
И сегодня мы займёмся совмещением приятного с полезным: разберём интересную (практическую) аналитическую задачу и заодно проанализируем ряд факторов, определяющих (не-)применимость нейронных сетей к аналитическим задачам.
Представьте, вы работаете аналитиком в какой-нибудь компании, которой важен её облик на Хабре (условно назовём её Почта.com). И тут к вам приходит девушка из PR-отдела и говорит: "Мы с менеджерами определили в качестве важного KPI нашего бренда Хабра-рейтинг компании. У нас есть бюджет и мы хотим понять, как его распределить, чтобы максимизировать Хабра-индекс. Нам нужно, чтобы ты определил ключевые факторы, которые на него влияют и вывел наиболее разумную стратегию. Попробуй там какие-нибудь нейросети".
Во время этой речи у вас начинает дергаться глаз, но спустя пару минут составляете список вопросов для анализа:
- Q1: Какие ключевые факторы влияют на Хабра-индекс компании?
- Q2: Где найти данные?
- Q3: Какой будет оптимальная стратегия согласно восстановленной эмпирической зависимости?
Структура статьи
- Определяем потенциальные факторы
- Сбор данных
- Эффект кармы и рейтинга подписчиков и работников
- Финальная формула
- Анализ применимости нейросетей
- Анализ оптимальной стратегии
Изначальный комментарий:
И ответ (отсюда):

Вообще, серьёзность подхода видна уже по презентациям компании на тему:

Определяем потенциальные факторы
Если взглянуть на профиль компании, то в глаза бросаются следующие возможные кандидаты:

Причем параметры могут состоять из целой группы переменных: карма и рейтинг сотрудников, количество просмотров, избранного, плюсов у статей, а также их количество, etc.
И тут самый интересный момент: feature construction, а что собственно является фактором определяющим Хабра-индекс? И почему это столь важно? Например, чтобы алгоритм машинного обучения "выучил" настоящую исходную функцию, нужно чтобы исходная функция была определена в правильном пространстве, которого у нас нет!
В некотором смысле это порочный круг — нужно знать, что пространство (или подпространство) содержит ключевые факторы, чтобы восстановить зависимость. Но в данной ситуации, если известны ключевые факторы (или их надмножество), то задача фактически решена.
Верное представление пространства характеристик (feature space)
Чуть более формально, это можно описать так: локальные закономерности присутствуют в нашем представлении данных, то есть у нас "верное представление" всех параметров функции, которую мы хотим выучить. Если настоящая функция f(X,Y,Z), а в нашем представлении есть только X и Y, то мы ищем функцию в заведомо неверном классе F(X,Y), не учитывающем Z. Этим реальные задачи существенно отличаются от Kaggle, нам ничего не дано.
Научный метод тыка
Как определить, что фактор важен? Мы знаем, что зависимость детерминированная, то есть есть некоторая аналитическая функция, по которой ТМ однозначно считает индекс. Обозначим, функцию индекса за f, тогда f зависит от фактора xi, тогда и только тогда когда для любых xi верно что:

и с мы будем называть величиной эффекта.
Данное определение не предполагает независимости между переменными. Если переменные зависимы, значит, что c для i-го фактора может меняться в зависимости от остальных переменных.
Также мы знаем, из нашего опыта, что функция обязана удовлетворять граничному условию:
Важный момент: интеграция сильных априорных представлений о том, какой должна быть функция в нейронные сети — задача совершенно нетривиальная.
Таким образом ключевое наблюдение в вопросе Q1: необходимо адекватным образом трансформировать данные из профиля компании (например, перечисленные выше) и произвести замер эффекта, по одному удаляя искажающие факторы (confounding variables). Также необходимо будет проверить условие факторизации, то есть, что переменные независимы друг от друга:

