предположим, что мы смотрим на какие-то настоящие и очень важные данные, что-нибудь типа графика температур для оценки глобального потепления).
, но это детали — давайте предположим, что мы смотрим на какие-то настоящие и очень важные данные, что-нибудь типа графика температур для оценки глобального потепления).
Окей, если мы нашли настоящие параметры, почему зеленая линия все-таки неидеально проходит через синие точки? Среднеквадратичное отклонение для этой линии все еще не нулевое (на самом деле оно примерно 0.97). Это нормально, или мы что-то сделали не так? На этот вопрос есть два ответа:
1. Наша модель недостаточно крута и недостаточно полно отражает искомую закономерность. Мы можем «обогатить» ее, добавив еще параметров — т.е., увеличить степень полинома. Для точек нам достаточно взять полином степени
точек нам достаточно взять полином степени  , чтобы он идеально прошел через все точки.
, чтобы он идеально прошел через все точки.
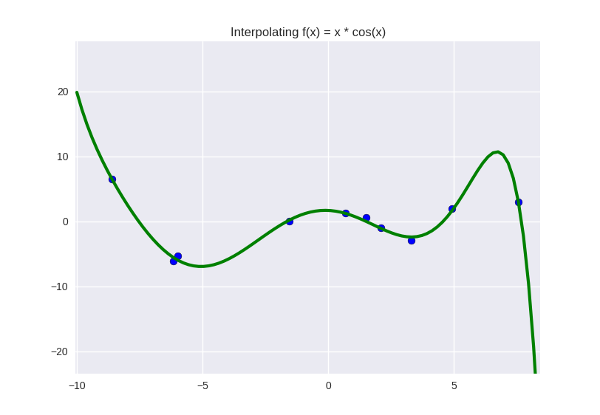
… не совсем идеально, но а почему бы и нет. Выглядит даже немного симпатичней, по-моему. Оставим как рабочую гипотезу.
2. Наша модель достаточно крута, проблема — в данных. В них есть какой-то шум, вызванный не иначе как несовершенством нашего мира (в данном случае тем, что я предательски приплюсовал к точкам немного рандома, но давайте представим себе, что это какие-то реальные данные). Даже если этот шум не по-настоящему случайный, а правда вызван факторами, которые мы не учли при постановке задачи, мы можем моделировать его как случайный — и считать, что колебания, вызванные вариациями всех этих факторов, может быть, удачненько лягут в нормальное распределение.
Не знаю, как вам, а мне второй вывод кажется если даже и не сразу правильным, то как минимум первоочередным. В конце концов, мы всегда можем подозревать, что в наших данных будет какой-то шум, мешающий планам и отклоняющий точки от нужного значения. Подумаем сначала про него, а дальше, если что, можно и степень полинома подкрутить.
Итак, мы делаем второй вывод, произносим слово «шум» и немедленно переносимся в теорию вероятностей. Удобнее всего (во всяком случае, мне) представить это так: наша зеленая линия пытается «прострелить» все синие точки, которые играют роль мишеней, при этом она может «промахиваться мимо», и размер промаха — как раз и есть тот самый шум. Предположим, что он Гауссовый (почему бы и нет). Тогда выстрел по мишени будет выглядеть так:
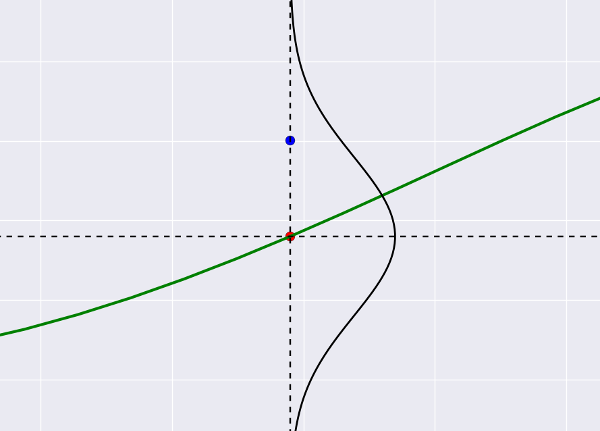
Это все тот же график регрессии, только с зумом. Синяя точка — фактическое значение из датасета, красная — то, что предсказывает регрессия. Маленькие отклонения синего от красного вероятней (лежат недалеко от центра гауссианы), большие — менее вероятны. Становится понятно, что если мы предскажем «неправильный центр» (разместим красную точку где-то далеко), отклонение для синей точки станет большим и следовательно, маловероятным.
В переводе на чуть более общепринятый язык эту вероятность называют правдоподобием (likelihood) и записывают в нашем гауссовском случае как (где
(где  и
и  — центр и стандартное отклонение гауссовой кривой), а в общем случае как
— центр и стандартное отклонение гауссовой кривой), а в общем случае как  , где под
, где под  имеют в виду любые параметры. Смысл у нее везде одинаковый — «вероятность того, что если распределением данных управляют такие-то параметры , результат будет именно
имеют в виду любые параметры. Смысл у нее везде одинаковый — «вероятность того, что если распределением данных управляют такие-то параметры , результат будет именно  ».
».
Теперь мы можем слегка переформулировать задачу регрессии. В терминах мишеней и правдоподобия они будет звучать как-то так: стрелять так, чтобы стрелок не выглядел полным неудачником, то есть чтобы его промахи были похожи на промахи и лежали в рамках погрешности. Придерживаясь общепринятого статистического языка, нам нужно максимизировать правдоподобие.
Сама искомая вероятность, как мы предположили, задается нормальным распределением. Спишем из википедии формулу и перемножим вероятности для каждой точки между собой (отсюда индекс ):
):

Ооокей, выглядит уже немного пугающе. Давайте, чтобы было немного полегче, зафиксируем — тогда мы сможем выкинуть половину символов отсюда. Чтобы у нас не портилось выражение вероятности, отдельно укажем, что нас интересует максимум:
— тогда мы сможем выкинуть половину символов отсюда. Чтобы у нас не портилось выражение вероятности, отдельно укажем, что нас интересует максимум:

Хээй, стало значительно веселее. Возьмем от этой штуки логарифм. Точка максимума при этом никуда не денется, зато произведение превратится в сумму, а экспонента — в свой показатель:

Ну и совсем наконец, уберем минус в сумме, заменив максимум на минимум:

Хм, где-то я уже видел такое выражение…
… и оказывается, что максимум правдоподобия достигается там же, где и минимум среднеквадратического отклонения регрессии. Такие моменты всегда почему-то ужасно разочаровывают — я уже был уверен, что щас открою какой-нибудь новый метод регрессии, а мы вернулись туда, откуда начинали.
С другой стороны, теперь мы знаем ответ на вопрос «а почему мы используем именно среднеквадратическое отклонение?» Раньше мы на это мысленно разводили руками, а теперь в курсе, что оно соответствует гауссовому шуму. Бонус-материал — если для оптимизации регрессии использовать абсолютную ошибку ( ), то получится шум по Лапласу (такой заостренный в центре). От вопроса «а чем один лучше другого» стыдливо уклонимся.
), то получится шум по Лапласу (такой заостренный в центре). От вопроса «а чем один лучше другого» стыдливо уклонимся.
Ладно, все это было весело, и довольно общеизвестно, на самом деле — мы тут просто на досуге переизобрели метод максимального правдоподобия. Настало время шагнуть чуть глубже и на другой уровень сна.
… как вы думаете, есть ли у вселенной параметры?
Это серьезный вопрос. Мы еще из школьной физики знаем, что у некоторых вещей вроде как точно есть — ускорение свободного падения, скажем, равно 9.8 метра на секунду в квадрате, и если мы хотим узнать, как падают вещи, или скажем, замоделировать компьютерную игру с физикой, нам придется это число туда вкрутить (или как делают компьютерные игры, хм? может, там притяжение Земли делается по закону Ньютона? или, черт возьми, с учетом эффектов теории относительности?). Или скажем, у пространства есть три измерения (макроскопических измерения, поправляет меня Мартин Риз); не 3.1 и не 2.8, а точно 3. Если бы мы вдруг решили построить алгоритм машинного обучения, который бы решил измерить размерность пространства, мы бы тем выше оценивали его работу, чем ближе бы он казался к числу три.
С другой стороны, есть ли точный, фиксированный параметр у того, сколько молока ребенок должен выпить за месяц? Сколько песен должна спеть птица, чтобы найти себе пару? В какой пропорции уменьшится опухоль после инъекции вещества X в тело пациента? Сколько воды протекает сквозь ручей за три минуты времени? Все эти вещи, несомненно, имеют под собой определенную закономерность — опухоль будет уменьшаться, ребенок — пить молоко, вода — течь, но если мы будем замерять точные значения, они постоянно будут колебаться, оставаясь при этом в каком-то интервале. Там, где в случае с физикой использование более точных инструментов дает нам все более точное значение величины («секунда есть время, равное 9 192 631 770 периодам излучения, соответствующего переходу между двумя сверхтонкими уровнями основного состояния атома цезия-133»), для измерения раковой опухоли нам скорее понадобится больше подопытных больных, чтобы очертить верхнюю и нижнюю границу и быть готовым к разным вариантам развития событий.
Это вообще вопрос откуда-то скорее из философии — и где-то здесь проходит водораздел между байесовской и ортодоксальной (или частотной) статистикой. Если грубо (я чуть дальше исправлюсь), то ортодоксальный подход скажет, что на каком-то уровне настоящие параметры все-таки есть (просто мы еще до него не добрались, а когда-нибудь выяснится, что рост опухоли, скажем, зависит от комбинации нескольких четко определяемых факторов). Байесовец же скажет, что точного параметра не существует — если даже не на уровне физического дизайна вселенной, то на уровне наблюдаемых нами эффектов — и что с параметрами надо обращаться как со случайными величинами, которые могут колебаться в разные стороны.
Давайте применим байесовскую философию «параметры — это случайные величины» к коэффициентам нашей регрессии. Для этого спишем теорему Байеса:
%20%3D%20%5Cfrac%7BP(X%20%5Cmid%20%5Ctheta)P(%5Ctheta)%7D%7BP(X)%7D)
Здесь означает «параметры в общем виде»; в нашем случае это уже знакомые коэффициенты полинома  . И мы уже знаем как минимум одну фигню из этой формулы —
. И мы уже знаем как минимум одну фигню из этой формулы — ) , то самое правдоподобие, которое мы максимизировали секцией выше (еще раз вспомним, что оно считается как значение отклонений точек датасета от регрессионной кривой или как «средний размер промаха по мишени»).
