
Мы живем то время, когда объемы информации растут с каждым днем все быстрее. Параллельно с этим растут и нужды бизнеса. Рост популярности виртуализации и облачных вычислений уровнял в возможностях как маленькие, так и большие компании, потому стало необходимо изменить подходы к сохранности данных.
Существует так называемое катастрофоустойчивое решение (Disaster Recovery Solution или DRS), которое часто путают с системой высокой доступности. Однако между этими понятиями есть разница, и это – допустимый масштаб аварии. DRS-системы могут восстановиться после крупного отказа сразу нескольких дата-центров, не парализовав работу сервисов на длительное время.
Когда речь заходит о системах подобного класса, люди часто подразумевают резервный центр обработки данных, который служит плацдармом для переноса нагрузки и данных из неработающего места. Выделяют три типа дата-центров: холодный резерв, теплый резерв и горячий резерв. Холодный резерв – это часто низкопроизводительные серверы, которые заказываются и настраиваются уже после возникновения аварии, а данные на них переносятся на магнитных лентах или дисках. «Подъем» этой инфраструктуры может тянуться несколько дней или недель и зависит от поставщиков, транспорта и навыков персонала.
Теплый резерв – это более слабые серверы в минимально необходимом количестве для запуска критически важных систем; они подключены, активированы и всегда готовы к переводу нагрузки. Для запуска такой системы требуется не более одного дня. Горячий резерв – это серверы, производительность которых соответствует серверам основной площадки; в этом случае все данные реплицируются регулярно и на постоянной основе. Так как есть готовая инфраструктура, каналы, программное обеспечение, и все это собирается воедино автоматически, запуск такой системы происходит в пределах одного часа (часто меньше).
Именно теплый вариант сейчас используется многими компаниями из-за приемлемой стоимости и неплохих временных показателей. Но если задействовать резервную площадку на базе IaaS, то можно получить даже горячий вариант без значительного увеличения бюджета. DRS в облачной инфраструктуре не особенно отличается от классических решений, но имеет несколько ощутимых преимуществ.
Если раньше для организации реплики LUN требовались совместимые СХД со специальными лицензиями, то сейчас достаточно поставить пару галок в виртуальной среде (тот же vSphere vSAN), а популярный вектор на аутсорсинг и облачные вычисления позволяет отдать в третьи руки некоторые корпоративные сервисы. Это дает возможность исключить из штата узкоспециализированных сотрудников и начать строить собственную систему управления и мониторинга.
Выделяя резервный дата-центр необходимо:
- Обеспечить возможность работы пользователей не только из основного офиса, но и из любого другого места (полезная при масштабной аварии децентрализация)
- Резервный дата-центр должен иметь показатель доступности, приближенный к 100% в год. На практике это означает максимальное число девяток после запятой (99,0%, …, 99,999%)
- Данные на аварийной площадке должны быть актуальными
Одним из важнейших компонентов катастрофоустойчивого решения является сохранение актуальной информации на обоих, например, сайтах. От стабильной синхронизации хранилищ напрямую зависят показатели RPO (допустимая точка восстановления). Репликацию виртуальных дисков можно выполнять, например, средствами vSphere Replication или переложить эту задачу на системы хранения (storage-based replication).
Собственный механизм vSphere Replica представляет собой репликацию на уровне гипервизора ESXi, которая не зависит от типа и идентичности СХД на всех сайтах. Отличительной особенностью является возможность пересылать данные между разными типами запоминающих устройств: с VSAN на основной площадке на DAS на резервной. Репликация на уровне систем хранения представляет собой более эффективный механизм, при котором весь процесс синхронизации передан устройствам хранения. Минимальное RPO аппаратной репликации составляет пару минут, что вполне вписывается в требования бизнес-критичного приложения.
И, как часто это бывает, в общем случае рекомендуется выбирать гибридный вариант. В нем вы выделяете datastore с аппаратной репликацией наиболее важных виртуальных машин, а все остальные защищаете механизмом vSphere Replica, который допускает работу с более дешевыми СХД. Приятным бонусом от устройств с аппаратной репликацией будут фирменные технологии снапшотов, теневые тома и прочие полезные функции. В связи с популярностью систем хранения NetApp на отечественном рынке, рассмотрим именно их в качестве основного хранилища для DRS (кстати, мы публиковали анбоксинги систем хранения данных, которые вы можете посмотреть здесь и здесь).
SnapMirror
SnapMirror известна как технология синхронной и асинхронной репликации на уровне дисковых массивов, которая происходит с использованием IP-сети. В основе технологии лежит концепция использования разностных снимков состояния соответствующего тома.
Синхронная репликация характеризуется тем, что сигнал готовности, идущий от хранилища к записывающему приложению, не передается до тех пор, пока не произойдет запись данных как на исходный том на стороне клиента, так и на реплику в облаке IaaS-провайдера. Иными словами, приложение ждет до тех пор, пока блок данных не будет записан сначала на локальный том, а затем на удаленный.
