 Продолжаем нашу серию статей про то, как влезть во внутренности игровых движков и вытаскивать из них всевозможное содержимое. Для тех, кто к нам только что присоединился, коротко напомню, что мы изучали такой забавный жанр, как визуальные новеллы.
Продолжаем нашу серию статей про то, как влезть во внутренности игровых движков и вытаскивать из них всевозможное содержимое. Для тех, кто к нам только что присоединился, коротко напомню, что мы изучали такой забавный жанр, как визуальные новеллы.
Прошло уже много времени с момента того, как мы научились разбирать архивы движка визуальных новелл Yuka, настало время взяться за самое интересное из того, что мы там нашли — собственно, скрипт. Забегая чуть-чуть вперед, сразу предупрежу, что скрипт, конечно, куда более сложная материя, чем просто архив с файлами, поэтому за одну статью нам с ним не разобраться, но сегодня мы попытаемся понять, из каких частей он состоит и получим доступ к текстовым ресурсам.
Перед тем, как погружаться в пучины бинарных дампов, давайте прикинем, как работают большинство движков визуальных новелл. Визуальная новелла сама по себе состоит из текста (реплик героев, диалогов, промежуточного повествования), графики и звуков. Для того, чтобы ее воспроизвести пользователю, явно нужно свести все это воедино с помощью какого-то управляющего воздействия. В теории можно было бы зашить это все прямо в exe-файл, но в 99% случаев (ладно, вру, в 100% виденных лично мной) так все-таки не делают, а хранят такие инструкции отдельно в виде отдельной программы-скрипта. Как правило, скрипт пишется на особенном языке программирования (специфичном для движка), который выглядит как-то так:
$ tarot = 0
$ memory = 0
scene bg01_1 with dissolve
play music "bgm/8.mp3" fadein (2.0)
play ambience "amb/forest.mp3" fadein (3.0)
"Morning."
"Not my favourite time of the day."
"The morning is when you're not awake enough to do anything..."Это фрагмент исходника скрипта из одной VN на Ren'Py — одном из наиболее популярных свободных/бесплатных движков. Оставляя за рамками этой статьи вопрос, насколько хорош Ren'Py сам по себе, просто пока отметим, что же обычно входит в скрипт визуальной новеллы и что нам нужно будет найти:
- текст — он еще бывает либо не приписан никакому персонажу (т.е. текст "от рассказчика" — как в нашем примере), либо таки произносится кем-то
- команды, чтобы показать графику — бэкграунд / спрайт (
scene bg01_1), иногда с каким-то спецэффектом (with dissolve) - команды, чтобы запустить играться музыку или звуки (
play music,play ambience), иногда тоже с какими-то дополнительными параметрами, чаще всего длинами fade-in и fade-out (плавного нарастания громкости) - работа с переменными: установка (
$ tarot = 0, проверка, ветвление) еще бывают команды:
- для воспроизведения произносимой героями речи
- для управления
- служебные штуки типа комментариев, меток, макросов
Разумеется, в реальном мире зачастую у нас не будет доступа к исходному коду скрипта. Люди уже лет 50 как научились писать компиляторы (в противовес интерпретаторам), поэтому обычно исходник скрипта компилируется в некий бинарный код (байт-код), который затем исполняется виртуальной машиной внутри движка визуальной новеллы. Иногда везет и для некоторых популярных движков есть легально или не очень легально доступные инструменты — отладчики, компиляторы, декомпиляторы, валидаторы скриптов и т.д, но чаще жизнь не бывает столь простой.
Итак, возвращаемся к нашей визуальной новелле, которую мы начали исследовать в прошлой статье — Koisuru Shimai no Rokujuso. Мы уже распаковали ее архивы и нашли внутри и графику, и звуки, и музыку, и, самое главное и непонятное пока — кучку файлов с расширением .yks. Предположительно, они и составляют скрипт новеллы. Файлов, кстати, много:
YKS/ScriptStart.yks
YKS/trial/Yoyaku.yks
YKS/trial/trial_00100.yks
YKS/trial/trial_00200.yks
YKS/all/all_00010.yks
...
