Сначала, хронологически, о первой, «онлайн» части. Есть сетка игр мирового финала «The Shanghai Major 2016». Нужно до матча предсказать его исход. Как показало время (но не описание конкурса), предсказывать нужно было матчи за 3, 4, 5 марта. Для обучения были даны исторические данные о матчах в Dota2 по разным прошлым турнирам с агрегированной информацией о каждом матче. Со среды пришлось начать недосыпать, т.к. все днем работают. Для онлайн этапа были разработаны две модели.
В качестве показателя качества прогноза использовалась следующая метрика: score=log2(p_winner)+1, где p_winner — предсказанная до начала матча вероятность победы команды, которая в результате победила.

Тут стоит сказать несколько слов о целях хакатона. Цель формальная — получить самую высокую относительно других оценку качества прогнозов. Цель, соответствующая смыслу Data Fest — построить самую лучшую, относительно других, модель для прогнозирования исхода матча методами машинного обучения.
Один выступающий в последний день Data Fest 2 (Nuker?) верно заметил, что «задачу машинного обучения всегда можно решить и без машинного обучения» (своими собственными нейронными сетями в голове). Кто использовал модели, кто использовал экспертный опыт, кто просто случайно играл? Неизвестно.
Финальная оценка первого этапа – среднее всех значений метрики качества для предсказанных вероятностей. Как показывает турнирная таблица первого этапа Хакатона, количество предсказаний на «команду» разнилось в 10-20 раз. Как мы знаем, отсутствующие данные можно, конечно, заменить чем-то, но здесь ключевой вопрос – это человек осознанно заключил, что вероятность 0,5 или просто проспал момент отправки прогноза? Вероятно, проспал, раз не отправил. Поэтому лучше бы было просто не рассматривать в таблице команды с количеством предсказаний меньше, чем, скажем, 10, т.к. слишком мало информации, чтобы оценить модель команды. А лучшая стратегия игры при финальной оценке – сделать удачный прогноз и больше не играть (отправлять 0,5), что, конечно, не соответствует смыслу Data Fest.
Модель онлайн части №1 «Nikolay» (машинное обучение). Алгоритм SVM предсказывает победу первой команды по долям побед первой команды во всех матчах за последние 1, 2, ..., 12 месяцев + то же самое для второй команды. При создании модели был выбран алгоритм и отсеяны незначимые признаки.
Набор признаков был выбран следующим образом. Доля побед команды в предыдущих матчах – показатель мастерства команды. Мастерство может меняться со временем, поэтому важно учитывать динамику. Изначально мы хотели использовать доли побед команд за отдельные месяцы, но наблюдалось слишком много пропусков в данных. Поэтому перешли к долям за последние несколько месяцев. Среди признаков была и доля побед первой команды во всех матчах против второй команды, но важность этого признака оказалась очень низкой (по-видимому, из-за большого числа пропусков), поэтому мы исключили этот признак.
Ещё была идея учитывать мастерство команд, побеждённых первой или второй командой при вычислении их мастерства, поскольку победа над сильной командой должна давать больший вклад в показатель мастерства, чем победа над слабой. Однако, не нашлось времени для реализации идеи.
Модель онлайн части №2 «Сергей Сметанин» (предположения + анализ данных). Решили рассматривать матчи только с 01.07.2015. Проанализировав таблицу побед/проигрышей/разницу побед и проигрышей, мы увидели, что сортировка по победам точнее всего группирует команды турнира «The Shanghai Major 2016»:
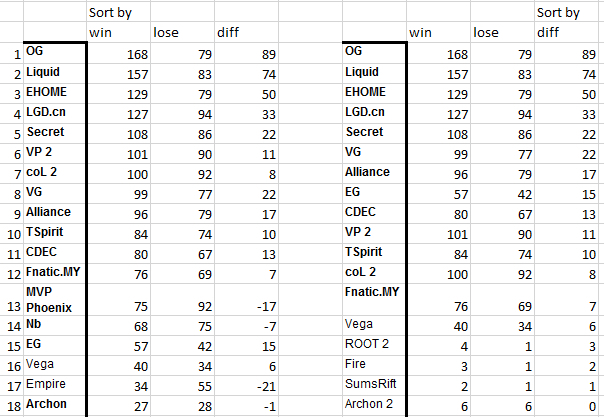
Соответственно, в качестве ad hoc вероятности победы первой команды использовали сумму с одинаковыми весами по 0.5 двух величин:
1) Отношение количества побед первой команды к суммарному количеству побед первой и второй команд во всех матчах с 01.07.2015;
2) Отношение количества побед первой команды к суммарному количеству побед первой и второй команд в матчах только между первой и второй командами с 01.07.2015.