, то самое правдоподобие, которое мы максимизировали секцией выше (еще раз вспомним, что оно считается как значение отклонений точек датасета от регрессионной кривой или как «средний размер промаха по мишени»).  называется априорной (prior) вероятностью и отражает наше изначальное предположение о том, как выглядит распределение параметров.
называется априорной (prior) вероятностью и отражает наше изначальное предположение о том, как выглядит распределение параметров.  в отечественной литературе, по-моему, никак специально не называется (полная вероятность?), в других версия ее можно встретить под словом evidence — это общая вероятность получить такие данные, как у нас есть, при всех возможных значениях параметров (пока не очень понятно, откуда ее брать). И наконец,
в отечественной литературе, по-моему, никак специально не называется (полная вероятность?), в других версия ее можно встретить под словом evidence — это общая вероятность получить такие данные, как у нас есть, при всех возможных значениях параметров (пока не очень понятно, откуда ее брать). И наконец,  — апостериорная вероятность (posterior), которая означает буквально «что мы думаем о распределении параметров после того, как увидели данные».
— апостериорная вероятность (posterior), которая означает буквально «что мы думаем о распределении параметров после того, как увидели данные».
… на самом деле есть даже-не-очень-сложные способы выразить posterior для регрессии аналитически — т.е., получить формулу, куда только подставить значения из датасета, и получится правильный ответ. Но мы будем делать все раздолбайским программистским способом — численно, итеративно, и совершенно неэффективно. Зато не придется читать про всякие инвертированные распределения Уишарта и прочие жуткие вещи, которые не проходят в школе (хотя потом все равно придется, так что если вы за хардкорный путь познания, то вэлкам). Логика тут такая:
— мы начинаем с состояния полного незнания, когда у нас есть только prior. То есть мы считаем, что коэффициенты у регрессии могут быть какие угодно. Чтобы ограничить бездну познания немного, скажем «какие угодно от -10 до 10».
— мы видим какой-то кусок данных (одну точку из датасета, скажем). Для каждой возможной комбинации параметров мы считаем правдоподобие — насколько вероятно, что выстрел по мишени делался именно с такими настройками. Как можно заранее догадаться, большинство настроек будут скорее невалидными, и выстрел унесет куда-то совсем мимо, но явно останется несколько (больше одного) вариантов, при которых дырка в мишени выглядит разумно. Правдоподобие мы считаем, как уже видели, по Гауссу — просто подставляем в формулу плотности нормального распределения предсказание регрессии вместо мю, а значение из датасеты — вместо икс.
— суммируем все рассчитанные на предыдущем шаге значения правдоподобия и получаем (в чем легко убедиться, написав  ). Теперь у нас есть все необходимое, чтобы проапдейтить posterior.
). Теперь у нас есть все необходимое, чтобы проапдейтить posterior.
— обработав одну мишень, мы получили какие-то представления о том, как могут выглядеть параметры; теперь это становится нашим новым prior. Достаем следующую точку из датасета и начинаем со второго шага.
Выглядит это все довольно несложно:
(перебрать все возможных комбинации коэффициентов нам поможет
В результате мы получим совместное распределение для наших коэффициентов регрессии — все их возможные значения будут суммироваться к единице. Получается, что у каждого набора коэффициентов будет какая-то вероятность, причем чем выше она, тем задаваемая ими кривая правильней и трушней.
Возникает вопрос на миллион — как эту фигню нарисовать?
Я попробовал примерно так: разбил спектр вероятностей на десять равных отрезков, и из каждого отрезка нарисовал на графике сколько-то кривых соответствующим цветом (от черного к белому — чем выше вероятность кривой). «Низковероятных» кривых, очевидно, больше, чем высоковероятных, поэтому пришлось ограничить их число рандомной сотней или около того, чтобы pyplot окончательно не умер в мучениях, пытаясь нарисовать… сколько, кстати, кривых? Я временно понизил степень полинома до третьей, каждый коэффициент может принимать значения от -10 до 10 с шагом в 0.5 — так что скромных регрессий там, где раньше была одна.
регрессий там, где раньше была одна.
Итого, выглядит это примерно так:
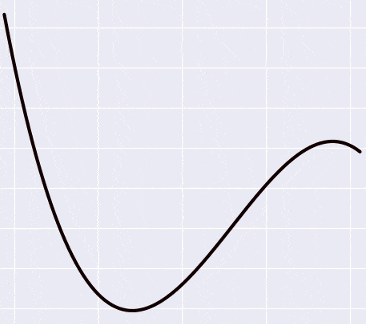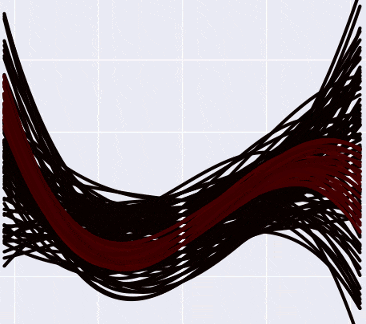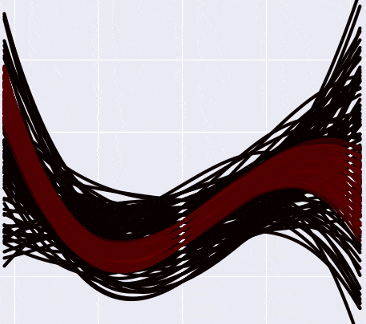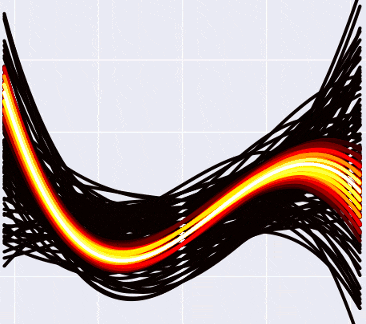
А если отметить на графике данные, то так (прошу прощения за вырвиглазно-зеленый цвет):
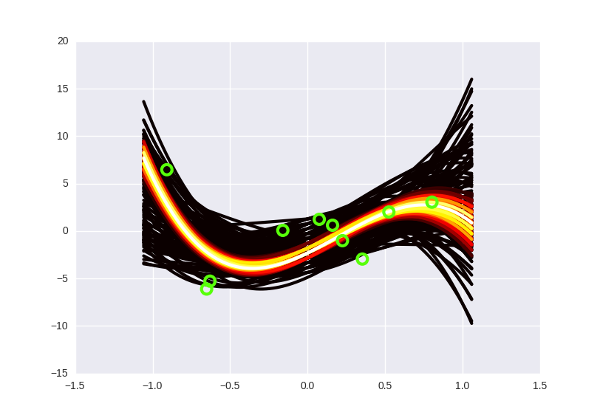
Заметьте, что более «горячие» кривые, конечно, имеют более высокую вероятность, но в Байесовской интерпретации это не означает, что эти кривые «правильные» (что мы должны взять их и выбросить все черные). Немного более интуитивный способ думать об этих кривых, по-моему — это представить, что вы смотрите как бы сверху на нормальное распределение, и видите, что в центре, конечно, есть какой-то пик вероятности, но сама по себе вероятность оказаться в точке пика все равно очень маленькая. Только собрав вместе какую-то часть распределения, можно «набрать» достаточно вероятности.
Если вы все еще недоумеваете, зачем нам эта штука, то вот вам маленький бонус: байесовская регрессия неуязвима к переобучению (overfitting). Причем я не имею в виду просто «устойчива» или «надежна» как регрессия с регуляризацией — в определенной степени она к нему вообще неуязвима.
Что такое переобучение, еще раз? Это когда мы «слишком подгоняем» модель к имеющимся данным (например, подбираем такую кривую, которая идеально пройдет через все точки датасета, но покажет плохие предсказания на новых данных). В переводе на философский язык прошлой секции это означает, что когда мы искали «правильный» набор параметров, мы нашли какой-то ошибочный, неправильный. Это невозможно сделать с байесовским подходом, потому что там просто нет понятия «правильного» набора параметров! Странный черно-желтый конус на картинках выше говорит нам: «да, скорее всего, следующие точки будут где-то в середине вдоль белых кривых, но могут оказаться и с краю, и выше, и ниже, никаких проблем». Степень полинома можно увеличивать сколько угодно: вместе с ней будет расти число возможных кривых, а у каждой из них по отдельности будет падать вероятность. «Выживут» все равно только те, которые будут лежать близко к данным, в нашем оранжево-«горячем» пучке. Сделаем пятую степень? Да никаких проблем, Хьюстон:
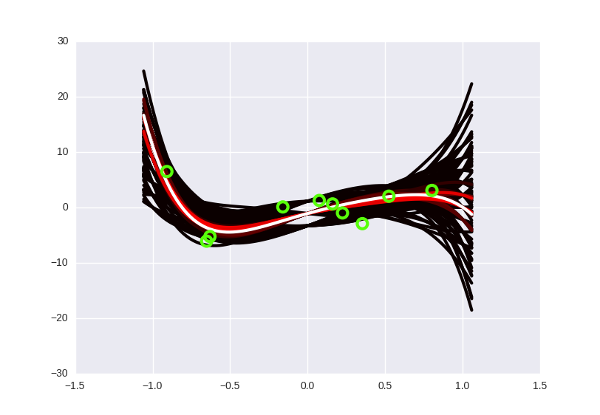
Выглядит чуть более блеклым, но это просто потому, что я уменьшил общее количество кривых — иначе мой лаптоп бы не проснулся.
На самом деле в таком контексте понятия переобучения вообще не существует. Невозможно неправильно найти параметр, потому что «параметр» — это не вещь, которую можно «найти», это здоровенное облако вероятности, которое становится «плотным» только там, где рядом лежат данные. Переобучения не существует, дамы и господа, расходимся. Не забудем сообщить всем этим важным ребятам из машинного обучения, что можно закрывать лавочку.
В машинном обучении есть такая очень простая техника — когда у вас есть несколько моделей и они все работают плохо, можно взять и усреднить (или еще как-нибудь объединить) их предсказания, и тогда они волшебным образом начинают работать хорошо. По-правильному это называется ансамбли, и их можно встретить почти где угодно, особенно на соревнованиях.