YKS/all/all_02320.yksВсего 103 файла в YKS/all/. Напомню, мы абсолютно честно скачали и исследуем триальную версию — но, судя по всему, разработчики несколько поленились и, видимо, в trial/ лежит скрипт для триальной версии, а в all/ — для полной.
Вообще, исходя из минимального опыта, у строителей движков визуальных новелл есть 2 подхода: либо все пакуется в один гигантский файл, либо файлов много и в каждом из них какая-то своя сцена или событие. Тут похоже, что второе. Кроме того, есть еще отдельный ScriptStart.yks — но он как таковой скорее всего будет нам практически неинтересен: дело в том, что зачастую разработчики хотят сделать движок как можно более универсальным и реализуют всякие пользовательские интерфейсы, менюшки-загрузки-сохранения-опции и т.д. тоже средствами своего скриптового языка. Разбираться с этим можно, но довольно скучно и неплодотворно: поэтому предлагаю брать быка за рога и начинать с собственно сценария игры.
Что мы можем сказать из поверхностного визуального осмотра? Во-первых, т.к. игра работает под Windows, то ее вполне реально запустить и посмотреть, как это выглядит. Тратим n-ное количество времени, находим машину с Windows, запускаем, смотрим, что происходит сразу после нажатия кнопки начала новой игры:

Нас встречает вроде бы начало повествования. Здесь есть фон (после недолгих поисков в BG/ находится файл bg01_01.png с этим фоном), и есть текст. Этот текст нам еще понадобится, поэтому стоит его перенабрать с экрана:
????????????????????Ver2????????????????????Два замечания:
Если есть проблемы с набиранием японского текста, могу порекомендовать освоить три-четыре приема, которые сильно упрощают это дело и при определенном терпении дают возможность набирать японские тексты тем, кто абсолютно не представляет, что же это за закорючки. Каждый значок рассматриваем по отдельности:
- проверяем, не знак ли это препинания по такой таблице: ?…??()? — если повезло, то копируем; обратите внимание на то, что и "запятые", и "точки", и скобочки тут специфичные.
- если нет, ищем в вот такой таблице: ?????????????????????????????????????????????
- потом ищем еще по вот такой: ????????????????????????????????????????????
- если не помогло — например, попался ? — то это kanji; тогда увеличиваем шрифт на 300-500%, чтобы было хорошо видно все мелкие детали и идем на jisho.org в раздел "поиск по радикалам"; там смотрим на таблицу составных частей (радикалов) и ищем похожие на то, что видим; на примере ? — после недолгой медитации находим, что снизу у него составная часть ? — зажимаем кнопку с этой составной частью и от многих тысяч у нас остается всего пара десятков значков; просматриваем их глазами и находим в выдаче в разделе "10" пятый с начала знак — это и будет искомый ?.
- Я не уверен, будет ли там Ver2 или Ver2 — обратите внимание, это не разные шрифты, а внезапно так называемые full-width characters — в юникоде они где-то в районе U+FF01..U+FF5E).
Текст нужен нам будет для двух вещей. Во-первых, собственно как текст — понять, что происходит (даже если не владеете японским — можно вставить в гугл-переводчик и понять, что нас здесь благодарят за скачивание триальной-версии этой игры => т.е. это еще не реальное начало сюжета, а некое вступление, "от автора"). Во-вторых, этот текст или его кусочек мы можем взять, сконвертировать в ShiftJIS (а скорее всего, как мы выяснили в предыдущей заметке, все будет именно в этой кодировке) и поискать его в файлах. Возьмем кусочек с конца и подготовим то, что будем искать:
$ echo '??????????????????' | iconv -t sjis | hd
00000000 83 5f 83 45 83 93 83 8d 81 5b 83 68 92 b8 82 ab |._.E.....[.h....|
00000010 82 a0 82 e8 82 aa 82 c6 82 a4 82 b2 82 b4 82 a2 |................|
00000020 82 dc 82 b7 |....|Ищем эту строчку в во всех наших файлах .yks и, разумеется, не находим. Не так все просто.
