
В этой статье я расскажу, как начать работать с сервисом EC2. По сути это пошаговая инструкция по полуавтоматической аренде спотового инстанса AWS для работы с Jupyter-блокнотами и сборкой библиотек Anaconda. Будет полезно, например, тем, кто в соревнованиях Kaggle все еще пользуется своим игрушечным маком.
Наверное, реакция каждого, кто в первый раз зашел на сайт Amazon Web Services — это растерянность от обилия предлагаемых услуг и виртуальных машин (которые там называются инстансами).
В этом тьюториале я покажу, как недорого арендовать вычислительный инстанс AWS и быстро настроить на нем сервер Jupyter, чтоб пользоваться столь полюбившимися блокнотами. Акцент сделаем на сборке Anaconda и задачах машинного обучения, но понятно, что сервер можно в разных целях использовать, хоть биткоины майнить :)
Мотивация: хотим быстро (в течение 5-7 минут) получать доступ из Jupyter-блокнотов к вычислительным ресурсам посерьезней, чем у домашнего компа.
Вообще есть под это дело неплохой тьюториал. Статья, которую Вы читаете — вольный перевод с дополнениями. Мы еще напишем скрипт, который будет запускаться каждый раз при аренде машины. А вот и результат для тех, кто в спешке.
Арендовывать мы будем спотовый инстанс с3.4xlarge с 16 ядрами и 30 Гб RAM.
«Спотовый» означает, что по сути мы будем участвовать в аукционе и, назначив цену за час пользования машиной, иметь к ней доступ до тех пор, пока спрос не возрастет. Если спрос возрастет, и рыночная цена превысит ту, которую мы назначили, машина от нас «убежит», причем внезапно. Именно по этой причине (нестабильности) многие боятся пользоваться спотовыми инстансами, хотя на них можно сильно сэкономить по сравнению с инстансами «по требованию». Та же машина, но в более «стабильном» режиме, обойдется примерно в $0.85/час, мы же потратим вчетверо меньше.
Теперь про типы машин. Они неплохо описаны в документации AWS, так что выбираем тип С — машины, оптимизированные для вычислений.
Аренда машины
Для начала зарегистрируемся на сайте Amazon Web Services. Тут инструкций писать не буду — все как обычно, надо будет только подтвердить и по телефону, и по e-mail. К аккаунту надо будет кредитную карту привязать, но если боитесь трат, можно инстанс m4large (2 CPU, 8 Gb RAM) взять за $0.05/час.
Заходим в свою консоль AWS и находим в Services службу EC2 (Elastic Compute Cloud)