Почему? Отталкивались от таких предположений:
— команды и опыт сильно менялись во времени, поэтому будем брать только свежую информацию. Что такое свежая? Не знаем. Например, 01.07.2015.
— таблица команд показывает, что победы точнее всего группируют команды «The Shanghai Major». Будем работать с выигрышами.
— вероятно важно, что игра была между двумя интересующими командами. Делаем признак только по таким матчам. (Однако, уже после матчей, пересчет показал, что лучше этот признак не брать. Отчасти, поэтому брали в расчет все команды во второй части хакатона.)
— смотрим на историческую силу команд.
— сила, измеренная выигрышами, уже имеет в себе всю информацию о выборе стратегии, игроков и т.д. Поэтому остановимся пока на ней.
Результаты моделей:
Сначала лидировала модель №2, но человеческий фактор сыграл свою роль – ошиблись при отправке, куда-то потерялось одно предсказание с вероятностью 1. С первого места 3-го марта быстро отдали пальму первенства устойчивой «Nikolay», которая выиграла бы 4-е место из 42 в конце онлайн части, если учитывать не менее 10 матчей.
Офлайн часть официально началась 5 марта в 20:00. Для построения моделей были предоставлены данные (в 0:30) о ходе матчей турнира (состояние игры в различные моменты времени в течение матча). В 1:30 получили последнюю недостающую информацию о том, кто в этих матчах выиграл. К началу первого матча финала (матча до гранд-финала) в 5:30 модель была готова.
Входные данные для модели:
— по игрокам: xp_per_min, gold, net_worth, respawn_timer
— по команде: tower_state, barracks_state
— по матчу: duration
Целевая переменная: вероятность победы Radiant
Отобранная модель: логистическая регрессия
Отобранные предикторы: опыт команд (xp), совокупная стоимость команд (net worth), отношение опыта и совокупной стоимости команд (Radiant к Dire), respawn_timer (по героям), level (по героям), respawn_timer * level (по героям).
Обучающая выборка: данные о ходе всех матчей Shanghai Major 2016.
Примечание: respawn_timer – время до возрождение убитого героя.
Мы брали произведение respawn_timer и level, поскольку мы предположили, что чем выше уровень героя, который временно покинул игру, тем хуже шансы у команды на победу.
Поскольку были некоторые сомнения относительно надёжности модели, мы также выводили график разницы в опыте команд в реальном времени, чтобы, если по графику видно кто побеждает, а модель даёт осторожные прогнозы около 0,5, отправлять вероятности повыше.
Финал удивил многих, когда победила Liquid в матче с EG при отрицательной разнице в опыте в течение всего матча (см. график). EG был фаворитом нашего первого консультанта по Dota2.
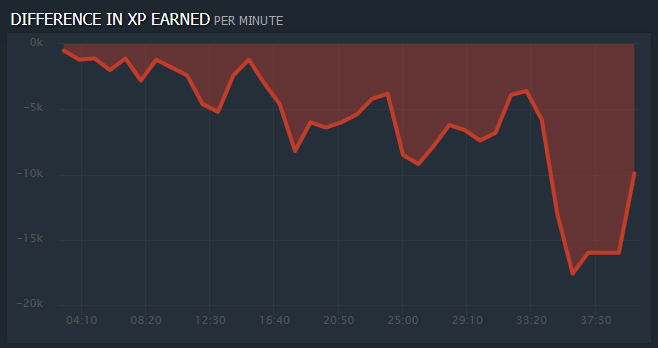
Есть редкие стратегии, которые работают таким образом, объяснил нам второй из двух (примкнувших) консультантов, который играл в Dota1 профессионально на уровне чемпионата России. Это не вписывалось в нашу логику отбора признаков, поскольку мы были уверены, что превосходство в опыте – один из самых решающих факторов для победы. Первый же консультант (молодой энтузиаст Dota2) был в шоке от увиденного.