Сделаем еще одно лирическое отступление: давайте ознакомимся с тем, как работает кодировка ShiftJIS. В японском языке, очевидно, значков сильно больше, чем в европейских: в ShiftJIS каждый из значков кодируется минимум 1 байтом, максимум 2. Как видно из этой таблички, значения байтов 00..7F совпадают с ASCII, а вот байты 81..9F и E0..EA означают, что это двухбайтовая комбинация, причем для совместимости опять же с бинарным чтением, второй байт будет иметь не какое угодно значение, а что-то между 40 и FF.
Микроэкскурс в японский язык: в языке используются 3 группы значков:
- hiragana — выглядит как-то так: ?????????? — т.е. округлые простые письменные формы; ~50 значков, но есть всякие вариации типа "большая i = ?, маленькая i = ?"; 1 слог = 1 знак.
- katakana — выглядит как-то так: ?????? — т.е. рублено-квадратные, простые печатные формы; звуки все примерно те же, что и изображаются hiragana, но используется для записи преимущественно заимствованных слов (?????? = da-u-n-lo:-do = download).
- kanji — выглядят как-то так: ??? — т.е. как правило, сложные квадратные конструкции из кучи разных частей и загогулек; с ними сложнее всего, вот как раз их много тысяч.
Плюс есть еще знаки препинания, плюс-минус такие же, как в европейских языках: точка ?, запятая ?, многоточие …, кавычки ??, восклицательный и вопросительный знаки и т.п. А вот пробелов обычно нет. Фокус в том, что в тексте постоянно чередуются "важные" слова, которые записываются kanji и частицы, которые записываются hiragana, в результате чего получается эту смесь хоть как-то можно разобрать. Например, возьмем название игры ?????????:
- ? — kanji
- ?? — hiragana
- ?? — kanji
- ? — hiragana
- ??? — kanji
Что это дает нам в сухом остатке? Очень просто: частотную таблицу. Берем готовый скрипт первой попавшейся под руку визуальной новеллы на японском, быстренько подсматриваем в юникоде границы диапазонов всех трех групп и прогоняем на нем такой скрипт (простите за каламбур):
stats = {}
$stdin.each_char { |c|
t = case c.ord
when 0x3041..0x309F then :hiragana
when 0x30A0..0x30FF then :katakana
when 0x4E00..0x9FCC then :kanji
end
stats[t] ||= 0
stats[t] += 1
}
p statsи получаем на выходе что-то вроде:
{nil=>72384, :kanji=>5731, :hiragana=>15377, :katakana=>2241}т.е. в типичном тексте будет ~25% kanji, 65% hiragana и 10% katakana.
Кажется, время расчехлять инструменты и погружаться с головой в работу. Совсем кратко напомню, что мы используем для анализа бинарных файлов с непонятной структурой новый open source инструмент Kaitai Struct — он позволяет описывать на языке разметки шаблоны, которые потом можно применять к файлам и быстро визуализировать их содержимое, разложенное по полочкам в виде дерева, а в качестве мега-бонуса потом — скомпилировать шаблон прямо в исходник на фактически любом популярном языке программирования (с момента написания предыдущей статьи Kaitai Struct стал поддерживать не только Java, JavaScript, Python и Ruby, но и C++, C#, Perl и PHP). То есть если смотреть по всяким спискам top-языков — топ 10 охвачен полностью, из топа 20, если не брать domain-specific вещи, не хватает Delphi, Visual Basic (хотя я слабо себе представляю, чтобы кто-то занимался реверс-инжинирингом на древнем Visual Basic не .NET), Swift и Go.
Базовый синтаксис шаблонов Kaitai Struct мы изучили в первой части статьи, поэтому, кто пропустил / подзабыл о чем речь — самое время с ним ознакомиться / освежить в памяти.
Итак, быстро смотрим на дампы 3-4 файлов и понимаем, что в качестве отправной точки нам подойдет такой шаблон:
meta:
id: yks
application: Yuka Engine
endian: le
seq:
- id: magic
contents: ["YKS001", 1, 0]
- id: magic2
contents: [0x30, 0, 0, 0, 0, 0, 0, 0, 0x30, 0, 0, 0]
- id: unknown1
type: u4
- id: unknown2
type: u4
- id: unknown3
type: u4
- id: unknown4
type: u4
- id: unknown5
type: u4
- id: unknown6
type: u4
- id: unknown7
type: u4Можно сразу провести аналогии с форматом YKC. Т.к. там в начале шло описание "заголовка", начиная с его длины, то с большой вероятностью фиксированные 0x30, встречающиеся в magic2 везде — это длина первоначального заголовка, поэтому предлагаю зачитывать сразу все до 0x30. Получается 7 чисел, сейчас будет пытаться угадывать, что это такое.