Сбор данных
Отправляемся по адресу: https://habrahabr.ru/companies/ на самую последнюю страницу и видим, ценнейший материал:
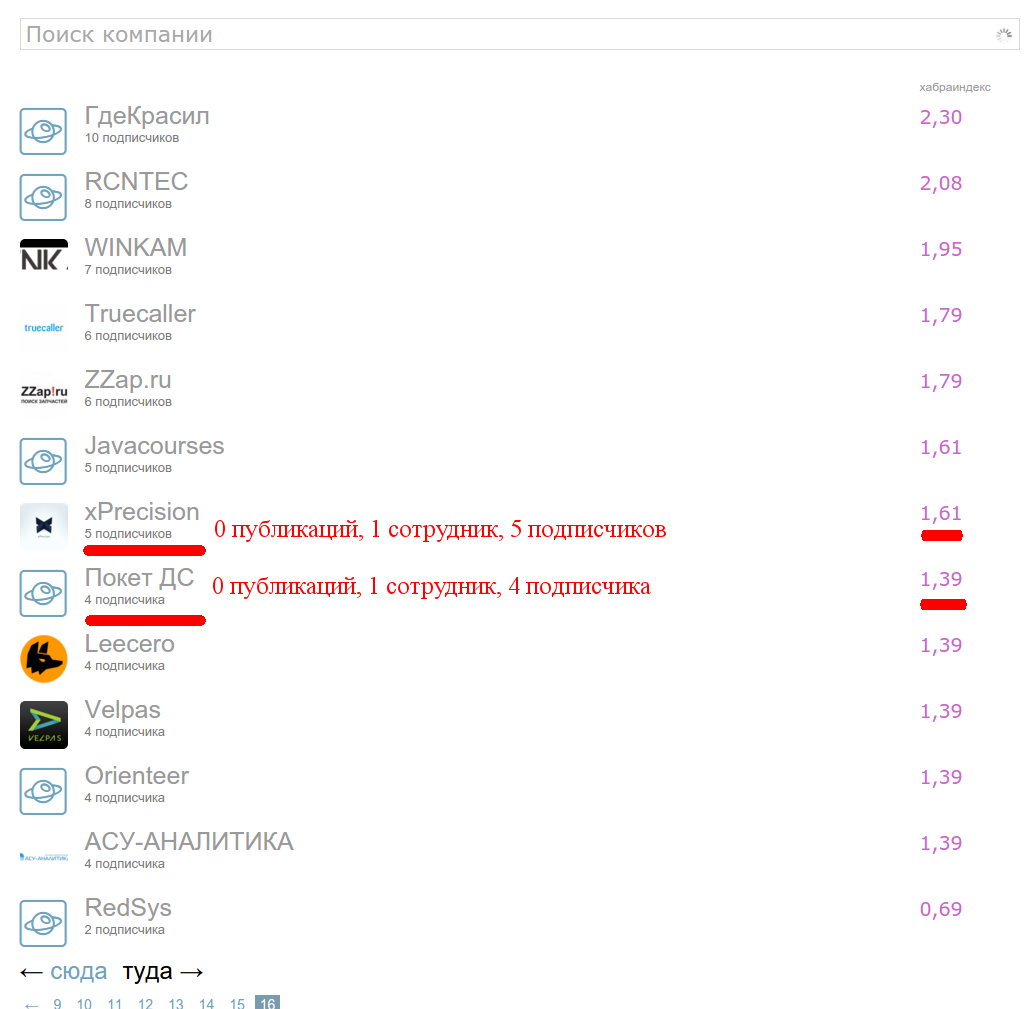
Подписчики
Это набор компаний, с нулём публикаций и небольшим числом сотрудников (один-два) и небольшим числом подписчиков. Выбрав две компании — xPrecision и Покет ДС с одинаковым числом сотрудников и разницей в одного подписчика, мы нашли ненулевую разницу в Хабра-индексе.
Бинго: первый фактор определяющий Хабра-индекс число подписчиков! Заметим, что рост явно не линейный — достаточно взглянуть на компании в начале, середине и конце списка. Логично, что функция должна насыщаться при достаточном числе подписчиков, чтобы не было накруток и вообще фактор подписчиков не доминировал сами статьи. Значит функция, должна расти медленно и в какой-то момент выходить почти на константу. Хм, логарифм!
log(2) = 0.69
log(4) = 1.39
log(5) = 1.61
.....
Итого, убеждаемся, что функция имеет вид:
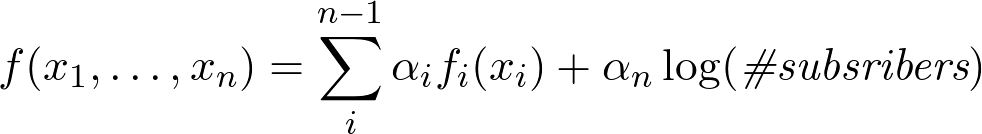
Заметим, что функция не зависит от кармы подписчиков, так как log(8) = 2.08:
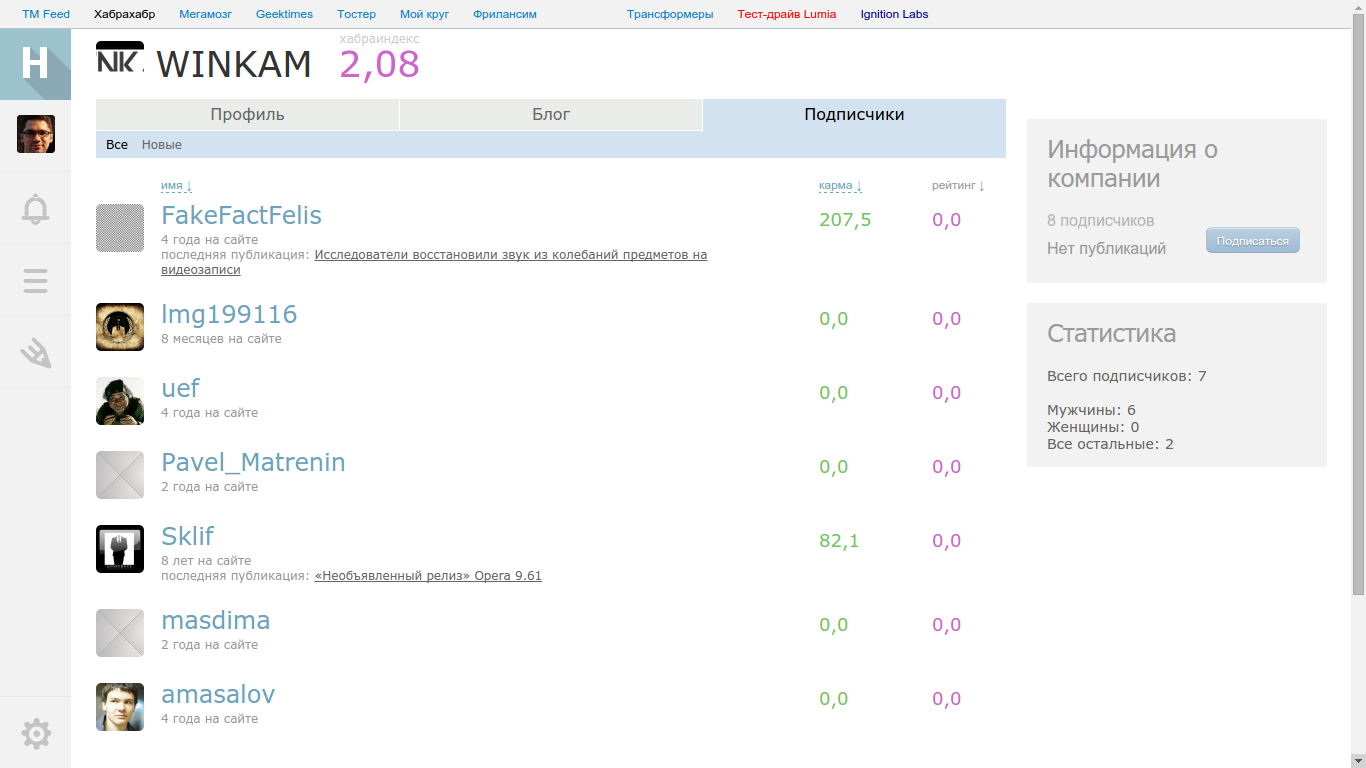
Причем коэффициент равен 1, если у компании нет публикаций, и равен 3, если есть (как показал дальнейший анализ).
Сотрудники
Рассмотрим 15ую страницу и возьмем две компании с одинаковым числом подписчиков и разным числом сотрудников:
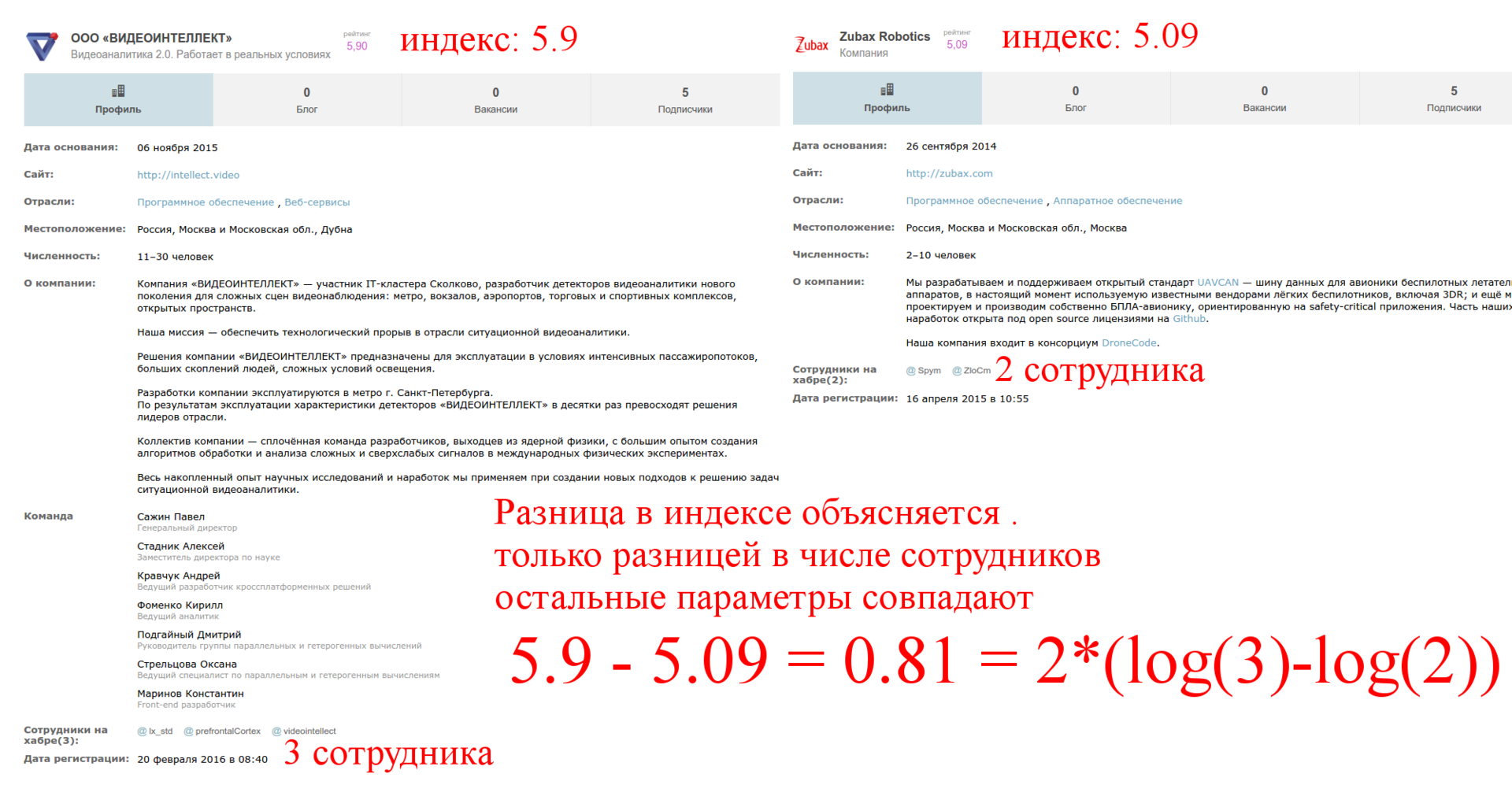
Второй фактор: логарифм числа сотрудников. Опять же это логично, нельзя, чтобы наличие сотрудников доминировало над статьями. Причём, множитель перед логарифмом тоже зависит от других параметров.
Формула приобретает вид:
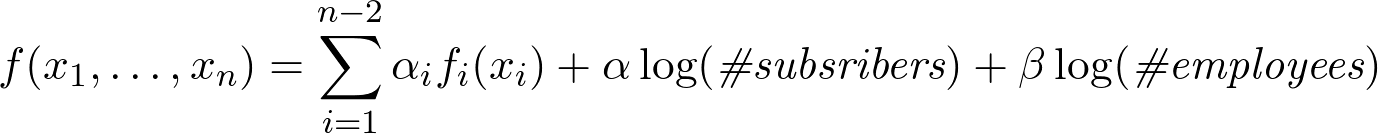
Влияние старых заслуг (по статьям)
Плюсы за старые статьи (~ больше месяца) влияния на рейтинг не оказывают:
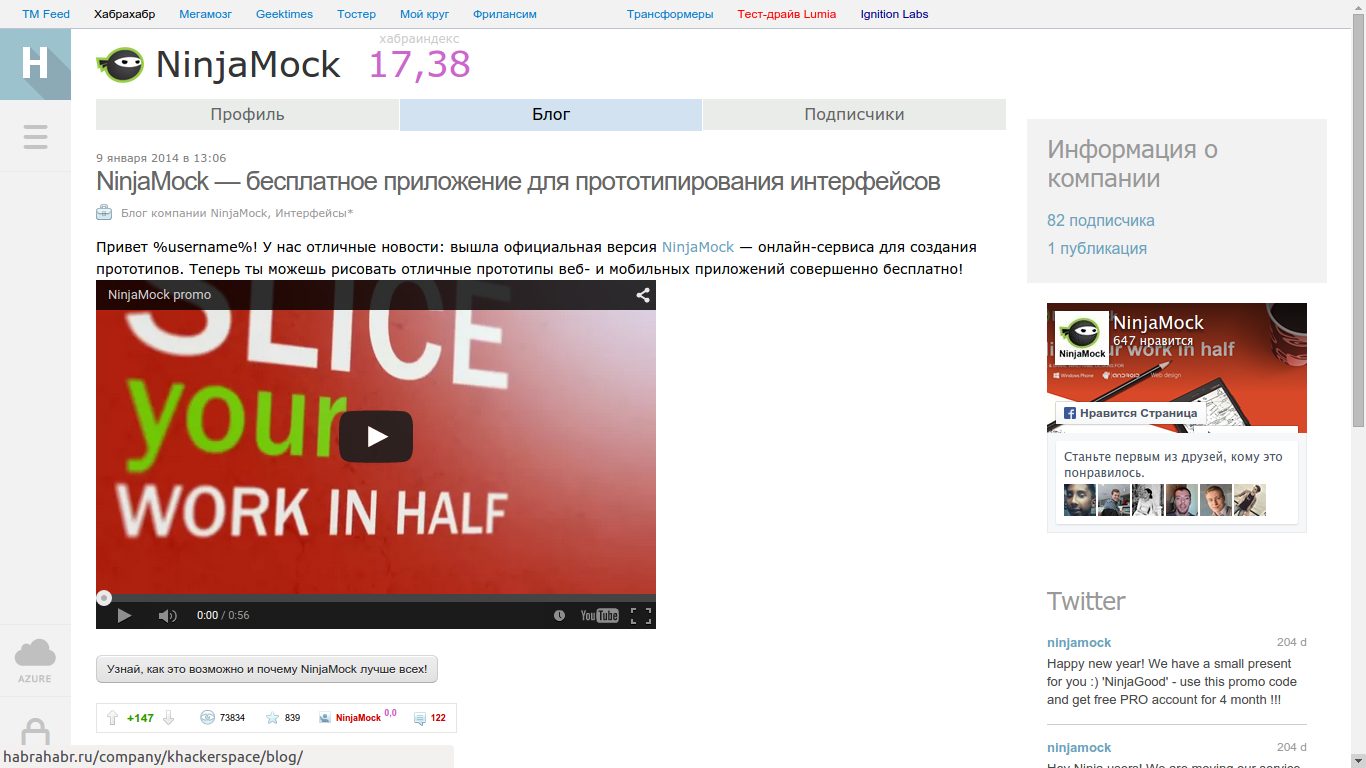