И вообще говоря, это не интуитивный вопрос: почему ансамбли вообще работают? В реальной жизни вещи редко ведут себя таким образом: если у вас есть десять плохих молотков, гвоздь не станет забиваться лучше от того, что вы будете использовать их по очереди. Иллюстрация к этому вопросу частично служит неплохой интуицией (по-моему) на тему того, почему работает байесовская регрессия. Выглядит это как-то так:
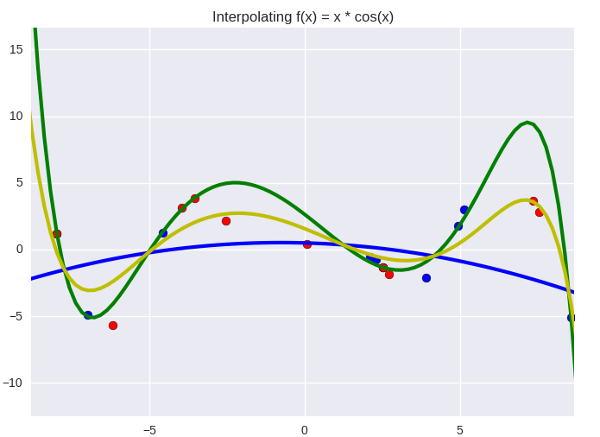
Зеленая линия — «сложная» модель (полином девятой степени), а синяя — «простая» (второй степени). Синией точки относятся к обучающей выборке, а красные — к тестовой. Желтая линия — простое среднее арифметическое между двумя моделями, и даже на глаз заметно, что она не такая размашистая, как зеленая, и действительно лежит ближе к красным точкам. Простота синего слегка компенсирует прыгучесть зеленого; средний вариант ближе к истине, чем оба отклонения, при условии, что отклонения направлены в разные стороны (это как раз одно из важных условий ансамблей — вам нужны разные модели для того, чтобы усреднение сработало).
Так вот, когда мы пытаемся предсказать что-то с байесовской регрессией, мы усредняем не две и не три модели, а — в нашем случае — два с половиной миллиона. Но погодите, на самом деле все еще круче. Это мы в своем кривом питонском коде ограничили коэффициенты значениями в -10 и 10 с шагом в 0.5, а если делать все по-правильному, они могут принимать любое значение на бесконечной числовой прямой. Секунду, включим калькулятор… , так точно. Байесовская регрессия — это ансамбль из бесконечного числа регрессий (сумма при этом превращается в интеграл). Где-то в этот момент скромное название «байесовская регрессия» начинает не передавать всей ее невозможной крутости, нужно бы что-нибудь эпичнее.
, так точно. Байесовская регрессия — это ансамбль из бесконечного числа регрессий (сумма при этом превращается в интеграл). Где-то в этот момент скромное название «байесовская регрессия» начинает не передавать всей ее невозможной крутости, нужно бы что-нибудь эпичнее.
«Не-совсем-случайный бесконечнолес?»
Настало время немного разочароваться: способ, который мы придумали для расчета posterior, плохой и работает только для каких-то очень маленьких задач. Дело в том, что количество всех возможных сочетаний параметров, которые нужно перебрать, растет экспоненциально. Мы оценивали его как число значений параметра в степени числа параметров, и уже для полинома девятой степени (десять коэффициентов/параметров) нам в текущем сеттинге придется пробежаться по циклу 10485760000000000 раз.
А теперь настало время по-настоящему разочароваться: для более сложных моделей, то есть нейронных сетей (которые представляют собой просто несколько регрессионных юнитов, соединенных друг с другом), чистый байесовский метод становится еще более неприменимым. «Параметры» нейронной сети — это ее веса; а их в современных сетях может быть очень и очень много (миллионы штук с легкостью). Существуют всякие способы упростить этот процесс: например, случайным образом доставать значения posterior вместо того, чтобы рассчитывать его в каждой точки (это называется сэмплинг), но мы не зря их все проигнорировали — они недостаточно круты, чтобы помочь получить байесовскую нейронную сеть по-настоящему серьезных размеров.
На самом деле для каких-то отдельных моделей все еще хуже. Наши коэффициенты регрессии, грубо говоря, «ни от чего не зависели»; если мы хотим посмотреть, как ведет себя модель с таким-то набором параметров, мы можем просто взять его и подставить в формулу Байеса. В сетях распределение весов отдельного нейрона может зависеть от того, как ведет себя предыдущий нейрон, а тот, в свою очередь, зависит от предыдущего (а настоящее веселье начинается, когда зависимости замыкаются в цикл).
Собственно, это и есть главная причина, по которой лавочка не закрыта, люди продолжают бороться с переобучениеми искусственный интеллект так и не построили. В общем, если мы хотим добраться до цели, указанной в заголовке, нам потребуется что-нибудь еще. Поэтому в следующей части мы поговорим об аппроксимациях к апостерорной вероятности, вариационных методах в машинном обучении, и об обратном байесораспространении ошибки.
Мы можем немного отступить назад и удовлетвориться частичным решением проблемы: найти максимум байесовского пучка, самую близкую к центру и самую «горячую» кривую. Это будет не так круто, как знание пучка целиком, но все лучше, чем то, с чего мы начинали.
То есть мы ищем . Берем привычный логарифм, чтобы превратить произведение в сумму:
. Берем привычный логарифм, чтобы превратить произведение в сумму:

Теперь смотрите: с мы уже разобразись в части про максимальное правдоподобие (под спойлером), и можем его пока проигнорировать. Что делать со вторым слагаемым (которое наш prior)? Для начала, вспомним, что в нашем случае — это набор коэффициентов регрессии, и в качестве априорной оценки мы вполне можем сказать, что каждый коэффициент имеет какое-то свое, независимое распределение (т.е., записать выражение как
мы уже разобразись в части про максимальное правдоподобие (под спойлером), и можем его пока проигнорировать. Что делать со вторым слагаемым (которое наш prior)? Для начала, вспомним, что в нашем случае — это набор коэффициентов регрессии, и в качестве априорной оценки мы вполне можем сказать, что каждый коэффициент имеет какое-то свое, независимое распределение (т.е., записать выражение как  ). Какое именно распределение взять? Мы раньше считали, что оно равномерное:
). Какое именно распределение взять? Мы раньше считали, что оно равномерное:  , но это скучно и сводится к максимальному правдоподобию (потому что тогда будет константой — вероятность все время одинаковая, какие бы коэффициенты мы не взяли). Давайте предположим, что каждый коэффициент регрессии распределен по Гауссу с центром в точке 0 и каким-то стандартным отклонением . Тогда:
, но это скучно и сводится к максимальному правдоподобию (потому что тогда будет константой — вероятность все время одинаковая, какие бы коэффициенты мы не взяли). Давайте предположим, что каждый коэффициент регрессии распределен по Гауссу с центром в точке 0 и каким-то стандартным отклонением . Тогда:

Подставляем вместо формулу нормального распределения. Мы уже такое делали, только если помните, раньше у нас было фиксировано стандартное отклонение, а середина варьировалась. Сейчас мы фиксируем сразу все:
формулу нормального распределения. Мы уже такое делали, только если помните, раньше у нас было фиксировано стандартное отклонение, а середина варьировалась. Сейчас мы фиксируем сразу все:

Коэффициент перед экспонентой опять-таки не важен для поиска максимума (он не зависит от ). Выкидываем его и применяем логарифм:
). Выкидываем его и применяем логарифм:

Получается, что максимум достигается там, где сумма квадратов коэффициентов регрессии минимальна. Ничего не напоминает? Мы переизобрели регуляризацию, на минуточку, и получили отличное обоснование тому, зачем она вообще нужна (раньше это была какая-то технарско-инженерная штука, в духе «нуу, давайте просто заставим коэффициенты регрессии быть маленькими, чтобы она не прыгала туда-сюда», но с Байесом в ваш дом приходит просветление и все обретает смысл).
На статистическом жаргоне это называется maximum a posteriori или MAP-learning. В отличие от «чистого» Байеса, MAP отлично применяется и к нейронным сетям, и к чему угодно — под скромным именем «регуляризация». К сожалению, это не тру-байесовское решение, потому что в конце концов мы заканчиваем игру с каким-то штучным «набором параметров» — и поэтому такой подход тоже может страдать от переобучения, хотя и более устойчив к нему, чем метод максимального правдоподобия.
По мотивам дискуссии, начатой haqreu на тему того, православно ли пытаться объяснять математические вещи на пальцах, мне немного интересно общественное мнение на эту тему. Ткните куда-нибудь в опрос по результатам прочтения, если не затруднит?
Если вы что-то знали о нейронных сетях до этого — забудьте это и не вспоминайте, как страшный сон.
Если вы не знали ничего — вам же легче, полпути уже пройдено.
Если вы на «ты» с байесовской статистикой, читали вот эту и вот эту статьи из Deepmind — не обращайте внимания на предыдущие две строчки
Итак, магия:
Слева — обычная и всем знакомая нейронная сеть, у которой каждая связь между парой нейронов задана каким-то числом (весом). Справа — нейронная сеть, веса которой представлены не числами, а демоническими облаками вероятности, колеблющимися всякий раз, когда дьявол играет в кости со вселенной. Именно ее мы в итоге и хотим получить. И если вы, как и я, озадаченно трясете головой и спрашиваете «а нафига все это нужно» — добро пожаловать под кат.
Один шаг назад: линейная регрессия
Давайте для начала путешествия возьмем самую простую в мире нейронную сеть, состоящую аж из одного нейрона. Отпилим у него функцию активации и заставим выплевывать просто произведение входов на веса (w) плюс b, и получим то, что называется линейной регрессией.
