 Хочу признаться: я обожаю визуальные новеллы. Кто не в курсе — это такие то ли интерактивные книжки, то ли игры-в-которых-надо-в-основном-читать-текст, то ли радиоспектакли-с-картинками, преимущественно японские. Последние лет 5, наверное, художественную литературу в другом формате толком не вопринимаю: у визуальных новелл по сравнению с бумажными книгами, аудио-книгами и даже сериалами — в разы большее погружение, да и сюжет регулярно куда интереснее.
Хочу признаться: я обожаю визуальные новеллы. Кто не в курсе — это такие то ли интерактивные книжки, то ли игры-в-которых-надо-в-основном-читать-текст, то ли радиоспектакли-с-картинками, преимущественно японские. Последние лет 5, наверное, художественную литературу в другом формате толком не вопринимаю: у визуальных новелл по сравнению с бумажными книгами, аудио-книгами и даже сериалами — в разы большее погружение, да и сюжет регулярно куда интереснее.
А еще я с детства обожаю разбираться в том, как устроены вещи и что у них внутри. Начинал с первых сломанных игрушек, дорос до реверс-инжиниринга и вирусного аналитика в одной не самой маленькой компании. И пришло мне в голову — почему бы не попробовать совместить эти вещи? Посмотреть, что у визуальных новелл внутри и разобраться, на основе чего работает тот или иной движок?
А тут как раз недавно вышел релиз Kaitai Struct — это такой новый фреймворк для реверс-инжиниринга бинарных структур данных (хотя авторы активно отпираются, говоря, что они это все только в мирных целях). Идея там банальная, но подкупает: декларативно описываешь на некоем языке разметки структуру данных — и тут же получаешь готовую библиотеку классов для парсинга на любом поддерживаемом языке программирования. В комплекте прилагаются визуализатор (чтобы легче было проверять) и, собственно, компилятор. Что ж, попробуем, на что оно годится?
В качестве разминки, а заодно для того, чтобы показать типовые действия, с которыми придется столкнуться в реверс-инжиниринге, предлагаю начать с чего-нибудь не очень тривиального, а именно с чудесной визуальной новеллы Koisuru Shimai no Rokujuso (в оригинале — ?????????) авторства широко известных в узких кругах PeasSoft. Это забавная, ненапрягающая романтическая комедия, с традиционно для PeasSoft красивой визуальной частью. С точки зрения реверсинга — меня она зацепила еще и тем, что использует не сильно распространенный и никем вроде бы еще не исследованный собственный движок. А это как минимум интереснее, чем ковыряться в уже напрочь замученных и растащенных по полочкам KiriKiri или Ren'Py.
Первым делом приведу список инструментов, которые нам потребуются:
- Kaitai Struct — компилятор и визуализатор к нему
- Java JRE — к сожалению, Kaitai Struct написан
на Javaна Scala иее требуеттребует либо JRE, либо node.js, но с node.js я не пробовал - любой из языков программирования, поддерживаемый KS (на данный момент это Java, JavaScript, Ruby, Python) — я буду использовать Ruby, но это не столь принципиально, на нем мы напишем листер и экстратор в самом конце
- какой-нибудь хекс-редактор — по большому счету, не важно какой, они все неидеальные; в принципе, хекс-редактор есть внутри визуализатора KS, но он тоже не самый удобный; я лично пользуюсь okteta (просто потому, что там есть по-человечески удобный копи-паст) — но пойдет почти все, что угодно — была б возможность смотреть дамп, переходить по заданному адресу и быстро скопировать выделенный кусок в отдельный файл
Дальше нужен сам продукт исследования — дистрибутив визуальной новеллы. Здесь тоже повезло: PeasSoft на своем сайте выкладывает для совершенно легального бесплатного скачивания триальные версии, которых нам вполне хватит для ознакомления с форматами. На сайте нужно найти такую вот страничку:

Обведенное синим — на самом деле ссылки на мирроры (все одинаковые), где дают скачать триал.
Скачав и распаковав дистрибутив, мы начнем со сбора информации. Давай подумаем, что мы уже знаем о нашем экспонате. Во-первых, платформа. По крайней мере та версия, что раздается на сайте, работает под Windows на процессорах Intel (вообще есть еще версия под Android, но на практике она продается только в маркетах приложений у японских сотовых операторов, плюс ее нетривиально вытащить с телефона). Из того, что это Windows/Intel вытекают несколько весьма вероятных вещей:
- целые числа в бинарных форматах будут кодироваться в little-endian
- программисты под Windows в Японии до сих пор
живут в каменном векепользуются кодировкой Shift-JIS - концы строчек, если мы их когда-то встретим в явно виде, будут обозначаться "\r\n", а не просто "\n"
Беглый осмотр распакованного и установленного показывает, что добыча состоит из:
- data01.ykc — 8393294
- data02.ykc — 560418878
- data03.ykc — 219792804
- sextet.exe — 978944
- AVI/op.mpg — 122152964
Т.е. здесь один небольшой exe-шник (очевидно, с движком), нескольких гигантских файлов .ykc (вероятно, архивов с контентом) и op.mpg — видеофайл с заставкой (в чем можно убедиться сразу, открыв его любым плеером).
Полезно быстренько визуально осмотреть exe-файл в хекс-редакторе: современные разработчики даже достаточно адекватны и зачастую пользуются готовыми библиотеками для работы с изображениями, звуками и музыкой. А такие библиотеки, как правило, при компиляции оставляют некие видимые невооруженным глазом сигнатуры. Что стоит искать:
- "libpng version 1.0.8 — July 24, 2000" — используется libpng, значит картинки будут в формате png
- "zlib version error", "Unknown zlib error" — означает, что будет использоваться сжатие zlib; на самом деле может быть ложным следом, т.к. zlib-сжатие используется при кодировании png; пока не будем делать далекоидущих выводов
- "Xiph.Org libVorbis I 20020717" — libvorbis, а это означает, что музыка, речь и звуки будут скорее всего в ogg/vorbis
- "Corrupt JPEG data", "Premature end of JPEG file" — строчки из libjpeg; если есть — значит, движок скорее всего умеет еще и картинки в формате jpg
- "D3DX8 Shader Assembler Version 0.91" — где-то внутри что-то использует шейдеры D3DX8
- россыпь сообщений типа "Microsoft Visual C++ Runtime Library", "
local vftable'", "eh vector constructor iterator'" и т.д. говорит нам о том, что компилировалось линковалось это с Microsoft'овской C++ библиотекой, и, скорее всего, написано на C++; при желании можно покопаться и узнать даже конкретную версию, но сейчас нам это особенно ни к чему — мы не собираемся ее дизассемблировать или что-то такое, у нас абсолютно честный clean room
Еще можно поискать строчки типа "version", "copyright", "compiler", "engine", "script" — причем, т.к. это Windows-файл, не забывать делать это еще и в двухбайтовых кодировках типа UTF16-LE — иногда может найтись еще что-нибудь интересное. У нас находится, например, "Yuka Compiler Error", "YukaWindowClass", "YukaApplicationWindowClass", "YukaSystemRunning", а также упоминания "start.yks", "system.ykg". Из всего этого логично предположить, что сами программисты называли свой движок как-то типа "Yuka", а всякие типы файлы, используемые им, все начинаются с yk — ykc, yks, ykg. Еще находится "CDPlayMode" и "CDPlayTime" — из чего можно предположить, что движок умеет играть музыку с дорожек Audio CD, а еще "MIDIStop" и "MIDIPlay" — из чего можно предположить поддержку музыки в MIDI.
По нашей новелле в сухом остатке получается достаточно оптимистичная картина:
- картинки в форматах png и jpg, что сразу на порядок облегчает задачу — скорее всего не нужно будет копаться в кастомных форматах сжатия картинок
- музыка, речь и звуки — скорее всего в ogg (но может быть и MIDI, и CDDA — хотя вряд ли, т.к. физического носителя нет)
Первоначальные сведения собраны — теперь можно засучить рукава и нырять в файлы. Файлов, на самом деле, несколько — и это тоже хорошо. Вообще в реверс-инжиниринге зачастую очень важным становится чисто статистический вопрос, когда изучаемого объекта можно достать более одного в различных вариациях и посмотреть, чем же они отличаются. Гораздо сложнее гадать, что же значит очередной 7F 02 00 00, когда он у тебя ровно один.
Проверяем, один ли и тот же формат у файлов. Судя по тому, что все они — data*.ykc — один. Смотрим внутрь на начало файла: все начинается с "YKC001\0\0" — очень хорошо, похоже, что это действительно архивы одного и того же формата.