Как мы видим старые статьи, даже в большом плюсе влияния не оказывают
Нехватка данных
Важнейшим условием применения нейросетей является наличие существенного объема данных, в котором "сигнал сильнее шума", причем пространство фич должно быть соотвествующим. То есть даже если у нас было много шумовых точек, имеющиеся закономерности бы определились сквозь шум. Как можно заметить, у нас фактически нет данных вообще, тем более явно демонстрирующих закономерности. А пространство особенностей небольшое и имеет какую-то несложную структуру (практически факторизуется). Таким образом Q2 подсказывает нам, что не стоит применять нейросети, если у вас нет большого количества адекватно размеченных данных.
Вывод: данные необходимо откуда-то достать. Пусть и в очень небольших количествах, но они нужны для точного формирования гипотез.
Где можно достать качественные исторические данные, когда их нет? Internet Time Machine!
Например, определяем, что временная константа для рейтинга корпоративных блогов порядка месяца, заглянув в историю компании:
http://web.archive.org/web/20151220201116/http://habrahabr.ru/company/oda/
Также мы хотим понять, как влияют плюсы к статьям. Для этого нам нужно узнать рейтинг компании сразу после того, как плюсы за статьи перестают учитываться — найти такие данные среди имеющихся в списке компаний фактически невозможно, так как должны совпасть практически все параметры, кроме плюсов к статье.
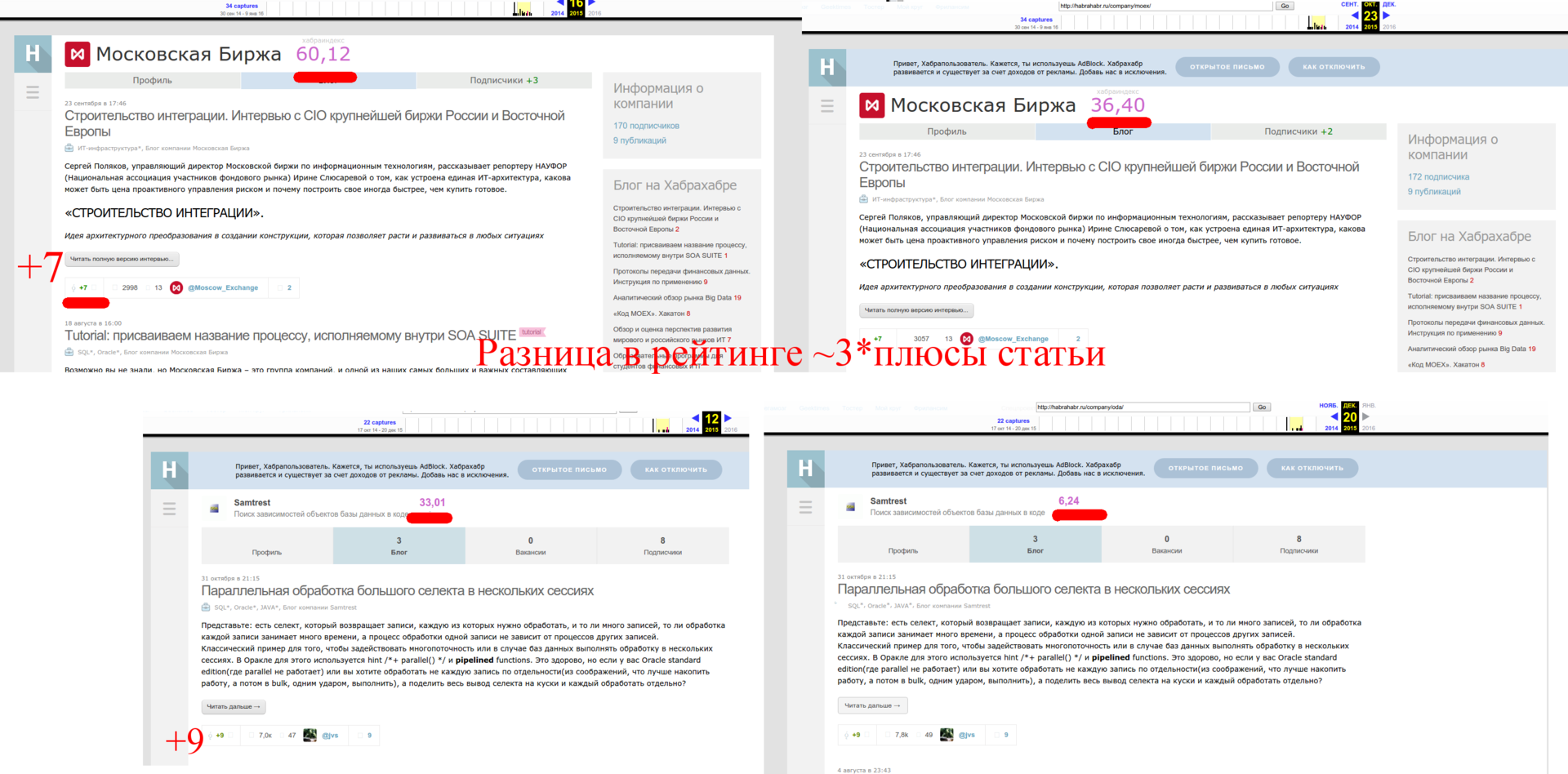
Таким образом формула принимает вид:
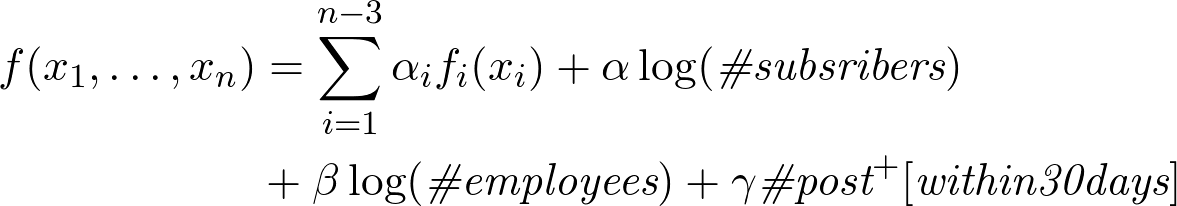
Причем, если мы произведем анализ рейтинга до появления поста и после, мы поймём, что если у компании есть хотя бы один пост, то рейтинг от подписчиков и работников увеличивается втрое и коэффициенты имеют следующий вид:

Заметим, что оценка коэффициента линейного члена примерная, но нам скорее важен сам характер зависимости, нежели абсолютно точное значение коэффициента.
Определяем эффект кармы и рейтинга подписчиков и работников
Рейтинг сотрудника
Для анализа данного эффекта нужно собрать столь нетривиальные данные, что тут даже Машина Времени Интернета бессильна. Но не будем отчаиваться, у меня как раз оказался доступ к панели управления одной компании и там виден рейтинг во времени:
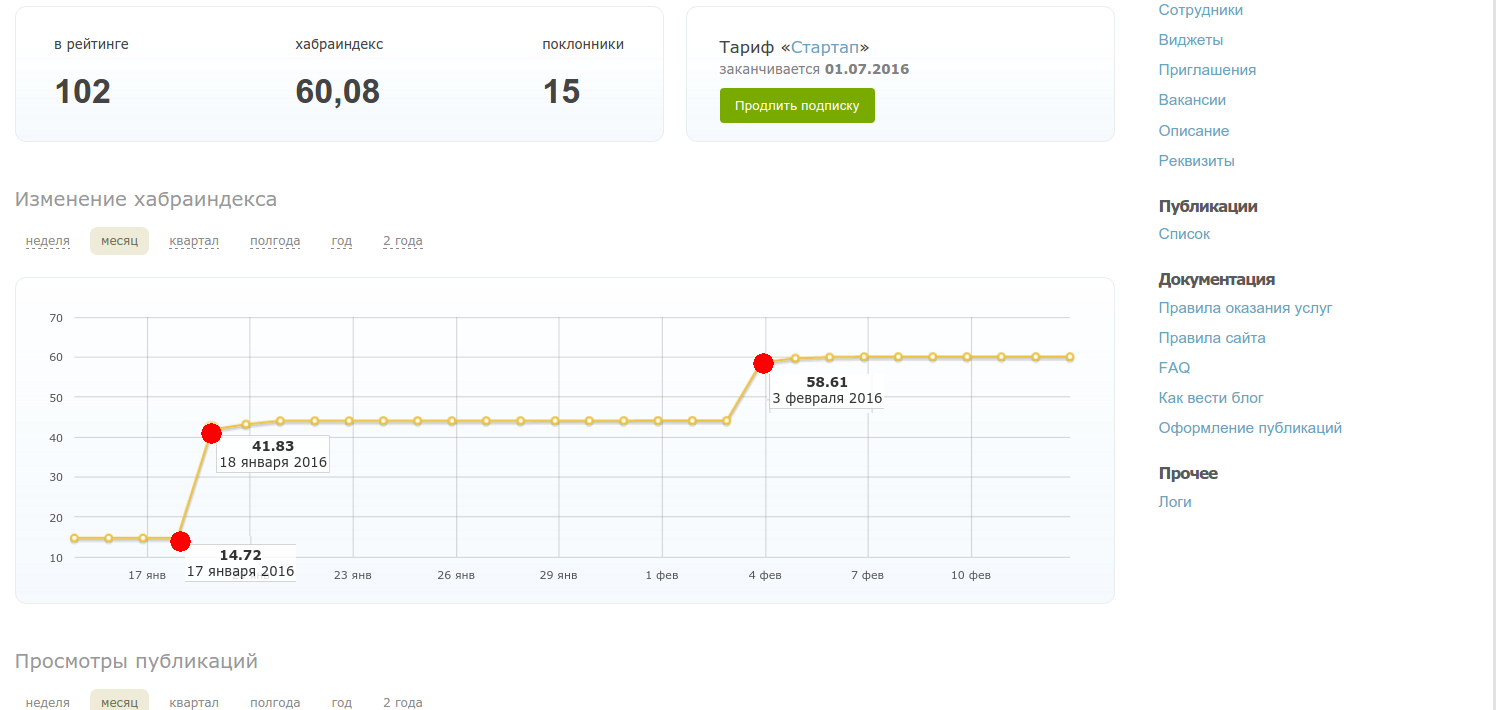
Эти точки соотвествуют моменту, когда у меня поднялся рейтинг от других статей. Значит рейтинг работников влияет на Хабра-индекс, анализ показывает, что снова логарифмически, с коэффициентом примерно равным 9:
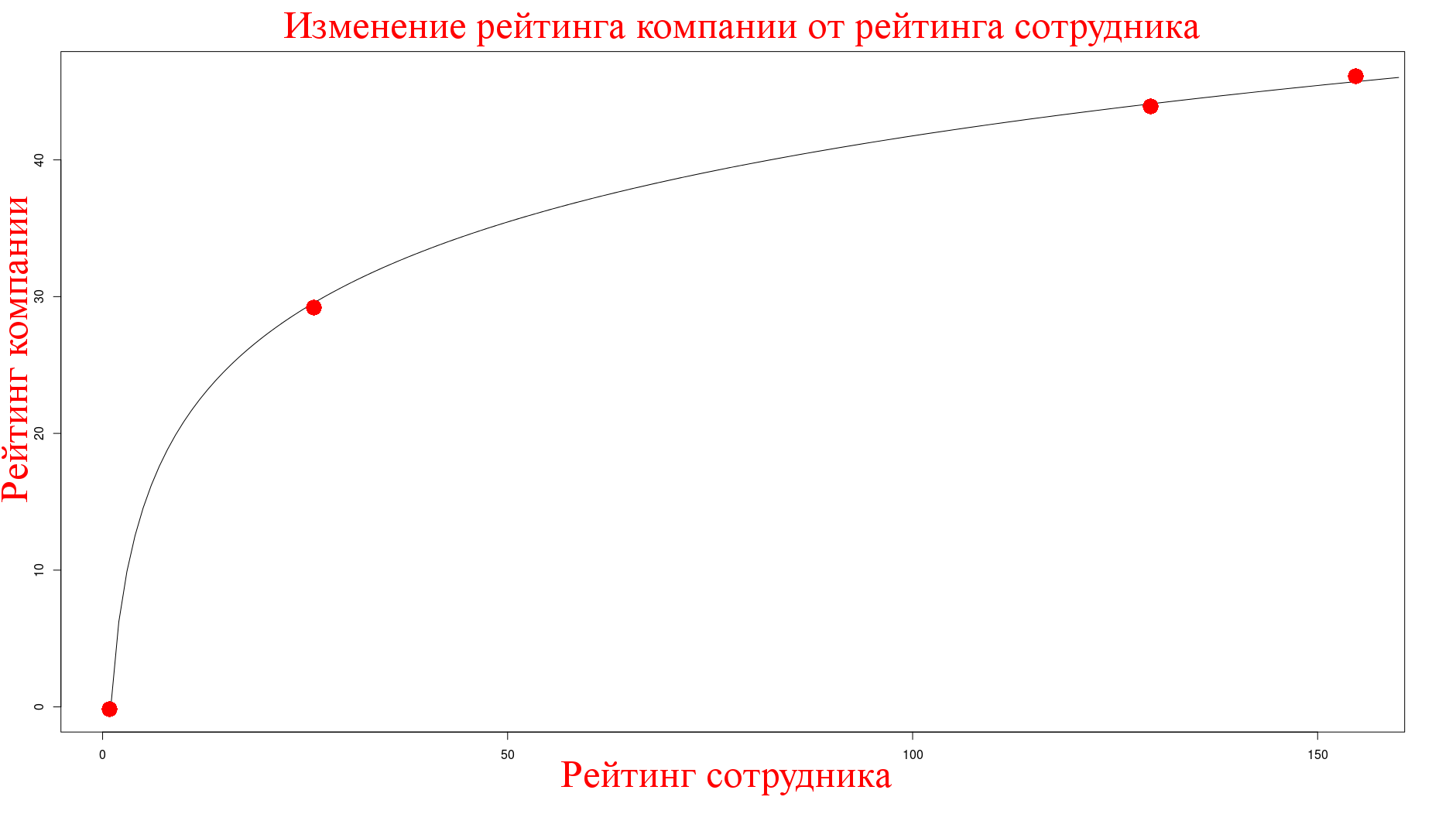
Карма сотрудников, полученная на корпоративных постах
Эффект от кармы сотрудников мы замеряем следующим образом, мы знаем, что посты Мосигры написаны одним человеком и карма им получена именно на этих постах, поэтому я замерил показатели в тот момент, когда у них не было активных статей (что было совсем не тривиально) и получил следующее:
name,blog,employees,subscribers,rating,size
.....
mos_igra,115,10,4877,59.48,101_200Карма автора составляла порядка ~850, отсюда зависимость от кармы полученной на этих постах также логарифмическая с коэффициентом примерно равным ~3.
Как можно заметить, собиралась также информация по размеру компании. Воздействие размера компании на индекс получилось нулевым.
Рейтинг подписчиков