На входе дополнительно есть несколько копий оригинального X, возведенных в степень. Это иногда еще называют полиномиальной регрессией, хотя теоретически, «нейрон» по-прежнему делает линейную функцию
Ну и как в классических задачках, допустим, у нас есть какие-то точки, и нам нужно подогнать под них функцию. Напишем какой-то такой не очень красивый, зато самый простой в мире код:
Заголовок спойлера
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
def add_powers(data, n=5):
result = [data]
for i in xrange(2, n + 1):
poly = np.power(data, i)
result.append(poly)
return np.vstack(result).T
def generate_data(n=20):
x = np.linspace(-10, 10, 100)
y = x * np.cos(x)
max_y = np.max(y)
y += np.random.random(y.shape)
idx = np.random.choice(len(y), n)
return x[idx], y[idx], max_y
if __name__ == '__main__':
original_data, target, max_y = generate_data(n=10)
power = 5
data = add_powers(original_data, power)
max_vals = np.array([max_y ** i for i in xrange(1, power + 1)])
data /= max_vals
w = (np.random.random(power) - 0.5) * 1.
b = -1.
learning_rate = 0.1
for e in xrange(100000):
h = data.dot(w) + b
w -= learning_rate * ((h - target)[:, None] * data).mean(axis=0)
b -= learning_rate * (h - target).mean()
plt.title('Interpolating f(x) = x * cos(x)')
x = add_powers(np.linspace(-10, 10, 100), power)
x /= max_vals
y = x.dot(w) + b
plt.plot(x[:, 0] * max_vals[0], y, lw=3, c='g')
plt.scatter(data[:, 0] * max_vals[0], target, s=50)
plt.show()
И получим примерно такое:
Функция, которую мы пытаемся пропихуть через синие точки, прямо сейчас задана полиномом пятой степени, а коэффициенты у нее такие:
[0.5423 -3.2648 -16.5311 43.3645 25.6159 -51.2418]. Что это, на всякий случай, означает? Это означает, что мы подозреваем в данных какую-то закономерность, и эта закономерность лучше всего выражается как Вероятностная интерпретация
Окей, если мы нашли настоящие параметры, почему зеленая линия все-таки неидеально проходит через синие точки? Среднеквадратичное отклонение для этой линии все еще не нулевое (на самом деле оно примерно 0.97). Это нормально, или мы что-то сделали не так? На этот вопрос есть два ответа:
1. Наша модель недостаточно крута и недостаточно полно отражает искомую закономерность. Мы можем «обогатить» ее, добавив еще параметров — т.е., увеличить степень полинома. Для
… не совсем идеально, но а почему бы и нет. Выглядит даже немного симпатичней, по-моему. Оставим как рабочую гипотезу.
2. Наша модель достаточно крута, проблема — в данных. В них есть какой-то шум, вызванный не иначе как несовершенством нашего мира (в данном случае тем, что я предательски приплюсовал к точкам немного рандома, но давайте представим себе, что это какие-то реальные данные). Даже если этот шум не по-настоящему случайный, а правда вызван факторами, которые мы не учли при постановке задачи, мы можем моделировать его как случайный — и считать, что колебания, вызванные вариациями всех этих факторов, может быть, удачненько лягут в нормальное распределение.
Не знаю, как вам, а мне второй вывод кажется если даже и не сразу правильным, то как минимум первоочередным. В конце концов, мы всегда можем подозревать, что в наших данных будет какой-то шум, мешающий планам и отклоняющий точки от нужного значения. Подумаем сначала про него, а дальше, если что, можно и степень полинома подкрутить.
Итак, мы делаем второй вывод, произносим слово «шум» и немедленно переносимся в теорию вероятностей. Удобнее всего (во всяком случае, мне) представить это так: наша зеленая линия пытается «прострелить» все синие точки, которые играют роль мишеней, при этом она может «промахиваться мимо», и размер промаха — как раз и есть тот самый шум. Предположим, что он Гауссовый (почему бы и нет). Тогда выстрел по мишени будет выглядеть так:
Это все тот же график регрессии, только с зумом. Синяя точка — фактическое значение из датасета, красная — то, что предсказывает регрессия. Маленькие отклонения синего от красного вероятней (лежат недалеко от центра гауссианы), большие — менее вероятны. Становится понятно, что если мы предскажем «неправильный центр» (разместим красную точку где-то далеко), отклонение для синей точки станет большим и следовательно, маловероятным.
В переводе на чуть более общепринятый язык эту вероятность называют правдоподобием (likelihood) и записывают в нашем гауссовском случае как
Теперь мы можем слегка переформулировать задачу регрессии. В терминах мишеней и правдоподобия они будет звучать как-то так: стрелять так, чтобы стрелок не выглядел полным неудачником, то есть чтобы его промахи были похожи на промахи и лежали в рамках погрешности. Придерживаясь общепринятого статистического языка, нам нужно максимизировать правдоподобие.
Сама искомая вероятность, как мы предположили, задается нормальным распределением. Спишем из википедии формулу и перемножим вероятности для каждой точки между собой (отсюда индекс
Ооокей, выглядит уже немного пугающе. Давайте, чтобы было немного полегче, зафиксируем
Хээй, стало значительно веселее. Возьмем от этой штуки логарифм. Точка максимума при этом никуда не денется, зато произведение превратится в сумму, а экспонента — в свой показатель:
Ну и совсем наконец, уберем минус в сумме, заменив максимум на минимум:
Хм, где-то я уже видел такое выражение…
… и оказывается, что максимум правдоподобия достигается там же, где и минимум среднеквадратического отклонения регрессии. Такие моменты всегда почему-то ужасно разочаровывают — я уже был уверен, что щас открою какой-нибудь новый метод регрессии, а мы вернулись туда, откуда начинали.
С другой стороны, теперь мы знаем ответ на вопрос «а почему мы используем именно среднеквадратическое отклонение?» Раньше мы на это мысленно разводили руками, а теперь в курсе, что оно соответствует гауссовому шуму. Бонус-материал — если для оптимизации регрессии использовать абсолютную ошибку (
Think Bayes
Ладно, все это было весело, и довольно общеизвестно, на самом деле — мы тут просто на досуге переизобрели метод максимального правдоподобия. Настало время шагнуть чуть глубже и на другой уровень сна.
… как вы думаете, есть ли у вселенной параметры?
Это серьезный вопрос. Мы еще из школьной физики знаем, что у некоторых вещей вроде как точно есть — ускорение свободного падения, скажем, равно 9.8 метра на секунду в квадрате, и если мы хотим узнать, как падают вещи, или скажем, замоделировать компьютерную игру с физикой, нам придется это число туда вкрутить (или как делают компьютерные игры, хм? может, там притяжение Земли делается по закону Ньютона? или, черт возьми, с учетом эффектов теории относительности?). Или скажем, у пространства есть три измерения (макроскопических измерения, поправляет меня Мартин Риз); не 3.1 и не 2.8, а точно 3. Если бы мы вдруг решили построить алгоритм машинного обучения, который бы решил измерить размерность пространства, мы бы тем выше оценивали его работу, чем ближе бы он казался к числу три.
С другой стороны, есть ли точный, фиксированный параметр у того, сколько молока ребенок должен выпить за месяц? Сколько песен должна спеть птица, чтобы найти себе пару? В какой пропорции уменьшится опухоль после инъекции вещества X в тело пациента? Сколько воды протекает сквозь ручей за три минуты времени? Все эти вещи, несомненно, имеют под собой определенную закономерность — опухоль будет уменьшаться, ребенок — пить молоко, вода — течь, но если мы будем замерять точные значения, они постоянно будут колебаться, оставаясь при этом в каком-то интервале. Там, где в случае с физикой использование более точных инструментов дает нам все более точное значение величины («секунда есть время, равное 9 192 631 770 периодам излучения, соответствующего переходу между двумя сверхтонкими уровнями основного состояния атома цезия-133»), для измерения раковой опухоли нам скорее понадобится больше подопытных больных, чтобы очертить верхнюю и нижнюю границу и быть готовым к разным вариантам развития событий.
Это вообще вопрос откуда-то скорее из философии — и где-то здесь проходит водораздел между байесовской и ортодоксальной (или частотной) статистикой. Если грубо (я чуть дальше исправлюсь), то ортодоксальный подход скажет, что на каком-то уровне настоящие параметры все-таки есть (просто мы еще до него не добрались, а когда-нибудь выяснится, что рост опухоли, скажем, зависит от комбинации нескольких четко определяемых факторов). Байесовец же скажет, что точного параметра не существует — если даже не на уровне физического дизайна вселенной, то на уровне наблюдаемых нами эффектов — и что с параметрами надо обращаться как со случайными величинами, которые могут колебаться в разные стороны.
На самом деле...
Обе стороны могут сейчас сказать, что я неправ, потому что интерпретаций этого вопроса — целая куча. Интересующихся отсылаю на StackExchange, откуда я позаимствовал несколько примеров вроде молока и опухоли, и более правильный ответ для байесовской статистики скорее будет «мы не знаем, как там устроен мир на самом деле, и возможно, фиксированные параметры и есть, но в своих взаимодействиях с ними мы неизменно оперируем с некоторым градусом неуверенности, и эту неуверенность мы моделируем с помощью вероятности». Фух. Срочно нужен выход на более мелкий уровень сна.
2560000 регрессий
Давайте применим байесовскую философию «параметры — это случайные величины» к коэффициентам нашей регрессии. Для этого спишем теорему Байеса:
Здесь
… на самом деле есть даже-не-очень-сложные способы выразить posterior для регрессии аналитически — т.е., получить формулу, куда только подставить значения из датасета, и получится правильный ответ. Но мы будем делать все раздолбайским программистским способом — численно, итеративно, и совершенно неэффективно. Зато не придется читать про всякие инвертированные распределения Уишарта и прочие жуткие вещи, которые не проходят в школе (хотя потом все равно придется, так что если вы за хардкорный путь познания, то вэлкам). Логика тут такая:
— мы начинаем с состояния полного незнания, когда у нас есть только prior. То есть мы считаем, что коэффициенты у регрессии могут быть какие угодно. Чтобы ограничить бездну познания немного, скажем «какие угодно от -10 до 10».
— мы видим какой-то кусок данных (одну точку из датасета, скажем). Для каждой возможной комбинации параметров
— суммируем все рассчитанные на предыдущем шаге значения правдоподобия и получаем
— обработав одну мишень, мы получили какие-то представления о том, как могут выглядеть параметры; теперь это становится нашим новым prior. Достаем следующую точку из датасета и начинаем со второго шага.
Выглядит это все довольно несложно:
Заголовок спойлера
from itertools import product
def likelihood(x, mu, sigma=1.):
return np.exp(-np.power(x - mu, 2.) / (2 * np.power(sigma, 2.)))
frequency = 40
posterior = np.ones(frequency ** (power + 1)) / float(frequency)
param_values = [np.linspace(-10, 10, frequency) for _ in xrange(power + 1)]
for i, pt in enumerate(data):
for j, params in enumerate(product(*param_values)):
b = params[0]
w = np.array(params[1:])
h = pt.dot(w) + b
like = likelihood(pt[0], h)
posterior[j] *= like
posterior /= posterior.sum()
(перебрать все возможных комбинации коэффициентов нам поможет
itertools.product)В результате мы получим совместное распределение для наших коэффициентов регрессии — все их возможные значения будут суммироваться к единице. Получается, что у каждого набора коэффициентов будет какая-то вероятность, причем чем выше она, тем задаваемая ими кривая правильней и трушней.