В разделе Spot Requests жмем «Request Spot Instance».
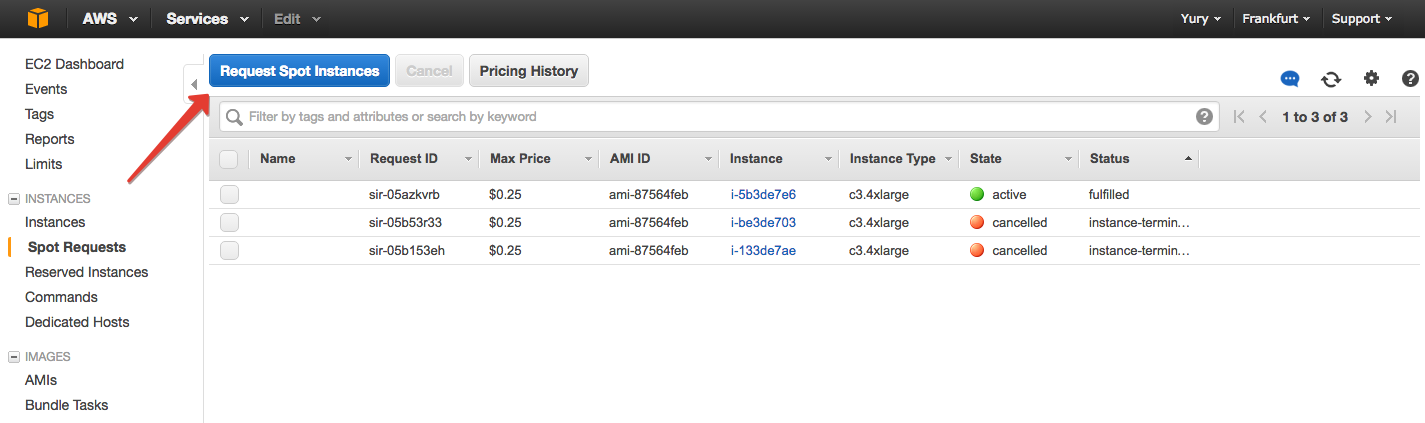
Выбираем тип ОС, которая будет стоять на виртуальной машине. В общих чертах: Windows дороже, среди *Nix не так важно, какую именно выбирать, пусть это будет Ubuntu.
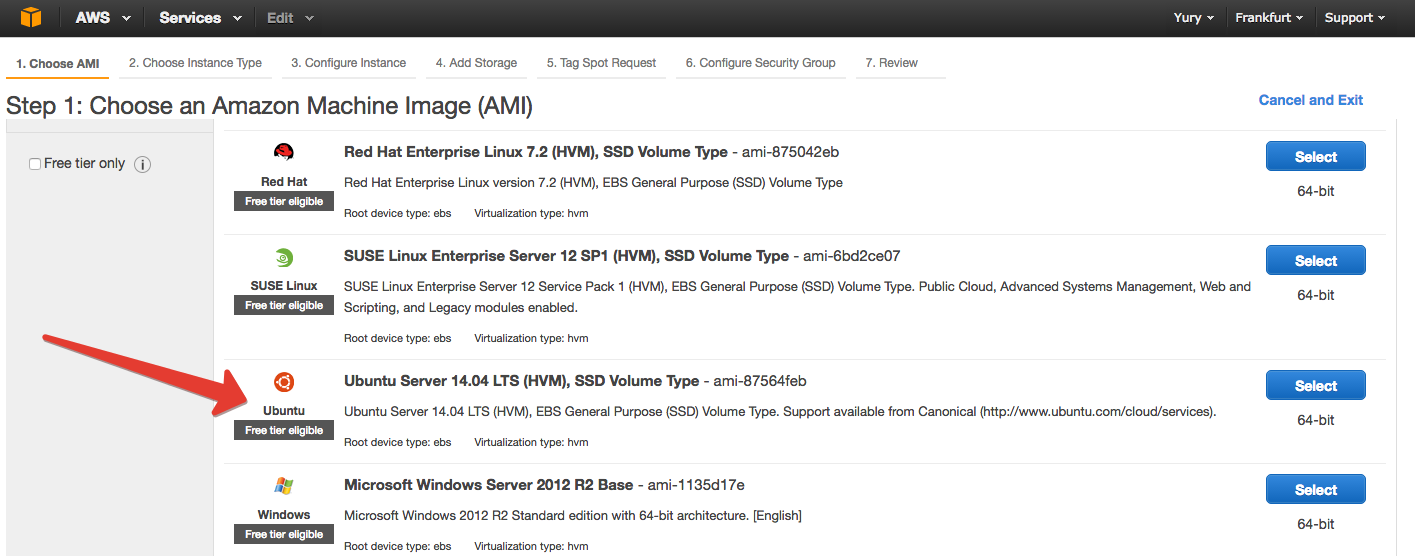
На следующей вкладке нам предлагают выбрать собственно инстанс. Здесь позалипаем, посравниваем (тут все подробней описано) и прокрутим до с3.4xlarge.

Затем самое главное — назначить цену за час пользования виртуалкой. Мы видим текущие цены в выбранных регионах.

Если видите, что у Вас цены намного выше, чем на скриншоте, значит, сейчас в текущем регионе всплеск — смените регион (в правом верхнем углу рядом с Вашим именем). Я пока с успехом использую регион Frankfurt, но можно и поизучать статистику, посмотреть, какие регионы подешевле и со стабильными ценами.
Цену лучше назначать раза в 1.5 выше текущей рыночной стоимости инстанса в данном регионе. При таком раскладе цена будет немного колебаться, но редко превышать заявленную Вами. Соответственно, так машина не часто будет «отваливаться».
Теперь подключим хранилище. Amazon угощает тридцатью Гб, так что почему бы не взять все 30…

Тегирование инстанса можно пропустить. И далее настройка портов. Тут главное — открыть порт, который мы будем использовать под Jupyter-сервер. Пусть по традиции это будет 8888. Жмем «Add rule», оставляем вариант «Custom TCP rule» и указываем порт 8888. Также добавляем протоколы HTTP и HTTPS и говорим, кто может прослушивать порты. Достаточно выбрать справа галки My IP.