Отсюда видно, что рост также логарифмический по рейтингу подписчиков, причем коэффициент равный трём, наблюдаемый ранее при наличии статей, появляется и здесь:

Финальная формула
Отсюда, формула для случая с публикациями имеет вид:
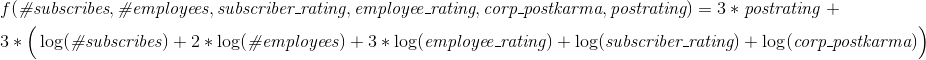
Причем коэффициент перед большой скобкой (где сумма всех логарифмов) равен 3, если у компании есть публикации и 1 если нет. Плюсы к постам считаются так же, как и плюсы к постам пользователей (то есть держатся в течении 30 дней).
О важности сбора качественных данных
При беглом просмотре статьи может показаться, что сбор данных — это исключительно второстепенный шаг. На самом деле, это фактически ключевой шаг в решении задачи, он позволил существенно сузить пространство гипотез и избавиться от второстепенных факторов, не влияющих на индекс.
Именно данных от Internet Time Machine и панели временного ряда компании мне не хватило, когда предпринял первую попытку анализа зависимости Хабра-индекса (~ в августе 2015го), чтобы вывести ключевые факторы. Например, взаимодействие параметров: коэффициент, зависящий от наличия статей, влияет сразу на группу параметров.
Анализ применимости нейросетей
Краткий список важных пунктов, по которым можно распознать, что задача может быть потенциально решена нейросетями:
- Имеется собранный (размеченный) датасет, существенного размера (тот в котором явно "сигнал сильнее шума*)
- Пространство особенностей существенного размера (представьте, что каждый пиксель вместе с цветом на картинке — это одна входная особенность, а также комбинация и суперпозиция, совокупно речь идет о 1M+ параметров модели)
- Особенности и закономерности имеют иерархическую структуру — представьте анализ цифр: точки собираются в прямые, комбинация прямых в закорючку, закорючки в циферку (упрощенно можно думать о сети, как о некотором сжимающем отображении)
- Отсутствуют существенные априорные представления о характере зависимости, если мы знаем, что зависимость линейная (квадратичная, сезонная, вообще не слишком варирующаяся функция), то возможно стоит сразу искать решения в этом классе
- Не требуется анализ полученной зависимости. Когда мы хотим получить черный ящик предсказывающий действия — это вполне неплохое решение — "вот этот ход в ГО интуитивно хорош", но если нам требуется произвести анализ зависимости, то это превращается в случае нейросетей в совершенно нетривиальную задачу (например, см. вот эту статью)
В разобранной нами задаче ни одно из этих условий не выполнено.
Иначе, всё это начинает напоминать подход кальсонных гномов