Возникает вопрос на миллион — как эту фигню нарисовать?
Я попробовал примерно так: разбил спектр вероятностей на десять равных отрезков, и из каждого отрезка нарисовал на графике сколько-то кривых соответствующим цветом (от черного к белому — чем выше вероятность кривой). «Низковероятных» кривых, очевидно, больше, чем высоковероятных, поэтому пришлось ограничить их число рандомной сотней или около того, чтобы pyplot окончательно не умер в мучениях, пытаясь нарисовать… сколько, кстати, кривых? Я временно понизил степень полинома до третьей, каждый коэффициент может принимать значения от -10 до 10 с шагом в 0.5 — так что скромных
Итого, выглядит это примерно так:
А если отметить на графике данные, то так (прошу прощения за вырвиглазно-зеленый цвет):
Заметьте, что более «горячие» кривые, конечно, имеют более высокую вероятность, но в Байесовской интерпретации это не означает, что эти кривые «правильные» (что мы должны взять их и выбросить все черные). Немного более интуитивный способ думать об этих кривых, по-моему — это представить, что вы смотрите как бы сверху на нормальное распределение, и видите, что в центре, конечно, есть какой-то пик вероятности, но сама по себе вероятность оказаться в точке пика все равно очень маленькая. Только собрав вместе какую-то часть распределения, можно «набрать» достаточно вероятности.
Переобучения не существует, Нео
Если вы все еще недоумеваете, зачем нам эта штука, то вот вам маленький бонус: байесовская регрессия неуязвима к переобучению (overfitting). Причем я не имею в виду просто «устойчива» или «надежна» как регрессия с регуляризацией — в определенной степени она к нему вообще неуязвима.
Что такое переобучение, еще раз? Это когда мы «слишком подгоняем» модель к имеющимся данным (например, подбираем такую кривую, которая идеально пройдет через все точки датасета, но покажет плохие предсказания на новых данных). В переводе на философский язык прошлой секции это означает, что когда мы искали «правильный» набор параметров, мы нашли какой-то ошибочный, неправильный. Это невозможно сделать с байесовским подходом, потому что там просто нет понятия «правильного» набора параметров! Странный черно-желтый конус на картинках выше говорит нам: «да, скорее всего, следующие точки будут где-то в середине вдоль белых кривых, но могут оказаться и с краю, и выше, и ниже, никаких проблем». Степень полинома можно увеличивать сколько угодно: вместе с ней будет расти число возможных кривых, а у каждой из них по отдельности будет падать вероятность. «Выживут» все равно только те, которые будут лежать близко к данным, в нашем оранжево-«горячем» пучке. Сделаем пятую степень? Да никаких проблем, Хьюстон:
Выглядит чуть более блеклым, но это просто потому, что я уменьшил общее количество кривых — иначе мой лаптоп бы не проснулся.
На самом деле в таком контексте понятия переобучения вообще не существует. Невозможно неправильно найти параметр, потому что «параметр» — это не вещь, которую можно «найти», это здоровенное облако вероятности, которое становится «плотным» только там, где рядом лежат данные. Переобучения не существует, дамы и господа, расходимся. Не забудем сообщить всем этим важным ребятам из машинного обучения, что можно закрывать лавочку.
На всякий случай
Это не означает что байесовская регрессия всегда дает правильные предсказания и не может ошибаться — может, конечно. Допустим, следующая точка в датасете будет иметь x=3 и y=-20 и упадет гораздо ниже оранжевого пучка — тогда наша модель предскажет неправильное значение. Фокус в том, что обычную регрессию вам в этом месте понадобилось бы обучать с нуля и подправлять параметры, в то время как байесовскую нужно всего лишь «проапдейтить», положив новую точку в алгоритм — и пучок соответстветствующим образом изогнется.
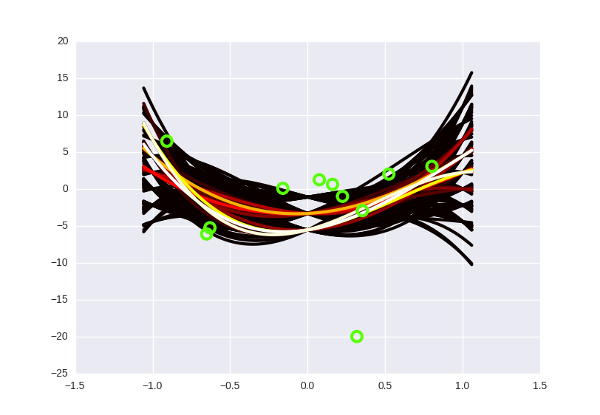
Примерно вот так.
Кроме того, байесовская регрессия, как бы это, сказать, «инертная». Имея в наличии десяток точек вдоль белой кривой и один outlier, она, скорее всего, прогнется в его сторону немного, но не до конца. И это, вообще говоря, хорошо и правильно, потому что а вдруг это очередной результат шума?
Примерно вот так.
Кроме того, байесовская регрессия, как бы это, сказать, «инертная». Имея в наличии десяток точек вдоль белой кривой и один outlier, она, скорее всего, прогнется в его сторону немного, но не до конца. И это, вообще говоря, хорошо и правильно, потому что а вдруг это очередной результат шума?
Почему ансамбли работают?
В машинном обучении есть такая очень простая техника — когда у вас есть несколько моделей и они все работают плохо, можно взять и усреднить (или еще как-нибудь объединить) их предсказания, и тогда они волшебным образом начинают работать хорошо. По-правильному это называется ансамбли, и их можно встретить почти где угодно, особенно на соревнованиях.
И вообще говоря, это не интуитивный вопрос: почему ансамбли вообще работают? В реальной жизни вещи редко ведут себя таким образом: если у вас есть десять плохих молотков, гвоздь не станет забиваться лучше от того, что вы будете использовать их по очереди. Иллюстрация к этому вопросу частично служит неплохой интуицией (по-моему) на тему того, почему работает байесовская регрессия. Выглядит это как-то так:
Зеленая линия — «сложная» модель (полином девятой степени), а синяя — «простая» (второй степени). Синией точки относятся к обучающей выборке, а красные — к тестовой. Желтая линия — простое среднее арифметическое между двумя моделями, и даже на глаз заметно, что она не такая размашистая, как зеленая, и действительно лежит ближе к красным точкам. Простота синего слегка компенсирует прыгучесть зеленого; средний вариант ближе к истине, чем оба отклонения, при условии, что отклонения направлены в разные стороны (это как раз одно из важных условий ансамблей — вам нужны разные модели для того, чтобы усреднение сработало).
Так вот, когда мы пытаемся предсказать что-то с байесовской регрессией, мы усредняем не две и не три модели, а — в нашем случае — два с половиной миллиона. Но погодите, на самом деле все еще круче. Это мы в своем кривом питонском коде ограничили коэффициенты значениями в -10 и 10 с шагом в 0.5, а если делать все по-правильному, они могут принимать любое значение на бесконечной числовой прямой. Секунду, включим калькулятор…
«Не-совсем-случайный бесконечнолес?»
От нейрона к множеству нейронов
Настало время немного разочароваться: способ, который мы придумали для расчета posterior, плохой и работает только для каких-то очень маленьких задач. Дело в том, что количество всех возможных сочетаний параметров, которые нужно перебрать, растет экспоненциально. Мы оценивали его как число значений параметра в степени числа параметров, и уже для полинома девятой степени (десять коэффициентов/параметров) нам в текущем сеттинге придется пробежаться по циклу 10485760000000000 раз.
А теперь настало время по-настоящему разочароваться: для более сложных моделей, то есть нейронных сетей (которые представляют собой просто несколько регрессионных юнитов, соединенных друг с другом), чистый байесовский метод становится еще более неприменимым. «Параметры» нейронной сети — это ее веса; а их в современных сетях может быть очень и очень много (миллионы штук с легкостью). Существуют всякие способы упростить этот процесс: например, случайным образом доставать значения posterior вместо того, чтобы рассчитывать его в каждой точки (это называется сэмплинг), но мы не зря их все проигнорировали — они недостаточно круты, чтобы помочь получить байесовскую нейронную сеть по-настоящему серьезных размеров.
На самом деле для каких-то отдельных моделей все еще хуже. Наши коэффициенты регрессии, грубо говоря, «ни от чего не зависели»; если мы хотим посмотреть, как ведет себя модель с таким-то набором параметров, мы можем просто взять его и подставить в формулу Байеса. В сетях распределение весов отдельного нейрона может зависеть от того, как ведет себя предыдущий нейрон, а тот, в свою очередь, зависит от предыдущего (а настоящее веселье начинается, когда зависимости замыкаются в цикл).
Собственно, это и есть главная причина, по которой лавочка не закрыта, люди продолжают бороться с переобучением
Что сделать, чтобы хоть что-нибудь работало
Мы можем немного отступить назад и удовлетвориться частичным решением проблемы: найти максимум байесовского пучка, самую близкую к центру и самую «горячую» кривую. Это будет не так круто, как знание пучка целиком, но все лучше, чем то, с чего мы начинали.
То есть мы ищем
Теперь смотрите: с
Подставляем вместо
Коэффициент перед экспонентой опять-таки не важен для поиска максимума (он не зависит от
Получается, что максимум достигается там, где сумма квадратов коэффициентов регрессии минимальна. Ничего не напоминает? Мы переизобрели регуляризацию, на минуточку, и получили отличное обоснование тому, зачем она вообще нужна (раньше это была какая-то технарско-инженерная штука, в духе «нуу, давайте просто заставим коэффициенты регрессии быть маленькими, чтобы она не прыгала туда-сюда», но с Байесом в ваш дом приходит просветление и все обретает смысл).
На статистическом жаргоне это называется maximum a posteriori или MAP-learning. В отличие от «чистого» Байеса, MAP отлично применяется и к нейронным сетям, и к чему угодно — под скромным именем «регуляризация». К сожалению, это не тру-байесовское решение, потому что в конце концов мы заканчиваем игру с каким-то штучным «набором параметров» — и поэтому такой подход тоже может страдать от переобучения, хотя и более устойчив к нему, чем метод максимального правдоподобия.
Маленький постскриптум
По мотивам дискуссии, начатой haqreu на тему того, православно ли пытаться объяснять математические вещи на пальцах, мне немного интересно общественное мнение на эту тему. Ткните куда-нибудь в опрос по результатам прочтения, если не затруднит?
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
haqreu
Большое спасибо, было интересно!
(Включаю тихо-занудный голос: argmax тоже должен быть набран прямым шрифтом, ровно как и log под ним.)