Вероятно, такое отклонение можно было бы увидеть по состоянию башен, но такая стратегия, по-видимому, настолько редкая, что не понятно, как ее выявить методами машинного обучения, не имея опыта игры в Dota2. Добавление признаков, связанных с состоянием башен и бараков, ухудшало качество модели на нашей тестовой выборке.

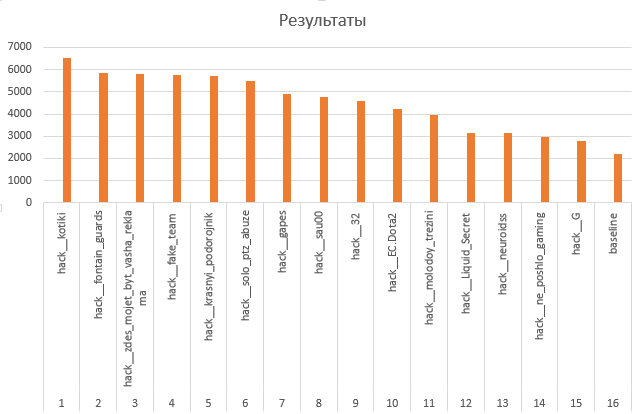
На графике показана важность признаков. Здесь много интересного, например, мы удивлены тем, что уровень первого героя R оказался существенно менее важным, чем уровень второго героя R.
К гранд-финалу мы подошли, не слишком веря в силу нашей модели. Двое, кто сделали модель и скрипт для рисования графика разницы в опыте команд в реальном времени, поехали спать, двое остались отправлять результаты модели для оценки и, вообще, «действовать по обстановке».
Также думали о стратегии отправки вероятностей с учетом оценки модели в конце матча. Вероятно, преимущество можно получить, начав как можно раньше предсказывать самые высокие вероятности. Подумали, не сделать ли такую стратегию: отправляем 0,5 пока «не увидим» победу команды и потом отправляем 1. Забегая вперед, можно сказать, что многие применяли такую стратегию или ее варианты. Было бы интересно исследовать более детально вопрос об оптимальной стратегии, но времени не было.
И… начался финал! Мы смотрели игру первый раз в жизни. Модель вдруг… упала. График все равно шел, и мы играли по нему, решив планомерно увеличивать отклонение отправляемой вероятности от 0,5 на трех периодах игры: start (10 мин) ±0,05, middle (20) ±0,25, final (20+) ±0,49.
Отправлять вероятности можно было и во время выбора героев. Можно было бы придумать другую модель, но решили просто ничего не отправлять.
Сыграли на 15 место из 23, предсказав исход матча по сумме оценок качества правильно (итоговая оценка качества прогнозов за весь матч оказалась положительной). Игра предсказывалась легко и, представляется, что в тот матч модель бы нам помогла больше, чем страх человека перед логарифмом.
Вторая игра. Самая интересная. Liquid вдруг ожил после поражения (выбрал правильно героев, как сказал консультант №2). Модель была починена (разбудили создателя). Мы не были уверены, как она отрабатывает (а было видно, что идет по опыту), и брали иногда штурвал в свои руки. Модель давала сильный разброс, решили охлаждать ее пыл. Поднялись на 14 место по итогам игры.
Третья игра. Что будет? Закончили 15 местом, думаю из-за вмешательств ставок до начала игры на Liquid.
Четвертая игра. Или пан или пропал. Решили не лезть к машине. Поставили на автопилот. Результат — 3 место (результаты последнего матча гранд-финала) после крайне экстремальных и крайне уверенных команд, возможно лучший результат чистого машинного обучения.