Для Yoyaku.yks (сам файл 27741 байт):
[.] @unknown1 = 1845
[.] @unknown2 = 7428
[.] @unknown3 = 795
[.] @unknown4 = 20148
[.] @unknown5 = 7593
[.] @unknown6 = 25
[.] @unknown7 = 0Для trial_00100.yks (файл 91267 байт):
[.] @unknown1 = 6433
[.] @unknown2 = 25780
[.] @unknown3 = 2376
[.] @unknown4 = 63796
[.] @unknown5 = 27471
[.] @unknown6 = 5
[.] @unknown7 = 0И, для сравнения, какой-нибудь файл из all, например all_00010.yks (12968 байт):
[.] @unknown1 = 933
[.] @unknown2 = 3780
[.] @unknown3 = 353
[.] @unknown4 = 9428
[.] @unknown5 = 3540
[.] @unknown6 = 1
[.] @unknown7 = 0Что видно? Во-первых, это все эпично похоже на смещения или размеры в файле, т.к. при размере файла в 91K числа плавают в районе 25-63K, а при размере в 12K — в районе 3-9K. При ближайшем рассмотрении, смещения и размеры скорее всего только unknown2, unknown4, unknown5 — они делятся на 4 и достаточно большие. Во-вторых, unknown7, кажется, всегда 0. В-третьих, unknown6, видимо, задает что-то очень штучно-считаемое. Это может быть, например, размер области зарезервированной памяти виртуальной машины под переменные, число сменяющихся сцен/спрайтов/бэкграундов или еще что-нибудь такое.
Сразу за 0x30 даже невооруженным глазом в людом хекс-редакторе видна таблица возрастающих (или почти всегда возрастающих чисел). Вряд ли это сам байт-код: для байт-кода характерно как раз постоянное повторение одних и тех же последовательностей. Это тоже скорее всего какие-нибудь смещения — например, это могут быть смещения, определяющие начала команд в байт-коде, или какие-нибудь начала-концы строк переменной длины или что-нибудь еще такое. У нас есть 7 unknown-значений, это не так много — давайте переберем и посмотрим, похоже ли одно из них:
- либо на длину этого участка
- либо на абсолютное смещение конца этого участка = начала нового
- либо на количество 4-байтовых целых чисел в участке
Практически первая же попытка подходит очень неплохо: unknown1 оказывается количеством элементов в этом разделе, а unknown2 оказывается указателем на начало следующего раздела. И, таким образом, похоже, что на практике unknown2 = 0x30 + unknown1 * 4. Добавляем сразу описание, заодно перенеся заголов в явно выделенный тип header, а открываемые секции начинаем называть sect1..sectX:
seq:
- id: header
type: header
- id: sect1
size: header.sect2_ofs - 0x30
type: sect1
types:
header:
seq:
- id: magic
contents: ["YKS001", 1, 0]
- id: magic2
contents: [0x30, 0, 0, 0, 0, 0, 0, 0, 0x30, 0, 0, 0]
- id: sect1_qty
type: u4
- id: sect2_ofs
type: u4
- id: unknown3
type: u4
- id: unknown4
type: u4
- id: unknown5
type: u4
- id: unknown6
type: u4
- id: unknown7
type: u4
sect1:
seq:
- id: entries
type: u4
repeat: expr
repeat-expr: _root.header.sect1_qtyВ итоге trial_00100 начинает выглядеть вот так:
[-] @header
[.] @magic = 59 4b 53 30 30 31 01 00
[.] @magic2 = 30 00 00 00 00 00 00 00 30 00 00 00
[.] @sect1_qty = 6433
[.] @sect2_ofs = 25780
[.] @unknown3 = 2376
[.] @unknown4 = 63796
[.] @unknown5 = 27471
[.] @unknown6 = 5
[.] @unknown7 = 0
[-] @sect1
[-] @entries (6433 = 0x1921 entries)
[.] 0 = 6
[.] 1 = 7
[.] 2 = 3
[.] 3 = 3
[.] 4 = 4
...