Strepetarh
Как привлечь внимание к надписи: написать её мелким шрифтом.
elite7
Переобучения не существует?
То есть вы увидели 100 белых лебедей и сделали вывод, что черных не существует.
Весь датасет из белых лебедей. И вы переобучились. В любом случае.
rocknrollnerd
А, ну да: обязательным условием к этому делу служит "датасет должен быть собран i.i.d.", т.е. из независимых и рандомизированных примеров. Собрать в датасет только белых лебедей равносильно тому, что я сделаю выборку из одних орлов при бросках монетки)
rocknrollnerd
Т.е., в вашем случае шаги такие:
Черных лебедей он при этом и правда не опознает — точно так же как радужно-урановых лебедей с планеты Солярис, например. Но "узнать о всех лебедях во вселенной" — это не задача машинлернинга, и по-моему, вообще сама по себе задача слабовыполнимая)
lightcaster
Что-то вы сложно отвечаете на простой вопрос. Тут весь смысл в том, что при байесовой оценке (MAP) вы не получите нулевую вероятность черных лебедей.
MLE оценка для черных лебедей (оцениваем матожидание mu):
mu = N_black / (N_white + N_black) = 0/100 = 0MAP оценка для черных лебедей, при условии бета-распределения на параметр mu B(alpha=5, beta=5):
mu = (N_black + alpha - 1) / (N_white + N_black + alpha + beta - 2) = (0 + 5 - 1) / (100 + 5 + 5 - 2) = 0.0370..То есть вероятность низка, но не нулевая.
ps спасибо за статью. Редко на хабре появляется байесовская статистика.
rocknrollnerd
Вы правы, но если белых лебедей будет стотыщмиллионов — то получите уже очень близкую к нулевой) "The data overwhelm the prior". Мне просто кажется, что это (черные лебеди) неудачный пример для переобучения — он интуитивно понятный, но неправильный. Когда алгоритму неоткуда узнать о существовании черных лебедей, у него нет никакого резона их предполагать — точно так же как зеленых, синих и фиолетовых)
Спасибо за фидбек)
ffriend
На чёрных лебедей, наверное, действительно можно забить, а вот, например, на новое слово в тексте — вряд ли. Т.е. если даже у вас есть архив половины интернета, то мы всё равно верим, что во второй половине есть слова, которые мы никогда до этого не видели. И вот эта вера переносит нас от частотного в байесовский подход и заставляет добавлять как минимум +1 ко всем вариантам (а как максимум, предполагать априорное бета распределение для параметров).
FlameStorm
Неплохой пример. На самом деле человек тоже переобучён. Видевший только белых лебедей будет уверен, что все лебеди белые. И очень удивится, увидев чёрного. Это не проблема чисто современных машинных нейросетей. Но, быть может, им не хватает "удивления". У человека в момент удивления происходит активизация гормонами всех процессов, в том числе записи опыта, событие "врезается в память".
Можно попробовать заложить механизм удивления. Например, хотя бы через умножение на порядок-другой поправок в веса от обратного распространения ошибки в нетипичном случае. И как понимаю, делать это нужно не ранее чем на 2-й прогон обучения, когда сеть уже даёт то, что от неё хотят в обычных случаях.
Monnoroch
Backprop итак даст сильно большие веса для нетипичных примеров. В данном случае несколько черных лебедей (один нельзя, вдруг кто-то его покрасил?) резко и брутально вытолкнет модель из ямы "все лебеди — белые".
arreqe
Hi, в разве теорема Байеса не P(theta | X) = P(X | theta) P(theta) / P(X), а не P(theta | X) = P(theta | X) P(theta) / P(X)? Или я что-то путаю, т.к. прогулял эту лекцию по ТВИМС ?)
rocknrollnerd
О черт, точно. Спасибо, что ткнули пальцем, это опечатка, конечно (как снизу тоже заметили)
Randl
Мой любимый парадокс в действии — еще две недели я потратил полдня разбираясь во всех этих правдоподобиях и апостриорных вероятностях — и вот статья, с которой я бы разобрался за час- полтора. Излагаете понятно и не заумно.
З.Ы. Зачем вариант "посмотреть результаты", когда есть "воздержаться"?
rocknrollnerd
Спасибо за фидбек) Не знал, что так можно было — а потом кажется, после создания опроса вариант убрать нельзя.
janatem
В формуле Байеса опечатка, которая потом лезет дальше по тексту под именем «правдоподобие». Грепать по $P(\theta | X)$.
rocknrollnerd
Упсссс. Спасибо, это косяк, конечно)
janatem
В последнем разделе не очень понятно, как удалось выразить argmax суммы по частям. Были найдены argmax'ы для каждого из двух слагаемых, но как потом из этого найти argmax суммы?
father_gorry
В какой-то момент у вас получились аттракторы. Если бы еще создать необратимость во времени, можно было бы научить сети выводить логически объяснимые закономерности или даже делать простейшие научные открытия.
entomolog
Мне вот интересно, имеет ли какое-то косвенное отношение рассмотренный вами подход к новомодному методу уменьшения переобучения, так называемому dropout.
Метод впервые был описан (насколько мне известно) в ImageNet Classification with Deep Convolutional Neural Networks. Alex Krizhevsky Ilya Sutskever Geoffrey E. Hinton
Но метод никак, кроме как на интуиции не обоснован. Суть примерно такая: а давайте с вероятностью 0.5 процентов будем выключать нейроны, чтобы они не расслаблялись и не начинали запоминать датасет.
Monnoroch
Во-первых, он не новомодный, ему уже лет пять как минимум.
Во-вторых, он еще как обоснован!
Т.е. вы как бы берете не одну сеть, а все 2^N возможных, но так, что каждый вес в матрице весов последнего слоя во всех сетях, в которые он попадает, одинаков.
rocknrollnerd
О да!)
Про дропаут, надеюсь, будет во второй части немного, но интересующиеся могут сразу заглянуть в статью Бланделла — там итоговая сеть как раз сравнивается с обычной-плюс-дропаут.
ffriend
Я на это всё обычно немножко с другой стороны смотрел. Есть некоторая зависимость
y = w0 + w1x1 + ... wnxn, которую мы хотим найти. Но, как учил дедушка Лаплас*, точные зависимости мы узнать не можем, поэтому должны работать с вероятностями. Тогда наше уравнение превращается в уравнение со случайными переменными:Где Y, X и W0..Wn — все являются случайными переменными. Классическая регрессия позволяет нам посчитать наиболее вероятное значение параметров W0...Wn, т.е. по сути представляет собой MLE. А вот чтобы из набора единичных параметров получить набор распределений этих параметров, достаточно всего лишь ресэмплировать наши данные нужно количество раз. Т.е. по сути вместо одной регрессии на всём нашем сэмпле мы строим, скажем, 100 регрессий на случайных 90% наших данных. 100 регрессий дают 100 значений каждого параметра, по которым уже вполне можно оценить их распределение. При этом не нужно ни проходить по всем возможным значениям параметров (как в вашем первом подходе), ни выводить аналитическую формулу (как в вашем втором примере… хотя формулы и хороши :)).
ffriend
Забыл про Лапласа. В своём замечательном эссе Пьер-Симон очень наглядно показывает, почему точные параметры вселенной нам недоступны, так что не стоит и пытаться. Зато статистическое описание мира позволяет вполне неплохо справляться с этой неопределённостью,
а не винить в чуме комету и не устраивать охоту на ведьм.Monnoroch
Все верно, только ваша модель будет ансамблем из ста моделей и если базовыми моделями будут нейронные сети, вы 100 штук будете до второго пришествия обучать. Поэтому хочется сделать такой ансамбль более хитрым методом и потратить не 100х времени, а 2х, как для dropout, но только получить не 2^N сетей с общими весами, а "бесконечное" число сетей, выраженное в распределениях весов в сети вместо самих весов. Тогда можно во время теста прогонять одну и ту же сеть 100 раз, каждый раз семплируя ее параметры из их распределений и получить то же, что вы предлагаете, но потратив в 50 раз меньше времени на обучение ансамбля. Как конкретно так обучать — видимо, будет в следующей статье, я, честно говоря, пока еще не до конца впитал оригинал и уверен, что вольный перевод rocknrollnerd мне поможет с этим.
Monnoroch
UPD: Ну, собственно, даже понятно в общих чертах как: вместо весов вы говорите, что каждый вес сэмплится из N(m, s) и теперь у вас вдвое больше параметров (по два на каждый вес), а потом с помощью матана доказываете, что так тоже можно использовать backpropagation с минорными изменениями.
Остается только непонятным, что в таких моделях с коадаптацией "весов" и не остается ли дропаут полезной техникой?
ffriend
Так вопрос именно в том, как получить рапределение параметров N(m, s), и один из самых простых способов — это ресэмплирование (при этом необязательно делать 100 сэмплов из 99%, можно и 10 сэмплов из 10% каждый, т.е разменять качество замеров на их количество при фиксированном количестве операций). Естественно, тут мы перекладываем головную боль с себя на компьютер — для той же линейной регрессии распределение параметров прекрасно выражается аналитически, но понять эти формулы без
веществпродвинутого курса линейной алгебры и матанализа практически невозможно.В общем и целом, стократное сэпмлирование — это вполне приемлимо и гораздо лучше 2560000 вычислений, вызванных перебором. А в целом ускорение обучения — это ооочень большая тема, и я бы её начал скорее с конкретной архитектуры сети ти с конкретных задач, чем с вариационных методов или обратного распространения ошибки.
Monnoroch
Может, мы о разном говорим, но распределение N(m, s) получается методом градиентного спуска по параметрам (m, s).
После обучения у вас получается не много MLE-сетей, а одна байесовская сеть, которая при каждом прогоне выдает сэмпл параметров (по сути, ту же MLE-сеть). Разница только в том, что метод с обучением классического ансамбля довольно эвристический в надежде что у базовых моделей ошибки противоположные, а тут ансамбль получается как бы выдающий сэмплы согласно уверенности в данных. Концептуально, одно и то же, но более математично: те же N сэмплов, только согласно выученному распределению, а не воле божьей.
Главная разница — это как раз тренировка. 2560000 регрессий — это просто демонстрация честного байеса для регрессии, в статье вместо метода "в лоб" используется backpropagation through posterior parameters, так что ли это называть.