Вывод: Хоть модель и представляется резкой, но она – сильная (она… поздравляем ее с 8 марта!). Особенно для матчей, которые идут с перевесом одной команды. Модель не теряла времени зря, не смотрела на недавнее прошлое так… как мы. Не искала стратегий, как консультант. Просто говорила, что от того места, где мы сейчас в матче, исторически все идет вот к такому результату.
В сумме, 10 место (по нашим суммарным подсчетам) из 23 команд, кто играл во все 4 игры гранд-финала.
Если же отсеять «экстремалов» и «уверенных», то место будет и повыше. Кстати, чтобы играли только алгоритмы, было бы полезно, чтобы люди ставили реальные деньги на результат. Тогда бы было интересно посмотреть на 5 последних команд по сумме 4 игр, которые бы скидывались от 9000 до 300000 рублей (при 1 руб. за единицу метрики). Думаю, тогда бы и команда-призер думала бы осторожнее.
Уроки:
1) Хакатон — вещь классная своим сжатым временем проведения и неизвестной темой, которую надо раскрыть. Будем играть в
2) Мы выступили неплохо, с учетом сжатых сроков и полного незнания Dota2.
3) Доверяй машине (но проверяй).
4) Эксперты нужны, чтобы передать знания, которые долго вытаскивать из данных и которые потом проверит машина. В этом хакатоне, «модели» экспертов имели одновременно bias + variance, т.е. у них была грубая модель «ставь все на эту команду», и большой разброс («нет, нет, теперь ставь на эту»). Возможно, симбиоз машина + эксперт лучше всего.
5) Не иди в боевую с одним инструментом. Вдруг откажет? Мы благодарны, что у нас был график, который спас первый матч гранд-финала.
6) Для редких событий (выбросов в виде очень редких стратегий) не хватает наблюдений, чтобы адекватно учесть вклад такой стратегии.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (17)

Psychopompe
09.03.2016 09:41Были мысли применить футбольные модели?

ivankomarov
09.03.2016 10:14Про футбол вспоминали, т.к. в него хоть некоторые из нас играют. Поиск в Инете не дал хороших подсказок про модели для Dota2, времени мало, делали все с нуля, чисто машинное обучение.
Данные -> Предикторы (сами) -> Алгоритм -> Предикторы (алгоритм) -> Модель
Анализируя сейчас, думаешь, а вот интересно, что будет, если это… а если то… Зависит и от знания игры, правил. Например, важен ли порядок героев?
tr0mb
09.03.2016 11:06Что понимается под порядком героев? Если порядок пика, то очень даже важен — если герой пикнут в начале, то скорее всего против него выберут какого-либо контргероя или забанят очень хорошую связку.

Jarens
11.03.2016 11:36В Captain's Draft и Ranked All Pick действительно есть возможность учесть порядок выбора героев, который очевидно оказывает очень большое влияние на успех матча, однако тут возникает проблема комбинаторного характера — количество уникальных игр, где герой А был выбран первым, B — вторым и т.д. равно числу размещений (arrangements) из 112 по 10, т.е. 205368317946676700000. Плюс по каждому из таких размещений нужно иметь статистику в несколько тысяч матчей. Я не уверен, что со времени запуска Доты2 накопилось столько матчей, чтобы можно было использовать машинное обучение для решения данной задачи с учётом порядка выбора героев. А хотелось бы...
ivankomarov
11.03.2016 17:16Из данных мы знали, какой герой и в какой последовательности выбран, какой у него уровень в момент t. Т.к. уровни, очевидно, важны, а как их складывать по героям — не понятно, кинули уровни по порядкам героев в регрессию. Имена и группировки героев трогать не стали. Видим результат на картинке в тексте: изменение уровня разных, по порядку, героев по разному влияет на вклад в победу команды. Похоже, какие-то непонятные взаимосвязи (для нас главное — выдача такой вероятности победы, чтобы самим победить в хакатоне).
ivankomarov
09.03.2016 11:47Мы, примерно, до этого дошли, хотя и не специалисты в игре.
Например, такой вопрос. Есть данные по всем матчам. Есть переменные: уровень героя 1, уровень героя 2 и т.д. (по порядку пика) для обоих команд. Вопрос: для вероятности моей победы, уровень моего героя 1 важнее ли уровня героя 1 соперника, при прочих равных? А важнее ли он уровня моего героя №2? В общем, с героями и их уровнями не все просто и понятно.