Быстро эмпирически проверим, используется ли какое-то сжатие. Берем любой архиватор, пытаемся сжать файл и смотрим, сколько было до и сколько стало после. Я тупо использовал zip:
- до — 8393294
- после — 6758313
Сжимается, но не сильно. Скорее всего таки или сжатия нет, или оно есть не для всех файлов. С другой стороны, если в архиве какие-нибудь png или ogg —они же уже сжатые, zip'ом сжиматься они сильнее не будут.
Из общих соображений, у практически любого архива есть какой-то заголовок, есть, как правило, каталог содержимого архива (относительно небольшой), и 99% архивного файла занимает, собственно содержимое — вложенные файлы или блоки данных. Заголовок, кстати, не обязательно начинается прямо с начала файла — может быть с сколько-нибудь отступив от конца файла или сколько-нибудь (обычно немного) — от начала. Крайне редко можно встретить, чтобы файл начинали с места в карьер читать из середины.
Смотрим на начало файлов. Видим примерно следующую картину:
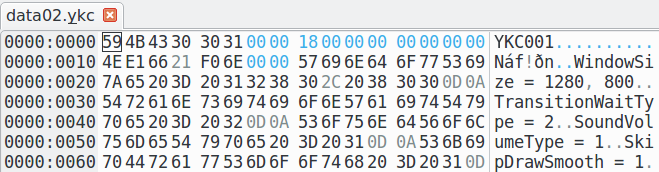
59 4B 43 30 ¦ 30 31 00 00— это явно просто сигнатура файла, в ASCII это "YKC001", скорее всего обозначает что-нибудь типа "Yuka Container", версии 00118 00 00 00 ¦ 00 00 00 00 ¦ 1A 00 80 00 ¦ 34 12 00 00— видимо, это и есть заголовок- дальше явно начинается тело какого-то файла внутри архива; особенно хорошо это видно в data02.ykc — там идут строчки какого-то то ли конфига, то ли скриптового языка: "WindowSize = 1280, 800", "TransitionWaitType = 2" и т.д.; т.е. дальше смотреть бессмысленно
Смотрим на то, как выглядит заголовок во всех трех имеющихся у нас файлах:
- data01.ykc:
18 00 00 00 ¦ 00 00 00 00 ¦ 1A 00 80 00 ¦ 34 12 00 00 - data02.ykc:
18 00 00 00 ¦ 00 00 00 00 ¦ 4E E1 66 21 ¦ F0 6E 00 00 - data03.ykc:
18 00 00 00 ¦ 00 00 00 00 ¦ 5C E1 18 0D ¦ 48 E4 00 00
Что такое "18 00 00 00 ¦ 00 00 00 00" — пока непонятно, но оно везде одинаковое. Гораздо интереснее остальные 2 поля — это явно два 4-байтовых целых числа. Кажется, пора доставать Kaitai Struct и начинать описывать полученные догадки в виде ksy-формата:
meta:
id: ykc
application: Yuka Engine
endian: le
seq:
- id: magic
contents: ["YKC001", 0, 0]
- id: magic2
contents: [0x18, 0, 0, 0, 0, 0, 0, 0]
- id: unknown1
type: u4
- id: unknown2
type: u4Вроде бы ничего сложного. ksy — на самом деле обычные YAML-файлы. Секция "meta" описывает, над чем мы собственно работаем и что мы собрали по итогам нашего предварительно расследования — т.е. что мы разбираем файлы "ykc", предположительно обрабатывает их приложение под названием "Yuka Engine" (поле "application" вроде бы ни на что не влияет, это как комментарий), и по умолчанию целые числа будут в little endian формате (endian: le).
Дальше идет описание того, как парсить файл и какие структуры данных мы в нем обнаружили — это задается массивом полей в секции "seq". Каждое поле обязано иметь id (и это логично, мы ради этого и работаем, чтобы понять, что где лежит) и описание содержимого. Тут мы использовали две конструкции:
- Конструкция типа
contents: [0x18, 0, 0, 0, 0, 0, 0, 0]задает поле с фиксированным содержимым. Работает это так: из содержимого автоматически следует его длина, плюс KS автоматически сделает проверку и выбросит exception, если при чтении такого поля содержимое не будет соответствовать ожидаемому - Конструкция типа
type: u4задает поле типа "целое беззнаковое (_u_nsigned) число, длина 4 байта". Endianness при этом такой, как мы указали в meta.
Загружаем теперь наш новоиспеченный формат в визуализатор:
ksv data01.ykc ykc.ksy и лицезрим для data01.ykc:
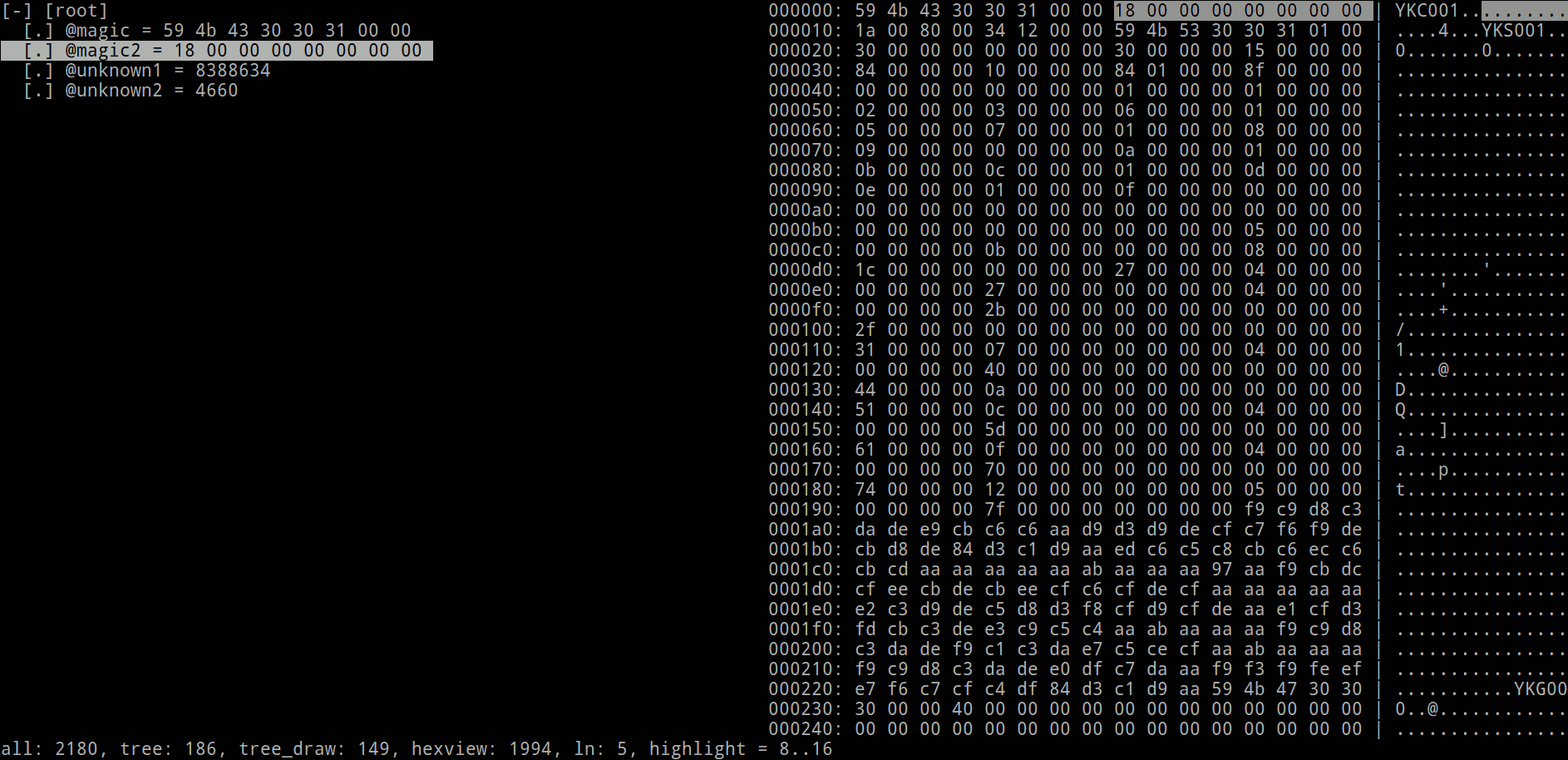
Да, визуализатор работает в консоли, можно начинать ощущать себя хакером. Но сейчас нас интересует дерево структур:
[-] [root]
[.] @magic = 59 4b 43 30 30 31 00 00
[.] @magic2 = 18 00 00 00 00 00 00 00
[.] @unknown1 = 8388634
[.] @unknown2 = 4660В визуализаторе можно стрелочками ходить по полям, можно переключаться в hex viewer и обратно нажатием Tab, а нажатием Enter можно проваливаться в содержимое полей, раскрывать instances (о них будет ниже) и просматривать хекс-дампы на полный экран. Для экономии места и времени я ниже скриншоты визуализатора больше показывать не буду, буду показывать только часть с деревом текстом.