На следующем шаге создаем ключ (pem-файл), который будет нас идентифицировать при удаленном подключении к машине через SSH протокол. Можно его назвать как угодно — главное после скачивания знать, где он лежит и ни в коем случае (!!!) не выкладывать на GitHub или куда-то еще онлайн. Относитесь к этому файлику почти как к паролю от банковской карты. Amazon рекомендует периодически обновлять pem-файлы (их можно иметь по 2 в каждом регионе, второй раз скачать тот же самый ключ нельзя).

Наконец все подтверждаем, ждем пару минут, пока инстанс запустится, и в EC2 на вкладке «Instances» замечаем, что что-то появилось.
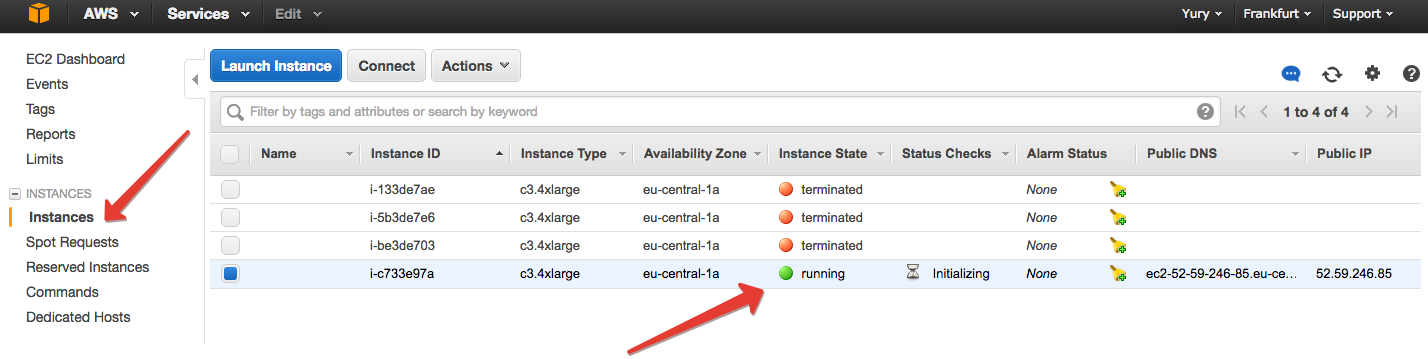
Выбираем появившийся инстанс и жмем Connect. Amazon дает инструкции, что делать дальше.
Если Вы сидите под Windows, то для Вас чтение статьи не заканчивается (обычно на этом месте в тьюториалах можно прочитать «Windows? Good luck!»). Надо только прочитать инструкции Amazon, как подключиться с помощью Putty.
Если же Вы под *NIX, то выполняем указанные 2 команды:
chmod 400 <PEM-file name>.pem
ssh -i <PEM-file name>.pem ubuntu@<HOST>
Первая заботится о том, чтоб не у всякого проходящего был доступ к Вашему pem-файлу. Вторая — это собственно подключение к виртуалке cо своим уникальным хостом .
Настройка машины
Если все прошло гладко, вы как юзер ubuntu попадете в терминал удаленной машины.
Можем делать что угодно, запускать любые скрипты, но мы остановимся на настройке инстанса для задач машинного обучения с Jupyter. Все команды далее описаны, чтоб в них было проще разобраться (и убедиться, что все обошлось без шуточек в стиле rm -rf /), но вообще второй раз и далее мы это будем запускать bash-скриптом.
Скачиваем и устанавливаем Miniconda. Она все же намного легче Anaconda, а необходимые библиотеки мы доустановим (впрочем, seaborn у меня не попер, а с Anaconda все нормально). Мы с машинкой ненадолго, вряд ли больше чем на несколько часов, так что без перфекционизма — устанавливаем все в домашний каталог.
wget -c http://repo.continuum.io/miniconda/Miniconda-latest-Linux-x86_64.sh
bash Miniconda-latest-Linux-x86_64.sh -b -p ~/miniconda
export PATH=~/miniconda/bin:$PATH
Теперь установим все библиотеки, какие захотим.
conda install -y numpy scipy pandas scikit-learn jupyter
Можно, например, и Vowpal Wabbit поставить (шустрые линейные модели, которые на больших выборках порой считаются и побыстрее MapReduce-реализаций).
sudo apt-get -qq install vowpal-wabbit
Не помешает и Git — так можно сразу нужный репозиторий скачать (использование Amazon S3 я в данном тюьториале не рассматриваю).