Потом еще догадались, что героев можно группировать… ) Даже есть такая статья на эту тему.tr0mb
09.03.2016 13:43Номер пика может не соответствовать значимости героя в игре. В команде условно есть 5 позиций — 1,2,..5. 1-я считается самой важной. Т.е. одна команда может первым пикнуть героя для первой позиции, а ее противники — для пятой. Тогда конечно сравнение уровней героев первой и пятой позиции не принесет много пользы. Т.е. тут нужно сравнивать героев на одной позиции, а не по номеру пика.

ivankomarov
09.03.2016 15:56Значит, подводя черту, героем с порядковым пик-номером 1 может быть герой любой силы.
Gordon01
10.03.2016 04:38На dotabuff есть огромная статистика по процентам побед в зависимости от скорости покупки и вообще наличия определенных предметов у определенных героев. Можно опираться на это.
Так же там есть статистика по процентам побед, в зависимости от роли, линии, итд.
Для профессиональных игр, статистика немного другая, но ее тоже можно найти.
На мой взгляд, это дало бы более точную оценку предсказания.ivankomarov
10.03.2016 08:58Наш выбор был ограничен теми данными, которые нам поступили.
Думая задним числом, конечно, данные об имени героя можно было бы использовать. Не помню про названия предметов, надо проверить. Совсем не уверен о наличии данных про линию и скорость покупки.
Вероятно, самое важное, что пропустили — типы героев. Но, в конце концов, все эти данные конвертировались в опыт, пусть и с большей ошибкой. Т.е. алгоритм, возможно, дал бы чуть большую точность, но настолько ли критическую, чтобы занять первое место, когда другие команды сразу "знали", кто победит?
В плане улучшения, было бы интересно смоделировать разные стратегии и время, когда становится понятно, что она провалилась. Также было бы интересно понять стратегию отправки ответов в свете финальной оценки модели.Jarens
11.03.2016 11:45Мы устраивали пробный in-class Kaggle для определения вероятности победы команды на основе одних только пиков, без учёта их порядка (см. мой предыдущий комментарий). Как ни парадоксально, добавление информации о герое (carry/pusher/nucker/и т.д., тип атаки и прочее) только ухудшало точность предсказания вне зависимости от выбранной модели (логрегрессия, XGBoost). Причём данный эффект был обнаружен не только у нас, но и в немногочисленной литературе по теме. С чем он связан мы пока так и не поняли.
ivankomarov
11.03.2016 17:23Мы тоже поудивлялись найденным связям, но модель молодцом реагировала на матч, подобно комментатору и консультанту, так что работала правильно, и это — самое главное!
ivankomarov
13.03.2016 01:09Ах, как хорошо, что решили пересчитать все. Взяли все матчи гранд-финала, все данные, которые отдала использовавшаяся во время хакатона система, посчитали все вероятности моделью. Потом посчитали score. Потом по score посчитали sum((1/2) х (duration(t+1)-duration(t)) х (score(t+1)+score(t))) (формула). Если формула правильная, то получили бы такие оценки: Match 51 = 1260, Match 50 = 1991, Match 49 = 2121, Match 48 = 1913 и заняли бы 3, 2, 3, 5 места в порядке матчей с конца… Ох да ах. Все же надо было больше доверять модели.
381222
В чем считали? Неужели в Excel? Почему выбрали SVM? Какой алгоритм был бы лучше? Код?)
ivankomarov
Считали на разном, модели — на Python, 2-ю модель онлайн конкурса (не машинное обучение) делали на Excel, SPSS Statistics, т.к. данных не много и больше смотрели статистику.
SVM показал себя лучше всего, kolyanzzz может лучше ответить про сравнение с конкурирующими моделями и вообще код. Модель выбрана оптимально по данным.
В офлайн части код использует описанные переменные и алгоритмы, берет данные, делает расчет и отправляет результат. Ждет 10 секунд и повторяет.
Psychopompe
А где можно код посмотреть?