Смотрим для data02.ykc:
[-] [root]
[.] @magic = 59 4b 43 30 30 31 00 00
[.] @magic2 = 18 00 00 00 00 00 00 00
[.] @unknown1 = 560390478
[.] @unknown2 = 28400для data03.ykc:
[-] [root]
[.] @magic = 59 4b 43 30 30 31 00 00
[.] @magic2 = 18 00 00 00 00 00 00 00
[.] @unknown1 = 219734364
[.] @unknown2 = 58440Негусто, в общем. Каталога файлов нет, где искать концы, на первый взгляд, непонятно. Тут самое время вспомнить еще раз, сколько же эти файлы занимают и прикинуть, не может ли одно из этих двух числе быть ссылкой куда-то еще:
- data01.ykc — 8393294 @unknown1 = 8388634
- data02.ykc — 560418878 @unknown1 = 560390478
- data03.ykc — 219792804 @unknown1 = 219734364
Какое поразительное сходство. Давайте проверять, что там лежит по этому смещению:
meta:
id: ykc
application: Yuka Engine
endian: le
seq:
- id: magic
contents: ["YKC001", 0, 0]
- id: magic2
contents: [0x18, 0, 0, 0, 0, 0, 0, 0]
- id: unknown_ofs
type: u4
- id: unknown2
type: u4
instances:
unknown3:
pos: unknown_ofs
size-eos: trueМы добавили описание еще этого поля "unknown3". На этот раз оно пошло не в секцию "seq", а в секцию "instances". По сути это примерно те же поля, что можно описать в "seq", но они идут не по порядку, а имеют явное указание, откуда их читать (по какому смещению, из какого потока и т.д.). Мы указали, что хотим иметь поле с названием "unknown3" (мы пока не знаем, что там), начинающееся от смещения unknown_ofs (pos: unknown_ofs) и длящееся до конца файла (size-eos: true). Как как ты не знаем, что там — нам прочитают просто поток байт. Да, пока негусто, но с этим уже можно пробовать жить. Пробуем:
Сразу обращаем внимание на то, что длина того, что у нас прочиталась поразительно похоже на содержимое поле unknown2. Т.е. похоже, что в начале YKC-файла лежит просто указание, по какому смещению и какого размера реальный заголовок файла. Исправляем наш файл формата, чтобы отразить эту догадку:
meta:
id: ykc
application: Yuka Engine
endian: le
seq:
- id: magic
contents: ["YKC001", 0, 0]
- id: magic2
contents: [0x18, 0, 0, 0, 0, 0, 0, 0]
- id: header_ofs
type: u4
- id: header_len
type: u4
instances:
header:
pos: header_ofs
size: header_lenИзменения незначительные: мы переименовали все unknown-поля, чтобы отразить их смысл, и "size-eos: true" (читать все безусловно до конца файла) изменили на "size: header_len". Скорее всего это близко соответствует замыслу того, кто придумывал этот формат. Загружаем еще раз и теперь концентрируемся на том блоке данных, что мы назвали "header". Вот как выглядит его начало для data01.ykc:
000000: 57 e7 7f 00 0a 00 00 00 18 00 00 00 13 02 00 00 | W...............
000010: 00 00 00 00 61 e7 7f 00 0b 00 00 00 2b 02 00 00 | ....a.......+...
000020: db 2a 00 00 00 00 00 00 6c e7 7f 00 11 00 00 00 | .*......l.......
000030: 06 2d 00 00 92 16 00 00 00 00 00 00 7d e7 7f 00 | .-..........}...для data02.ykc:
000000: d1 2b 66 21 0c 00 00 00 18 00 00 00 5a 04 00 00 | .+f!........Z...
000010: 00 00 00 00 dd 2b 66 21 14 00 00 00 72 04 00 00 | .....+f!....r...
000020: 26 1a 00 00 00 00 00 00 f1 2b 66 21 16 00 00 00 | &........+f!....
000030: 98 1e 00 00 a8 32 00 00 00 00 00 00 07 2c 66 21 | .....2.......,f!для data03.ykc:
000000: ec 30 17 0d 26 00 00 00 18 00 00 00 48 fd 00 00 | .0..&.......H...
000010: 00 00 00 00 12 31 17 0d 26 00 00 00 60 fd 00 00 | .....1..&...`...
000020: 0d 82 03 00 00 00 00 00 38 31 17 0d 26 00 00 00 | ........81..&...
000030: 6d 7f 04 00 d0 85 01 00 00 00 00 00 5e 31 17 0d | m...........^1..На первый взгляд, ничего не понятно и общего ничего нет. На второй взгляд, на самом деле, глаз цепляется за последовательность повторяющихся байт. В первом файле это e7 7f, во втором — 2b 66, в третьем — 30 17 и 31 17. Очень похоже, что мы имеем дело с повторяющимися записями фиксированной длины и длина эта — 0x14 (т.е. 20) байт. Кстати, это хорошо согласуется с длинами header во всех трех файлах: и 4660, и 28400, и 58440 делятся на 20. Давайте проверять такую гипотезу:
meta:
id: ykc
application: Yuka Engine
endian: le
seq:
- id: magic
contents: ["YKC001", 0, 0]
- id: magic2
contents: [0x18, 0, 0, 0, 0, 0, 0, 0]
- id: header_ofs
type: u4
- id: header_len
type: u4
instances:
header:
pos: header_ofs
size: header_len
type: header
types:
header:
seq:
- id: entries
size: 0x14
repeat: eosОбратите внимание на то, что стало с instance "header". Оно все так же начинается с header_ofs и имеет длину header_len, но добавилось еще указание type: header. В отличие от "u4" (целое число), мы сейчас объявим и будем использовать пользовательский тип и весь блок "header" будет разбираться этим типом. Ниже идет описание типа "header" — см. "types: header: ". Как можно догадаться по внешнему виду и слову "seq" — дальше следует ровно такой же синтаксис как на самом верхнем уровне файла. Т.е. внутри нашего нового типа header можно точно так же задать поля, которые будут читать с самого начала блока последовательно (в "seq"), поля по определенным смещениям (в "instances"), свои подтипы (в "types") и т.д.
Итак, мы задали тип "header", состоящий пока из одного поля entries, имеющего размер 0x14 байт, зато повторенного столько раз, сколько возможно до конца потока (repeat: eos). Потоком, кстати, в этом случае считается уже блок header, который мы объявили явно как блок в header_len байт, начинающийся с header_ofs. Т.е. если бы там что-то было за ним еще — оно бы не прочиталось, все в порядке.
Смотрим, что получилось:
[-] header
[-] @entries (233 = 0xe9 entries)
[.] 0 = 57 e7 7f 00|0a 00 00 00|18 00 00 00|13 02 00 00|00 00 00 00
[.] 1 = 61 e7 7f 00|0b 00 00 00|2b 02 00 00|db 2a 00 00|00 00 00 00
[.] 2 = 6c e7 7f 00|11 00 00 00|06 2d 00 00|92 16 00 00|00 00 00 00
[.] 3 = 7d e7 7f 00|14 00 00 00|98 43 00 00|69 25 00 00|00 00 00 00
[.] 4 = 91 e7 7f 00|15 00 00 00|01 69 00 00|d7 12 00 00|00 00 00 00
[.] 5 = a6 e7 7f 00|12 00 00 00|d8 7b 00 00|27 3f 07 00|00 00 00 00 А что, неплохо. Какая-то общность записей явно прослеживается. Из спортивного интереса посмотрим второй файл:
[-] header
[-] @entries (1420 = 0x58c entries)
[.] 0 = d1 2b 66 21|0c 00 00 00|18 00 00 00|5a 04 00 00|00 00 00 00
[.] 1 = dd 2b 66 21|14 00 00 00|72 04 00 00|26 1a 00 00|00 00 00 00
[.] 2 = f1 2b 66 21|16 00 00 00|98 1e 00 00|a8 32 00 00|00 00 00 00
[.] 3 = 07 2c 66 21|16 00 00 00|40 51 00 00|a2 16 00 00|00 00 00 00
[.] 4 = 1d 2c 66 21|16 00 00 00|e2 67 00 00|89 c4 00 00|00 00 00 00
[.] 5 = 33 2c 66 21|16 00 00 00|6b 2c 01 00|fa f5 00 00|00 00 00 00 Кстати, "233" и "1420" записей вполне похоже на количество файлов в архиве. Первый архив у нас маленький (8 мегабайт), на 233 файла — получается в среднем по 36022 байта на файл. Вполне похоже на какие-то скрипты, конфиги, файлы сценариев и т.п. Второй архив у нас самый большой (560 мегабайт), на 1420 файлов — по 394661 байта на файл, вполне похоже на какие-нибудь картинки или файлы с записями голоса.