sudo apt-get -qq install git
Создадим сертификат, чтоб входить на Jupyter по паролю — так намного безопасней. Сейчас сделаем это руками, со второго раза этот созданный сертификат будет использоваться скриптом.
openssl req -x509 -nodes -days 365 rsa:2048 -keyout jupyter.pem -out jupyter.pem
Появится запрос об информации пользователя. В принципе это не обязательно заполнять.
Теперь создадим пароль для входа на Jupyter-сервер.
Можно воспользоваться функцией passwd из Ipython
python
>>> from IPython.lib import passwd
>>> passwd('Sample password')
Появится хэш Вашего пароля. Копируем его.
'sha1:d0c0b7eb515e:f0e59fcd04aec7bb50886084ae8e1fa9a273f88e'
Наконец, создаем профиль IPython и запускаем сервер, предварительно указав в файле настроек, какой порт мы хотим использовать и с каких адресов разрешен доступ. Указываем хэшированный пароль. У Вас пароль будет отличаться — надо вставить свой.
ipython profile create nbserver
printf "\n# Configuration file for ipython-notebook.\n
c = get_config()\n
# Notebook config\n
c.NotebookApp.ip = '*'\n
c.NotebookApp.password = u''sha1:d0c0b7eb515e:f0e59fcd04aec7bb50886084ae8e1fa9a273f88e''\n
c.NotebookApp.open_browser = False\n
c.NotebookApp.port = 8888\n" >> ~/.ipython/profile_nbserver/ipython_notebook_config.py
Последнее, что мы делаем только на удаленной машине — запускаем IPython-сервер.
(Почему IPython, а не Jupyter?.. Почему certfile явно указан? Ответ простой: костыли. Jupyter не хотел видеть config-файл, а потом не хотел в нем видеть настройки файла сертификата. Проверьте, может, у Вас и с командой jupyter запустится, и без явного указания файла настройки и сертификата).
ipython notebook --config="~/.ipython/profile_nbserver/ipython_notebook_config.py" --certfile=jupyter.pem
Если все прошло удачно, Вы увидите в конце прочитаете что-то типа этого.
[I 10:09:08.774 NotebookApp] Serving notebooks from local directory: /home/ubuntu
[I 10:09:08.775 NotebookApp] 0 active kernels
[I 10:09:08.775 NotebookApp] The Jupyter Notebook is running at: https://[all ip addresses on your system]:8888/
[I 10:09:08.775 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
Профит
Теперь переходим в браузере на HOST:8888, где HOST — это, по-прежнему, адрес вашего инстанса. Внимание! Протокол должен быть именно HTTPS, может также понадобиться подтверждение сертификата. (Например, в Chrome надо ткнуть «Дополнительные» и подтвердить переход на сайт).
Вводим свой пароль (тут уже, само собой, не хэшированный, а «обычный») и видим приятную картинку — файловую систему из Jupyter.

Создаем новый блокнот и радуемся обилию ядер под капотом.