Анализ оптимальной стратегии
Имея формулу с основными факторами, определяющими Хабра-индекс, мы можем ответить на вопрос Q3 — оценить эффективность различных стратегий ведения блога.
Важное наблюдение: линейный член легко мажорирует остальные логарифмические члены, даже при небольших значениях порядка +10. Нужно иметь 25 тысяч подписчиков, чтобы получить эффект сходный с одной статьёй в 10 плюсов (или зарегистрировать 150 сотрудников). Эффекта статьи от +20 одними подписчиками получить фактически невозможно.
Стратегия первая: регулярно писать много маленьких статей на ~+10, например каждую неделю. Тогда, рейтинг компании получает плюс ~ 3*5*10 ~= 150 и легко проходит на первую страницу, при условии, что остальные параметры имеют хоть сколько-нибудь реалистичные значение (например, 5 сотрудников и 100 подписчиков): данная стратегия достаточна эффективна, см. стратегию Microsoft, который сейчас на первом месте по рейтингу. Стратегия выглядит разумной, если вы большая компания и у вас много инфоповодов.

Стратегия вторая: писать одну-две вдумчивые статьи в месяц на 50-100 плюсов. Вы гарантировано попадаете в топ и первую страницу компаний. Минус стратегии — писать статьи такого качества в таком количестве невероятно сложно. С этим, например, справляются в Мосигре, см. визуализацию ниже.

Попытки накрутить подписчиков особо эффективной стратегией не являются, так как логарифм быстро выходит на константу (для любых разумных значений числа подписчиков). Зарегистрировать всех работников в блоге имеет смысл, но также имеет исключительно ограниченный эффект, даже у Яндекса, у которого здесь 577 сотрудников, эффект сравним с одной "постоянной" статьёй на +12-13.
Комментарии (30)