57 e7 7f 00, 61 e7 7f 00, 6c e7 7f 00 и т.д. — это явно последовательность увеличивающихся чисел, что бы она могла означать? Во втором файле это, соответственно, d1 2b 66 21, dd 2b 66 21, f1 2b 66 21. Стоп, где-то я уже видел эти цифры. Смотрим в самое начало нашего исследования — точно. Это же близко к длине всего архивного файла целиком. А значит это опять указатели на что-то внутри файла. Собственно, давайте уже опишем структуру этих 20-байтовых записей. Вроде бы из внешнего вида понятно, что это банально 5 целых чисел. Описываем еще один тип "file_entry". В вашего молчаливого разрешения я не буду приводить весь ksy файл целиком, а приведу только изменившуюся секцию types:
types:
header:
seq:
- id: entries
repeat: eos
type: file_entry
file_entry:
seq:
- id: unknown_ofs
type: u4
- id: unknown2
type: u4
- id: unknown3
type: u4
- id: unknown4
type: u4
- id: unknown5
type: u4Здесь никаких новых конструкций вроде бы нет. Добавили "type" к полю entries и описали этот самый тип как 5 подряд идущих целых (типа u4). Смотрим, что получилось:
[-] header
[-] @entries (233 = 0xe9 entries)
[-] 0
[.] @unknown_ofs = 8382295
[.] @unknown2 = 10
[.] @unknown3 = 24
[.] @unknown4 = 531
[.] @unknown5 = 0
[-] 1
[.] @unknown_ofs = 8382305
[.] @unknown2 = 11
[.] @unknown3 = 555
[.] @unknown4 = 10971
[.] @unknown5 = 0
[-] 2
[.] @unknown_ofs = 8382316
[.] @unknown2 = 17
[.] @unknown3 = 11526
[.] @unknown4 = 5778
[.] @unknown5 = 0Вырисовывается еще одна гипотеза: unknown3 — указатель на начало тела файла в архиве, а unknown4 — его длина. Ведь 24 + 531 = 555, а 555 + 10971 = 11526. Т.е. это файлы внутри архива, которые тупо идут последовательно. Аналогичное наблюдение можно сделать и для unknown_ofs и unknown2: 8382295 + 10 = 8382305, 8382305 + 11 = 8382316. То есть unknown2 — длина каких-то записей, начинающихся с unknown_ofs. unknown5, похоже, всегда равен 0. Вперед, добавляем внутрь каждого file_entry еще два поля: зачитаем, контент (unknown_ofs; unknown2) и тело файла на (unknown3; unknown4). Привожу только описание file_entry:
file_entry:
seq:
- id: unknown_ofs
type: u4
- id: unknown_len
type: u4
- id: body_ofs
type: u4
- id: body_len
type: u4
- id: unknown5
type: u4
instances:
unknown:
pos: unknown_ofs
size: unknown_len
io: _root._io
body:
pos: body_ofs
size: body_len
io: _root._ioИз нового и нетривиального здесь только одна конструкция: io: _root._io. Без нее pos: body_ofs, скажем, будет отсчитывать смещение body_ofs в текущем потоке, т.е. в потоке, состоящем из 20 байт file_entry. Разумеется, попытка прочитать 8-милионный байт из 20 приведет к ошибке. Поэтому и нужна эта самая специальная магия, которая говорит о том, что зачитывать мы будем не из текущего потока, а из того потока, который соответствует всему файлу в целом — _root._io.
Что получилось:
[-] @entries (233 = 0xe9 entries)
[-] 0
[.] @unknown_ofs = 8382295
[.] @unknown_len = 10
[.] @body_ofs = 24
[.] @body_len = 531
[.] @unknown5 = 0
[-] unknown = 73 74 61 72 74 2e 79 6b 73 00
[-] body = 59 4b 53 30 30 31 01 00 30 00 00 00…
[-] 1
[.] @unknown_ofs = 8382305
[.] @unknown_len = 11
[.] @body_ofs = 555
[.] @body_len = 10971
[.] @unknown5 = 0
[-] unknown = 73 79 73 74 65 6d 2e 79 6b 67 00
[-] body = 59 4b 47 30 30 30 00 00 40 00 00 00…Даже невооруженным глазом видно, что 73 74 61 72 74 2e 79 6b 73 00 — это ASCII-строка, а посмотрев в char-представление, можно убедиться, что это "start.yks" с терминирующим 0 байтом, а 73 79 73 74 65 6d 2e 79 6b 67 00 — это "system.ykg". Ура, это похоже на имена файлов. И про них мы точно знаем, что они — строки. Давайте отразим этот факт:
file_entry:
seq:
- id: filename_ofs
type: u4
- id: filename_len
type: u4
- id: body_ofs
type: u4
- id: body_len
type: u4
- id: unknown5
type: u4
instances:
filename:
pos: filename_ofs
size: filename_len
type: str
encoding: ASCII
io: _root._io
body:
pos: body_ofs
size: body_len
io: _root._ioИз нововведений — type: str (означает, что захваченные байты надо интерпретировать, как строку) и encoding: ASCII (мы пока точно не знаем, что там за кодировка, поэтому пойдем по пути наименьшего сопротивления). Смотрим в визуализаторе:
[-] header
[-] @entries (233 = 0xe9 entries)
[-] 0
[.] @filename_ofs = 8382295
[.] @filename_len = 10
[.] @body_ofs = 24
[.] @body_len = 531
[.] @unknown5 = 0
[-] filename = "start.yks\x00"
[-] body = 59 4b 53 30 30 31 01 00 30 00 00 00…
[-] 1
[.] @filename_ofs = 8382305
[.] @filename_len = 11
[.] @body_ofs = 555
[.] @body_len = 10971
[.] @unknown5 = 0
[-] filename = "system.ykg\x00"
[-] body = 59 4b 47 30 30 30 00 00 40 00 00 00…
[-] 2
[.] @filename_ofs = 8382316
[.] @filename_len = 17
[.] @body_ofs = 11526
[.] @body_len = 5778
[.] @unknown5 = 0
[-] filename = "SYSTEM\\black.PNG\x00"
[-] body = 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d…Красота. Фактически, все, задачу мы уже выполнили, этого достаточно, чтобы извлекать файлы. А теперь — та магия, ради которой все затевалось. Давайте напишем скрипт, который выгрузит нам все файлы из одного архива. И для этого нам не придется писать парсинг всех этих полей еще раз. Мы просто берем компилятор ksc и делаем:
ksc -t ruby ykc.ksyи получаем в текущей папке прекрасный файл ykc.rb, который можно тут же подключать, как библиотеку и использовать. Как? Давайте для разминки покажу, как вывести на экран листинг всех файлов архива:
require_relative 'ykc'
Ykc.from_file('data01.ykc').header.entries.each { |f| puts f.filename }Внушает? Всего одна строчка (не считая подключения библиотеки) — и готово. Запускаем и видим здоровый листинг:
start.yks
system.ykg
SYSTEM\black.PNG
SYSTEM\bt_click.ogg
SYSTEM\bt_select.ogg
SYSTEM\config.yks
SYSTEM\Confirmation.yks
SYSTEM\confirmation_load.png
SYSTEM\confirmation_no.ykg
SYSTEM\confirmation_no_load.ykg
...Давайте разберемся, что же тут происходит:
Ykc.from_file(...)— порождает объект класса Ykc из указанного файла на диске; в поля объекта автоматически парсится то, что описано в формате.header— выбирает поле "header" класса Ykc, тем самым возвращая экземпляр класса Ykc::Header.entries— выбирает поле "entries" у заголовка, возвращает массив элементов класса Ykc::FileEntry.each { |f| ... }— делает что-то с каждым элементом массиваputs f.filename— выводит поле "filename" объекта f (который класса Ykc::FileEntry)
Перед тем, как написать код, который будет извлекать из архива все файлы, обратим внимание еще на пару фактов:
- Во-первых, в путях есть папки, а т.к. этот архив делали на Windows-системе, в качестве знака разделителя элементов пути используется обратный слэш ("\"). Не знаю как где, но как минимум в Ruby это приводит к тому, что создается папка с обратными слэшами в ней. Для корректной работы всяких там mkdir_p нужно будет поменять "\" на "/".
- Во-вторых, в именах файлов в конце есть терминирующий 0, доставшийся нам, видимо, как тяжелое наследие C. При выводе на печать его не видно, но по хорошему его бы тоже стоит убрать.