Теперь вернемся в терминал (нашего компа, а не удаленной машины) и закинем на наш инстанс какой-нибудь набор данных. Скажем, из соревнования Kaggle "Forest Cover Type Prediction".
scp -i <PEM-file name>.pem <LOCAL_PATH_TO_DATA> ubuntu@<HOST>:/~
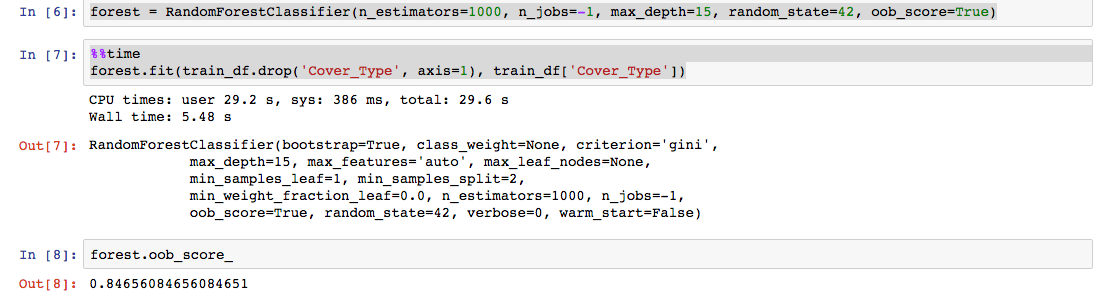
Про машинное обучение, конечно, интересно поговорить, но тут мы просто запустим случайный лес Sklearn на сырых данных.

Обратите внимание на параметр n_jobs — тут мы как раз и задействуем все 16 ядер.
1000 деревьев максимальной глубины 15 обучились ~ за 5 секунд — в 3 раза быстрее, чем на моем MacBook Air c 4 ядрами и 4 Гб памяти. На больших выборках разница, конечно, будет существенней.
То же самое скриптом
Процесс можно автоматизировать. С помощью Python Amazon SDK по имени boto можно и резервирование спотового инстанса скриптом делать. Но пока мы посмотрим на скрипты, которые готовят машину для работы с Jupyter уже после того, как она запустилась.
Все это — в репозитории Github.
Всего понадобятся 3 файла:
- В config.txt записываете путь к своему pem-файлу, хост свеже выданного инстанса, а также хэшированный пароль доступа к Jupyter-серверу, который мы создавали чуть раньше.
pemfile='<PEM-file>.pem' host='<HOST>' jupyter_password='<JUPYTER_PASSWORD>'
- В remote_setup.sh дописываете все, что хотите выполнить на удаленной машине.
# Installing Miniconda wget -c http://repo.continuum.io/miniconda/Miniconda-latest-Linux-x86_64.sh bash Miniconda-latest-Linux-x86_64.sh -b -p /home/ubuntu/miniconda export PATH=/home/ubuntu/miniconda/bin:$PATH #Installing neccesary libraries conda install -y numpy scipy pandas scikit-learn jupyter #Can add whatever you want to install #sudo apt-get -qq install vowpal-wabbit #sudo apt-get -qq install git ipython profile create nbserver printf "\n# Configuration file for ipython-notebook.\n c = get_config()\n # Notebook config\n c.NotebookApp.password = u'"$1"'\n c.NotebookApp.ip = '*'\n c.NotebookApp.open_browser = False\n c.NotebookApp.port = 8888\n" > ~/.ipython/profile_nbserver/ipython_notebook_config.py ipython notebook --config="~/.ipython/profile_nbserver/ipython_notebook_config.py" --certfile=jupyter.pem
- Скрипт launch_remote_setup.sh просто выполняет remote_setup.sh с нужными параметрами на удаленной машине.
source 'config.txt' scp -i $pemfile ./ipython.pem ubuntu@$remote_host:~ ssh -i $pemfile ubuntu@$remote_host 'bash -s' < remote_setup.sh $jupyter_password
В нужном каталоге выполните:
sh launch_remote_setup.sh
5-7 минут, и все! Можно работать с Jupyter-сервером.
Уже собрался было налить чаю. Но! Очень важный момент!
По окончании работы остановите ваш инстанс.
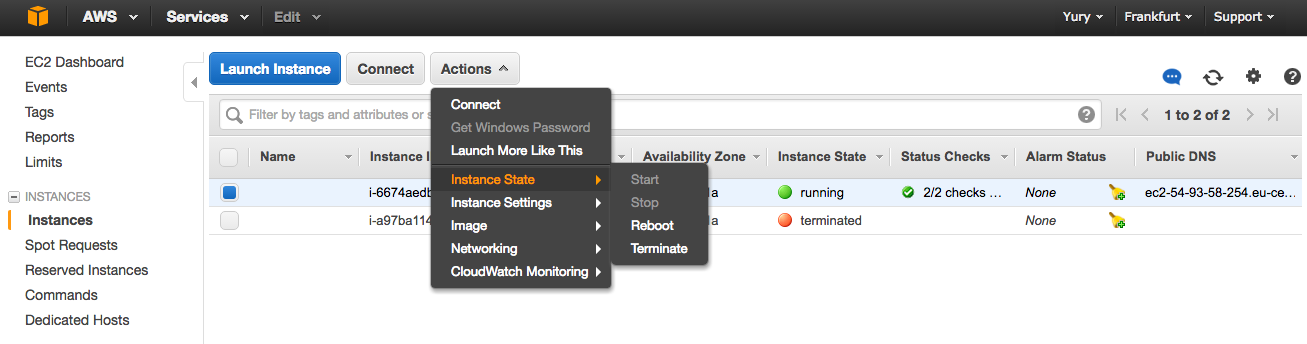
EC2 -> Instances -> Actions -> Instance State -> Terminate.
Именно terminate, а не stop (хотя для спотовых это только и доступно). Но в случае запуска инстансов по требованию stop не полностью выключает машину, могут набегать деньги за обмен данными.
Напоследок можно немного обсудить финансы. Текущий счет проверяется в Amazon при нажатии на свое имя и потом на «Billing & Cost Management».
$0.25 / час — это около $25 в месяц, если пользоваться по 4 часа каждый будний день. Дальше каждый сам решает, готов ли на такие траты.
Можно тут прорекламировать и GitHub Student Developer's Pack — я лично с их помощью получил сертификат Amazon на $110, все еще им пользуюсь. Кроме того, для серьезных научных проектов можно получить и грант Amazon.
Заключение
На этом пока все. Думаю, для некоторых это был jump-start в Amazon Web Services EC2. Дадим своим машинкам отдохнуть ночью!
PS. Замечания / советы / обмен опытом / pull request'ы приветствуются.
Комментарии (37)