Mendel
07.03.2016 19:20+1Немного капитанства:
1) Сбор данных в виде машины времени и инсайда это немного не из области анализа.
2) Логарифмы в НС вносятся или примесью нейронов с другими сжимающими функциями или банальным добавлением каждого параметра в виде двух параметров — параметр и его логарифм. В нашей задаче мысль о логарифме является априорной, и этого может хватить, в других случаях можно дать много разных функций, да увеличив размерность при нетривиальной связанностью данных, но неудачные входы можно "гасить" или анализом получившейся обученной сети или структурой сети.
3) ваш анализ в значительной степени базировался на фильтрации пар входных образов в которых различие входов было минимальным.
В принципе пул таких дельта-образов отфильтрованный по степени схожести (скажем самые схожие 0,01% всех пар) был бы неплохим пулом обучающих данных. Не совсем понятно правда как их подмешивать в основной поток, ведь два независимых пула данных с разной структурой это не очень хорошо (и да, я помню что я уже так логарифм подмешивать предложил). Как вариант считать обычные образы дельтой от нулевого образа (который у нас априорно — все нули дают ноль).
Не спорю с общим выводом статьи, просто накидываю на вентилятор надеясь на интересное обсуждение. Статья интересная, большая благодарность.
varagian
08.03.2016 12:29Согласен, но получается, что мне сначала нужно угадать про логарифмические дельты (причем не обязательно сразу угадывать, что это правильный ответ), а потом применять алгоритм обучения. В принципе идея неплохая, но в получается, что она бы уже была фактически решена, как только стало понятно какие могут быть факторы реально определяющие зависимость. В общем как ни круты выходит решающим feature engineering.
И ещё нужно было бы сделать модель time-aware, так как плюсы нужно считать во времени. Для подсчета корпоративной кармы у меня фактически одна reliable точка была (ну ок, на самом деле штуки 3-4).Mendel
08.03.2016 22:56+1Логарифмы достаточно частое явление и в принципе напрашиваются на этапе нормализации.
Тут нужно экспериментировать, но я бы ожидал что высокая зависимость на низких значениях и низкая зависимость на высоких должна быть заметной, а это явное показание к логарифму. Четко мысль не сформулирую, надо будет подумать на досуге. Но думаю найдутся хорошие эвристики которые можно даже в НС запихнуть.
Что касается разницы, то разница это тоже распространенная стратегия. В модели НС которую я последний год обдумываю (всё никак нет времени дойти до написания и тестов) такое поведение образуется автоматически. Ну и в принципе — близнецовый метод это классика.
Вообще хотелось бы объясниться. По моему мнению, во многом совпадающему с мнением автора статьи — самое сложное в этом анализе это сбор данных и нахождение наиболее информативных данных в этой массе. Добыча данных не формализуется в принципе (без полноценного ИИ способного общаться, выведывать информацию и т.п.). Для второй части можно, и нужно по возможности привлекать автоматику. Я люблю НС, да и в теме они звучат, так что хочется по возможности привлечь их к задаче.
Ну и чуть оффтопа. Сегодня в споре мамочек-педагогов в меня швырнули школьной математической задачкой.
Поскольку задача решалась на слух и на бегу, то решалась она типично для машинного обучения:
По мере получения мною фактов из задачи я выводил новые факты исходя из тех правил которые мне известны.
Цель я узнал уже в конце, когда у меня уже был готов ответ, хотя я и не знал что именно он мне нужен.
Т.е. я не вычислял переменные потому что они мне были нужны, а вычислял их "потому что могу". И это сработало.
Я их дискуссию не особо отслеживал, но если я правильно реверснул их выкладки, то один из способов решения (стратегия а не формула) который новая учебная программа должна давать детям именно в этом и заключается — выписывать факты и по возможности выводить из них новые пока не дойдешь до цели. Вторая стратегия это параллельно двигаться со стороны цели выписывая какие данные тебе бы помогли, т.е. некие подцели.

NetBUG
08.03.2016 04:09+1хм, интересно в эту стратегию укладывается поведения ua-hosting.
Но статьи у них чаще всего интересные, иногда хромает полнота (про советские миниЭВМ, например).varagian
08.03.2016 12:32Мне кажется, у них в некотором роде гибридная стратегия, когда могут пишут интересные научно-популярные посты. В остальное время много маленьких статей.
Сейчас посмотрел подробней, мне кажется они все-таки больше тяготеют к первой стратегии.

Turbo
08.03.2016 08:40+1Статья про машинное обучение, но зачем-то выводятся формулы. ) Что мешало взять в качестве "features" все параметры из таблички, взять в качестве "target" рейтинг. Построить модель, например, с помощью XGBoost. И дальше проверять на ней — увеличил количество статей на единичку, скормил модели, посмотрел рейтинг, увеличил подписчиков на единичку, посмотрел рейтинг и.т.д.
varagian
08.03.2016 12:42Статья, как раз о том, что не нужно думать, что можно взять какие-то числа и использовать магический алгоритм обучения, который со всем сам разберется. Подробнее:
- Какие именно числа нужно взять и откуда их взять?
- Числа из таблички выучат мусор, потому в ней нет ключевых фич
- Модель должна быть time-aware, здесь ключевой компонент зависит от времени, как это учесть в алгоритме обучения?
- XGBoost — модель хорошо масштабируемая на данных, тут данных с гулькин хвост, зачем она здесь?
- XGBoost — алгоритм из семейства ансамблей, у них не слишком хорошо с interpretability, а здесь это с самого начало предполагалось важным условием

pro100olga
08.03.2016 17:36Какие именно числа нужно взять и откуда их взять?
Числа из таблички выучат мусор, потому в ней нет ключевых фич
Вы используете показатели из профиля компании, почему бы не взять их?
И еще: почему вы искали единичные примеры, а не построили график зависимости хабраиндекса от каждой переменной?
Модель должна быть time-aware, здесь ключевой компонент зависит от времени, как это учесть в алгоритме обучения?
Собрать данные за несколько периодов времени?
XGBoost — алгоритм из семейства ансамблей, у них не слишком хорошо с interpretability, а здесь это с самого начало предполагалось важным условием
У нейронных сетей тоже с этим "не слишком хорошо", по идее, от этого метода можно отказаться на этапе "Нам нужно, чтобы ты определил ключевые факторы, которые на него влияют"varagian
08.03.2016 18:30Вы используете показатели из профиля компании, почему бы не взять их?
Показатели нужно выбрать и как-то превратить в численный вектор, например страница подписчиков и работников содержит пачку показателей — сложить для разных работников, выписать отдельно, посчитать их количество, учитывать общее число плюсов, за все посты? (Это никак не даст фактор кармы полученной на корпоративных постах, например). В этом и состоит feature engineering — понять, что может быть ключевым фактором и смысл статьи во многом в том, что этот важнейший шаг не получает внимания и люди начинают считать, что его можно обойти одним только умным методом обучения.
О времени — тут у нас есть очень сильный background knowledge о границе для пользователей, который естественным образом обобщается на корпоративный индекс.
И еще: почему вы искали единичные примеры, а не построили график зависимости хабраиндекса от каждой переменной?
Есть идеи как это нужно было сделать? Для этого нужно иметь достаточно данных, в которых все остальные параметры равны. Или вы имеете виду, построить регрессию по каждому из параметров и оценить качество?pro100olga
11.03.2016 12:00Какой смысл привязываться к всем остальным факторам, если вы в ручном подходе тоже привязываетесь не ко всем? Например, делая вывод о влиянии кол-ва подписчиков, вы берете две компании, у которых зафиксированы только два других фактора (публикации и сотрудники). Вот интересно проверить: если взять график хабраиндекса от кол-ва подписчиков (без оглядки на другие факторы), будет видна логарифмическая зависимость?
Mendel
11.03.2016 14:43Не будет ничего видно. Шум выше полезного сигнала на порядок, да еще и нехило коррелирует с сигналом.
(рост колва подписчиков связан с популярностью тематики, а значит и популярностью контента и т.п.)pro100olga
11.03.2016 14:46Хотелось бы увидеть график
Mendel
12.03.2016 09:13-1А что мешает? У вас же есть опыт построения графиков для проверки маргинальных теорий датамайнинга. На Хабре 309 компаний. Даже руками это будет не сложно. Да и другим интересно будет я думаю. Не столько график сколько дискуссия на тему подходов которые вы будете использовать при построении и интерпретации.
Я уже вижу как вы найдете логрифм не в графике а в шкале, чем подтвердите мою мысль о нахождении логирифма при нормировке, но будете считать чтодепутаты это исключениеэто и есть "видно из графика что зависимость логарифмическая"pro100olga
12.03.2016 10:30Переход на личности без аргументации и с попутным перекладыванием задачи доказательства своей правоты на оппонента — это простой, но неэффективный способ ведения дискуссии. До свидания.
Mendel
13.03.2016 21:18+11 ) Переход на личности? Да. Вы опасно некомпетентны в дата-майнинге, и я я стараюсь везде где это возможно подчеркивать.
2 ) Без аргументации? Нет. Аргументы слишком просты и очевидны. И были приведены.
3 ) Перекладывание задачи доказательства… Что простите? Вам захотелось графика. Бессмысленного графика. Что видно из формулы и размера выборки. Даже не нужно смотреть "навскидку" на цифры, чтобы понять весь абсурд. Но вам захотелось. Я здесь причем? Вы мне кто, чтобы я вам ДОЛЖЕН был что-то доказывать? Ну честно, это школьный уровень. Не для каждой школы, но школьный.
4 ) Я действительно не понимаю в чем проблема построить график если вам так уж интересно убедиться в своей неправоте а не понять аргументацию? Вы же умеете строить графики. Не умеете их интерпретировать, но строить то умеете. Возьмите и постройте. Или лень парсить данные? Или не умеете? Ну так попросите. Мне не лень ЗА ВАС сделать работу, чтобы потом понаблюдать за тем что вы будете с этим делать.
5 ) И нет, я не выпендриваюсь, я просто реально не вижу как можно построить график с таким размером выборки, и такой структурой данных, чтобы можно было что-то увидеть. Если бы на порядок-другой больше выборка то ладно… Напарсить за вас могу, но строить график? Увольте.