[.] 6425 = 2371
[.] 6426 = 2372
[.] 6427 = 34
[.] 6428 = 1
[.] 6429 = 2373
[.] 6430 = 2374
[.] 6431 = 1
[.] 6432 = 2375На самом деле теперь уже заметно, что это не просто возрастающие значения — это вполне может быть байткодом. В этом файле заметные возрастающие числа идут, видимо, от 0 или 1 и в итоге увеличиваются до 2375. Внезапно, unknown3 = 2376 — очень похоже на число этих самых значений. Т.е. байткод ссылается на еще одну какую-то таблицу, в которой 2376 различных значений (видимо, от 0 до 2375 включительно). Что же это может быть?
Смотрим на следующую секцию, просмотрев что там бывает на экрана 3-4 вперед:

По-моему, более-менее очевидно, что это записи по 16 байт (1 строчку) длиной, причем в них есть опять же что-то поразительно похожее на явно постоянно неравномерно увеличивающиеся смещения или индексы. Будет ли таких записей 2376? Проверяем, переименовая unknown3 в sect2_qty и добавляя тривиальный кусочек, чтобы собрать sect2 из 16-байтовых записей:
- id: sect2
size: 16
repeat: expr
repeat-expr: header.sect2_qtyи, кажется, бинго, это оно и очень точно:

Невооруженным глазом хорошо видно, что эти самые стройные 16-байтовые записи действительно кончаются ровно после sect2_qty штук и дальше начинается уже что-то совсем другое. Что мы тут видим? Это явно не длинные 4-байтовые числа, примерно все ненулевое. Какой-то явно периодической структуры тоже не прослеживается, по крайней мере на первый взгляд. Обилие 0xaa. Много 0x28, чередующихся через раз. Смотрим в конец файла, пытаясь обнаружить еще какие-то секции — кажется, нет, в конце примерно такая же фактура:
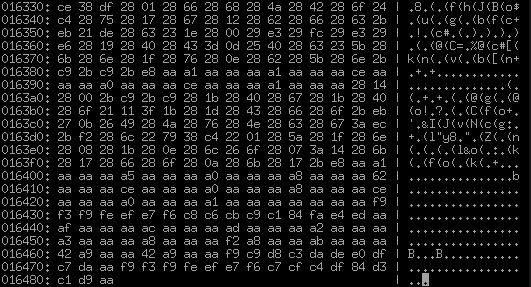
То есть это третья и последняя секция файла, больше в нем ничего не будет. А что мы еще не видели? Текст и строчки. Видимо, это они и есть, но явно как-то покодированные. Сжатые? Нет, не похоже. Такого количества повторяющихся 0x28 и 0xaa не было бы. Да и повторяющиеся 0x28 во всяких там 28 08 28 1b 28 0e 28 6c 26 6f 28 07 3a 14 28 6b выглядят страшно подозрительно. Для сравнения, вспомним, как выглядит в ShiftJIS среднестатистический японский текст: 82 a0 82 e8 82 aa 82 c6 82 a4 82 b2 82 b4 82 a2. Сразу же напрашивается гипотеза, что это простейший подстановочный шифр, где каждый байт преобразуется всегда в один и тот же другой байт. Что это может быть, как получить из 0x82 => 0x28? Человечество придумало на самом деле не так много вариантов:
- сложение/вычитание — прибавить (или вычесть, что одно и то же) к каждому байту одно и то же число, переполнение просто не учитывать
- rol/ror — циклический сдвиг на какое-то число бит, в самом тупом варианте делается сдвиг ровно на 4 бита вправо или влево меняет 2 шестнадцатеричные цифры местами
- исключающее "или" (xor) — с каждым байтом проделать операцию xor с каким-то другим, фиксированным байтом; один из самых тупых, банальных, как-то действующих и посему популярных способов
Вообще есть даже "тяжелая" артиллерия в виде программ типа XORSearch, которые пытаются угадывать такие преобразования перебором, но тут все еще банальнее и у меня получается угадать со второго раза. Обилие 0xaa позволяет предположить, что там много нулей, которые XOR'ятся с 0xaa, что дает 0xaa. А внезапно 0x82 ^ 0xaa как раз равно 0x28. 0xaa — вообще одно из самых банальных предположений, которые стоит проверять по хорошему в первую очередь, т.к. 0xaa = 0b10101010, т.е. xor с ним тупо переворачивает каждый второй бит.