- В-третьих, на самом деле вскрытие показало, что в data02.ykc находятся файлы, выглядящие как-то так:
"SE\\00050_\x93d\x98b\x82P.ogg\x00"
"SE\\00080_\x83J\x81[\x83e\x83\x93.ogg\x00"
"SE\\00090_\x83`\x83\x83\x83C\x83\x80.ogg\x00"
"SE\\00130_\x83h\x83\x93\x83K\x83`\x83\x83\x82Q.ogg\x00"
"SE\\00160_\x91\x96\x82\xE8\x8B\x8E\x82\xE9\x82Q.ogg\x00"Вспомнив гипотезу из самого начала статьи о том, что программисты явно были японцами и это может быть ShiftJIS, меняем encoding у filename на "SJIS", активно утешая себя мыслью о том, что для тех, кто использует не-ASCII символы в именах файлах приготовлен специальный круг в аду. Не забываем перекомпилировать ksy => rb, проверяем, теперь все в порядке:
SE\00050_??1.ogg
SE\00080_????.ogg
SE\00090_????.ogg
SE\00130_?????2.ogg
SE\00160_????2.oggНу, не то, чтобы совсем в порядке, но это вполне похоже на японский. Воспользовавшись хотя бы гуглопереводчиком, можно проверить, что "??" — это "телефон", и "SE\00050" — видимо, звуковой эффект звонка телефона.
Окончательный скрипт выгрузки всего выглядит так:
require 'fileutils'
require_relative 'ykc'
EXTRACT_PATH = 'extracted'
ARGV.each { |ykc_fn|
Ykc.from_file(ykc_fn).header.entries.each { |f|
filename = f.filename.strip.encode('UTF-8').gsub("\\", '/')
dirname = File.dirname(filename)
FileUtils::mkdir_p("#{EXTRACT_PATH}/#{dirname}")
File.write("#{EXTRACT_PATH}/#{filename}", f.body)
}
}Уже не одна строчка, конечно, но, с другой стороны, комментировать тут тоже особенно нечего. Из аргументов командной строки получаем имена файлов с архивами (вполне можно запускать что-то типа ./extract-ykc *.ykc — сработает), приводим к нужному нам виду имя файла из f.filename, создаем, если нужно, папки в пути, берем само содержимое файла из f.body и записываем его в файл с нужным путем.
Наша задача выполнена — запустив скрипт, можно действительно убедиться в том, что файлы извлекаются. Как мы и предполагали, картинки будут преимущественно в png (и их можно сразу же смотреть), музыка и звуки — в ogg (и их можно сразу же слушать). Вот, например, что в папке BG явно получились все бэкграунды:
А в папке TA/ по разложены спрайты, которые на них накладываются. Так, например, выглядит Мика:

Отдельно обратите внимание на страшные названия файлов. Самое нетривиальное, что остается — это извлеченные файлы yks и ykg — видимо, в них и есть сценарий и текст новеллы. На первый взгляд — это бинарные файлы с непонятной структурой. Думаю, отложим их на следующий раз :)
Краткие выводы по итогам такого шапочного знакомства с KS:
- Kaitai Struct в целом весьма годен, достаточно близко соответствует тем действиям, которые бы делались без него и экономит кучу времени. Если делать такое руками — то, как минимум, пришлось бы писать то же самое на каком-нибудь Ruby или Python: один раз, чтобы разобраться со структурой бинарника, другой — чтобы собственно сделать распаковщик. А если делать это средствами каких-нибудь "продвинутых" редакторов типа 101 или Hexinator — то и три раза (плюс еще один раз — описать в редакторе).
- Визуализатор Kaitai Struct — весьма примитивен, и местами тормозит и подглючивает, но, в целом, это лучшее, что я видел в этой области. Ему бы еще хекс-редактор доделать до состояния okteta.
- Хекс-редактор, собственно, можно выкидывать после того, как сделан первый скелет файла. Все равно ходить по дереву куда проще и нагляднее, чем вручную вбивать смещения. Но он все еще нужен и полезен для предварительного просмотра + просмотра exe-шника.
- Экспрессивность языка ksy очень большая (в разы лучше и удобнее, чем те же языки разметки в редакторах — например, там, как правило, даже речь не идет о том, чтобы декларативно описать структуру в другом конце файла), но вот документация, мягко говоря, оставляет желать лучшего. Признаюсь честно — за последнюю неделю я, наверное, задолбал вопросами автора KS. Вот этот самый трюк с
io: _root._io— вообще отстрел мозга, который самостоятельно не придумаешь. Надеюсь, к версии 1.0 документацию таки приведут в приличный вид.
UPDATE: Прошу у всех прощения за ввод в заблуждение с визуализатором. Оказывается, он еще не опубликован — мне автор высылал лично пару недель назад. Сейчас написал автору, спросил, можно ли его выложить.
UPDATE 2: Как оказалось, в статье был ряд неточностей, а автор KS — GreyCat — есть на хабре. Автор обещал выложить визуализатор в ближайшее время.
UPDATE 3: Визуализатор выложили. Ставится через gem install kaitai-struct-visualizer.
Комментарии (51)

nightw0rk
14.04.2016 15:29+2Установил пакет kaitai-struct-compiler, но там нет визуализатора =(. Где его взять?

zone19
14.04.2016 17:34+1Присоединяюсь к вопросу.

GreyCat
15.04.2016 11:33+4Ох %) Я не автор статьи, зато как бы немножко автор KS :) До сих пор немножко в офигевшем состоянии.
Уважаемый товарищ mnakamura каким-то непостижимым образом нашел KS, когда мы его только начинали выкладывать на github и по сути была выложена только первая версия компилятора. Написал мне, я ответил, завязалась переписка — всегда же здорово, когда обращают внимание и когда по делу. Общались по-английски. И я, разумеется, в жизнь бы не подумал, что товарищ с именем Nakamura Matsuo и японским e-mail'ом может писать по-русски, да и еще отгрохать такую статью на хабр. Накамура, блин. Ну ладно я. Но у меня-то в почте вполне русские имя-фамилия видны, да и на github'е я особенно не скрываюсь. Неужели было сложно посмотреть? И уж тем более если статью на уважаемый ресурс пишешь — хоть спросить?
Сворачивая драму и возвращаясь к исходному вопросу и статье, позволю себе немножко прокомментировать:
1. На самом деле современная версия компилятора написана на Scala, а не на Java.
2. Для запуска на самом деле есть варианта: либо под JRE, либо под node.js (т.к. Scala может компилироваться в JavaScript).
3. Визуализатор действительно есть и он действительно не выложен. Мы планировали выкладывать его на следующей неделе, но раз события так подстегивают — дайте хоть полчаса-час времени, приведу его в более-менее приличное состояние и выложу.
ComradeAndrew
15.04.2016 11:53Т.е. у автора статьи визуализатор, которого нет в паблике?
И вправду интересно получилось :)GreyCat
15.04.2016 12:01+4Да я как бы не против, его в любом случае предполагалось выкладывать, но все ж знают, что одна ошибка — и ты поддерживаешь ее всю оставшуюся жизнь %)

mnakamura
15.04.2016 12:10+2Еще раз виноват. Признаю, меру, степень, глубину. Я как-то не догадался посмотреть — уже привык, что преимущественно вся infosec-тусовка в штатах и общается по-английски. У меня сейчас в контактах, например, Feodor Fitzman и Stacy Krymsky — с обоими знакомился на конференциях, про обоих я достоверно знаю, что люди родились в штатах и по-русски не говорят (хотя, вероятно, семейные корни из xUSSR).
Пользуясь случаем, хочу поблагодарить тогда еще раз уже по-русски за отличный проект. Извините, что так получилось с визуализатором.
mnakamura
20.04.2016 09:58Визуализатор появился в районе https://github.com/kaitai-io/kaitai_struct_visualizer/ — см. update 3.

DanSpirov
15.04.2016 10:22+1Да, хотелось бы по-подробнее о том, где взять визуализатор или как включить, если он есть в стандартной сборке?
mnakamura
20.04.2016 09:58Визуализатор появился в районе https://github.com/kaitai-io/kaitai_struct_visualizer/ — см. update 3.
mnakamura
15.04.2016 10:42Посыпаю голову пеплом, мой промах. Я узнал о KS пару недель назад, списался с автором — и он мне много чем помогал, в том числе прислал кучу примеров форматов, вот этот самый визуализатор, дампер в YAML/JSON и т.п. утилиты. Я, собственно, увидел анонс на opennet, что у них релиз таки состоялся и подумал, что это все уже опубликовали, а, оказывается, пока опубликовали только компилятор.
Сейчас посмотрел внимательнее — в компиляторе явно есть файл LICENSE, что он GPL, а вот в визуализаторе нигде упоминаний о лицензии нет — соответственно, я немножко в ступоре — могу ли я его куда-то выкладывать или как… Сейчас напишу и спрошу.
mnakamura
20.04.2016 09:58Визуализатор появился в районе https://github.com/kaitai-io/kaitai_struct_visualizer/ — см. update 3.