Так же как вы не оптимизируете сеть методом случайного поиска в пространстве векторов параметров, а методом градиентного поиска, так и в оригинальной статье, они байесовский подход реализовали не построением модели для всех возможных комбинаций параметров и интеграцией, как тут автор для примера показал, а оптимизацей градиентным спуском.
Я очень вот сейчас надеюсь, что я понял все правильно, а не чушь тут горожу :)
ffriend
Ах, вот оно в чём дело. Просто, оригинальную статью я ещё не читал, и о том, что мы ищем параметры распределения через backpropagation и как можно быстрее, пока ещё не знаю. Поэтому меня и смутило, что в статье описан полный перебор и вслед за ним сразу аналитика с кучей допущений, а простое сэмплирование, которое гораздо быстрее перебора, но гораздо проще аналитики, прошло как-то мимо.
В общем, давайте я тоже прочитаю статью, а потом уже побеседуем более подробно, ибо просится много комментариев, но без контекста, которые уже есть у вас, но ещё нет у меня, разговор вряд ли получится осмысленным.
ffriend
Я пробежался по обеим статьям и теперь готов ответить. Сразу извиняюсь, если буду "доколёбываться до мышей", но вопрос тонкий и хотелось бы убрать все неточности.
"Байесовская сеть" — это устойчивое выражение, означающее направленную вероятностную графическую модель. Возможно, описанные в статьях сети можно сформулировать и так, но вроде нигде это не делается. Дальше в этом комментарии я буду полагать, что вы имели ввиду нейронную сеть с весами, описанными распределением.
Честно говоря, не нашёл такой информации ни в той, ни в другой статье. В моём понимании при прогоне данных через сеть на выходе мы получаем не набор сэмплов, а конкретное распределение, описывающее степень уверенности в каждом ответе. Это как с логистической регрессией: на выходе у нас не просто 1 или 0, а вероятность P(1), а вот что с этой вероятностью делать — это уже вопрос к пользователю (например, банк может быть заинтересован в выдаче кредита человеку, для которого вероятность вернуть кредит значительно меньше 0.5).
Как раз если брать классическое ресэмплирование, то у него очень даже хорошее математическое обоснование и минимум допущений. В общем-то, сэмплирование как раз и используется в описанном методе для минимизации разницы между распределениями P и Q (см. cекцию "Unbiased Monte Carlo gradients" во второй работе).
Вот тут не понял, что есть байесовский подход? Байесовский подход к статистике (в противоположность частотному) предполагает некоторую априорную веру в параметры распределения, однако все описанные методы вроде как опираются исключительно на частоту данных.
Monnoroch
Вы все правильно понимаете, но я не об этом говорил. BNN — это не feed-forward сеть, через нее нельзя прогнать данные. Сначала мы из модели BNN семплируем много обычных NN согласно распределениям параметров, а потом прогоняем данные через эти обычные NN и получаем обычные распределения по классам или на что мы там учились. Получается тот же ансамбль, только базовые модели — это семплы из BNN, а не просто модели, параллельно обученные на разных подмножествах данных в наивной надежде, что ошибки при их усреднении "сократятся", а не усилятся.
Я имел ввиду именно то, что вы сказали. Автор этого вольного перевода пошел в лоб согласно теореме Баеса для получения posterior на параметры интегрировать по всему пространству параметров (считать 100500 регрессий). А в оригинале они приближают этот posterior вариационным методом и оптимизируют некую функцию градиентным спуском.
ffriend
Да почему же, вроде обычный belief propagation здесь должен сработать на ура.
Да почему же в наивной надежде, эта "надежда" является прямым следствием центральной предельной теоремы: у вас есть N моделей обученных на разных сэмплах из изначальной выборки, т.е. N сэмплов функций f_i(x) из одной "популяции функций". Прогоняя фиксированные данные x через эти функции f_i вы получаете N матожиданий. По центральной предельной теореме эти N матожиданий будут иметь нормальное распределение, для которого тоже можно посчитать своё эмпирическое матожидание, которое будет ничем иным как средним арифметическим от всех f_i(x). И это работает что для N сетей обученных на рахных сэмплах данных, что на N сэмплах сетей (параметров), обученных на одних данных.
Так это использование байесовской теоремы, которая к байесовскому подходу имеет весьма слабое отношение ;)
Байес вообще был классный мужик, но 1) формула Байеса; 2) байесовское определение вероятности; 3) байесовские сети вообще связаны друг с другом весьма апосредованно.
Monnoroch
Уууу, ну вы загнули, вы хотите BNN трактовать, как графическую модель и считать распределение выходов given input, я правильно понял? Да вы знаете толк :)
ЦПТ работает при числе сэмплов, стремящемся к бесконечности. Ни разу не видел, чтоб был у кого-то ансамбль больше, чем из десятка сетей, а обычно две-три-четыре, что почти наверное является слишком грубой аппроксимацией ЦПТ. Так что это таки надежда.
Ну да, вы меня поймали, я не очень успешно оперирую терминологией, особенно на Русском. Под Байесовыми сетями я, конечно, имел ввиду BNN, а не графические модели, а под Байесовским методом я имел ввиду подмену параметров модели на их распределения и использование posterior из формулы Байеса для сэмплирования этих параметров.
Мне кажется нормальным в комментариях оперировать терминами в контексте статьи без уточнения. Тем более, статьи на такую тему :)
ffriend
В общем и целом, нейронные сети довольно просто обобщаются до байесовских или марковских, нужно только проверить и причесать всю математику в них. Правда, судя по всему вы всё-таки правы и конкретно в этих работах действительно сэмплируются параметры.
ЦПТ даёт теоретическое обоснование, на практике же есть 10-fold cross validation, которая прекрасно работает на практике, хотя и использует всего 10 сэмплов.
Monnoroch
Теорию можно сколько угодно обобщать, но считать машина вывод в графической модели будет до второго пришествия. Это просто непрактично.
Конкретно во второй статье в экспериментах они, похоже, вообще один сэмпл берут. Я даже спросил, и похоже там суть не в качестве, которое получается, а в том, что сэмплированные модели качественно другие выходят, чем сети, обученные обычным backprop.
Я раньше с деревяшками всегда 200-fold использовал, это считалось стандартом у нас :)
ffriend
У вас какое-то негативное представление о PGM :) Вероятностные сети могут быть очень разными, но в обученной байесовской сети, особенно если она дискретная, вывод делается за линейное время и количество операций чуть большее, чем в стандартной feedforward нейронной сети. С неприрывными переменным всё немного сложней, там нужно, чтобы априорное и апостериорное распределения были сопряжёнными, чтобы апостериорную вероятность можно было считать аналитически, а это не всегда практично. Но и тут есть куча обходных путей, начиная с сэмплирования и заканчивая тем же вариационным Байесом. Так или иначе, это вопросы к методу, вычислительно в большинстве практических сетей ничего тяжёлого нет.
Monnoroch
Наверное, вы лучше меня разбираетесь в этом, не могу спорить, но мне всегда казалось, что вывод в графических моделях подразумевает явное построение совместного распределения всех нужных переменных из этой графической модели, что дает многомиллиономерный такой паралеллепипед даже в случае дискретных распределений величин.
Возможно, я просто не разбираюсь достаточно хорошо в теме графических моделей.
ffriend
Как раз построения полной совместной вероятности все пытаются избежать. Я как-то считал, что таблица полной вероятности для RBM с какими-то шуточными 1000 видимыми и 100 скрытыми бинарными узлами, имеет размер примерно на 5 порядков больше, чем количество атомов во вселенной :) А вот как раз факторизация на графическую модель и параметризация через лог-линейные модели (те же веса) позволяет вполне спокойно с этим работать.
ZlodeiBaal
Правильно ли я понимаю, что на таких сетях какого-то дельного результата так и не смогли показать? Я пару лет назад что-то пробовал сделать на них, но получилось неубедительно (если я правильно помню, брал реализацию из Accord).
Из тех статей что я читал тоже получалось, что какого-то качественно нового результата получить не удалось.
Но оно, конечно, офигенно красиво с точки зрения математики, это я не спорю:)
Сам долго впечетлялся.
rocknrollnerd
Там в самом начале две ссылки — вообще идея написать пост была про эти две статьи, но пришлось немного разбить его, потому что вводная в Байеса слегка затянулась) Вторая часть будет про сети, с примерами, шахматами и поэтессами.
Если вкратце, то получилось много чего, особенно за последний год — вот небольшое ревью на тему NIPS 2015, и там можно кликать по всему, где есть слово "variational")
Monnoroch
А круто получается, что если модель не подвержена переобучению (given good data), то можно обучить супербольшую модель с соответствующим улучшением качества на тесте, а потом занулить 95% весов, как они в статье сделали.
PavelMSTU
Философский диспут.
Некорректная метафора!
Корректная метафора.
У вас есть три молотка.
Если вы разберете все три молотка — вы можете собрать один молоток, у которого хороший наболдашник, удобная ручка и титановый гвоздь.
В ML у нас есть процедура "усреднения", которая недоступна в физическом мире… Вот и все отличие.
dimview
То, что вы описали, не очень похоже на усреднение. Даже если правильно переставить делали, кроме одного хорошего молотка получится два плохих. Чтобы выбрать из трёх молотков хороший, надо обладать знанием, которое модели недоступно.
PavelMSTU
Если у вас "наболдашник" имеет три степени помятости: "совсем помятый", "немножко помятый" и "идеальный"; то среднее арифметическое будет "немножко помятый".
Если ручка имеет три степени "гнилости": совсем сгнила, немножко сгнила, идеально новая; то среднее арифметическое будет "немножко сгнила"
Аналогичные рассуждения с гвоздем.
Если бы мы умели усреднять, то получили бы молоток со слегка подгнившей ручкой и немножко помятым наболдашником. Вполне сносный инструмент, я считаю.
dimview
Ансамбли хорошо работают не просто потому, что у них внутри много моделей, а потому что у них внутри много разных моделей. Например, в случайном лесе отдельные деревья специально выращивают на разных подмножествах независимых переменных.
Чем более кардинально отличаются модели в ансамбле, тем больше пользы от усреднения их результатов. У очень разных моделей ошибки скорее всего в разных местах, поэтому с добавлением новых моделей сигнал растёт пропорционально количеству моделей, а шум — пропорционально корню их количества, отсюда и выигрыш.
А если модели примерно одинаковые, то и ошибки у них тоже примерно одинаковые и сигнал с шумом растут вместе.