К счастью, в Kaitai Struct есть встроенная поддержка таких преобразований, активизируется через process:. Достаточно написать вот так:
- id: sect3
size-eos: true
process: xor(0xaa)после чего мы, наконец, сможем наблюдать богатый внутренний мир строковых констант наших подопечных скриптов:
000000: 69 66 00 c8 00 00 00 47 6c 6f 62 61 6c 46 6c 61 | if.....GlobalFla
000010: 67 00 3d 00 ff ff 00 00 01 00 00 00 3d 00 7b 00 | g.=.........=.{.
000020: 0d 00 00 00 57 69 6e 64 6f 77 4e 61 6d 65 53 65 | ....WindowNameSe
000030: 74 00 97 f6 82 b7 82 e9 8e 6f 96 85 82 cc 98 5a | t........o.....Z
000040: 8f 64 91 74 28 83 66 83 6f 83 62 83 4f 29 81 7c | .d.t(.f.o.b.O).|
000050: 46 69 6c 65 20 3a 20 74 72 69 61 6c 68 5f 6d 61 | File : trialh_ma
000060: 79 75 2e 79 6b 73 00 7d 00 09 00 00 00 44 72 61 | yu.yks.}.....Dra
000070: 77 53 74 6f 70 00 47 72 61 70 68 69 63 48 69 64 | wStop.GraphicHid
000080: 65 00 0a 00 00 00 54 72 61 6e 73 69 74 69 6f 6e | e.....Transition
000090: 00 02 00 00 00 64 00 00 00 0a 00 00 00 0b 00 00 | .....d..........
0000a0: 00 47 72 61 70 68 69 63 4c 6f 61 64 00 00 00 00 | .GraphicLoad....К счастью, там кроме всего прочего есть туча ASCII-строчек, что сильно упрощает жизнь. На первый взгляд кажется, что это просто C-style строчки, терминированные нулями, но при более внимательном рассмотрении оказывается, что это не совсем так. Тут есть и строчки, и всякая непонятные вкрапления констант, например: ff ff 00 00 01 00 00 00, или 02 00 00 00 64 00 00 00 0a 00 00 00 0b 00 00 00, которые, несмотря на наличие одного печатного ASCII-символа в центре (d = 0x64) скорее всего строчками не являются. Кроме того, что самое ценное — вот они — эти самые строчки на японском в ShiftJIS с 82.
Подытожим, что у нас получилось:
- sect1, состоящий из 4-байтовых целых чисел (предположительно это и есть байткод), частично ссылающийся этими числами на 16-байтовые записи в sect2
- sect2, состоящий из 16-байтовых записей с возрастающими числами внутри (предположительно — какие-то смещения)
- sect3, состоящий преимущественно из null-terminated строчек в ShiftJIS, но не совсем (предположительно — строковые ресурсы и всякие другие константы, на которые ссылается байткод)
На этой маленькой победе, думаю, мы завершим наши сегодняшние изыскания, так как статья очередной раз получается неприлично большой. В какой-то степени — если, например, стоит задача перевести визуальную новеллу — достигнутого сегодня уже достаточно для того, чтобы выдрать тексты и отдать их переводчикам. Берем sect3, находим в ней все, что похоже на SJIS, аккуратно выбрасываем все остальное — вуаля:
?????????(????)-File : trialh_mayu.yks
??
????……!!?
????????????????????????????????!!
???……??????……?
????????????????????????????
?????????????????……???????????????????????
????……?Спасибо всем, кто дочитал до этого места. В следующий раз мы доберемся до собственно байткода и попытаемся понять, как устроены sect1 и sect2. До встречи!
Комментарии (32)

LoadRunner
07.09.2016 15:30+5Неужели единственная причина прервать на самом интересном месте — это отмазка «статья слишком длинная»?