yorko
31.03.2016 16:33+2Все зависит от Ваших потребностей. Вы описали сценарий, когда машина работает круглые сутки. Но если она Вам нужна, скажем, по 4 часа в день в будни для анализа данных, то за те же ~ $20 Вы можете использовать c3.4xlarge. На самом деле даже меньше, поскольку Вы платите по рыночной стоимости инстанса ($0.16-$0.2), а не заявленные $0.25.

gaploid
31.03.2016 17:20+1А еще можно воспользоваться Jupyter notes совершенно бесплатно в рамках Azure ML studio — https://blogs.technet.microsoft.com/machinelearning/2015/07/24/introducing-jupyter-notebooks-in-azure-ml-studio/ там уже есть Anaconda и прочие библиотеки и не нужно мучатся с деплойментом.
bonv
01.04.2016 13:00Последний раз когда пробовал Jupyter в Azure ML с ним было тяжело работать:
постоянный самопроизвольный рестарт ядра
невозможность установить нужные пакеты, например, XGBoost
yorko
01.04.2016 13:04Я для этого cloud.sagemath.com использую. Там и ядро Apache Saprk есть, и свои пакеты можно ставить. Но не думаю, что это боевой вариант. Я плачу $7 в месяц, и для серьезных задач этого мало — то ядро отвалится, то памяти не хватает, и все такое… А $49 в месяц им платить — неохота даже пробовать.
Тем не менее, для хостинга своих блокнотов без серьезных вычислений — отличный вариант.
Также неплохо для знакомства с Apache Spark.
nikitastaf1996
31.03.2016 17:24Меня в Amazon AWS и Microsoft Asure удивляет почему нельзя «закинуть денег на счет».Закинул предполжим долларов 20.И ты знаешь что больше 20 долларов с тебя не снимут если ты забудешь выключить.

coolspot
31.03.2016 20:18Именно потому что
больше 20 долларов с тебя не снимут если ты забудешь выключить.

acmnu
01.04.2016 13:00Многие банки такую услугу предоставляют: карта, которой можно пользоваться только для онлайн платежей. Стоит обычно около 1 доллара в месяц, а то и бесплатно, если вы привилегированный клиент. Закидываете на эту карту ровно 20 долларов, в минус на ней нельзя уйти (впрочем читайте мануал вашего банка, мало ли что). Ну а пополнение онлайн с другой карты или счета в том же аккаунте это дело нескольких минут.
netto
01.04.2016 20:04Это не решает проблему перерасхода. Просто у вас будет висеть неоплаченный счет.
vanyamasnuha
31.03.2016 17:24Почему бы не использовать vultr.com, например? Там тоже намного дешевле, чем в AWS, если програма не поддерживает GPGPU.