veshurik
14.04.2016 15:41+3Всё, теперь я знаю, к кому обращаться для того, чтобы вскрыть никому не известную визуалку на непонятно каком движке.
mnakamura
15.04.2016 10:44+2Обращайтесь, на самом деле, ???? ;) У меня в коллекции пока 4 расковырянных более-менее хорошо движка, хотелось бы еще собрать.

andreili
15.04.2016 23:40+1Вскройте двиг фирмы eushully ;)
Там своя ВМка с опкодами (коих я насчитал около 300). Больше года колупал — так и не смог понять принципа работы, настолько там всё завернуто. Все скрипты являются бинарниками с секциями кода и прочих данных, включая даже некие таблицы смещений. Все тексты упрятаны там же и не правятся без изменения кучи смещений в коде и т.п.
PS: Я пока колупаю двиг Overflow (School Days & Co). Уже давно 95%, даже свой двиг готов на его основе. осталось только пара фитч нереализованных.veshurik
16.04.2016 18:18+1О, сейчас как раз идёт перевод Kami no Rhapsody от них, бедные ребята переводят через Visual Novel Reader, так как скрипты никто не смог вскрыть :(
andreili
16.04.2016 19:18+1Я частично вскрыл, но все зависло на всех этих смещениях. Я даже сам движок пропатчил (ASMом, в HEX-редакторе), переведя весь вывод текста на экране на Юникод. В итоге даже отвязал игру от японской локали вовсе (даже поиск шрифтов перебил, что бы показывал именно Юникодовские шрифты, а не ShifJS).
mnakamura
17.04.2016 03:50Давайте объединять усилия? У меня по Eushully ряд наработок есть (я Arterial начинал, но он дико нудный и длинный — в итоге так и не прошел, да и интерес ковырять поугас — VMка там действительно одна из самых странных, что я видел). VMки, кстати, в KS разбираются относительно неплохо, я уже штуки 3 сделал в нем.
grechnik
23.04.2016 23:20Вы меня заинтриговали, скачал, посмотрел. А что там принципиально сложного? Ну, помимо очевидного замечания, что при количестве команд в несколько сотен выяснение всех деталей того, что делает каждая, потребует некоторой усидчивости?
Таблицы смещений в скриптах в количестве трёх штук — просто адреса команд с опкодами 0x71, 3, 0x8F. Первая — список возможных сообщений для хранения флагов прочитанности/непрочитанности, вторая — список возможных внешних вызовов из скрипта, третья — список возможных вызовов процедур. Подозреваю, что так сделано для большей стабильности сейвов: когда в сейвах стек вызовов хранится как массив индексов в отдельной таблице, а не прямо адресами внутри файла, это не будет плыть при каждом изменении скриптов.
Для правки текстов кучу смещений изменять не нужно, достаточно дописывать исправленные тексты в конец файла и править только одно смещение — собственно адрес текста.
Примитивный дизассемблерfrom __future__ import print_function import io, sys, struct #table generated automatically, minor mistakes are possible cmdsizes = ( 0,1,1,3,3,1,5,3,3,1,5,23,1,9,25,3, #0x0 9,19,3,9,1,11,5,5,0,0,0,0,0,0,17,25, #0x10 13,5,5,5,5,7,9,9,9,0,9,11,11,25,11,9, #0x20 11,9,21,13,25,23,7,23,25,0,0,0,0,0,0,0, #0x30 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #0x40 7,7,7,7,7,5,7,7,7,7,7,7,7,7,7,7, #0x50 5,7,7,5,5,5,7,7,7,7,7,7,5,1,5,3, #0x60 11,3,3,21,3,3,3,3,3,7,7,5,1,5,3,3, #0x70 3,3,11,7,3,1,3,1,3,9,13,3,3,5,3,3, #0x80 15,3,5,1,1,5,1,11,0,0,0,0,0,0,0,0, #0x90 7,1,5,5,0,0,0,0,0,0,5,5,19,1,1,1, #0xa0 3,3,5,1,5,3,3,3,1,3,3,3,3,3,3,3, #0xb0 3,1,5,3,3,5,5,5,3,1,1,3,5,1,7,1, #0xc0 3,1,3,1,9,3,13,3,5,1,13,0,0,0,0,0, #0xd0 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #0xe0 0,0,0,0,0,0,0,0,0,0,1,5,1,5,3,1, #0xf0 1,1,7,3,1,3,3,5,3,5,5,5,5,3,5,3, #0x100 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #0x110 0,0,0,0,0,0,0,0,0,0,0,0,11,15,17,9, #0x120 3,3,3,5,7,5,5,3,5,7,13,15,3,7,5,7, #0x130 9,3,3,1,5,3,3,13,3,3,15,3,5,13,0,0, #0x140 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #0x150 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #0x160 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #0x170 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #0x180 5,5,5,7,7,7,7,3,7,1,3,1,1,5,5,5, #0x190 19,5,3,3,5,3,5,3,1,3,3,5,7,1,7,7, #0x1a0 7,3,3,1,1,3,3,3,5,5,5,3,1,3,5,1, #0x1b0 3,7,5,5,3,9,5,3,5,7,3,3,3,5,3,3, #0x1c0 7,11,5,11,9,1,5,5,7,5,0,0,0,0,0,0, #0x1d0 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #0x1e0 0,0,0,0,1,1,1,5,9,7,3,17,3,9,11,9, #0x1f0 3,3,11,9,9,13,15,17,7,11,3,15,1,3,1,7, #0x200 3,3,5,7,5,5,5,9,9,9,9,3,1,5,13,15, #0x210 13,9,5,17,1,5,11,13,11,11,7,9,7,11,13,11, #0x220 3,9,9,11,11,11,9,5,3,13,5,15,1,1,5,5, #0x230 9,11,5,1,1,5,5,3,3,7,7,5,5,25,3,21, #0x240 21,25,3,5,11,13,11,11,5,1,3,3,17,7,11,9, #0x250 9,3,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #0x260 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #0x270 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #0x280 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #0x290 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #0x2a0 0,0,0,0,0,0,0,0,0,0,0,0,23,3,3,7, #0x2b0 7,3,13,5,1,5,5,9,9,7,3,3,3,3,3,3, #0x2c0 7,7,7,7,7,5,5,5,7,5,17,3,3,5,5,7, #0x2d0 7,7,7,7,7,3,5,5,3,3,3,3,5,3,3,23, #0x2e0 19,15,13,13,7,9,3,3,5,15,3,3,11,13,0,0, #0x2f0 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #0x300 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #0x310 21,7,9,11,1,5,9,3,7,5,3,1,13,5,23,3, #0x320 5,9,9,11,3,9,11,9,13,15,13,9,5,7,11,7 #0x330 ) # list created manually, may be incomplete # (cmd in oplabels[i]) == (i-th operand of cmd is an offset) oplabels = ( (0x7B,0x8C,0x8F,0xD5), (0x7B,0x8D,0x92,0x95,0xA0,0xA2,0xA3,0xCC,0xCE,0xFB), (0xA0,0xCE,0xD4,0x102), (0xD4,), (0xD6,0x90), (0xD6,0x90), (0x90,), ) with io.open(sys.argv[1], 'rb') as f: header = struct.unpack('<4s4s6I', f.read(0x20)) if header[0] != b'SYS3' and header[0] != b'SYS4': print("invalid signature") sys.exit(1) header2size = struct.unpack('<I', f.read(4))[0] header2 = struct.unpack('<' + str(header2size // 4 - 1) + 'I', f.read(header2size - 4)) data = f.read() # pass 1: prepare labels pos = 0 maxAddr = 0 labels = set() while pos < len(data) // 4: cmd = struct.unpack_from('<I', data, pos * 4)[0] if cmd >= len(cmdsizes) or cmdsizes[cmd] == 0: break for i in xrange((cmdsizes[cmd] - 1) // 2): optype, operand = struct.unpack_from('<ii', data, (pos + 1 + 2 * i) * 4) if i < len(oplabels) and cmd in oplabels[i] and optype == 0 and operand >= 0: labels.add(operand) maxAddr = max(maxAddr, operand) pos += cmdsizes[cmd] if cmd in (1,2,5) and pos > maxAddr: break # pass 2: print print("\theader '%s', %d, %d, %d, %d, %d, %d" % header[1:]) pos = 0 unprintedLabels = labels firstStringOffs, lastStringOffs = -1, -1 firstArrayOffs, lastArrayOffs = -1, -1 messageStarts = [] externalCalls = [] internalCalls = [] while pos < len(data) // 4: if pos in labels: print("loc_%08X:" % pos) unprintedLabels.remove(pos) cmd = struct.unpack_from('<I', data, pos * 4)[0] if cmd >= len(cmdsizes) or cmdsizes[cmd] == 0: print("\t[invalid command 0x%X]" % cmd) break if cmd == 0x71: messageStarts.append(pos) if cmd == 3: externalCalls.append(pos) if cmd == 0x8F: internalCalls.append(pos) cmdsize = cmdsizes[cmd] cmdargs = struct.unpack_from('<' + str(cmdsize - 1) + 'i', data, (pos + 1) * 4) print("\tcmd%03X" % cmd, end='') for i in xrange((cmdsize - 1) // 2): if i: print(",", end='') print(" ", end='') if cmdargs[i * 2] == 0: if i < len(oplabels) and cmd in oplabels[i] and cmdargs[i * 2 + 1] >= 0: print("loc_%08X" % cmdargs[i * 2 + 1], end='') elif cmd == 0x64 and i == 1: # second arg of cmd064 is offset of array in data offs = cmdargs[i * 2 + 1] if lastArrayOffs == -1: firstArrayOffs = offs elif lastArrayOffs != offs: print("[Warning: out-of-order array]"); arrsize = struct.unpack_from('<I', data, offs * 4)[0] arr = struct.unpack_from('<' + str(arrsize) + 'i', data, (offs + 1) * 4) lastArrayOffs = offs + 1 + arrsize print('<', end='') for j in xrange(arrsize): if j: print(",", end='') print('%d' % arr[j], end='') print('>', end='') else: print('%d' % cmdargs[i * 2 + 1], end='') elif cmdargs[i * 2] == 2: offs = cmdargs[i * 2 + 1] * 4 if lastStringOffs == -1: firstStringOffs = offs // 4 elif lastStringOffs != offs // 4: print("[Warning: out-of-order string: %08X instead of %08X]" % (offs // 4, lastStringOffs), end=''); decoded = b'' while True: s = ord(data[offs]) ^ 0xFF if s == 0: break decoded += chr(s) offs += 1 lastStringOffs = (offs + 1) // 4 + 1 print(b'"' + decoded + b'"', end='') else: print('op%X[0x%X]' % (cmdargs[i * 2], cmdargs[i * 2 + 1]), end='') print() pos += cmdsize # command 5 can be a normal command with size=1 or nofollow-command depending on ??? # commands 4,9,0x7C are actually nofollow, but codegen seems to treat them as normal ones if cmd in (1,2,5) and pos > maxAddr: break if len(unprintedLabels): print("Warning: not all labels were printed"); expectedEndAddr = min(len(data) // 4, header2[1], header2[3], header2[5]) if firstArrayOffs != -1: if lastArrayOffs != expectedEndAddr: print("Warning: range [%08X,%08X) was not printed" % (lastArrayOffs, expectedEndAddr)) expectedEndAddr = min(expectedEndAddr, firstArrayOffs) if firstStringOffs != -1: if lastStringOffs != expectedEndAddr: print("Warning: range [%08X,%08X) was not printed" % (lastStringOffs, expectedEndAddr)) expectedEndAddr = min(expectedEndAddr, firstStringOffs) if pos != expectedEndAddr: print("Warning: range [%08X,%08X) was not printed" % (pos, expectedEndAddr)) if messageStarts != list(struct.unpamnakamura
24.04.2016 13:13Интересно. А cmdsizes вы доставали откуда-то из exe-шника?
grechnik
24.04.2016 13:27Да. В движке обработчики команд довольно любезно начинают с того, что выставляют размер команды типа
mov dword ptr [esi+ecx*4+5D804h], 5, так чтопримерно такой скрипт IDAauto a,b,aprev,anext,s,f; f=fopen("c:\\temp\\eushully_vm_cmdsize.txt","w"); for (b=0x415303;b!=BADADDR;b=NextHead(b,0x416713)){ // установка обработчиков: mov dword ptr [esi+0xA4F24+i*4], offset cmd_i if (GetOpType(b,0)!=4) continue; fprintf(f,"0x%X\t",(GetOperandValue(b,0) - 0xA4F24)/4); s=GetOperandValue(b,1); aprev=BADADDR; for (a=s;a!=BADADDR;a=anext){ anext=NextHead(a,BADADDR); if(!isCode(GetFlags(a))){fprintf(f,"[not a code at %X]\n",a);break;} if (GetOpType(a,0) == 4 && GetOperandValue(a,0) == 0x5D804) { if (GetOpType(a,1) == 5)fprintf(f,"%d\n",GetOperandValue(a,1)); else if (GetOpType(a,1) == 1 && GetMnem(aprev) == "mov" && GetOpType(aprev,0) == 1 && GetOperandValue(aprev,0) == GetOperandValue(a,1) && GetOpType(aprev,1) == 5)fprintf(f,"%d\n",GetOperandValue(aprev,1)); else fprintf(f,"[unknown write type at %x]\n",a); break; } // если обнаружили ветвление, на всякий случай выходим if(Rfirst(a)!=anext || Rnext(a,anext)!=BADADDR){a=BADADDR;break;} aprev=a; } if (a==BADADDR) fprintf(f,"[unresolved: %x]\n",s); } fclose(f);mnakamura
24.04.2016 14:28Ох. Это уже как-то неспортивно получается и уже совсем не clean-room, но в целом — почему бы и нет ;)
Я все пытаюсь делать максимально без залезания внутрь, кроме совсем уж тяжких случаев — так и интереснее, и куда ближе к боевым условиям. Ну и банально потому, что есть туча новелл типа под всякие PC98, которые даже запустить негде, не то, что дизассемблировать или дебагать.
А 0x415303 и 0xa4f24 — это в age.exe от какой игры?
grechnik
24.04.2016 14:58У меня в анамнезе слишком много копания в коде, чтобы думать о clean-room, и слишком много программирования, чтобы руками заполнять таблицу, которую может сделать скриптик на десяток строчек кода. Но ваш подход тоже заслуживает внимания.
Тут выше назвали одну конкретную игру, Kami no Rhapsody, это оттуда. Движок версии 4.46.

LoadRunner
14.04.2016 17:10Ну вот, на самом интересном месте.
А то как-то пытался расковырять формат хранения диалогов в одной игре (ресурсы не запакованы), но так ничего и не вышло (нет опыта в реверсе).
Максимум, что выжал — название движка, сайт, где можно его скачать и собственно, триал движка и вроде даже какого-то инструментария. Но он, разумеется, даже не на английском. На этом я остановился и бросил затею.
klirichek
14.04.2016 17:28-1010Editor. Работает без явы. Правда, платный.
mnakamura
15.04.2016 10:52+1Угу. И написать сначала темплейт для него, а потом все переписать по второму разу, уже в виде кода. Собственно, статья ровно про то, что можно так не делать и экономить время и силы.
vit9696
19.04.2016 11:14Выскажусь в защиту предыдущего автора. Новый инструмент достаточно интересный, и мне самому захотелось попробовать, как понадобится разобрать какой-то формат.
Однако я бы не был столь категоричен насчёт 010. Распаковщик можно написать даже в рамках его скриптового языка, и мне приходилось вполне успешно это делать (хотя количество багов что в 010, что в питоновой реализации его шаблонизатора убивает).
Более того, лично мне представление данных в 010 очень удобно, так что уйти от него будет нелегко. Да и много больше времени при разборе формата уходит на алгоритм сжатия, чем на написание небольшого куска кода для i/o. Тем более, что почти всегда это копипаст с других утилит.mnakamura
20.04.2016 08:56К конкретно 010 у меня есть несколько крупных претензий:
- Он закрытый и стоит денег.
- Его язык шаблонов только на первый взгляд декларативный. Думаю, вы как раз знаете, что там шаг влево-шаг вправо — привет, старые добрые циклы
while (!FEof()) { ... }или ручныеReadBytes(...),ReadUInt(...)и т.д. - Как следствие императивности — на любых более-менее больших файлах (гигабайты хотя бы) — 010 превращается в улитку и жрет память, как не в себя. Нельзя даже просто разметить области, не вдаваясь в подробности: приходится искусственно городить в шаблоне некое подобие LOD, только для того, чтобы каждая итерация не занимала по 5-7 минут.
Насчет алгоритма сжатия — с одной стороны соглашусь, с другой — как раз, субъективно, это куда более банальная задача. Алгоритм сжатия особенно нечего угадывать и исследовать — он зачастую выдирается буквально как есть из бинарника, ассемблер транслируется в эквивалентный C, скажем, после чего его можно просто запускать и особенно в нем не копаться.
vit9696
20.04.2016 09:16Стоит порадоваться, что в отличие от конкурентов даже после выжирания гигабайтов памяти он не вылетает и не зависает наглухо. Но претензии по делу, достаточно какого-нибудь скрипта с несколькими миллионами инструкций. Хотя для меня императивность — это особенность/возможность, а не недостаток.
А вот со сжатием — если дело с популярной платформой типа x86, то часто легче выдрать, в консольных же движках подлезть далеко не всегда проще ручного анализа.mnakamura
20.04.2016 10:06отличие от конкурентов даже после выжирания гигабайтов памяти он не вылетает и не зависает наглухо
Данупрям. Вот только что попробовал загрузить свою разбиралку формата VNки 3-летней давности: исходный бинарник 4 гига (под 1 DVD подгоняли), выжрало 16 гигабайт памяти и 8 с чем-то свопа, потормозило минут 15 и умерло.