Такие статьи по реверсу читаются лучше, чем детективы. А тут бац! — и кто убийца, пока непонятно.
mnakamura
07.09.2016 15:38+3Написание этой статьи я долго откладывал, потом долго писал ;) У меня сейчас уже написано текста примерно в 2.5 раза больше, чем тут опубликовано — и это совсем не конец исследования. Относительно легко понять, что такое sect1 и sect2, но когда дойдет до опкодов — дальше там идет кротопливая и требующая определенных знаний и доли интуиции работа по определению, что же есть что.
Сначала я хотел таки дописать ее до самого конца, но, к счастью, ряд товарищей, постоянно пинающих меня в стиле "обещал аж в апреле, а когда же уже будет продолжение" — отговорили от этой идеи, посоветовав опубликовать то, что уже есть в формате "по частям". И, наверное, это хорошо — а то оно бы мариновалось еще пару-тройку месяцев. А то бы и вообще сгинуло...
LoadRunner
07.09.2016 15:47что же есть что
Прочитал как «что жесть это».
Ну а вообще, я так и подумал, что дальше начинается такой экшочник, что его быстро не осилить и лучше опубликовать хотя бы то, что уже есть и мотивироваться закончить начатое.
Считайте, что я тоже Вас пинаю на продолжение.mnakamura
07.09.2016 15:56+1Дело не в быстро/не быстро, дело в том, что специально приходится себя заставлять обдумывать каждый шаг и описывать его. Можете посмотреть у меня на гитхабе — там выложена часть моих наработок по другим движкам — для не очень сложных байткодов современных VN у меня типично уходит пара-тройка вечеров, чтобы в них разобраться. А тут — такой долгострой на полгода — именно потому, что после того, как разберешься — пытаешься осознать и понять, как ты при этом размышлял, какова была логическая цепочка, которая привела к успеху и какие из ложных следов стоит упомянуть, если вообще какие-то стоит.
В общем, да, очень похоже на детектив и, да, спасибо за пинание :)
LoadRunner
07.09.2016 16:15Прекрасно понимаю это состояние. Сам статью уже больше года пилю именно из-за попыток описать весь процесс от и до. Тем более, что сам не знаю, каков же финал.
И под «экшончик, который быстро не осилить» в большей степени подразумевал: «блин, как теперь мысли грамотно и доступно изложить в письменной форме?». Они же скачут и торопятся, а ты им: «Эй, ребята, стоп! Помедленнее, я записываю.». А азарт и успехи подгоняют, скучно топтаться на месте, хочется двигаться дальше.mnakamura
08.09.2016 03:28Ну да, все так :) А что делаете и про что статью пишете, если не секрет?
LoadRunner
08.09.2016 06:25Не секрет. Статья о судоку — нахождение уникальных раскладов, алгоритм генерации, решения.

ValdikSS
07.09.2016 20:40+1Риточка тут почти сделала новую новеллу «Love, Money, Rock`n`Roll», выйдет в конце года.
http://sovietgames.su/love-money-rocknroll/mnakamura
08.09.2016 03:25Да я как-то равнодушно отношусь к русскоязычным новеллам. Практически все, что я видел, каких-то особых чувств во мне не вызвали.


las68
08.09.2016 08:48+2Вот тема, вроде бы, для меня лично, совершенно лишняя, но как описан процесс! Читаю с удовольствием. Парни, вы, молодцы!
mnakamura
08.09.2016 08:52Да мне самому процесс нравится — зачастую даже больше, чем результат :) Можно разбирать какие-нибудь сетевые протоколы, malware, а можно — всякие продукты игровой индустрии. Первого мне на работе хватает, а второе, на мой вкус, куда интереснее :)
las68
08.09.2016 09:08Было дело, разбирал на заре туманной юности SPX и рисовал его конечный автомат. Отличное занятие.

RZK333
08.09.2016 18:56тогда увеличиваем шрифт на 300-500%, чтобы было хорошо видно все мелкие детали и идем на jisho.org в раздел «поиск по радикалам»;
идем на google translate, нажимаем рукописный ввод, рисуем, получаем список, выбираем верный вариант, profit.las68
08.09.2016 19:07вы ограничиваете себя в удовольствии. процесс важен.