dmandreev
08.03.2016 09:49+1Я все пытаюсь сообразить как сделать регрессионную модель на основе LSTM, чтобы заранее оценивать рейтинг и количество просмотров статей. По идее это можно сделать с помощью Torch7 http://dmandreev.github.io/2016/03/05/torch7-windows/
varagian
08.03.2016 23:15В смысле оценивать рейтинг и количество статей на Хабре? А что будет входными данными? Текст и мета-информация статьи (автор, теги, заголовок) и тд?
dmandreev
10.03.2016 09:43+1Да, чистый текст и заголовок. Сценарий который я хочу реализовать — скармливаем сети новую статью а она предсказывает сколько будет у нее рейтинг, объем просмотров и комментариев.
Mendel
10.03.2016 10:28+1Забавно. Но задачка как раз в контексте статьи.
Думаю хорошие результаты покажет алгоритм который сначала выделяет ключевые слова, а потом по весу ключевых слов определяет вероятную популярность. Я бы вычислил словарь Хабра, раздал бы веса от частоты слова, чтобы узнать важность слова в тексте (редкие слова имеют больший вес, частые — меньший). Стопслова не отбрасывал бы, потому что они отражают стиль.
Потом раздал бы веса по корреляции с оценками.
Если был бы бюджет, то дал бы сетке на кластеризацию, это дало бы возможность автоматически нагенерировать сотню других параметров вроде моей "водности текста". Фразы бы еще по нескольким параметрам оцифровал бы, для дополнительных стилистических параметров.
Задача вполне себе решаемая численными методами вроде НС, но требует очень большого массива ручной аналитики и априорных знаний. О чем собственно и статья.)))dmandreev
10.03.2016 19:23+1Хочется не заморачиваться с ключевыми словами и word2vec, дать на вход сети именно набор букв, LSTM как раз такие фокусы и позволяют.
varagian
10.03.2016 14:33Кстати, а почему именно Torch, а не CNTK? Мне казалось логичным, что он заточен по Windows.
А вообще было бы круто сделать что-то похожее на iconosquare для статей, особенно если модель будет ресурсо-независимой, т.е. входные данные действительно только текст+заголовок (и может быть теги?). Этакий легко-разворачиваемый http://www.habr-analytics.com (кстати, надо бы его воскресить уже).dmandreev
10.03.2016 19:22+1Именно для того чтобы потом перенести в CNTK, у Torch7 примеров больше, а у CNTK пока никаких биндингов кроме c++ нет.

zirf
08.03.2016 23:48+1Мне не совсем понятно, как все-таки отделяются действующие факторы? В классическом планировании эксперимента рассматривают N факторов и отклик — результирующее значение (тут индекс). Причем действующие факторы и их взаимодействие могут быть определены статистическими методами, а тут как быть уверенным, что фактор не шум?
varagian
09.03.2016 00:05Тут критическим является тот фактор, что функция детерминированная — то есть, если есть две точки отличающиеся только одним параметром и есть разница в индексе, то фактор существенен (или какая-то функция от него).
Если бы этого предположения не было, то нужно было бы статистически обосновывать, что разница значима и не может быть объяснена случайными факторами.
А вообще, да, отличное замечание.zirf
09.03.2016 10:56+1Получается, априори, предполагается, что авторы индекса используют некоторую детерменированную функцию N переменных. Только нам неизвестную. Наша задача определит максимум (вообще, экстремум) этой функции. В планировании эксперимента есть экспериментальный метод Бокса-Уилсона. Суть очень проста. Предполагается, что "поверхность отклика" (условное название области значений функции) на каком-то ограниченном участке может быть описана полиномомом (это не физическая модель, конечно), члены первого порядка отвечают за факторы, их произведения — взаимодействия. При подтверджении значимости коэффициентов при членах факторов определяется направление к экстремуму и дальнейшие исследования (постановка факторных экспериментов) ведутся по направлению вектора, пока не будет достигнута точка перегиба или получены удовлетворительные значения отклика.
Подробнее у тут или еще список.
Метод дает хорошие результаты, если о физической природе мало что известно и построить модель не представляется возможным.
Monnoroch
Стоит заметить, что transfer learning может помочь с устранением этого недостатка. Правда, не всегда, но все же.
А при чем тут это?
varagian
В этой статье есть ряд примеров, показывающих, что поведение предиктора может быть крайне удивительным для пользователя и внутренние зависимости могут быть крайне не интуитивны.
Monnoroch
Понятно, спасибо. На самом деле там же довольно простая математика этого явления, как только разберешься вроде уже и интуитивно.