А вот со сжатием — если дело с популярной платформой типа x86, то часто легче выдрать, в консольных же движках подлезть далеко не всегда проще ручного анализа.
radare чудесно делает из фактически кода любой платформы C-подобный код, который минимально надо обработать напильником и можно хоть в C, хоть в Java, хоть в JavaScript.
vit9696
20.04.2016 10:44Допускаю, хотя 24 гига всего на 1 DVD — я бы задумался, а как оно написано. Однако тот же нео или синалайзис, которые являлись прямыми (и чуть ли не единственными) конкурентами, вылетят много раньше.
Лукавство лукавством, но как реверсер вы должны понимать, что сложность не столько в декомпиляторах, сколько в возможности подобраться к функции распаковки, начиная с возможности чтения бинарника вообще. Отладчика может не быть, а XREF-ы на библиотеки не находиться.
Впрочем, мы по-моему отошли от темы, к предложенному инструменту конкуренты не относятся; спасибо за дискуссию.mnakamura
21.04.2016 02:41Да ответ, в общем, простой: все эти штуки создают разметку не on demand, а сразу проходя всё. При том, что в реальности читающая процедура делает не так: ей незачем загружать в память (и тем более распаковывать сразу) все содержимое DVD, она зачитает три с половиной нужных прямо сейчас файла, остальное зачитает, когда будет нужно.
Впрочем, мы по-моему отошли от темы, к предложенному инструменту конкуренты не относятся; спасибо за дискуссию.
Вполне интересная тема, я на такие могу часами разговаривать :) На одном небезызвестном сайте, обсуждая эту статью, сейчас подкинули новую интересную задачку — я уже второй вечер над ней голову ломаю. Пока заткнулся на том, что есть 16-байтовые строчки, из которой надо извлечь позицию и размер файла в архиве. Еще пару вечеров помедитирую, а потом, наверное, сдамся, и перейду на тяжелую артиллерию типа Olly или IDA.
Daytar
21.04.2016 13:00+1radare чудесно делает из фактически кода любой платформы C-подобный код, который минимально надо обработать напильником и можно хоть в C, хоть в Java, хоть в JavaScript.
Не поделитесь как от r2 получить такой C-подобный код?

gena_glot
14.04.2016 17:44-3Мне все это напомнило " бесконечное лето", очень популярную игру, причем популярную у очень странных и смешных людей
Squoworode
15.04.2016 10:23+1«Бесконечное лето» — визуалка, написанная странным людьми для странных людей под впечатлением от качественных японских визуалок.

Yuuri
14.04.2016 18:03+3Это офигительно. Хорошие статьи про реверс-инженеринг читаются как технодетектив. А есть ли в природе контесты с подобными заданиями «расковырять непонятно что»?
Daytar
14.04.2016 18:07+1Да берёте любой бинарь и в путь, не? Правда расковыривать те же исполняемые файлы — это вам не парсить простенький не зашифрованный и даже не сжатый том с обычными файлами.
poddav
14.04.2016 20:21+1для распаковки архивов т.н. «визуальных новелл» есть несколько инструментов, например, вот этот. в нём, правда, нет функциональности для описания неизвестных форматов по типу kaitai, но всё же список известных довольно обширен, в частности, есть и поддержка Yuka (движок, описанный в заметке).
mnakamura
15.04.2016 10:57+1Их, на самом деле много, если интересно. Из больших есть Crass, есть [vn-tools](https://github.com/vn-tools/arc_unpacker/), есть [ae](http://wks.arai-kibou.ru/ae.php), есть приснопамятный ExtractData (автора которого засудили). Я на самом деле ковыряю визуальные новеллы уже довольно давно (примерно как переехал сюда и начал язык учить) — у меня внушительная коллекция собралась.
ComradeAndrew
15.04.2016 12:00примерно как переехал сюда и начал язык учить
Т.е. вы переехали в Японию. Я правильно понял? А с какой целью и чем занимаетесь, если не секрет?
В статье вы, кажется, не упоминали.mnakamura
15.04.2016 12:31+1Правильно. В статье не упоминал, потому что статья все-таки не про меня, да и я относительно шифруюсь. Как показала ситуация с minori и ExtractData — местные копирасты весьма агрессивно относятся к тому, что продаваемые в их магазинах визуальные новеллы распаковывают. Если читаете по-японски — то http://mitiku3.jugem.jp/?eid=5959 — автор ExtractData вроде бы до сих пор settlement им выплачивает, ему что-то в районе 2 миллионов йен выкатили.
А с какой целью и чем занимаетесь, если не секрет?
Конечно же, скупить все фигурки на Акихабаре (*•??•?*)
А если серьезно — ну, нравится мне страна, нравится культура. Сакура-но-кайка вон неделю назад буквально закончилась.
А так все примерно как у 90% уезжающих: минимально выучил язык по аниме, сдал на JLPT n4, поступил учиться, за год освоился, в итоге остался. Живу, работаю. Компанию, наверное, напрямую писать от греха подальше не буду, но, с другой стороны гуглится это все за две минуты.ComradeAndrew
15.04.2016 13:40minori и ExtractData — местные копирасты весьма агрессивно относятся к тому, что продаваемые в их магазинах визуальные новеллы распаковывают. Если читаете по-японски — то http://mitiku3.jugem.jp/?eid=5959 — автор ExtractData вроде бы до сих пор settlement им выплачивает, ему что-то в районе 2 миллионов йен выкатили.
По-японски к сожалению не читаю. Но то, что жестко относятся к ковыряниям продуктов — тут бы и я не сильно-то распространялся про себя, в таком случае.
Любопытно. Чтож, успехов вам :)
P.S. И большое спасибо за статью. Хорошая статья про реверс инженеринг — это большая редкость.
veshurik
16.04.2016 18:20О, как интересно… Не планируете работать в эроге-компаниях программистом, к случаю? :)
Хотя я думаю, они там и без вас свои движки вовсю клепать будут.mnakamura
17.04.2016 03:44+1Не планирую, а зачем? В год выпускается, наверное, несколько тысяч VNок. На ту же vndb, по ощущениям, попадает процентов 60-70. «Эроге-компании», как вы их назвали — зачастую полтора человека (сценарист и иногда художник). Большая часть выпускающегося — демки и всякие пробы пера новичков — далеко они не уходят. Денег там платят весьма скромно, особенно если ты не сценарист, а программист на день-два фриланса.
Эдак с половина индустрии лицензирует так или иначе kirikiri, вторая половина пишет свое. Как правило, по одной из двух причин: либо требование издателя, либо некий юношеский максимализм и гордость не позволяют освоить готовое, а хочется обязательно написать свое. У мейджоров, опять же, как правило свои уже готовые и десятилетиями отлаженные решения.
Написание движков — по большому счету, относительно простой и нудный процесс. Каких-то программистских сверхзадач там нет, все весьма рутинно: загрузи картинки-музыку-звук-шрифты-текст да показывай/запускай их в нужном порядке. Встроенные минигеймы, если они и есть, опять же, обычно в лучшем случае добавляют к вышеописанному чуть более сложную математику и все.
В общем, не, не нужны там программисты. Там творческие люди нужны, а из меня писатель никакой, тем более на японском.

CodeRush
15.04.2016 22:56Спасибо автору за отличное введение в KS, а тов. GreyCat за саму утилиту. Надо будет взять на вооружение, а то я так и продолжаю хранить все форматы в виде С-стуруктур и комментариев к ним, а парсеры писать вручную (вкривь и вкось).
mnakamura
17.04.2016 03:04+1Пожалуйста :) Будем надеяться, раскачаюсь на еще туториалы по реверсингу.

Dimano
Хороший инструмент. Помню нам один из поставщиков, присылал документы в формате frp (20-30 листов ежемесячно). Нам из него надо было вытащить таблицы для дальнейшей работы. Программа designfr умеет конвертировать frp в разные форматы, но если в поле таблицы есть перенос строки, то при конверте всё ломается, часть поля может встать выше или ниже, вариантов много. Вначале конвертированный файл исправлялся с помощью регулярок (шутка по 99 проблем), но со временем число вариантов росло, и добавлялся ручной труд по вычистке. Следующей идеей было парсить frp файл самостоятельно, и вытаскивать оттуда таблицу, но это очень трудозатратно. Остановился на промежуточном варианте, склеивая поля с переносами, соответственно корректируя размер документа, страницы и разные смещения, а после чего штатными средствами конвертируя. Писал скрипт на PowerShell с «магическими цифрами» смещений. Поставщик теперь уже сменился.