RZK333
09.09.2016 13:07процесс рисования в правильном порядке > процесс выбирания радикалов.
alsii
09.09.2016 17:02А в чем проблема в использрвании словаря? Ключей не так уж и много, они обычно утпорядочены по числу черт. После некоторого количества упражнений вычленяются в знаке и находятся в таблице практически автоматически. Под ключом знаки тоже расположены по количеству черт. Правда меня смутило, что ? попал в раздел 10. Десять — это общее количество черт в этом знаке, а разделы нумеруются обычно по количеству черт дополнительных к ключу, по крайней мере в китайских словарях. Так что я бы его искал в разделе 6. Единственная засада, это научиться правильно считать черты.
RZK333
09.09.2016 17:33проблемы нет и я не писал что она есть.
mnakamura
10.09.2016 01:14окей, окей, господа правильные японисты, не задерживаемся, проходим :)
мы тут немножко ересью занимаемся, а уж посмотреть, как я попытался объяснить про строение японских текстов — меня за такое на костре сжечь надо...
mnakamura
10.09.2016 01:13Проблема в том, что у меня пока не получилось это объяснить ни одному человеку. Да и в целом порог вхождения без шуток гигантский — это месяцы тренировок, чтобы уверенно узнавать все радикалы, знать, что ?, ? и ? — это одно и тоже и т.д. и т.п. Рисование черт и считание их в правильном порядке вообще толком неотделимо от изучения самих kanji как таковых. В современном мире, по большому счету, умение относительно бесполезное. Я сам, например, от руки пишу весьма криво и медленно, и куча моих знакомых так же. Все с клавиатуры, культуры ?? никакой.
Китайские словари, кстати, сильно отличаются от японских, если уж на то пошло. Я так понимаю, в Китае более-менее победила 4-угловая система, что сильно упрощает жизнь при таком количестве значков. В Японии — кто в лес, кто по дрова.
mnakamura
09.09.2016 12:57Я его уже пару лет не пробовал, когда пробовал — результат был практически бесполезный. Сейчас попробовал на себе — в целом все сильно лучше, но, во-первых, до идеала еще очень далеко (особенно на более сложных kanji где >20 штрихов), во-вторых, возможно, это не потому, что там движок как-то улучшили, а скорее потому, что я сам стал рисовать это все несколько более правильно за это время.
Говорят, что еще помогают приложения, ставящиеся на телефон — фотографируешь текст, тебе его распознают.
Тут был еще неподтвержденный комментарий примерно в ту же тему, но модераторы его удалили :(
RZK333
09.09.2016 13:06этот же google translate на смартфонах неплохо распознает «шрифтовые» кандзи с фотографий, один и тот же движок :)
интернет, естественно, требует для своей работы.
TrueBers
Выглядит круто. Сам занимаюсь реверс-инжинирингом, с новеллами не сталкивался и поэтому возник вопрос:
Часто вижу на фриланс-биржах задачи с реверсом именно визуальных новелл.
Почему к ним такой высокий интерес? Это какие особенности движков, которые можно использовать для создания своих новелл? Не дешевле будет создать свой движок, нежели платить за реверс уже существующего?
mnakamura
Ни разу, честно говоря, не сталкивался с тем, чтобы искали реверсеров за деньги на фрилансе — но могу предположить, что сейчас идет определенный бум популярности визуальных новелл у западных издательств. Есть MangaGamer, есть Sekai Project, которые если не прям купаются в долларах, то выходят на хороших промышленный уровень регулярных выпусков переводов.
Сами по себе затраты на лицензирование и переводы — сравнительно небольшие. Если повезет — то, вон, какая-нибудь Grisaia собрала на предзаказе почти пол-миллиона долларов. Лицензионные отчисления — единицы или десятки тысяч долларов, остальное забирает западный издатель. Для небольшой команды — это вполне себе деньги, особенно если выпускать по 2-3 новеллы в месяц.
На практике все, конечно, совсем не так радужно, но куча народа думает, что это именно что простой способ заработка. И как только ты провел переговоры с японцами, закупил права и начал перевод, выясняется что-нибудь вроде того, что:
Тут, видимо, и приходит в голову остроумная идея нанять фрилансера для разбирательства с движком?