При асинхронной репликации в ходе записи локальная система сразу же отправляет сигнал приложению со статусом «записано», после чего (с заданным интервалом) отправляются обновления на удаленную площадку.
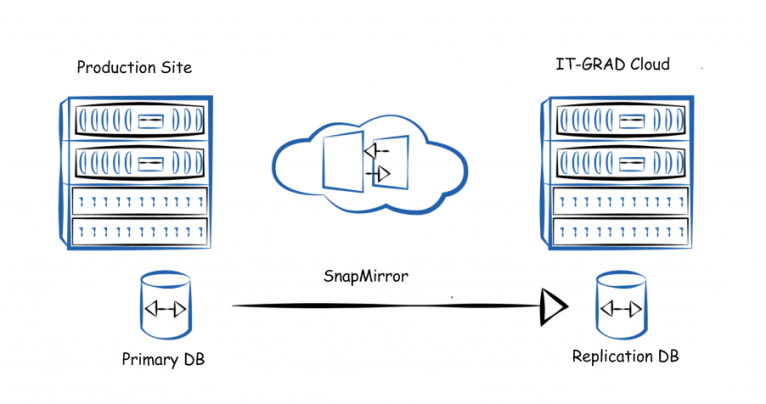
Технология синхронной/асинхронной репликации SnapMirror
В случае разрыва реплики принимающая сторона осуществляет перевод реплицируемого зеркала в режим read-write, который остается активным до тех пор, пока оборудование на стороне заказчика не будет восстановлено. После того как все вернулось на круги своя, в работу вступает SnapMirror в режиме обратной репликации и восстанавливает базу на стороне клиента.
SnapVault
Репликация хороша сама по себе, вот только вряд ли она поможет в случае повреждения данных. При репликации «испорченные» фрагменты попадают в резервную систему, что ведет к возникновению двух поврежденных комплектов данных. Избежать подобных неприятных ситуаций позволяет технология резервного копирования SnapVault, которая решает задачи длительного хранения и защиты данных от изменений для последующего их восстановления.

Технология резервного копирования SnapVault
В случае с клиентом и облачным провайдером суть использования SnapVault сводится к тому, что данные заказчика, располагающиеся на исходном томе, копируются на том-приемник в облако хостинг-провайдера согласно расписанию. Такая копия создается в режиме «только для чтения», к которой обращаются по мере необходимости.
Вообще тема резервного копирования всегда была актуальна. Исследование, проведенное аналитической компанией Gartner, показало, что рост объема данных является самой большой проблемой инфраструктуры дата-центров в крупных организациях. Все данные необходимо защищать от различных угроз, а также применять методы сокращения объема данных и их восстановления.
Сама идея облачного резервного копирования заключается в автоматическом переносе резервных копий клиента в дата-центр провайдера облачной услуги. Разумеется, чтобы сформировать услугу, недостаточно просто выделить место на хранилище и дать клиенту доступ, нужно обеспечить безопасное хранение информации и доступ к ней, а также грамотно сформировать тарифную политику и предоставить сервис определенного уровня с фиксированным временем отклика.
Основная задача любого облачного бэкапа – это сохранить резерв данных на случай непредвиденной ситуации. Доступность этих резервных копий зависит от уровня надежности (Tier) провайдера. Например, Tier-1 предполагает доступность 99,671% в год, а Tier-4 – уже 99,995%.
Поставщики ЦОД могут заявлять самые разные значения доступности, но реальность такова, что вывести оборудование и сделать недоступными ваши данные могут любые непредвиденные события (хакерская атака, природные катаклизмы). В качестве примера можно вспомнить масштабную аварию в ЦОД Amazon, когда из-за грозы отключились целые сервисы: Netflix, Instagram и Pinterest. Так как катастрофы не всегда возможно предотвратить, стоит выбирать провайдера с проработанным планом disaster recovery. Тогда вы хотя бы получите свои данные обратно в разумный срок.
Также для любого бизнеса одним из важнейших приоритетов является конфиденциальность пользовательских данных. Чтобы снизить шанс компрометации информации, важно выбирать поставщика с подтвержденным соответствием местным и мировым стандартам обеспечения безопасности. К примеру, одним из самых жестких современных стандартов является стандарт PCI (Payment Card Industry Standard), защищающий финансовые сведения. Если же вы работаете с другой специфичной информацией (медицина, промышленность и т. п.), то от провайдера потребуется соблюдение стандартов и этой отрасли.
Любая компания, существующая достаточно долго, знает, что невозможно полностью исключить вероятность потери данных. Но станет ли это просто неудобством или же ситуацией, которая положит весь бизнес на лопатки, зависит от качества предварительной подготовки. Правила игры в бизнес-среде регулярно меняются, а облачные услуги позволяют организациям застраховаться от серьезных потерь.
P.S. Интересные материалы по теме из нашего блога на Хабре:
- Кратко о трендах в сфере IaaS
- Опыт и проблемы ЦОД: Как проверить надежность дата-центра
- Как IaaS-провайдеру выбрать ЦОД для размещения облака: Опыт ИТ-ГРАД
- Как мы внедряли Disaster Recovery