Stas911
31.03.2016 18:20+2Полезный туториал, спасибо!
Stas911
31.03.2016 18:23Еще бы добавить туда Spark\PySpark — вообще б классно было!
yorko
01.04.2016 02:38Это сам тоже делаю, расписывать пока лень, но в скором времени — возможно.
yorko
01.04.2016 11:00Изменения не такие большие будут, вот несколько тьюториалов: один, два, три.
Для конфигурации самого Spark можно использовать скрипт spark-ec2, входящий в дистрибутив (в каталоге ec2). Он написан с использованием boto, так что вручную запрашивать инстансы не придется.
Пример:
sudo ./spark-ec2 --key-pair=spark_key_pair --identity-file=spark_key_pair.pem --region=us-west-2 --zone=us-west-2c --instance-type=m4.large --slaves=3 --spot-price=0.02 launch m4largex3-cluster
Главное — не упустить аргумент spot-price. Иначе инстансы по требованию пойдут, и это будет намного дороже.
Но тут немало подводных камней. Если самому скрипт модифицировать, туда добавятся 2-3 костыля. Как руки дойдут, выложу на GitHub.yorko
01.04.2016 11:07+1Но если прям совсем боевая машина не нужна, посмотрите вариант Databricks Community Edition. 6 Гб они уже бесплатно дают. Можно попытаться грант у них выиграть.
Также надо быть уверенным, что вам именно Spark нужен. Может, сойдет и просто Vowpal Wabbit или Xgboost на одной машине с 30 ядрами?
Вот статья по теме. Тут VW на 2 порядка быстрее Hadoop-кластера.