Monnoroch
Фишка Байесового фреймворка как раз в том, что модели получатся более похожие в тех частях входного пространства, где модель очень уверена в своих знаниях, в тех же частях пространства входов, где модель уверена меньше, дисперсия получившихся распределений весов сильно выше, что скажется на большем разнообразии моделей при их сэмплировании из Байесовой сети.
Короче, чем более "сложный" для сети вход, тем большее разнообразие в базовых моделях генерируемого сэмплами ансамбля.
dimview
Всё равно мало разнообразия. Тут все модели по сути одинаковые — одна и та же линейная регрессия, отличие только в коэффициентах. Можно посчитать корреляцию между коэффициентами и она наверняка получится весьма сильной, то есть предсказывают они почти одно и то же почти одинаковым способом.
А от ансамблей больше всего пользы, когда модели в ансамбле принципиально разные — регрессия, деревья, ближайший сосед, адабуст, экспертная оценка, больцмановские машины и так далее. Каждая сходит с ума по-своему, но на среднее значение заскоки отдельных моделей мало влияют.
Monnoroch
Это вы просто почему-то думаете, что нейронные сети с одинаковой топологией но разными параметрами — недостаточно разные. А они очень разные. Прямо вот совсем. Если каждый параметр распределен как N(0, s_i), то выбрав два сэмпла, у вас на руках два, предположим, стомиллионномерных вектора. Основная масса координат этих векторов будет в (-s_i, s_i), так что если в вашей паре параметры будут отличаться на s_i / 4, что очень вероятно, если выбрать достаточно много сэмплов, то это уже отличие на 1/8 основной части "мира" параметров.
Как-то я, наверное, неформально описал, но основная идея, что если кажется, что сети одинаковые так как параметры отличаются на небольшие значения, то это иллюзия, модели отличаются очень сильно.
Да вы хоть посмотрите на людей: насколько все разные, а ДНК отличается на какие-то мизерные доли процента. А тут модели вполне могут на 15% только так отличаться.
buriy
Обязательно пишите ещё. Тема классная, похоже, многие мечтают совместить достижения классической теории вероятности и нейросети. И даже жалко становится, что нейросети работают так хорошо сами по себе (особенно, с dropout и batch normalization), что теорией вероятности их улучшить пока толком не получается…
В этом плане мне очень понравилась статья http://mlg.eng.cam.ac.uk/yarin/blog_3d801aa532c1ce.html, по-моему, она могла бы стать частями 3, 4 и 5 вашего повествования.
Классическая теория вероятности позволяет оценить степень уверенности в знании, возможно, это помогло бы нейросетям меньше страдать от переобучения и ещё быстрее и ещё качественнее обучаться на смеси из небольшого количества классифицированных (supervised) и большого количества неклассифицированных (unsupervised) данных.
seis
Про ансамбли есть хорошая история о Фрэнсисе Галтоне и толпу зевак с ярмарки, которые пытались угадать вес мяса с разделанного быка — медиана по восьми сотням предположений отклонялась от реального веса на 0,8%.
rocknrollnerd
Прекрасно)
alexkolzov
В Ваших формулах я заблудился. По порядку сверху вниз. Если Вы максимизируете правдоподобие, то лучше явно указать, что это функция от вектора параметров распределения. Обычно же она записывается так: . Ваши обозначения заставили меня засомневаться в сохранности метода максимального правдоподобия в нейросети внутри моей черепушки. Странные они. В формуле слева почему-то индексируются параметры распределения, а справа с одним индексом и точки выборки, и параметры распределения. Я с просонья долго не мог понять, что Вы имели ввиду. И сейчас не понял, разве что ошибка обозначений. Неплохо также указать, что argmax берется по множеству допустимых параметров распределения, которые фиксируются в распределении, мне это показалось не очевидным из изложенного. А ведь это, если я правильно понял, основное отличие классики от далее излагаемого. Дальше то же, индексация непонятна.
. Ваши обозначения заставили меня засомневаться в сохранности метода максимального правдоподобия в нейросети внутри моей черепушки. Странные они. В формуле слева почему-то индексируются параметры распределения, а справа с одним индексом и точки выборки, и параметры распределения. Я с просонья долго не мог понять, что Вы имели ввиду. И сейчас не понял, разве что ошибка обозначений. Неплохо также указать, что argmax берется по множеству допустимых параметров распределения, которые фиксируются в распределении, мне это показалось не очевидным из изложенного. А ведь это, если я правильно понял, основное отличие классики от далее излагаемого. Дальше то же, индексация непонятна.
Потом Вы показываете, что в случае наличия аддитивного гауссового шума (зафиксировав дисперсию, но об этом позже) метод максимального правдоподобия сводится к методу наименьших квадратов. И после этого применяете ММП к тестовой выборке! Это после критики классической регрессии в самом начале статьи! Да, последовательно, по одной точке за раз, итеративно уточняя параметры распределения, рассматривая их как случайные величины и вводя дополнительные предположения относительно характера их распределения. То есть, на мой скромный взгляд, не очень четко показана сама фишка описываемого метода. Как такой подход избавляет от проблемы переобучения? Видимо, следствие попытки не залезать в математические премудрости.
Отдельно относительно заявления о невосприимчивости байесовского обучения к проблеме переобучения. Чем подкреплен этот вывод? В случае с минимизацией квадратичного функционала типа того, что используется при обучении нейросетей, проблема переобучения обычно возникает при многократном натаскивании нейросети на одних и тех же данных. Статистически это в определенной мере равнозначно утверждению, что шум в них имеет минимальную дисперсию. Вы в своем примере постулировали заданный уровень дисперсии, ровно как и вид распределения шума (что, кстати, обычно приводится как недостаток параметрических статистических методов байесовского типа), после чего указываете на небольшой разброс правдоподобных кривых. Ясен пень он оказывается небольшим.
И всё-таки за статью спасибо, заставила заинтересоваться вопросом. Вероятно, я в чем-то неправ. Поправьте.
rocknrollnerd
Привет) Правдоподобие все-таки записывается как-то не так, кажется (у вас оно выглядит как совместное распределение). Индекс i у параметров распределения и у икс действительно один и тот же — тут я просто последовал картинке, которая была нарисована перед этим (с лежащим на боку гауссианом): мы как бы считаем, что у каждой точки "свое" среднее значение и "свое" стандартное отклонение. Второе мы потом фиксируем, так что индекс тут, наверное, действительно может быть обманчив, но первое вроде бы индексировано правильно — на каждую i-тую точку у нас есть i-тое мю.
Следующий абзац я немного не понял. У меня тут нигде нет тестовой выборки (кроме слайда про ансамбли) — везде в остальных местах одни и те же десять точек, а "адекватность" регрессии предлагается оценить на глазок.
По поводу переобучения вот да, возможно, стоило рассмотреть подробнее. Тут дело не столько в дисперсии, сколько в том, сколько у нас есть данных и насколько сложная у нас модель:
alexkolzov
Так, давайте разбираться. Правдоподобие — это функция параметров распределения, показывающая (нестрого) степень вероятности того, что выборка отвечает именно этому распределению именно с этими параметрами. Эта функция определяется относительно имеющейся выборки. В приведенной мной формуле p — плотность вероятности параметрического распределения. Корректней было бы написать тету как нижний индекс, но и такая запись допускается. Имейте ввиду, что в википедии, на которую Вы ссылаетесь, приводится нестрогое определение функции правдоподобия, в вашем случае неверное — Вы используете непрерывные случайные величины, для которых вероятность принятия любого конкретного значения равна нулю. Далее, если Вы приписываете каждой точке свои мат. ожидание и дисперсию — то они, очевидно, не принадлежат одному и тому же распределению и говорить о правдоподобии не имеет смысла, поскольку эта величина характеризует распределение относительно выборки. Именно поэтому формула и поставила меня в тупик: по какому множеству берется аргмин, если вроде как свободные параметры в формуле проиндексированны?
Вы ведь строите регрессионную модель по ЭТИМ девяти точкам? Значит это и есть выборка.
Насчет сложности модели — здесь несколько интересней. "Сложная" модель обычно имеет большое количество реализаций, которые в заданной эпсилон-окрестности (в рамках модели сигнал-шум она как раз связана с дисперсией) приближают небольшие наборы данных. Причем обычно такие модели включают в себя как подмножество более простые, типа как полиномы высоких степеней включают полиномы низших степеней. Проблема переобучения тогда заключается в искусственном операционном занижении адекватной окрестности, частный случай — требование полного попадания в точки выборки. Проблема выбора подходящей окрестности — это да, проблема, решаемая обычно примерно и эвристичеки, в частности, оценкой качества на тестовой выборке.
Но с практической точки зрения Вам ведь в конечном счете необходимо остановиться на одной-единственной модели — и Вы это делаете, выбирая реализацию с максимальным правдоподобием. Ровно также, как это делается в "классическом" случае. Так что в этом аспекте я принципиальной разницы не уловил, и в том и в другом случае Вы имеете дело со сжатием к множеству адекватных выборке моделей и к выбору из него по какому-либо критерию единственного решения.
mrgloom
Может кто нибудь еще объяснит про Bayesian optimization?
https://en.wikipedia.org/wiki/Bayesian_optimization
VMAtm
Огромное спасибо за статью, стало гораздо понятнее. Единственное, что ещё хотелось бы — можно ли картинки положить на хабра сторадж? А то много чего не видно, и непонятно, как заставить это всё работать на рабочем компе.
rocknrollnerd
Спасибо! Пост готовился по вот этой замечательной технологии, почему все картинки заливались автоматически. И при всем горячем одобрении к хабрастораджу, пусть они лучше поддержку MathJax в посты добавят, не так уж это и сложно ведь)
kaichou
Байесовская нейронная сеть при очень большом количестве элементов не будет ничем отличаться от «классической», с весами, верно?
rocknrollnerd
Э, кажется нет, будет) А почему такие мысли?
kaichou
Соображения не подкреплены формулами, только рассуждения по аналогии.
> веса которой представлены не числами, а демоническими облаками вероятности
Микромир с вероятностными законами квантовой физики на очень большом количестве частиц (10^20, например, по порядку) превращается в «наш» макромир, вполне строгий и логичный.
Если для электрона туннельный эффект в порядке вещей, то для чайника вероятность оказаться за стенкой равна нулю.
«Чудо-эффекты» вероятности «гасятся» большим количеством элементов в макросистемах.
Тот же эффект будет наблюдаться в байесовских нейронных сетях, м?
Leo5700
По стилю изложения: на мой вкус — отлично, читается легко, написано не пошло и по делу.
С нетерпением жду продолжения изысканий, автору спасибо.