Mugik
31.03.2016 23:03+2Я бы предостерег от необдуманных действий, особенно тех, кто раньше не управлял удаленными машинами.
Может к концу месяца придти счёт на несколько тысяч долларов и доказать что вы «не знали» «не хотели» «не думали» будет тяжеловато, скорее всего оплатить всё-таки придётся.TheCoreFactory
01.04.2016 10:35Я в свое время попался на их бесплатном варианте на год — побаловался и забыл, через год пришел счет на 12 что ли долларов за месяц. С точки зрения логики — сервер работал, так что оплатил и полностью удалил аккаунт, но могли бы и уведомления прислать о том что скоро окончание бесплатного года.(Перед окончанием подписки на Office Microsoft уведомление, кстати присылает).
yorko
01.04.2016 10:48А какие советы дадите?
Кроме тех предостережений Amazon — про пароли, IAM-пользователей, root-ключи, двухфакторную авторизацию и бережное хранение ключей.Mugik
01.04.2016 22:52использовать сервера с предоплатной системой. Заплатил — используешь, денег нет — сервер выключается.
Вполне реален путь, когда вы собрали какую-то платформу, запустили в реальный мир и легли спать. Утром будете должны 500 тысяч рублей. Верхнего порога нет, из коробки его нет, можно настроить конечно, но можно забыть, настроить не так, «случайно» отмениться порог и всё в таком духе.
Возможно это параноя, но можно за 1 ночь задолжать серьёзные деньги.
yorko
01.04.2016 10:36В AWS можно настроить уведомления. Когда счет превышает какой-то порог (скажем, $50), приходит письмо.
Grebenshchikov_Alex
Возможно я что то не понимаю, но пока можно взять нормальную виртуалку 2 Core CPU 8 GB RAM 200 GB SSD на фултайм за 20 долларов в месяц, зачем мне платить 36 долларов в тот же месяц, даже если это по 0,05 долл в час?
yusman
Скорее всего в такой виртуалке вы не сможете использовать ресурсы CPU и RAM на полную, а только 20-30% от номинальной(в лучшем случае), если это OpenVZ.
KVM точно не будут стоить таких денег
sim3x
www.vultr.com/pricing
www.digitalocean.com/pricing
meta4
В DO за 20 баксов 2Gb RAM и 40Gb SSD а не 8Gb & 200Gb соответственно
Dads_Minigun
hetzner
aru
Спот-инстансы (да и вообще подобные серверы с многоядерными процессорами и гигабайтами памяти) — это хороший выбор для тех, кто либо для себя, либо по работе занимается всякой бигдатой, когда нужно, например, тренировать модель, которая в «жалкие» 8 гигабайт просто не влезает и когда объем данных зашкаливает за десятки тысяч элементов. Если такого спроса у Вас нет — то, естественно, и платить любые деньги за это будет бессмысленно.
manucan
Буду очень признателен, если бы Вы смогли рассказать как можно натренировать модель где-то (как Вы указываете на спотах), а потом использовать слабенький локальный сервачок для предикта не гоняя по сети гигабайты трафика взяд-вперед, что обычно занимает между серваками крайне большое время.
aru
Пример из жизни: предположительно, Вам нужно натренировать качественную Named Entity Recognition модель, используя Conditional Random Fields в любой имплементации, для примера — CRF++. При большом количестве признаков и широких контекстах, память даже для небольшого (3-4 тысячи двух-трёх абзацевых документов), потребление памяти будет легко зашкаливать за 8Гб, однако, если использовать L1-регуляризацию и/или поставить отсечки по встречаемости признаков — то итоговая модель выберет наиболее успешные признаки и будет успешно обрабатывать новые тексты, потребляя гораздо более скромные 300-500Мб.
manucan
Пример из нашей жизни: постоянно переобучается классификатор текста. Объем модели 1,9 гигов и растет. Переобучается три-четыре раза в сутки примерно час на машине с 4гигами и всеми данными на винте. Задача обуславливается большим объемом текста и рубрик. Эта же машина делает предикты. Задача применить ваши методы и использовать спотовое обучение мощным инстансом на час несколько раз в день и предикты слабым инстансом в течение дня. Как это сделать не гоняя базу с инстанса на инстанс? Ведь даже если вынести данные на отдельный SQL инстанс, то для обучения модель все равно физически окажется на другом инстансе, а это потянет всю ту же перегонку данных взад-вперед и возврат модели на слабый инстанс. Перегонка туда-сюда данных\модели убивает все плюшки от раздельных вычислений. Поправьте пожалуйста где я не прав и что упускаю из виду.
aru
Напрямую, без хаков, никак — считайте, что вы тренируете модель на одном физическом сервере, а запускаете — на другом. Флешка, передача по сети, переставить жесткие диски — какой-то поток траффика понадобится.
Никогда так не делал, но в разрезе AWS можно поступить таким способом: http://stackoverflow.com/a/19870935/1628088.
Вкратце: в определенный момент (по окончании тренировки модели), создаётся Amazon Machine Image (AMI) из спот-инстанса и потом создаётся новый инстанс, с использованием созданного AMI (что подтянет дисковую систему и там будет лежать свежая модель).
Хотя что-то мне подсказывает, что так подход (копия, подъём инстанса с новой моделью) будет едва ли не дольше, чем просто скопировать модель с инстанса на инстанс. Судя по данным амазона, тот же Elastic Block Storage может дать производительность от ~35 до ~340 Мб/с (http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSVolumeTypes.html), что для вашей модели и данных даст время загрузки данных в две минуты, а вызгрузки модели — в минуту в худшем случае.
manucan
Большое спасибо! :) С меня пиво :)
aru
На здоровье, лишь бы заработало как вам надо!
grossws
Ещё можно выгружать модель на s3 и забирать другим инстансом/своим сервером.
necromant2005
Я просто оставлю это здесь:
https://aws.amazon.com/efs/ — elastic file system (aka NSF от амазона)
https://www.gluster.org — распределения файловая система с недавнего времени принадлежит redhat
Делается следующим образом:
а. пишем данные в локальный файл в распределенной файловой системе
b. запускаем инстанс из сохраненного образа и считаем все что нужно
c. тушим инстанс который занимался расчетом
brigader
Расскажите, пожалуйста, где можно заказать 2 Core CPU 8 GB RAM 200 GB SSD виртуалку за 20 долларов?
Grebenshchikov_Alex
в хецнере например.